Was ist Retrieval-Augmented Generation (RAG)?
RAG (Retrieval-Augmented Generation) ist ein KI-Framework, das die Stärken herkömmlicher Systeme für die Informationsbeschaffung (wie Suchmaschinen und Datenbanken) mit den Funktionen von generativen Large Language Models (LLMs) kombiniert. Durch die Kombination Ihrer Daten und Ihres Weltwissens mit den Sprachfähigkeiten von LLM ist Grounded Generation genauer, aktueller und relevanter für Ihre spezifischen Anforderungen. In diesem E-Book erfahren Sie, wie Sie Unternehmensdaten ausschöpfen.
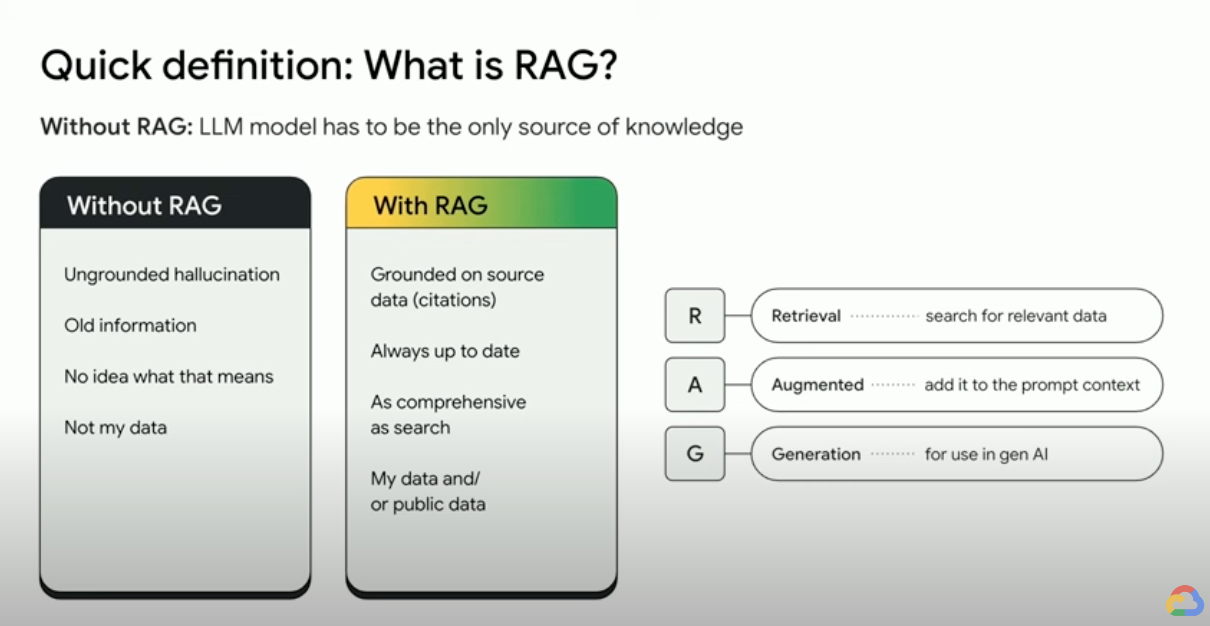
Wie funktioniert die Retrieval-Augmented Generation?
RAGs nutzen einige wichtige Schritte, um generative AI-Ausgaben zu verbessern:
- Abrufen und Vorverarbeitung: RAGs nutzen leistungsstarke Suchalgorithmen, um externe Daten wie Webseiten, Wissensdatenbanken und andere Datenbanken abzufragen. Nach dem Abruf werden die relevanten Informationen vorverarbeitet (einschließlich Tokenisierung, Wortstammfunktion und Entfernung von Stoppwörtern).
- Fundierte Generierung: Die vorverarbeiteten abgerufenen Informationen werden dann nahtlos in das vortrainierte LLM eingebunden. Durch diese Einbindung wird der Kontext des LLM erweitert, sodass es ein umfassenderes Verständnis des Themas erhält. Dieser erweiterte Kontext ermöglicht es dem LLM, präzisere, informativere und ansprechendere Antworten zu generieren.
Welche Vorteile hat der Einsatz von RAG?
