このトピックでは、Anthos clusters on AWS のユーザー クラスタから Cloud Logging と Cloud Monitoring にログと指標をエクスポートする方法について説明します。
概要
Anthos clusters on AWS でのロギングとモニタリングには、複数の方法があります。Anthos は、Cloud Logging および Cloud Monitoring と統合できます。Anthos はオープンソース Kubernetes をベースにしているため、多くのオープンソース ツール、サードパーティ ツールとの互換性があります。
ロギングとモニタリングの方法
Anthos クラスタのロギングとモニタリングには、いくつかのオプションがあります。
Cloud Logging エージェントと Cloud Monitoring エージェントをデプロイして、Google Cloud Console でワークロードのログをモニタリング、表示する。このトピックでは、このソリューションについて説明します。
Prometheus、Grafana、Elasticsearch などのオープンソース ツールを使用する。このトピックでは、このソリューションについては説明しません。
Datadog などのサードパーティ ソリューションを使用する。このトピックでは、このソリューションについては説明しません。
Cloud Logging と Cloud Monitoring
Anthos、Cloud Logging、Cloud Monitoring を使用すると、クラスタで実行中のワークロードのダッシュボードの作成、アラートの送信、モニタリング、ログの確認ができます。Google Cloud プロジェクトにログと指標を収集するには、Cloud Logging エージェントと Cloud Monitoring エージェントを構成する必要があります。これらのエージェントを構成しなければ、AWS 上の Anthos クラスタはロギングデータやモニタリング データを収集しません。
収集されるデータの種類
構成すると、エージェントはクラスタとクラスタで実行されているワークロードからログと指標データを収集します。これらのデータは Google Cloud プロジェクトに保存されます。そのプロジェクト ID は、Log Forwarder をインストールするときに、構成ファイルの project_id フィールドに構成します。
収集されるデータには次の対象が含まれます。
- 各ワーカーノードのシステム サービス用のログ。
- クラスタで実行されている全ワークロードのアプリケーション ログ。
- クラスタとシステム サービスの指標。特定の指標の詳細については、Anthos の指標をご覧ください。
- アプリケーションが Prometheus 取得ターゲットで構成され、
prometheus.io/scrape、prometheus.io/path、prometheus.io/portなどの構成のアノテーションが付けられている場合は、ポッド用のアプリケーション指標。
エージェントは任意の時点で無効にできます。詳しくは、クリーンアップをご覧ください。エージェントによって収集されたデータは、Cloud Monitoring と Cloud Logging のドキュメントの手順に沿って、その他の指標やログデータと同様に管理、削除できます。
ログデータは、構成されている保持ルールに従って保存されます。指標データの保持は、指標タイプによって異なります。
コンポーネントのロギングとモニタリング
Anthos clusters on AWS から Google Cloud にクラスタレベルのテレメトリーをエクスポートするには、次のコンポーネントをクラスタにデプロイします。
- Stackdriver Log Forwarder(stackdriver-log-forwarder-*)。各 Kubernetes ノードから Cloud Logging にログを転送する Fluentbit の DaemonSet です。
- GKE Metrics Agent(gke-metrics-agent-*)。指標データを収集し Cloud Monitoring に転送する OpenTelemetry Collector ベースの DaemonSet です。
これらのコンポーネントのマニフェストは、GitHub の anthos-samples リポジトリにあります。
