
Spanner
Immer aktive Datenbank mit praktisch unbegrenzter Skalierung
Erstellen Sie intelligente, geschäftskritische Anwendungen mit einer einzigen Datenbank, die relationale, Graph-, Schlüssel/Wert-Paar- und Suchfunktionen vereint. Mit Spanner Omni überall ausführbar.
Starten Sie mit einer kostenlosen 90-tägigen Testinstanz.
Features
Mehrere Modelle: eine Datenbank, viele Möglichkeiten
Mit den Multi-Modell-Funktionen von Spanner können Sie intelligente, KI-basierte Anwendungen auf der Grundlage Ihrer relationalen und NoSQL-Betriebsdaten erstellen. Dazu nutzen Sie die native Einbindung in die Gemini Enterprise Agent Platform, Spanner Graph für das Abfragen komplexer Beziehungen, die Vektorsuche für die semantische Suche und die integrierte Volltextsuche – und das alles mit „echter ZeroETL“-Interoperabilität. Dieser einheitliche Ansatz beseitigt Datensilos, schmälert Kosten, reduziert operative und Sicherheits-Touchpoints und sorgt für Datenkonsistenz in allen Modellen.

Grundlage für agentische KI-Anwendungen
Nahtlose Einbindung in die Gemini Enterprise Agent Platform, um die neuesten Gemini-Modelle zu nutzen. Mit dem Agent Development Kit (ADK) können Sie die Produktivität von KI-Entwicklern maximieren und autonome KI-Agenten erstellen, die den Betriebsstatus in Echtzeit analysieren. Sie können sich mit Plattformen für Vibe Coding wie Gemini CLI in natürlicher Sprache mit Ihren Daten in Spanner unterhalten, indem Sie remote MCP-Server verwenden. Nutzen Sie KI-Funktionen in Cloud Spanner, um komplexe semantische Operationen direkt in SQL auszuführen und so die Intelligenz näher an Ihre Daten zu bringen. Mit der konversationellen Analyse für Spanner können Sie sich in natürlicher Sprache mit KI-Agenten über Ihre Datenbankdaten unterhalten. Das Data Agent Kit optimiert Ihre Workflows, indem es sichere Model Context Protocol (MCP)-Tools, native IDE-Plug-ins und vorkodierte Data-Engineering-, Data-Science- und Data App-Entwicklerfähigkeiten in einem einzigen Open-Source-Paket bündelt.

Überall ausführbar
Spanner Omni ist eine herunterladbare Version von Spanner, der global verteilten Multimodell-Datenbank von Google Cloud. Sie profitieren von der branchenführenden Skalierbarkeit, Hochverfügbarkeit und starken globalen Konsistenz von Spanner in Ihrer Infrastruktur – lokal, in verschiedenen Clouds oder auf Ihrem Laptop. Spanner Omni ist die ideale Lösung, wenn Sie cloudübergreifende Ausfallsicherheit oder eine Scale-out-Datenbank benötigen, die außerhalb von Google Cloud betrieben wird, um Ihre agentischen KI-Anwendungen zu unterstützen.

Echtzeit-Einblicke in Geschäftsgeschwindigkeit
Beseitigen Sie die Silos zwischen Betriebs- und Analysedaten. Die integrierte spaltenbasierte Engine von Spanner ermöglicht Ihnen die Durchführung von leistungsstarken Ad-hoc-Analysen von Live-Daten, ohne den Transaktionsdurchsatz zu beeinträchtigen. Für eine detailliertere Analyse lässt sich Spanner nahtlos in Data Lakehouses wie BigQuery einbinden. Dabei können Sie föderierte Abfragen verwenden, um Daten in Spanner und BigQuery in Echtzeit zu analysieren, oder mit einem Klick Reverse-ETL nutzen, um Erkenntnisse aus Ihrem Lakehouse zurück in Spanner zu übertragen.

Einfache Skalierbarkeit
Groß denken, klein anfangen und bei Bedarf einfach aufstocken: Dank der horizontalen Skalierbarkeit von Lese- und Schreibvorgängen kann Cloud Spanner wachsende Datasets und anspruchsvolle Arbeitslasten nahtlos bewältigen. Die automatische Datenbankfragmentierung sorgt für eine optimale Datenverteilung, während die Geopartitionierung Daten näher an Ihre Nutzer heranbringt und so die Latenz verringert. Mit der von Arbeitslasten isolierten Abfrageverarbeitung von Spanner Data Boost profitieren Sie von einer konstant hohen Leistung, selbst bei Spitzenlasten.

Ständige Verfügbarkeit
Sorgen Sie dafür, dass Ihre Anwendungen immer aktiv und für Ihre Nutzer bereit sind. Cloud Spanner bietet eine Verfügbarkeit von bis zu 99,999 % mit automatisierter Wartung und flexiblen Bereitstellungsoptionen. Sie können zwischen Konfigurationen für eine, zwei oder mehrere Regionen wählen, um Ihre spezifischen Anforderungen an Verfügbarkeit und Fehlertoleranz zu erfüllen.

Absolut konsistente Transaktionen
Verabschieden Sie sich von Dateninkonsistenzen und der Komplexität ihrer Verwaltung. Cloud Spanner sorgt für transaktionale Konsistenz. Das bedeutet, dass jeder Lesevorgang die letzten Änderungen widerspiegelt, unabhängig von Größe und Verteilung der Daten. So können Sie Ihre Anwendungen mit der Gewissheit entwickeln, dass sie immer eine konsistente Sicht auf Ihre Daten haben.
Zuverlässige Sicherheit und Compliance
Mit Cloud Spanner vertrauen Sie Ihre Daten einer sicheren und konformen Plattform an. Mit dem Database Center profitieren Sie von einer zentralen Verwaltung und Steuerung, die die Datenbankverwaltung Ihrer Cloud-Datenbanken vereinfacht. Spanner bietet Sicherheit und Kontrollfunktionen auf Unternehmensniveau, darunter Verschlüsselung ruhender Daten und während der Übertragung, detaillierte Zugriffsverwaltung über Identity and Access Management (IAM) und die Einhaltung von Branchenstandards. Mit robusten Funktionen für die Sicherung und Wiederherstellung, einschließlich der Wiederherstellung zu einem bestimmten Zeitpunkt, können Sie Ihre Daten noch besser schützen.
