概要
このチュートリアルでは、Vertex AI で vLLM を使用して Llama 3.1 モデルと 3.2 モデルをデプロイしてサービングするプロセスについて説明します。これは、2 つの別々のノートブック、「vLLM で Llama 3.1 をサービングする」(テキストのみの Llama 3.1 モデルをデプロイする場合)と vLLM でマルチモーダル Llama 3.2 をサービングする」(テキストと画像の両方の入力を処理するマルチモーダル Llama 3.2 モデルをデプロイする)と組み合わせて使用するように設計されています。このページでは、GPU でモデル推論を効率的に処理し、さまざまなアプリケーションに合わせてモデルをカスタマイズする方法について説明します。これにより、高度な言語モデルをプロジェクトに統合するためのツールが提供されます。
このガイドを修了すると、次のことを行う方法を理解できます。
- vLLM コンテナを使用して、Hugging Face から事前構築済みの Llama モデルをダウンロードする。
- vLLM を使用して、これらのモデルを Google CloudVertex AI Model Garden 内の GPU インスタンスにデプロイする。
- モデルを効率的に提供して、大規模な推論リクエストを処理する。
- テキストのみのリクエストとテキストと画像のリクエストで推論を実行する。
- クリーンアップする。
- デプロイをデバッグする。
vLLM の主な機能
| 機能 | 説明 |
|---|---|
| PagedAttention | 推論中にメモリを効率的に管理するための最適化されたアテンション メカニズム。メモリリソースを動的に割り当てることで、高スループットのテキスト生成をサポートし、複数の同時リクエストのスケーラビリティを実現します。 |
| 連続的なバッチ処理 | 複数の入力リクエストを 1 つのバッチに統合して並列処理し、GPU の使用率とスループットを最大化します。 |
| トークンのストリーミング | テキスト生成中にトークン単位のリアルタイム出力を有効にします。チャットボットやインタラクティブな AI システムなど、低レイテンシが必要なアプリケーションに最適です。 |
| モデルの互換性 | Hugging Face Transformers などの一般的なフレームワークで、幅広い事前トレーニング済みモデルをサポートしています。さまざまな LLM を統合してテストすることが容易になります。 |
| マルチ GPU とマルチホスト | ワークロードを 1 台のマシン内の複数の GPU とクラスタ内の複数のマシンに分散することで、モデル サービングを効率化し、スループットとスケーラビリティを大幅に向上させます。 |
| 効率的なデプロイ | OpenAI の Chat completions などの API とシームレスに統合できるため、本番環境のユースケースで簡単にデプロイできます。 |
| Hugging Face モデルとのシームレスな統合 | vLLM は Hugging Face モデル アーティファクト形式と互換性があり、HF からの読み込みをサポートしているため、Gemma、Phi、Qwen などの一般的なモデルとともに、最適化された設定で Llama モデルを簡単にデプロイできます。 |
| コミュニティ主導のオープンソース プロジェクト | vLLM はオープンソースであり、コミュニティの貢献を奨励し、LLM サービングの効率を継続的に改善しています。 |
Google Vertex AI vLLM のカスタマイズ: パフォーマンスと統合を強化します
Google Vertex AI Model Garden 内の vLLM 実装は、オープンソース ライブラリを直接統合したものではありません。Vertex AI は、 Google Cloud内のパフォーマンス、信頼性、シームレスな統合を強化するように特別に調整された、カスタマイズされ最適化されたバージョンの vLLM を維持します。
- パフォーマンスの最適化:
- Cloud Storage からの並列ダウンロード: Cloud Storage からの並列データ取得を有効にしてレイテンシを短縮し、起動速度を向上させることで、モデルの読み込みとデプロイの時間を大幅に短縮します。
- 機能の強化:
- キャッシュと Cloud Storage のサポートを強化した動的 LoRA: ローカル ディスク キャッシュ メカニズムと堅牢なエラー処理により動的 LoRA 機能を拡張し、Cloud Storage パスと署名付き URL から LoRA 重みを直接読み込むことをサポートします。これにより、カスタマイズされたモデルの管理とデプロイが簡素化されます。
- Llama 3.1/3.2 関数呼び出しの解析: Llama 3.1/3.2 関数呼び出し用の特殊な解析を実装し、解析の堅牢性を向上させました。
- ホストメモリ接頭辞のキャッシュ: 外部 vLLM は、GPU メモリ接頭辞のキャッシュのみをサポートします。
- 推測デコード: これは既存の vLLM 機能ですが、Vertex AI はテストを実行して、パフォーマンスの高いモデル設定を見つけました。
これらの Vertex AI 固有のカスタマイズは、多くの場合エンドユーザーには透過的ですが、Vertex AI Model Garden での Llama 3.1 デプロイのパフォーマンスと効率を最大化できます。
- Vertex AI エコシステムとの統合:
- Vertex AI 予測の入出力形式のサポート: Vertex AI 予測の入出力形式とのシームレスな互換性を確保し、データ処理と他の Vertex AI サービスとの統合を簡素化します。
- Vertex 環境変数の認識: Vertex AI 環境変数(
