¿Qué es la generación aumentada de recuperación (RAG)?
La generación aumentada por recuperación (RAG) es un framework de inteligencia artificial que combina las ventajas de los sistemas tradicionales de recuperación de información (como la búsqueda y las bases de datos) con las capacidades de los modelos generativos de lenguaje extenso (LLM). Al combinar tus datos y el conocimiento del mundo con las habilidades lingüísticas de los LLMs, la generación fundamentada es más precisa, actualizada y relevante para tus necesidades específicas. Echa un vistazo a este libro electrónico para descubrir la evidencia empresarial.
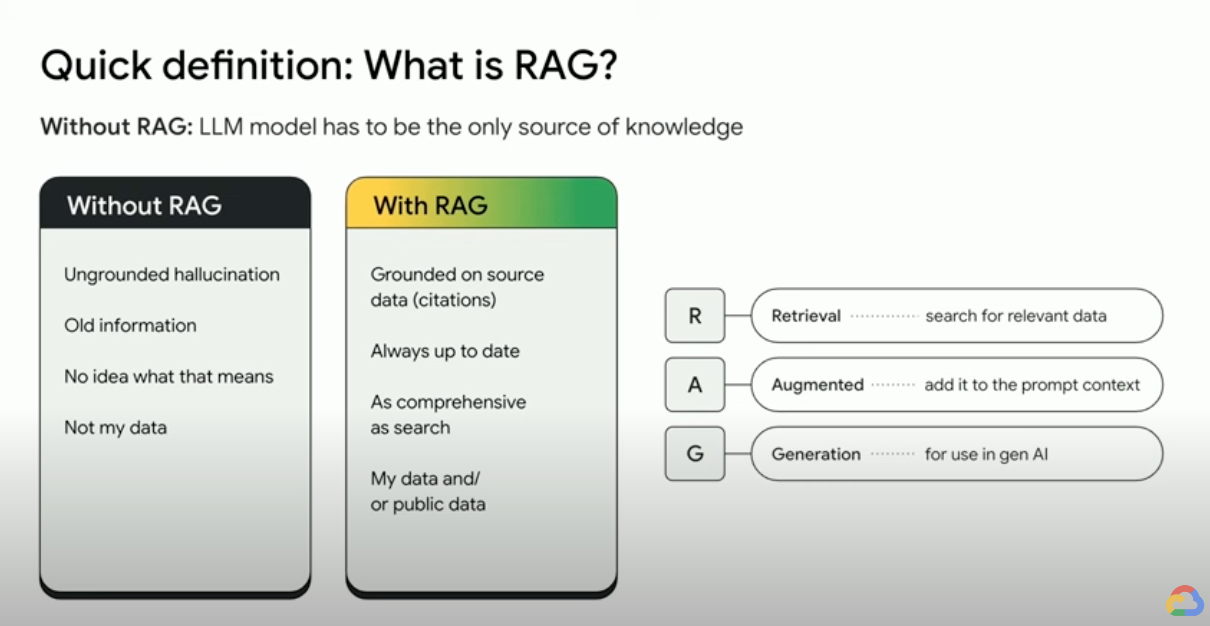
¿Cómo funciona la generación aumentada por recuperación?
Las RAG siguen una serie de pasos principales para mejorar los resultados de la IA generativa:
- Recuperación y preprocesamiento: las RAG utilizan potentes algoritmos de búsqueda para hacer consultas a datos externos, como páginas web, bases de conocimientos y bases de datos. Una vez obtenida, la información pertinente se somete a un procesamiento previo, lo que incluye la tokenización, la raíz y la eliminación de las palabras irrelevantes.
- Generación fundamentada: la información obtenida previamente se incorpora sin problemas al LLM entrenado previamente. Esta integración mejora el contexto del LLM, lo que proporciona una comprensión más completa del tema. Este contexto mejorado permite a los LLMs generar respuestas más precisas, informativas y atractivas.
¿Por qué utilizar RAG?
