Text-to-image AI
Create and edit images from text without writing a single line of code
Generate and edit images from text descriptions in seconds using Gemini 3 Pro Image and Imagen image generation models with available APIs in Python, Java, and Go programming languages.
New customers get up to $300 in free credits to generate images and more on Gemini Enterprise Agent Platform.
Overview
What is text-to-image AI?
Text-to-image AI is a type of artificial intelligence that can generate and edit images from text descriptions. This technology has the potential to transform how we interact with and create visual content. Google Cloud text-to-AI tools and resources, including pre-trained AI models like Imagen, Gemini 3 Pro Image, and Veo, available in Agent Platform, are designed to help developers easily implement text-to-image generation in their applications.
How is text-to-image used in application development?
Text-to-image AI can be used in application development to generate mockups, prototypes, illustrations, test data, educational content, and visualizations for debugging. Google Cloud's Agent Platform and Cloud Vision API giving developers access to a suite of image processing capabilities, including text detection, object detection, and image classification. Document AI can be used to extract text from scanned documents to generate text description images.
How can I use these Google models?
You can access these text-to-image AI models through Agent Platform on Google Cloud or Google AI Studio. To use the models, just provide a text prompt, select parameters (some models allow you to select parameters that control the style, creativity, and accuracy of the generated image) and finally generate the image.
How It Works
Text-to-image AI uses natural language processing (NLP) to convert the text description into a machine-readable format. Once converted into a machine-readable format, the machine learning model is trained on a massive dataset of text and images, learns to identify patterns, and to uses them to generate or edit images.
Text-to-image AI uses natural language processing (NLP) to convert the text description into a machine-readable format. Once converted into a machine-readable format, the machine learning model is trained on a massive dataset of text and images, learns to identify patterns, and to uses them to generate or edit images.
Generate images using AI
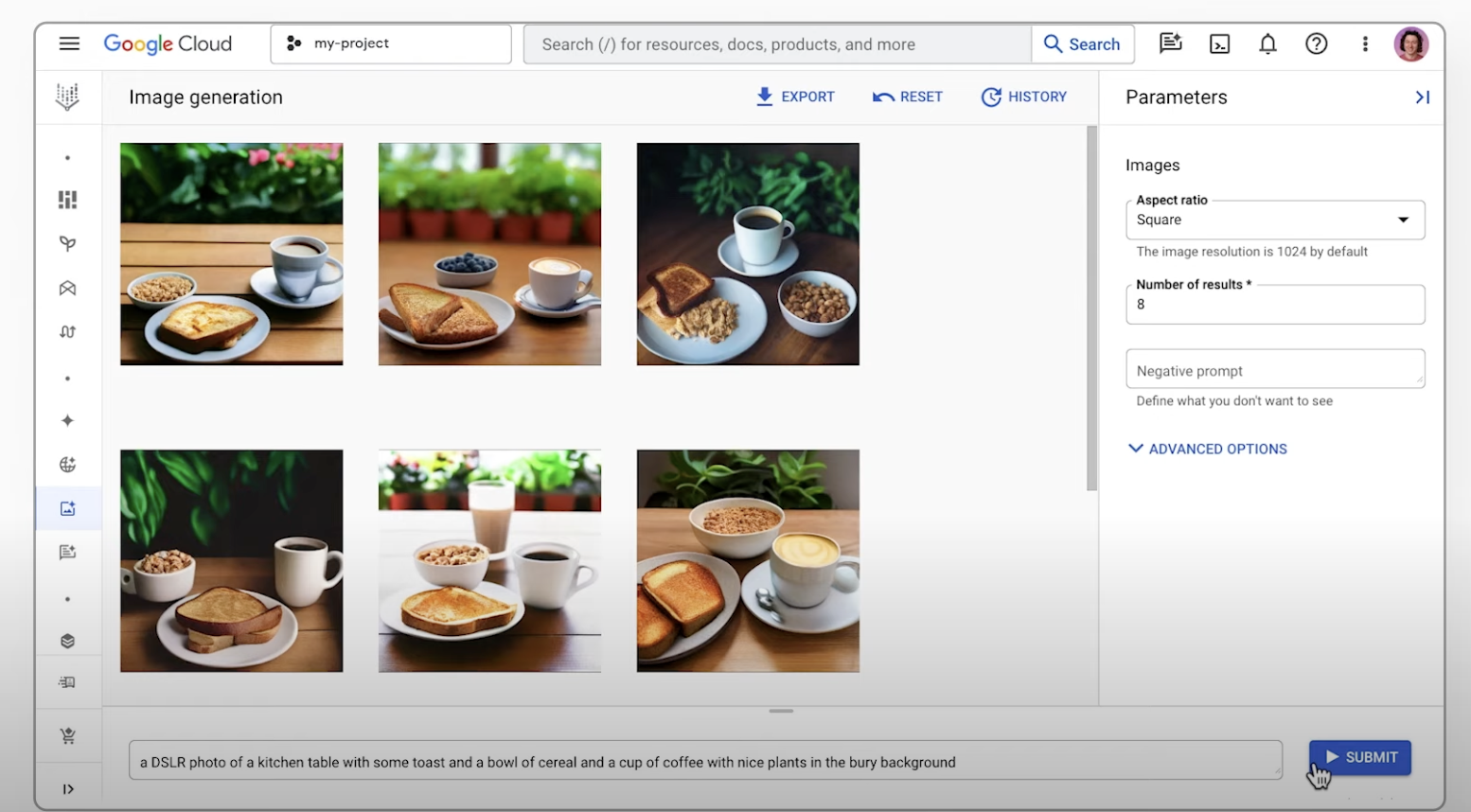
Generate images using text prompts
Learn how to use the text-to-image generation feature of Imagen on Agent Platform and export an upscaled version of a generated image. This quickstart shows you how to use Imagen image generation in the Google Cloud console.

