Questo tutorial illustra come utilizzare Dataflow per estrarre, trasformare e caricare i dati (ETL) di un database relazionale di elaborazione delle transazioni online (OLTP) in BigQuery per l'analisi.
Questo tutorial è rivolto ad amministratori di database, professionisti delle operazioni e Cloud Architect interessati a sfruttare le funzionalità di query analitiche di BigQuery e le funzionalità di elaborazione batch di Dataflow.
I database OLTP sono spesso database relazionali che archiviano informazioni ed elaborano transazioni per siti di e-commerce, applicazioni SaaS (Software as a Service) o giochi. I database OLTP sono generalmente ottimizzati per le transazioni, che richiedono le proprietà ACID (atomicità, coerenza, isolamento e durabilità) e in genere hanno schemi altamente normalizzati. Al contrario, i data warehouse tendono a essere ottimizzati per il recupero e l'analisi dei dati, anziché per le transazioni, e in genere presentano schemi denormalizzati. Generalmente, la denormalizzazione dei dati di un database OLTP li rende più utili per l'analisi in BigQuery.
Obiettivi
Il tutorial mostra due approcci ai dati RDBMS normalizzati ETL in dati BigQuery denormalizzati:
- Utilizzo di BigQuery per caricare e trasformare i dati. Utilizza questo approccio per eseguire un caricamento una tantum di una piccola quantità di dati in BigQuery per l'analisi. Puoi utilizzare questo approccio anche per prototipare il set di dati prima di automatizzare set di dati più grandi o multipli.
- Utilizzo di Dataflow per caricare, trasformare e cancellare i dati. Utilizza questo approccio per caricare una quantità maggiore di dati, caricare dati da più origini o per caricare i dati in modo incrementale o automatico.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il Calcolatore prezzi.
Una volta completate le attività descritte in questo documento, puoi evitare la fatturazione continua eliminando le risorse che hai creato. Per ulteriori informazioni, consulta la pagina Pulizia.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Abilita le API Compute Engine e Dataflow.
-
Nella pagina del selettore di progetti della console Google Cloud, seleziona o crea un progetto Google Cloud.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Abilita le API Compute Engine e Dataflow.
Utilizzo del set di dati MusicBrainz
Questo tutorial si basa sugli snapshot JSON delle tabelle nel database MusicBrainz, che è basato su PostgreSQL e contiene informazioni su tutta la musica di MusicBrainz. Alcuni elementi dello schema di MusicBrainz includono:
- Artisti
- Gruppi di rilascio
- Release
- Registrazioni
- Works
- Etichette
- Molte delle relazioni tra queste entità.
Lo schema di MusicBrainz include tre tabelle pertinenti: artist, recording e artist_credit_name. Un artist_credit rappresenta il merito attribuito all'artista per una registrazione e le righe artist_credit_name collegano la registrazione all'artista corrispondente tramite il valore artist_credit.
Questo tutorial fornisce le tabelle PostgreSQL già estratte in formato JSON delimitato da una nuova riga e archiviate in un bucket Cloud Storage pubblico: gs://solutions-public-assets/bqetl
Se vuoi eseguire questo passaggio autonomamente, devi disporre di un database PostgreSQL contenente il set di dati MusicBrainz e utilizzare i seguenti comandi per esportare ciascuna tabella:
host=POSTGRES_HOST
user=POSTGRES_USER
database=POSTGRES_DATABASE
for table in artist recording artist_credit_name
do
pg_cmd="\\copy (select row_to_json(r) from (select * from ${table}) r ) to exported_${table}.json"
psql -w -h ${host} -U ${user} -d ${db} -c $pg_cmd
# clean up extra '\' characters
sed -i -e 's/\\\\/\\/g' exported_${table}.json
done
Approccio 1: ETL con BigQuery
Utilizza questo approccio per eseguire un caricamento una tantum di una piccola quantità di dati in BigQuery per l'analisi. Puoi utilizzare questo approccio anche per prototipare il set di dati prima di utilizzare l'automazione con set di dati più grandi o più grandi.