RAG ofrece varias ventajas sobre los métodos tradicionales de generación aumentada, especialmente cuando se trata de información factual o respuestas basadas en datos. A continuación se presentan algunas razones clave por las que el uso de RAG puede resultar beneficioso:
Acceso a información actualizada
Los LLMs se limitan a sus datos previamente entrenados. Esto da lugar a respuestas obsoletas y potencialmente inexactas. RAG supera este problema proporcionando información actualizada a los LLMs.
Fundamentos fácticos
Los LLM son herramientas poderosas para generar textos creativos y atractivos, pero a veces pueden tener dificultades con la precisión de los hechos. Esto se debe a que los LLM se entrenan con cantidades masivas de datos de texto, que pueden contener imprecisiones o sesgos.
Proporcionar "datos" al LLM como parte de la petición de entrada puede mitigar las "alucinaciones de la IA generativa". La clave de este enfoque es asegurar que se proporcionan los datos más relevantes al LLM y que la salida del LLM se basa completamente en esos datos, a la vez que responde a la pregunta del usuario y cumple las instrucciones del sistema y las restricciones de seguridad.
Usar la ventana de contexto largo (LCW) de Gemini es una forma excelente de proporcionar materiales de origen al LLM. Si necesitas proporcionar más información de la que cabe en la LCW o si necesitas aumentar el rendimiento, puedes usar un enfoque de RAG que reducirá el número de tokens, lo que te ahorrará tiempo y dinero.
Busca con bases de datos de vectores y reclasificadores de relevancia
Las RAGs suelen obtener datos mediante búsquedas, y los buscadores modernos ahora utilizan bases de datos de vectores para recuperar documentos relevantes de forma eficiente. Las bases de datos vectoriales almacenan documentos como incrustaciones en un espacio de gran tamaño, lo que permite obtener datos de forma rápida y precisa basándose en la similitud semántica. Las incrustaciones multimodales se pueden usar en imágenes, audio, vídeo y más, y se pueden recuperar junto con incrustaciones de texto o multilingües.
Los buscadores avanzados, como Agent Search en Gemini Enterprise Agent Platform, usan la búsqueda semántica y la búsqueda por palabras clave a la vez (búsqueda híbrida), y un reclasificador que asigna una puntuación a los resultados de búsqueda para que los primeros resultados devueltos sean los más relevantes. Además, los resultados de las búsquedas son mejores si la consulta es clara y específica, y no contiene errores ortográficos. Por eso, antes de hacer la búsqueda, los buscadores sofisticados transforman la consulta y corrigen los errores ortográficos.
Pertinencia, precisión y calidad
El mecanismo de recuperación en la RAG es de vital importancia. Necesitas la mejor búsqueda semántica junto con una base de conocimientos seleccionada para asegurarte de que la información obtenida sea pertinente para la consulta de entrada o el contexto. Si la información que has obtenido es irrelevante, es posible que la respuesta que hayas generado sea correcta pero no tenga nada que ver con la pregunta o sea incorrecta.
Al ajustar o hacer ingeniería de peticiones en el LLM para que genere texto basándose únicamente en los conocimientos obtenidos, RAG ayuda a minimizar las contradicciones y las incoherencias en el texto generado. Esto mejora significativamente la calidad del texto generado y la experiencia de usuario.
La evaluación de modelos en Gemini Enterprise Agent Platform ahora puntúa el texto generado por el LLM y los fragmentos recuperados en métricas como "coherencia", "fluidez", "fundamentación", "seguridad", "cumplimiento_de_instrucciones", "calidad_de_respuesta_a_preguntas", etc. Estas métricas te ayudan a medir el texto fundamentado que obtienes del LLM (en el caso de algunas métricas, se trata de una comparación con una respuesta validada en el terreno que has proporcionado). Al implementar estas evaluaciones, obtienes una medida de referencia y puedes optimizar la calidad de las respuestas automáticas configurando tu buscador, seleccionando tus datos de origen, mejorando las estrategias de análisis o segmentación del diseño de la fuente o perfilando la pregunta del usuario antes de que haga la búsqueda. Un enfoque de operaciones de RAG basado en métricas como este te ayudará a conseguir un RAG y una generación fundamentada de alta calidad.
