本页面介绍了如何使用 Query Insights 信息中心检测和分析性能问题。如需大致了解此功能,请参阅 Query Insights 概览。
您可以使用 Gemini Cloud Assist 来帮助您监控 AlloyDB 资源并对其进行问题排查。如需了解详情,请参阅使用 Gemini 协助进行监控和问题排查。
准备工作
如果您或其他用户需要查看查询计划或执行端到端跟踪,则需要具备特定的 Identity and Access Management (IAM) 权限。您可以创建一个自定义角色,并为其添加必要的 IAM 权限。然后,您可以将此角色添加到使用 Query Insights 排查问题的每个用户账号。请参阅创建自定义角色
自定义角色需要具有以下 IAM 权限:cloudtrace.traces.get。
打开 Query Insights 信息中心
如需打开 Query Insights 信息中心,请执行以下步骤:
- 在集群和实例列表中,点击一个实例。
- 点击集群“概览”页面上指标图表下方的前往 Query Insights,详细了解查询和性能,或选择左侧导航面板中的 Query Insights 标签页。
在后续页面上,您可以使用以下选项过滤结果:
- 实例选择器。可让您选择集群中的主实例或读取池实例。默认情况下,系统会选择主实例。 显示的详细信息是针对所有连接的读取池实例及其节点进行汇总的。
- 数据库。过滤特定数据库或所有数据库上的查询负载。
- 用户。过滤来自特定用户账号的查询负载。
- 客户端地址。过滤来自特定 IP 地址的查询查询。
- 时间范围。按时间范围(如小时、天、周或自定义范围)过滤查询。
修改 Query Insights 配置
默认情况下,AlloyDB 实例会启用 Query Insights。您可以修改默认的 Query Insights 配置。
如需修改 AlloyDB 实例的 Query Insights 配置,请按照以下步骤操作:
控制台
在 Google Cloud 控制台中,前往集群页面。
在资源名称列中点击相应集群。
在左侧导航面板中点击 Query Insights。
从 Query Insights 列表中选择主实例或读取池,然后点击修改。
修改 Query Insights 字段:
如需更改 AlloyDB 要分析的查询长度的默认限制(1024 字节),请在查询长度字段中输入一个介于 256 到 4,500 之间的数字。
修改此字段后,实例会重启。
注意:查询长度限制越高,需要的内存就越多。
如需自定义 Query Insights 特征集,请调整以下选项:
查询计划采样:选中此复选框可直观呈现用于完成查询样本的操作。采样率决定了 AlloyDB 每个节点每分钟可以为实例采样的查询数上限。
在采样率上限字段中,输入一个介于 1 到 20 之间的数字。默认情况下采样率设置为 5。如需停用采样,请清除查询计划采样复选框。
存储客户端 IP 地址:选中此复选框可了解查询的来源,并对相关信息进行分组以运行指标。
存储应用标记:选中此复选框可了解哪些已标记的应用正在发出请求,并对这些信息进行分组以运行指标。 如需详细了解应用标记,请参阅规范。
点击更新实例。
