In dieser Anleitung wird Folgendes beschrieben:
- Cloud TPU-VM zum Bereitstellen von Llama erstellen 2-Familie von Large Language Models (LLMs), erhältlich in verschiedenen Größen (7B, 13B oder 70B)
- Prüfpunkte für die Modelle vorbereiten und in SAX bereitstellen
- Über einen HTTP-Endpunkt mit dem Modell interagieren
Serving for AGI Experiments (SAX) ist ein experimentelles System, das Paxml-, JAX- und PyTorch-Modelle zur Inferenz bereitstellt. Code und Dokumentation für SAX finden Sie im Saxml-Git-Repository. Die aktuelle stabile Version mit TPU v5e-Unterstützung ist v1.1.0.
SAX-Zellen
Eine SAX-Zelle (oder ein SAX-Cluster) ist die Haupteinheit für die Bereitstellung Ihrer Modelle. Sie besteht aus zwei Hauptteilen:
- Admin-Server: Dieser Server überwacht Ihre Modellserver, weist diesen Modellen Modelle zu und hilft Clients, den richtigen Modellserver zu finden, mit dem sie interagieren können.
- Modellserver: Auf diesen Servern wird Ihr Modell ausgeführt. Sie sind für die Verarbeitung eingehender Anfragen und die Generierung von Antworten verantwortlich.
Das folgende Diagramm zeigt eine SAX-Zelle:
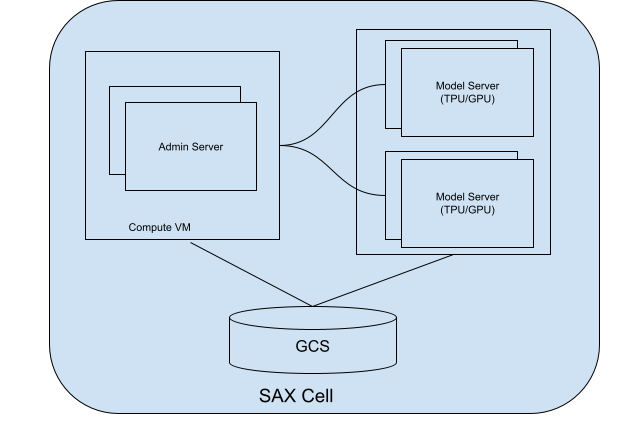
Abbildung 1. SAX-Zelle mit Administratorserver und Modellserver
Sie können mit einer SAX-Zelle über Clients interagieren, die in Python, C++ oder Go geschrieben sind, oder direkt über einen HTTP-Server. Das folgende Diagramm zeigt, wie ein externer Client kann mit einer SAX-Zelle interagieren:

Abbildung 2. Laufzeitarchitektur eines externen Clients, der mit einem SAX interagiert Zelle.
Lernziele
- TPU-Ressourcen für die Bereitstellung einrichten
- SAX-Cluster erstellen
- Llama 2-Modell veröffentlichen
- Mit dem Modell interagieren
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Cloud TPU
- Compute Engine
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
Richten Sie Ihr Google Cloud-Projekt ein, aktivieren Sie die Cloud TPU API und erstellen Sie ein Dienstkonto. Folgen Sie dazu der Anleitung unter Cloud TPU-Umgebung einrichten.
TPU erstellen
In den folgenden Schritten wird gezeigt, wie Sie eine TPU-VM erstellen, auf der Ihr Modell ausgeführt wird.
Erstellen Sie Umgebungsvariablen:
export PROJECT_ID=PROJECT_ID export ACCELERATOR_TYPE=ACCELERATOR_TYPE export ZONE=ZONE export RUNTIME_VERSION=v2-alpha-tpuv5-lite export SERVICE_ACCOUNT=SERVICE_ACCOUNT export TPU_NAME=TPU_NAME export QUEUED_RESOURCE_ID=QUEUED_RESOURCE_ID
Beschreibungen der Umgebungsvariablen
PROJECT_ID- Die ID Ihres Google Cloud-Projekts.
ACCELERATOR_TYPE- Der Beschleunigertyp gibt die Version und Größe des
Cloud TPU, die Sie erstellen möchten. Für unterschiedliche Llama 2-Modellgrößen gelten unterschiedliche TPU-Größenanforderungen:
- 7B:
v5litepod-4oder größer - 13B:
v5litepod-8oder größer - 70 Mrd.:
v5litepod-16oder größer
- 7B:
ZONE- Die Zone, in der Sie die Cloud TPU erstellen möchten.
