AI teks ke gambar
Membuat dan mengedit gambar dari teks tanpa menulis kode apa pun
Buat dan edit gambar dari deskripsi teks dalam hitungan detik menggunakan model pembuatan gambar Gemini 3 Pro Image dan Imagen dengan API yang tersedia dalam bahasa pemrograman Python, Java, dan Go.
Pelanggan baru mendapatkan kredit gratis senilai hingga $300 untuk membuat gambar dan lainnya di Platform Agen Gemini Enterprise.
Ringkasan
Apa itu AI teks ke gambar?
AI text-to-image adalah jenis kecerdasan buatan yang dapat menghasilkan dan mengedit gambar dari deskripsi teks. Teknologi ini memiliki potensi untuk mengubah cara kita berinteraksi dengan konten visual dan cara pembuatannya. Alat dan resource text-to-AI Google Cloud, termasuk model AI terlatih seperti Imagen, Gemini 3 Pro Image, dan Veo, yang tersedia di Platform Agen, dirancang untuk membantu developer mengimplementasikan pembuatan text-to-image dengan mudah dalam aplikasi mereka.
Bagaimana teks-ke-gambar digunakan dalam pengembangan aplikasi?
AI text-to-image dapat digunakan dalam pengembangan aplikasi untuk membuat mockup, prototipe, ilustrasi, data pengujian, konten edukasi, dan visualisasi untuk proses debug. Platform Agen dan Cloud Vision API dari Google Cloud memungkinkan developer mengakses serangkaian kapabilitas pemrosesan gambar, termasuk deteksi teks, deteksi objek, dan klasifikasi gambar. Document AI dapat digunakan untuk mengekstrak teks dari dokumen yang dipindai untuk membuat gambar yang disertai deskripsi teks.
Bagaimana cara menggunakan model Google ini?
Anda dapat mengakses model AI text-to-image ini melalui Platform Agen di Google Cloud atau Google AI Studio. Untuk menggunakan model tersebut, cukup sediakan perintah teks, pilih parameter (beberapa model memungkinkan Anda memilih parameter yang mengontrol gaya, kreativitas, dan akurasi gambar yang dihasilkan), dan hasilkan gambar.