Crea un set di dati BigQuery
Per creare un set di dati BigQuery, devi caricare le tabelle MusicBrainz in BigQuery singolarmente, quindi unire le tabelle caricate in modo che ogni riga contenga il collegamento dati che vuoi. Puoi archiviare i risultati join in una nuova tabella BigQuery. Poi puoi eliminare le tabelle originali che hai caricato.
Nella console Google Cloud, apri BigQuery.
Nel riquadro Explorer, fai clic sul menu more_vert accanto al nome del progetto, quindi fai clic su Crea set di dati.
Nella finestra di dialogo Crea set di dati, completa i seguenti passaggi:
- Nel campo ID set di dati, inserisci
musicbrainz. - Imposta Ubicazione dei dati su us.
- Fai clic su Crea set di dati.
- Nel campo ID set di dati, inserisci
Importare tabelle MusicBrainz
Per ogni tabella MusicBrainz, procedi nel seguente modo per aggiungere una tabella al set di dati creato:
- Nel riquadro BigQuery Explorer della console Google Cloud, espandi la riga con il nome del progetto per visualizzare il set di dati
musicbrainzappena creato. - Fai clic sul menu more_vert accanto al set di dati
musicbrainz, quindi fai clic su Crea tabella. Nella finestra di dialogo Crea tabella, completa i seguenti passaggi:
- Nell'elenco a discesa Crea tabella da, seleziona Google Cloud Storage.
Nel campo Seleziona file dal bucket GCS, inserisci il percorso del file di dati:
solutions-public-assets/bqetl/artist.jsonIn Formato file, seleziona JSONL (Newline Delimited JSON).
Assicurati che Project contenga il nome del tuo progetto.
Assicurati che il set di dati sia
musicbrainz.In Tabella, inserisci
artistcome nome della tabella.Per Tipo di tabella, lascia selezionata l'opzione Tabella nativa.
Sotto la sezione Schema, fai clic per attivare Modifica come testo.
Scarica il file di schema
artiste aprilo in un editor di testo o in un visualizzatore.Sostituisci i contenuti della sezione Schema con i contenuti del file di schema che hai scaricato.
Fai clic su Crea tabella:
Attendi qualche istante per il completamento del job di caricamento.
Al termine del caricamento, la nuova tabella viene visualizzata sotto il set di dati.
Ripeti i passaggi 1-5 per creare la tabella
artist_credit_namecon le seguenti modifiche:Utilizza il seguente percorso per il file di dati di origine:
solutions-public-assets/bqetl/artist_credit_name.jsonUtilizza
artist_credit_namecome nome della tabella.Scarica il file dello schema
artist_credit_namee utilizza i contenuti dello schema.
Ripeti i passaggi 1-5 per creare la tabella
recordingcon le seguenti modifiche:Utilizza il seguente percorso per il file di dati di origine:
solutions-public-assets/bqetl/recording.jsonUtilizza
recordingcome nome della tabella.Scarica il file dello schema
recordinge utilizza i contenuti dello schema.
Denormalizzare manualmente i dati
Per denormalizzare i dati, uniscili in una nuova tabella BigQuery con una riga per la registrazione di ogni artista, insieme ai metadati selezionati che vuoi conservare per l'analisi.
- Se l'editor query di BigQuery non è aperto nella console Google Cloud, fai clic su add_box Crea nuova query.
Copia la seguente query e incollala nell'Editor query:
SELECT artist.id, artist.gid AS artist_gid, artist.name AS artist_name, artist.area, recording.name AS recording_name, recording.length, recording.gid AS recording_gid, recording.video FROM `musicbrainz.artist` AS artist INNER JOIN `musicbrainz.artist_credit_name` AS artist_credit_name ON artist.id = artist_credit_name.artist INNER JOIN `musicbrainz.recording` AS recording ON artist_credit_name.artist_credit = recording.artist_creditFai clic sull'elenco a discesa settings Altro e seleziona Impostazioni query.
