Carbon Footprint
クラウドの二酸化炭素排出量を測定、報告、削減します
レポートや情報開示にロケーション ベースと市場ベースの両方の二酸化炭素排出量データを含める
二酸化炭素排出量の分析情報をダッシュボードとグラフで可視化する
クラウド アプリケーションとインフラストラクチャからの排出量を削減する
主な機能
主な機能
[新規] ロケーション ベースの排出量と市場ベースの排出量のデュアル レポート
コンソール内ダッシュボードと BigQuery のエクスポートでは、スコープ 1 とスコープ 3 の排出量に加えて、スコープ 2 の排出量データ(市場ベースとのロケーション ベースの両方)が提供されます。
電力関連(スコープ 2)の排出量について市場ベースのデータに限定したレポートと比較して、デュアル レポートでは、さまざまなユースケースに対して透明性と包括性の高い分析情報が提供されます。
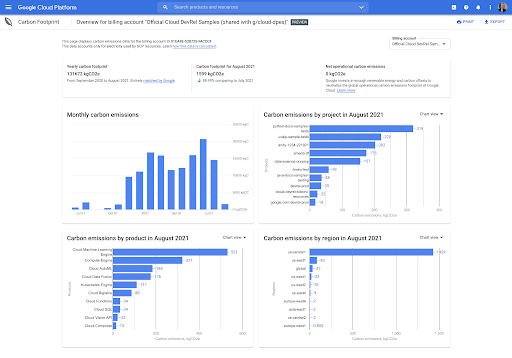
コンソール内ダッシュボード
ダッシュボードのデータの概要では、アカウントの対象となる Google Cloud サービスの使用状況に関連付けられている、3 つのスコープすべてにおける二酸化炭素排出量(ロケーション ベースと市場ベースの両方)の概要を確認できます。
BigQuery への詳細な自動エクスポート
Carbon Footprint データを BigQuery にエクスポートして、データ分析、カスタム ダッシュボードやレポートの作成、組織の総排出量計算ツールへのデータの取り込みを行えます。
選択した請求先アカウントの Google Cloud サービス、プロジェクト、リージョン、月に基づいて、利用可能なすべての月の二酸化炭素排出量を詳細に分析できます。
ロケーション ベースの排出量削減の推定
Carbon Footprint データは、放置されたプロジェクトの Recommender と統合されています。これにより、アイドル状態のプロジェクトを削除することで実現できる、ロケーション ベースの排出量削減の推定値を確認できます。
サードパーティによる Carbon Footprint 手法のレビュー
Carbon Footprint 手法が GHG プロトコルごとに Google Cloud プロダクトの二酸化炭素排出量の計算、割り当てに適していて合理的であると結論付けている Google のサステナビリティ コンサルティングに関する第三者の専門家によるレビュー ステートメントを公開しています。
導入事例
環境への影響の低減を支援
Google Cloud は、お客様と連携し、お客様がサステナビリティに関する目標を達成できるよう支援しています。



最新情報
最新のカーボン レポートに関するニュースやイベントをチェック
Google Cloud のニュースレターにご登録いただくと、プロダクトの最新情報、イベント情報、特典のお知らせなどが配信されます。



ドキュメント
ドキュメント
料金
料金
Carbon Footprint は、すべての Google Cloud のお客様に無料で提供されています。
二酸化炭素排出量データを BigQuery にエクスポートすると、料金を最小限に抑えることができます。予想される料金については、ストレージとクエリの費用の見積もりをご覧ください。







開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る