RAG bietet mehrere Vorteile gegenüber herkömmlichen Methoden der Textgenerierung, insbesondere wenn es um faktische Informationen oder datengestützte Antworten geht. Hier sind einige wichtige Gründe, warum die Verwendung von RAG von Vorteil sein kann:
Zugriff auf aktuelle Informationen
LLMs sind auf ihre vortrainierten Daten beschränkt. Das führt zu veralteten und möglicherweise ungenauen Antworten. RAG überwindet dieses Problem, indem es LLMs aktuelle Informationen zur Verfügung stellt.
Faktengestützte Antworten
LLMs sind leistungsstarke Tools, um kreative und ansprechende Texte zu generieren, haben aber manchmal Probleme mit der sachlichen Richtigkeit. Das liegt daran, dass LLMs mit riesigen Mengen an Textdaten trainiert werden, die Ungenauigkeiten oder Verzerrungen enthalten können.
Wenn Sie dem LLM im Rahmen der Eingabeaufforderung „Fakten“ zur Verfügung stellen, können Sie Gen-KI-Halluzinationen vermeiden. Die Crux bei diesem Ansatz ist sicherzustellen, dass dem LLM die relevantesten Fakten bereitgestellt werden und die Ausgabe des LLMs vollständig auf diesen Fakten beruht, während gleichzeitig die Frage des Nutzers beantwortet wird und die Systemanweisungen und Sicherheitsbeschränkungen eingehalten werden.
Das große Kontextfenster (LCW) von Gemini ist eine gute Möglichkeit, dem LLM Quellenmaterial zur Verfügung zu stellen. Wenn Sie mehr Informationen bereitstellen müssen, als in das LCW passen, oder wenn Sie die Leistung steigern müssen, können Sie einen RAG-Ansatz verwenden, der die Anzahl der Tokens reduziert. So sparen Sie Zeit und Kosten.
Suche mit Vektordatenbanken und Relevanz-Neubewertungen
RAGs rufen Fakten in der Regel über die Suche ab. Moderne Suchmaschinen nutzen Vektordatenbanken, um effizient relevante Dokumente abzurufen. Vektordatenbanken speichern Dokumente als Einbettungen in einem hochdimensionalen Raum, was ein schnelles und genaues Abrufen basierend auf semantischer Ähnlichkeit ermöglicht. Multimodale Einbettungen können für Bilder, Audio, Video und andere Medien verwendet werden. Diese Medien-Einbettungen können zusammen mit Text-Einbettungen oder mehrsprachigen Einbettungen abgerufen werden.
Fortschrittliche Suchmaschinen wie Agent Search auf der Gemini Enterprise Agent Platform verwenden semantische Suche und Stichwortsuche zusammen (sogenannte hybride Suche) sowie einen Re-Ranker, der Suchergebnisse bewertet, um sicherzustellen, dass die am besten zurückgegebenen Ergebnisse die relevantesten sind. Außerdem werden Suchanfragen mit einer klaren, fokussierten Anfrage ohne Rechtschreibfehler besser ausgeführt. Daher wandeln anspruchsvolle Suchmaschinen vor der Suche eine Anfrage um und korrigieren Rechtschreibfehler.
Relevanz, Genauigkeit und Qualität
Der Abrufmechanismus in RAG ist von entscheidender Bedeutung. Sie benötigen die beste semantische Suche auf der Grundlage einer kuratierten Wissensdatenbank, um sicherzustellen, dass die abgerufenen Informationen für die Eingabeabfrage oder den Kontext relevant sind. Wenn die abgerufenen Informationen irrelevant sind, kann die Generierung zwar fundiert sein, aber vom Thema abweichen oder falsch sein.
Durch die Feinabstimmung oder das Prompt Engineering des LLM, um Text zu generieren, der vollständig auf dem abgerufenen Wissen basiert, trägt RAG dazu bei, Widersprüche und Inkonsistenzen im generierten Text zu minimieren. Dadurch wird die Qualität des generierten Textes deutlich verbessert und die Nutzerfreundlichkeit erhöht.
Die Modellbewertung in der Gemini Enterprise Agent Platform bewertet jetzt LLM-generierten Text und abgerufene Textabschnitte anhand von Messwerten wie „Kohärenz“, „Sprachfluss“, „Fundierung“, „Sicherheit“, „Anleitungsbefolgung“, „Qualität der Beantwortung von Fragen“ und mehr. Mit diesen Messwerten können Sie den fundierten Text messen, den Sie vom LLM erhalten (bei einigen Messwerten erfolgt ein Vergleich mit einer von Ihnen bereitgestellten Grundwahrheits-Antwort). Durch die Implementierung dieser Bewertungen erhalten Sie eine Baseline-Messung. Sie können die RAG-Qualität optimieren, indem Sie Ihre Suchmaschine konfigurieren, Ihre Quelldaten kuratieren, die Analyse von Quelllayouts oder Chunking-Strategien verbessern oder die Frage der Nutzer vor der Suche verfeinern. Ein RAG Ops-Ansatz, der wie dieser auf Messwerten basiert, hilft Ihnen, eine hohe Qualität der RAG und eine fundierte Generierung zu erreichen.
