本教程将指导您完成在 Vertex AI 上部署 Meta-Llama-3.1-8B 模型的过程。您将了解如何部署端点并根据您的特定需求进行优化。如果您有容错型工作负载,可以使用 Spot 虚拟机来优化费用。如果您想确保可用性,请使用 Compute Engine 预留。您将了解如何部署利用以下技术的端点:
- Spot 虚拟机:使用预配了 spot 的实例来大幅节省费用。
- 预留:保证资源可用性以实现可预测的性能,尤其是对于生产工作负载。本教程演示了如何使用自动 (
ANY_RESERVATION) 和特定 (SPECIFIC_RESERVATION) 预留。
如需了解详情,请参阅 Spot 虚拟机或 Compute Engine 资源的预留。
前提条件
在开始之前,请完成以下前提条件:
- 启用了结算功能的 Google Cloud 项目。
- 启用了 Vertex AI 和 Compute Engine API。
- 您打算使用的机器类型和加速器(例如 NVIDIA L4 GPU)具有足够的配额。如需检查配额,请查看 Google Cloud 控制台中的“配额和系统限制”。
- 一个 Hugging Face 账号和一个具有读取权限的用户访问令牌。
- 如果您是使用共享预留,请在项目之间授予 IAM 权限。笔记本中涵盖了所有这些权限。
在 Spot 虚拟机上部署
以下部分将指导您完成以下过程:设置 Google Cloud 项目、配置 Hugging Face 身份验证、使用 Spot 虚拟机或预留部署 Llama-3.1 模型以及测试部署。
1. 设置 Google Cloud 项目和共享预留
在第一部分中,在 Colab 笔记本中设置 PROJECT_ID、SHARED_PROJECT_ID(如果适用)、BUCKET_URI 和 REGION 变量。
笔记本会向这两个项目的服务账号授予 compute.viewer 角色。
如果您打算使用在同一组织内的其他项目中创建的预留,请务必向两个项目的 P4SA(主账号服务账号)授予 compute.viewer 角色。笔记本代码将自动执行此操作,但请确保 SHARED_PROJECT_ID 设置正确。此跨项目权限允许主项目中的 Vertex AI 端点查看并使用共享项目中的预留容量。
2. 设置 Hugging Face 身份验证