前提事項
課金を有効にした Google Cloud プロジェクト。費用の詳細については、Google Cloud のオペレーション スイート料金をご覧ください。
プロジェクトで Cloud Logging API と Cloud Monitoring API を有効にすることも必要です。これらの API を有効にするには、次のコマンドを実行します。
gcloud services enable logging.googleapis.com gcloud services enable monitoring.googleapis.comAnthos clusters on AWS 環境(Connect に登録されたユーザー クラスタを含む)。クラスタが登録済みであることは、次のコマンドを実行して確認します。
gcloud container fleet memberships listクラスタが登録されている場合は、Google Cloud CLI により、クラスタの名前と ID が出力されます。
NAME EXTERNAL_ID cluster-0 1abcdef-1234-4266-90ab-123456abcdefクラスタの一覧が表示されない場合は、Connect を使用したクラスタへの接続をご覧ください。
マシンに
gitコマンドライン ツールをインストールします。
Google Cloud のオペレーション スイートの権限を設定する
Logging および Monitoring エージェントは、フリートの Workload Identity を使用して Cloud Logging および Cloud Monitoring と通信します。この ID には、プロジェクト内のログと指標を書き込む権限が必要です。権限を追加するには、次のコマンドを実行します。
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:PROJECT_ID.svc.id.goog[kube-system/stackdriver]" \
--role=roles/logging.logWriter
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:PROJECT_ID.svc.id.goog[kube-system/stackdriver]" \
--role=roles/monitoring.metricWriter
PROJECT_ID は、Google Cloud プロジェクトに置き換えます。
踏み台インスタンスに接続する
Anthos clusters on AWS リソースに接続するには、次の手順を行います。既存の AWS VPC(または VPC への直接接続)があるか、管理サービスの作成時に専用の VPC を作成したかに基づいて、以下の手順を行います。
既存の VPC
既存の VPC への直接接続または VPN 接続がある場合は、このトピックのコマンドから env HTTP_PROXY=http://localhost:8118 行を省略します。
専用の VPC
専用の VPC で管理サービスを作成すると、Anthos clusters on AWS にパブリック サブネットの踏み台インスタンスが含まれています。
管理サービスに接続するには、次の手順を行います。
Anthos clusters on AWS 構成のディレクトリに移動します。このディレクトリは、管理サービスをインストールしたときに作成したものです。
cd anthos-aws
トンネルを開くには、
bastion-tunnel.shスクリプトを実行します。トンネルはlocalhost:8118に転送されます。踏み台インスタンスへのトンネルを開くには、次のコマンドを実行します。
./bastion-tunnel.sh -NSSH トンネルからのメッセージがこのウィンドウに表示されます。接続を閉じる準備ができたら、Ctrl+C を使用するか、ウィンドウを閉じて処理を停止します。
新しいターミナルを開き、
anthos-awsディレクトリに移動します。cd anthos-aws
kubectlを使用してクラスタに接続できることを確認します。env HTTPS_PROXY=http://localhost:8118 \ kubectl cluster-info出力には、Management Service API サーバーの URL が含まれます。