AIP_*)を尊重し、構成とリソース管理に活用することで、デプロイを効率化して、Vertex AI 環境内での一貫した動作を実現します。 - エラー処理と堅牢性の強化: 包括的なエラー処理、入出力の検証、サーバー終了メカニズムを実装し、マネージド Vertex AI 環境内での安定性、信頼性、シームレスなオペレーションを実現します。
- 機能用の Nginx サーバー: vLLM サーバーの上に Nginx サーバーを統合して、複数のレプリカのデプロイを容易にし、サービング インフラストラクチャのスケーラビリティと高可用性を強化します。
vLLM のその他のメリット
- ベンチマークのパフォーマンス: vLLM は、スループットとレイテンシの点で、Hugging Face text-generation-inference や NVIDIA の FasterTransformer などの他のサービング システムと比較して競争力のあるパフォーマンスを実現します。
- 使いやすさ: このライブラリには、既存のワークフローと統合するための簡単な API が用意されているため、最小限の設定で Llama 3.1 モデルと 3.2 モデルの両方をデプロイできます。
- 高度な機能: vLLM はストリーミング出力(トークンごとにレスポンスを生成)をサポートし、可変長プロンプトを効率的に処理することで、アプリケーションのインタラクティビティと応答性を向上させます。
vLLM システムの概要については、論文をご覧ください。
サポートされているモデル
vLLM は、幅広い最先端モデルをサポートしているため、ニーズに最適なモデルを選択できます。次の表に、これらのモデルの一部を示します。ただし、テキストのみとマルチモーダルの両方の推論用のモデルなど、サポートされているモデルの包括的なリストについては、vLLM の公式ウェブサイトをご覧ください。
| カテゴリ | モデル |
|---|---|
| Meta AI | Llama 3.3、Llama 3.2、Llama 3.1、Llama 3、Llama 2、Code Llama |
| Mistral AI | Mistral 7B、Mixtral 8x7B、Mixtral 8x22B、それらのバリアント(Instruct、Chat)、Mistral-tiny、Mistral-small、Mistral-medium |
| DeepSeek AI | DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B、DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B、Deepseek-vl2-tiny、Deepseek-vl2-small、Deepseek-vl2 |
| MosaicML | MPT(7B、30B)とバリエーション(指示、チャット)、MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2、GPT-3、GPT-4、GPT-NeoX |
| Together AI | RedPajama、Pythia |
| Stability AI | StableLM(3B、7B)、StableLM-Alpha-3B、StableLM-Base-Alpha-7B、StableLM-Instruct-Alpha-7B |
| TII(Technology Innovation Institute) | Falcon 7B、Falcon 40B とそれらのバリエーション(Instruct、Chat)、Falcon-RW-1B、Falcon-RW-7B |
| BigScience | BLOOM、BLOOMZ |
| FLAN-T5、UL2、Gemma(2B、7B)、PaLM 2、 | |
| Salesforce | CodeT5、CodeT5+ |
| LightOn | Persimmon-8B-base、Persimmon-8B-chat |
| EleutherAI | GPT-Neo、Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| その他の注目モデル | StarCoder、OPT、Baichuan、Aquila、Qwen、InternLM、XGen、OpenLLaMA、Phi-2、Yi、OpenCodeInterpreter、Nous-Hermes、Gemma-it、Mistral-Instruct-v0.2-7B-Zeus |
Model Garden を使ってみる
vLLM Cloud GPU サービング コンテナは、Model Garden のプレイグラウンド、ワンクリック デプロイ、Colab Enterprise ノートブックの例に統合されています。このチュートリアルでは、Meta AI の Llama モデル ファミリーを例として取り上げます。
Colab Enterprise ノートブックを使用する
プレイグラウンドとワンクリック デプロイも使用できますが、このチュートリアルでは説明しません。
- モデルカードのページに移動し、[ノートブックを開く] をクリックします。
- Vertex Serving ノートブックを選択します。ノートブックが Colab Enterprise で開きます。
- ノートブックを実行して、vLLM を使用してモデルをデプロイし、予測リクエストをエンドポイントに送信します。
設定と要件
このセクションでは、 Google Cloudプロジェクトを設定し、vLLM モデルのデプロイと提供に必要なリソースを確保するために必要な手順について概説します。
1. 課金
- 課金を有効にする: プロジェクトで課金が有効になっていることを確認します。プロジェクトの課金を有効化、無効化、または変更するを参照してください。
2. GPU の可用性と割り当て
- 高性能 GPU(NVIDIA A100 80 GB または H100 80 GB)を使用して予測を実行するには、選択したリージョンでこれらの GPU の割り当てを確認してください。