SERVICE_ACCOUNT- Das Dienstkonto, das Sie an Ihre Cloud TPU anhängen möchten.
TPU_NAME- Der Name für Ihre Cloud TPU.
QUEUED_RESOURCE_ID- Eine Kennung für Ihre anstehende Ressourcenanfrage.
Legen Sie die Projekt-ID und die Zone in Ihrer aktiven Google Cloud CLI-Konfiguration fest:
gcloud config set project $PROJECT_ID && gcloud config set compute/zone $ZONETPU-VM erstellen:
gcloud compute tpus queued-resources create ${QUEUED_RESOURCE_ID} \ --node-id ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --accelerator-type ${ACCELERATOR_TYPE} \ --runtime-version ${RUNTIME_VERSION} \ --service-account ${SERVICE_ACCOUNT}Prüfen Sie, ob die TPU aktiv ist:
gcloud compute tpus queued-resources list --project $PROJECT_ID --zone $ZONE
Prüfpunkt-Conversion-Knoten einrichten
Wenn Sie die Llama-Modelle auf einem SAX-Cluster ausführen möchten, müssen Sie die ursprünglichen Llama-Checkpunkte in ein SAX-kompatibles Format konvertieren.
Die Umwandlung erfordert je nach Modellgröße erhebliche Arbeitsspeicherressourcen:
| Modell | Maschinentyp |
|---|---|
| 7 Mrd. | 50–60 GB Arbeitsspeicher |
| 13 B | 120 GB Arbeitsspeicher |
| 70 Mrd. | 500–600 GB Arbeitsspeicher (N2- oder M1-Maschinentyp) |
Für das 7B- und das 13B-Modell können Sie die Umwandlung auf der TPU-VM ausführen. Für die 70B-Modell haben, müssen Sie eine Compute Engine-Instanz mit ca. 1 TB Speicherplatz:
gcloud compute instances create INSTANCE_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=n2-highmem-128 \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=bk-workday-dlvm,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Unabhängig davon, ob Sie eine TPU- oder Compute Engine-Instanz als Conversion-Server verwenden, Ihren Server so einrichten, dass die Llama 2-Prüfpunkte konvertiert werden:
Legen Sie für die Modelle 7B und 13B die Umgebungsvariable für den Servernamen in den Namen Ihrer TPU:
export CONV_SERVER_NAME=$TPU_NAMELegen Sie für das 70B-Modell die Umgebungsvariable für den Servernamen auf den Namen Ihre Compute Engine-Instanz:
export CONV_SERVER_NAME=INSTANCE_NAME
Stellen Sie über SSH eine Verbindung zum Conversion-Knoten her.
Wenn Ihr Conversion-Knoten eine TPU ist, stellen Sie eine Verbindung zur TPU her:
gcloud compute tpus tpu-vm ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEWenn Ihr Conversion-Knoten eine Compute Engine-Instanz ist, stellen Sie eine Verbindung zu der Compute Engine-VM her:
gcloud compute ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEInstallieren Sie die erforderlichen Pakete auf dem Conversion-Knoten:
sudo apt update sudo apt-get install python3-pip sudo apt-get install git-all pip3 install paxml==1.1.0 pip3 install torch pip3 install jaxlib==0.4.14Laden Sie das Llama-Checkpoint-Konvertierungsskript herunter:
gcloud storage cp gs://cloud-tpu-inference-public/sax-tokenizers/llama/convert_llama_ckpt.py .
Llama 2-Gewichte herunterladen
Bevor Sie das Modell konvertieren, müssen Sie die Llama 2-Gewichte herunterladen. In diesem Fall müssen Sie die ursprünglichen Llama 2-Gewichtungen verwenden (z. B. meta-llama/Llama-2-7b) und nicht die Gewichtungen, die für das Hugging Face Transformers-Format konvertiert wurden (Beispiel: meta-llama/Llama-2-7b-hf).
Wenn du bereits die Llama 2-Gewichtungen hast, gehe zu Konvertiere die Gewichtungen.
Um die Gewichte aus dem Hugging Face-Hub herunterzuladen, musst du ein Nutzerzugriffstoken und Zugriff auf die Llama 2-Modelle anfordern. Wenn Sie Zugriff anfordern möchten, folgen Sie der Anleitung auf der Hugging Face-Seite für das gewünschte Modell, z. B. meta-llama/Llama-2-7b.