Cara Kerjanya
AI text-to-image menggunakan natural language processing (NLP) untuk mengonversi deskripsi teks ke format yang dapat dibaca mesin. Setelah dikonversi ke format yang dapat dibaca mesin, model machine learning dilatih menggunakan set data teks dan gambar dalam skala besar, belajar mengidentifikasi pola, dan menggunakannya untuk menghasilkan atau mengedit gambar.
AI text-to-image menggunakan natural language processing (NLP) untuk mengonversi deskripsi teks ke format yang dapat dibaca mesin. Setelah dikonversi ke format yang dapat dibaca mesin, model machine learning dilatih menggunakan set data teks dan gambar dalam skala besar, belajar mengidentifikasi pola, dan menggunakannya untuk menghasilkan atau mengedit gambar.
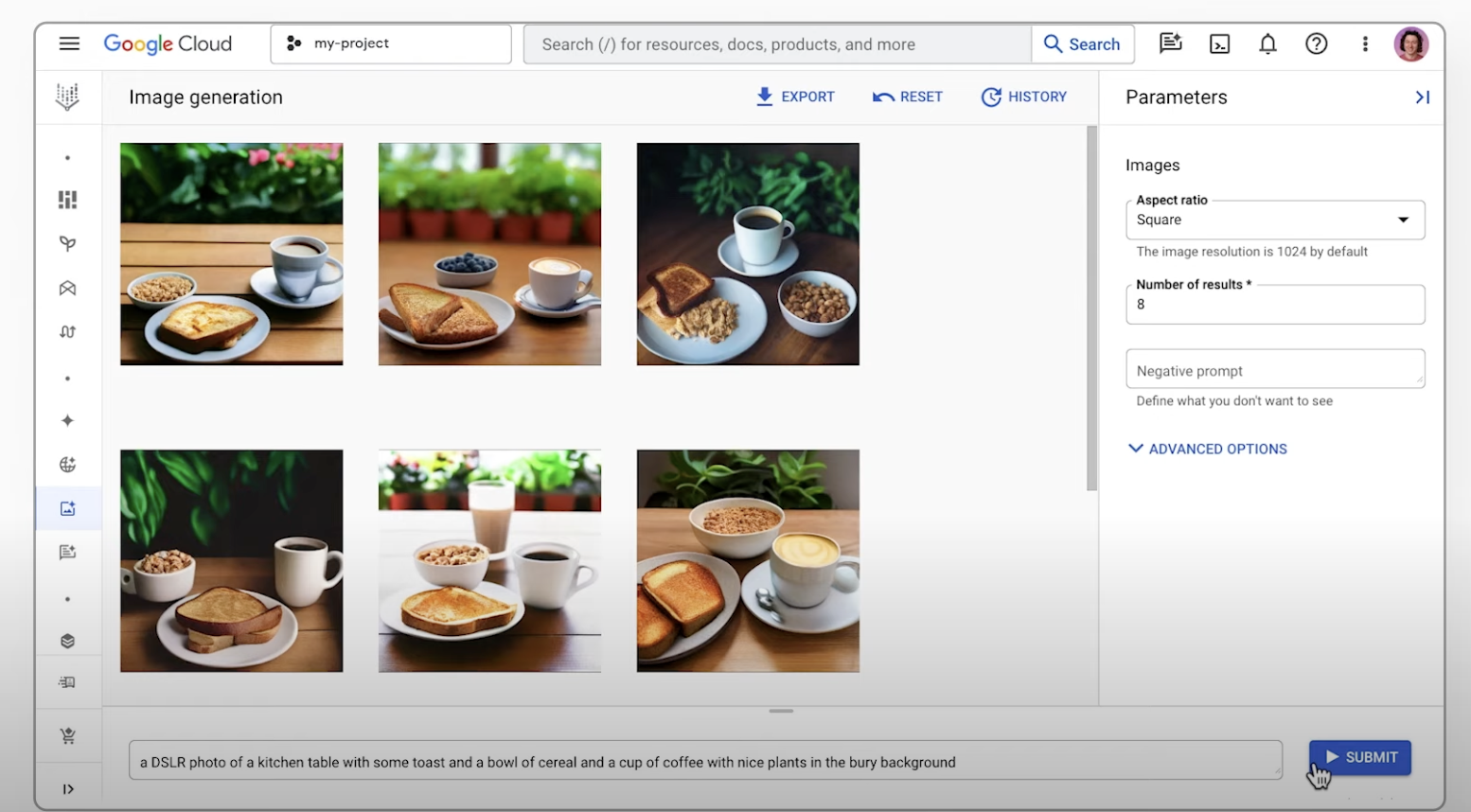
Membuat gambar menggunakan AI
Membuat gambar menggunakan perintah teks
Pelajari cara menggunakan fitur pembuatan text-to-image dari Imagen di Platform Agen dan mengekspor versi gambar generatif yang ditingkatkan kualitasnya. Panduan memulai ini menunjukkan cara menggunakan pembuatan gambar Imagen di konsol Google Cloud.

Petunjuk
Membuat gambar menggunakan perintah teks
Pelajari cara menggunakan fitur pembuatan text-to-image dari Imagen di Platform Agen dan mengekspor versi gambar generatif yang ditingkatkan kualitasnya. Panduan memulai ini menunjukkan cara menggunakan pembuatan gambar Imagen di konsol Google Cloud.
Mengedit gambar dengan AI
Penggabungan multi-gambar dan pengeditan via percakapan
Dengan Gemini, Anda dapat menggabungkan berbagai gambar menjadi satu visual baru yang mulus. Gunakan beberapa gambar referensi untuk membuat satu gambar terpadu. Anda juga dapat mengedit gambar dengan petunjuk bahasa natural yang sederhana. Mulai dari menghapus seseorang dari foto grup hingga memperbaiki detail kecil seperti noda, Anda dapat melakukan perubahan melalui percakapan sederhana.