Datenbankvergleich
| Datenbankattribut | Andere relationale Datenbank | Andere nicht relationale Datenbank | Spanner |
|---|---|---|---|
Schema | Statisch | Dynamisch | Dynamisch |
SQL | Ja | Nein | Ja (PostgreSQL, Google SQL) |
Transaktionen | ACID (Atomarität, Konsistenz, Isolation, Langlebigkeit) | Möglich | Striktes ACID mit TrueTime-Ordnung |
Skalierbarkeit | Vertikal (verwenden Sie einen größeren Computer) | Horizontal (weitere Computer hinzufügen) | Horizontal |
Verfügbarkeit | Failover (Ausfallzeit) | Hoch | Hohes 99,999% SLA |
Replikation | Konfigurierbar | Konfigurierbar | Automatisch |
Gartner® hat Spanner als beste Lösung für Anwendungsfälle mit einfachen Transaktionen eingestuft. Zum vollständigen Bericht.
Schema
Statisch
Dynamisch
Dynamisch
SQL
Ja
Nein
Ja
(PostgreSQL, Google SQL)
Transaktionen
ACID
(Atomarität, Konsistenz, Isolation, Langlebigkeit)
Möglich
Striktes ACID
mit TrueTime-Ordnung
Skalierbarkeit
Vertikal
(verwenden Sie einen größeren Computer)
Horizontal
(weitere Computer hinzufügen)
Horizontal
Verfügbarkeit
Failover (Ausfallzeit)
Hoch
Hohes 99,999% SLA
Replikation
Konfigurierbar
Konfigurierbar
Automatisch
Gartner® hat Spanner als beste Lösung für Anwendungsfälle mit einfachen Transaktionen eingestuft. Zum vollständigen Bericht.
Funktionsweise
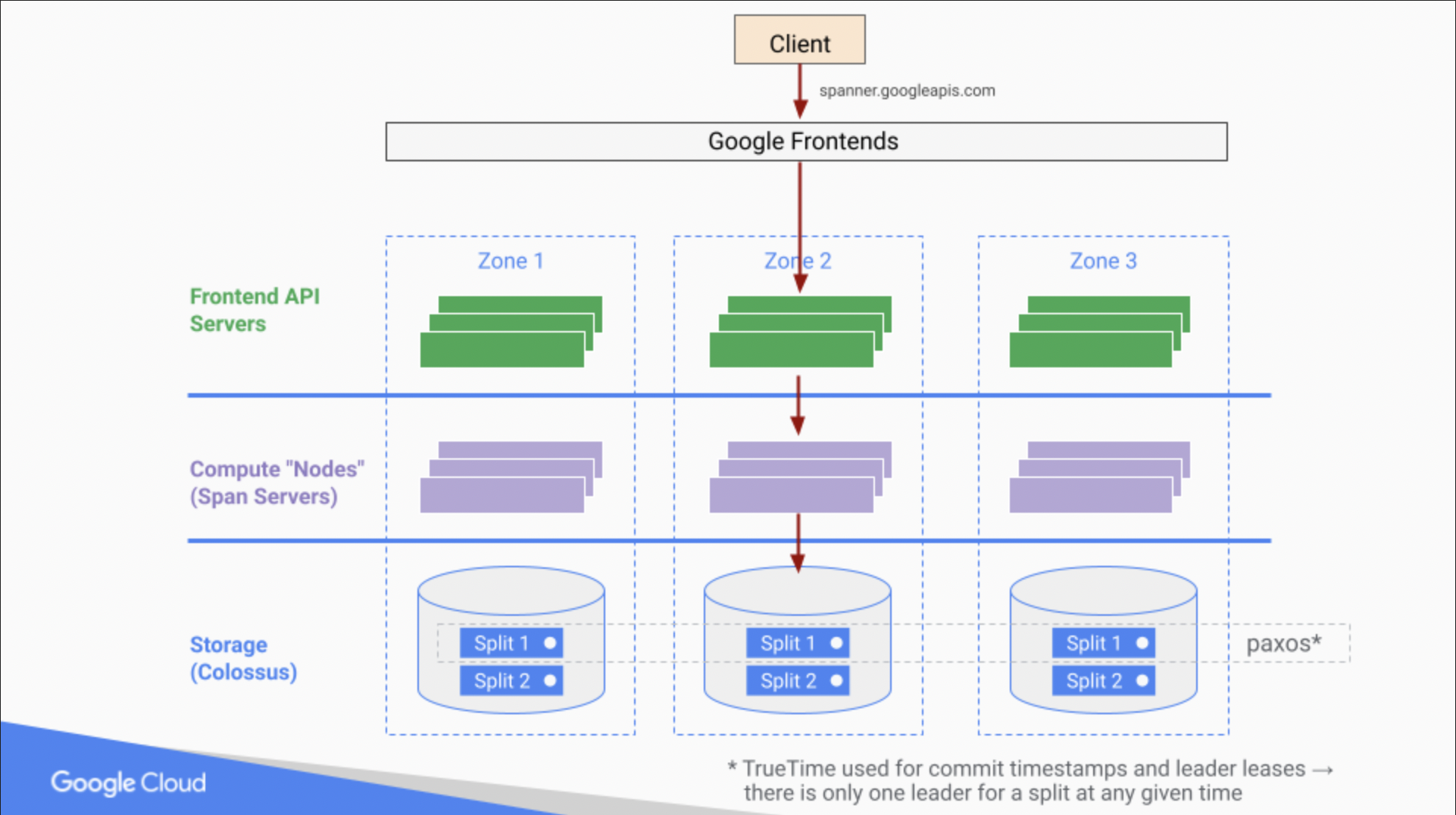
Cloud Spanner-Instanzen bieten Rechen- und Speicherressourcen in einer oder mehreren Regionen. Eine verteilte Uhr namens TrueTime sorgt dafür, dass Transaktionen auch über Regionen hinweg strikt konsistent sind. Daten werden aus Gründen der Skalierbarkeit automatisch „geteilt“ und mit einem synchronen Paxos-basierten Schema für die Verfügbarkeit repliziert.
Cloud Spanner-Instanzen bieten Rechen- und Speicherressourcen in einer oder mehreren Regionen. Eine verteilte Uhr namens TrueTime sorgt dafür, dass Transaktionen auch über Regionen hinweg strikt konsistent sind. Daten werden aus Gründen der Skalierbarkeit automatisch „geteilt“ und mit einem synchronen Paxos-basierten Schema für die Verfügbarkeit repliziert.