Erstellen Sie ein Verzeichnis für die Gewichtungen:
sudo mkdir WEIGHTS_DIRECTORY
Llama2-Gewichte aus dem Hugging Face-Hub abrufen:
Installieren Sie die Hugging Face Hub-Befehlszeile:
pip install -U "huggingface_hub[cli]"Wechseln Sie in das Verzeichnis „weights“:
cd WEIGHTS_DIRECTORY
Laden Sie die Llama 2-Dateien herunter:
python3 from huggingface_hub import login login() from huggingface_hub import hf_hub_download, snapshot_download import os PATH=os.getcwd() snapshot_download(repo_id="meta-llama/LLAMA2_REPO", local_dir_use_symlinks=False, local_dir=PATH)
Ersetzen Sie LLAMA2_REPO durch den Namen des Hugging Face-Repositorys, aus dem Sie herunterladen möchten:
Llama-2-7b,Llama-2-13boderLlama-2-70b.
Gewichte konvertieren
Bearbeiten Sie das Conversion-Script und führen Sie es dann aus, um die Modellgewichte zu konvertieren.
Erstellen Sie ein Verzeichnis zum Speichern der umgewandelten Gewichte:
sudo mkdir CONVERTED_WEIGHTS
Klonen Sie das Saxml-GitHub-Repository in ein Verzeichnis, in dem Sie Lese-, Schreib- und Ausführungsberechtigungen haben:
git clone https://github.com/google/saxml.git -b r1.1.0Wechseln Sie in das Verzeichnis
saxml:cd saxmlÖffnen Sie die Datei
saxml/tools/convert_llama_ckpt.py.Ändern Sie in der Datei
saxml/tools/convert_llama_ckpt.pyZeile 169 von:'scale': pytorch_vars[0]['layers.%d.attention_norm.weight' % (layer_idx)].type(torch.float16).numpy()An:
'scale': pytorch_vars[0]['norm.weight'].type(torch.float16).numpy()Führen Sie das Skript
saxml/tools/init_cloud_vm.shaus:saxml/tools/init_cloud_vm.shNur bei 70 Mrd.: Testmodus deaktivieren:
- Öffnen Sie das
saxml/server/pax/lm/params/lm_cloud.py-Datei. Ändern Sie in der Datei
saxml/server/pax/lm/params/lm_cloud.pydie Zeile 344 von:return TrueAn:
return False
- Öffnen Sie das
Gewichtungen umrechnen:
python3 saxml/tools/convert_llama_ckpt.py --base-model-path WEIGHTS_DIRECTORY \ --pax-model-path CONVERTED_WEIGHTS \ --model-size MODEL_SIZE
Ersetzen Sie Folgendes:
- WEIGHTS_DIRECTORY: Verzeichnis für die ursprünglichen Gewichte.
- CONVERTED_WEIGHTS: Zielpfad für die konvertierten Gewichte.
- MODEL_SIZE:
7b,13boder70b.
Checkpoint-Verzeichnis vorbereiten
Nach der Umwandlung sollte das Prüfpunktverzeichnis die folgende Struktur haben:
checkpoint_00000000
metadata/
metadata
state/
mdl_vars.params.lm*/
...
...
step/
Erstellen Sie eine leere Datei mit dem Namen commit_success.txt und speichern Sie eine Kopie der Datei im Ordner
checkpoint_00000000, metadata und state. So weiß das SAX,
dass dieser Prüfpunkt vollständig konvertiert und geladen werden kann:
Wechseln Sie in das Checkpoint-Verzeichnis:
cd CONVERTED_WEIGHTS/checkpoint_00000000
Erstellen Sie eine leere Datei mit dem Namen
commit_success.txt:touch commit_success.txtWechseln Sie zum Metadatenverzeichnis und erstellen Sie eine leere Datei mit dem Namen
commit_success.txt:cd metadata && touch commit_success.txtWechseln Sie zum Statusverzeichnis und erstellen Sie eine leere Datei mit dem Namen
commit_success.txt:cd .. && cd state && touch commit_success.txt
Das Checkpoint-Verzeichnis sollte jetzt die folgende Struktur haben:
checkpoint_00000000
commit_success.txt
metadata/
commit_success.txt
metadata
state/
commit_success.txt
mdl_vars.params.lm*/
...