Selain itu, Imagen di Platform Agen memungkinkan Anda mengedit gambar yang dihasilkan Imagen atau gambar yang sudah ada. Anda dapat menentukan bagian gambar yang akan dimodifikasi beserta deskripsi teks dari gambar yang diperbarui (pengeditan berbasis mask)
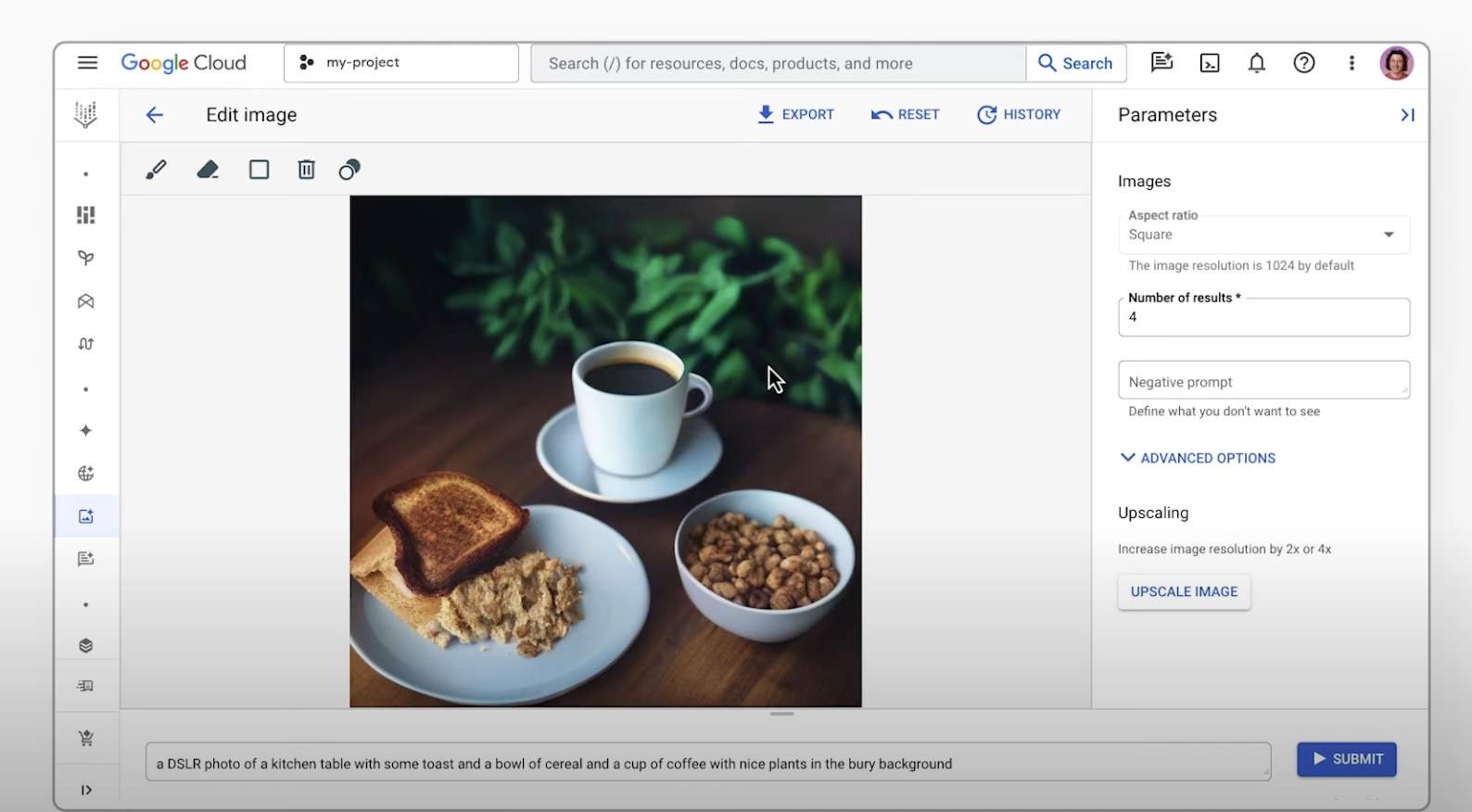
Petunjuk
Penggabungan multi-gambar dan pengeditan via percakapan
Dengan Gemini, Anda dapat menggabungkan berbagai gambar menjadi satu visual baru yang mulus. Gunakan beberapa gambar referensi untuk membuat satu gambar terpadu. Anda juga dapat mengedit gambar dengan petunjuk bahasa natural yang sederhana. Mulai dari menghapus seseorang dari foto grup hingga memperbaiki detail kecil seperti noda, Anda dapat melakukan perubahan melalui percakapan sederhana.
Selain itu, Imagen di Platform Agen memungkinkan Anda mengedit gambar yang dihasilkan Imagen atau gambar yang sudah ada. Anda dapat menentukan bagian gambar yang akan dimodifikasi beserta deskripsi teks dari gambar yang diperbarui (pengeditan berbasis mask)
Teks visual dengan AI
Mendapatkan deskripsi gambar menggunakan teks visual
Buat deskripsi yang relevan untuk gambar, termasuk metadata mendetail, teks otomatis, serta deskripsi singkat produk dan aset visual.
Petunjuk
Mendapatkan deskripsi gambar menggunakan teks visual
Buat deskripsi yang relevan untuk gambar, termasuk metadata mendetail, teks otomatis, serta deskripsi singkat produk dan aset visual.