Migration und Modernisierung
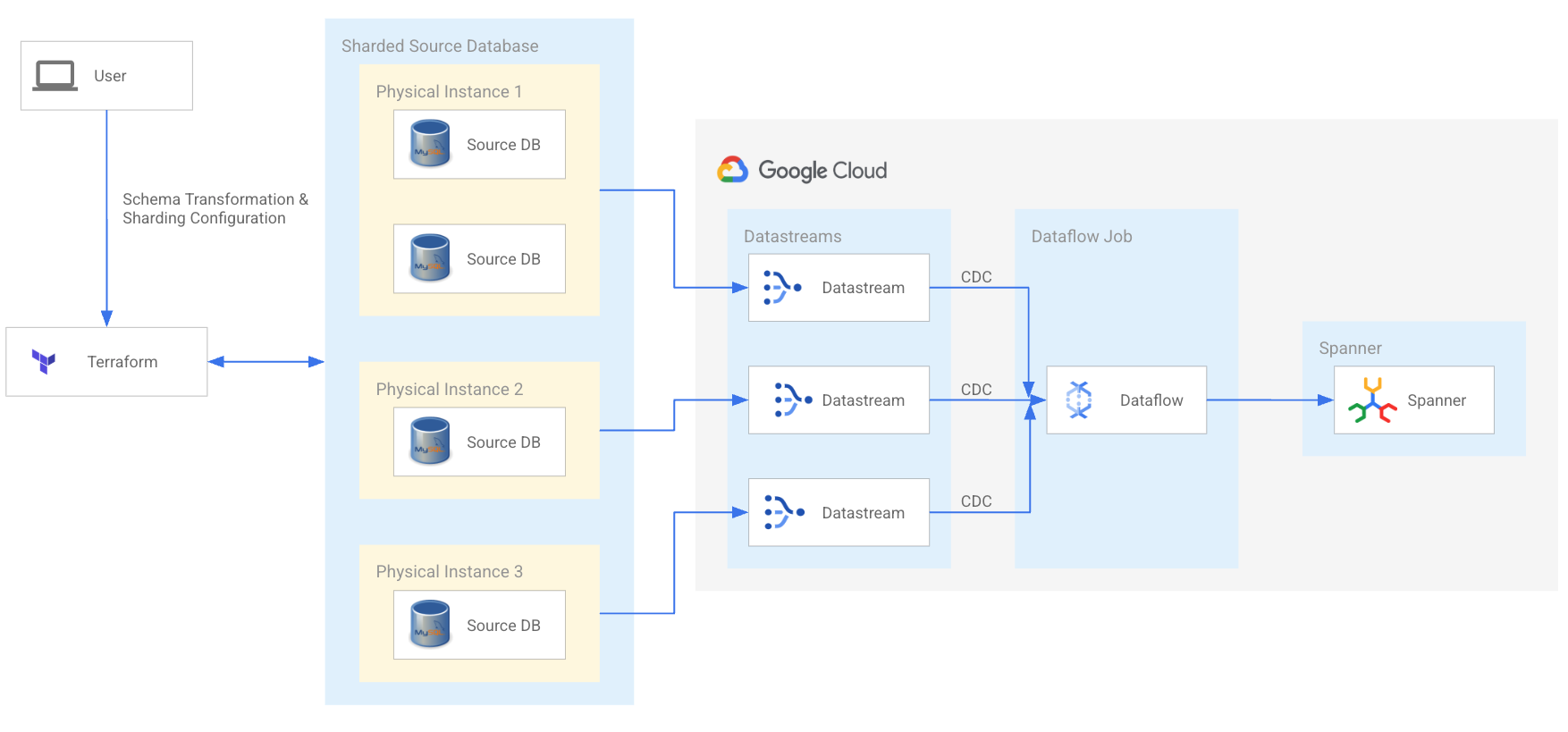
MySQL- und Cassandra-Modernisierung optimieren
MySQL- und Cassandra-Modernisierung optimieren
Modernisieren Sie Ihre fragmentierten MySQL- und Cassandra-Arbeitslasten, um Ihre Entwicklungsteams zu unterstützen und für die nächste Wachstumsphase zu skalieren. Nutzen Sie das Open-Source-Migrationstool für Cloud Spanner und ein Netzwerk qualifizierter Dienstleistungs- und Technologiepartner, um Ihre Migration zu optimieren.
Tutorials, Kurzanleitungen und Labs
MySQL- und Cassandra-Modernisierung optimieren
MySQL- und Cassandra-Modernisierung optimieren
Modernisieren Sie Ihre fragmentierten MySQL- und Cassandra-Arbeitslasten, um Ihre Entwicklungsteams zu unterstützen und für die nächste Wachstumsphase zu skalieren. Nutzen Sie das Open-Source-Migrationstool für Cloud Spanner und ein Netzwerk qualifizierter Dienstleistungs- und Technologiepartner, um Ihre Migration zu optimieren.