Nella finestra di dialogo Impostazioni query, completa i seguenti passaggi:
- Seleziona Imposta una tabella di destinazione per i risultati della query.
- In Set di dati, inserisci
musicbrainze seleziona il set di dati nel tuo progetto. - In ID tabella, inserisci
recordings_by_artists_manual. - In Preferenza di scrittura della tabella di destinazione, fai clic su Sovrascrivi tabella.
- Seleziona la casella di controllo Consenti risultati di grandi dimensioni (nessun limite di dimensione).
- Fai clic su Salva.
Fai clic su play_circle_filled Esegui.
Al termine della query, i dati del risultato della query sono organizzati in canzoni per ogni artista nella tabella BigQuery appena creata e in un campione dei risultati mostrati nel riquadro Risultati delle query, ad esempio:
Row id artist_gid artist_name area recording_name lunghezza recording_gid video 1 97546 125ec42a... unknown 240 Horo Gun Toireamaid Hùgan Fhathast Air 174106 c8bbe048... FALSE 2 266317 2e7119b5... Capella Istropolitana 189 Concerto Grosso in D minor, op. 2 no. 3: II. Adagio 134000 af0f294d... FALSE 3 628060 34cd3689... Conspirare 5196 Liturgy, op. 42: 9. Praise the Lord from the Heavens 126933 8bab920d... FALSE 4 423877 54401795... Boys Air Choir 1178 Nunc Dimittis 190000 111611eb... FALSE 5 394456 9914f9f9... L’Orchestre de la Suisse Romande 23036 Concert Waltz no. 2, op. 51 509960 b16742d1... FALSE
Approccio 2: ETL in BigQuery con Dataflow
In questa sezione del tutorial, anziché utilizzare l'interfaccia utente di BigQuery, utilizzerai un programma di esempio per caricare dati in BigQuery mediante una pipeline Dataflow. Quindi, utilizzerai il modello di programmazione Beam per denormalizzare e pulire i dati da caricare in BigQuery.
Prima di iniziare, rivedi i concetti e il codice campione.
Rivedi i concetti
Sebbene i dati siano di piccole dimensioni e possano essere caricati rapidamente utilizzando l'interfaccia utente di BigQuery, ai fini di questo tutorial puoi utilizzare anche Dataflow per l'ETL. Utilizza Dataflow per l'ETL in BigQuery anziché nell'interfaccia utente di BigQuery quando esegui enormi join, ovvero da circa 500-5000 colonne di oltre 10 TB di dati, con i seguenti obiettivi:
- Vuoi pulire o trasformare i dati man mano che vengono caricati in BigQuery, anziché archiviarli e unirli in un secondo momento. Di conseguenza, questo approccio ha anche requisiti di archiviazione inferiori perché i dati vengono archiviati in BigQuery solo nello stato unito e trasformato.
- Prevedi di eseguire una pulizia personalizzata dei dati (che non può essere ottenuta semplicemente con SQL).
- Prevedi di combinare i dati con dati esterni all'OLTP, come log o dati a cui si accede in remoto, durante il processo di caricamento.
- Prevedi di automatizzare i test e il deployment della logica di caricamento dei dati utilizzando l'integrazione continua o il deployment continuo (CI/CD).
- Prevedi l'iterazione graduale, il miglioramento e il miglioramento del processo ETL nel tempo.
- Prevedi di aggiungere dati in modo incrementale invece di eseguire un ETL una tantum.
Ecco un diagramma della pipeline di dati creata dal programma di esempio:

Nel codice di esempio, molti passaggi della pipeline vengono raggruppati o aggregati in metodi pratici, indicati con nomi descrittivi e riutilizzati. Nel diagramma, i passaggi riutilizzati sono indicati con bordi tratteggiati.