RAGs, Agents und Chatbots
RAG und Fundierung können in alle LLM-Anwendungen oder LLM-Agents integriert werden, die Zugriff auf aktuelle, private oder spezialisierte Daten benötigen. Durch den Zugriff auf externe Informationen helfen RAG-gesteuerte Chatbots und Konversations-Agents, externes Wissen zu nutzen, um umfassende, informative und kontextsensitive Antworten zu liefern und so die Nutzererfahrung insgesamt zu verbessern.
Ihre Daten und Ihr Anwendungsfall sind das, was Sie bei der Entwicklung mit generativer KI von anderen unterscheidet. RAG und Fundierung bringen Ihre Daten effizient und skalierbar in LLMs.
Welche Google Cloud-Produkte und -Dienste beziehen sich auf RAG?
Die folgenden Google Cloud-Produkte sind mit der Retrieval-Augmented Generation verwandt:
 RAG-Engine der Gemini Enterprise Agent PlatformDatenframework für die Entwicklung von kontextangereicherten LLM-Anwendungen und erleichtert die Retrieval-Augmented Generation.
RAG-Engine der Gemini Enterprise Agent PlatformDatenframework für die Entwicklung von kontextangereicherten LLM-Anwendungen und erleichtert die Retrieval-Augmented Generation.- Agent Search auf der Gemini Enterprise Agent PlatformAgent Search ist die Google Suche für Ihre Daten, ein vollständig verwalteter, sofort einsatzbereiter Such- und RAG-Builder.
 Vektorsuche auf der Gemini Enterprise Agent PlatformDer äußerst leistungsstarke Vektorindex, der Agent Search unterstützt, ermöglicht semantische und hybride Suchen und Abrufe aus riesigen Sammlungen von Einbettungen mit hohem Recall bei hoher Abfragerate.
Vektorsuche auf der Gemini Enterprise Agent PlatformDer äußerst leistungsstarke Vektorindex, der Agent Search unterstützt, ermöglicht semantische und hybride Suchen und Abrufe aus riesigen Sammlungen von Einbettungen mit hohem Recall bei hoher Abfragerate. BigQueryGroße Datasets, mit denen Sie Modelle für maschinelles Lernen trainieren können, einschließlich Modelle für die Vektorsuche auf der Agent-Plattform.
BigQueryGroße Datasets, mit denen Sie Modelle für maschinelles Lernen trainieren können, einschließlich Modelle für die Vektorsuche auf der Agent-Plattform.- Grounded Generation APIGemini im Modus „Hohe Genauigkeit“ mit der Google Suche oder Inline-Fakten fundieren oder eine eigene Suchmaschine verwenden.
 AlloyDB AIFühren Sie Modelle in der Agent Platform aus und greifen Sie mit vertrauten SQL-Abfragen in Ihrer Anwendung auf diese zu. Sie können Google-Modelle wie Gemini oder Ihre eigenen benutzerdefinierten Modelle verwenden.
AlloyDB AIFühren Sie Modelle in der Agent Platform aus und greifen Sie mit vertrauten SQL-Abfragen in Ihrer Anwendung auf diese zu. Sie können Google-Modelle wie Gemini oder Ihre eigenen benutzerdefinierten Modelle verwenden.
Weitere Informationen
In diesen Ressourcen erfahren Sie mehr über RAG (Retrieval-Augmented Generation).
- RAGs powered by Google Search technology
- RAG mit Datenbanken in Google Cloud
- APIs zum Erstellen eigener Such- und RAG-Systeme (Retrieval Augmented Generation)
- RAG in BigQuery zur LLM-Optimierung nutzen
- Codebeispiel und Kurzanleitung, um sich mit RAG vertraut zu machen
- Infrastruktur für eine RAG-fähige generative KI-Anwendung mit GKE
Gleich loslegen
Profitieren Sie von einem Guthaben in Höhe von 300 $ und mehr als 20 immer kostenlose Produkten, um Google Cloud kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partnerunternehmen arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen


















