Application Integration でサポートされているコネクタをご覧ください。
データ マッピング タスク
データ マッピングタスクを使用すると、統合で変数の割り当てを実行し、json オブジェクトのプロパティを取得して設定し、値にネストされた変換関数を適用できます。これらの変数は統合変数またはタスク変数です。
たとえば、統合変数 X の値をタスク変数 Y に割り当てることも、タスク変数 Y の値を統合変数 X に割り当てることもできます。Application Integration の変数の詳細については、Application Integration での変数の使用をご覧ください。
データ マッピング タスクを構成する
データ マッピング タスクを構成するには、次の手順を実施します。
- Google Cloud コンソールで、[Application Integration] ページに移動します。
- ナビゲーション メニューで [統合] をクリックします。
[統合] ページが開き、Google Cloud プロジェクトで使用可能なすべての統合が一覧表示されます。
- 既存の統合を選択するか、[統合の作成] をクリックして新しい統合を作成します。
新しい統合を作成する場合:
- [統合の作成] ペインで名前と説明を入力します。
- 統合のリージョンを選択します。
- 統合用のサービス アカウントを選択します。統合のサービス アカウントの詳細は、統合ツールバーの [統合の概要] ペインでいつでも変更または更新できます。
- [作成] をクリックします。新しく作成された統合が統合エディタで開きます。
- 統合エディタのナビゲーション バーで、[タスク] をクリックして、使用可能なタスクとコネクタのリストを表示します。
- 統合エディタで [Data Mapping] 要素をクリックして配置します。
- デザイナーの [Data Mapping] 要素をクリックして、[Data Mapping] タスク構成ペインを表示します。
-
タスクのデフォルト値を表示して、新しいマッピングを追加するには、[データ マッピング エディタを開く] をクリックします。マッピングの追加方法について詳しくは、マッピングの追加をご覧ください。
データ マッピング エディタのレイアウトの詳細については、データ マッピングの概要をご覧ください。
マッピングを追加する
マッピングを追加する手順は、次のとおりです。
- データ マッピング タスク構成ペインで、[Open Data Mapping Editor] をクリックします。
- マッピング [Input] を構成します。
- 変数またはそのサブフィールドを、[Variables] リストから [Input] 行にドラッグします。変数の使用可能なサブフィールドを表示するには、[Variables] リストの変数の横にある (Expand)をクリックします。
- または、入力行で、変数または値をクリックし、次の操作を行います。
- [変数] を選択して、既存の変数を検索して使用します。新しい変数を作成するには、[+ Add new variable] をクリックして、新しい変数の名前とデータ型を入力します。
- [値] を選択して、
string、integer、double、Boolean型のリテラル値を入力します。 - [Function] を選択して、基本関数を検索して使用します。
基本関数は、統合の実行中に値を取得または生成するために使用されます。たとえば、ランダムな UUID の生成、現在の統合リージョンの取得などです。サポートされている基本関数については、サポートされている基本関数をご覧ください。
- [保存] をクリックします。