Esamina il codice della pipeline
Il codice crea una pipeline che esegue i seguenti passaggi:
Carica ogni tabella che vuoi far parte del join dal bucket Cloud Storage pubblico in un
PCollectiondi stringhe. Ogni elemento include la rappresentazione JSON di una riga della tabella.Converte le stringhe JSON in rappresentazioni di oggetti
MusicBrainzDataObject, quindi organizza le rappresentazioni degli oggetti in base a uno dei valori della colonna, ad esempio una chiave primaria o esterna.Entra a far parte dell'elenco in base all'artista più comune. Il
artist_credit_namecollega i riconoscimenti di un artista con la sua registrazione e include la chiave esterna dell'artista. La tabellaartist_credit_nameviene caricata come elenco di oggettiKVdelle coppie chiave-valore. Il membroKè l'artista.Unisce l'elenco utilizzando il metodo
MusicBrainzTransforms.innerJoin().- Raggruppa le raccolte di oggetti
KVin base al membro della chiave a cui vuoi partecipare. Ciò generaPCollectiondiKVoggetti con una chiave lunga (il valore della colonnaartist.id) e risultanteCoGbkResult(che sta per Combina gruppo per risultato chiave). L'oggettoCoGbkResultè una tupla di elenchi di oggetti il cui valore-chiave è in comune tra il primo e il secondoPCollections. È possibile indirizzare questa tupla utilizzando il tag della tupla formulato per ogniPCollectionprima di eseguire l'operazioneCoGroupByKeynel metodogroup. Unisce ogni corrispondenza di oggetti in un oggetto
MusicBrainzDataObjectche rappresenta un risultato di join.Riorganizza la raccolta in un elenco di
KVoggetti per iniziare il join successivo. Questa volta il valoreKè la colonnaartist_credit, utilizzata per l'unione alla tabella di registrazione.Consente di ottenere la raccolta finale risultante di
MusicBrainzDataObjectoggetti unendo questo risultato alla raccolta caricata di registrazioni organizzate daartist_credit.id.Mappa gli oggetti
MusicBrainzDataObjectsrisultanti inTableRows.Scrive il valore
TableRowsrisultante in BigQuery.
- Raggruppa le raccolte di oggetti
Per informazioni dettagliate sui meccanismi della programmazione delle pipeline Beam, consulta i seguenti argomenti relativi al modello di programmazione:
PCollection- Caricamento di dati da file di testo (incluso Cloud Storage)
- Trasformazioni come
ParDoe MapElements' - Partecipazione e
GroupByKey - I/O BigQuery
Dopo aver esaminato i passaggi eseguiti dal codice, puoi eseguire la pipeline.
crea un bucket Cloud Storage
Esegui il codice della pipeline
Nella console Google Cloud, apri Cloud Shell.
Imposta le variabili di ambiente per lo script del progetto e della pipeline
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow export DATASET=musicbrainzSostituisci PROJECT_ID con l'ID del tuo progetto Google Cloud.
Assicurati che
gcloudstia utilizzando il progetto che hai creato o selezionato all'inizio del tutorial:gcloud config set project $PROJECT_IDSegui il principio di sicurezza del privilegio minimo, crea un account di servizio per la pipeline Dataflow e concedigli solo i privilegi necessari: i ruoli
roles/dataflow.worker,roles/bigquery.jobUseredataEditornel set di datimusicbrainz:gcloud iam service-accounts create musicbrainz-dataflow export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.com gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/dataflow.worker gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member=serviceAccount:${SERVICE_ACCOUNT} \ --role=roles/bigquery.jobUser bq query --use_legacy_sql=false \ "GRANT \`roles/bigquery.dataEditor\` ON SCHEMA musicbrainz TO 'serviceAccount:${SERVICE_ACCOUNT}'"Crea un bucket per la pipeline Dataflow da utilizzare per i file temporanei e concedi all'account di servizio
musicbrainz-dataflowi privilegiOwner:export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} gsutil mb -l us ${DATAFLOW_TEMP_BUCKET} gsutil acl ch -u ${SERVICE_ACCOUNT}:O ${DATAFLOW_TEMP_BUCKET}Clona il repository che contiene il codice Dataflow:
git clone https://github.com/GoogleCloudPlatform/bigquery-etl-dataflow-sample.gitCambia la directory nell'esempio:
cd bigquery-etl-dataflow-sampleCompila ed esegui il job Dataflow:
./run.sh simpleL'esecuzione del job dovrebbe richiedere circa 10 minuti.