Ausfallsicherheit in Hybrid- und Multi-Cloud-Umgebungen
Geschäftskontinuität in verschiedenen Umgebungen gewährleisten
Geschäftskontinuität in verschiedenen Umgebungen gewährleisten
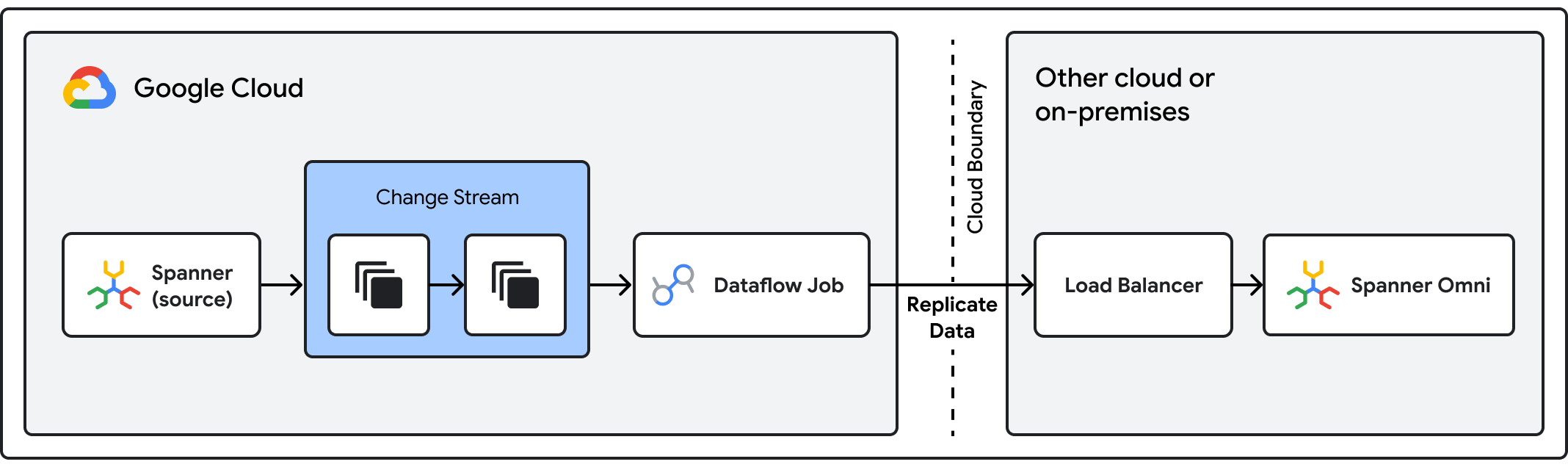
Sie können wirklich ausfallsichere Architekturen mit hoher Verfügbarkeit erstellen, die über die Grenzen eines einzelnen Cloud-Anbieters hinausgehen. Wenn Sie Spanner Omni in einer sekundären Cloud oder einem lokalen Rechenzentrum als „Hot/Cold“-Failover-Standort für Ihren primären verwalteten Spanner-Dienst in Google Cloud bereitstellen, schaffen Sie ein wichtiges Sicherheitsnetz. Diese „Primär/Sekundär“-Architektur reduziert die Anfälligkeit für Dienstunterbrechungen und trägt dazu bei, die strengen regulatorischen Anforderungen für Finanzdienstleistungen zu erfüllen.
Tutorials, Kurzanleitungen und Labs
Geschäftskontinuität in verschiedenen Umgebungen gewährleisten
Geschäftskontinuität in verschiedenen Umgebungen gewährleisten
Sie können wirklich ausfallsichere Architekturen mit hoher Verfügbarkeit erstellen, die über die Grenzen eines einzelnen Cloud-Anbieters hinausgehen. Wenn Sie Spanner Omni in einer sekundären Cloud oder einem lokalen Rechenzentrum als „Hot/Cold“-Failover-Standort für Ihren primären verwalteten Spanner-Dienst in Google Cloud bereitstellen, schaffen Sie ein wichtiges Sicherheitsnetz. Diese „Primär/Sekundär“-Architektur reduziert die Anfälligkeit für Dienstunterbrechungen und trägt dazu bei, die strengen regulatorischen Anforderungen für Finanzdienstleistungen zu erfüllen.
Nutzerprofil und Berechtigungen
Kritische Nutzerdaten sicher verwalten bei jeder Skalierung
Kritische Nutzerdaten sicher verwalten bei jeder Skalierung
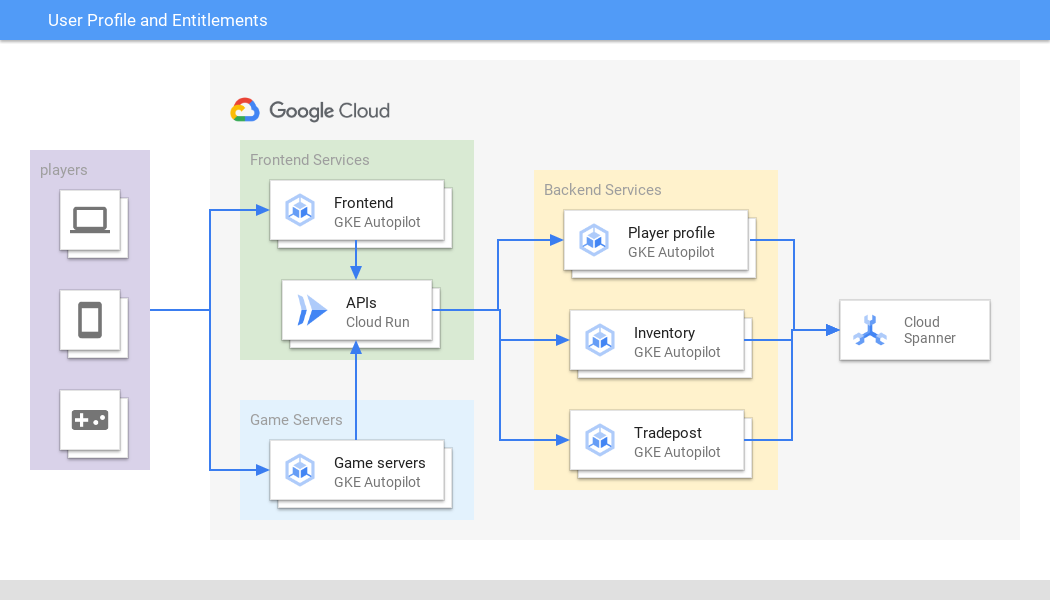
Die Nutzerprofilverwaltung ist eine wichtige Funktion, die die Skalierbarkeit, Verfügbarkeit und globale Konsistenz von Spanner erfordert. Sie ist der Einstiegspunkt für Spieler aus verschiedenen Spielen, Plattformen und Regionen. Ähnlich verwalten Finanzdienstleister Kundendaten und Produktangebote über Spanner.
Tutorials, Kurzanleitungen und Labs
Kritische Nutzerdaten sicher verwalten bei jeder Skalierung
Kritische Nutzerdaten sicher verwalten bei jeder Skalierung
Die Nutzerprofilverwaltung ist eine wichtige Funktion, die die Skalierbarkeit, Verfügbarkeit und globale Konsistenz von Spanner erfordert. Sie ist der Einstiegspunkt für Spieler aus verschiedenen Spielen, Plattformen und Regionen. Ähnlich verwalten Finanzdienstleister Kundendaten und Produktangebote über Spanner.