gcloud
如需使用 Google Cloud CLI 命令为 AlloyDB 实例启用 Query Insights,请执行以下操作:
- 安装 Google Cloud CLI。
- 如需初始化 gcloud CLI,请运行以下命令:
gcloud init
如果您使用的是本地 shell,请为您的用户账号创建本地身份验证凭证:
gcloud auth application-default login
如果您使用的是 Cloud Shell,则无需执行此操作。
如需了解详情,请参阅为本地开发环境设置身份验证。
示例如下:
gcloud alloydb instances update INSTANCE \
--cluster=CLUSTER \
--project=PROJECT \
--region=REGION \
--insights-config-query-string-length=QUERY_LENGTH \
--insights-config-query-plans-per-minute=QUERY_PLANS \
--insights-config-record-application-tags \
--insights-config-record-client-address替换以下内容:
INSTANCE:要更新的实例的 IDCLUSTER:实例集群的 IDPROJECT:集群的项目的 IDREGION:集群所在的区域,例如us-central1QUERY_LENGTH:查询的长度,范围为 256 到 4,500QUERY_PLANS:每分钟要配置的查询计划数。
此外,请使用以下一个或多个可选标志:
--insights-config-query-string-length:将默认查询长度限制设置为 256 到 4,500 字节范围内的指定值。默认查询长度为 1024 字节。 更长的查询长度对于分析查询更有用,但也需要更多内存。更改查询长度需要重启实例。 您仍然可以为超出长度上限的查询添加标记。--insights-config-query-plans-per-minute:默认情况下,实例上的所有数据库每分钟最多捕获 5 个已执行的查询计划样本。 将此值更改为 1 到 20 之间的数字。如需停用采样,请输入 0。 提高采样率或许能为您带来更多数据点,但可能会增加性能开销。--insights-config-record-client-address:存储查询的来源客户端 IP 地址,并帮助您对相关数据进行分组,以便针对其运行指标。查询来自多个主机。查看来自客户端 IP 地址的查询的图表有助于识别问题的来源。如果您不想存储客户端 IP 地址,请使用--no-insights-config-record-client-address。--insights-config-record-application-tags:存储应用标记,以帮助您确定正在发出请求的 API 和模型视图控制器 (MVC) 路由,并对数据进行分组以对其运行指标。此选项要求您使用一组特定标记对查询进行注释。如果您不想存储应用标记,请使用--no-insights-config-record-application-tags。