RAGs, agentes y bots de chat
La RAG y la fundamentación se pueden integrar en cualquier aplicación o agente de LLM que necesite acceder a datos nuevos, privados o especializados. Al acceder a información externa, los bots de chat y los agentes conversacionales basados en RAG aprovechan el conocimiento externo para ofrecer respuestas más completas, informativas y contextuales, lo que mejora la experiencia general de los usuarios.
Tus datos y tu caso práctico son los que diferencian lo que estás creando con la IA generativa. RAG y la fundamentación te permiten llevar tus datos a los LLMs de forma eficiente y escalable.
¿Qué productos y servicios de Google Cloud están relacionados con la función RAG?
Los siguientes productos de Google Cloud están relacionados con la generación aumentada de recuperación:
 Motor RAG de Gemini Enterprise Agent PlatformMarco de datos para desarrollar aplicaciones de LLM con contexto aumentado y que facilita la generación aumentada por recuperación.
Motor RAG de Gemini Enterprise Agent PlatformMarco de datos para desarrollar aplicaciones de LLM con contexto aumentado y que facilita la generación aumentada por recuperación.- Búsqueda de agentes en Gemini Enterprise Agent PlatformAgent Search es la Búsqueda de Google para tus datos, un sistema de búsqueda y creación de RAG totalmente gestionado y listo para usarse.
 Búsqueda vectorial en Gemini Enterprise Agent PlatformEl índice de vectores de alto rendimiento que impulsa Agent Search. Permite la búsqueda y la recuperación semánticas e híbridas de enormes colecciones de incrustaciones con una alta recuperación a un alto ritmo de consultas.
Búsqueda vectorial en Gemini Enterprise Agent PlatformEl índice de vectores de alto rendimiento que impulsa Agent Search. Permite la búsqueda y la recuperación semánticas e híbridas de enormes colecciones de incrustaciones con una alta recuperación a un alto ritmo de consultas. BigQueryConjuntos de datos grandes que puedes utilizar para entrenar modelos de aprendizaje automático, incluidos los modelos para Vector Search en Agent Platform.
BigQueryConjuntos de datos grandes que puedes utilizar para entrenar modelos de aprendizaje automático, incluidos los modelos para Vector Search en Agent Platform.- API Grounded GenerationEl modo de alta fidelidad de Gemini se basa en la Búsqueda de Google o en datos insertados, o puedes usar tu propio buscador.
 AlloyDB AIEjecuta modelos en Agent Platform y accede a ellos en tu aplicación mediante consultas de SQL conocidas. Puedes usar modelos de Google, como Gemini, o tus propios modelos personalizados.
AlloyDB AIEjecuta modelos en Agent Platform y accede a ellos en tu aplicación mediante consultas de SQL conocidas. Puedes usar modelos de Google, como Gemini, o tus propios modelos personalizados.
Más información
Obtén más información sobre cómo usar la generación aumentada por recuperación con estos recursos.
- RAGs con la tecnología de la Búsqueda de Google
- RAG con bases de datos en Google Cloud
- APIs para crear tus propios sistemas de generación aumentada de recuperación (RAG)
- Cómo usar RAG en BigQuery para reforzar los LLMs
- Código de ejemplo e inicio rápido para familiarizarte con RAG
- Infraestructura para una aplicación de IA generativa compatible con RAG que use GKE
Ve un paso más allá
Empieza a crear en Google Cloud con 300 USD en crédito sin coste económico y más de 20 productos que siempre se ofrecen sin coste.
¿Necesitas ayuda para empezar?
Contactar con VentasColabora con un partner de confianza
Buscar un partnerSigue explorando
Ver todos los productos


















