本页面介绍如何为 Google Distributed Cloud 配置集群,以便将用户应用中的自定义日志和指标发送到 Cloud Logging 和 Cloud Monitoring 以及 Google Cloud Managed Service for Prometheus。
为了获得最佳的用户应用日志记录和监控体验,我们强烈建议您使用以下配置:
通过在
Stackdriver对象中将enableGMPForApplications设置为true,启用 Google Cloud Managed Service for Prometheus。此配置使您可以使用 Prometheus 全局监控工作负载并发出提醒。如需查看相关说明和其他信息,请参阅本页面上的启用 Google Cloud Managed Service for Prometheus。通过在
Stackdriver对象中将enableCloudLoggingForApplications设置为true,为用户应用启用 Cloud Logging。此配置为您的工作负载提供日志记录。如需了解相关说明和其他信息,请参阅本页面上的为用户应用启用 Cloud Logging。
启用 Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus 的配置在名为 stackdriver 的 Stackdriver 对象中指定。如需了解详情(包括最佳实践和问题排查),请参阅 Google Cloud Managed Service for Prometheus 文档。
如需配置 stackdriver 对象以启用 Google Cloud Managed Service for Prometheus,请执行以下操作:
打开 Stackdriver 对象进行修改:
kubectl --kubeconfig=CLUSTER_KUBECONFIG \ --namespace kube-system edit stackdriver stackdriver将
CLUSTER_KUBECONFIG替换为集群 kubeconfig 文件的路径。在
spec下,将enableGMPForApplications设置为true:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableGMPForApplications: true enableVPC: ... optimizedMetrics: true保存并关闭修改后的文件。
Google 管理的 Prometheus 组件会自动在
gmp-system命名空间的集群中启动。检查 Google 管理的 Prometheus 组件:
kubectl --kubeconfig=CLUSTER_KUBECONFIG --namespace gmp-system get pods此命令的输出类似以下内容:
NAME READY STATUS RESTARTS AGE collector-abcde 2/2 Running 1 (5d18h ago) 5d18h collector-fghij 2/2 Running 1 (5d18h ago) 5d18h collector-klmno 2/2 Running 1 (5d18h ago) 5d18h gmp-operator-68d49656fc-abcde 1/1 Running 0 5d18h rule-evaluator-7c686485fc-fghij 2/2 Running 1 (5d18h ago) 5d18h
Google Cloud Managed Service for Prometheus 支持规则评估和提醒。如需设置规则评估,请参阅规则评估。
运行一个示例应用
托管式服务会为在其 metrics 端口上发出 Prometheus 指标的示例应用 prom-example 提供清单。该应用使用三个副本。
如需部署应用,请执行以下操作:
为您在示例应用中创建的资源创建
gmp-test命名空间:kubectl --kubeconfig=CLUSTER_KUBECONFIG create ns gmp-test使用以下命令实施应用清单:
kubectl -n gmp-test apply \ -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.4.1/examples/example-app.yaml
配置 PodMonitoring 资源
在本部分中,您将配置 PodMonitoring 自定义资源以捕获示例应用发出的指标数据,并将其发送到 Google Cloud Managed Service for Prometheus。PodMonitoring 自定义资源使用目标爬取。在这种情况下,收集器代理会爬取示例应用将数据发出到的 /metrics 端点。
PodMonitoring 自定义资源仅会爬取在其中进行部署的命名空间中的目标。如需爬取多个命名空间中的目标,请在每个命名空间中部署相同的 PodMonitoring 自定义资源。您可以通过运行以下命令来验证 PodMonitoring 资源是否已安装在预期的命名空间中:
kubectl --kubeconfig CLUSTER_KUBECONFIG get podmonitoring -A
如需查看所有 Google Cloud Managed Service for Prometheus 自定义资源的参考文档,请参阅 prometheus-engine/doc/api 参考文档。
以下清单在 gmp-test 命名空间中定义了 PodMonitoring 资源 prom-example。该资源会查找命名空间中值为 prom-example 的 app 标签的所有 Pod。在 /metrics HTTP 路径上,每 30 秒在名为 metrics 的端口上抓取匹配的 Pod。
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app: prom-example
endpoints:
- port: metrics
interval: 30s
要应用此资源,请运行以下命令:
kubectl --kubeconfig CLUSTER_KUBECONFIG -n gmp-test apply \
-f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.4.1/examples/pod-monitoring.yaml
Google Cloud Managed Service for Prometheus 现在正在爬取匹配的 Pod。