Terraform
如需使用 Terraform 配置 Query Insights,请使用 google_alloydb_instance 资源。
示例如下:
query_insights_config {
query_string_length = QUERY_STRING_LENGTH_VALUE
record_application_tags = RECORD_APPLICATION_TAG_VALUE
record_client_address = RECORD_CLIENT_ADDRESS_VALUE
query_plans_per_minute = QUERY_PLANS_PER_MINUTE_VALUE5
}
替换以下内容:
QUERY_STRING_LENGTH_VALUE:查询字符串长度。默认值为1024。介于 256 到 4,500 之间的任何整数均有效。RECORD_APPLICATION_TAG_VALUE:记录实例的应用标记。默认值为true。RECORD_CLIENT_ADDRESS_VALUE:记录实例的客户端地址。默认值为true。QUERY_PLANS_PER_MINUTE_VALUE:Insights 每分钟捕获的查询执行计划数量(针对所有查询)。默认值为5。介于 0 到 20 之间的任何整数均有效。如需了解如何应用或移除 Terraform 配置,请参阅基本 Terraform 命令。
添加了 Query Insights 配置的示例实例配置应如下所示:
resource "google_alloydb_instance" "instance_name" { provider = "google-beta" cluster = google_alloydb_cluster.default.name instance_id = "instance_id" instance_type = "PRIMARY" machine_config { cpu_count = 8 } query_insights_config { query_string_length = 1024 record_application_tags = false record_client_address = false query_plans_per_minute = 5 } depends_on = [google_alloydb_instance.default] }
REST v1
此示例用于配置 AlloyDB 实例上的可观测性设置。如需查看此调用的完整参数列表,请参阅方法:projects.locations.clusters.instances.patch。
如需配置 Query Insights 设置,请根据需要修改可选字段。如需查看此调用的完整字段列表,请参阅 QueryInsightsInstanceConfig。
在使用任何请求数据之前,请先进行以下替换:
CLUSTER_ID:您创建的集群的 ID。它必须以小写字母开头,可以包含小写字母、数字和连字符。PROJECT_ID:您要将集群放置在其中的项目的 ID。LOCATION_ID:集群区域的 ID。INSTANCE_ID:您要创建的主实例的名称。
