Text-zu-Bild-KI
Erstellen und bearbeiten Sie Bilder über Texteingaben, ohne eine einzige Codezeile schreiben zu müssen.
Mit den Bildgenerierungsmodellen Gemini 3 Pro Image und Imagen können Sie in Sekundenschnelle Bilder aus Textbeschreibungen generieren und bearbeiten. APIs sind in den Programmiersprachen Python, Java und Go verfügbar.
Neukunden erhalten ein Guthaben von bis zu 300 $, um Bilder und mehr auf der Gemini Enterprise Agent Platform zu generieren.
Überblick
Was ist Text-zu-Bild-KI?
Eine Text-zu-Bild-KI ist eine Art künstlicher Intelligenz, die Bilder aus Textbeschreibungen generieren und bearbeiten kann. Diese Technologie hat das Potenzial, die Art und Weise, wie wir mit visuellen Inhalten interagieren und sie erstellen, zu verändern. Die Text-zu-Bild-KI von Google Cloud, einschließlich vortrainierter KI-Modelle wie Imagen, Gemini 3 Pro Image und Veo, die in Agent Platform verfügbar sind, wurden entwickelt, um Entwicklern die Implementierung der Text-zu-Bild-Generierung in ihren Anwendungen zu erleichtern.
Wie wird Text-zu-Bild bei der Anwendungsentwicklung verwendet?
KI-Tools zur Text-zu-Bild-Generierung können in der Anwendungsentwicklung eingesetzt werden, um Mockups, Prototypen, Illustrationen, Testdaten, Lerninhalte und Visualisierungen für das Debugging zu erstellen. Die Agent Platform und die Cloud Vision API von Google Cloud bieten Entwicklern Zugriff auf eine Reihe von Bildverarbeitungsfunktionen, darunter Texterkennung, Objekterkennung und Bildklassifizierung. Document AI kann verwendet werden, um Text aus gescannten Dokumenten zu extrahieren und so Textbeschreibungsbilder zu generieren.
Wie kann ich diese Google-Modelle verwenden?
Sie können über Agent Platform in Google Cloud oder Google AI Studio auf diese KI-Modelle für die Text-zu-Bild-Generierung zugreifen. Um die Modelle zu verwenden, geben Sie einfach einen Text-Prompt ein, wählen Parameter aus (bei einigen Modellen können Sie Parameter wählen, die Stil, Kreativität und Genauigkeit des generierten Bildes steuern) und generieren schließlich das Bild.
Funktionsweise
Die KI für die Text-zu-Bild-Generierung nutzt Natural Language Processing (NLP), um die Textbeschreibung in ein maschinenlesbares Format zu konvertieren. Nach der Konvertierung in ein maschinell lesbares Format wird das Modell für maschinelles Lernen mit einem riesigen Datensatz aus Text und Bildern trainiert, wobei es lernt, Muster zu erkennen und über diese Bilder zu generieren zu bearbeiten.
Die KI für die Text-zu-Bild-Generierung nutzt Natural Language Processing (NLP), um die Textbeschreibung in ein maschinenlesbares Format zu konvertieren. Nach der Konvertierung in ein maschinell lesbares Format wird das Modell für maschinelles Lernen mit einem riesigen Datensatz aus Text und Bildern trainiert, wobei es lernt, Muster zu erkennen und über diese Bilder zu generieren zu bearbeiten.