查询指标数据
如需验证是否导出了 Prometheus 数据,最简单的方法是在 Google Cloud 控制台的 Metrics Explorer 中使用 PromQL 查询。
如需运行 PromQL 查询,请执行以下操作:
在 Google Cloud 控制台中,前往 Monitoring 页面或点击以下按钮:
在导航窗格中,选择
 Metrics Explorer。
Metrics Explorer。使用 Prometheus 查询语言 (PromQL) 指定要在图表上显示的数据:
在选择指标窗格的工具栏中,选择代码编辑器。
在PromQL切换菜单中选择 PromQL。 语言切换开关位于代码编辑器窗格的底部。
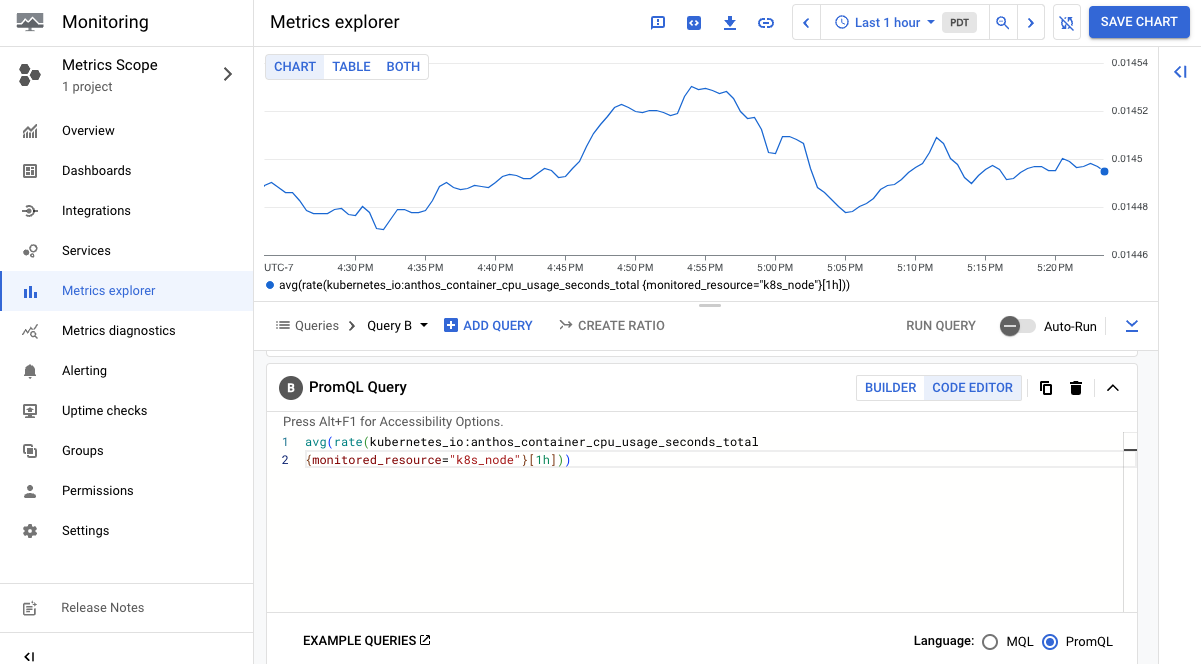
在查询编辑器中输入查询。例如,如需绘制过去一小时内 CPU 在每个模式下所花费的平均秒数,请使用以下查询:
avg(rate(kubernetes_io:anthos_container_cpu_usage_seconds_total {monitored_resource="k8s_node"}[1h]))
如需详细了解如何使用 PromQL,请参阅 Cloud Monitoring 中的 PromQL。
以下屏幕截图中的图表显示了 anthos_container_cpu_usage_seconds_total 指标:
如果您收集了大量数据,则建议您过滤导出的指标以降低费用。
为用户应用启用 Cloud Logging
Cloud Logging 和 Cloud Monitoring 的配置保存在名为 stackdriver 的 Stackdriver 对象中。
打开 Stackdriver 对象进行修改:
kubectl --kubeconfig=CLUSTER_KUBECONFIG \ --namespace kube-system edit stackdriver stackdriver将
CLUSTER_KUBECONFIG替换为用户集群 kubeconfig 文件的路径。在
spec部分中,将enableCloudLoggingForApplications设置为true:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableCloudLoggingForApplications: true enableVPC: ... optimizedMetrics: true保存并关闭修改后的文件。
运行一个示例应用
在本部分中,您将创建一个写入自定义日志的应用。
将以下 Deployment 清单保存到名为
my-app.yaml的文件中:apiVersion: apps/v1 kind: Deployment metadata: name: "monitoring-example" namespace: "default" labels: app: "monitoring-example" spec: replicas: 1 selector: matchLabels: app: "monitoring-example" template: metadata: labels: app: "monitoring-example" spec: containers: - image: gcr.io/google-samples/prometheus-dummy-exporter:latest name: prometheus-example-exporter imagePullPolicy: Always command: - /bin/sh - -c - ./prometheus-dummy-exporter --metric-name=example_monitoring_up --metric-value=1 --port=9090 resources: requests: cpu: 100m创建 Deployment
kubectl --kubeconfig CLUSTER_KUBECONFIG apply -f my-app.yaml
查看应用日志
控制台
在 Google Cloud 控制台中前往 Logs Explorer。
点击资源。在所有资源类型菜单中,选择 Kubernetes 容器。
在 CLUSTER_NAME 下,选择用户集群的名称。
在 NAMESPACE_NAME 下,选择默认。
点击添加,然后点击运行查询。
在查询结果下,您可以查看来自
monitoring-exampleDeployment 的日志条目。例如:{ "textPayload": "2020/11/14 01:24:24 Starting to listen on :9090\n", "insertId": "1oa4vhg3qfxidt", "resource": { "type": "k8s_container", "labels": { "pod_name": "monitoring-example-7685d96496-xqfsf", "cluster_name": ..., "namespace_name": "default", "project_id": ..., "location": "us-west1", "container_name": "prometheus-example-exporter" } }, "timestamp": "2020-11-14T01:24:24.358600252Z", "labels": { "k8s-pod/pod-template-hash": "7685d96496", "k8s-pod/app": "monitoring-example" }, "logName": "projects/.../logs/stdout", "receiveTimestamp": "2020-11-14T01:24:39.562864735Z" }
gcloud CLI
运行此命令:
gcloud logging read 'resource.labels.project_id="PROJECT_ID" AND \ resource.type="k8s_container" AND resource.labels.namespace_name="default"'将
PROJECT_ID替换为您的项目 ID。在输出中,您可以看到来自
