Google Distributed Cloud for Bare Metal(纯软件)支持多种集群日志记录和监控选项,包括云端托管式服务、开源工具,以及经过验证的与第三方商业解决方案的兼容性。本页面介绍了这些选项,并提供一些基本指导来帮助您选择适合您环境的解决方案。
本页面适用于希望监控已部署应用或服务的健康状况(例如为了实现服务等级目标 [SLO] 合规性)的管理员、架构师和运维人员。如需详细了解我们在 Google Cloud 内容中提及的常见角色和示例任务,请参阅常见的 GKE Enterprise 用户角色和任务。
用于 Google Distributed Cloud 的选项
您可以为您的集群提供多个日志记录和监控选项:
- Cloud Logging 和 Cloud Monitoring,在 Bare Metal 系统组件上默认启用。
- Prometheus 和 Grafana,可从 Cloud Marketplace 获取。
- 经过验证且适用于第三方解决方案的配置。
Cloud Logging 和 Cloud Monitoring
Google Cloud Observability 是Google Cloud的内置可观测性解决方案。它提供了全代管式日志记录解决方案、指标收集、监控、信息中心和提醒。Cloud Monitoring 监控 Google Distributed Cloud 集群的方式与监控云端 GKE 集群的方式类似。
当您使用所需服务账号和 Identity and Access Management (IAM) 角色创建集群时,系统会默认启用 Cloud Logging 和 Cloud Monitoring。您无法停用 Cloud Logging 和 Cloud Monitoring。如需详细了解服务账号和所需角色,请参阅配置服务账号。
代理可以配置为更改以下内容:
- 日志记录和监控范围,从仅限系统组件(默认)到系统组件和应用。
- 收集的指标级别,从仅限优化的指标(默认)到所有指标。
如需了解详情,请参阅本文档中的为 Google Distributed Cloud 配置 Stackdriver 代理。
Logging 和 Monitoring 提供了单一、易于配置且基于云的强大可观测性解决方案。在 Google Distributed Cloud 上运行工作负载时,我们强烈建议使用 Logging 和 Monitoring。对于组件在 Google Distributed Cloud 和标准本地基础设施上运行的应用,您可以考虑采用其他解决方案来实现这些应用的端到端视图。
如需详细了解架构、配置以及默认复制到您的 Google Cloud 项目的数据,请参阅适用于 Google Distributed Cloud 的 Logging 和 Monitoring 的工作原理。
如需详细了解 Logging,请参阅 Cloud Logging 文档。
如需详细了解 Monitoring,请参阅 Cloud Monitoring 文档。
如需了解如何在舰队级层查看和使用 Google Distributed Cloud 中的 Cloud Monitoring 资源利用率指标,请参阅使用 Google Kubernetes Engine 概览。
Prometheus 和 Grafana
Prometheus 和 Grafana 是 Cloud Marketplace 中提供的两款热门的开源监控产品:
Prometheus 会收集应用和系统指标。
Alertmanager 使用多种不同的提醒机制来发送提醒。
Grafana 是一种信息中心工具。
我们建议您使用基于 Cloud Monitoring 的 Google Cloud Managed Service for Prometheus 来满足您的所有监控需求。借助 Google Cloud Managed Service for Prometheus,您可以免费监控系统组件。Google Cloud Managed Service for Prometheus 也与 Grafana 兼容。不过,如果您更喜欢纯本地监控系统,则可以选择在集群中安装 Prometheus 和 Grafana。
如果您在本地安装了 Prometheus,并希望从系统组件收集指标,则需要向本地 Prometheus 实例授予访问系统组件的指标端点的权限:
将 Prometheus 实例的服务账号绑定到预定义的
gke-metrics-agentClusterRole,并使用服务账号令牌作为凭据从以下系统组件中抓取指标:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
使用存储在