| マシンタイプ | アクセラレータ タイプ | 推奨されるリージョン |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1、us-east4、europe-west4、asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1、us-west1、europe-west4、asia-southeast1 |
3. Google Cloud プロジェクトを設定する
次のコードサンプルを実行して、 Google Cloud 環境が正しく設定されていることを確認します。このステップでは、必要な Python ライブラリをインストールし、 Google Cloud リソースへのアクセスを設定します。以下のような操作を行います。
- インストール:
google-cloud-aiplatformライブラリをアップグレードし、ユーティリティ関数を含むリポジトリのクローンを作成します。 - 環境の設定: Google Cloud プロジェクト ID、リージョン、モデル アーティファクトを保存する一意の Cloud Storage バケットの環境変数を定義します。
- API の有効化: AI モデルのデプロイと管理に不可欠な Vertex AI API と Compute Engine API を有効にします。
- バケットの構成: 新しい Cloud Storage バケットを作成するか、既存のバケットを確認して、正しいリージョンにあることを確認します。
- Vertex AI の初期化: プロジェクト、ロケーション、ステージング バケットの設定を使用して Vertex AI クライアント ライブラリを初期化します。
- サービス アカウントの設定: Vertex AI ジョブの実行に使用するデフォルトのサービス アカウントを特定し、必要な権限を付与します。
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Meta Llama 3.1、3.2、vLLM で Hugging Face を使用する
Meta の Llama 3.1 コレクションと 3.2 コレクションには、さまざまなユースケースで高品質のテキストを生成するように設計された、さまざまな多言語大規模言語モデル(LLM)が用意されています。これらのモデルは事前トレーニングされ、指示でチューニングされており、多言語の会話、要約、エージェント検索などのタスクに優れています。Llama 3.1 モデルと 3.2 モデルを使用する前に、スクリーンショットに示すように利用規約に同意する必要があります。vLLM ライブラリは、レイテンシ、メモリ効率、スケーラビリティを最適化したオープンソースの効率的なサービング環境を提供します。
 図 1: Meta LLama 3 コミュニティ ライセンス契約
図 1: Meta LLama 3 コミュニティ ライセンス契約Meta Llama 3.1 コレクションと 3.2 コレクションの概要
Llama 3.1 コレクションと 3.2 コレクションは、それぞれ異なるデプロイ スケールとモデルサイズに対応しており、多言語の会話タスクなどに対する柔軟なオプションが用意されています。詳細については、Llama の概要ページをご覧ください。
- テキストのみ: 多言語大規模言語モデル(LLM)の Llama 3.2 コレクションは、1B と 3B のサイズ(テキスト入力、テキスト出力)の事前トレーニング済みモデルと指示用にチューニングされた生成モデルのコレクションです。
- ビジョンとビジョン インストラクト: マルチモーダル大規模言語モデル(LLM)の Llama 3.2-Vision コレクションは、11B と 90B のサイズ(テキスト + 画像入力、テキスト出力)の事前トレーニング済みモデルと指示用にチューニングされた画像推論生成モデルのコレクションです。最適化: Llama 3.1 と同様に、3.2 モデルは多言語の会話用に調整されており、取得タスクと要約タスクで優れたパフォーマンスを発揮し、標準ベンチマークで最高の結果を達成しています。
- モデル アーキテクチャ: Llama 3.2 には、自動回帰トランスフォーマー フレームワークも搭載されています。SFT と RLHF が適用され、有用性と安全性のためにモデルが調整されます。
Hugging Face ユーザー アクセス トークン
このチュートリアルでは、必要なリソースにアクセスするために、Hugging Face Hub の読み取りアクセス トークンが必要です。認証を設定するには、次の操作を行います。
 図 2: Hugging Face アクセス トークンの設定
図 2: Hugging Face アクセス トークンの設定読み取りアクセス トークンを生成します。
- Hugging Face アカウントの設定に移動します。
- 新しいトークンを作成し、読み取りロールを割り当てて、トークンを安全に保存します。
トークンを使用します。
- 生成されたトークンを使用して、チュートリアルに応じて公開リポジトリまたは非公開リポジトリを認証してアクセスします。
 図 3: Hugging Face アクセス トークンを管理する
図 3: Hugging Face アクセス トークンを管理するこの設定により、不要な権限を付与することなく、適切なレベルのアクセス権を付与できます。これらの方法により、セキュリティが強化され、トークンの偶発的な漏洩を防ぐことができます。アクセス トークンの設定の詳細については、Hugging Face アクセス トークンのページをご覧ください。
トークンを公開する、またはオンラインで共有または公開することは回避してください。デプロイ時にトークンを環境変数として設定すると、トークンはプロジェクトに限定されたままになります。Vertex AI は、他のユーザーがモデルとエンドポイントにアクセスできないようにすることでセキュリティを確保します。