monitoring-exampleDeployment 的日志条目。例如:insertId: 1oa4vhg3qfxidt labels: k8s-pod/app: monitoring-example k8s- pod/pod-template-hash: 7685d96496 logName: projects/.../logs/stdout receiveTimestamp: '2020-11-14T01:24:39.562864735Z' resource: labels: cluster_name: ... container_name: prometheus-example-exporter location: us-west1 namespace_name: default pod_name: monitoring-example-7685d96496-xqfsf project_id: ... type: k8s_container textPayload: | 2020/11/14 01:24:24 Starting to listen on :9090 timestamp: '2020-11-14T01:24:24.358600252Z'
过滤应用日志
应用日志过滤功能可以减少应用日志记录费用以及从集群到 Cloud Logging 的网络流量。从 Google Distributed Cloud 1.15.0 版开始,当 enableCloudLoggingForApplications 设置为 true 时,您可以按以下条件过滤应用日志:
- Pod 标签 (
podLabelSelectors) - 命名空间 (
namespaces) - 日志内容的正则表达式 (
contentRegexes)
Google Distributed Cloud 仅将过滤结果发送到 Cloud Logging。
定义应用日志过滤条件
Logging 的配置在名为 stackdriver 的 Stackdriver 对象中指定。
打开要修改的
stackdriver对象:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG --namespace kube-system \ edit stackdriver stackdriver将 USER_CLUSTER_KUBECONFIG 替换为用户集群 kubeconfig 文件的路径。
将
appLogFilter部分添加到spec:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: enableCloudLoggingForApplications: true projectID: ... clusterName: ... clusterLocation: ... appLogFilter: keepLogRules: - namespaces: - prod ruleName: include-prod-logs dropLogRules: - podLabelSelectors: - disableGCPLogging=yes ruleName: drop-logs保存并关闭修改后的文件。
(可选)如果您使用的是
podLabelSelectors,请重启stackdriver-log-forwarderDaemonSet 以尽快使您的更改生效:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG --namespace kube-system \ rollout restart daemonset stackdriver-log-forwarder通常,
podLabelSelectors会在 10 分钟后生效。重启 DaemonSetstackdriver-log-forwarder可以使更改更快生效。
示例:仅包含 prod 命名空间中的 ERROR 或 WARN 日志
以下示例展示了应用日志过滤条件的工作原理。您可以定义使用命名空间 (prod)、正则表达式 (.*(ERROR|WARN).*) 和 Pod 标签 (disableGCPLogging=yes) 的过滤条件。然后,为了验证过滤条件有效,您可以在 prod 命名空间中运行 Pod 来测试这些过滤条件。
如需定义和测试应用日志过滤条件,请执行以下操作:
在 Stackdriver 对象中指定应用日志过滤条件:
以下
appLogFilter示例中,仅保留prod命名空间中的ERROR或WARN日志。具有disableGCPLogging=yes标签的 Pod 的所有日志都将被丢弃:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: ... appLogFilter: keepLogRules: - namespaces: - prod contentRegexes: - ".*(ERROR|WARN).*" ruleName: include-prod-logs dropLogRules: - podLabelSelectors: - disableGCPLogging=yes # kubectl label pods pod disableGCPLogging=yes ruleName: drop-logs ...在
prod命名空间中部署 Pod,并运行生成ERROR和INFO日志条目的脚本:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG run pod1 \ --image gcr.io/cloud-marketplace-containers/google/debian10:latest \ --namespace prod --restart Never --command -- \ /bin/sh -c "while true; do echo 'ERROR is 404\\nINFO is not 404' && sleep 1; done"过滤后的日志应仅包含
ERROR条目,不包含INFO条目。向 Pod 添加标签
disableGCPLogging=yes:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG label pods pod1 \ --namespace prod disableGCPLogging=yes过滤后的日志应不再包含
pod1Pod 的任何条目。
应用日志过滤条件 API 定义
应用日志过滤条件的定义在 Stackdriver 自定义资源定义中声明。
如需获取 Stackdriver 自定义资源定义,请运行以下命令:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG get crd stackdrivers.addons.gke.io \
--namespace kube-system -o yaml