Diese Seite bietet eine konzeptionelle Übersicht über das Exportieren von Trace-Daten mit Cloud Trace. Trace-Daten können aus folgenden Gründen exportiert werden:
- Zum Speichern von Trace-Daten über einen längeren Aufbewahrungszeitraum als 30 Tage.
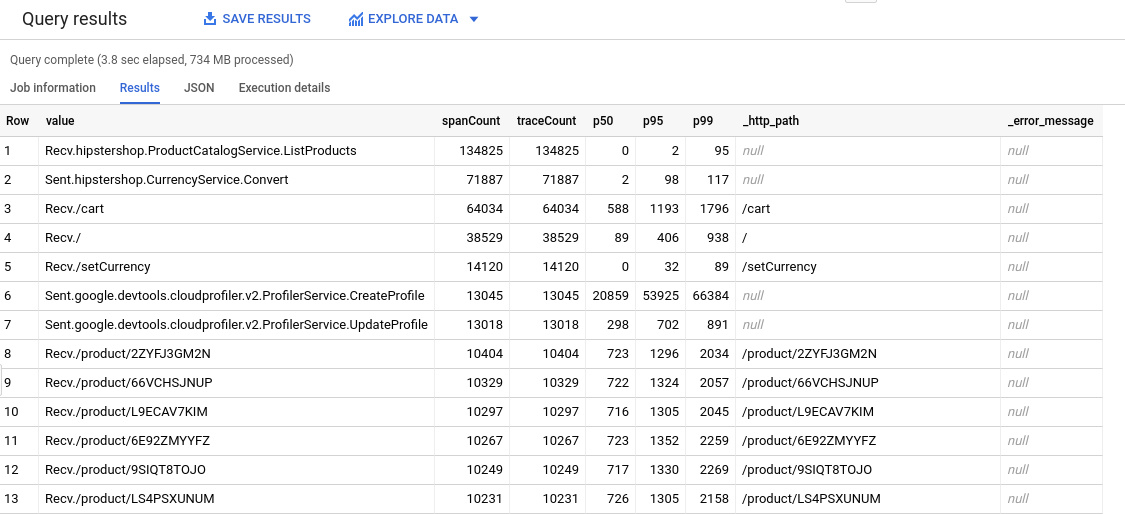
Damit Sie Trace-Daten mit BigQuery-Tools analysieren können. Mit BigQuery können Sie beispielsweise Span-Zahlen und Quantile ermitteln. Informationen zu der Abfrage, die zum Generieren der folgenden Tabelle verwendet wird, finden Sie unter HipsterShop-Abfrage.
Funktionsweise von Exporten
Beim Exportieren wird eine Senke für ein Google Cloud -Projekt erstellt. Eine Senke definiert ein BigQuery-Dataset als Ziel.
Sie können eine Senke mit der Cloud Trace API oder der Google Cloud CLI erstellen.
Senken-Properties und Terminologie
Senken werden für ein Google Cloud Projekt definiert und haben die folgenden Attribute:
Name: Der Name der Senke. Ein Name könnte beispielsweise so aussehen:
"projects/PROJECT_NUMBER/traceSinks/my-sink"
Dabei ist
PROJECT_NUMBERdie Projektnummer der Senke Google Cloud undmy-sinkdie Senken-ID.Übergeordnet: Die Ressource, in der Sie die Senke erstellen. Das übergeordnete Element muss ein Google Cloud -Projekt sein:
"projects/PROJECT_ID"
Die
PROJECT_IDkann entweder eine Google Cloud Projekt-ID oder eine Projektnummer sein.Ziel: Ein einzelner Ort, an den Trace-Spans gesendet werden. Trace unterstützt den Export von Traces nach BigQuery. Das Ziel kann das Google Cloud Projekt der Senke oder ein anderes Google Cloud Projekt in derselben Organisation sein.
Ein gültiges Ziel ist beispielsweise:
bigquery.googleapis.com/projects/DESTINATION_PROJECT_NUMBER/datasets/DATASET_ID
Dabei ist
DESTINATION_PROJECT_NUMBERdieGoogle Cloud Projektnummer des Ziels undDATASET_IDdie BigQuery-Dataset-ID.Identität des Autors: Der Name des Dienstkontos. Der Inhaber des Exportziels muss diesem Dienstkonto Berechtigungen zum Schreiben in das Exportziel erteilen. Traces wendet diese Identität beim Exportieren von Traces für die Autorisierung an. Neue Senken erhalten zur Erhöhung der Sicherheit ein eindeutiges Dienstkonto:
export-PROJECT_NUMBER-GENERATED_VALUE@gcp-sa-cloud-trace.iam.gserviceaccount.com
Dabei ist
PROJECT_NUMBERIhre Google Cloud Projektnummer in Hex undGENERATED_VALUEein zufällig generierter Wert.Sie erstellen, besitzen oder verwalten das Dienstkonto nicht, das durch die Writer-Identität einer Senke identifiziert wird. Wenn Sie eine Senke erstellen, wird das dafür erforderliche Dienstkonto von Trace erstellt. Dieses Dienstkonto wird erst in die Liste der Dienstkonten für Ihr Projekt aufgenommen, wenn es mindestens eine IAM-Bindung (Identity and Access Management) hat. Sie fügen diese Bindung hinzu, wenn Sie ein Senkenziel konfigurieren.