...
step/
Cloud Storage-Bucket erstellen
Die konvertierte Datei muss gespeichert werden. in einem Cloud Storage-Bucket prüfen, wenn Sie das Modell veröffentlichen.
Legen Sie eine Umgebungsvariable für den Namen Ihres Cloud Storage-Buckets fest:
export GSBUCKET=BUCKET_NAME
So erstellen Sie einen Bucket:
gcloud storage buckets create gs://${GSBUCKET}Kopieren Sie die konvertierten Prüfpunktdateien in Ihren Bucket:
gcloud storage cp -r CONVERTED_WEIGHTS/checkpoint_00000000 gs://$GSBUCKET/sax_models/llama2/SAX_LLAMA2_DIR/
Ersetzen Sie SAX_LLAMA2_DIR durch den entsprechenden Wert:
- 7B:
saxml_llama27b - 13B:
saxml_llama213b - 70 Mrd.:
saxml_llama270b
- 7B:
SAX-Cluster erstellen
So erstellen Sie einen SAX-Cluster:
In einer typischen Bereitstellung würden Sie den Admin-Server in einer Compute Engine ausführen. Instanz und dem Modellserver auf einer TPU oder GPU. In dieser Anleitung stellen Sie den Administratorserver und den Modellserver in derselben TPU v5e-Instanz bereit.
Administratorserver erstellen
Erstellen Sie den Docker-Container für den Administratorserver:
Installieren Sie Docker auf dem Conversion-Server:
sudo apt-get update sudo apt-get install docker.ioStarten Sie den Docker-Container des Administratorservers:
sudo docker run --name sax-admin-server \ -it \ -d \ --rm \ --network host \ --env GSBUCKET=${GSBUCKET} us-docker.pkg.dev/cloud-tpu-images/inference/sax-admin-server:v1.1.0
Sie können den Befehl docker run ohne die Option -d ausführen, um sich die Protokolle anzusehen und sicherzustellen, dass der Admin-Server richtig gestartet wird.
Modellserver erstellen
In den folgenden Abschnitten wird gezeigt, wie Sie einen Modellserver erstellen.
Modell 7b
Starten Sie den Docker-Container des Modellservers:
sudo docker run --privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='4'
13b-Modell
Die Konfiguration für LLaMA13BFP16TPUv5e fehlt in lm_cloud.py. In den folgenden Schritten wird gezeigt, wie Sie lm_cloud.py aktualisieren und ein neues Docker-Image committen.
Starten Sie den Modellserver:
sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'Stellen Sie über SSH eine Verbindung zum Docker-Container her:
sudo docker exec -it sax-model-server bashInstallieren Sie Vim im Docker-Image:
$ apt update $ apt install vimÖffnen Sie die Datei
saxml/server/pax/lm/params/lm_cloud.py. Suchen nachLLaMA13BSie sollten den folgenden Code sehen:@servable_model_registry.register @quantization.for_transformer(quantize_on_the_fly=False) class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueKommentieren oder löschen Sie die Zeile, die mit
@quantizationbeginnt. Nach dieser Änderung sollte die Datei so aussehen:@servable_model_registry.register class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueFügen Sie den folgenden Code hinzu, um die TPU-Konfiguration zu unterstützen.
@servable_model_registry.register class LLaMA13BFP16TPUv5e(LLaMA13B): """13B model on TPU v5e-8. """ BATCH_SIZE = [1] BUCKET_KEYS = [128] MAX_DECODE_STEPS = [32] ENABLE_GENERATE_STREAM = False ICI_MESH_SHAPE = [1, 1, 8] @property def test_mode(self) -> bool: return FalseBeenden Sie die SSH-Sitzung des Docker-Containers:
exitWenden Sie die Änderungen auf ein neues Docker-Image an:
sudo docker commit sax-model-server sax-model-server:v1.1.0-modPrüfen Sie, ob das neue Docker-Image erstellt wurde:
sudo docker imagesSie können das Docker-Image in der Artifact Registry Ihres Projekts veröffentlichen. wird mit dem lokalen Bild fortgefahren.