Per visualizzare l'avanzamento della pipeline, vai alla pagina Dataflow nella console Google Cloud.
Lo stato dei job viene visualizzato nella colonna dello stato. Lo stato Riuscito indica che il job è stato completato.
(Facoltativo) Per visualizzare il grafico del job e i dettagli sui passaggi, fai clic sul nome del job, ad esempio
etl-into-bigquery-bqetlsimple.Una volta completato il job, vai alla pagina BigQuery.
Per eseguire una query sulla nuova tabella, nel riquadro Editor query, inserisci quanto segue:
SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;Il riquadro dei risultati mostrerà un insieme di risultati simili al seguente:
Row artist_name artist_gender artist_area recording_name recording_length 1 mirin 2 107 Sylphia 264000 2 mirin 2 107 Dependence 208000 3 Gaudiburschen 1 81 Die Hände zum Himmel 210000 4 Sa4 1 331 Ein Tag aus meiner Sicht 221000 5 Dpat 1 7326 Cutthroat 249000 6 Dpat 1 7326 Deloused 178000 L'output effettivo potrebbe variare in quanto i risultati non sono ordinati.
Pulisci i dati
Successivamente, apporterai una leggera modifica alla pipeline Dataflow in modo da poter caricare le tabelle di ricerca ed elaborarle come input secondari, come mostrato nel diagramma seguente.

Quando esegui una query sulla tabella BigQuery risultante, è difficile determinare da dove proviene l'artista senza cercare manualmente l'ID numerico dell'area dalla tabella area del database MusicBrainz. Ciò rende
l'analisi dei risultati delle query meno semplice di quanto potrebbe essere.
Allo stesso modo, i generi degli artisti vengono mostrati come ID, ma l'intera tabella dei generi di MusicBrainz è composta solo da tre righe. Per risolvere il problema, puoi aggiungere un passaggio nella pipeline di Dataflow per utilizzare le tabelle area e gender di MusicBrainz al fine di mappare gli ID alle rispettive etichette.
Entrambe le tabelle artist_area e artist_gender contengono un numero significativamente inferiore di righe rispetto agli artisti o alla tabella di dati di registrazione. Il numero di elementi nelle tabelle successive è limitato rispettivamente dal numero di aree geografiche o generi.
Di conseguenza, la fase di ricerca utilizza la funzionalità Dataflow denominata input laterale.
Gli input secondari vengono caricati come esportazioni delle tabelle di file JSON delimitati da righe nel bucket Cloud Storage pubblico contenente il set di dati musicbrainz e vengono utilizzati per denormalizzare i dati della tabella in un unico passaggio.
Esamina il codice che aggiunge input secondari alla pipeline
Prima di eseguire la pipeline, esamina il codice per comprendere meglio i nuovi passaggi.
Questo codice dimostra la pulizia dei dati con input collaterali. La classe MusicBrainzTransforms offre una maggiore comodità per l'utilizzo di input laterali per mappare i valori chiave esterna alle etichette. La libreria MusicBrainzTransforms
fornisce un metodo che crea una classe di ricerca interna. La classe di ricerca descrive ogni tabella di ricerca e i campi che vengono sostituiti con etichette e argomenti di lunghezza variabile. keyKey è il nome della colonna che contiene la chiave di ricerca e valueKey è il nome della colonna che contiene l'etichetta corrispondente.
Ogni input laterale viene caricato come un singolo oggetto mappa, che viene utilizzato per cercare l'etichetta corrispondente per un ID.
Innanzitutto, il codice JSON per la tabella di ricerca viene caricato inizialmente in MusicBrainzDataObjects con uno spazio dei nomi vuoto e trasformato in una mappa dal valore della colonna Key al valore della colonna Value.
Ciascuno di questi oggetti Map viene inserito in un oggetto Map in base al valore del relativo
destinationKey, che è la chiave da sostituire con i valori cercati.