アクセス トークンの保護の詳細については、Hugging Face アクセス トークン - ベスト プラクティスをご覧ください。
vLLM を使用してテキストのみの Llama 3.1 モデルをデプロイする
大規模言語モデルの本番環境デプロイでは、vLLM がメモリ使用量を最適化し、レイテンシを短縮してスループットを向上させる効率的なサービング ソリューションを提供します。そのため、大規模な Llama 3.1 モデルやマルチモーダル Llama 3.2 モデルの処理に特に適しています。
ステップ 1: デプロイするモデルを選択する
デプロイする Llama 3.1 モデル バリアントを選択します。使用可能なオプションには、さまざまなサイズと指示チューニング済みバージョンがあります。
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
ステップ 2: デプロイのハードウェアと割り当てを確認する
deploy 関数は、モデルサイズに基づいて適切な GPU とマシンタイプを設定し、特定のプロジェクトのそのリージョンの割り当てを確認します。
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
指定したリージョンで GPU 割り当ての可用性を確認します。
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
ステップ 3: vLLM を使用してモデルを検査する
次の関数は、モデルを Vertex AI にアップロードして、デプロイ設定を構成し、vLLM を使用してエンドポイントにデプロイします。
- Docker イメージ: デプロイでは、効率的なサービングのためにビルド済みの vLLM Docker イメージが使用されます。
- 構成: メモリ使用率、モデルの長さ、その他の vLLM 設定を構成します。サーバーでサポートされている引数の詳細については、vLLM の公式ドキュメント ページをご覧ください。
- 環境変数: 認証とデプロイ元の環境変数を設定します。
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
ステップ 4: デプロイを実行する
選択したモデルと構成でデプロイ関数を実行します。このステップでは、モデルをデプロイし、モデルとエンドポイントのインスタンスを返します。
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
このコードサンプルを実行すると、Llama 3.1 モデルが Vertex AI にデプロイされ、指定したエンドポイントからアクセスできるようになります。テキスト生成、要約、会話などの推論タスクで使用できます。モデルのサイズによっては、新しいモデルのデプロイに最大 1 時間かかることがあります。進行状況はオンライン予測で確認できます。
 図 4: Vertex ダッシュボードの Llama 3.1 デプロイ エンドポイント
図 4: Vertex ダッシュボードの Llama 3.1 デプロイ エンドポイントVertex AI で Llama 3.1 を使用して予測を行う
Llama 3.1 モデルを Vertex AI に正常にデプロイしたら、エンドポイントにテキスト プロンプトを送信して予測を開始できます。このセクションでは、出力を制御するためにさまざまなカスタマイズ可能なパラメータを使用してレスポンスを生成する例を示します。
ステップ 1: プロンプトとパラメータを定義する
まず、テキスト プロンプトとサンプリング パラメータを設定して、モデルのレスポンスをガイドします。主なパラメータは次のとおりです。
prompt: モデルにレスポンスを生成させる入力テキスト。たとえば、プロンプト =「車とは何か?」max_tokens: 生成される出力のトークンの最大数。この値を小さくすると、タイムアウトの問題を防ぐことができます。temperature: 予測のランダム性を制御します。値が大きいほど(1.0 など)多様性が高まり、値が小さいほど(0.5 など)出力の焦点が絞られます。top_p: サンプリング プールを上位の累積確率に制限します。たとえば、top_p = 0.9 に設定すると、確率のトップ 90% 内のトークンのみが考慮されます。top_k: サンプリングは、最も可能性の高い上位 K 個のトークンに制限されます。たとえば、top_k = 50 に設定すると、上位 50 個のトークンからのみサンプリングされます。raw_response: True の場合、未加工のモデル出力を返します。False の場合は、Prompt:\n{prompt}\nOutput:\n{output} という形式で追加のフォーマットを適用します。lora_id(省略可): Low-Rank Adaptation(LoRA)重みを適用する LoRA 重みファイルのパス。Cloud Storage バケットまたは Hugging Face リポジトリの URL を指定できます。これは、デプロイ パラメータで--enable-loraが設定されている場合にのみ機能します。動的 LoRA はマルチモーダル モデルではサポートされていません。
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
ステップ 2: 予測リクエストを送信する
インスタンスが構成されたので、デプロイされた Vertex AI エンドポイントに予測リクエストを送信できます。次の例は、予測を行い、結果を出力する方法を示しています。
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
出力例