如需修改实例配置,请使用以下 PATCH 请求:
PATCH https://alloydb.googleapis.com/v1beta/{instance.name=projects/PROJECT_ID/locations/LOCATION_ID/clusters/CLUSTER_ID/instances/INSTANCE_ID?updateMask=observabilityConfig.enabled}
用于配置所有可观测性字段的请求 JSON 正文如下所示:
{
"queryStringLength": integer,
"recordApplicationTags": boolean,
"recordClientAddress": boolean,
"queryPlansPerMinute": integer
}
提高查询性能
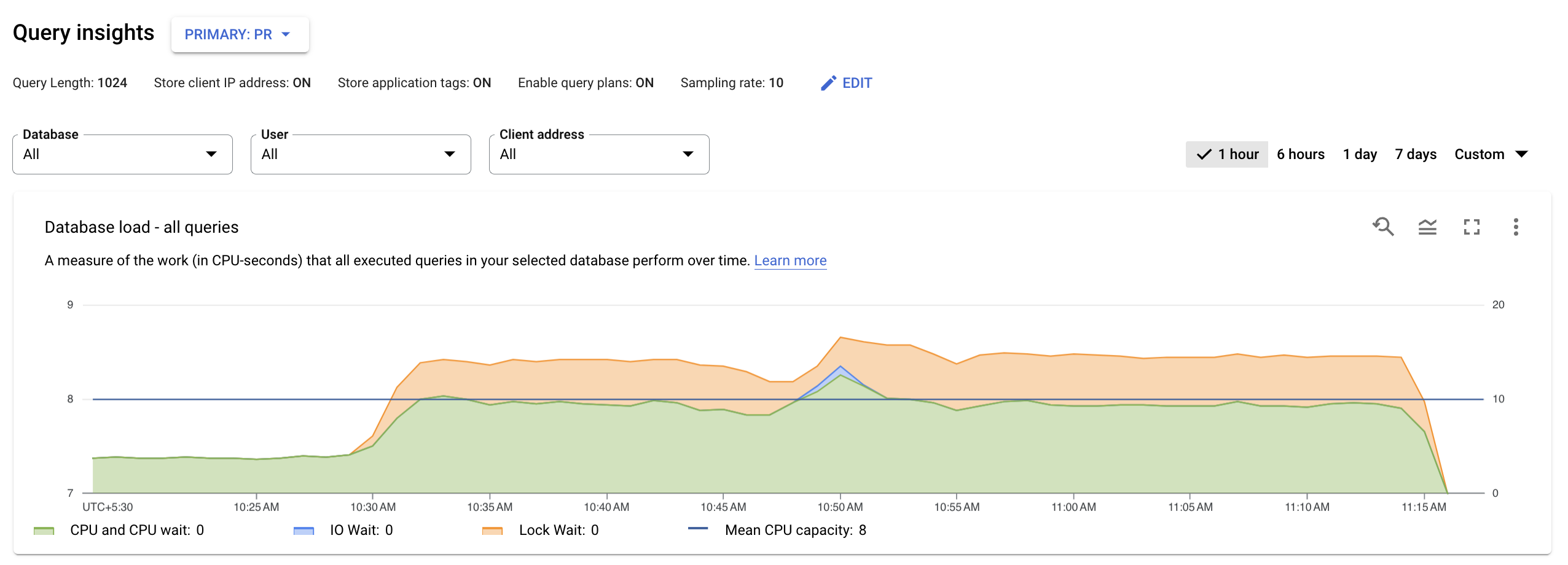
Query Insights 排查 AlloyDB 查询以查找性能问题。Query Insights 信息中心会基于您选择的因素显示查询负载。查询负载是衡量选定时间范围内实例中所有查询的总工作量。
Query Insights 可帮助您检测和分析查询性能问题。如需使用 Query Insights 排查查询问题,请按照以下步骤操作:
查看所有查询的数据库负载
顶级 Query Insights 信息中心会使用过滤的数据显示数据库负载 - 所有热门查询图表。数据库查询负载用于衡量所选数据库中执行的查询在一段时间内所执行的工作(以 CPU 秒为单位)。每个正在运行的查询都使用或等待 CPU 资源、IO 资源或锁定资源。数据库查询负载是在给定时间范围内完成的所有查询所花费的时间与挂钟时间之比。
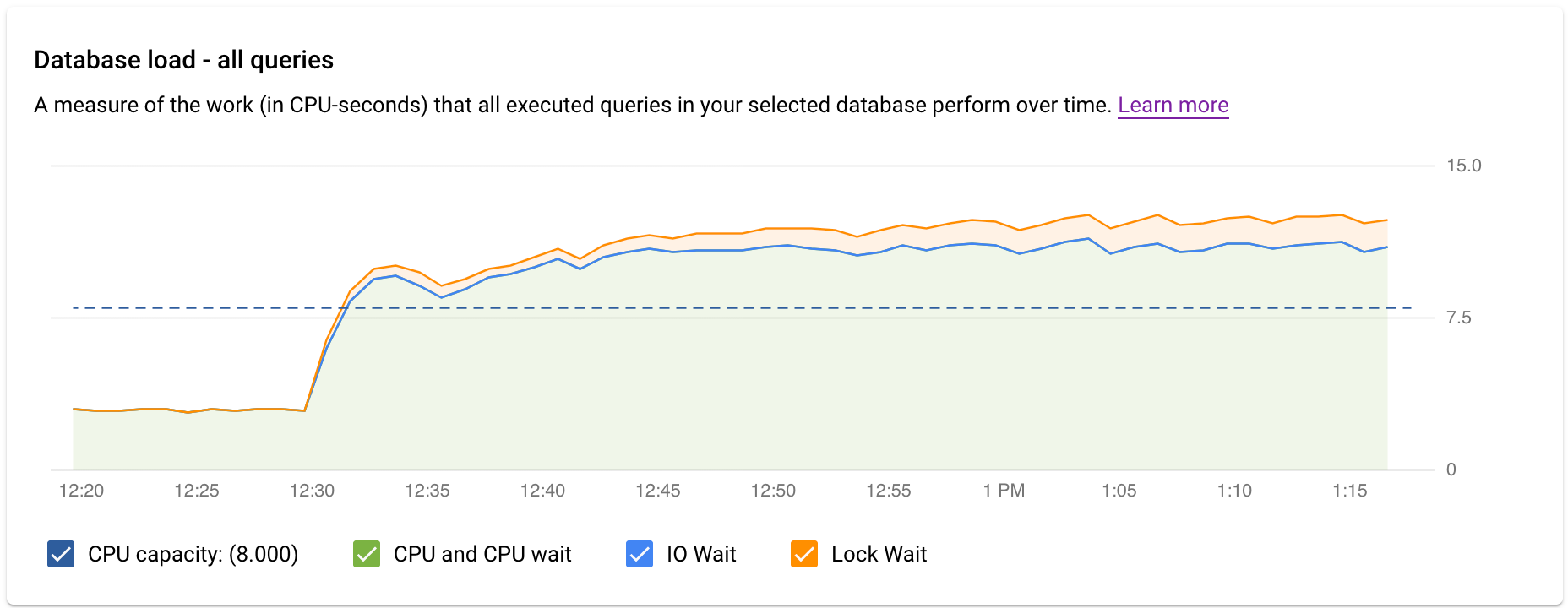
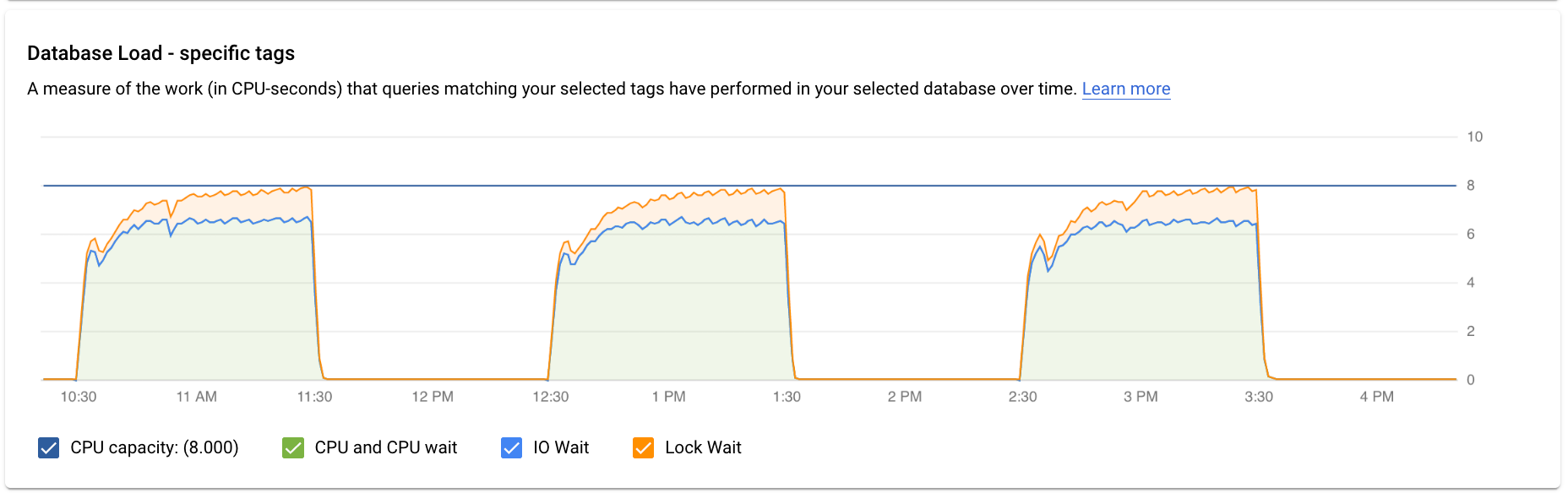
图表中的颜色线条表示查询负载,分为以下四个类别:
- CPU 容量:实例上可用的 CPU 数量。
CPU 和 CPU 等待:活跃状态下查询所花费的时间与实际用时之比。IO 和锁定等待不会阻止处于活跃状态的查询。此指标可能意味着查询正在使用 CPU,或正在等待 Linux 调度器在其他进程正在使用 CPU 时安排用于运行查询的服务器进程。
注意:CPU 负载会同时考虑运行时以及等待 Linux 调度程序调度正在运行的服务器进程的时间。因此,CPU 负载可能会超出核心线数上限。
IO 等待:等待 IO 的查询所花费的时间与实际用时之比。IO 等待包括读取 IO 等待和写入 IO 等待。请参阅 PostgreSQL 事件表。如果您需要有关 IO 等待的信息明细,可以在 Cloud Monitoring 中查看这些信息。如需了解详情,请参阅指标图表。
锁定等待:等待锁定的查询所花费的时间与实际用时之比,其中包括锁定等待、LwLock 等待和 BufferPin 锁定等待。如果您需要有关锁定等待的信息明细,可以在 Cloud Monitoring 中查看这些信息。如需了解详情,请参阅指标图表。
