
Spanner
Banco de dados sempre disponível com escalonamento praticamente ilimitado
Crie apps inteligentes e essenciais em um único banco de dados que unifica recursos relacionais, gráficos, de chave-valor e de pesquisa. Execute em qualquer lugar com o Spanner Omni.
Primeiros passos com uma instância de teste sem custo financeiros de 90 dias.
Recursos
Multimodelo: um banco de dados, muitas possibilidades
Os recursos multimodelo do Spanner permitem criar aplicativos inteligentes com tecnologia de IA sobre seus dados operacionais relacionais e NoSQL usando a integração nativa com a Gemini Enterprise Agent Platform, o Spanner Graph para consultar relações complexas, a pesquisa vetorial para pesquisa semântica e a pesquisa de texto completo integrada, tudo com interoperabilidade "verdadeiramente sem ETL". Essa abordagem unificada elimina silos de dados, economiza custos, reduz pontos de contato operacionais e de segurança e garante a consistência dos dados em todos os modelos.

Base para aplicativos de IA agênticos
Integração total com a Gemini Enterprise Agent Platform para aproveitar os modelos mais recentes do Gemini. Maximize a produtividade dos desenvolvedores de IA para criar agentes autônomos que raciocinam sobre o estado operacional em tempo real usando o Kit de Desenvolvimento de Agente (ADK). Tenha conversas em linguagem natural com seus dados no Spanner usando plataformas de vibe coding como a CLI do Gemini com servidores MCP remotos. Aproveite as funções de IA no Spanner para realizar operações semânticas complexas diretamente no SQL, aproximando a inteligência dos seus dados. Converse com agentes sobre os dados do seu banco de dados usando linguagem natural com as análises de conversação para o Spanner. O Data Agent Kit simplifica seus fluxos de trabalho ao reunir ferramentas seguras do Protocolo de Contexto de Modelo (MCP), plug-ins nativos de IDE e habilidades de engenharia e ciência de dados pré-codificadas em um único pacote de código aberto.

Execute em qualquer lugar
O Spanner Omni é uma versão para download do Spanner, o banco de dados multimodelo distribuído globalmente do Google Cloud. Ele estende a escala líder do setor, a alta disponibilidade e a forte consistência global do Spanner para sua infraestrutura, seja no local, em várias nuvens ou no seu notebook. O Spanner Omni é a solução ideal quando você precisa de resiliência entre nuvens ou de um banco de dados de escalonamento horizontal que opere fora do Google Cloud para potencializar seus aplicativos de IA agêntica.

Insights em tempo real na velocidade dos negócios
Elimine os silos entre dados operacionais e analíticos. O mecanismo colunar integrado do Spanner permite realizar análises ad hoc de alto desempenho em dados ativos sem afetar a capacidade de processamento transacional. Para uma análise mais detalhada, o Spanner se integra perfeitamente a data lakehouses como o BigQuery, aproveitando consultas federadas para analisar dados no Spanner e no BigQuery em tempo real ou utilizando ETL reverso com um clique para transferir insights do seu lakehouse de volta para o Spanner.

Escalonabilidade sem complicações
Sonhe alto, comece com pouco e escalone sem esforço conforme suas necessidades aumentarem. O Spanner processa conjuntos de dados em crescimento e cargas de trabalho exigentes com a escalonabilidade horizontal de leitura e "gravação". A fragmentação automática de banco de dados garante a distribuição ideal de dados, enquanto o particionamento geográfico aproxima os dados dos usuários para reduzir a latência. Tenha um desempenho alto e consistente com o processamento de consultas isolado de cargas de trabalho com o Spanner Data Boost, mesmo durante os picos de demanda.

Disponibilidade sempre ativada
Garanta que seus aplicativos estejam sempre ativos e prontos para atender os usuários. O Spanner oferece até 99,999% de disponibilidade com manutenção automatizada e opções de implantação flexíveis. Escolha entre configurações de região única, dupla ou multirregional para atender aos seus requisitos específicos de disponibilidade e tolerância a falhas.

Transações com consistência garantida
Diga adeus às inconsistências de dados e às complexidades de gerenciá-los. O Spanner garante consistência transacional forte, ou seja, cada leitura reflete as atualizações mais recentes, independentemente do tamanho ou da distribuição dos dados. Crie com confiança, sabendo que seus aplicativos sempre têm uma visualização consistente dos dados.
Segurança e conformidade confiáveis
Confie seus dados a uma plataforma segura e em conformidade com o Spanner. Tenha administração e controle centralizados com o Database Center, simplificando o gerenciamento de bancos de dados na nuvem. O Spanner oferece segurança e controles de nível empresarial, incluindo criptografia de dados em repouso e em trânsito, gerenciamento de acesso granular pelo Identity and Access Management (IAM) e compliance com os padrões do setor. Proteja ainda mais seus dados com recursos robustos de backup e restauração, incluindo recuperação pontual para ter tranquilidade operacional.
Comparação de bancos de dados
| Atributo do banco de dados | Outro banco de dados relacional | Outro banco de dados não relacional | Spanner |
|---|---|---|---|
Esquema | Estático | Dinâmico | Dinâmico |
SQL | Sim | Não | Yes (PostgreSQL, SQL do Google) |
Transações | ACID (atomicidade, consistência, isolamento e durabilidade) | Eventual | ACID forte com ordenação TrueTime |
Escalonabilidade | Vertical (usar uma máquina maior) | Horizontal (adicionar mais máquinas) | Horizontal |
Disponibilidade | Failover (inatividade) | Alta | Alto SLA de 99,999% |
Replicação | Configurável | Configurável | Automático |
O Gartner® classificou o Spanner como o nº 1 no caso de uso de transações leves. Veja o relatório completo.
Esquema
Estático
Dinâmico
Dinâmico
SQL
Sim
Não
Yes
(PostgreSQL, SQL do Google)
Transações
ACID
(atomicidade, consistência, isolamento e durabilidade)
Eventual
ACID forte
com ordenação TrueTime
Escalonabilidade
Vertical
(usar uma máquina maior)
Horizontal
(adicionar mais máquinas)
Horizontal
Disponibilidade
Failover (inatividade)
Alta
Alto SLA de 99,999%
Replicação
Configurável
Configurável
Automático
O Gartner® classificou o Spanner como o nº 1 no caso de uso de transações leves. Veja o relatório completo.