kube-system/stackdriver-prometheus-etcd-scrapeSecret 中的客户端密钥和证书对从 etcd 爬取的指标进行身份验证。创建 NetworkPolicy 以允许从命名空间访问 kube-state-metrics。
第三方解决方案
Google 与多个第三方日志记录和监控解决方案提供商合作,帮助他们的产品与 Google Distributed Cloud 很好地搭配使用。 这些提供方包括 Datadog、Elastic 和 Splunk。将来我们会添加经过验证的其他第三方。
以下解决方案指南适用于将第三方解决方案与 Google Distributed Cloud 搭配使用:
适用于 Google Distributed Cloud 的 Logging 和 Monitoring 的工作原理
创建新管理员集群或用户集群时,系统会在每个集群中安装并激活 Cloud Logging 和 Cloud Monitoring。
Stackdriver 代理在每个集群上都包含多个组件:
Stackdriver Operator (
stackdriver-operator-*):管理部署到集群上的所有其他 Stackdriver 代理的生命周期。Stackdriver Custom Resource:在 Google Distributed Cloud 安装过程中自动创建的资源。
GKE Metrics Agent (
gke-metrics-agent-*)。一个基于 OpenTelemetry 收集器的 DaemonSet,用于将每个节点的指标爬取到 Cloud Monitoring。 此外,还包括node-exporterDaemonSet 和kube-state-metrics部署,以提供有关集群的更多指标。Stackdriver Log Forwarder (
stackdriver-log-forwarder-*)。一个 Fluent Bit DaemonSet,用于将日志从每台机器转发到 Cloud Logging。日志转发器将日志条目在本地缓冲,并在最长 4 小时内将重新发送这些日志条目。如果缓冲区已满,或者日志转发器达到 Cloud Logging API 时间超过 4 小时时,日志会被丢弃。Metadata Agent (
stackdriver-metadata-agent-)。一个部署,用于将 Pod、Deployment 或节点等 Kubernetes 资源的元数据发送到 Config Monitoring for Ops API。通过添加元数据,您可以按 Deployment 名称、节点名称甚至 Kubernetes 服务名称查询指标数据。
您可以通过运行以下命令查看 Stackdriver 安装的代理:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
此命令的输出类似如下所示:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Cloud Monitoring 指标
如需查看 Cloud Monitoring 收集的指标列表,请参阅查看 Google Distributed Cloud 指标。
为 Google Distributed Cloud 配置 Stackdriver 代理
与 Google Distributed Cloud 一起安装的 Stackdriver 代理会收集有关系统组件的数据,以便维护集群并排查集群问题。以下部分介绍了 Stackdriver 配置和操作模式。
仅限系统组件(默认模式)
安装后,Stackdriver 代理会默认配置为收集 Google 所提供系统组件的日志和指标,包括性能详情(如 CPU 和内存利用率)和类似元数据。这些组件包括管理员集群中的所有工作负载,以及用户集群的 kube-system、gke-system、gke-connect、istio-system、config-management-system 命名空间中的工作负载。
系统组件和应用
如需在默认模式的基础上启用应用日志记录和监控,请按照启用应用日志记录和监控中的步骤操作。
优化的指标(默认指标)
默认情况下,集群中运行的 kube-state-metrics 部署会收集一组优化的 kube 指标,并报告给 Google Cloud Observability(原 Stackdriver)。
收集这组优化的指标需要的资源较少,这可以提高整体性能和可伸缩性。
如需停用优化的指标(不推荐),请替换 Stackdriver 自定义资源中的默认设置。
将 Google Cloud Managed Service for Prometheus 用于所选系统组件
Google Cloud Managed Service for Prometheus 是 Cloud Monitoring 的一部分,可用作系统组件的选项。Google Cloud Managed Service for Prometheus 的优势包括:
您可以继续使用基于 Prometheus 的现有监控,而无需更改提醒和 Grafana 信息中心。
如果您同时使用 GKE 和 Google Distributed Cloud,则可以对所有集群上的指标使用相同的 Prometheus 查询语言 (PromQL)。您还可以使用 Google Cloud 控制台的 Metrics Explorer 中的 PromQL 标签页。
启用和停用 Google Cloud Managed Service for Prometheus
从 Google Distributed Cloud 1.30.0-gke.1930 版开始,Google Cloud Managed Service for Prometheus 始终处于启用状态。在早期版本中,您可以修改 Stackdriver 资源 stackdriver,以启用或停用 Google Cloud Managed Service for Prometheus。如需针对 1.30.0-gke.1930 之前的集群版本停用 Google Cloud Managed Service for Prometheus,请将 stackdriver 资源中的 spec.featureGates.enableGMPForSystemMetrics 设置为 false。
查看指标数据
将 enableGMPForSystemMetrics 设置为 true 时,以下组件的指标因在 Cloud Monitoring 中的存储和查询方式而具有不同的格式:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet 和 cadvisor
- kube-state-metrics
- node-exporter
在新格式中,您可以使用 Prometheus 查询语言 (PromQL) 查询上述指标。
PromQL 查询示例:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
使用 Google Cloud Managed Service for Prometheus 配置 Grafana 信息中心
如需将 Grafana 与来自 Google Cloud Managed Service for Prometheus 的指标数据搭配使用,您必须先对 Grafana 数据源进行配置和身份验证。如需对数据源进行配置和身份验证,请使用数据源同步器 (datasource-syncer) 生成 OAuth2 凭据,并通过 Grafana 数据源 API 将凭据同步到 Grafana。数据源同步器会将 Cloud Monitoring API 设置为 Grafana 中数据源下的 Prometheus 服务器网址(网址值以 https://monitoring.googleapis.com 开头)。
按照使用 Grafana 进行查询中的步骤对 Grafana 数据源进行身份验证和配置,以查询来自 Google Cloud Managed Service for Prometheus 的数据。
GitHub 上的 anthos-samples 代码库中提供了一组示例 Grafana 信息中心。如需安装示例信息中心,请执行以下操作:
下载示例 JSON 文件:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
如果您创建的 Grafana 数据源的名称与
Managed Service for Prometheus不同,请更改所有 JSON 文件中的datasource字段:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
将 [DATASOURCE_NAME] 替换为 Grafana 中指向 Prometheus
frontend服务的数据源名称。通过浏览器访问 Grafana 界面,然后在信息中心菜单下选择 + 导入。
上传 JSON 文件,或复制并粘贴文件内容,然后选择加载。文件内容成功加载后,选择导入。您还可以根据需要在导入之前更改信息中心名称和 UID。
如果 Google Distributed Cloud 和数据源配置正确,则导入的信息中心应该会成功加载。例如,以下屏幕截图显示了
cluster-capacity.json配置的信息中心。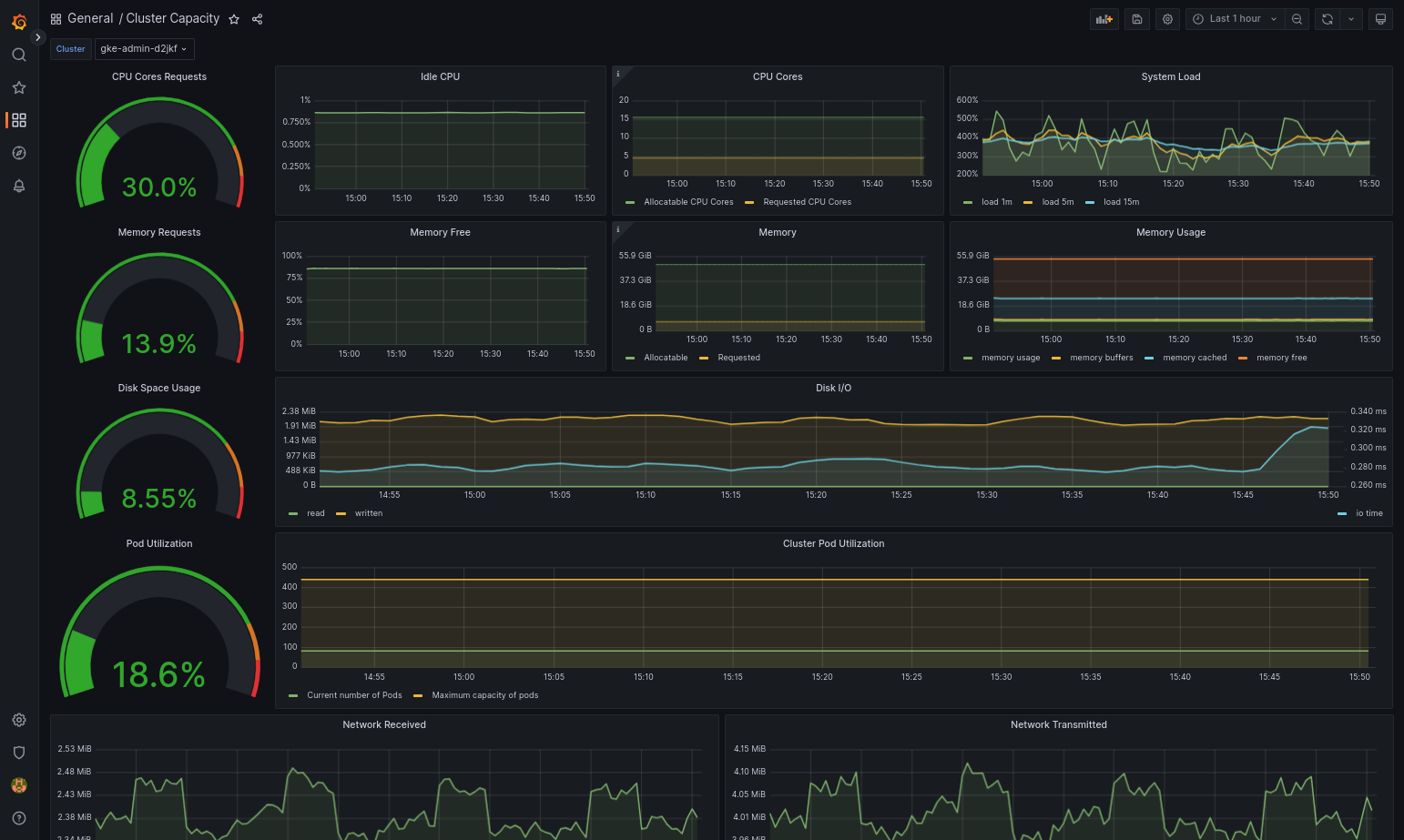
其他资源
如需详细了解 Google Cloud Managed Service for Prometheus,请参阅以下内容:
配置 Stackdriver 组件资源