接下来,请查看图表并使用过滤选项来回答以下问题:
- 查询负载较高吗?图表是否随着时间推移或上升?如果未看到高负载,则问题与您的查询无关。
- 负载高的时间有多长?只是现在高吗?还是长时间位于高负载?使用范围选择来选择不同时段,以确定问题发生的时间。或者,您可以放大以查看观察到的查询负载峰值的时间范围。您可以缩小以查看一周的时间轴。
- 导致高负载的原因是什么?您可以选择查看 CPU 容量、CPU 和 CPU 等待时间、锁定等待或 IO 等待选项。这三种选项的图表是不同的颜色,便于您了解哪些选项的负载最高。图表上的深蓝色线条表示系统的最大 CPU 容量。它允许您比较查询负载与 CPU 系统容量上限。这种比较可帮助您了解实例是否耗尽 CPU 资源。
- 哪个数据库遇到了负载?从“数据库”下拉菜单中选择不同的数据库,找出负载最高的数据库。
- 特定的用户或 IP 地址是否会导致负载过高?从下拉菜单中选择不同的用户和地址,以比较哪些负载较高。
过滤数据库负载
借助查询和标记,您可以按所选查询或 SQL 查询标记过滤或排序查询负载。
按查询过滤
查询表概述了导致查询加载次数最多的查询。下表显示了 Query Insights 信息中心上所选时间范围和选项的所有标准化查询。
默认情况下,该表会按您选择的时间段内的总执行时间对查询进行排序。
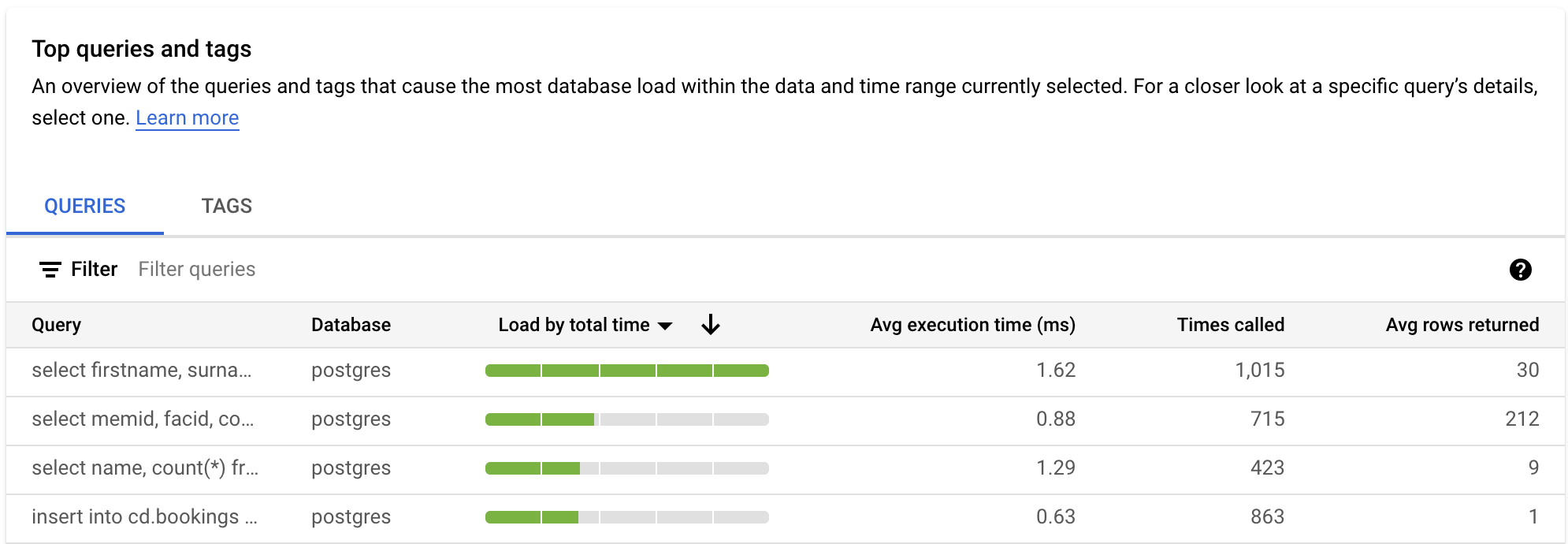
如需过滤表格,请从过滤查询中选择属性。如需对表格进行排序,请选择列标题。下表显示了以下属性:
查询字符串。标准化查询字符串。默认情况下,Query Insights 仅显示查询字符串中的 1,024 个字符。
标记为
UTILITY COMMAND的查询通常包含BEGIN、COMMIT、EXPLAIN命令或封装容器命令。数据库。针对其运行查询的数据库。
按总时间的负载/按 CPU 的负载/按 IO 等待的负载/按锁定等待的负载。借助这些选项,您可以过滤特定查询以查找每个选项的最大负载。
平均执行时间(毫秒)。所有并行工作器完成查询的所有子任务所花费的总时间。 如需了解详情,请参阅平均执行时间和时长。
调用次数。应用调用查询的次数。
平均提取行数。查询平均提取行数。
Query Insights 会显示标准化查询,即 $1、$2 等替换字面量常量值。例如:
UPDATE
"demo_customer"
SET
"customer_id" = $1::uuid,
"name" = $2,
"address" = $3,
"rating" = $4,
"balance" = $5,
"current_city" = $6,
"current_location" = $7
WHERE
"demo_customer"."id" = $8
此常量的值会被忽略,因此 Query Insights 可以汇总类似查询并移除该常量可能显示的任何个人身份信息。
按查询标记过滤
如需排查应用问题,您必须先将标记添加到 SQL 查询。
Query Insights 提供以应用为中心的监控功能,可诊断使用 ORM 构建的应用的性能问题。
