AI multimodal
Membuat teks, kode, video, audio, dan gambar dari hampir semua jenis konten
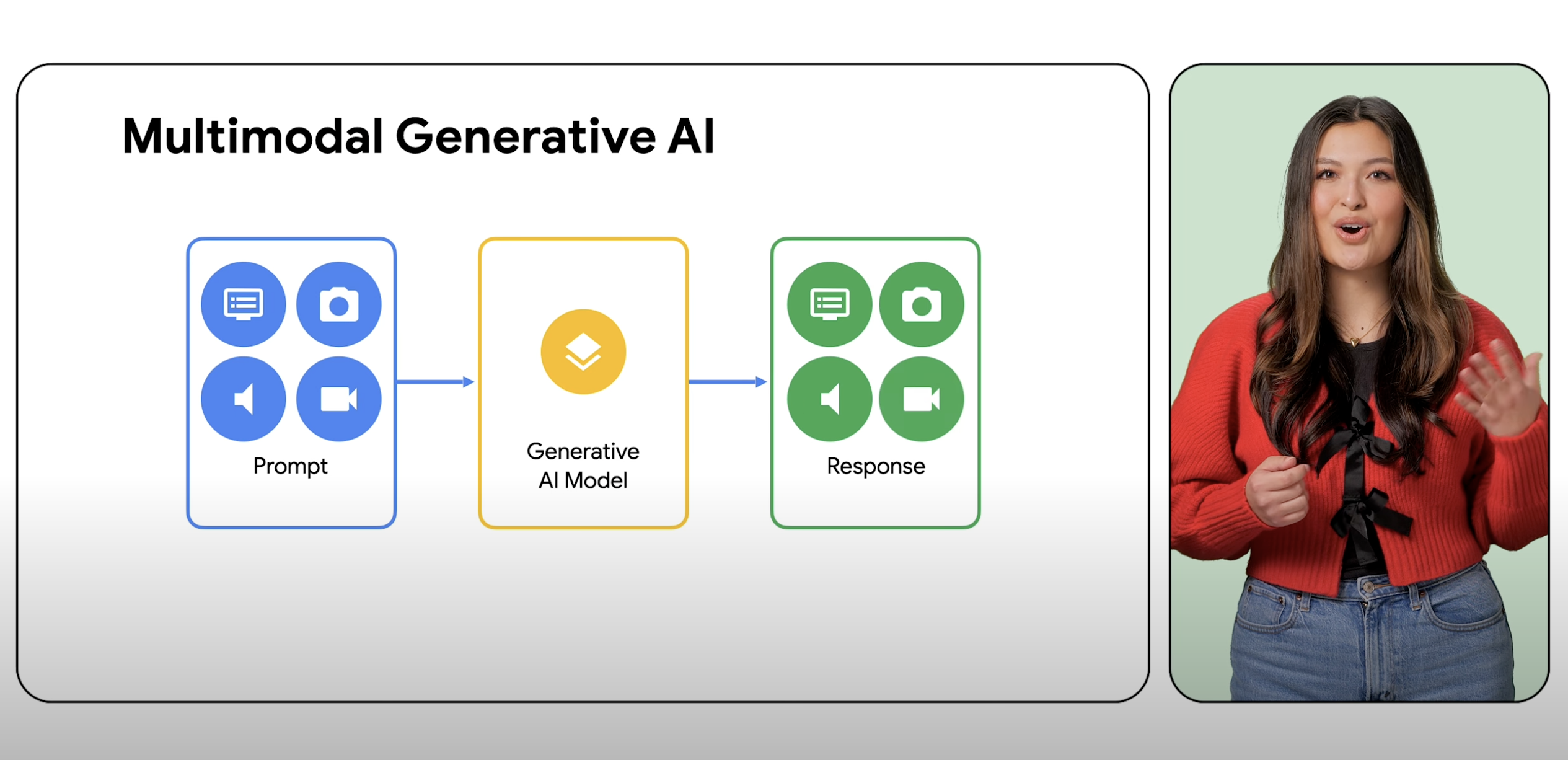
Model multimodal dapat memproses berbagai input, termasuk teks, gambar, dan audio, sebagai perintah dan mengonversi perintah tersebut menjadi berbagai output, bukan hanya jenis sumber.
Pelanggan baru mendapatkan kredit gratis senilai hingga $300 untuk mencoba model multimodal di Platform Agen Gemini Enterprise dan produk Google Cloud lainnya.

Ringkasan
Apa contoh AI multimodal?
