什么是检索增强生成 (RAG)?
RAG(检索增强生成)是一种 AI 框架,将传统信息检索系统(例如搜索和数据库)的优势与生成式大语言模型 (LLM) 的功能相结合。通过将您的数据和世界知识与 LLM 语言技能相结合,接地输出更准确、更及时,并且与您的具体需求相关。请阅读此电子书,挖掘您的“企业真实数据”。
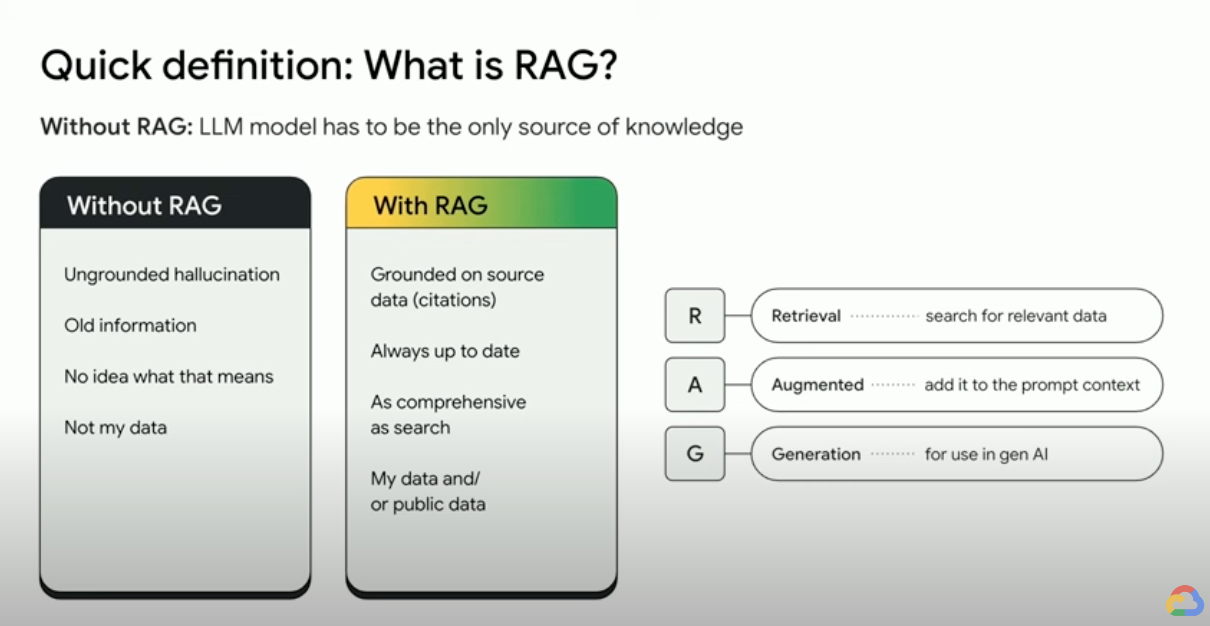
检索增强生成是如何工作的?
RAG 通过几个主要步骤来帮助增强生成式 AI 输出:
- 检索和预处理:RAG 利用强大的搜索算法查询外部数据,例如网页、知识库和数据库。检索完毕后,相关信息会进行预处理,包括标记化、词干提取和停用词移除。
- 接地输出:经过预处理的检索到的信息接着会无缝整合到预训练的 LLM 中。此整合增强了 LLM 的上下文,使其能够更全面地理解主题。这种增强的上下文使 LLM 能够生成更精确、更翔实且更具吸引力的回答。
为什么使用 RAG?
