文本到图像 AI
根据文本创建和编辑图片,无需编写任何代码
使用 Gemini 2.5 Flash Image 和 Imagen 图片生成模型,搭配 Python、Java 和 Go 编程语言的可用 API,短短几秒钟内就能根据文本描述生成和修改图片。
新客户可获享最高 $300 赠金,用于在 Vertex AI 上生成图片及完成其他任务。
概览
什么是文字转图像 AI?
文生图 AI 是一种可以根据文本描述生成和编辑图像的人工智能。这项技术有望改变我们与视觉内容互动的方式以及创作视觉内容的方式。Vertex AI 中提供的 Google Cloud 文本到 AI 工具和资源(包括 Imagen、Gemini 2.5 Flash Image 和 Veo 等预训练 AI 模型)旨在帮助开发者在其应用中轻松实现文生图。
在应用开发中如何使用文本到图像?
在应用开发中,文本到图像 AI 可用于生成模型、原型、插图、测试数据、教育内容和可视化内容,以便进行调试。object detection借助 Google Cloud 的 Vertex AI 和 Cloud Vision API,开发者可以使用一整套图像处理功能,包括文本检测、对象检测和图片分类。Document AI 可用于提取扫描文档中的文本,以生成文本描述图片。
哪些模型可用于生成文本到图像?
Imagen 和 Gemini 2.5 Flash Image 是 Google 主要的文生图模型。
这些模型有何不同?
Imagen:Imagen 是一个专用的纯图片模型。它构建为 diffusion 引擎,这意味着它的主要功能是根据文本提示生成精美且逼真的高质量图片。它的优势在于“将文本与像素进行模式匹配”,生成美观且具有视觉吸引力的输出。
Gemini 2.5 Flash Image:这是一个原生多模态大语言模型 (LLM)。与专用图像模型不同,它将图像视为另一种形式的“语言”。这意味着它是从头开始训练的,会在一个统一的步骤中理解和处理文本及图片。正是这种架构让它具备了超越简单生成功能的独特能力。
如何使用这些 Google 模型?