Model multimodal adalah model ML (machine learning) yang mampu memproses informasi dari berbagai modalitas, termasuk gambar, video, dan teks. Misalnya, model multimodal Google, Gemini, dapat menerima foto sepiring kue dan menghasilkan resep tertulis sebagai respons, dan sebaliknya.
Apa perbedaan antara AI generatif dan AI multimodal?
AI Generatif adalah istilah umum penggunaan model ML untuk membuat konten baru, seperti teks, gambar, musik, audio, dan video yang biasanya berasal dari prompt satu jenis. AI multimodal memperluas kemampuan generatif ini, dengan memproses informasi dari berbagai modalitas, termasuk gambar, video, dan teks. Multimodalitas dapat dianggap sebagai kemampuan AI untuk memproses dan memahami berbagai mode sensoris. Secara praktis, hal ini berarti pengguna tidak terbatas pada satu input dan satu jenis output serta dapat meminta prompt model dengan hampir semua input untuk menghasilkan hampir semua jenis konten.
AI apa yang dapat menggunakan gambar sebagai prompt?
Gemini adalah model multimodal dari tim di Google DeepMind yang dapat diminta tidak hanya dengan gambar, tetapi juga dengan teks, kode, dan video. Gemini dirancang dari awal agar dapat berpikir dengan lancar menggunakan teks, gambar, video, audio, dan kode. Platform Agen Gemini Enterprise bahkan dapat menggunakan perintah untuk mengekstrak teks dari gambar, mengonversi teks gambar ke JSON, dan menghasilkan jawaban tentang gambar yang diupload.
Bagaimana masa depan AI multimodal dan mengapa hal ini penting?
AI multimodal dan model multimodal mewakili lompatan maju dalam cara developer membangun dan memperluas fungsi AI di aplikasi generasi berikutnya. Misalnya, Gemini dapat memahami, menjelaskan, dan menghasilkan kode berkualitas tinggi dalam bahasa pemrograman paling populer di dunia, seperti Python, Java, C++, dan Go—sehingga membebaskan developer untuk bekerja membangun lebih banyak aplikasi yang berisi fitur. Potensi AI multimodal juga membawa dunia lebih dekat dengan AI, yang tidak seperti software cerdas dan lebih seperti asisten atau asisten ahli.
Apa manfaat model multimodal dan AI multimodal?
Manfaat AI multimodal adalah menawarkan AI dengan kemampuan penalaran, pemecahan masalah, dan pembuatan yang lebih canggih kepada developer dan pengguna. Kemajuan ini menawarkan kemungkinan tak terbatas tentang bagaimana aplikasi generasi berikutnya dapat mengubah cara kita bekerja dan hidup. Bagi developer yang ingin mulai membangun solusi, Gemini Enterprise Agent Platform API menawarkan berbagai fitur seperti keamanan perusahaan, residensi data, performa, dan dukungan teknis. Pelanggan Google Cloud lama dapat mulai meminta dengan Gemini di Platform Agen saat ini.
Cara Kerjanya
Model multimodal mampu memahami dan memproses hampir semua input, menggabungkan berbagai jenis informasi, dan menghasilkan hampir semua output. Misalnya, melalui Platform Agen, pengguna dapat meminta dengan teks, gambar, video, atau kode untuk menghasilkan berbagai jenis konten dari yang dimasukkan sebelumnya.
Model multimodal mampu memahami dan memproses hampir semua input, menggabungkan berbagai jenis informasi, dan menghasilkan hampir semua output. Misalnya, melalui Platform Agen, pengguna dapat meminta dengan teks, gambar, video, atau kode untuk menghasilkan berbagai jenis konten dari yang dimasukkan sebelumnya.