如果您负责整个应用栈,则 Query Insights 可从应用视图提供查询监控。查询标记可帮助您查找更高级别的结构(例如使用业务逻辑、微服务或一些其他结构)中的问题。您可以按业务逻辑标记查询,例如使用付款、库存、业务分析或配送标记等。然后,您可以找到由各种类型的业务逻辑创建的查询负载。例如,您可能发现意外事件,例如:业务报告标记在下午 1 点出现峰值。或者,您可能发现支付服务与上周相比出现意外的上升趋势。
查询加载标记提供选定标记的查询负载随时间的变化情况。
如需计算标记的数据库负载,Query Insights 会使用所选标记使用各查询所花费的时间。Query Insights 使用实际用时计算在分钟边界处的完成时间。
在 Query Insights 信息中心内,选择 TAGS 以查看标记表。TAGS 表按总加载时间对标记进行排序。

您可以通过过滤查询中的属性或点击列标题对表进行排序。下表显示了以下属性:
- 操作、控制器、框架、路由、应用、数据库驱动程序。您添加到查询的每个属性都显示为一列。如果您想按标记过滤,必须至少添加这些属性中的一个。
- 按总时间的负载/按 CPU 的负载/按 IO 等待的负载/按锁定等待的负载。借助这些选项,您可以过滤特定查询以查找每个选项的最大负载。
- 平均执行时间(毫秒)。所有并行工作器完成查询的所有子任务所花费的总时间。 如需了解详情,请参阅平均执行时间和时长。
- 调用次数。应用调用查询的次数。
- 平均提取行数。查询平均提取行数。
- 数据库。针对其运行查询的数据库。
检查特定查询或标记
如需确定查询或标记是否为问题的根本原因,请在查询标签或标记标签中分别执行以下操作:
- 点击负载(按总时长)标头,按降序对列表进行排序。
- 点击看似负载最高并因此比其他查询或标记用时更久的查询或标记。
这将打开一个信息中心,其中显示所选查询或标记的详细信息。
如果您选择了某个查询,系统会显示所选查询的概览:

如果您选择了某个标记,系统会显示所选标记的概览。
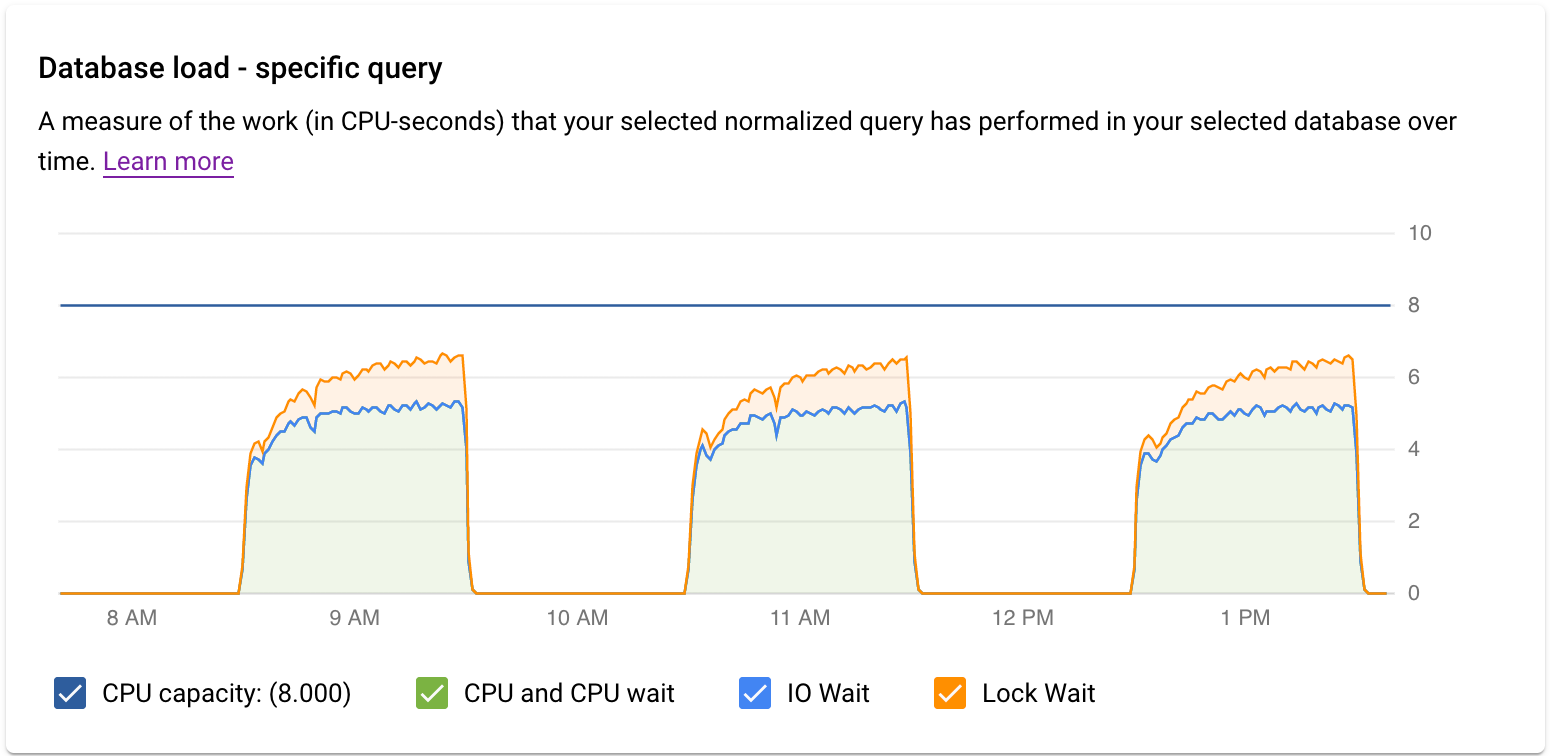
检查特定查询或标记的负载
数据库加载 - 特定查询图表显示所选规范化查询在一段时间内所执行的工作(以 CPU 秒为单位)。计算负载所用的时间是每分钟边界处的规范化查询所花费的时间与实际用时之比。 表格顶部会显示规范化查询的前 1024 个字符(出于聚合和个人身份信息考虑,先移除字面量)。 与总查询图一样,您可以按数据库、用户和客户端地址过滤特定查询的负载。查询负载分为 CPU 容量、CPU 和 CPU 等待、IO 等待和锁定等待。
数据库负载 - 特定标记图表显示一段时间内与所选标记匹配的查询在所选数据库中执行的工作(以 CPU 秒为单位)。与总查询图一样,您可以按 Database、User 和 Client Address 过滤特定标记的负载。
检查延迟时间
您可以使用延迟时间图表来检查查询或标记的延迟时间。延迟时间是完成标准化查询所需的时间(实际用时)。延迟时间信息中心会显示第 50、第 95 和第 99 百分位的延迟时间,以帮助您找出离群值行为。
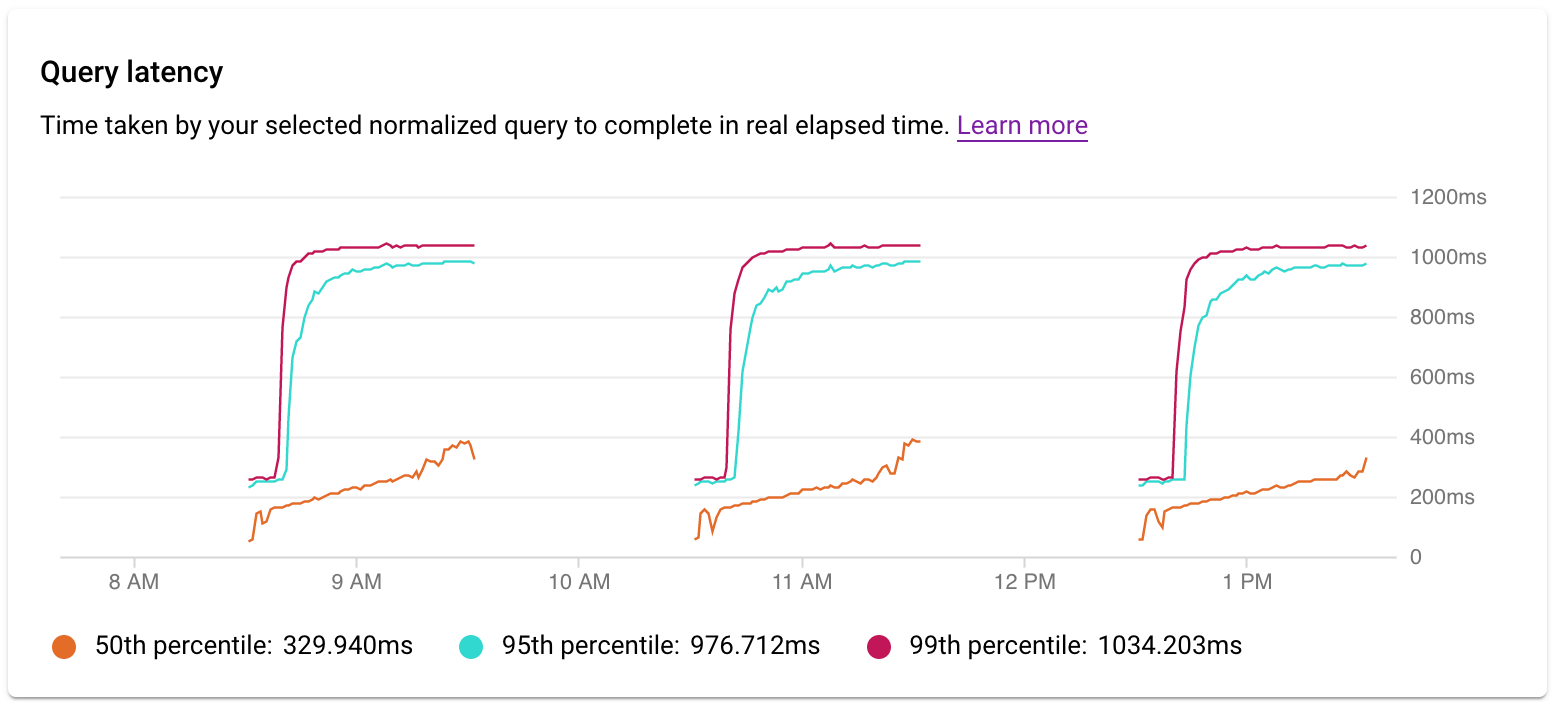
并行查询的延迟时间是按实际用时衡量的,即使查询的查询负载可能更高(由于使用了多个核心来运行查询的一部分)也是如此。