次に、プロンプト「車とは?」に対するモデルの回答の例を示します。
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
その他の情報
- モデレーション: 安全なコンテンツを確保するために、Vertex AI のテキスト モデレーション機能を使用して生成されたテキストをモデレートできます。
- タイムアウトの処理:
ServiceUnavailable: 503などの問題が発生した場合は、max_tokensパラメータを減らしてみてください。
このアプローチでは、さまざまなサンプリング手法と LoRA アダプターを使用して Llama 3.1 モデルを柔軟に操作できるため、汎用テキスト生成からタスク固有のレスポンスまで、さまざまなユースケースに適しています。
vLLM を使用したマルチモーダル Llama 3.2 モデルのデプロイ
このセクションでは、事前構築された Llama 3.2 モデルを Model Registry にアップロードし、Vertex AI エンドポイントにデプロイするプロセスについて説明します。デプロイ時間は、モデルのサイズによって最大 1 時間かかることがあります。Llama 3.2 モデルは、テキストと画像の両方の入力をサポートするマルチモーダル バージョンで利用できます。vLLM は次のものをサポートしています。
- テキストのみの形式
- 単一の画像とテキストの形式
これらの形式により、Llama 3.2 は画像処理とテキスト処理の両方を必要とするアプリケーションに適しています。
ステップ 1: デプロイするモデルを選択する
デプロイする Llama 3.2 モデル バリアントを指定します。次の例では、選択したモデルとして Llama-3.2-11B-Vision を使用していますが、要件に応じて他の利用可能なオプションを選択することもできます。
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
ステップ 2: ハードウェアとリソースを構成する
モデルサイズに適したハードウェアを選択します。vLLM は、モデルのコンピューティング要件に応じてさまざまな GPU を使用できます。
- 1B モデルと 3B モデル: NVIDIA L4 GPU を使用します。
- 11B モデル: NVIDIA A100 GPU を使用します。
- 90B モデル: NVIDIA H100 GPU を使用します。
この例では、モデルの選択に基づいてデプロイを構成します。
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
必要な GPU 割り当てがあることを確認します。
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
ステップ 3: vLLM を使用してモデルをデプロイする
次の関数は、Vertex AI への Llama 3.2 モデルのデプロイを処理します。効率的なサービングのために、モデルの環境、メモリ使用量、vLLM 設定を構成します。
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
ステップ 4: デプロイを実行する
構成済みのモデルと設定を使用してデプロイ関数を実行します。この関数は、モデル インスタンスとエンドポイント インスタンスの両方を返します。これらは推論に使用できます。
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
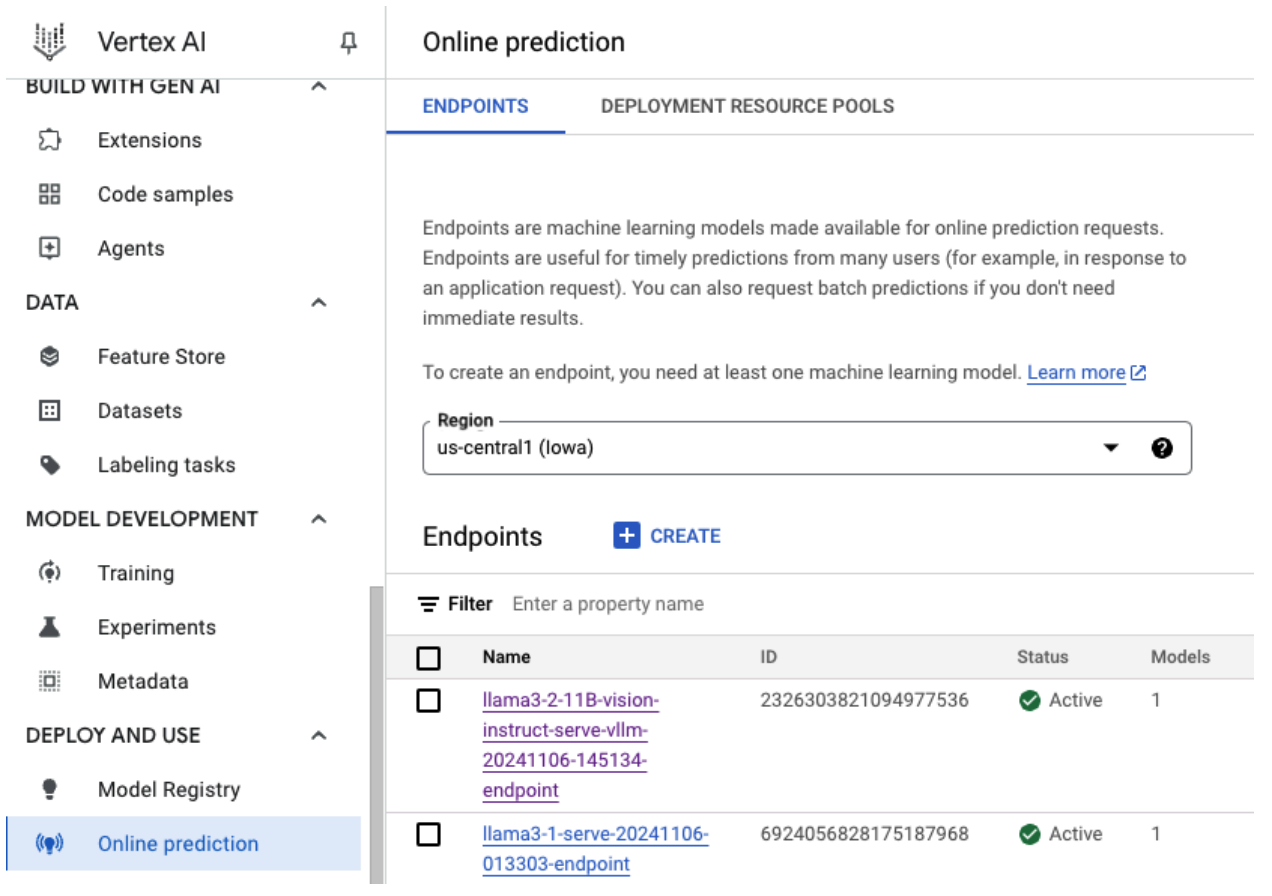 図 5: Vertex ダッシュボードの Llama 3.2 デプロイ エンドポイント
図 5: Vertex ダッシュボードの Llama 3.2 デプロイ エンドポイントモデルのサイズによっては、新しいモデルのデプロイが完了するまでに最大 1 時間かかることがあります。進行状況はオンライン予測で確認できます。
デフォルトの予測ルートを使用して Vertex AI で vLLM による推論を行う
このセクションでは、デフォルトの予測ルートを使用して、Vertex AI で Llama 3.2 Vision モデルの推論を設定する方法について説明します。vLLM ライブラリを使用してサービングを効率化し、テキストと組み合わせてビジュアル プロンプトを送信してモデルを操作します。
始める前に、モデル エンドポイントがデプロイされ、予測の準備ができていることを確認します。
ステップ 1: プロンプトとパラメータを定義する
この例では、画像の URL とテキスト プロンプトを指定します。モデルはこれを処理してレスポンスを生成します。
 図 6: Llama 3.2 のプロンプト用のサンプル画像入力
図 6: Llama 3.2 のプロンプト用のサンプル画像入力image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
ステップ 2: 予測パラメータを構成する
次のパラメータを調整して、モデルのレスポンスを制御します。
max_tokens = 64
temperature = 0.5
top_p = 0.95
ステップ 3: 予測リクエストを準備する
画像 URL、プロンプト、その他のパラメータを使用して予測リクエストを設定します。
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
ステップ 4: 予測を行う
リクエストを Vertex AI エンドポイントに送信し、レスポンスを処理します。
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
タイムアウトの問題(ServiceUnavailable: 503 Took too