コントロール プレーン ノード上の Cloud Logging と Cloud Monitoring
Anthos clusters on AWS 1.8.0 以降では、新しいユーザー クラスタを作成するときに、コントロール プレーン ノード用の Cloud Logging と Cloud Monitoring が自動的に構成されます。Cloud Logging や Cloud Monitoring を有効にするには、AWSCluster 構成の controlPlane.cloudOperations セクションに情報を入力します。
cloudOperations:
projectID: PROJECT_ID
location: GC_REGION
enableLogging: ENABLE_LOGGING
enableMonitoring: ENABLE_MONITORING
以下を置き換えます。
PROJECT_ID: プロジェクト ID。GC_REGION: ログを保存する Google Cloud リージョン。AWS リージョンに近接したリージョンを選択します。詳細については、グローバル ロケーション - リージョンとゾーン(例:us-central1)をご覧ください。ENABLE_LOGGING:trueまたはfalse。コントロール プレーン ノードで Cloud Logging が有効かどうか。ENABLE_MONITORING:trueまたはfalse。コントロール プレーン ノードで Cloud Monitoring が有効かどうか。
次に、カスタム ユーザー クラスタの作成の手順に沿って操作します。
ワーカーノード上の Cloud Logging と Cloud Monitoring
前のバージョンを削除する
stackdriver-log-aggregator(Fluentd)や stackdriver-prometheus-k8s(Prometheus)など、前のバージョンの Logging エージェントと Monitoring エージェントが設定されている場合は、先に進む前にアンインストールすることをおすすめします。
ロギング フォワーダーのインストール
このセクションでは、クラスタに Stackdriver Log Forwarder をインストールします。
anthos-samples/aws-logging-monitoring/ディレクトリから、logging/ディレクトリに移動します。cd logging/プロジェクトの構成に合わせてファイル
forwarder.yamlを変更します。sed -i "s/PROJECT_ID/PROJECT_ID/g" forwarder.yaml sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" forwarder.yaml sed -i "s/CLUSTER_LOCATION/GC_REGION/g" forwarder.yaml以下を置き換えます。
PROJECT_ID: プロジェクト ID。CLUSTER_NAME: クラスタの名前(例:cluster-0)。GC_REGION: ログを保存する Google Cloud リージョン。AWS リージョンに近接したリージョンを選択します。詳細については、グローバル ロケーション - リージョンとゾーン(例:us-central1)をご覧ください。
(省略可)ワークロード、クラスタ内のノードの数、ノードあたりの Pod 数に応じて、メモリと CPU のリソース リクエストを設定する必要があります。詳細については、推奨される CPU とメモリ割り当てをご覧ください。
anthos-awsディレクトリからanthos-gkeを使用して、コンテキストをユーザー クラスタに切り替える。cd anthos-aws env HTTPS_PROXY=http://localhost:8118 \ anthos-gke aws clusters get-credentials CLUSTER_NAME