Finanzverzeichnis
Aktueller, einheitlicher Überblick über globale Transaktionen
Aktueller, einheitlicher Überblick über globale Transaktionen
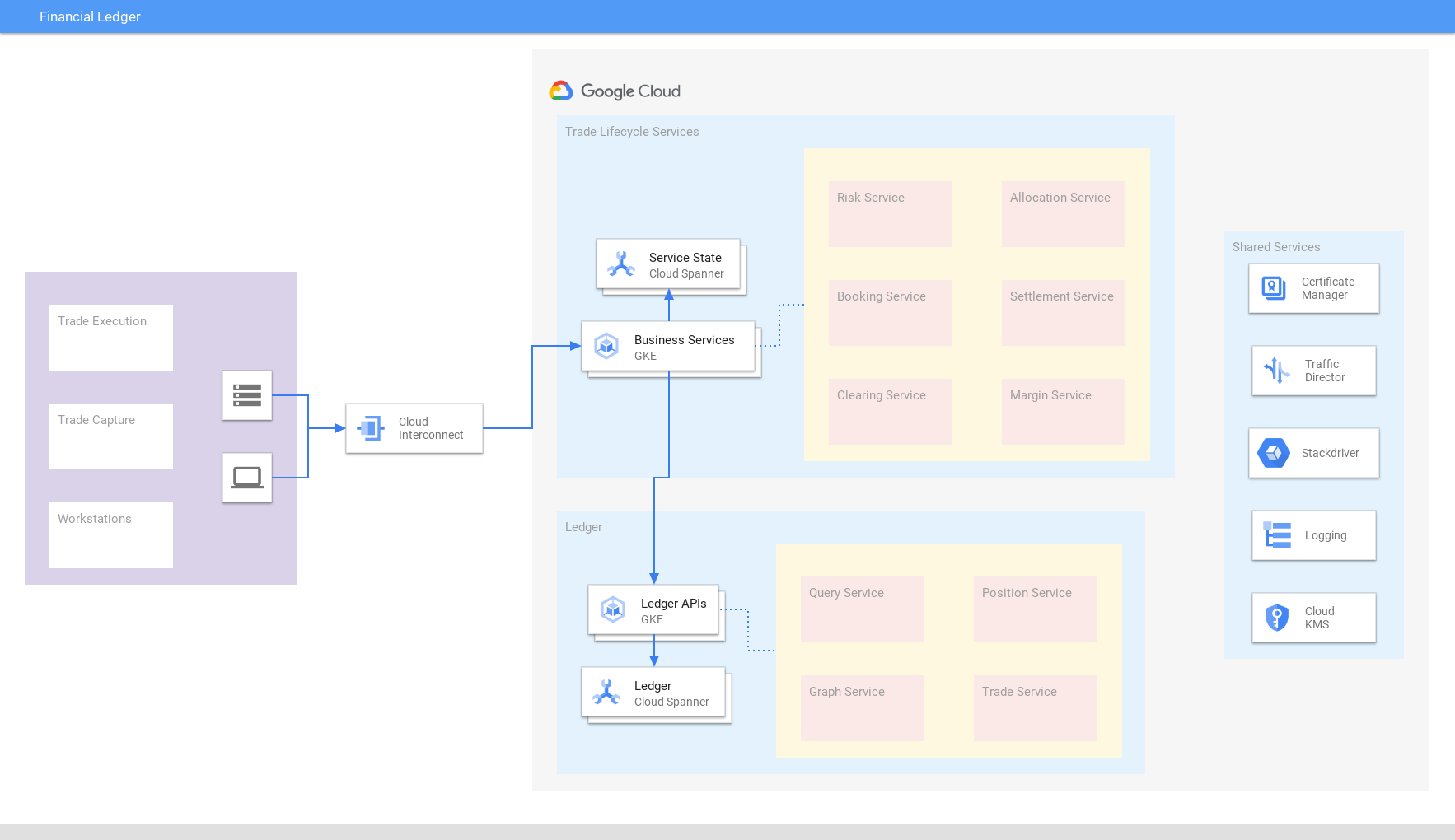
Führen Sie Finanztransaktionen, Handelsgeschäfte, Settlements und Positionen weltweit zu einem konsolidierten, in Cloud Spanner erstellten Handelsverzeichnis zusammen, das externe Konsistenz und Skalierbarkeit sicherstellt. Die Konsolidierung von Daten ermöglicht eine schnelle Anpassung an sich verändernde Marktbedingungen und behördliche Anforderungen. In ähnlicher Weise verwenden Einzelhandels-/E-Commerce-Unternehmen Spanner für das Inventar-Verzeichnis.
Tutorials, Kurzanleitungen und Labs
Aktueller, einheitlicher Überblick über globale Transaktionen
Aktueller, einheitlicher Überblick über globale Transaktionen
Führen Sie Finanztransaktionen, Handelsgeschäfte, Settlements und Positionen weltweit zu einem konsolidierten, in Cloud Spanner erstellten Handelsverzeichnis zusammen, das externe Konsistenz und Skalierbarkeit sicherstellt. Die Konsolidierung von Daten ermöglicht eine schnelle Anpassung an sich verändernde Marktbedingungen und behördliche Anforderungen. In ähnlicher Weise verwenden Einzelhandels-/E-Commerce-Unternehmen Spanner für das Inventar-Verzeichnis.