- [Input] 行の任意の入力変数、値、または基本関数で [+(Add a function)] をクリックして、使用可能なマッピング関数のリストからマッピング関数を追加します。マッピング関数には 1 つ以上のパラメータを指定できます。各パラメータには、さらに値、変数、または基本関数の後にマッピング関数のチェーンを記述できます。
- ネストされた関数を追加するには、関数のパラメータの横にある [+(Add a function)] をクリックします。同様に、最後に追加された関数を削除するには、[- (直前の関数を削除)] をクリックします。
- マッピング式の間で関数を追加、削除、または変更するには、関数をクリックし、プルダウン メニューから [Add Function]、[Remove Function]、または [Change Function] を選択します。
- マッピング式内の変数を削除するには、変数行の横にある (Remove)をクリックします。
- 入力行全体を削除するには、行の (Clear)をクリックします。
マッピング関数の詳細については、マッピング関数をご覧ください。
サポートされているマッピング関数については、サポートされているデータ型とマッピング関数をご覧ください。
- [Output] のマッピングを構成します。
- 変数を [Variables] リストから [Output] 行にドラッグします。変数が使用できない場合は、[create a new one] をクリックして、新しい変数の名前とデータ型を構成します。必要に応じて、出力変数をクリックして、その変数を統合の出力として使用するか、別の統合への入力として使用するかを選択できます。
- 出力変数を削除するには、 (Clear) をクリックします。
- (省略可)マッピング行を削除するには、 (Delete this mapping) をクリックします。
- マッピングが完了したら、[データ マッピング エディタ] を閉じます。変更は自動的に保存されます。
完了したデータ マッピングは、次の図に示すように、[Data Mapping] タスク構成ペインに表示されます。
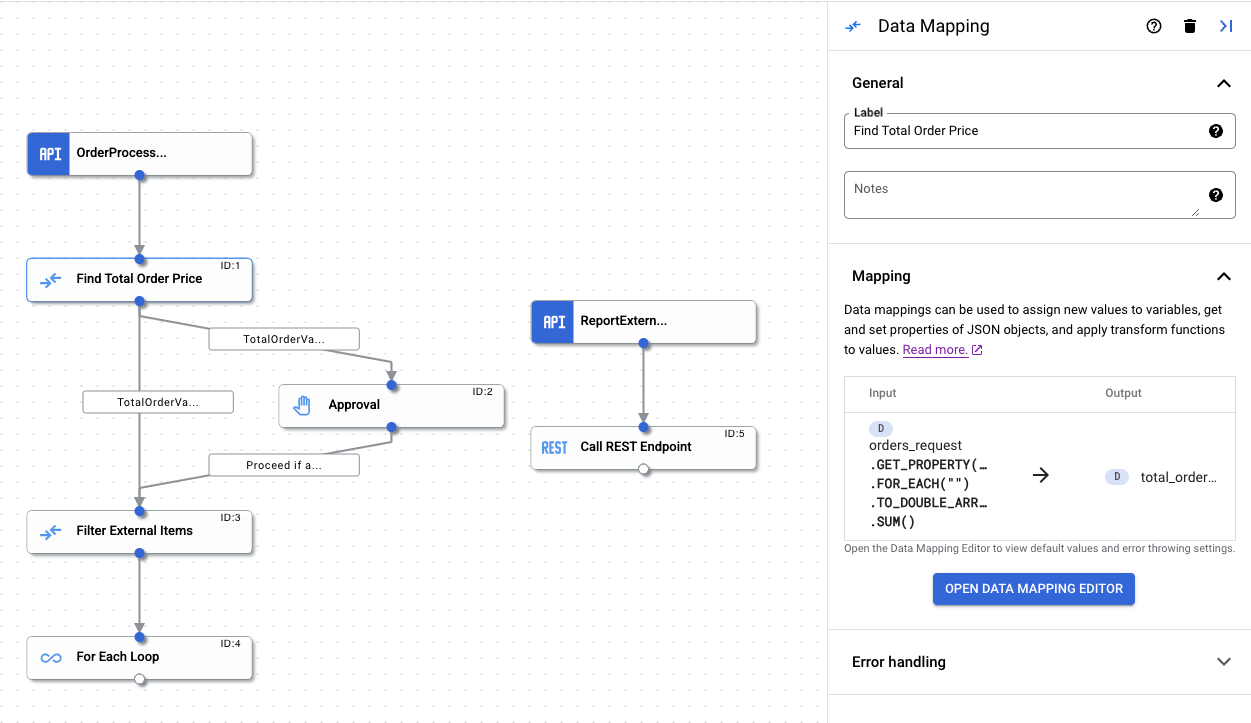
サポートされているデータ型とマッピング関数
Application Integration では、データ マッピング タスクの変数に対して次のデータ型がサポートされています。
- 文字列と文字列配列
- 整数と整数配列
- Double と Double 配列
- ブール値とブール値配列
- JSON
サポートされている基本関数
次の表に、利用可能なデータ マッピングの基本関数を示します。| データ型 | サポートされている基本関数 |
|---|---|
| 整数 | NOW_IN_MILLIS |
| 整数配列 | INT_LIST |
| 文字列 | GENERATE_UUID、GET_EXECUTION_ID、GET_INTEGRATION_NAME、GET_INTEGRATION_REGION、GET_PROJECT_ID |
ベスト プラクティス
データ マッピング タスクは、キー変数を統合内のさまざまなタスクに渡す強力な方法になります。統合を構築する際に、次のヒントを参考にしてください。
- マッピングは上から下に順次実行されます。つまり、入力変数
Aが最初の行の出力変数Bにマッピングされている場合、変数Bは、後続の行のマッピングに使用できます。 - 各行で、入力行のデータ型は出力行のデータ型と一致する必要があります。型の間でキャストするには、
TO_STRING、TO_INTなどの変換関数を使用します。 - 変換チェーンの長さに制限はありません。ただし、大規模な連鎖変換のデバッグは難しくなる場合があります。入力変換を読み取り可能にし、複雑な変換を複数のマッピングに分割することをおすすめします。