CLUSTER_NAME は、ユーザー クラスタ名に置き換えます。stackdriverサービス アカウントが存在しない場合は作成し、クラスタに Log Forwarder をデプロイします。env HTTPS_PROXY=http://localhost:8118 \ kubectl create serviceaccount stackdriver -n kube-system env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f forwarder.yamlkubectlを使用して、Pod が起動されたことを確認します。env HTTPS_PROXY=http://localhost:8118 \ kubectl get pods -n kube-system | grep stackdriver-logノードプールでは、ノードごとに 1 つのフォワーダー Pod が表示されます。たとえば、6 ノードのクラスタでは、6 つのフォワーダー Pod が表示されます。
stackdriver-log-forwarder-2vlxb 2/2 Running 0 21s stackdriver-log-forwarder-dwgb7 2/2 Running 0 21s stackdriver-log-forwarder-rfrdk 2/2 Running 0 21s stackdriver-log-forwarder-sqz7b 2/2 Running 0 21s stackdriver-log-forwarder-w4dhn 2/2 Running 0 21s stackdriver-log-forwarder-wrfg4 2/2 Running 0 21s
ログ転送のテスト
このセクションでは、負荷生成ツールを使用した基本的な HTTP ウェブサーバーを含むワークロードをクラスタにデプロイします。次に、Cloud Logging にログが存在することをテストします。
ウェブサーバーと負荷ジェネレータのマニフェストは、このワークロードをインストールする前に確認できます。
ウェブサーバーと負荷ジェネレータをクラスタにデプロイします。
env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/server/server.yaml env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/loadgen/loadgen.yamlCloud Logging ダッシュボードでクラスタのログを表示できることを確認するには、Google Cloud Console の [ログ エクスプローラ] に移動します。
次のサンプルクエリを [クエリビルダー] フィールドにコピーします。
resource.type="k8s_container" resource.labels.cluster_name="CLUSTER_NAME"CLUSTER_NAME はクラスタ名で置き換えます。
[クエリを実行] をクリックします。最近のクラスタログが [クエリ結果] に表示されます。
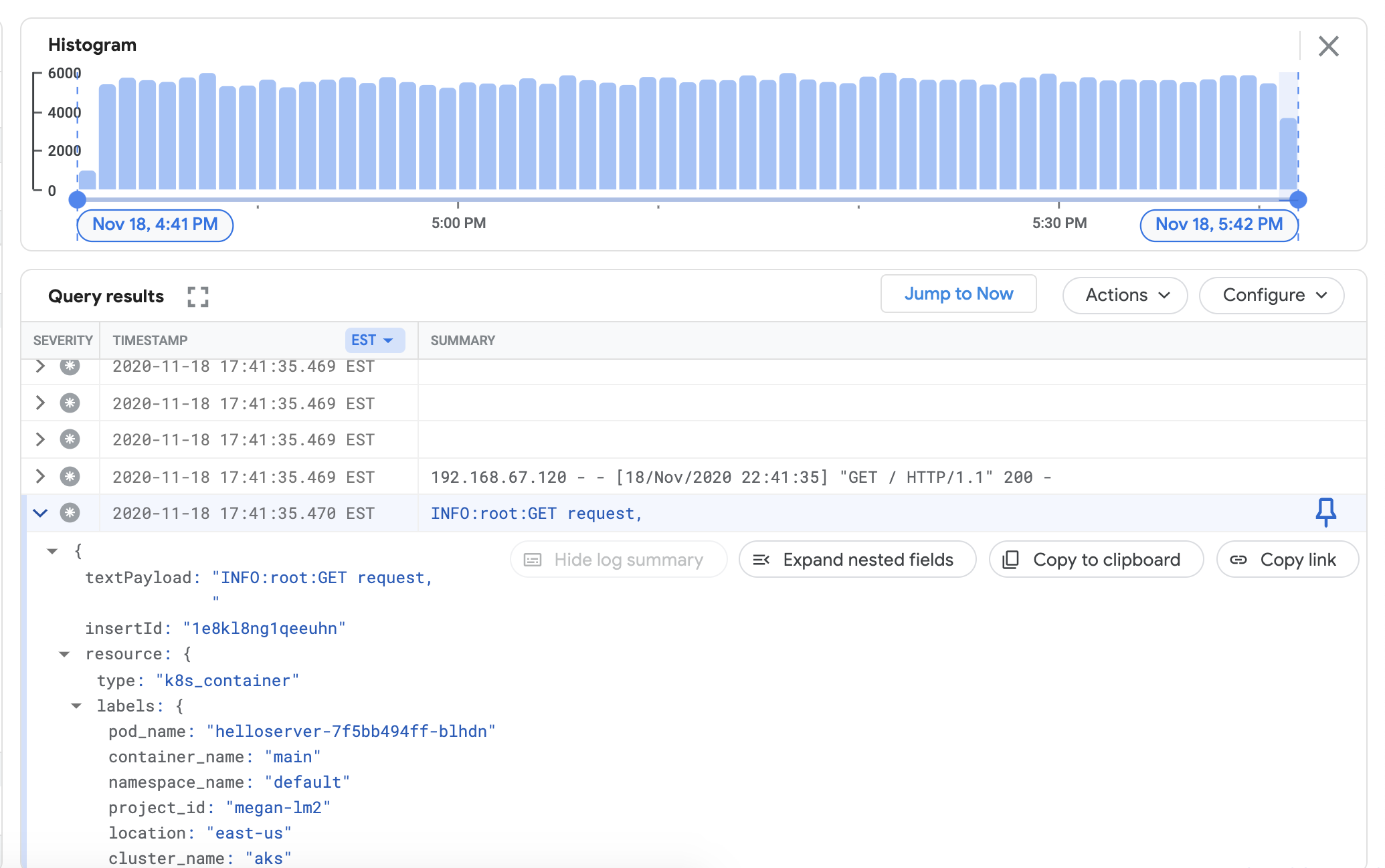
ログがクエリ結果に表示されることを確認したら、負荷生成ツールとウェブサーバーを削除します。
env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/loadgen/loadgen.yaml env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/istio-samples/master/sample-apps/helloserver/server/server.yaml
Metrics Collector のインストール
このセクションでは、Cloud Monitoring にデータを送信するエージェントをインストールします。
anthos-samples/aws-logging-monitoring/logging/ディレクトリから、anthos-samples/aws-logging-monitoring/monitoring/ディレクトリに移動します。cd ../monitoringプロジェクトの構成に合わせてファイル
gke-metrics-agent.yamlを変更します。sed -i "s/PROJECT_ID/PROJECT_ID/g" gke-metrics-agent.yaml sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" gke-metrics-agent.yaml sed -i "s/CLUSTER_LOCATION/GC_REGION/g" gke-metrics-agent.yaml以下を置き換えます。