Mencoba prompt multimodal
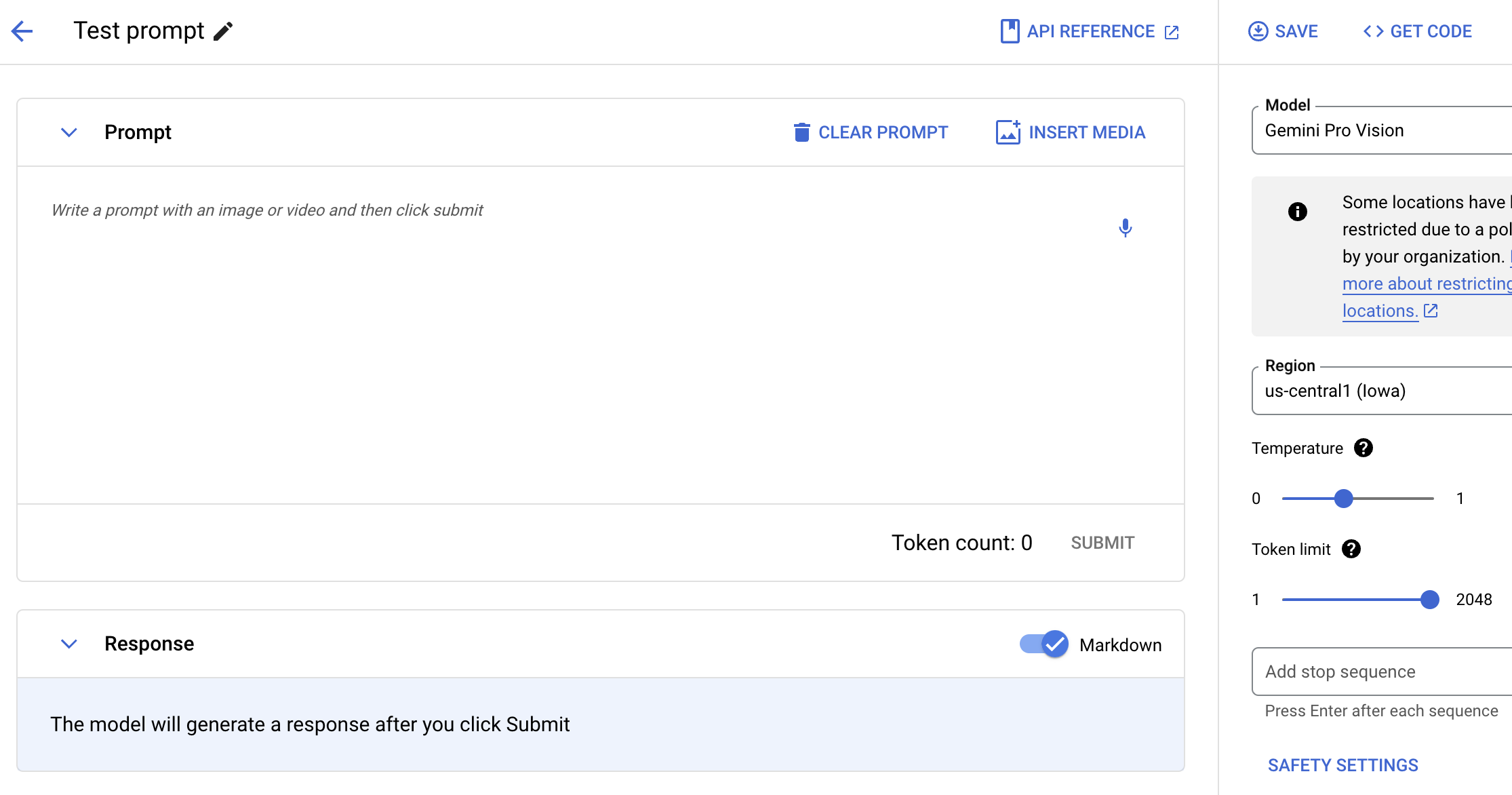
Minta prompt Gemini dengan teks, gambar, dan video
Uji model Gemini menggunakan natural language, kode, atau gambar. Coba contoh prompt untuk mengekstrak teks dari gambar, mengonversi teks gambar menjadi JSON, dan bahkan membuat jawaban tentang gambar yang diupload untuk membangun aplikasi AI generasi berikutnya.
Petunjuk
Minta prompt Gemini dengan teks, gambar, dan video
Uji model Gemini menggunakan natural language, kode, atau gambar. Coba contoh prompt untuk mengekstrak teks dari gambar, mengonversi teks gambar menjadi JSON, dan bahkan membuat jawaban tentang gambar yang diupload untuk membangun aplikasi AI generasi berikutnya.
Menggunakan model multimodal
Memulai Gemini, model multimodal Google
Dapatkan ringkasan tentang penggunaan model multimodal di Google Cloud, kekuatan dan batasan Gemini, info perintah dan permintaan, serta jumlah token.

Petunjuk
Memulai Gemini, model multimodal Google
Dapatkan ringkasan tentang penggunaan model multimodal di Google Cloud, kekuatan dan batasan Gemini, info perintah dan permintaan, serta jumlah token.


