Halten Sie den Modellserver an. Im weiteren Verlauf dieser Anleitung wird das aktualisierte Modell verwendet. Server.
sudo docker stop sax-model-serverStarten Sie den Modellserver mit dem aktualisierten Docker-Image. Achten Sie darauf, den aktualisierten Image-Namen
sax-model-server:v1.1.0-mod:sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ sax-model-server:v1.1.0-mod \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'
Modell 70B
Stellen Sie über SSH eine Verbindung zu Ihrer TPU her und starten Sie den Modellserver:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE} \
--worker=all \
--command="
gcloud auth configure-docker \
us-docker.pkg.dev
# Pull SAX model server image
sudo docker pull us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0
# Run model server
sudo docker run \
--privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root \
us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='16'
"
Logs prüfen
Prüfen Sie anhand der Modellserver-Logs, ob der Modellserver richtig gestartet wurde:
docker logs -f sax-model-server
Wenn der Modellserver nicht gestartet wurde, finden Sie weitere Informationen im Abschnitt Fehlerbehebung.
Wiederholen Sie für das 70B-Modell diese Schritte für jede TPU-VM:
Stellen Sie eine SSH-Verbindung zur TPU her:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --worker=WORKER_NUMBER
WORKER_NUMBER ist ein 0-basierter Index, der angibt, welche TPU-VM Sie ausführen möchten mit denen Sie eine Verbindung herstellen können.
Logs prüfen:
sudo docker logs -f sax-model-serverFür drei TPU-VMs sollte angezeigt werden, dass sie mit den anderen Instanzen verbunden sind:
I1117 00:16:07.196594 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.3:10001 I1117 00:16:07.197484 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.87:10001 I1117 00:16:07.199437 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.13:10001Eine der TPU-VMs sollte über Logs verfügen, aus denen hervorgeht, dass der Modellserver gestartet wird:
I1115 04:01:29.479170 139974275995200 model_service_base.py:867] Started joining SAX cell /sax/test ERROR: logging before flag.Parse: I1115 04:01:31.479794 1 location.go:141] Calling Join due to address update ERROR: logging before flag.Parse: I1115 04:01:31.814721 1 location.go:155] Joined 10.182.0.44:10000
Modell veröffentlichen
SAX wird mit dem Befehlszeilentool saxutil geliefert, das die Interaktion mit SAX-Modellservern vereinfacht. In dieser Anleitung verwenden Sie saxutil, um das Modell zu veröffentlichen. Eine vollständige Liste der saxutil-Befehle finden Sie in der README-Datei von Saxml.
Wechseln Sie in das Verzeichnis, in das Sie das Saxml-GitHub-Repository geklont haben:
cd saxmlStellen Sie für das Modell 70B eine Verbindung zu Ihrem Conversion-Server her:
gcloud compute ssh ${CONV_SERVER_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE}Installieren Sie Bazel:
sudo apt-get install bazelLegen Sie einen Alias für die Ausführung von
saxutilmit Ihrem Cloud Storage-Bucket fest:alias saxutil='bazel run saxml/bin:saxutil -- --sax_root=gs://${GSBUCKET}/sax-root'Veröffentlichen Sie das Modell mit
saxutil. Das dauert auf einer TPU v5litepod-8 etwa 10 Minuten.saxutil --sax_root=gs://${GSBUCKET}/sax-root publish '/sax/test/MODEL' \ saxml.server.pax.lm.params.lm_cloud.PARAMETERS \ gs://${GSBUCKET}/sax_models/llama2/SAX_LLAMA2_DIR/checkpoint_00000000/ \ 1
Ersetzen Sie die folgenden Variablen:
Modellgröße Werte 7B MODEL: Lama27b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama27b
13 B MODEL: llama213b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA13BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama213b
70 Mrd. MODEL: llama270b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA70BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama270b
Testbereitstellung
Mit dem Befehl saxutil ls können Sie prüfen, ob die Bereitstellung erfolgreich war:
saxutil ls /sax/test/MODEL
Bei einer erfolgreichen Bereitstellung sollte die Anzahl der Replikate größer als null sein und in etwa so aussehen:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| MODEL | MODEL PATH | CHECKPOINT PATH | # OF REPLICAS | (SELECTED) REPLICAADDRESS |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| llama27b | saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e | gs://${MODEL_BUCKET}/sax_models/llama2/7b/pax_7B/checkpoint_00000000/ | 1 | 10.182.0.28:10001 |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
Die Docker-Protokolle für den Modellserver sehen in etwa so aus:
I1114 17:31:03.586631 140003787142720 model_service_base.py:532] Successfully loaded model for key: /sax/test/llama27b
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
Fehlerbehebung
Wenn die Bereitstellung fehlschlägt, prüfen Sie die Modellserverprotokolle:
sudo docker logs -f sax-model-server
Bei einer erfolgreichen Bereitstellung sollte die folgende Ausgabe angezeigt werden:
Successfully loaded model for key: /sax/test/llama27b
Wenn aus den Logs nicht hervorgeht, dass das Modell bereitgestellt wurde, prüfen Sie das Modell Konfiguration und den Pfad zum Modellprüfpunkt.
