O que é a geração aumentada de recuperação (RAG)?
A geração aumentada por recuperação (RAG) é um framework de IA que combina os pontos fortes dos sistemas tradicionais de recuperação de informações (como pesquisa e bancos de dados) com os recursos dos modelos de linguagem grande (LLMs) generativos. Ao combinar seus dados e conhecimento do mundo com as habilidades linguísticas do LLM, a geração com base no mundo real é mais precisa, atualizada e relevante para suas necessidades específicas. Confira este e-book para descobrir a Fonte de verdade da empresa.
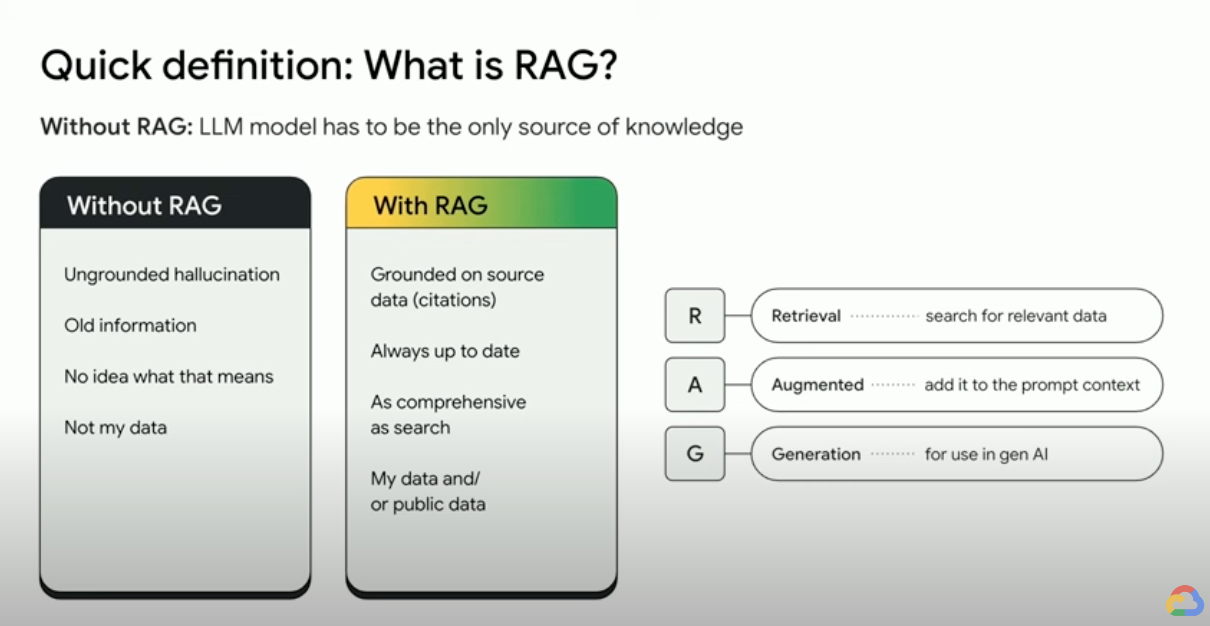
Como funciona a geração aumentada por recuperação?
As RAGs operam com algumas etapas principais para ajudar a melhorar as saídas da IA generativa:
- Recuperação e pré-processamento: as RAGs usam algoritmos de pesquisa avançados para consultar dados externos, como páginas da Web, bases de conhecimento e bancos de dados. Depois de recuperadas, as informações relevantes passam por um pré-processamento, incluindo tokenização, derivação e remoção de palavras de parada.
- Geração embasada: as informações pré-processadas recuperadas são incorporadas ao LLM pré-treinado. Essa integração melhora o contexto do LLM, oferecendo uma compreensão mais abrangente do assunto. Esse contexto aumentado permite que o LLM gere respostas mais precisas, informativas e interessantes.
Por que usar a RAG?
A RAG oferece várias vantagens em relação aos métodos tradicionais de geração de texto, especialmente ao lidar com informações factuais ou respostas baseadas em dados. Aqui estão alguns dos principais motivos pelos quais o uso da RAG pode ser benéfico:
Acesso a informações recentes
Os LLMs são limitados aos dados pré-treinados. Isso gera respostas desatualizadas e possivelmente imprecisas. A RAG supera esse problema fornecendo informações atualizadas aos LLMs.
Embasamento factual
LLMs são ferramentas poderosas para gerar textos criativos e envolventes, mas às vezes eles podem ter dificuldades com a precisão dos fatos. Isso ocorre porque os LLMs são treinados com quantidades enormes de dados de texto, que podem conter imprecisões ou vieses.
Fornecer "fatos" ao LLM como parte do comando de entrada pode reduzir as "alucinações da IA generativa". O ponto principal dessa abordagem é garantir que os fatos mais relevantes sejam fornecidos ao LLM e que a saída do LLM seja totalmente baseada nesses fatos, além de responder à pergunta do usuário e obedecer às instruções do sistema e às restrições de segurança.
Usar a janela de contexto longa (LCW) do Gemini é uma ótima maneira de fornecer materiais de origem ao LLM. Se você precisar fornecer mais informações do que cabe na LCW ou se precisar aumentar o desempenho, use uma abordagem RAG que reduza o número de tokens, economizando tempo e custos.
Pesquise com bancos de dados de vetores e reclassificadores de relevância
As RAGs geralmente recuperam fatos por meio de pesquisa, e os mecanismos de pesquisa modernos agora usam bancos de dados de vetores para recuperar documentos relevantes com eficiência. Bancos de dados vetoriais armazenam documentos como embeddings em um espaço de alta dimensão, permitindo uma recuperação rápida e precisa com base na semelhança semântica. As embeddings multimodais podem ser usadas para imagens, áudio, vídeo e muito mais, e essas embeddings de mídia podem ser recuperadas junto com embeddings de texto ou multilíngues.