PROJECT_ID: プロジェクト ID。CLUSTER_NAME: クラスタの名前(例:cluster-0)。GC_REGION: ログを保存する Google Cloud リージョン。AWS リージョンに近接したリージョンを選択します。詳細については、グローバル ロケーション - リージョンとゾーン(例:us-central1)をご覧ください。
(省略可)ワークロード、クラスタ内のノードの数、ノードあたりの Pod 数に応じて、メモリと CPU のリソース リクエストを設定する必要があります。詳細については、推奨される CPU とメモリ割り当てをご覧ください。
stackdriverサービス アカウントが存在しない場合は作成し、クラスタに指標エージェントをデプロイします。env HTTPS_PROXY=http://localhost:8118 \ kubectl create serviceaccount stackdriver -n kube-system env HTTPS_PROXY=http://localhost:8118 \ kubectl apply -f gke-metrics-agent.yamlkubectlツールを使用して、gke-metrics-agentPod が動作していることを確認します。env HTTPS_PROXY=http://localhost:8118 \ kubectl get pods -n kube-system | grep gke-metrics-agentノードプールでは、ノードごとに 1 つのエージェント Pod が表示されます。たとえば、3 ノードクラスタでは、3 つのエージェント Pod が表示されます。
gke-metrics-agent-gjxdj 2/2 Running 0 102s gke-metrics-agent-lrnzl 2/2 Running 0 102s gke-metrics-agent-s6p47 2/2 Running 0 102s
クラスタの指標が Cloud Monitoring にエクスポートされていることを確認するには、Google Cloud Console の Metrics Explorer に移動します。
Metrics Explorer で、[Query Editor] をクリックし、次のコマンドをコピーします。
fetch k8s_container | metric 'kubernetes.io/anthos/otelcol_exporter_sent_metric_points' | filter resource.project_id == 'PROJECT_ID' && (resource.cluster_name =='CLUSTER_NAME') | align rate(1m) | every 1m以下を置き換えます。
PROJECT_ID: プロジェクト ID。CLUSTER_NAME: ユーザー クラスタの作成で使用したクラスタ名(例:cluster-0)。
[クエリを実行] をクリックします。クラスタ内の各
gke-metrics-agentPod から Cloud Monitoring に送信される指標ポイントのレートが表示されます。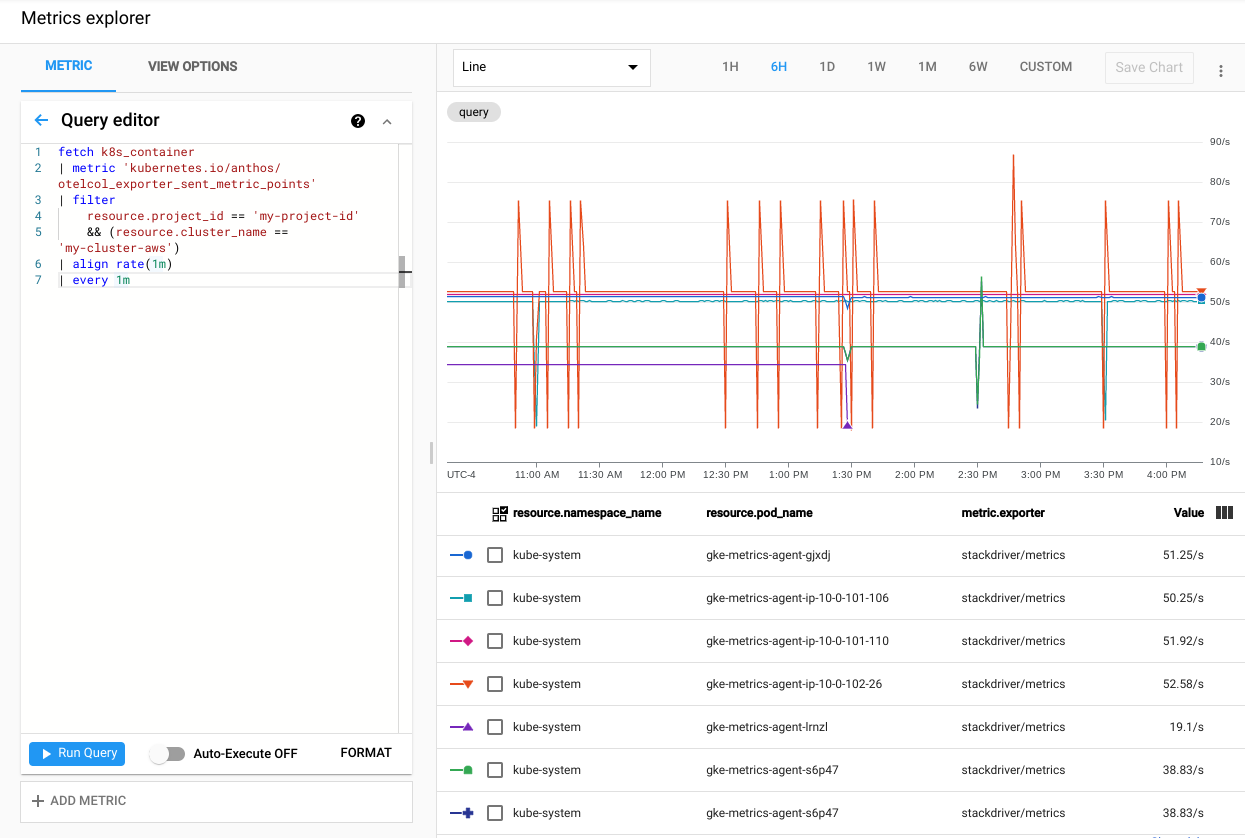
他にも試してみるのにふさわしい指標を以下に掲載しますが、これらはあくまでも例です。
kubernetes.io/anthos/container_memory_working_set_bytes: コンテナのメモリ使用量kubernetes.io/anthos/container_cpu_usage_seconds_total: コンテナの CPU 使用率kubernetes.io/anthos/apiserver_aggregated_request_total: kube-apiserver のリクエスト数。コントロール プレーンで Cloud Monitoring が有効になっている場合にのみ使用できます。
利用可能な指標の一覧については、Anthos の指標をご覧ください。ユーザー インターフェースの使用方法については、Metrics Explorer をご覧ください。
Cloud Monitoring のダッシュボードを作成する
このセクションでは、クラスタ内のコンテナのステータスをモニタリングする Cloud Monitoring ダッシュボードを作成します。