long to respond when processing など)が発生した場合は、max_tokens の値を 20 など小さい値に減らして、レスポンス時間を短縮してみてください。
OpenAI Chat Completion を使用して Vertex AI で vLLM による推論を行う
このセクションでは、Vertex AI で OpenAI Chat Completions API を使用して Llama 3.2 Vision モデルで推論を行う方法について説明します。このアプローチでは、画像とテキスト プロンプトの両方をモデルに送信してマルチモーダル機能を使用することで、よりインタラクティブなレスポンスを得ることができます。
ステップ 1: Llama 3.2 Vision Instruct モデルのデプロイを実行する
構成済みのモデルと設定を使用してデプロイ関数を実行します。この関数は、モデル インスタンスとエンドポイント インスタンスの両方を返します。これらは推論に使用できます。
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
ステップ 2: エンドポイント リソースを構成する
まず、Vertex AI デプロイのエンドポイント リソース名を設定します。
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
ステップ 3: OpenAI SDK と認証ライブラリをインストールする
OpenAI の SDK を使用してリクエストを送信するには、必要なライブラリがインストールされていることを確認します。
!pip install -qU openai google-auth requests
ステップ 4: チャットの完了の入力パラメータを定義する
モデルに送信する画像の URL とテキスト プロンプトを設定します。max_tokens と temperature を調整して、レスポンスの長さとランダム性をそれぞれ制御します。
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
ステップ 5: 認証とベース URL を設定する
認証情報を取得し、API リクエストのベース URL を設定します。
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
ステップ 6: チャット完了リクエストを送信する
OpenAI の Chat Completions API を使用して、画像とテキスト プロンプトを Vertex AI エンドポイントに送信します。
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(省略可)ステップ 7: 既存のエンドポイントに再接続する
以前に作成したエンドポイントに再接続するには、エンドポイント ID を使用します。この手順は、エンドポイントを新しく作成するのではなく再利用する場合に便利です。
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
この設定により、必要に応じて新しく作成したエンドポイントと既存のエンドポイントを柔軟に切り替えることができ、テストとデプロイを効率化できます。
クリーンアップ
課金され続けることがないようにし、リソースを解放するには、デプロイされたモデル、エンドポイント、必要に応じてこのテストに使用したストレージ バケットを削除してください。
ステップ 1: エンドポイントとモデルを削除する
次のコードは、各モデルのデプロイを解除し、関連するエンドポイントを削除します。
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
ステップ 2:(省略可)Cloud Storage バケットを削除する
このテスト専用に Cloud Storage バケットを作成した場合は、delete_bucket を true に設定して削除できます。この手順は省略可能ですが、バケットが不要になった場合は行うことをおすすめします。
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
次の処理を行うと、このチュートリアルで使用したすべてのリソースがクリーンアップされ、テストに関連する不要な費用を削減できます。
一般的な問題のデバッグ
このセクションでは、Vertex AI での vLLM モデルのデプロイと推論中に発生する一般的な問題の特定と解決に関するガイダンスについて説明します。
ログを調べる
ログを確認して、デプロイの失敗や予期しない動作の根本原因を特定します。
- Vertex AI Prediction Console に移動する: Google Cloud コンソールで Vertex AI Prediction Console に移動します。
- エンドポイントを選択する: 問題が発生しているエンドポイントをクリックします。ステータスから、デプロイが失敗したかどうかを確認できます。
- ログを表示する: エンドポイントをクリックし、[ログ] タブに移動するか、[ログを表示] をクリックします。Cloud Logging に移動し、そのエンドポイントとモデルのデプロイに固有のログが表示されます。Cloud Logging サービスから直接ログにアクセスすることもできます。
- ログを分析する: ログエントリでエラー メッセージ、警告、その他の関連情報を確認します。タイムスタンプを表示して、ログエントリを特定のアクションと関連付けます。リソースの制約(メモリと CPU)、認証の問題、構成エラーに関する問題を探します。
一般的な問題 1: デプロイ中の CUDA メモリ不足(OOM)
CUDA メモリ不足(OOM)エラーは、モデルのメモリ使用量が利用可能な GPU 容量を超えると発生します。