创建集群时,Google Distributed Cloud 会自动创建 Stackdriver 自定义资源。您可以在自定义资源中修改规范,以替换 Stackdriver 组件的 CPU 和内存请求及限制的默认值,也可以单独替换优化的指标默认设置。
替换 Stackdriver 组件的默认 CPU 及内存请求和限制
pod 密度较高的集群引入了较高的日志记录和监控开销。在极端情况下,Stackdriver 组件可能会报告接近 CPU 和内存利用率限制,资源限制甚至可能导致持续重启。在这种情况下,如需替换 Stackdriver 组件的 CPU 和内存请求以及限制的默认值,请按以下步骤操作:
运行以下命令,在命令行编辑器中打开您的 Stackdriver 自定义资源:
kubectl -n kube-system edit stackdriver stackdriver
在 Stackdriver 自定义资源中的
spec字段下添加resourceAttrOverride部分:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITY请注意,
resourceAttrOverride部分将替换指定组件的所有现有默认限制和请求。resourceAttrOverride支持以下组件:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
示例文件如下所示:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5Gi如需保存对 Stackdriver 自定义资源的更改,请保存并退出命令行编辑器。
检查 Pod 的运行状况:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
健康的 Pod 的响应如下所示:
gke-metrics-agent-4th8r 1/1 Running 1 40h
检查组件的 Pod 规范,确保资源设置正确。
kubectl -n kube-system describe pod POD_NAME
将
POD_NAME替换为您刚刚更改的 Pod 的名称。例如gke-metrics-agent-4th8r。回答如下所示:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
停用优化的指标
默认情况下,集群中运行的 kube-state-metrics 部署会收集一组优化的 kube 指标并报告给 Stackdriver。如果您需要其他指标,我们建议您从 Google Distributed Cloud 指标列表中寻找替代指标。
以下是一些您可能使用的替代指标示例:
| 已停用的指标 | 替代指标 |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
如需停用优化指标默认设置(不推荐),请执行以下操作:
在命令行编辑器中打开 Stackdriver 自定义资源:
kubectl -n kube-system edit stackdriver stackdriver
将
optimizedMetrics字段设置为false:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
保存更改并退出命令行编辑器。
指标服务器
Metrics Server 是各种自动扩缩流水线的容器资源指标的来源。Metrics Server 会从 kubelet 检索指标,并通过 Kubernetes Metrics API 公开这些指标。然后,HPA 和 VPA 将使用这些指标来确定何时触发自动扩缩。Metrics Server 使用插件调整器进行扩缩。
在高 Pod 密度导致过多日志记录和监控开销的极端情况下,资源限制可能导致 Metrics Server 停止并重新启动。在这种情况下,您可以通过修改 gke-managed-metrics-server 命名空间中的 metrics-server-config configmap 并更改 cpuPerNode 和 memoryPerNode 的值,为指标服务器分配更多资源。
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
ConfigMap 的示例内容如下:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
更新 ConfigMap 后,使用以下命令重新创建指标服务器 Pod:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
日志和指标路由