anthos-samples/aws-logging-monitoring/monitoring/ディレクトリから、anthos-samples/aws-logging-monitoring/monitoring/dashboardsディレクトリに移動します。cd dashboardspod-status.jsonのCLUSTER_NAME文字列のインスタンスは、クラスタ名に置き換えます。sed -i "s/CLUSTER_NAME/CLUSTER_NAME/g" pod-status.jsonCLUSTER_NAMEはクラスタ名で置き換えます。次のコマンドを実行して、構成ファイルを含むカスタム ダッシュボードを作成します。
gcloud monitoring dashboards create --config-from-file=pod-status.jsonダッシュボードが作成されたことを確認するには、Google Cloud Console で Cloud Monitoring ダッシュボードに移動します。
CLUSTER_NAME (Anthos cluster on AWS) pod status形式の名前を持つ新しく作成したダッシュボードを開きます。
クリーンアップ
このセクションでは、クラスタからロギング コンポーネントとモニタリング コンポーネントを削除します。
Google Cloud Console のダッシュボード一覧ビューで、ダッシュボード名に関連付けられている削除ボタンをクリックしてモニタリング ダッシュボードを削除します。
anthos-samples/aws-logging-monitoring/ディレクトリに移動します。cd anthos-samples/aws-logging-monitoringこのガイドで作成したすべてのリソースを削除するには、次のコマンドを実行します。
env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f logging/ env HTTPS_PROXY=http://localhost:8118 \ kubectl delete -f monitoring/
推奨する CPU とメモリの割り当て
このセクションでは、ロギングとモニタリングに使用される個別のコンポーネントに推奨の CPU と割り当てについて説明します。次の各表は、ノードサイズの範囲があるクラスタの CPU リクエストとメモリ リクエストの一覧です。表内に示されたファイルでコンポーネントのリソース リクエストを設定します。
詳細については、Kubernetes のベスト プラクティス: リソースのリクエストと制限およびコンテナのリソースの管理をご覧ください。
1~10 ノード
| ファイル | リソース | CPU リクエスト | CPU 制限 | メモリ リクエスト | メモリ制限 |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 30m | 100m | 50Mi | 500Mi |
logging/forwarder.yaml |
stackdriver-log-forwarder | 50m | 100m | 100Mi | 600Mi |
10~100 ノード
| ファイル | リソース | CPU リクエスト | CPU 制限 | メモリ リクエスト | メモリ制限 |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 50m | 100m | 50Mi | 500Mi |
logging/forwarder.yaml |
stackdriver-log-forwarder | 60m | 100m | 100Mi | 600Mi |
100 ノード超
| ファイル | リソース | CPU リクエスト | CPU 制限 | メモリ リクエスト | メモリ制限 |
|---|---|---|---|---|---|
monitoring/gke-metrics-agent.yaml |
gke-metrics-agent | 50m | 100m | 100Mi | 該当なし |
logging/forwarder.yaml |
stackdriver-log-forwarder | 60m | 100m | 100Mi | 600Mi |