RAG 在传统文本生成方法的基础上增添了多项优势,尤其是在处理事实信息或数据驱动型回答时。以下是使用 RAG 技术的一些主要优势:
获取最新信息
大型语言模型 (LLM) 的知识来源于预训练数据,这使得它们容易给出过时甚至不准确的答案。而 RAG 技术通过为 LLM 提供实时更新的信息,有效克服了这一局限性。
事实依据
LLM 是生成富有创意且引人入胜的文本的强大工具,但有时它们在事实准确性方面会力不从心。这是因为 LLM 是使用大量文本数据训练的,其中可能包含不准确的信息或存在偏差的信息。
将“事实”作为输入提示的一部分提供给 LLM 可以减轻“生成式 AI 幻觉”。这种方法的关键是确保向 LLM 提供最相关的事实,并确保 LLM 输出完全基于这些事实,同时还要回答用户的问题并遵循系统指令和安全限制。
使用 Gemini 的长上下文窗口 (LCW) 是向 LLM 提供源材料的绝佳方式。如果您需要提供的详细信息超出了 LCW 的限制,或者您需要提高性能,可以使用 RAG 方法来减少 token 的数量,从而节省时间和费用。
使用向量数据库和相关性重新排名算法进行搜索
RAG 通常通过搜索检索事实,而现代搜索引擎现在利用矢量数据库来高效检索相关文档。矢量数据库将文档作为嵌入存储在高维空间中,允许基于语义相似度快速、准确地进行检索。多模态嵌入可用于处理图片、音频和视频等内容,这些媒体嵌入可与文本嵌入或多语言嵌入一起检索。
Vertex AI Search 等高级搜索引擎同时使用语义搜索和关键字搜索(称为混合搜索),并使用重新排名工具对搜索结果进行评分,以确保返回的首页结果具有最高相关性。此外,如果查询内容清晰、简洁且无拼写错误,搜索效果会更好;因此,在查找之前,先进的搜索引擎会转换查询并更正拼写错误。
相关性、准确性和质量
RAG 中的检索机制至关重要。您需要在精选的知识库之上使用最佳的语义搜索,以确保检索到的信息与输入的查询或上下文相关。如果您检索的信息不相关,生成的内容可能接地,但与主题无关或不正确。
RAG 通过微调或提示工程来优化 LLM,使其完全基于检索到的知识来生成文本,从而有助于最大限度地减少所生成文本中的矛盾和不一致之处。这大大提高了生成文本的质量,并改善了用户体验。
Vertex Eval Service 现在可以根据“连贯性”“流畅性”“接地性”“安全性”“指令遵从”“问题回答质量”等指标对 LLM 生成的文本和检索的段落进行评分。这些指标可帮助您衡量从 LLM 中获得的接地文本(对于某些指标,是与您提供的标准答案进行比较)。实施这些评估可为您提供基准测量结果,您可以通过配置搜索引擎、精选来源数据、改进来源布局解析或分块策略,或者在搜索之前优化用户的问题,从而优化 RAG 质量。这种 RAG Ops 指标驱动型方法将帮助您通过不断优化实现高质量的 RAG 和接地输出。
RAG、智能体和聊天机器人
RAG 和接地可集成到任何需要访问新鲜、私有或专业数据的大型语言模型 (LLM) 应用或智能体中。通过访问外部信息,由 RAG 提供支持的聊天机器人和对话代理可以利用外部知识提供更加全面、翔实和上下文内容感知的回答,从而改善整体用户体验。
您使用生成式 AI 构建的内容取决于您的数据和应用场景。RAG 和接地可高效、可伸缩地将您的数据引入 LLM。
哪些 Google Cloud 产品和服务与 RAG 相关?
以下 Google Cloud 产品与检索增强生成相关:
 Vertex AI RAG 引擎用于开发上下文增强型 LLM 应用的数据框架,有助于实现检索增强生成 (RAG)。
Vertex AI RAG 引擎用于开发上下文增强型 LLM 应用的数据框架,有助于实现检索增强生成 (RAG)。- Vertex AI SearchVertex AI Search:用 Google 搜索技术赋能您的数据,开箱即用,全托管式,轻松构建搜索和 RAG 应用。
- Vertex AI Vector Search为 Vertex AI Search 提供支持的超高性能向量索引;能够以高召回率和高查询速率,从大量嵌入集合中进行语义和混合搜索和检索。
 BigQuery可用于训练包括 Vertex AI Vector Search 模型在内的多种机器学习模型的大型数据集。
BigQuery可用于训练包括 Vertex AI Vector Search 模型在内的多种机器学习模型的大型数据集。- Grounded Generation APIGemini 高保真模式,依托 Google 搜索的强大支持和内嵌的事实核查机制,确保信息准确可靠。您也可以选择接入您自己的搜索引擎,定制专属体验。
 AlloyDB AI在 Vertex AI 中运行模型,并使用熟悉的 SQL 查询在您的应用中访问这些模型。使用 Google 模型(如 Gemini)或您自己的自定义模型。
AlloyDB AI在 Vertex AI 中运行模型,并使用熟悉的 SQL 查询在您的应用中访问这些模型。使用 Google 模型(如 Gemini)或您自己的自定义模型。
补充阅读材料
通过这些资源详细了解如何使用检索增强生成。