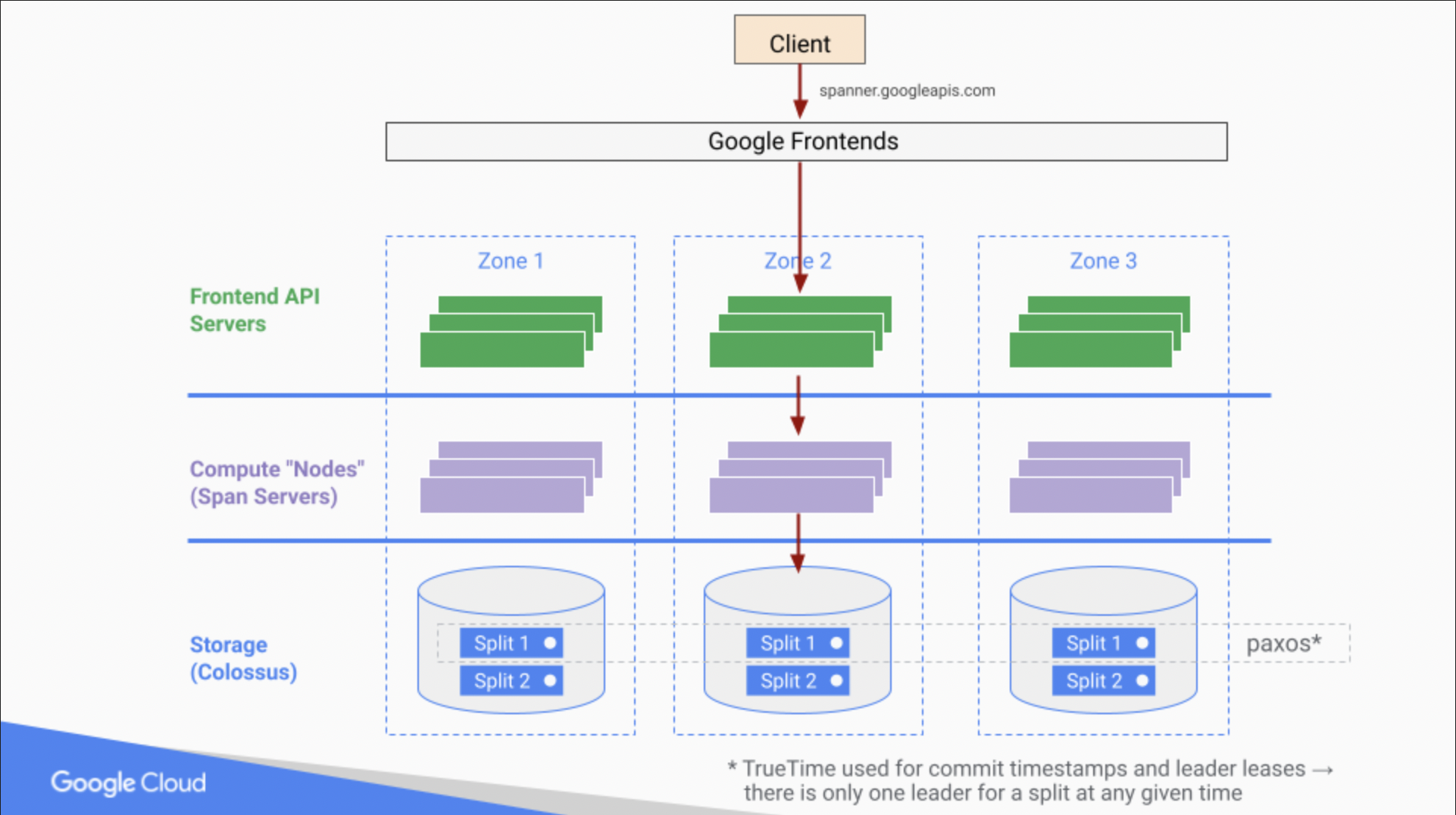
Como funciona
As instâncias do Spanner fornecem computação e armazenamento em uma ou mais regiões. Um relógio distribuído chamado
TrueTime garante que as transações sejam fortemente
consistentes, mesmo entre regiões. Os dados são "divididos"
automaticamente para escalonabilidade e replicados usando um
esquema síncrono baseado em Paxos para disponibilidade.
As instâncias do Spanner fornecem computação e armazenamento em uma ou mais regiões. Um relógio distribuído chamado TrueTime garante que as transações sejam fortemente consistentes, mesmo entre regiões. Os dados são "divididos" automaticamente para escalonabilidade e replicados usando um esquema síncrono baseado em Paxos para disponibilidade.