Onlinebanking
Durchgehend aktive interaktive Funktionen für digitale Angebote bereitstellen
Durchgehend aktive interaktive Funktionen für digitale Angebote bereitstellen
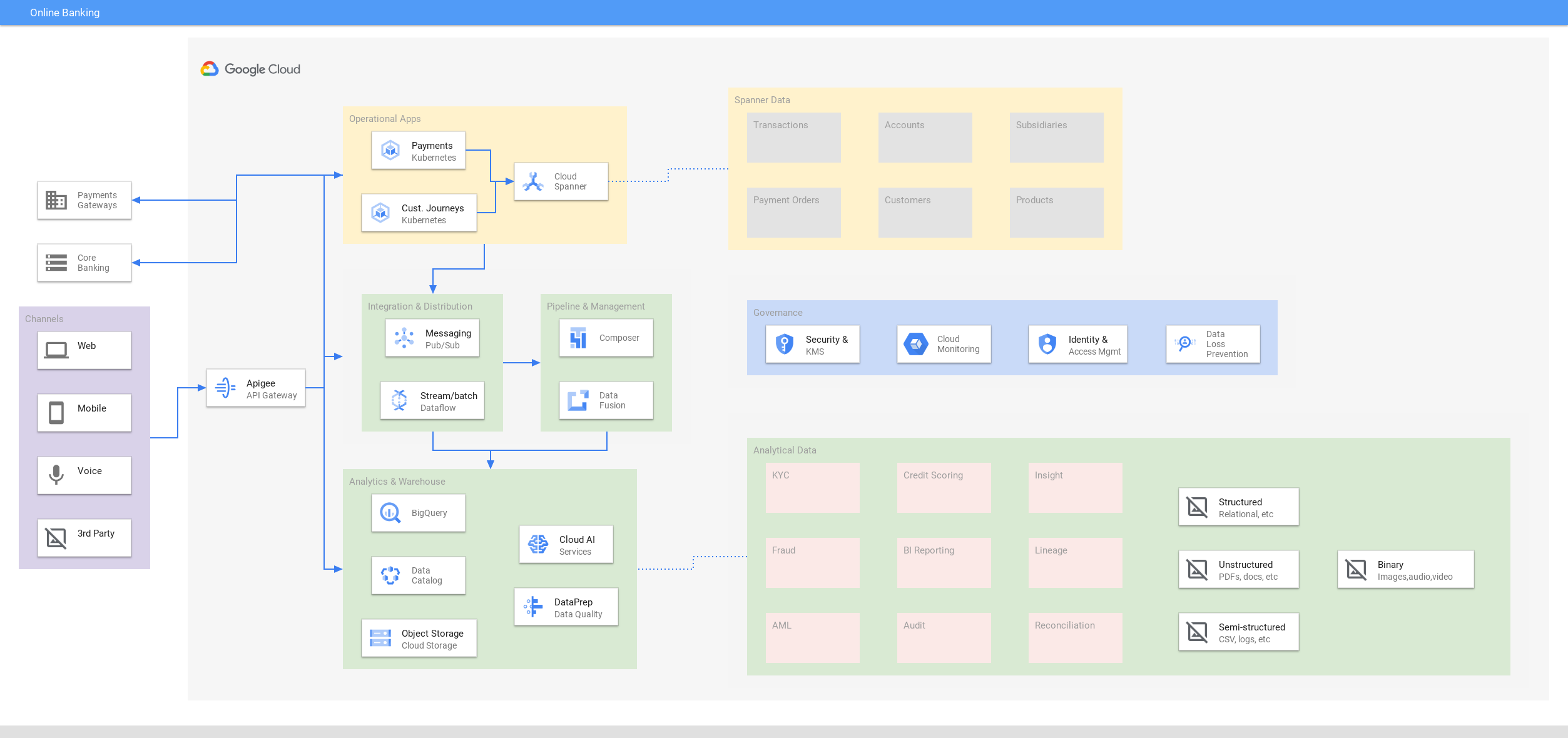
Nutzer erwarten außerhalb der üblichen Banking-Zeiten Zugriff auf ihre kritischen Finanzdaten auf ihren Geräten. So können sich Ihre Entwickler auf neue Umgebungen statt auf operativen Aufwand wie manuelle Fragmentierung oder Eventual Consistency konzentrieren. Reduzieren Sie Risiken und Ausfallzeiten mit einer Verfügbarkeit von 99,999 % und null Wartung.
Tutorials, Kurzanleitungen und Labs
Durchgehend aktive interaktive Funktionen für digitale Angebote bereitstellen
Durchgehend aktive interaktive Funktionen für digitale Angebote bereitstellen
Nutzer erwarten außerhalb der üblichen Banking-Zeiten Zugriff auf ihre kritischen Finanzdaten auf ihren Geräten. So können sich Ihre Entwickler auf neue Umgebungen statt auf operativen Aufwand wie manuelle Fragmentierung oder Eventual Consistency konzentrieren. Reduzieren Sie Risiken und Ausfallzeiten mit einer Verfügbarkeit von 99,999 % und null Wartung.
Treuepunkteprogramme und Werbeaktionen
Erlebnisse mit Echtzeit-Updates personalisieren
Erlebnisse mit Echtzeit-Updates personalisieren
Verfolgen Sie die Teilnahme und Präferenzen von Kunden in einem Treuepunkteprogramm, um Trends zu analysieren und die Kundenzufriedenheit zu verbessern. Ebenso verwenden Spieleunternehmen Cloud Spanner, um personalisierte Bestenlisten in Spielen zu erstellen.
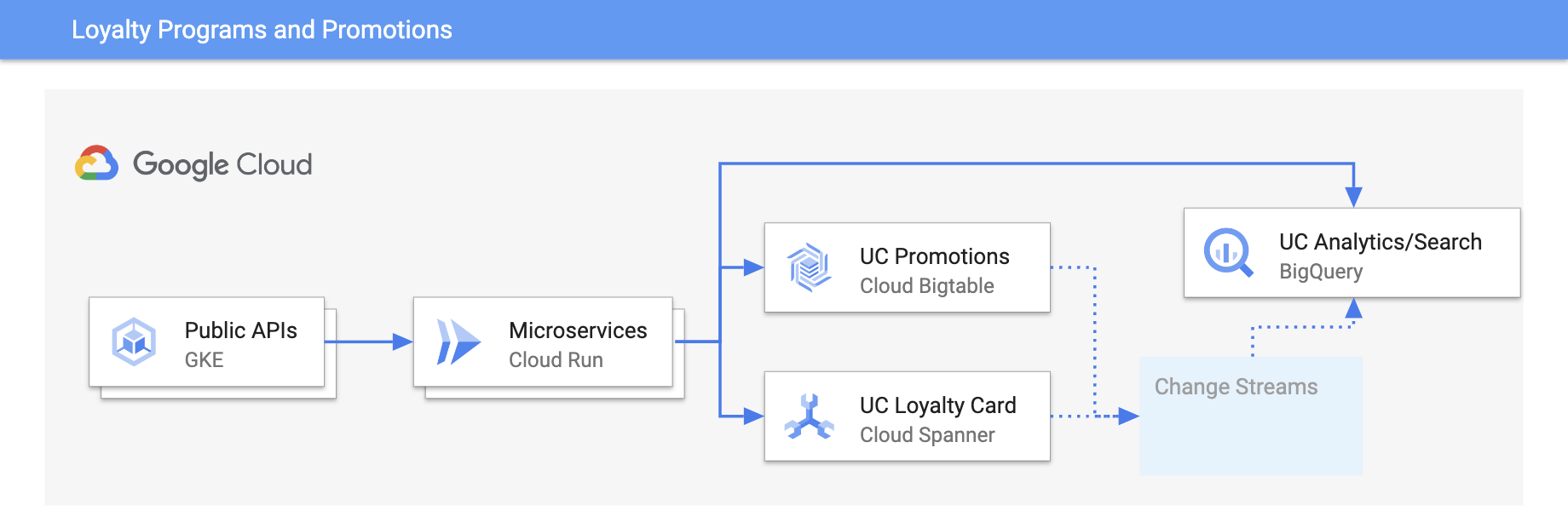
Tutorials, Kurzanleitungen und Labs
Erlebnisse mit Echtzeit-Updates personalisieren
Erlebnisse mit Echtzeit-Updates personalisieren
Verfolgen Sie die Teilnahme und Präferenzen von Kunden in einem Treuepunkteprogramm, um Trends zu analysieren und die Kundenzufriedenheit zu verbessern. Ebenso verwenden Spieleunternehmen Cloud Spanner, um personalisierte Bestenlisten in Spielen zu erstellen.