您可以通过 Google Cloud 上的 Vertex AI 或 Google AI Studio 访问这些文生图 AI 模型。如需使用这些模型,只需提供文本提示,选择参数(某些模型允许您选择参数来控制所生成图片的风格、创意和准确率),最后生成图片。
工作方式
文本到图像 AI 使用自然语言处理 (NLP) 将文本描述转换为机器可读的格式。转换为机器可读的格式后,机器学习模型即可使用大型文本和图像数据集进行训练,学习识别模式,并使用这些模式生成或修改新的图像。Google Cloud 的文本到图像 AI 使用名为 Imagen 的深度学习模型。Imagen 是一种先进的模型,可以基于文本描述生成逼真的图像。
文本到图像 AI 使用自然语言处理 (NLP) 将文本描述转换为机器可读的格式。转换为机器可读的格式后,机器学习模型即可使用大型文本和图像数据集进行训练,学习识别模式,并使用这些模式生成或修改新的图像。Google Cloud 的文本到图像 AI 使用名为 Imagen 的深度学习模型。Imagen 是一种先进的模型,可以基于文本描述生成逼真的图像。
常见用途
使用 AI 生成图片
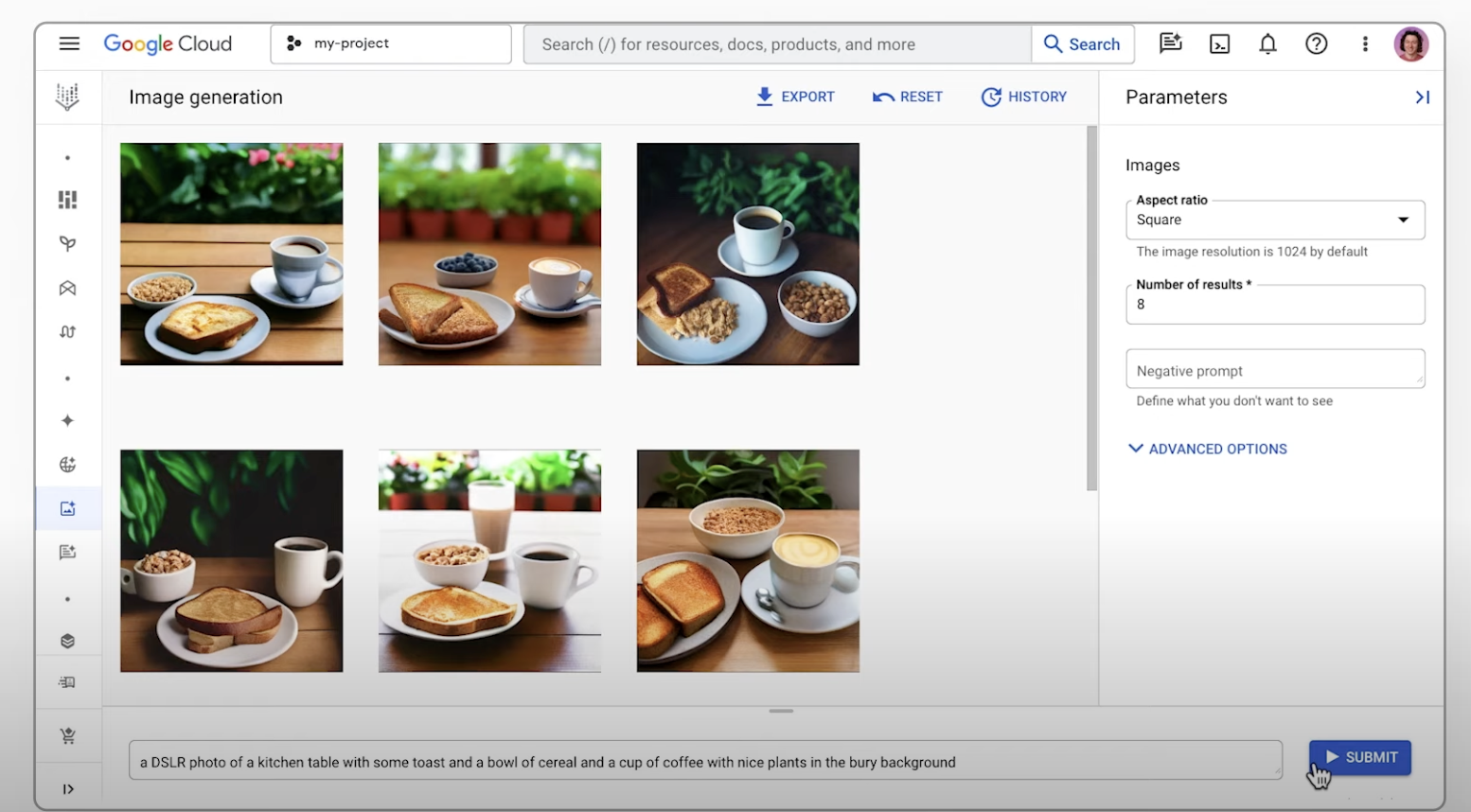
使用文本提示生成图片
了解如何使用 Imagen on Vertex AI 的文本到图像功能并导出生成的图片的放大版本。本快速入门介绍如何在 Google Cloud 控制台中使用 Imagen 图片生成功能。

方法指南
使用文本提示生成图片
了解如何使用 Imagen on Vertex AI 的文本到图像功能并导出生成的图片的放大版本。本快速入门介绍如何在 Google Cloud 控制台中使用 Imagen 图片生成功能。
利用 AI 技术编辑图片
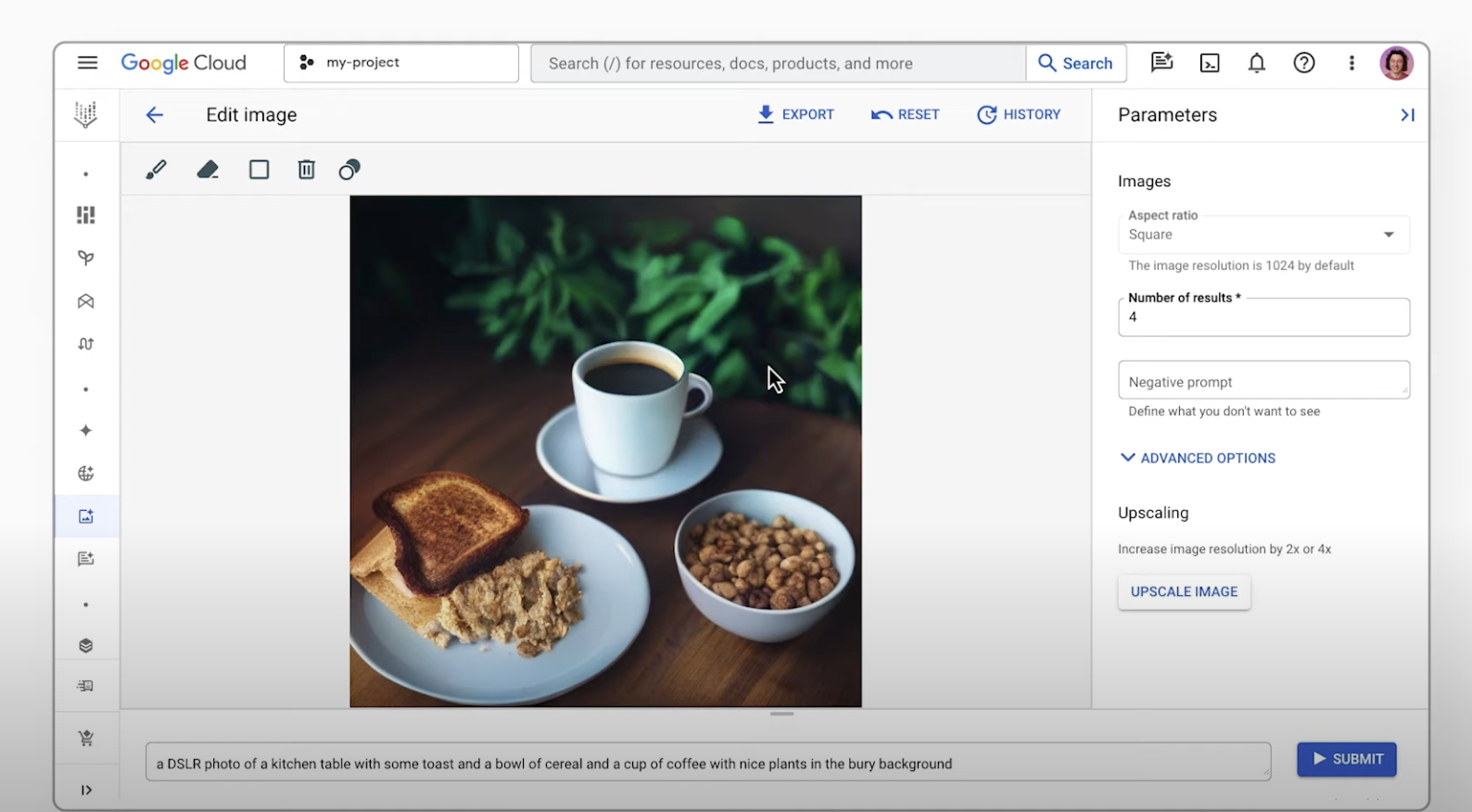
多图片融合和对话式智能修图
借助 Gemini 2.5 Flash Image,您可以将不同的图片组合成一张无缝拼接的新图片。使用多张参考图片,创建一张统一的图片。您还可以使用简单的自然语言指令来编辑图片。无论是从合照中移除某个人,还是修复污渍等小细节,你都可以通过简单的对话进行更改。