How-tos
Generate images using text prompts
Learn how to use the text-to-image generation feature of Imagen on Agent Platform and export an upscaled version of a generated image. This quickstart shows you how to use Imagen image generation in the Google Cloud console.
Edit images with AI
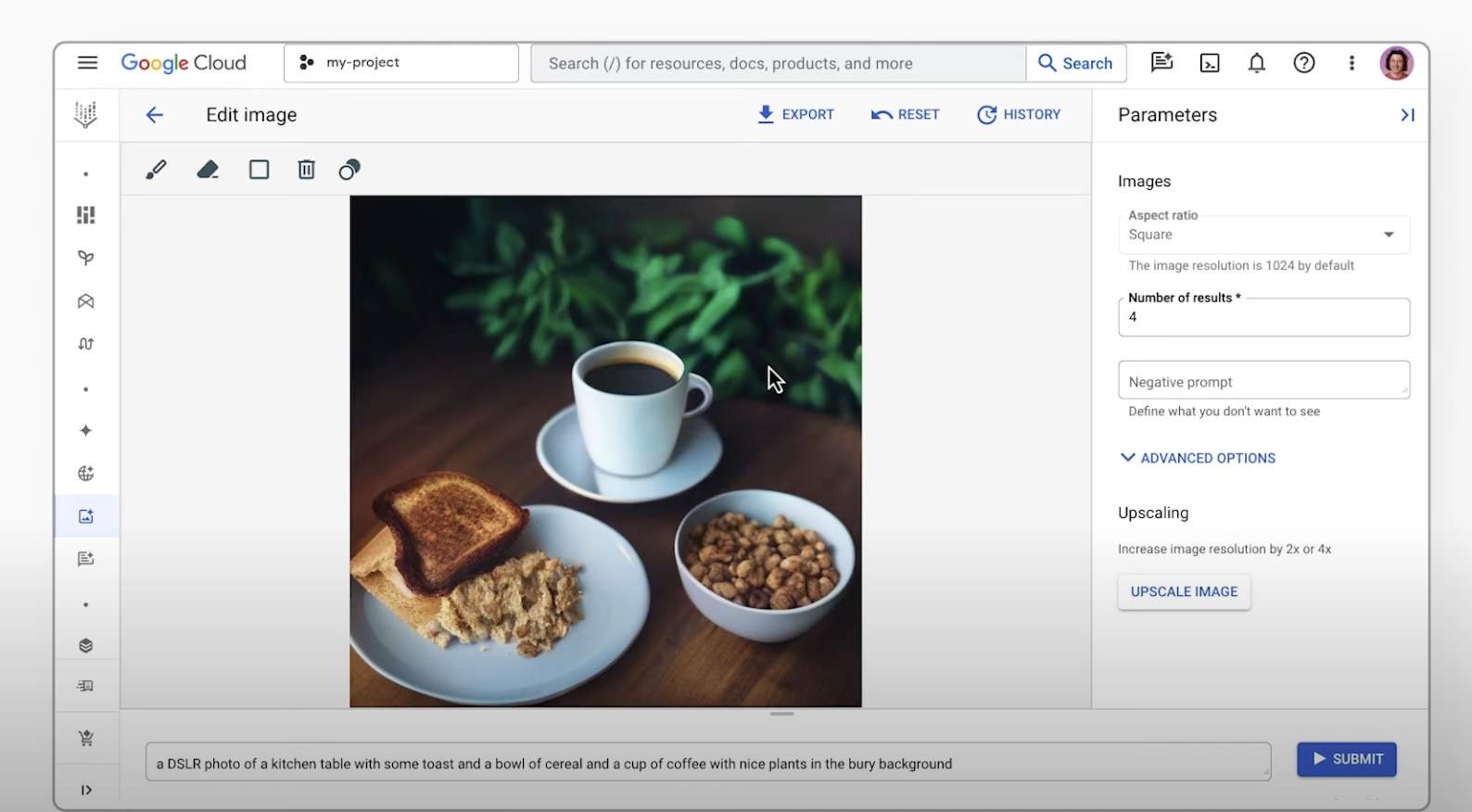
Multi-image fusion and conversational editing
With Gemini you can combine different images into one seamless new visual. Use multiple reference images to create a single, unified image. You can also edit images with simple, natural language instructions. From removing a person from a group photo to fixing a small detail like a stain, you can make changes through a simple conversation.
Additionally, Imagen on Agent Platform lets you edit Imagen-generated or existing images. You can specify part of the image to modify in addition to a text description of the updates (mask-base editing)
How-tos
Multi-image fusion and conversational editing
With Gemini you can combine different images into one seamless new visual. Use multiple reference images to create a single, unified image. You can also edit images with simple, natural language instructions. From removing a person from a group photo to fixing a small detail like a stain, you can make changes through a simple conversation.
Additionally, Imagen on Agent Platform lets you edit Imagen-generated or existing images. You can specify part of the image to modify in addition to a text description of the updates (mask-base editing)
Visual captioning with AI
Get image descriptions using visual captioning
Generate relevant descriptions for images, including detailed metadata, automated captioning, and quick descriptions of products and visual assets.
How-tos
Get image descriptions using visual captioning
Generate relevant descriptions for images, including detailed metadata, automated captioning, and quick descriptions of products and visual assets.


