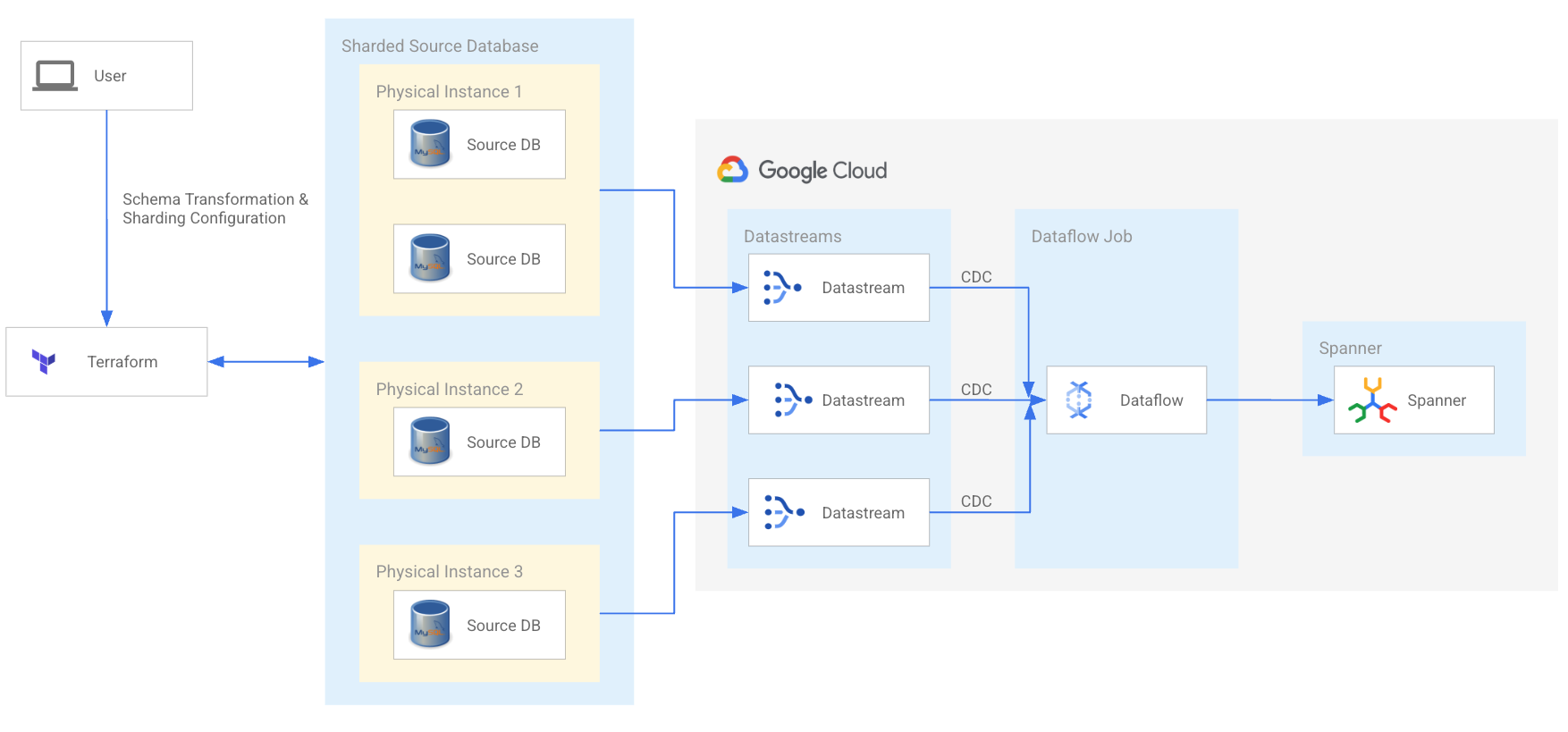
Migração e modernização
Simplifique a modernização do MySQL e do Cassandra
Simplifique a modernização do MySQL e do Cassandra
Modernize suas cargas de trabalho fragmentadas do MySQL e do Cassandra para potencializar as equipes de desenvolvimento e escalonar para a próxima fase de crescimento. Aproveite a ferramenta de migração do Spanner de código aberto e uma rede de parceiros de tecnologia e serviços qualificados que podem simplificar sua migração.
Tutoriais, guias de início rápido e laboratórios
Simplifique a modernização do MySQL e do Cassandra
Simplifique a modernização do MySQL e do Cassandra
Modernize suas cargas de trabalho fragmentadas do MySQL e do Cassandra para potencializar as equipes de desenvolvimento e escalonar para a próxima fase de crescimento. Aproveite a ferramenta de migração do Spanner de código aberto e uma rede de parceiros de tecnologia e serviços qualificados que podem simplificar sua migração.
Resiliência híbrida e multicloud
Garantir a continuidade dos negócios em diversos ambientes
Garantir a continuidade dos negócios em diversos ambientes
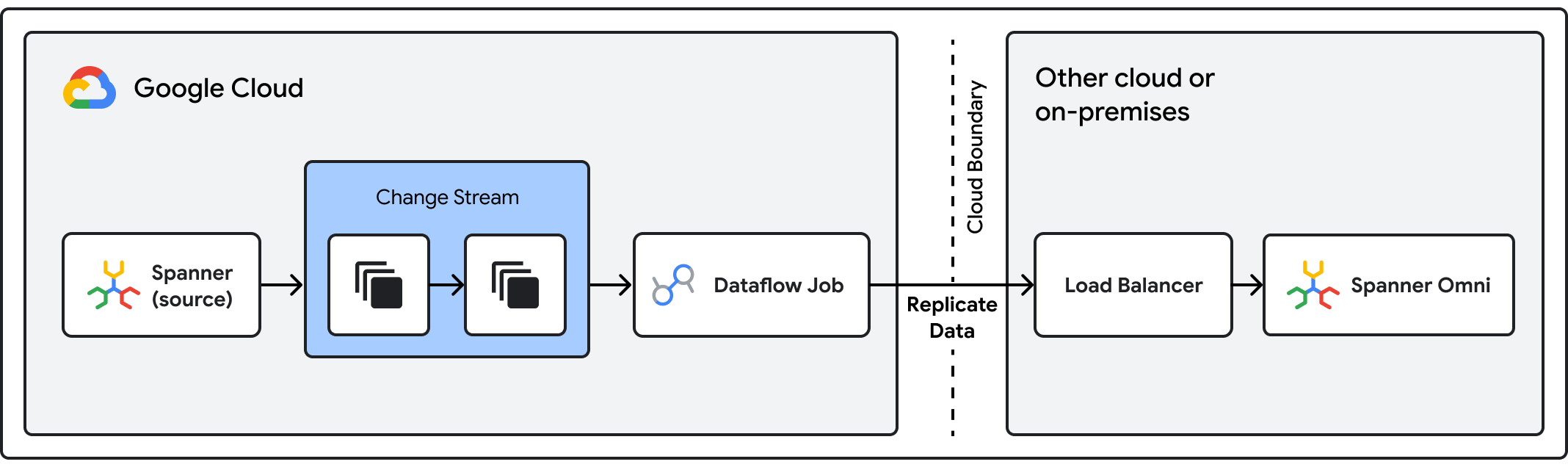
Crie arquiteturas verdadeiramente resilientes e de alta disponibilidade que vão além dos limites de um único provedor de nuvem. Ao implantar o Spanner Omni em uma nuvem secundária ou data center no local como um site de failover "quente/frio" para o serviço gerenciado do Spanner principal no Google Cloud, você cria uma rede de segurança essencial. Essa arquitetura "primária/secundária" reduz a vulnerabilidade a interrupções de serviço e ajuda a atender aos requisitos regulatórios rigorosos de "saída sob estresse" para serviços financeiros.
Tutoriais, guias de início rápido e laboratórios
Garantir a continuidade dos negócios em diversos ambientes
Garantir a continuidade dos negócios em diversos ambientes
Crie arquiteturas verdadeiramente resilientes e de alta disponibilidade que vão além dos limites de um único provedor de nuvem. Ao implantar o Spanner Omni em uma nuvem secundária ou data center no local como um site de failover "quente/frio" para o serviço gerenciado do Spanner principal no Google Cloud, você cria uma rede de segurança essencial. Essa arquitetura "primária/secundária" reduz a vulnerabilidade a interrupções de serviço e ajuda a atender aos requisitos regulatórios rigorosos de "saída sob estresse" para serviços financeiros.