Quindi, durante la trasformazione degli oggetti dell'artista in formato JSON, il valore di destinationKey (che inizia come numero) viene sostituito con la relativa etichetta.
Per aggiungere la decodifica dei campi artist_area e artist_gender, svolgi i seguenti passaggi:
In Cloud Shell, assicurati che l'ambiente sia configurato per lo script della pipeline:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_sideinputs export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comSostituisci PROJECT_ID con l'ID del tuo progetto Google Cloud.
Esegui la pipeline per creare la tabella con l'area decodificata e il genere dell'artista:
./run.sh simple-with-lookupsCome prima, per visualizzare l'avanzamento della pipeline, vai alla pagina Dataflow.
Il completamento della pipeline richiederà circa 10 minuti.
Una volta completato il job, vai alla pagina BigQuery.
Esegui la stessa query che include
artist_areaeartist_gender:SELECT artist_name, artist_gender, artist_area, recording_name, recording_length FROM musicbrainz.recordings_by_artists_dataflow_sideinputs WHERE artist_area is NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;Nell'output,
artist_areaeartist_gendersono ora decodificati:Row artist_name artist_gender artist_area recording_name recording_length 1 mirin Female Japan Sylphia 264000 2 mirin Female Japan Dependence 208000 3 Gaudiburschen Male Germany Die Hände zum Himmel 210000 4 Sa4 Male Hamburg Ein Tag aus meiner Sicht 221000 5 Dpat Male Houston Cutthroat 249000 6 Dpat Male Houston Deloused 178000 L'output effettivo potrebbe variare in quanto i risultati non sono ordinati.
Ottimizzare lo schema BigQuery
Nella parte finale di questo tutorial eseguirai una pipeline che genera uno schema di tabella più ottimale utilizzando campi nidificati.
Esamina il codice utilizzato per generare questa versione ottimizzata della tabella.
Il seguente diagramma mostra una pipeline Dataflow leggermente diversa che nidifica le registrazioni dell'artista all'interno di ogni riga di artista, invece di creare righe di artisti duplicate.

L'attuale rappresentazione dei dati è piuttosto piatta. In altre parole, include una
riga per registrazione accreditata che include tutti i metadati dell'artista provenienti dallo
schema di BigQuery, nonché tutte le registrazioni e i metadati artist_credit_name. Questa rappresentazione semplice presenta almeno due svantaggi:
- Vengono ripetuti i metadati
artistper ogni registrazione attribuita a un artista, il che a sua volta aumenta lo spazio di archiviazione necessario. - Quando esporti i dati in formato JSON, viene esportato un array che ripete quei dati, invece di un artista con i dati di registrazione nidificati, che probabilmente sono quelli che vuoi.
Senza alcuna penalità delle prestazioni e senza utilizzare spazio di archiviazione aggiuntivo, invece di archiviare una registrazione per riga, puoi archiviarle come campo ripetuto in ogni record dell'artista apportando alcune modifiche alla pipeline di Dataflow.
Anziché unire le registrazioni alle informazioni sull'artista tramite artist_credit_name.artist, questa pipeline alternativa crea un elenco nidificato di registrazioni all'interno di un oggetto artist.
L'API BigQuery prevede un limite massimo di dimensione delle righe di 100 MB durante l'esecuzione di inserti collettivi (10 MB per l'inserimento di flussi di dati), di conseguenza il codice limita il numero di registrazioni nidificate per un determinato record a 1000 elementi per garantire che questo limite non venga raggiunto. Se un determinato artista ha più di 1000 registrazioni, il codice duplica la riga, inclusi i metadati artist, e continua a nidificare i dati della registrazione nella riga duplicata.
Il diagramma mostra le origini, le trasformazioni e i sink della pipeline.
