In diesem Dokument werden einige Attribute des BigQuery-Datasets beschrieben, das erstellt wird, wenn eine Senke Traces aus Cloud Trace nach BigQuery exportiert.
Schema
Das Schema für Ihre Tabelle, in der Trace-Daten gespeichert werden, wird durch die Trace V2 API-Definition für Span bestimmt.
Trace verfolgt Ihre Tabellenspalten und patcht die Tabelle, wenn ein neuer Span Felder enthält, die nicht in der vorhandenen Tabelle gespeichert werden können. Ein Patch-Vorgang ist erforderlich, wenn ein eingehender Span Einträge enthält, die zuvor nicht vorhanden sind. Wenn ein eingehender Span beispielsweise ein neues Attribute enthält, wird die Tabelle gepatcht.
Datenaufbewahrung
Sie konfigurieren die Datenaufbewahrungsrichtlinien Ihrer BigQuery-Tabellen. Informationen zum Verwalten von Tabellen und Tabellendaten finden Sie unter Mit Tabellen arbeiten.
Tabellentyp
Wenn Sie eine Senke zum Exportieren von Traces nach BigQuery konfigurieren, konfiguriert Trace eine nach Aufnahmezeit partitionierte Tabelle. Ausführliche Informationen zu partitionierten Tabellen, einschließlich des Erstellens, Verwaltens, Abfragens und Löschens dieser Tabellen, finden Sie unter Mit partitionierten Tabellen arbeiten.
Beispielabfragen
In folgenden Abfragen ist DATASET der Name des BigQuery-Datasets und MY_TABLE der Name einer Tabelle in diesem Dataset.
Führen Sie die Abfrage aus, um alle Spalten in der Tabelle für den 20. November 2019 anzuzeigen und das Ergebnis auf zehn Zeilen zu begrenzen:
SELECT * FROM `DATASET.MY_TABLE` WHERE DATE(_PARTITIONTIME) = "2019-11-20" LIMIT 10
Führen Sie die Abfrage aus, um alle in der Tabelle verfügbaren Partitionen aufzurufen:
SELECT _PARTITIONTIME as pt FROM `DATASET.MY_TABLE` GROUP BY 1
HipsterShop-Abfrage
HipsterShop ist eine auf GitHub verfügbare Demoanwendung.
Folgendes Beispiel zeigt, wie Sie mit BigQuery-Abfragen Informationen erfassen können, die über die Trace-Oberfläche nicht verfügbar sind.
Die innere Abfrage sucht alle mit dem angegebenen regulären Ausdruck übereinstimmenden Spans, die am 2. Dezember 2019 empfangen wurden. Die äußere Abfrage wählt Folgendes zur Anzeige aus:
- name
- Anzahl der übereinstimmenden Spans
- Anzahl einzelner Trace-IDs
- 50., 90. und 99. Quantile
- HTTP-Pfad
- Fehlermeldung
und zeigt die Ergebnisse nach der Trace-Anzahl sortiert an:
SELECT t0.span.displayName.value, count(t0.span.spanId) as spanCount, count(distinct traceId) as traceCount, APPROX_QUANTILES(milliseconds, 100)[OFFSET(50)] as p50, APPROX_QUANTILES(milliseconds, 100)[OFFSET(95)] as p95, APPROX_QUANTILES(milliseconds, 100)[OFFSET(99)] as p99, t0.span.attributes.attributeMap._http_path, t0.span.attributes.attributeMap._error_message FROM ( SELECT *, REGEXP_EXTRACT(span.name, r"./traces/([a-f0-9]+).") as traceId, TIMESTAMP_DIFF(span.endTime,span.startTime, MILLISECOND) as milliseconds FROM `hipstershop-demo.Hipstershop_trace_export.cloud_trace` WHERE DATE(_PARTITIONTIME) = "2019-12-02") AS t0 WHERE t0.span.parentSpanId is NULL GROUP by t0.span.displayName.value, t0.span.attributes.attributeMap._http_path,t0.span.attributes.attributeMap._error_message ORDER BY traceCount DESC LIMIT 1000
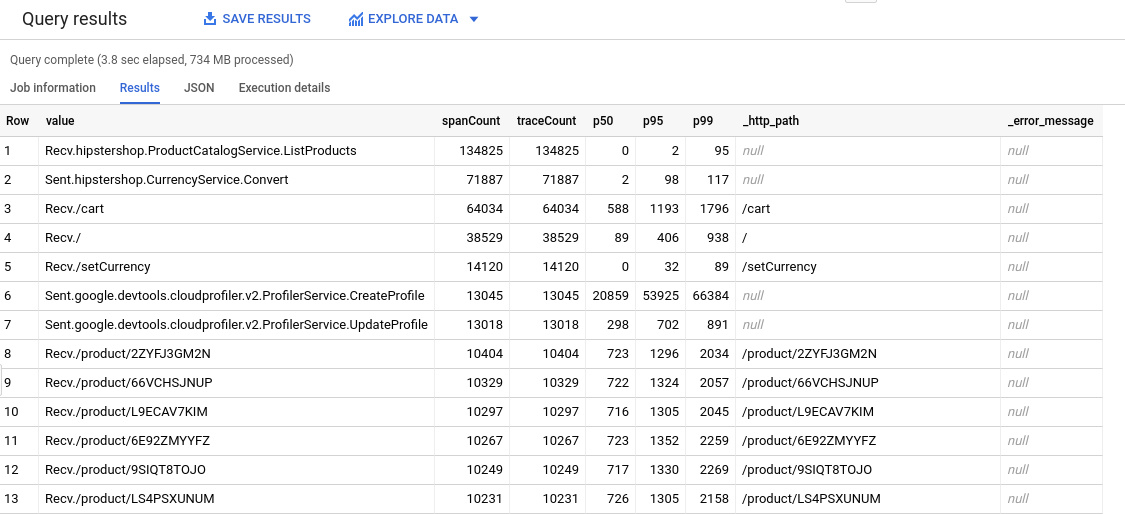
Für eine bestimmte Installation dieser Anwendung sieht das Abfrageergebnis so aus:
Trace-Daten ansehen
Wählen Sie die Tabelle mit den exportierten Traces aus, um die Trace-Daten über die BigQuery-Benutzeroberfläche anzusehen.