Perfil e direitos do usuário
Gerencie dados críticos do usuário com segurança em qualquer escala
Gerencie dados críticos do usuário com segurança em qualquer escala
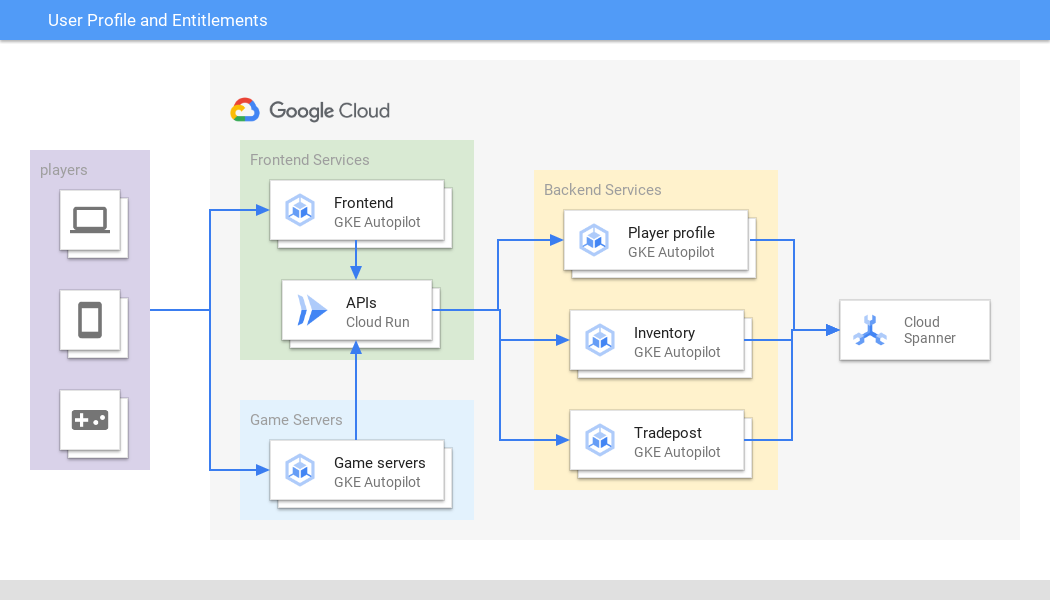
O gerenciamento de perfis de usuário é uma função crítica que exige escalonabilidade, disponibilidade e consistência global do Spanner. Ela é o ponto de entrada para os jogadores em vários jogos, plataformas e regiões. Da mesma forma, as empresas de serviços financeiros gerenciam informações do cliente e ofertas de produtos usando o Spanner.
Tutoriais, guias de início rápido e laboratórios
Gerencie dados críticos do usuário com segurança em qualquer escala
Gerencie dados críticos do usuário com segurança em qualquer escala
O gerenciamento de perfis de usuário é uma função crítica que exige escalonabilidade, disponibilidade e consistência global do Spanner. Ela é o ponto de entrada para os jogadores em vários jogos, plataformas e regiões. Da mesma forma, as empresas de serviços financeiros gerenciam informações do cliente e ofertas de produtos usando o Spanner.
Livro financeiro
Tenha uma visão atualizada e consistente das transações globais
Tenha uma visão atualizada e consistente das transações globais
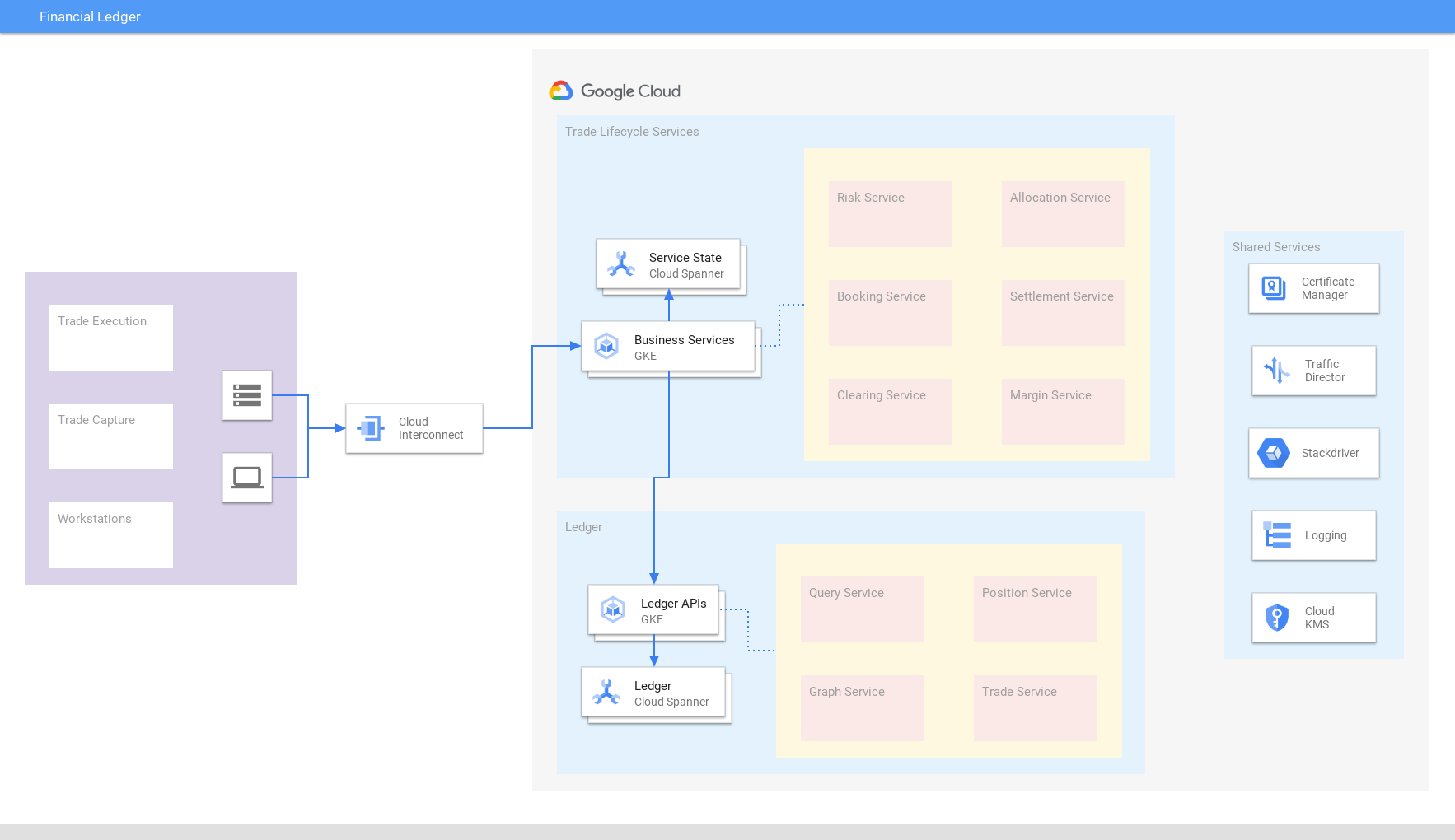
Unifique transações financeiras, negócios, acordos e posições em todo o mundo em um livro de registro consolidado criado no Spanner que garante escalonabilidade e consistência externas. A consolidação de dados ajuda na adaptação rápida às mudanças nas condições de mercado e aos requisitos regulatórios. Da mesma forma, empresas de varejo/comércio eletrônico usam o Spanner para registros contábeis.