テキストのみのモデルの場合、次のエンジン引数が使用されています。
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
マルチモーダル モデルの場合、次のエンジン引数が使用されています。
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
テキストのみのモデルの場合と同様に、max_num_seqs = 256 でマルチモーダル モデルをデプロイすると、次のエラーが発生する可能性があります。
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
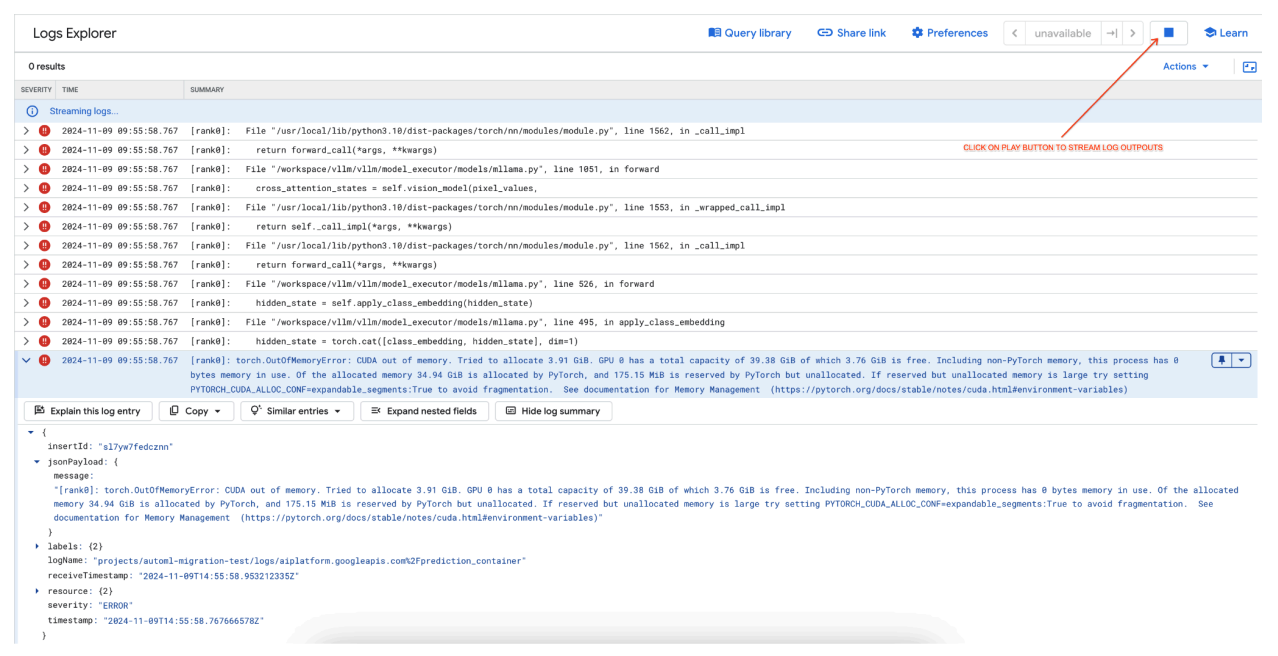 図 7: メモリ不足(OOM)GPU エラーログ
図 7: メモリ不足(OOM)GPU エラーログmax_num_seqs と GPU メモリについて理解します。
max_num_seqsパラメータは、モデルが処理できる同時リクエストの最大数を定義します。- モデルによって処理される各シーケンスは GPU メモリを消費します。合計メモリ使用量は、
max_num_seqs倍のシーケンスあたりのメモリに比例します。 - 通常、テキストのみのモデル(Meta-Llama-3.1-8B など)は、テキストと画像の両方を処理するマルチモーダル モデル(Llama-3.2-11B-Vision-Instruct など)よりもシーケンスあたりのメモリ消費量が少なくなります。
エラーログを確認します(図 8)。
- GPU でメモリを割り当てようとしたときに、ログに
torch.OutOfMemoryErrorが表示されます。 - このエラーは、モデルのメモリ使用量が利用可能な GPU 容量を超えているために発生します。NVIDIA L4 GPU は 24 GB です。マルチモーダル モデルに対して
max_num_seqsパラメータを高く設定しすぎると、オーバーフローが発生します。 - ログでは、メモリ管理を改善するために
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Trueを設定することを示唆していますが、主な問題はメモリ使用量が多いことです。
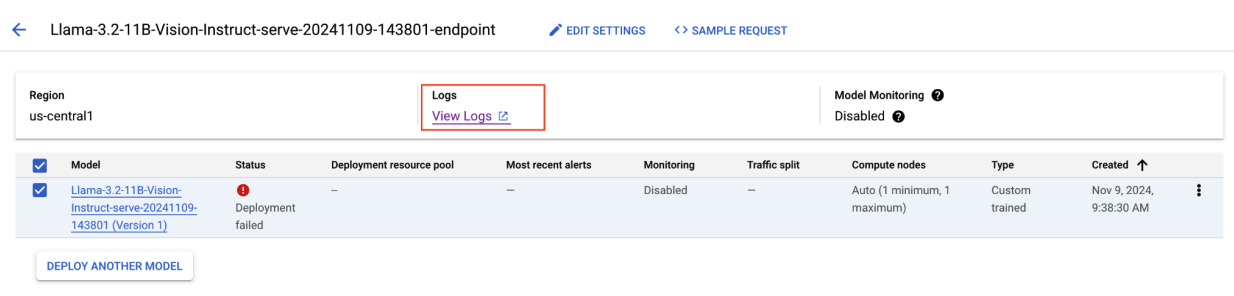 図 8: Llama 3.2 のデプロイに失敗した
図 8: Llama 3.2 のデプロイに失敗した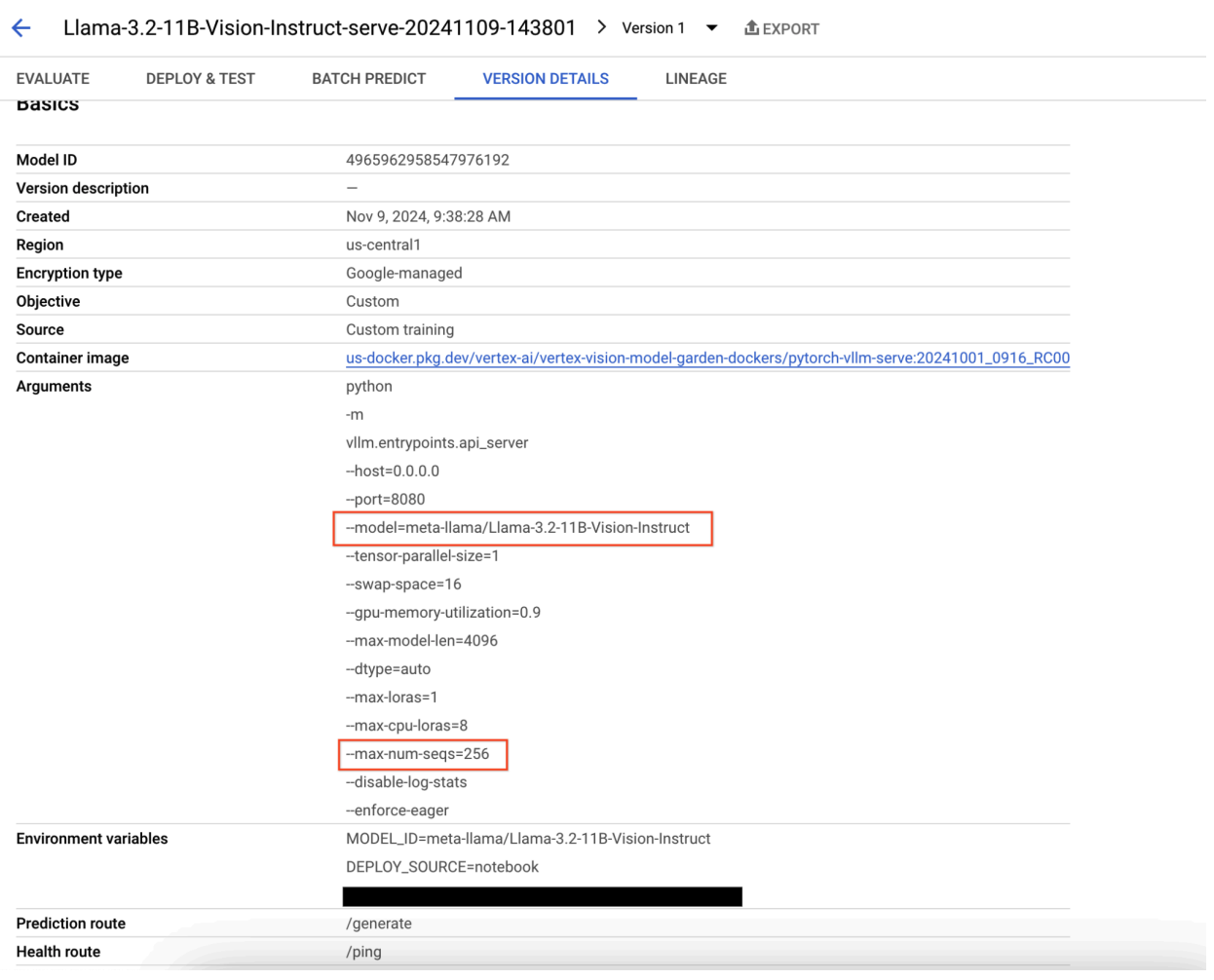 図 9: モデル バージョンの詳細パネル
図 9: モデル バージョンの詳細パネルこの問題を解決するには、Vertex AI Prediction コンソールに移動し、エンドポイントをクリックします。ステータスは、デプロイが失敗したことを示します。クリックしてログを表示します。max-num-seqs が 256 であることを確認します。この値は Llama-3.2-11B-Vision-Instruct には高すぎます。適切な値は 12 です。
一般的な問題 2: Hugging Face トークンが必要
Hugging Face トークンエラーは、モデルが制限付きで、アクセスに適切な認証情報を必要としている場合に発生します。
次のスクリーンショットは、Hugging Face でホストされている Meta LLaMA-3.2-11B-Vision モデルへのアクセスに関連するエラー メッセージが表示された、Google Cloud のログ エクスプローラのログエントリを示しています。このエラーは、モデルへのアクセスが制限されており、続行するには認証が必要であることを示します。メッセージには「Cannot access gated repository for URL」(URL の限定公開リポジトリにアクセスできません)と明記されており、モデルが限定公開であり、アクセスするには適切な認証情報が必要であることを示しています。このログエントリは、外部リポジトリで制限付きリソースを操作する際の認証に関する問題のトラブルシューティングに役立ちます。
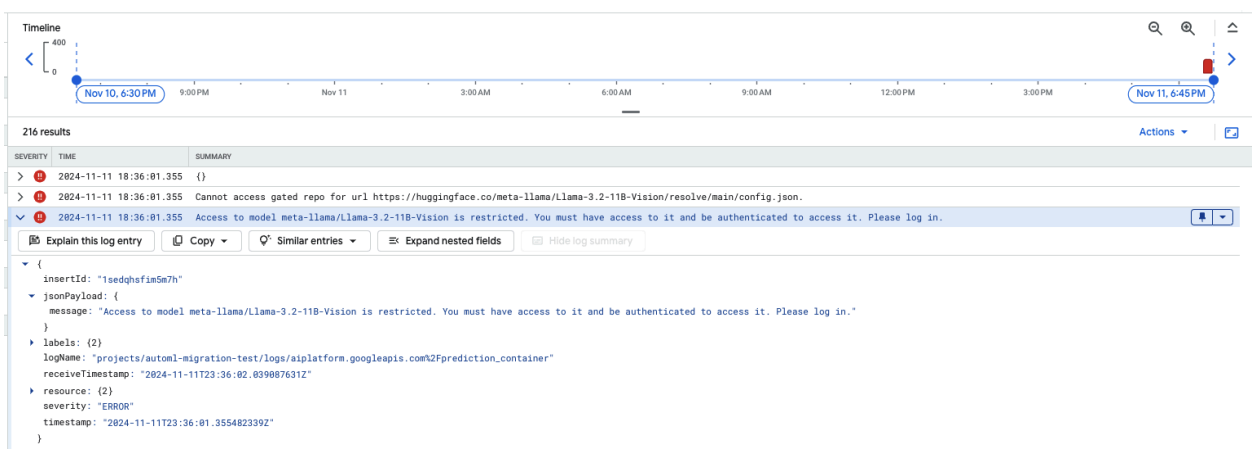 図 10: Hugging Face トークンのエラー
図 10: Hugging Face トークンのエラーこの問題を解決するには、Hugging Face アクセス トークンの権限を確認します。最新のトークンをコピーして、新しいエンドポイントをデプロイします。
一般的な問題 3: チャット テンプレートが必要
チャット テンプレート エラーは、デフォルトのチャット テンプレートを使用できなくなった場合に発生します。トークン化ツールで定義されていない場合は、カスタム チャット テンプレートを指定する必要があります。
このスクリーンショットは、Google Cloud のログ エクスプローラのログエントリを示しています。トランスフォーマー ライブラリ バージョン 4.44 にチャット テンプレートがないため、ValueError が発生しています。このエラー メッセージは、デフォルトのチャット テンプレートが使用できなくなったことを示します。また、トークン化ツールで定義されていない場合は、カスタム チャット テンプレートを指定する必要があります。このエラーは、ライブラリの最近の変更により、チャット テンプレートの明示的な定義が必要になったことを示します。これは、チャットベースのアプリのデプロイ時に問題をデバッグする際に役立ちます。
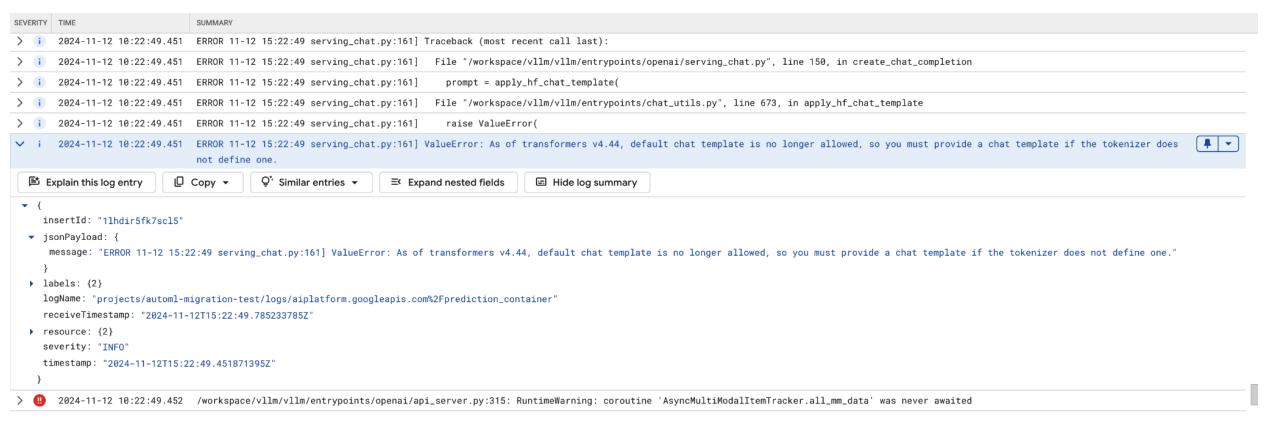 図 11: 必要なチャット テンプレート
図 11: 必要なチャット テンプレートこのエラーを回避するには、デプロイ時に --chat-template 入力引数を使用してチャット テンプレートを指定してください。サンプル テンプレートは、vLLM サンプル リポジトリにあります。