- マッピングにフォールバック値が必要な場合は、マッピングのフォールバック値を設定します。フォールバック値を指定しない場合、入力値または変換が
nullを返すときにマッピングがエラーを返します。 - 変数を削除する場合は、それを含むマッピングをすべて削除してください。
データ マッピング タスクに適用される使用量上限については、使用量上限をご覧ください。
考慮事項
JSON 変数の場合、JSON スキーマに基づいて、Application Integration では次の場合に変数の子プロパティが JSON 型として解釈されます。
- 子プロパティの型が null を指定している場合。次に例を示します。
{ "properties": { "PersonID": { "type": [ "double", "null" ], "readOnly": false } } }
- 子プロパティの型が複数のデータ型を指定している場合。次に例を示します。
{ "properties": { "PersonID": { "type": [ "integer", "string", "number" ], "readOnly": false } } }
このような場合、データ マッピング関数を使用して、子変数を目的の型に明示的に変換する必要があります。
次の例は、さまざまなタイプのプロパティ宣言を示しており、データ マッピング関数を使用して目的のタイプを取得する方法を示しています。
例 1
{ "type": "object", "properties": { "dbIntegers": { "type": "array", "items": { "type": [ "integer", "null" ] } }, "dbBooleans": { "type": [ "array" ], "items": { "type": "boolean" } } } }
dbIntegers が JSON 型として、dbBooleans が BOOLEAN_ARRAY 型として解釈されます。
dbIntegers を変換するには、次を使用します。
dbIntegers.TO_INT_ARRAY()
例 2
{ "type": "object", "properties": { "dbId": { "type": [ "number", "null" ], "readOnly": false }, "dbStatus": { "type": [ "boolean", "null" ], "readOnly": false } } }
dbId と dbStatus の両方が JSON 型として認識されますが、dbId は単一の double 値または null 値を取ることができるパラメータであり、dbStatus は単一のブール値または null 値を取ることができるパラメータです。
dbId と dbStatus を変換するには、次を使用します。
dbId.TO_DOUBLE()
dbStatus.TO_BOOLEAN()
例 3
{ "type": "object", "properties": { "dbString": { "type": [ "string" ], "readOnly": false } } }
dbString が文字列型として認識されます。エラー処理方法
タスクのエラー処理方法では、一時的なエラーによってタスクが失敗した場合のアクションを指定します。エラー処理方式と、さまざまな種類のエラー処理方式の詳細については、エラー処理方法をご覧ください。
割り当てと上限
割り当てと上限については、割り当てと上限をご覧ください。
次のステップ
- すべてのタスクとトリガーを確認する。
- データ マッピング タスクの関数について学習する
- インテグレーションをテストして公開する方法について学習する。
- エラー処理について学習する。
- 統合の実行ログについて学習する。