Informationen zur Verwendung der Identität des Autors finden Sie unter Zielberechtigungen.
Funktionsweise von Senken
Jedes Mal, wenn ein Trace-Span in einem Projekt ankommt, exportiert Trace eine Kopie des Spans.
Traces, die vor der Erstellung der Senke empfangen wurden, können nicht exportiert werden.
Zugriffsteuerung
Zum Erstellen oder Ändern einer Senke benötigen Sie eine der folgenden Rollen für die Identitäts- und Zugriffsverwaltung:
- Trace-Administrator
- Trace-Nutzer
- Projektinhaber
- Projektbearbeiter
Weitere Informationen finden Sie unter Zugriffssteuerung.
Für den Export von Traces an ein Ziel benötigt das Dienstkonto des Senkenautors Schreibzugriff auf das Ziel. Weitere Informationen zu Identitäten von Autoren finden Sie auf dieser Seite unter Senkeneigenschaften.
Kontingente und Limits
Cloud Trace verwendet die BigQuery Streaming API, um Trace-Spans an das Ziel zu senden. Cloud Trace fasst API-Aufrufe in Batches zusammen. Cloud Trace implementiert keinen Wiederholungs- oder Drosselungsmechanismus. Trace-Spans werden möglicherweise nicht erfolgreich exportiert, wenn die Datenmenge die Zielkontingente überschreitet.
Weitere Informationen zu BigQuery-Kontingenten und -Limits finden Sie unter Kontingente und Limits.
Preise
Für den Export von Traces fallen keine Cloud Trace-Kosten an. Es können jedoch Kosten für BigQuery anfallen. Weitere Informationen finden Sie unter BigQuery-Preise.
Ihre Kosten schätzen
In BigQuery fallen Gebühren für die Datenaufnahme und -speicherung an. So schätzen Sie Ihre monatlichen BigQuery-Kosten:
Schätzen Sie die Gesamtzahl der Trace-Spans, die in einem Monat aufgenommen werden.
Informationen zum Aufrufen der Nutzung finden Sie unter Nutzung nach Rechnungskonto ansehen.
Schätzen Sie die Streaminganforderungen basierend auf der Anzahl der aufgenommenen Trace-Spans.
Jeder Span wird in eine Tabellenzeile geschrieben. Jede Zeile in BigQuery benötigt mindestens 1024 Byte. Eine Untergrenze für Ihre BigQuery-Streaminganforderungen besteht daher darin, jedem Span 1024 Byte zuzuweisen. Wenn in Ihrem Google Cloud-Projekt beispielsweise 200 Spans aufgenommen wurden, benötigen diese Spans für die Streaming-Insert-Anweisung mindestens 20.400 Byte.
Mit dem Preisrechner können Sie Ihre BigQuery-Kosten aufgrund von Speicher, Streaming-Insert-Anweisungen und Abfragen schätzen.
BigQuery-Nutzung ansehen und verwalten
Die BigQuery-Nutzung können Sie mit dem Metrics Explorer einsehen. Sie können auch eine Benachrichtigungsrichtlinie erstellen, die Sie benachrichtigt, wenn Ihre BigQuery-Nutzung vordefinierte Limits überschreitet. Die folgende Tabelle enthält die Einstellungen zum Erstellen einer Benachrichtigungsrichtlinie. Sie können die Einstellungen in der Tabelle des Zielbereichs verwenden, wenn Sie ein Diagramm erstellen oder Metrics Explorer verwenden.
Verwenden Sie die folgenden Einstellungen, um eine Benachrichtigungsrichtlinie zu erstellen, die ausgelöst wird, wenn die aufgenommenen BigQuery-Messwerte eine benutzerdefinierte Ebene überschreiten.
| Neue Bedingung Feld |
Wert |
|---|---|
| Ressource und Messwert | Wählen Sie im Menü Ressourcen die Option BigQuery-Dataset aus. Wählen Sie im Menü Messwertkategorien die Option Speicher aus. Wählen Sie einen Messwert aus dem Menü Messwerte aus. Zu den spezifischen Messwerten zählen Stored bytes, Uploaded bytes und Uploaded bytes billed. Eine vollständige Liste der verfügbaren Messwerte finden Sie unter BigQuery-Messwerte.
|
| Filter | project_id: Ihre Google Cloud Projekt-ID. dataset_id: Ihre Dataset-ID. |
| Über Zeitreihen Zeitreihen gruppieren nach |
dataset-id: Ihre Dataset-ID. |
| Über Zeitreihen hinweg Zeitreihenaggregation |
sum |
| Rollierendes Zeitfenster | 1 m |
| Funktion für rollierendes Zeitfenster | mean |
| Benachrichtigungstrigger konfigurieren Feld |
Wert |
|---|---|
| Bedingungstyp | Threshold |
| Benachrichtigungstrigger | Any time series violates |
| Grenzwertposition | Above threshold |
| Grenzwert | Sie legen den akzeptablen Wert fest. |
| Zeitfenster noch einmal testen | 1 minute |
Nächste Schritte
Informationen zum Konfigurieren einer Senke finden Sie unter Traces exportieren.