Tutoriais, guias de início rápido e laboratórios
Tenha uma visão atualizada e consistente das transações globais
Tenha uma visão atualizada e consistente das transações globais
Unifique transações financeiras, negócios, acordos e posições em todo o mundo em um livro de registro consolidado criado no Spanner que garante escalonabilidade e consistência externas. A consolidação de dados ajuda na adaptação rápida às mudanças nas condições de mercado e aos requisitos regulatórios. Da mesma forma, empresas de varejo/comércio eletrônico usam o Spanner para registros contábeis.
Internet banking
Ofereça interatividade contínua para experiências digitais
Ofereça interatividade contínua para experiências digitais
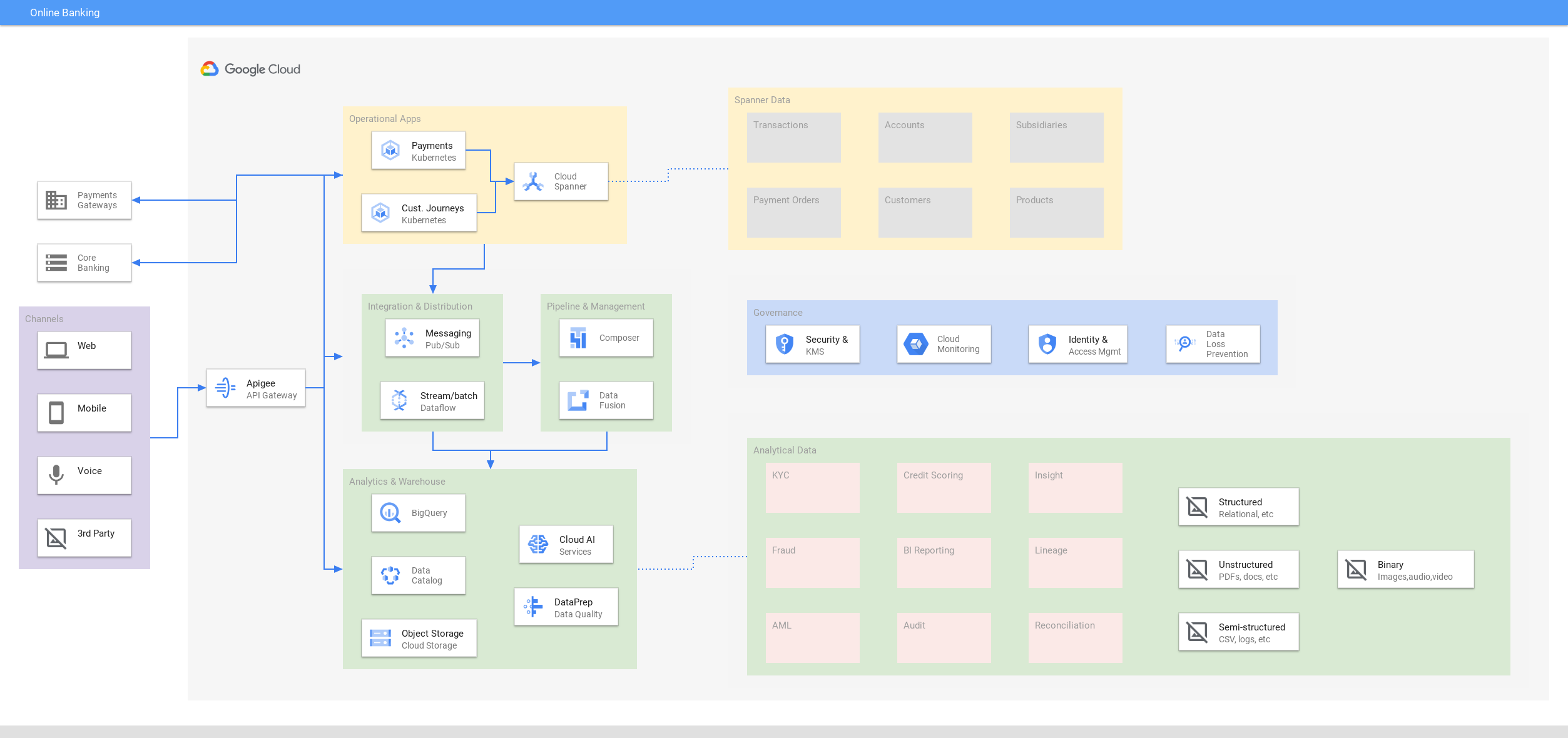
Os consumidores esperam acessar os dados financeiros essenciais nos dispositivos fora do horário comercial. Permita que os desenvolvedores se concentrem em novas experiências em vez de na sobrecarga operacional, como fragmentação manual ou consistência eventual. Reduza riscos e inatividade com 99,999% de disponibilidade e nenhuma manutenção.
Tutoriais, guias de início rápido e laboratórios
Ofereça interatividade contínua para experiências digitais
Ofereça interatividade contínua para experiências digitais
Os consumidores esperam acessar os dados financeiros essenciais nos dispositivos fora do horário comercial. Permita que os desenvolvedores se concentrem em novas experiências em vez de na sobrecarga operacional, como fragmentação manual ou consistência eventual. Reduza riscos e inatividade com 99,999% de disponibilidade e nenhuma manutenção.