Antworten generieren
Mit dem saxutil-Tool können Sie Antworten auf Prompts generieren.
So generieren Sie Antworten auf eine Frage:
saxutil lm.generate -extra="temperature:0.2" /sax/test/MODEL "Q: Who is Harry Potter's mother? A:"
Die Ausgabe sollte in etwa so aussehen:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root' lm.generate /sax/test/llama27b 'Q: Who is Harry Potter's mother? A: `
+-------------------------------+------------+
| GENERATE | SCORE |
+-------------------------------+------------+
| 1. Harry Potter's mother is | -20.214787 |
| Lily Evans. 2. Harry Potter's | |
| mother is Petunia Evans | |
| (Dursley). | |
+-------------------------------+------------+
Mit dem Modell über einen Client interagieren
Das SAX-Repository enthält Clients, über die Sie mit einer SAX-Zelle interagieren können. Clients sind in C++, Python und Go verfügbar. Im folgenden Beispiel wird gezeigt, wie ein Python-Client erstellt wird.
Erstellen Sie den Python-Client:
bazel build saxml/client/python:sax.cc --compile_one_dependencyFügen Sie den Kunden zu
PYTHONPATHhinzu. In diesem Beispiel wird davon ausgegangen, dass sichsaxmlin Ihrem Basisverzeichnis befindet:export PYTHONPATH=${PYTHONPATH}:$HOME/saxml/bazel-bin/saxml/client/python/Mit SAX über die Python-Shell interagieren:
$ python3 Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sax >>>
Über einen HTTP-Endpunkt mit dem Modell interagieren
Erstellen Sie einen HTTP-Client, um über einen HTTP-Endpunkt mit dem Modell zu interagieren:
Eine Compute Engine-VM erstellen:
export PROJECT_ID=PROJECT_ID export ZONE=ZONE export HTTP_SERVER_NAME=HTTP_SERVER_NAME export SERVICE_ACCOUNT=SERVICE_ACCOUNT export MACHINE_TYPE=e2-standard-8 gcloud compute instances create $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=$MACHINE_TYPE \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=$HTTP_SERVER_NAME,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Stellen Sie eine SSH-Verbindung zur Compute Engine-VM her:
gcloud compute ssh $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEKlonen Sie das GitHub-Repository für KI auf GKE:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.gitWechseln Sie in das HTTP-Serververzeichnis:
cd ai-on-gke/tools/saxml-on-gke/httpserverErstellen Sie die Dockerfile:
docker build -f Dockerfile -t sax-http .Führen Sie den HTTP-Server aus:
docker run -e SAX_ROOT=gs://${GSBUCKET}/sax-root -p 8888:8888 -it sax-http
Endpunkt auf einem lokalen Computer oder einem anderen Server mit Portzugriff testen 8888 mit den folgenden Befehlen:
Exportieren Sie Umgebungsvariablen für die IP-Adresse und den Port Ihres Servers:
export LB_IP=HTTP_SERVER_EXTERNAL_IP export PORT=8888
Legen Sie die JSON-Nutzlast mit dem Modell und der Abfrage fest:
json_payload=$(cat << EOF { "model": "/sax/test/MODEL", "query": "Example query" } EOF )
Senden Sie diese Anfrage:
curl --request POST --header "Content-type: application/json" -s $LB_IP:$PORT/generate --data "$json_payload"
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Wenn Sie mit dieser Anleitung fertig sind, führen Sie die folgenden Schritte aus, um Ihre Ressourcen zu bereinigen.
Löschen Sie Ihre Cloud TPU.
$ gcloud compute tpus tpu-vm delete $TPU_NAME --zone $ZONE
Löschen Sie die Compute Engine-Instanz, falls Sie eine erstellt haben.
gcloud compute instances delete INSTANCE_NAME
Löschen Sie Ihren Cloud Storage-Bucket und seinen Inhalt.
gcloud storage rm --recursive gs://BUCKET_NAME
Nächste Schritte
- Alle TPU-Anleitungen
- Unterstützte Referenzmodelle
- Inferenz mit v5e
- Modell mit v5e für die Inferenz konvertieren