Stackdriver 日志转发器 (stackdriver-log-forwarder) 会将每个节点机器的日志发送到 Cloud Logging。同样,GKE 指标代理 (gke-metrics-agent) 会将每个节点机器的指标发送到 Cloud Monitoring。在发送日志和指标之前,Stackdriver Operator (stackdriver-operator) 会将 stackdriver 自定义资源的 clusterLocation 字段中的值附加到每个日志条目和指标,然后再将它们路由到 Google Cloud。此外,日志和指标与 stackdriver 自定义资源规范 (spec.projectID) 中指定的 Google Cloud 项目关联。
stackdriver 资源会在集群创建时从集群资源的 clusterOperations 部分的 location 和 projectID 字段获取 clusterLocation 和 projectID 字段的值。
Stackdriver 代理发送的所有指标和日志条目都会路由到全局注入端点。从此处,数据会转发到可访问的最近区域级 Google Cloud 端点,以确保数据传输的可靠性。
全球端点收到指标或日志条目后,接下来发生的情况取决于服务:
日志路由配置方式:当日志记录端点收到日志消息时,Cloud Logging 会通过日志路由器传递消息。日志路由器配置中的接收器和过滤器决定了如何路由消息。您可以将日志条目路由到目标位置(例如用于存储日志条目的区域级 Logging 存储桶),也可以路由到 Pub/Sub。如需详细了解日志路由的工作原理以及如何进行配置,请参阅路由和存储概览。
此路由流程中不考虑
stackdriver自定义资源中的clusterLocation字段或集群规范中的clusterOperations.location字段。对于日志,clusterLocation仅用于为日志条目添加标签,这对于在 Logs Explorer 中进行过滤很有帮助。指标路由的配置方式:当指标端点收到指标条目时,系统会自动将该条目路由到指标指定的位置进行存储。指标中的位置来自
stackdriver自定义资源中的clusterLocation字段。规划配置:配置 Cloud Logging 和 Cloud Monitoring 时,请配置日志路由器,并使用最能满足您需求的位置来指定
clusterOperations.location。例如,如果您希望日志和指标发送到同一位置,请将clusterOperations.location设置为日志路由器为您的 Google Cloud 项目使用的同一 Google Cloud 区域。根据需要更新日志配置:您可以根据业务需求(例如灾难恢复计划)随时更改日志的目标位置设置。对Google Cloud 中的日志路由器配置所做的更改会立即生效。Cluster 资源的
clusterOperations部分中的location和projectID字段是不可变的,因此在您创建集群后,这些字段将无法更新。我们不建议您直接更改stackdriver资源中的值。每当集群操作(例如升级)触发协调时,此资源都会还原到原始集群创建状态。
Logging 和 Monitoring 的配置要求
为 Google Distributed Cloud 启用 Cloud Logging 和 Cloud Monitoring 需要满足几项配置要求。这些步骤包含在“启用 Google 服务”页面上的配置服务账号以与 Logging 和 Monitoring 搭配使用中,具体如下列出:
- Cloud Monitoring 工作区必须在Google Cloud 项目中创建。要实现此目的,请在Google Cloud 控制台中点击监控并按照工作流操作。
您需要启用以下 Stackdriver API:
您需要将以下 IAM 角色分配给 Stackdriver 代理使用的服务账号:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
日志标记
许多 Google Distributed Cloud 日志都包含 F 标记:
logtag: "F"
此标记表示日志条目是完整的。如需详细了解此标记,请参阅 GitHub 上的 Kubernetes 设计方案中的日志格式。
价格
在 Google Distributed Cloud 集群中,系统日志和指标包括以下方面:
- 管理员集群中所有组件的日志和指标。
- 用户集群的以下命名空间中组件的日志和指标:
kube-system、gke-system、gke-connect、knative-serving、istio-system、monitoring-system、config-management-system、gatekeeper-system、cnrm-system。
如需了解详情,请参阅 Google Cloud Observability 的价格。
如需了解 Cloud Logging 指标的赠送金额,请与销售人员联系了解价格。