Programas de fidelidade e promoções
Personalize experiências com atualizações em tempo real
Personalize experiências com atualizações em tempo real
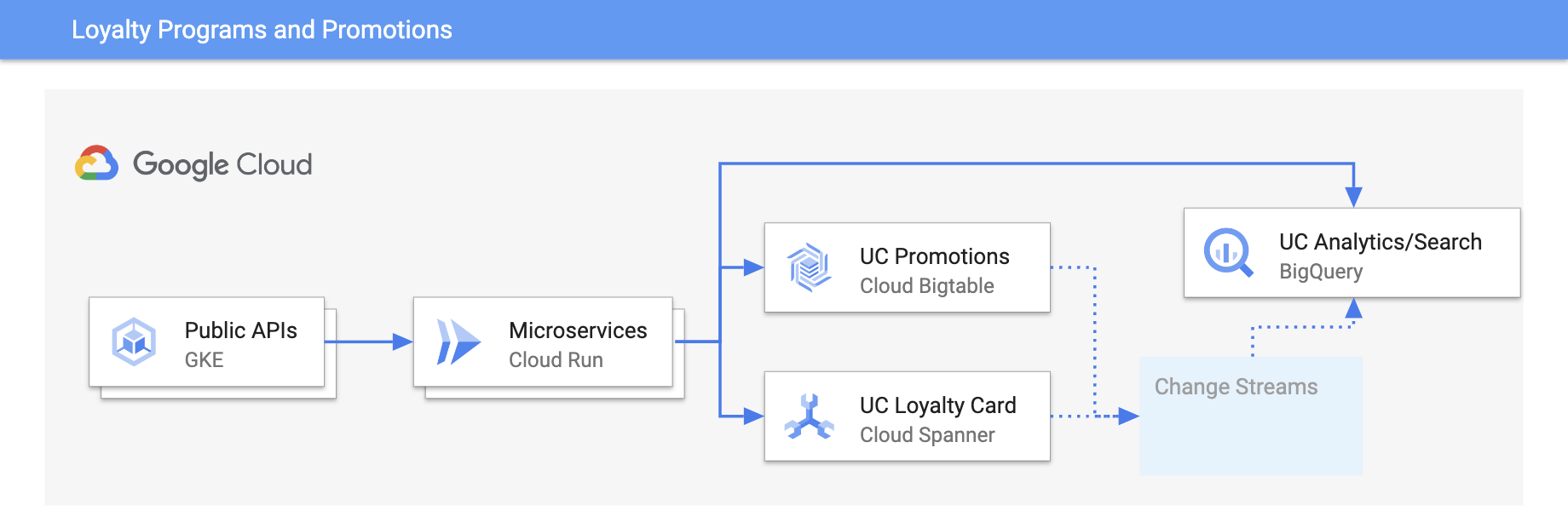
Acompanhe a participação e as preferências dos clientes em um programa de fidelidade para analisar tendências e melhorar a satisfação dos clientes. Da mesma forma, as empresas de jogos usam o Spanner para criar placares personalizados em jogos.
Tutoriais, guias de início rápido e laboratórios
Personalize experiências com atualizações em tempo real
Personalize experiências com atualizações em tempo real
Acompanhe a participação e as preferências dos clientes em um programa de fidelidade para analisar tendências e melhorar a satisfação dos clientes. Da mesma forma, as empresas de jogos usam o Spanner para criar placares personalizados em jogos.
Gerenciamento de inventário omni-channel
Oferecer uma visualização consistente em vários canais e apps
Oferecer uma visualização consistente em vários canais e apps
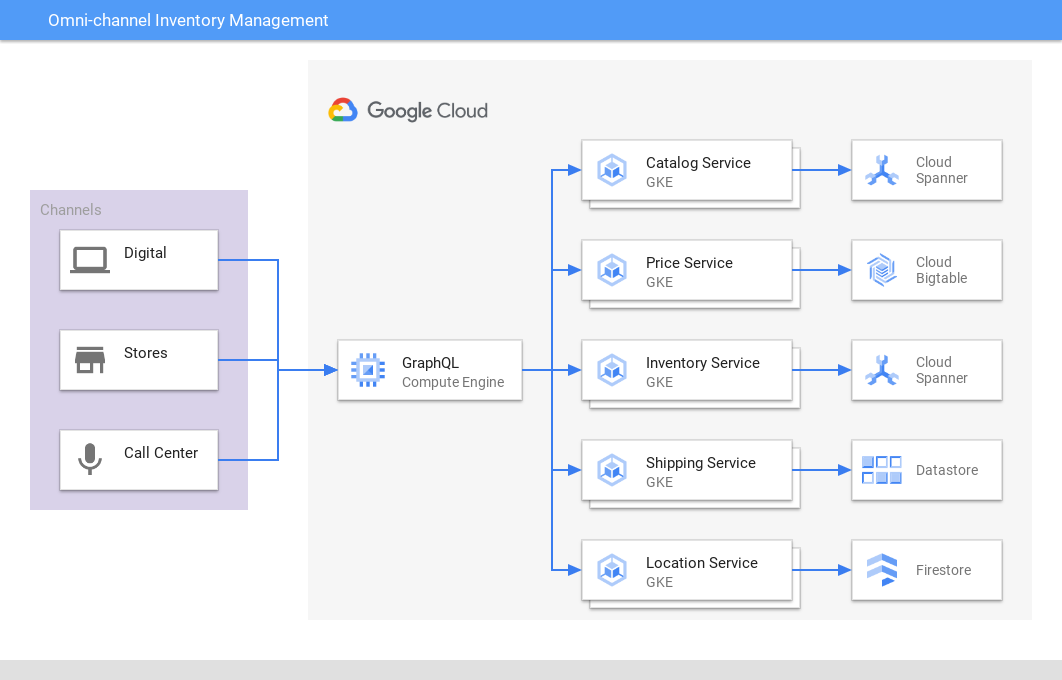
O Spanner fornece uma única fonte de informações confiáveis para inventário e pedidos de varejo on-line, na loja, centros de distribuição e frete para combinar o inventário com a demanda, melhorando a experiência do cliente e lucratividade. As empresas de jogos também usam o Spanner para armazenar dados de inventário no jogo.