Omni-Channel-Inventarverwaltung
Einheitliche Ansicht über mehrere Kanäle und Apps hinweg
Einheitliche Ansicht über mehrere Kanäle und Apps hinweg
Cloud Spanner bietet eine leistungsstarke zentrale Informationsquelle für den Bestand und Bestellungen im Einzelhandel, sowohl online als auch im Ladengeschäft, in Vertriebszentren und beim Versand, um das Inventar mit der Nachfrage abzugleichen und die Kundenerfahrung und die Profitabilität zu verbessern. Spieleunternehmen nutzen Cloud Spanner zum Speichern von In-Game-Inventardaten.
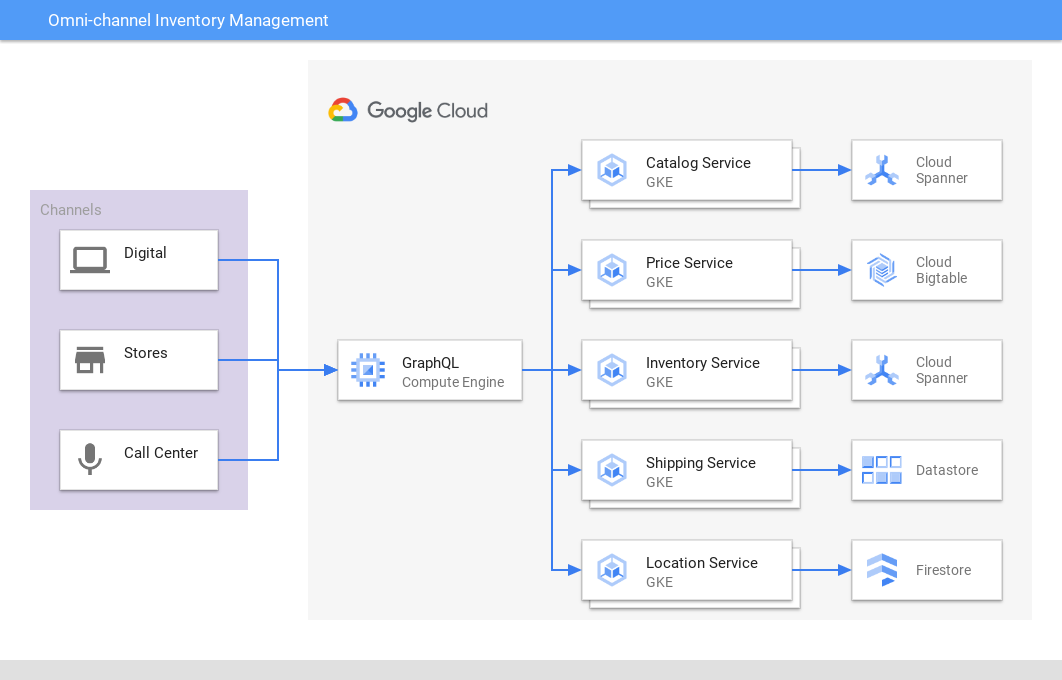
Tutorials, Kurzanleitungen und Labs
Einheitliche Ansicht über mehrere Kanäle und Apps hinweg
Einheitliche Ansicht über mehrere Kanäle und Apps hinweg
Cloud Spanner bietet eine leistungsstarke zentrale Informationsquelle für den Bestand und Bestellungen im Einzelhandel, sowohl online als auch im Ladengeschäft, in Vertriebszentren und beim Versand, um das Inventar mit der Nachfrage abzugleichen und die Kundenerfahrung und die Profitabilität zu verbessern. Spieleunternehmen nutzen Cloud Spanner zum Speichern von In-Game-Inventardaten.
Knowledge Graph
Verborgene Beziehungen und Verbindungen in Ihren Daten aufdecken
Verborgene Beziehungen und Verbindungen in Ihren Daten aufdecken
Mit Cloud Spanner Graph können Sie Knowledge Graphs entwickeln, die die komplexen Verbindungen zwischen Entitäten in Form von Knoten und deren Beziehungen als Kanten erfassen. Diese Verbindungen liefern einen umfassenden Kontext, wodurch Knowledge Graphs für die Entwicklung von Wissensdatenbanksystemen und Empfehlungssystemen von unschätzbarem Wert sind. Dank integrierten Suchfunktionen können Sie semantisches Verständnis, stichwortbasiertes Abrufen und Graph nahtlos kombinieren, um umfassende Ergebnisse zu erhalten.
Tutorials, Kurzanleitungen und Labs
Verborgene Beziehungen und Verbindungen in Ihren Daten aufdecken
Verborgene Beziehungen und Verbindungen in Ihren Daten aufdecken
Mit Cloud Spanner Graph können Sie Knowledge Graphs entwickeln, die die komplexen Verbindungen zwischen Entitäten in Form von Knoten und deren Beziehungen als Kanten erfassen. Diese Verbindungen liefern einen umfassenden Kontext, wodurch Knowledge Graphs für die Entwicklung von Wissensdatenbanksystemen und Empfehlungssystemen von unschätzbarem Wert sind. Dank integrierten Suchfunktionen können Sie semantisches Verständnis, stichwortbasiertes Abrufen und Graph nahtlos kombinieren, um umfassende Ergebnisse zu erhalten.