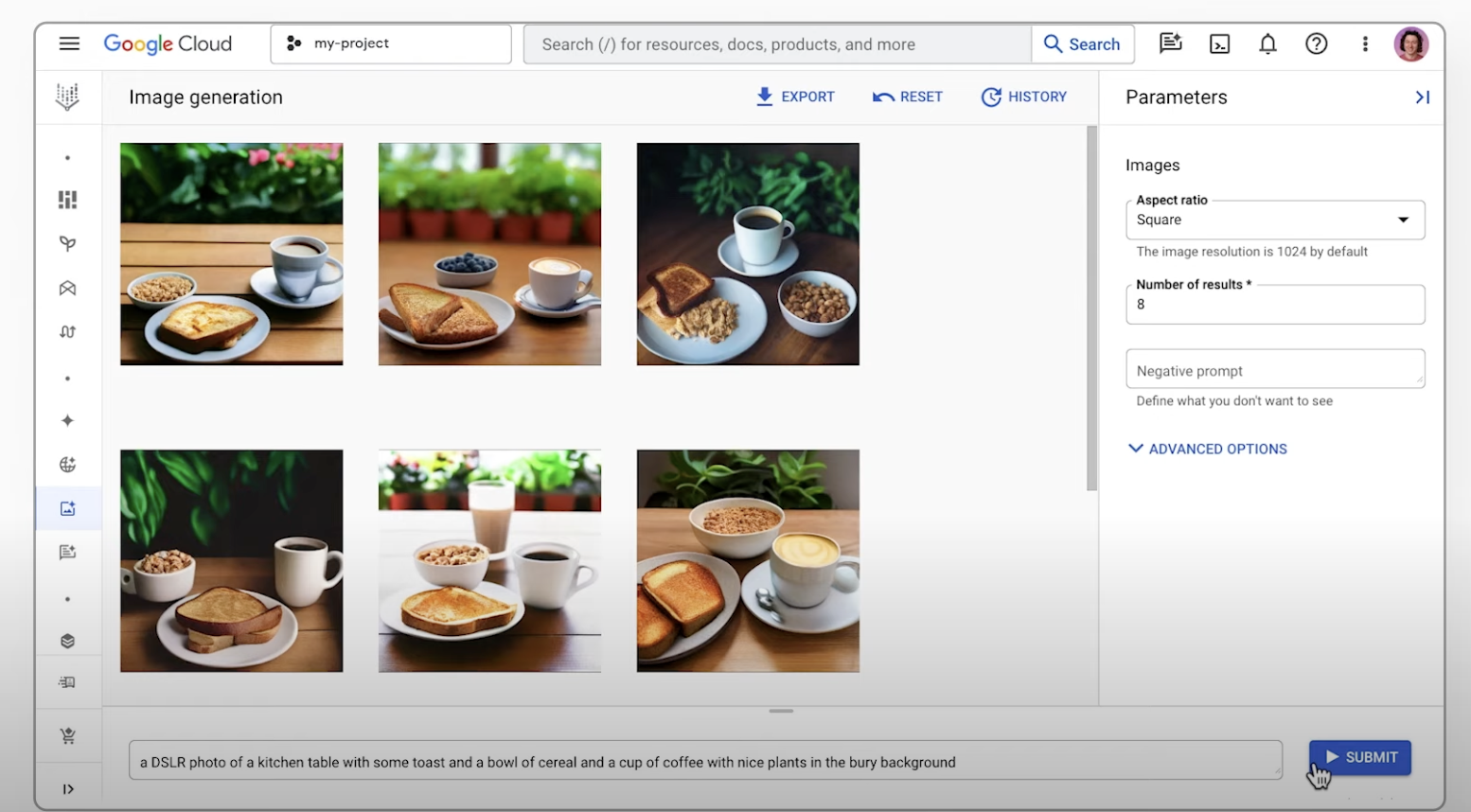
Mit KI Bilder generieren
Bilder mithilfe von Text-Prompts erstellen
Erfahren Sie, wie Sie das Feature zur Text-zu-Bild-Generierung von Imagen in Agent Platform verwenden und eine erweiterte Version eines generierten Bildes exportieren. In dieser Kurzanleitung erfahren Sie, wie Sie die Bildgenerierung von Imagen in der Google Cloud Console verwenden.

Anleitungen
Bilder mithilfe von Text-Prompts erstellen
Erfahren Sie, wie Sie das Feature zur Text-zu-Bild-Generierung von Imagen in Agent Platform verwenden und eine erweiterte Version eines generierten Bildes exportieren. In dieser Kurzanleitung erfahren Sie, wie Sie die Bildgenerierung von Imagen in der Google Cloud Console verwenden.
Bildbearbeitung mit KI
Zusammenführen mehrerer Bilder und Bearbeitung per Prompt
Mit Gemini können Sie verschiedene Bilder zu einem neuen, nahtlos wirkenden Bild kombinieren. Sie können mehrere Referenzbilder nutzen, um ein einziges, einheitliches Bild zu erstellen. Außerdem können Sie Bilder mit einfachen Anweisungen in natürlicher Sprache bearbeiten. Ob Sie eine Person aus einem Gruppenfoto entfernen oder ein kleines Detail wie einen Fleck korrigieren möchten – es geht ganz einfach per Sprachbefehl.
Außerdem können Sie mit Imagen auf der Agent Platform von Imagen generierte oder vorhandene Bilder bearbeiten. Sie können den zu bearbeitenden Teil des Bildes und eine Textbeschreibung der Änderungen angeben (maskenbasierte Bearbeitung).