Tutoriais, guias de início rápido e laboratórios
Oferecer uma visualização consistente em vários canais e apps
Oferecer uma visualização consistente em vários canais e apps
O Spanner fornece uma única fonte de informações confiáveis para inventário e pedidos de varejo on-line, na loja, centros de distribuição e frete para combinar o inventário com a demanda, melhorando a experiência do cliente e lucratividade. As empresas de jogos também usam o Spanner para armazenar dados de inventário no jogo.
Mapa de informações
Revele relações e conexões ocultas nos dados
Revele relações e conexões ocultas nos dados
Com o Spanner Graph, é possível desenvolver gráficos de informações que capturam as conexões complexas entre entidades, representadas como nós, e as relações delas, representadas como bordas. Essas conexões fornecem mais contexto, tornando os mapas de informações inestimáveis para o desenvolvimento de sistemas de base de conhecimento e mecanismos de recomendação. Com recursos de pesquisa integrados, você pode combinar perfeitamente a compreensão semântica, a recuperação baseada em palavras-chave e a criação de gráficos para resultados abrangentes.
Tutoriais, guias de início rápido e laboratórios
Revele relações e conexões ocultas nos dados
Revele relações e conexões ocultas nos dados
Com o Spanner Graph, é possível desenvolver gráficos de informações que capturam as conexões complexas entre entidades, representadas como nós, e as relações delas, representadas como bordas. Essas conexões fornecem mais contexto, tornando os mapas de informações inestimáveis para o desenvolvimento de sistemas de base de conhecimento e mecanismos de recomendação. Com recursos de pesquisa integrados, você pode combinar perfeitamente a compreensão semântica, a recuperação baseada em palavras-chave e a criação de gráficos para resultados abrangentes.
Preços
| Como funcionam os preços do Spanner | Os preços do Spanner são baseados na capacidade de computação, no Spanner Data Boost, no armazenamento do banco de dados, no armazenamento de backup, na replicação e no uso da rede. Os preços de computação variam de acordo com a edição e a configuração selecionadas. Os descontos por uso contínuo podem reduzir ainda mais o preço de computação. | |
|---|---|---|
| Serviço | Descrição | Preço (USD) |
Computação | Standard edition Com um pacote abrangente de recursos estabelecidos para configurações regionais (uma região) A capacidade de computação é provisionada como unidades de processamento ou nós (1 nó = 1.000 unidades de processamento). | A partir de US$ 0,030 por 100 unidades de processamento por hora por réplica |
Enterprise edition Ofereça mais recursos de pesquisa avançada e de vários modelos com mais simplicidade e eficiência operacionais A capacidade de computação é provisionada como unidades de processamento ou nós (1 nó = 1.000 unidades de processamento). | A partir de US$ 0,041 por 100 unidades de processamento por hora por réplica | |
Enterprise Plus edition Suporte às cargas de trabalho mais exigentes com os níveis mais altos de disponibilidade, desempenho, conformidade e governança A capacidade de computação é provisionada como unidades de processamento ou nós (1 nó = 1.000 unidades de processamento). | A partir de US$ 0,057 por 100 unidades de processamento por hora por réplica | |
Data Boost | Recursos de computação isolados e sob demanda, incluindo CPU, memória e transferência de dados local | A partir de US$ 0,00117 por unidade de processamento sem servidor por hora |
Armazenamento de banco de dados | O preço se baseia na quantidade de dados armazenados no banco de dados e inclui o custo de armazenamento em réplicas de leitura e gravação e de somente leitura. As réplicas testemunhas não têm custo financeiro. Armazenamento SSD Use o armazenamento em SSD quando precisar de baixa latência e alta capacidade de processamento de dados operacionais. | A partir de US$ 0,10 por GB por mês por réplica para SSD |
Armazenamento HDD Use o armazenamento em HDD para dados que precisam ser acessados com menos frequência e podem tolerar latências de leitura mais altas e menor capacidade de processamento. Também é possível configurar políticas de escalonamento para mover dados de SSD para HDD após a expiração de uma janela de tempo especificada. | A partir de US$ 0,02 por GB por mês por réplica para HDD | |
Armazenamento de backup | Configuração regional Os preços são baseados na quantidade de armazenamento de backup e incluem o custo de armazenamento em todas as réplicas. | A partir de US$ 0,10 por GB por mês (incluindo todas as réplicas) |
Configuração de birregional e multirregional Os preços são baseados na quantidade de armazenamento de backup e incluem o custo de armazenamento em todas as réplicas. | A partir de US$ 0,30 por GB por mês (incluindo todas as réplicas) | |
Replicação | Replicação intrarregional | Sem custo financeiro |
Replicação entre regiões | A partir de US$ 0,04 por GB | |
Rede | Entrada | Sem custo financeiro |
Saída intrarregional | Sem custo financeiro | |
Saída inter-regional | A partir de US$ 0,01 por GB | |
Saiba mais sobre os preços do Spanner e os descontos por compromisso de uso.
Como funcionam os preços do Spanner
Os preços do Spanner são baseados na capacidade de computação, no Spanner Data Boost, no armazenamento do banco de dados, no armazenamento de backup, na replicação e no uso da rede. Os preços de computação variam de acordo com a edição e a configuração selecionadas. Os descontos por uso contínuo podem reduzir ainda mais o preço de computação.
Computação
Standard edition
Com um pacote abrangente de recursos estabelecidos para configurações regionais (uma região)
A capacidade de computação é provisionada como unidades de processamento ou nós (1 nó = 1.000 unidades de processamento).
Starting at
US$ 0,030
por 100 unidades de processamento por hora por réplica
Enterprise edition
Ofereça mais recursos de pesquisa avançada e de vários modelos com mais simplicidade e eficiência operacionais
A capacidade de computação é provisionada como unidades de processamento ou nós (1 nó = 1.000 unidades de processamento).
Starting at
US$ 0,041
por 100 unidades de processamento por hora por réplica
Enterprise Plus edition
Suporte às cargas de trabalho mais exigentes com os níveis mais altos de disponibilidade, desempenho, conformidade e governança
A capacidade de computação é provisionada como unidades de processamento ou nós (1 nó = 1.000 unidades de processamento).
Starting at
US$ 0,057
por 100 unidades de processamento por hora por réplica
Data Boost
Recursos de computação isolados e sob demanda, incluindo CPU, memória e transferência de dados local
Starting at
US$ 0,00117
por unidade de processamento sem servidor por hora
Armazenamento de banco de dados
O preço se baseia na quantidade de dados armazenados no banco de dados e inclui o custo de armazenamento em réplicas de leitura e gravação e de somente leitura. As réplicas testemunhas não têm custo financeiro.
