什麼是檢索增強生成 (RAG) 技術?
RAG 是「檢索增強生成」的簡稱,這是一種 AI 架構,結合傳統資訊檢索系統 (如搜尋和資料庫) 的優勢,以及生成式大型語言模型 (LLM) 的功能。如果將您的資料和世界知識與 LLM 語言技術加以結合,根據基準生成的內容就會較為準確,資訊也會是最新的,而且更切合您的特定需求。歡迎參閱這本電子書,瞭解如何讓「企業真相」發揮價值。
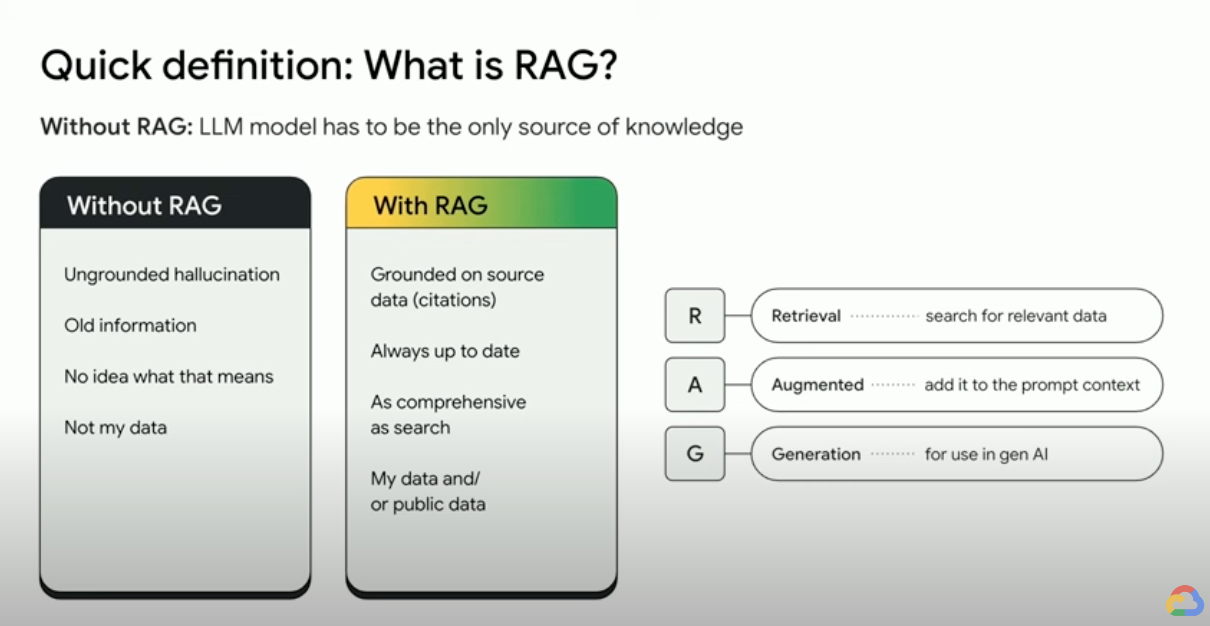
檢索增強生成 (RAG) 技術如何運作?
RAG 會採取幾個主要步驟,提升生成式 AI 輸出內容的品質:
- 檢索及預先處理:RAG 會運用強大的搜尋演算法來查詢外部資料,例如網頁、知識庫和資料庫。完成擷取作業後,系統就會開始預先處理相關資訊,包括斷詞、分析詞幹,以及移除非檢索用字。
- 根據基準生成內容:接著,經過預先處理的檢索資訊便能順暢整合至預先訓練的 LLM。這項整合流程可增強 LLM 的脈絡理解能力,更全面地瞭解主題。一旦脈絡理解能力提升,LLM 就能生成更精確、實用且引人入勝的回覆。
為什麼要使用 RAG?