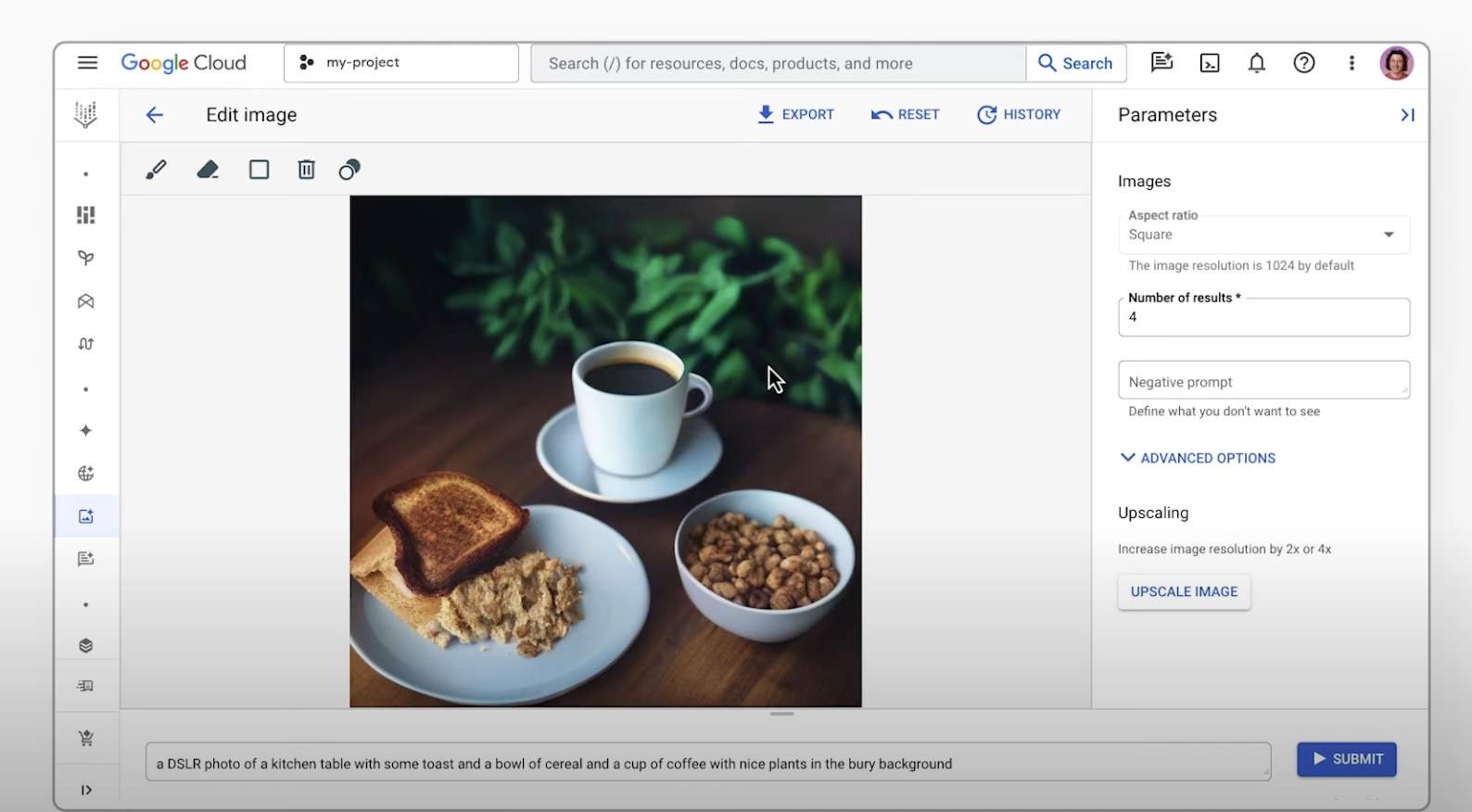
Anleitungen
Zusammenführen mehrerer Bilder und Bearbeitung per Prompt
Mit Gemini können Sie verschiedene Bilder zu einem neuen, nahtlos wirkenden Bild kombinieren. Sie können mehrere Referenzbilder nutzen, um ein einziges, einheitliches Bild zu erstellen. Außerdem können Sie Bilder mit einfachen Anweisungen in natürlicher Sprache bearbeiten. Ob Sie eine Person aus einem Gruppenfoto entfernen oder ein kleines Detail wie einen Fleck korrigieren möchten – es geht ganz einfach per Sprachbefehl.
Außerdem können Sie mit Imagen auf der Agent Platform von Imagen generierte oder vorhandene Bilder bearbeiten. Sie können den zu bearbeitenden Teil des Bildes und eine Textbeschreibung der Änderungen angeben (maskenbasierte Bearbeitung).
Visuelle Untertitel mit KI
Bildbeschreibungen mit der visuellen Untertitelung abrufen
Relevante Beschreibungen für Bilder erstellen, einschließlich detaillierter Metadaten, automatisierter Untertitel und kurzer Beschreibungen von Produkten und visuellen Assets.
Anleitungen
Bildbeschreibungen mit der visuellen Untertitelung abrufen
Relevante Beschreibungen für Bilder erstellen, einschließlich detaillierter Metadaten, automatisierter Untertitel und kurzer Beschreibungen von Produkten und visuellen Assets.