Mecanismos de pesquisa avançada como a Pesquisa de agentes na Plataforma de Agentes do Gemini Enterprise usam a pesquisa semântica e a pesquisa por palavra-chave ao mesmo tempo (chamada de pesquisa híbrida) e um reclassificador que pontua os resultados da pesquisa para garantir que os primeiros resultados retornados sejam os mais relevantes. Além disso, as pesquisas têm melhor desempenho com uma consulta clara e focada, sem erros de ortografia. Por isso, antes da pesquisa, mecanismos de pesquisa sofisticados transformam uma consulta e corrigem erros ortográficos.
Relevância, precisão e qualidade
O mecanismo de recuperação no RAG é extremamente importante. Você precisa da melhor pesquisa semântica em uma base de conhecimento selecionada para garantir que as informações recuperadas sejam relevantes para a consulta ou o contexto de entrada. Se as informações recuperadas forem irrelevantes, a geração pode ser fundamentada, mas fora do assunto ou incorreta.
Ao ajustar ou fazer engenharia de comandos no LLM para gerar texto totalmente com base no conhecimento recuperado, a RAG ajuda a minimizar contradições e inconsistências no texto gerado. Isso melhora significativamente a qualidade do texto gerado e a experiência do usuário.
A avaliação de modelos na Plataforma de Agentes do Gemini Enterprise agora pontua o texto gerado pelo LLM e os blocos recuperados usando métricas como "coerência", "fluência", "embasamento", "segurança", "seguimento de instruções", "qualidade das respostas a perguntas" e mais. Essas métricas ajudam você a medir o texto embasado recebido do LLM (para algumas métricas, é uma comparação com uma resposta de informação empírica que você forneceu). A implementação dessas avaliações fornece uma medição de referência, e você pode otimizar a qualidade do RAG configurando seu mecanismo de pesquisa, selecionando dados de origem, melhorando a análise de layout ou estratégias de divisão de blocos ou refinando a pergunta do usuário antes da pesquisa. Uma abordagem de RAG Ops e métricas como essa vai ajudar você a alcançar um RAG de alta qualidade e uma geração fundamentada.
RAGs, agentes e chatbots
A RAG e o embasamento podem ser integrados a qualquer aplicativo ou agente de LLM que precise de acesso a dados novos, privados ou especializados. Ao acessar informações externas, os chatbots e agentes de conversação com a tecnologia RAG utilizam o conhecimento externo para fornecer respostas mais abrangentes, informativas e contextuais, melhorando a experiência geral do usuário.
Seus dados e seu caso de uso são o que diferencia o que você está criando com a IA generativa. A RAG e o embasamento levam seus dados aos LLMs de maneira eficiente e escalonável.
Quais produtos e serviços do Google Cloud estão relacionados à RAG?
Os produtos do Google Cloud a seguir estão relacionados à geração aumentada por recuperação:
 Mecanismo RAG da plataforma de agentes do Gemini EnterpriseFramework de dados para desenvolver aplicativos de LLM ampliados por contexto e para facilitar a geração aumentada de recuperação.
Mecanismo RAG da plataforma de agentes do Gemini EnterpriseFramework de dados para desenvolver aplicativos de LLM ampliados por contexto e para facilitar a geração aumentada de recuperação.- Pesquisa de agentes na plataforma de agentes do Gemini EnterpriseO Agente para Pesquisa é o Pesquisa Google para seus dados, uma ferramenta de pesquisa e criação de RAG totalmente gerenciada e pronta para uso.
 Pesquisa de vetor na plataforma de agentes do Gemini EnterpriseO índice de vetores de alto desempenho que alimenta o Agente para Pesquisa. Ele permite a pesquisa e a recuperação semânticas e híbridas de grandes coleções de embeddings com alta recuperação e taxa de consulta.
Pesquisa de vetor na plataforma de agentes do Gemini EnterpriseO índice de vetores de alto desempenho que alimenta o Agente para Pesquisa. Ele permite a pesquisa e a recuperação semânticas e híbridas de grandes coleções de embeddings com alta recuperação e taxa de consulta. BigQueryGrandes conjuntos de dados que podem ser usados para treinar modelos de machine learning, incluindo modelos para a pesquisa vetorial na Agent Platform.
BigQueryGrandes conjuntos de dados que podem ser usados para treinar modelos de machine learning, incluindo modelos para a pesquisa vetorial na Agent Platform.- API Grounded GenerationModo de alta fidelidade do Gemini com base na Pesquisa Google ou fatos inline ou traga seu próprio mecanismo de pesquisa.
 IA do AlloyDBExecute modelos na plataforma de agentes e acesse-os no aplicativo usando consultas SQL conhecidas. Use modelos do Google, como o Gemini ou seus próprios modelos personalizados.
IA do AlloyDBExecute modelos na plataforma de agentes e acesse-os no aplicativo usando consultas SQL conhecidas. Use modelos do Google, como o Gemini ou seus próprios modelos personalizados.
Leitura adicional
Saiba mais sobre como usar a geração aumentada de recuperação com esses recursos.
- RAGs com a tecnologia do Pesquisa Google
- RAG com bancos de dados no Google Cloud
- APIs para criar seus próprios sistemas de busca de Geração Aumentada de Recuperação (RAG, na sigla em inglês)
- Como usar a RAG no BigQuery para melhorar LLMs
- Amostra de código e guia de início rápido para se familiarizar com a RAG
- Infraestrutura para um aplicativo de IA generativa com capacidade para RAG usando o GKE
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos, tudo isso sem custo financeiro.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