RAG 具備許多優勢,能強化傳統文字生成方法,在處理事實資訊或資料導向回應方面的表現特別出色。以下是建議使用 RAG 的幾個主要原因:
存取最新資訊
LLM 受限於預先訓練的資料,也許會提供過時或可能不準確的回覆,但 RAG 可為 LLM 提供最新資訊,藉此克服這個問題。
以事實建立基準
LLM 是一項功能強大的工具,可以生成具創意且吸引人的文字,但這類模型有時無法確保輸出內容符合事實,因為 LLM 是以大量文字資料訓練而成,而這些資料可能含有錯誤資訊或有偏誤。
在輸入提示中提供「事實」資料給 LLM,有助於減少「生成式 AI 幻覺」。這個做法的關鍵在於確保 LLM 取得最相關的事實,並根據這些事實提供 LLM 輸出內容,同時回答使用者的問題,並遵照系統指示和安全限制。
Gemini 的長脈絡窗口 (LCW) 相當方便,可用來提供來源資料給 LLM。如果要提供的資訊量超出 LCW 的容納範圍,或是必須提高效能,您可以使用 RAG 來縮減詞元數量,省時又省錢。
使用向量資料庫和關聯性重新排名工具打造搜尋體驗
RAG 通常會透過搜尋來檢索事實,而新型搜尋引擎現在則是運用向量資料庫,以有效率的方式檢索相關文件。向量資料庫會將文件以嵌入形式儲存在一個高維度空間中,以便根據語意相似度快速而準確地檢索內容。多模態嵌入可用於圖像、音訊和影片等內容,而且這些媒體嵌入可與文字嵌入或多語言嵌入一起檢索。
Gemini Enterprise Agent Platform 的 Agent Search 等進階搜尋引擎會同時使用語意搜尋和關鍵字搜尋 (稱為「混合搜尋」),並透過重新排名工具為搜尋結果評分,確保系統傳回內容時,排在前面的是最相關的結果。此外,如果查詢內容明確、有重點且沒有錯別字,搜尋成效會更好。因此,精密的搜尋引擎會先轉換查詢內容並修正拼寫錯誤,再執行查詢。
關聯性、準確度和品質
RAG 的檢索機制極其重要。您需要的是語意搜尋功能以精選知識庫為基礎,發揮最佳成效,確保擷取的資訊與輸入的查詢或情境密切相關。如果擷取的資訊不相關,生成的內容可能有所根據,但卻已離題或不正確。
RAG 會透過微調或提示工程,讓 LLM 完全根據擷取的知識生成文字,這麼做有助於減少生成文字的矛盾和不一致情況,進而大幅提升生成文字的品質及使用者體驗。
Gemini Enterprise Agent Platform 的模型評估服務現可針對「連貫性」、「流暢度」、「實證性」、「安全性」、「指令遵循情形」和「問題回答品質」等指標,為 LLM 生成的文字和擷取的片段評分。這些指標可協助您評估 LLM 根據基準生成的文字 (部分指標會與您提供的基準真相答案進行比較)。導入這些評估機制後,您就能取得基準評估結果,並採取下列行動來提升 RAG 品質:設定搜尋引擎、整理來源資料、改良來源版面配置剖析或分塊策略,或是在搜尋前修正使用者的問題。採用這類指標導向的 RAG 運作策略,有助於您進一步享有優質的 RAG 體驗並有效根據基準生成內容。
RAG、代理和聊天機器人
RAG 和基準建立功能可整合至任何需存取最新、私人或專業資料的 LLM 應用程式或代理。透過存取外部資訊,採用 RAG 技術的聊天機器人和對話型代理便可運用外部知識來提供更完整、更具參考價值且符合情境的回覆,進而改善整體使用者體驗。
運用生成式 AI 建構內容時,資料和用途是讓成品脫穎而出的關鍵。RAG 和基準建立功能可將資料導入 LLM,同時兼顧效率和擴充性。
哪些 Google Cloud 產品/服務和 RAG 有關?
下列 Google Cloud 產品與檢索增強生成 (RAG) 技術有關:
 Gemini Enterprise Agent Platform RAG 引擎這是一種資料框架,可用於開發具備脈絡資料增強功能的大型語言模型 (LLM) 應用程式,並協助執行檢索增強生成作業。
Gemini Enterprise Agent Platform RAG 引擎這是一種資料框架,可用於開發具備脈絡資料增強功能的大型語言模型 (LLM) 應用程式,並協助執行檢索增強生成作業。- Gemini Enterprise Agent Platform 的 Agent SearchAgent Search 是您的資料專屬的 Google 搜尋,提供立即可用的全代管搜尋和 RAG 建構服務。
 Gemini Enterprise Agent Platform 向量搜尋功能這個效能絕佳的向量索引服務為 Agent Search 提供強大後盾,能讓您對大量嵌入項目進行語意和混合搜尋與檢索,不僅召回率高,查詢速度也很快。
Gemini Enterprise Agent Platform 向量搜尋功能這個效能絕佳的向量索引服務為 Agent Search 提供強大後盾,能讓您對大量嵌入項目進行語意和混合搜尋與檢索,不僅召回率高,查詢速度也很快。 BigQuery可用來訓練機器學習模型 (包括 Agent Platform 上的 Vector Search 模型) 的大型資料集。
BigQuery可用來訓練機器學習模型 (包括 Agent Platform 上的 Vector Search 模型) 的大型資料集。- Grounded Generation API您可以使用 Gemini 高精準度模式,以 Google 搜尋或內嵌事實為基準,也可以使用自己的搜尋引擎。
 AlloyDB AI在 Agent Platform 執行模型,並透過慣用的 SQL 查詢在應用程式存取模型。您可以使用 Gemini 等 Google 模型或自己的自訂模型。
AlloyDB AI在 Agent Platform 執行模型,並透過慣用的 SQL 查詢在應用程式存取模型。您可以使用 Gemini 等 Google 模型或自己的自訂模型。