如需下载 Llama-3.1 模型,您需要在 Colab 笔记本中的 HF_TOKEN 变量中提供您的 Hugging Face 用户访问令牌。如果您未提供,则会收到以下错误:Cannot access gated repository for URL。
 图 1:Hugging Face 访问令牌设置
图 1:Hugging Face 访问令牌设置
3. 使用 Spot 虚拟机进行部署
如需将 Llama 模型部署到 Spot 虚拟机,请前往 Colab 笔记本中的“Spot 虚拟机 Vertex AI 端点部署”部分,然后设置 is_spot=True。
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
在共享预留实例上部署
以下部分将指导您完成以下过程:创建共享预留、配置预留设置、使用 ANY_RESERVATION 或 SPECIFIC_RESERVATION 部署 Llama-3.1 模型以及测试部署。
1. 创建共享预留
如需配置预留,请参阅笔记本的“为 Vertex AI 预测设置预留”部分。为预留设置必需的变量,例如 RES_ZONE、RESERVATION_NAME、RES_MACHINE_TYPE、RES_ACCELERATOR_TYPE 和 RES_ACCELERATOR_COUNT。
您需要将 RES_ZONE 设置为 {REGION}-{availability_zone}
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. 共享预留
有两种类型的预留:单项目预留(默认)和共享预留。单项目预留只能由与预留本身位于同一项目中的虚拟机使用。另一方面,共享预留可供预留所在的项目中的虚拟机使用,也可供与之共享预留的任何其他项目中的虚拟机使用。使用共享预留可以提高预留资源的利用率,并减少需要创建和管理的预留总数。本教程重点介绍共享预留。如需了解详情,请参阅共享预留的工作原理。
在继续操作之前,请确保从 Google Cloud 控制台“与其他 Google 服务共享”,如图所示:
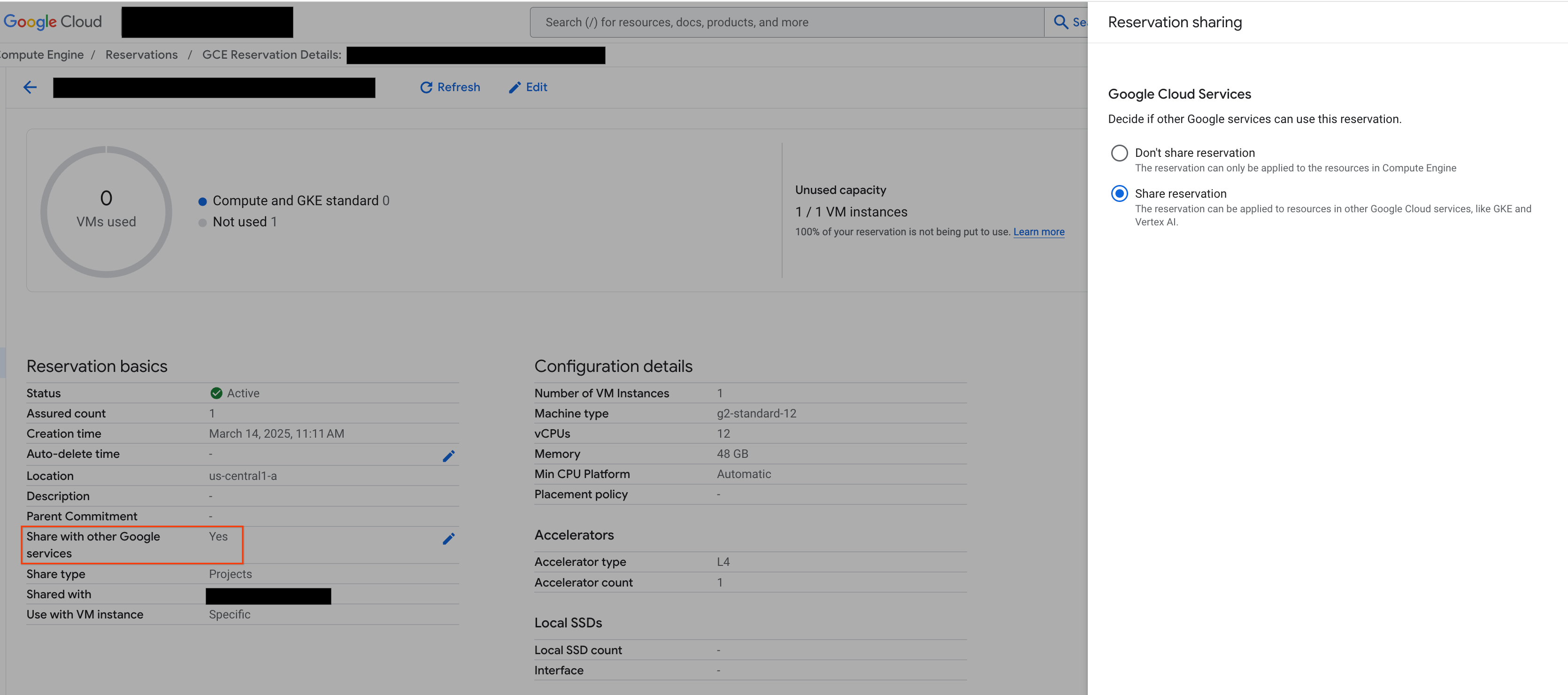 图 2:与其他 Google 服务共享预留
图 2:与其他 Google 服务共享预留
3. 使用 ANY_RESERVATION 进行部署