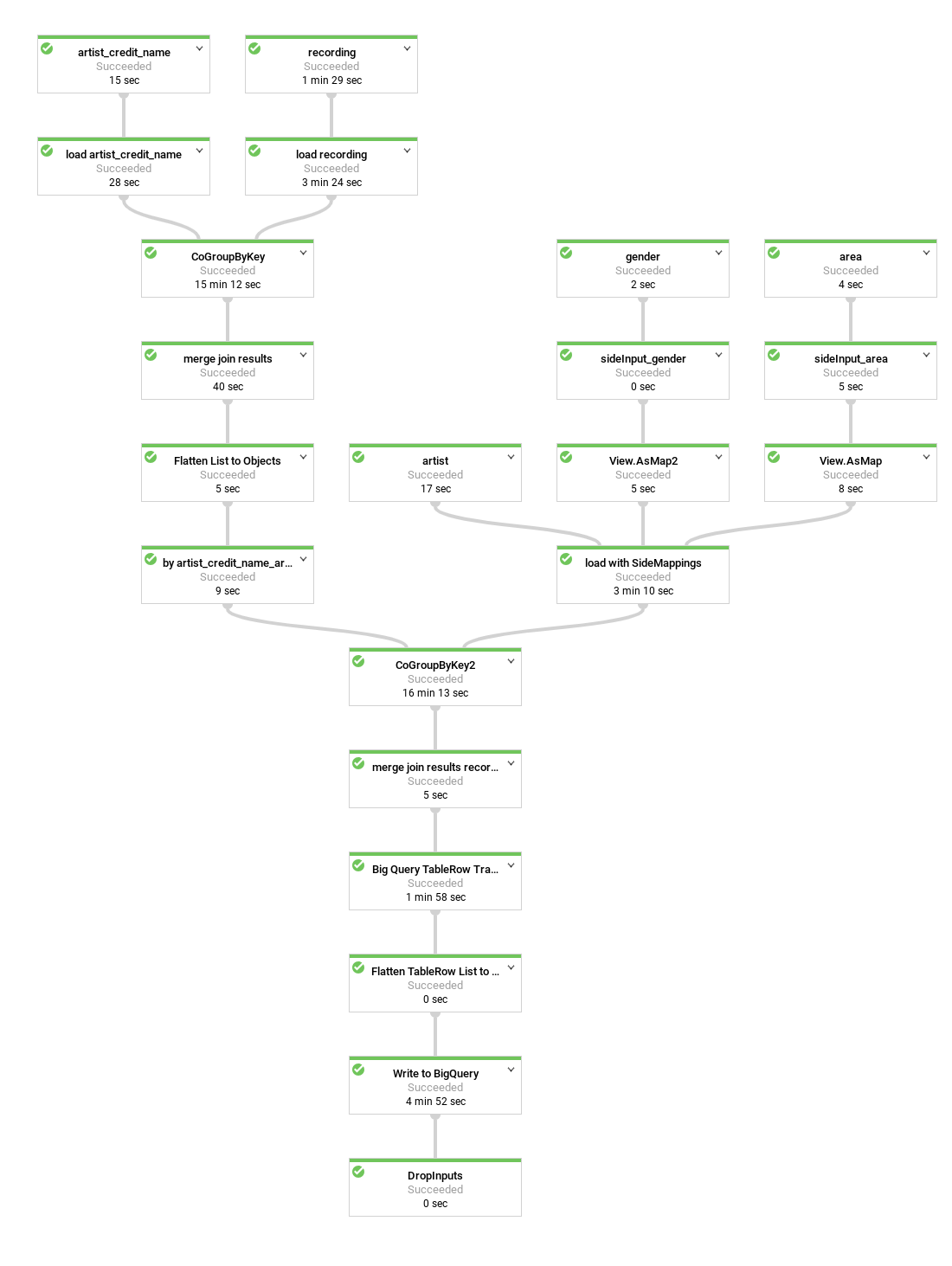
Nella maggior parte dei casi, i nomi dei passaggi sono forniti nel codice come parte della chiamata al metodo apply.