通过查看以下内容来缩小问题范围:
- 导致高负载的原因是什么?选择查看 CPU 容量、CPU 和 CPU 等待时间、锁定等待或 IO 等待选项的选项。
- 负载高的时间有多长?只是现在高吗?还是长时间位于高负载?更改时间范围以查找加载开始效果不佳的日期和时间。
- 延迟时间是否存在急剧增加? 您可以更改时间窗口来研究规范化查询的历史延迟时间。
当您找到负载最高的区域和时间时,可以进一步深入分析。
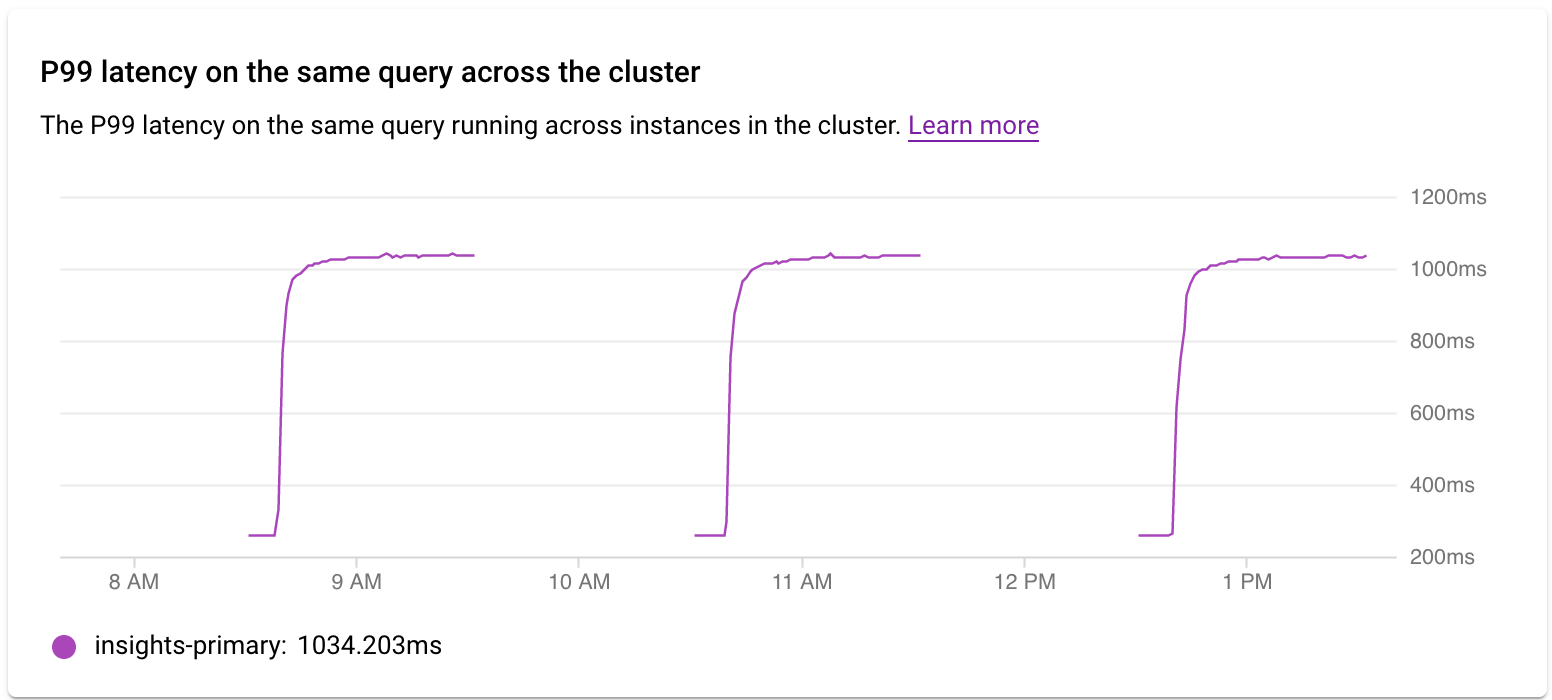
检查整个集群的延迟时间
您可以使用整个集群中同一查询的 P99 延迟时间图表,来检查集群中各实例的查询或标记的 P99 延迟时间。
检查采样查询计划中的操作
查询计划会获取查询的示例,并将其拆分为单独的操作。它解释并分析查询中的每个操作。查询计划示例图表显示了在特定时间运行的所有查询计划以及每个计划运行的时长。
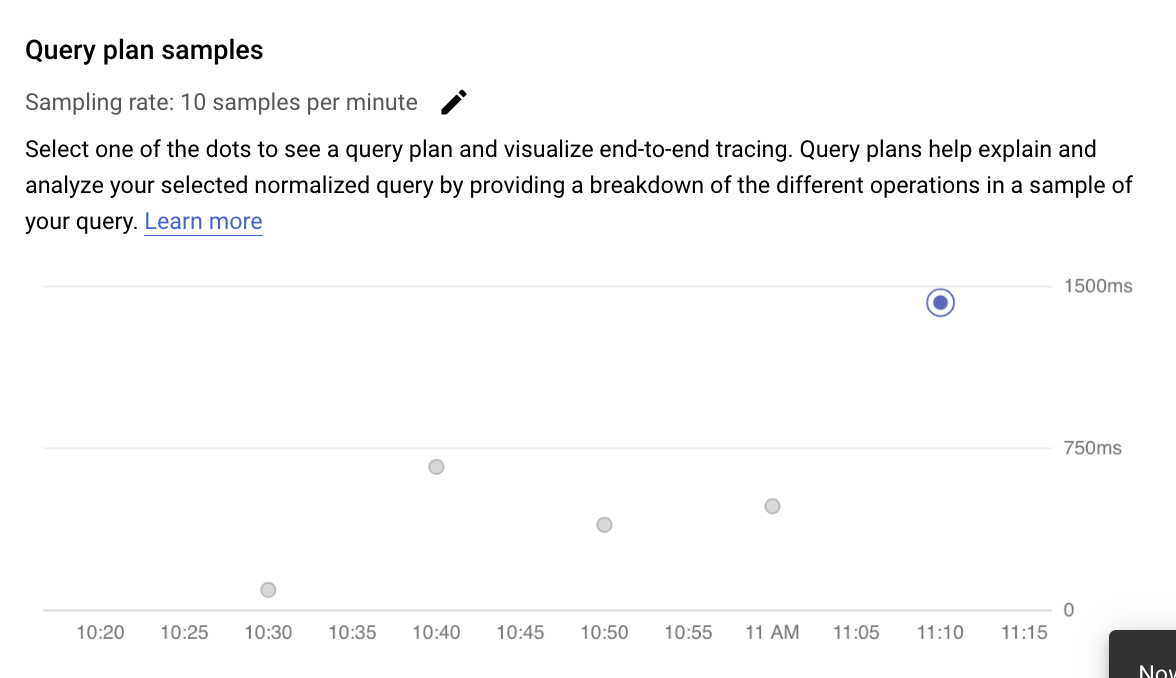
如需查看示例查询计划的详细信息,请点击示例查询计划图表中的点。大多数查询都有一个已执行的示例查询计划视图,但并非所有查询都有。展开的详细信息显示查询计划中的所有操作的模型。每项操作都会显示延迟时间、返回的行数以及该操作的费用。选择操作后,您可以查看更多详细信息,例如共享命中块、架构类型、实际循环、计划行等。
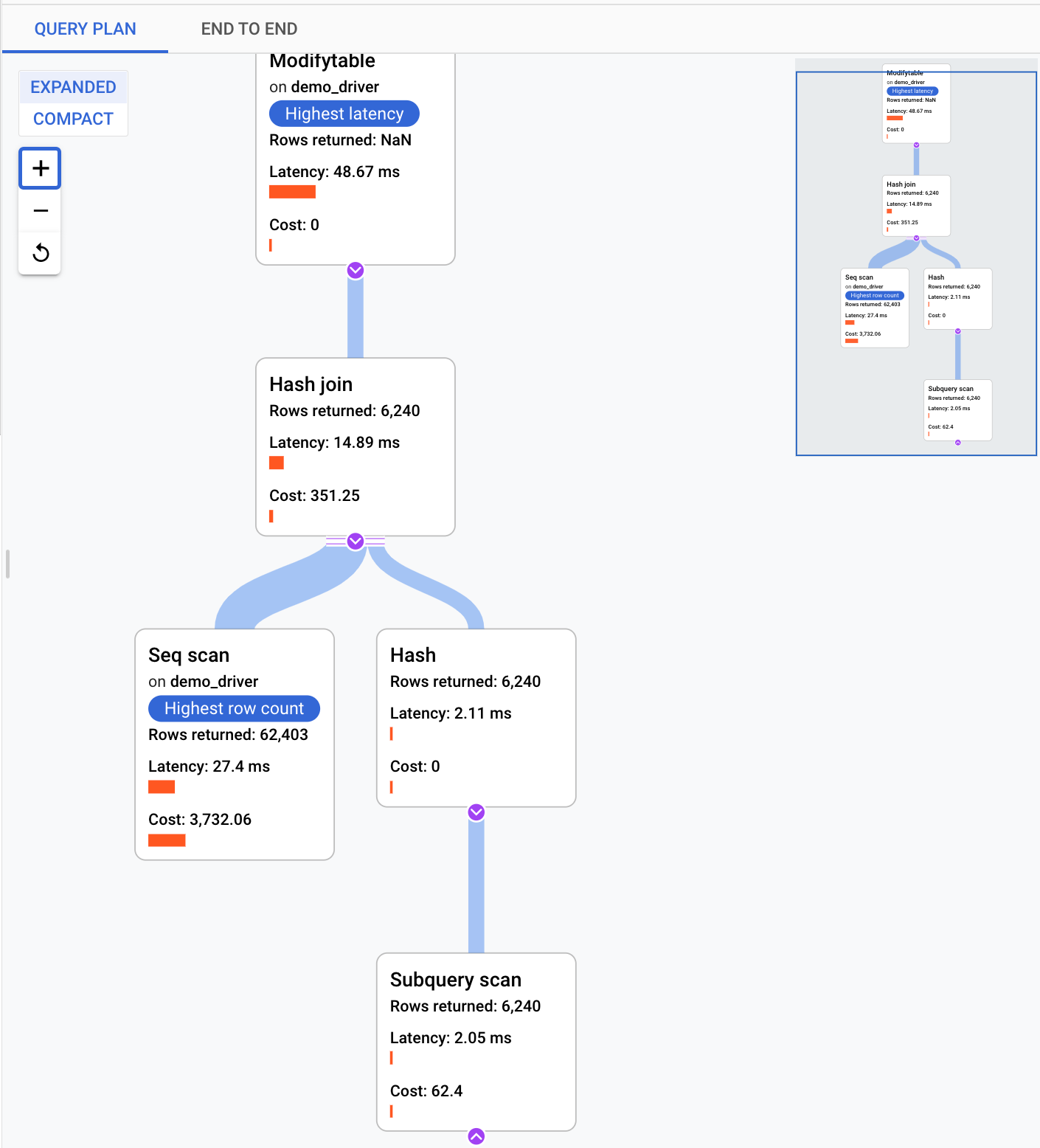
通过查看以下问题来缩小问题范围:
- 什么是资源消耗量?
- 它与其他查询有何关系?
- 消耗量是否随着时间的推移而变化?
检查由示例查询生成的跟踪记录
除了查看示例查询计划之外,您还可以使用 Query Insights 来查看示例查询的上下文中的端到端应用跟踪记录。此跟踪记录可通过显示特定请求的数据库活动,为帮助您确定有问题的查询的来源。此外,应用在请求期间发送到 Cloud Logging 的日志条目会与跟踪记录相关联,这有助于您进行调查。
如需查看上下文相关跟踪记录,请执行以下操作:
在示例查询窗格中,点击端到端跟踪记录标签页。此标签页会显示一个甘特图,其中详细列出了查询生成的跟踪记录的 span(即各个操作的记录)。
如需查看每个 span 的更多详细信息(例如属性和元数据),请点击相应 span。
您还可以在 Trace 探索器页面中查看跟踪记录。为此,请点击在 Cloud Trace 中查看。如需详细了解如何使用 Trace 探索器页面探索跟踪记录数据,请参阅查找和探索跟踪记录。
向 SQL 查询添加标记
标记 SQL 查询可简化应用问题排查。您可以使用 sqlcommenter,通过对象关系映射 (ORM) 自动将标记添加到 SQL 查询或手动添加。
将 sqlcommenter 与 ORM 搭配使用
如果使用 ORM 而不是直接编写 SQL 查询,则您可能找不到导致出现性能问题的应用代码。您可能还需要分析应用代码对查询性能的影响。如需解决这一难题,Query Insights 提供了一个名为 sqlcommenter 的开源库 ORM 插桩库。对于使用 ORM 的开发者和管理员,此库对于检测哪些应用代码引发性能问题非常有用。