如需使用 ANY_RESERVATION 部署端点,请前往笔记本的“使用 ANY_RESERVATION 部署 Llama-3.1 端点”部分。指定部署设置,然后设置 reservation_affinity_type="ANY_RESERVATION"。然后运行相应单元以部署端点。
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. 测试 ANY_RESERVATION 端点
部署端点后,请务必测试几个提示,以确保端点已正确部署。
5. 使用 SPECIFIC_RESERVATION 进行部署
如需使用 SPECIFIC_RESERVATION 部署端点,请前往笔记本的“使用 SPECIFIC_RESERVATION 部署 Llama-3.1 端点”部分。指定以下参数:reservation_name、reservation_affinity_type="SPECIFIC_RESERVATION"、reservation_project 和 reservation_zone。然后运行相应单元以部署端点。
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. 测试 SPECIFIC_RESERVATION 端点
部署端点后,请验证 Vertex AI Online Prediction 是否使用了预留,并且务必测试几个提示,以确保端点已正确部署。
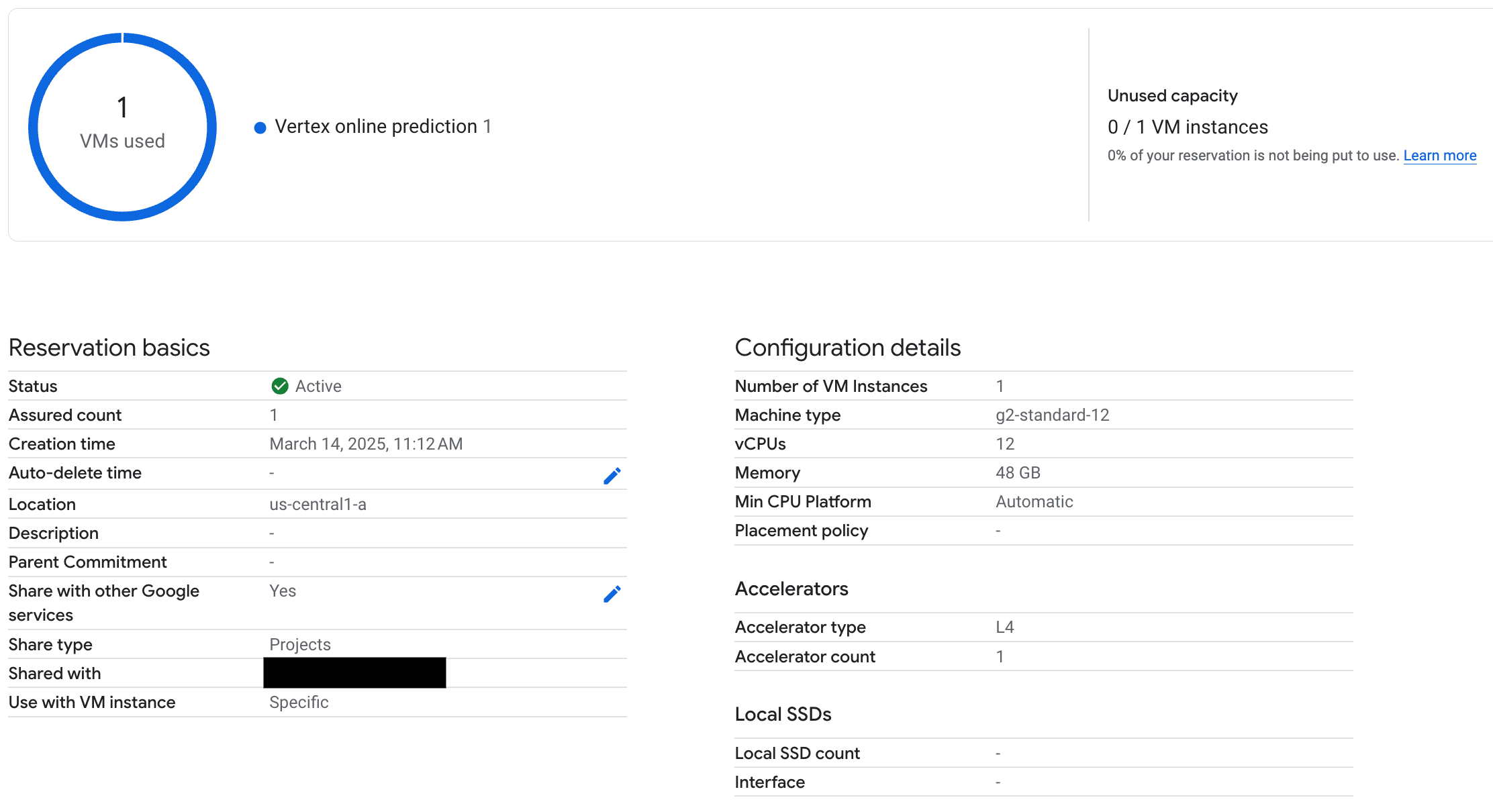 图 3:检查预留是否被 Vertex 在线预测使用
图 3:检查预留是否被 Vertex 在线预测使用
7. 清理
为避免持续产生费用,请删除在本教程中创建的模型、端点和预留。Colab 笔记本的“清理”部分提供了用于自动执行此清理过程的代码。
问题排查
- Hugging Face 令牌错误:核查您的 Hugging Face 令牌是否具有
read权限,以及是否已在笔记本中正确设置。 - 配额错误:验证您在部署到的区域中是否拥有足够的 GPU 配额。如有需要,请申请增加配额。
- 预留冲突:确保端点部署的机器类型和加速器配置与预留的设置相匹配。确保预留已启用,可与 Google 服务共享
后续步骤
- 探索不同的 Llama 3 模型变体。
- 如需详细了解预留,请参阅 Compute Engine 预留概览。
- 如需详细了解 Spot 虚拟机,请参阅 Spot 虚拟机概览。