Per creare questa pipeline ottimizzata, completa i seguenti passaggi:
In Cloud Shell, assicurati che l'ambiente sia configurato per lo script della pipeline:
export PROJECT_ID=PROJECT_ID export REGION=us-central1 export DESTINATION_TABLE=recordings_by_artists_dataflow_nested export DATASET=musicbrainz export DATAFLOW_TEMP_BUCKET=gs://temp-bucket-${PROJECT_ID} export SERVICE_ACCOUNT=musicbrainz-dataflow@${PROJECT_ID}.iam.gserviceaccount.comEsegui la pipeline per nidificare le righe di registrazione all'interno delle righe dell'artista:
./run.sh nestedCome prima, per visualizzare l'avanzamento della pipeline, vai alla pagina Dataflow.
Il completamento della pipeline richiederà circa 10 minuti.
Una volta completato il job, vai alla pagina BigQuery.
Campi di query dalla tabella nidificata in BigQuery:
SELECT artist_name, artist_gender, artist_area, artist_recordings FROM musicbrainz.recordings_by_artists_dataflow_nested WHERE artist_area IS NOT NULL AND artist_gender IS NOT NULL LIMIT 1000;Nell'output, i valori
artist_recordingsvengono mostrati come righe nidificate che possono essere espanse:Row artist_name artist_gender artist_area artist_recordings 1 mirin Female Japan (5 rows) 3 Gaudiburschen Male Germany (1 row) 4 Sa4 Male Hamburg (10 rows) 6 Dpat Male Houston (9 rows) L'output effettivo potrebbe variare in quanto i risultati non sono ordinati.
Esegui una query per estrarre valori da
STRUCTe usarli per filtrare i risultati, ad esempio per gli artisti che hanno registrazioni contenenti la parola "Giuseppe":SELECT artist_name, artist_gender, artist_area, ARRAY(SELECT artist_credit_name_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS artist_credit_name_name, ARRAY(SELECT recording_name FROM UNNEST(recordings_by_artists_dataflow_nested.artist_recordings)) AS recording_name FROM musicbrainz.recordings_by_artists_dataflow_nested, UNNEST(recordings_by_artists_dataflow_nested.artist_recordings) AS artist_recordings_struct WHERE artist_recordings_struct.recording_name LIKE "%Justin%" LIMIT 1000;Nell'output,
artist_credit_name_nameerecording_namevengono mostrate come righe nidificate che possono essere espanse, ad esempio:Row artist_name artist_gender artist_area artist_credit_name_name recording_name 1 Damonkenutz null null (1 row) 1 Yellowpants (Justin Martin remix) 3 Fabian Male Germany (10+ rows) 1 Heatwave . 2 Starlight Love . 3 Dreams To Wishes . 4 Last Flight (Justin Faust remix) . ... 4 Digital Punk Boys null null (6 rows) 1 Come True . 2 We Are... (Punkgirlz remix by Justin Famous) . 3 Chaos (short cut) . ... L'output effettivo potrebbe variare in quanto i risultati non sono ordinati.
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Eliminazione di singole risorse
Segui questa procedura per eliminare singole risorse, anziché eliminare l'intero progetto.
Eliminazione del bucket Cloud Storage
- Nella console Google Cloud, vai alla pagina Bucket di Cloud Storage.
- Fai clic sulla casella di controllo relativa al bucket da eliminare.
- Per eliminare il bucket, fai clic su Elimina e segui le istruzioni.
Eliminazione dei set di dati BigQuery
Apri l'interfaccia utente web di BigQuery.
Seleziona i set di dati BigQuery che hai creato durante il tutorial.
Fai clic su Eliminadelete.
Passaggi successivi
- Scopri di più sulla scrittura di query per BigQuery. L'esecuzione di query sui dati spiega come eseguire query sincrone e asincrone, creare funzioni definite dall'utente e altro ancora.
- Esplora la sintassi di BigQuery. BigQuery utilizza una sintassi di tipo SQL descritta nel Riferimento per query (SQL precedente).
- Esplora le architetture di riferimento, i diagrammi e le best practice su Google Cloud. Visita il nostro Cloud Architecture Center.