此外,借助 Imagen on Vertex AI,您可以修改 Imagen 生成的图片或现有图片。除了更新的文本说明之外,您还可以指定图片中要修改的部分(基于蒙版的修改)。
方法指南
多图片融合和对话式智能修图
借助 Gemini 2.5 Flash Image,您可以将不同的图片组合成一张无缝拼接的新图片。使用多张参考图片,创建一张统一的图片。您还可以使用简单的自然语言指令来编辑图片。无论是从合照中移除某个人,还是修复污渍等小细节,你都可以通过简单的对话进行更改。
此外,借助 Imagen on Vertex AI,您可以修改 Imagen 生成的图片或现有图片。除了更新的文本说明之外,您还可以指定图片中要修改的部分(基于蒙版的修改)。
数字水印
生成并验证图片的水印
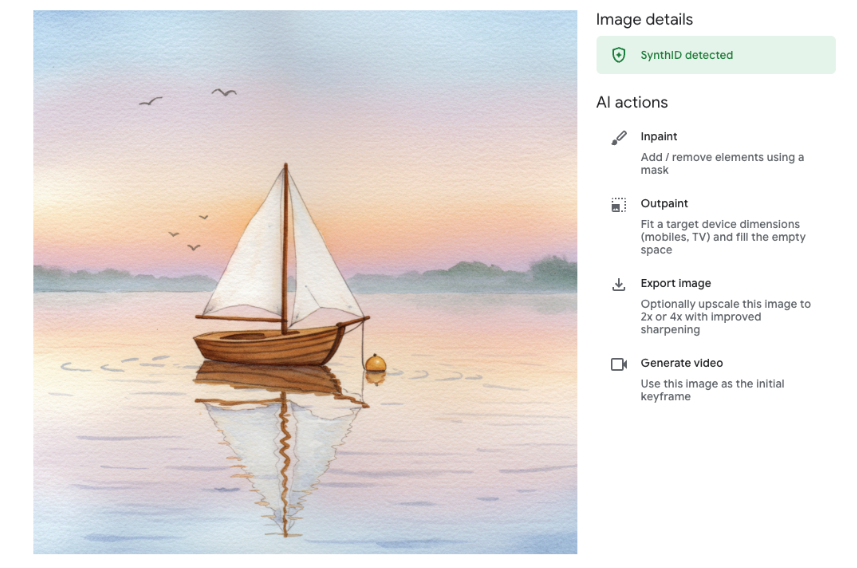
Vertex AI 上的某些 AI 模型(例如 Imagen 和 Gemini 2.5 Flash Image)生成的图片会自动添加数字水印。这项技术名为 SynthID,由 Google Deepmind 开发,可将不可见的水印直接嵌入到图片的像素中。
如需在 Vertex AI 上检测图片中的数字水印,可以使用内置的检测工具。使用 Vertex AI Media Studio,您只需上传想要验证的图片,如果检测到 SynthID 水印,图片就会显示“检测到 SynthID”标记。
方法指南
生成并验证图片的水印
Vertex AI 上的某些 AI 模型(例如 Imagen 和 Gemini 2.5 Flash Image)生成的图片会自动添加数字水印。这项技术名为 SynthID,由 Google Deepmind 开发,可将不可见的水印直接嵌入到图片的像素中。
如需在 Vertex AI 上检测图片中的数字水印,可以使用内置的检测工具。使用 Vertex AI Media Studio,您只需上传想要验证的图片,如果检测到 SynthID 水印,图片就会显示“检测到 SynthID”标记。