一般的な問題 4: モデルの最大シーケンス長
モデルの最大シーケンス長エラーは、モデルの最大シーケンス長(4,096)が KV キャッシュに保存できるトークンの最大数(2,256)を超えている場合に発生します。
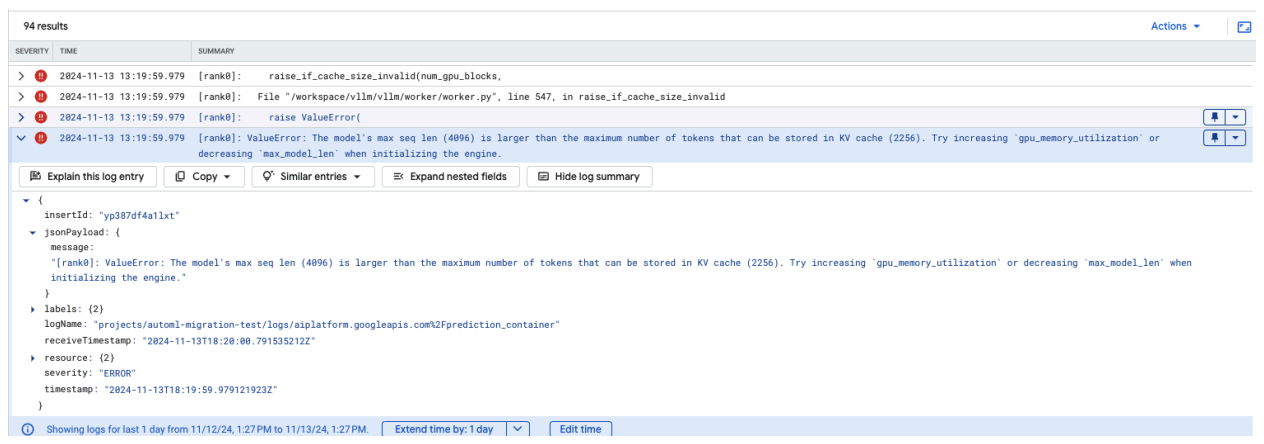 図 12: 最大シーケンス長が過剰に長い
図 12: 最大シーケンス長が過剰に長いValueError: モデルの最大シーケンス長(4,096)が、KV キャッシュに保存できるトークンの最大数(2,256)より大きい。エンジンを初期化する際に gpu_memory_utilization の値を引き上げるか、max_model_len の値を低減してみてください。
この問題を解決するには、max_model_len を 2,256 未満の 2,048 に設定します。この問題の解決策として、GPU の数を増やすか、より大きな GPU を使用する方法もあります。使用する GPU の数を増やす場合は、tensor-parallel-size を適切に設定する必要があります。
Model Garden vLLM コンテナのリリースノート
メインリリース
標準 vLLM
リリース日 |
アーキテクチャ |
vLLM バージョン |
コンテナ URI |
|---|---|---|---|
| 2025 年 7 月 17 日 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 2025 年 7 月 10 日 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 2025 年 6 月 20 日 | x86 |
v0.9.1 以降、commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 2025 年 6 月 11 日 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2025 年 6 月 2 日 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 2025 年 5 月 6 日 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 2025 年 4 月 29 日 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 2025 年 4 月 17 日 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| 2025 年 4 月 10 日 | x86 |
v0.8.3 以降、commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| 2025 年 4 月 7 日 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| 2025 年 4 月 7 日 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 2025 年 4 月 5 日 | x86 |
v0.8.2 以降、commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 2025 年 3 月 31 日 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 2025 年 3 月 26 日 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 2025 年 3 月 23 日 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 2025 年 3 月 21 日 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 2025 年 3 月 11 日 | x86 |
v0.7.3 以降、commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 2025 年 3 月 3 日 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 2025 年 1 月 14 日 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2024 年 12 月 2 日 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 2024 年 11 月 12 日 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 2024 年 10 月 16 日 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
最適化された vLLM
リリース日 |
アーキテクチャ |
コンテナ URI |
|---|---|---|
| 2025 年 1 月 21 日 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 2024 年 10 月 29 日 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
その他のリリース
VMG 標準 vLLM コンテナ リリースの完全なリストについては、Artifact Registry のページをご覧ください。
試験運用版の vLLM-TPU のリリースには <yyyymmdd_hhmm_tpu_experimental_RC00> のタグが付けられています。