如果您同时使用 ORM 和 sqlcommenter,则系统会自动创建标记,无需更改自定义代码或将自定义代码添加到应用中。
您可以在应用服务器上安装 sqlcommenter。插桩库允许将 MVC 框架的应用信息连同查询一起作为 SQL 注释一起传播到数据库。数据库会获取这些标记,并开始按标记记录和聚合统计信息,这些统计信息与规范化查询汇总的统计信息不同。Query Insights 会显示标记,以便您了解哪个应用导致查询负载。此信息可帮您找出导致性能问题的应用代码。
在 SQL 数据库日志中检查结果时,结果如下所示:
SELECT * from USERS /*action='run+this',
controller='foo%3',
traceparent='00-01',
tracestate='rojo%2'*/
支持的标记包括控制器名称、路由、框架和操作。
各种编程语言支持 sqlcommenter 中的 ORM:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
如需详细了解 sqlcommenter 以及如何在 ORM 框架中使用 sqlcommenter,请参阅 GitHub 中的 sqlcommenter 文档。
使用 sqlcommenter 手动添加标记
如果您未使用 ORM,则必须手动向 SQL 查询添加 sqlcommenter 标记。在查询中,您必须使用每个序列化键值对的注释来扩充每个 SQL 语句。请至少使用以下其中一个密钥:
action=''controller=''framework=''route=''application=''db driver=''
Query Insights 会删除所有其他键。如需了解正确的 SQL 注释格式,请参阅 sqlcommenter 文档。
执行时间和时长
Query Insights 提供平均执行时间(毫秒)指标,该指标会报告所有并行工作器完成查询的所有子任务所花费的总时间。此指标可帮助您找到并优化产生最高 CPU 开销的查询,从而优化数据库的总体资源利用率。
如需查看所用时间,您可以在 psql 客户端上运行 \timing 命令来衡量查询的时长。它用于衡量从接收查询到 PostgreSQL 服务器发送响应之间的所用时间。此指标可帮助您分析给定查询耗时过长的原因,并决定是否对其进行优化以加快运行速度。
如果查询由单个任务以单线程方式完成,则时长和平均执行时间保持不变。
启用 AlloyDB 高级 Query Insights 功能
AlloyDB 信息中心的高级 Query Insights 功能已集成在标准 Query Insights 信息中心中。 如需详细了解如何启用高级 Query Insights 功能,请参阅使用高级 Query Insights 功能提高查询性能。
后续步骤
- Query Insights 概览
- 使用 AlloyDB 高级 Query Insights 功能提升查询性能
- AlloyDB 指标
- SQL 评论者博客:介绍 Sqlcommenter:开源 ORM 自动插桩库
- 方法博客:使用 Sqlcommenter 启用查询标记