Armazenamento SSD
Use o armazenamento em SSD quando precisar de baixa latência e alta capacidade de processamento de dados operacionais.
Starting at
US$ 0,10
por GB por mês por réplica para SSD
Armazenamento HDD
Use o armazenamento em HDD para dados que precisam ser acessados com menos frequência e podem tolerar latências de leitura mais altas e menor capacidade de processamento. Também é possível configurar políticas de escalonamento para mover dados de SSD para HDD após a expiração de uma janela de tempo especificada.
Starting at
US$ 0,02
por GB por mês por réplica para HDD
Armazenamento de backup
Configuração regional
Os preços são baseados na quantidade de armazenamento de backup e incluem o custo de armazenamento em todas as réplicas.
Starting at
US$ 0,10
por GB por mês (incluindo todas as réplicas)
Configuração de birregional e multirregional
Os preços são baseados na quantidade de armazenamento de backup e incluem o custo de armazenamento em todas as réplicas.
Starting at
US$ 0,30
por GB por mês (incluindo todas as réplicas)
Replicação
Replicação intrarregional
Sem custo financeiro
Replicação entre regiões
Starting at
US$ 0,04
por GB
Rede
Entrada
Sem custo financeiro
Saída intrarregional
Sem custo financeiro
Saída inter-regional
Starting at
US$ 0,01
por GB
Saiba mais sobre os preços do Spanner e os descontos por compromisso de uso.
Caso de negócio
Veja como outras empresas criaram apps inovadores para entregar ótimas experiências aos clientes, reduzir custos e aumentar o ROI com o Spanner.
- O estudo Total Economic Impact™ da Forrester mostra que o Spanner oferece um ROI de 132%, um período de retorno de investimento de 9 meses e benefícios de vários milhões de dólares para uma organização mista representativa. Baixe o estudo completo para saber mais.
- O Gartner® identifica 13 recursos críticos para bancos de dados operacionais e classifica o Spanner como o número 1 no caso de uso de transações leves. Veja o relatório completo.

Como o Uber é escalonado para milhões de solicitações simultâneas?
Veja como a Uber reformulou a plataforma de atendimento usando o Spanner.



Benefícios e clientes em destaque
Expanda seus negócios com aplicativos inovadores que são escalonados sem limites para atender a qualquer demanda.
Reduza o TCO e libere os desenvolvedores de operações complicadas para sonhar alto e criar mais rápido.
Tenha um excelente desempenho por preço e pague pelo que usar, a partir de US $40 por mês.















Parceiros e integração
Aproveite os parceiros que têm experiência com o Spanner para ajudar você em todas as etapas da jornada, desde avaliações e casos de negócios até migrações e criação de novos aplicativos no Spanner.












Integradores de sistemas
Os parceiros do Spanner ajudam você a modernizar aplicativos e migrar para a nuvem sem complicações. Encontre seu parceiro ideal ou integração de terceiros em nosso diretório.
Outros recursos e suporte
Perguntas frequentes
O Spanner é um banco de dados relacional ou não relacional?
O Spanner simplifica sua arquitetura de dados reunindo cargas de trabalho relacionais, de chave-valor, de gráficos e de pesquisa vetorial, tudo no mesmo banco de dados. Ele é um banco de dados altamente escalonável que combina escalonabilidade ilimitada com semântica relacional, como índices secundários, consistência forte, esquemas e SQL, fornecendo 99,999% de disponibilidade em uma solução fácil. Portanto, ele é adequado para cargas de trabalho relacionais e não relacionais.
O que é o Spanner Omni?
O Spanner Omni é uma versão para download do Spanner que oferece os mesmos recursos básicos com a flexibilidade adicional para os clientes implantarem em qualquer lugar. Para saber mais, acesse https://cloud.google.com/products/spanner/omni
O Spanner usa SQL?
O Spanner oferece dois dialetos SQL baseados em ANSI sobre o mesmo conjunto avançado de recursos: GoogleSQL e PostgreSQL. O GoogleSQL compartilha sintaxe com o BigQuery para equipes que padronizam os fluxos de trabalho de gerenciamento de dados. A interface do PostgreSQL proporciona familiaridade às equipes que já conhecem o PostgreSQL e à portabilidade de esquemas e consultas para outros ambientes do PostgreSQL. Consulte mais informações sobre a interface PostgreSQL do Spanner na documentação.
Como faço para migrar bancos de dados para o Spanner?
A migração de cargas de trabalho atuais para o Spanner garante uma base para o crescimento futuro, sem comprometer a confiabilidade ou o custo-benefício. A interface multimodelo do Spanner é usada hoje por organizações inovadoras de vários setores com cargas de trabalho operacionais provenientes de bancos de dados relacionais, como MySQL e SQL Server, armazenamentos de chave-valor, como Cassandra ou DynamoDB, além de ferramentas de gráfico, pesquisa e documentos. A abordagem específica para uma migração depende dos requisitos relacionados ao volume de dados, aos SLOs de desempenho e à disponibilidade. A ferramenta de migração do Spanner oferece avaliação completa, migração de esquema e dados e transações com pouco tempo de inatividade para bancos de dados fragmentados do MySQL e do Cassandra, além de avaliação e migração para o PostgreSQL. Uma rede qualificada de parceiros de tecnologia e serviços pode acelerar as migrações de praticamente qualquer origem.
Quais são as principais considerações para operar o Spanner?
O Spanner é um banco de dados totalmente gerenciado. Portanto, ele fornece automaticamente recursos abrangentes de gerenciamento de infraestrutura, mas algumas ações de gerenciamento específicas do aplicativo podem ser necessárias, dependendo da carga de trabalho. Verifique se você configurou alertas e monitoramento adequados e se está prestando atenção para garantir que a produção esteja sendo executada sem problemas. Você precisa entender quais ações precisam ser tomadas quando o tráfego crescer organicamente ao longo do tempo ou se houver pico de tráfego esperado, ou como lidar com a corrupção de dados devido a bugs de aplicativos e, por último, mas não menos importante, como solucionar problemas de desempenho e entender quais componentes são responsáveis por maiores latências.


