Preise
| Spanner-Preise | Die Preise für Spanner basieren auf der Rechenkapazität, dem Spanner Data Boost, dem Datenbankspeicher, dem Sicherungsspeicher, der Replikation und der Netzwerknutzung. Die Preise für Rechenressourcen variieren je nach gewählter Version und Konfiguration. Mit Rabatten für zugesicherte Nutzung können Sie den Preis für Computing-Ressourcen weiter senken. | |
|---|---|---|
| Dienst | Beschreibung | Preis (in $) |
Computing | Standard Edition Umfassende Suite bewährter Funktionen für regionale (Einzelregion-)Konfigurationen Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten). | Ab 0,030 $ pro 100 Verarbeitungseinheiten pro Stunde und Replikat |
Enterprise Edition Zusätzliche Multi-Modell- und erweiterte Suchfunktionen mit verbesserter operativer Einfachheit und Effizienz Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten). | Ab 0,041 $ pro 100 Verarbeitungseinheiten pro Stunde und Replikat | |
Enterprise Plus Edition Unterstützen Sie selbst die anspruchsvollsten Arbeitslasten mit höchster Verfügbarkeit, Leistung, Compliance und Governance. Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten). | Ab 0,057 $ pro 100 Verarbeitungseinheiten pro Stunde und Replikat | |
Data Boost | Isolierte On-Demand-Computing-Ressourcen, einschließlich CPU, Arbeitsspeicher und lokaler Datenübertragung | Ab 0,00117 $ pro serverloser Verarbeitungseinheit und Stunde |
Datenbankspeicher | Die Preise richten sich nach der in der Datenbank gespeicherten Datenmenge. Sie beinhalten die Speicherkosten von Schreib-/Lese- und Lese-/Schreib-Replikaten. Zeugenreplikate sind kostenlos. SSD-Speicher Verwenden Sie SSD-Speicher, wenn Sie eine niedrige Latenz und einen hohen Durchsatz für Ihre Betriebsdaten benötigen. | Ab 0,10 $ pro GB und Monat pro Replikation für SSD |
HDD-Speicher Verwenden Sie HDD-Speicher für Daten, auf die seltener zugegriffen werden muss und für die eine höhere Leselatenz und ein geringerer Durchsatz tolerierbar sind. Sie können auch Richtlinien für Speicherebenen konfigurieren, um Daten nach Ablauf eines bestimmten Zeitfensters von SSD auf HDD zu verschieben. | Ab 0,02 $ pro GB und Monat pro Replikation für HDD | |
Sicherungsspeicher | Regionale Konfiguration Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate. | Ab 0,10 $ pro GB und Monat (inkl. aller Replikate) |
Dual-Region- und Multi-Region-Konfiguration Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate. | Ab 0,30 $ pro GB und Monat (inkl. aller Replikate) | |
Replikation | Intraregionale Replikation | Kostenlos |
Interregionale Replikation | Ab 0,04 $ pro GB | |
Netzwerk | Eingehender Traffic | Kostenlos |
Intra-regionaler ausgehender Traffic | Kostenlos | |
Interregionaler ausgehender Traffic | Ab 0,01 $ pro GB | |
Weitere Informationen zu den Cloud Spanner-Preisen und den Rabatten für zugesicherte Nutzung.
Spanner-Preise
Die Preise für Spanner basieren auf der Rechenkapazität, dem Spanner Data Boost, dem Datenbankspeicher, dem Sicherungsspeicher, der Replikation und der Netzwerknutzung. Die Preise für Rechenressourcen variieren je nach gewählter Version und Konfiguration. Mit Rabatten für zugesicherte Nutzung können Sie den Preis für Computing-Ressourcen weiter senken.
Computing
Standard Edition
Umfassende Suite bewährter Funktionen für regionale (Einzelregion-)Konfigurationen
Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten).
Starting at
0,030 $
pro 100 Verarbeitungseinheiten pro Stunde und Replikat
Enterprise Edition
Zusätzliche Multi-Modell- und erweiterte Suchfunktionen mit verbesserter operativer Einfachheit und Effizienz
Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten).
Starting at
0,041 $
pro 100 Verarbeitungseinheiten pro Stunde und Replikat
Enterprise Plus Edition
Unterstützen Sie selbst die anspruchsvollsten Arbeitslasten mit höchster Verfügbarkeit, Leistung, Compliance und Governance.
Rechenkapazität wird als Verarbeitungseinheiten oder Knoten bereitgestellt (1 Knoten = 1.000 Verarbeitungseinheiten).
Starting at
0,057 $
pro 100 Verarbeitungseinheiten pro Stunde und Replikat
Data Boost
Isolierte On-Demand-Computing-Ressourcen, einschließlich CPU, Arbeitsspeicher und lokaler Datenübertragung
Starting at
0,00117 $
pro serverloser Verarbeitungseinheit und Stunde
Datenbankspeicher
Die Preise richten sich nach der in der Datenbank gespeicherten Datenmenge. Sie beinhalten die Speicherkosten von Schreib-/Lese- und Lese-/Schreib-Replikaten. Zeugenreplikate sind kostenlos.
SSD-Speicher
Verwenden Sie SSD-Speicher, wenn Sie eine niedrige Latenz und einen hohen Durchsatz für Ihre Betriebsdaten benötigen.
Starting at
0,10 $
pro GB und Monat pro Replikation für SSD
HDD-Speicher
Verwenden Sie HDD-Speicher für Daten, auf die seltener zugegriffen werden muss und für die eine höhere Leselatenz und ein geringerer Durchsatz tolerierbar sind. Sie können auch Richtlinien für Speicherebenen konfigurieren, um Daten nach Ablauf eines bestimmten Zeitfensters von SSD auf HDD zu verschieben.
Starting at
0,02 $
pro GB und Monat pro Replikation für HDD
Sicherungsspeicher
Regionale Konfiguration
Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate.
Starting at
0,10 $
pro GB und Monat (inkl. aller Replikate)
Dual-Region- und Multi-Region-Konfiguration
Die Preise richten sich nach der Menge des Sicherungsspeichers. Sie beinhalten die Speicherkosten aller Replikate.
Starting at
0,30 $
pro GB und Monat (inkl. aller Replikate)
Replikation
Intraregionale Replikation
Kostenlos
Interregionale Replikation
Starting at
0,04 $
pro GB
Netzwerk
Eingehender Traffic
Kostenlos
Intra-regionaler ausgehender Traffic
Kostenlos
Interregionaler ausgehender Traffic
Starting at
0,01 $
pro GB
Weitere Informationen zu den Cloud Spanner-Preisen und den Rabatten für zugesicherte Nutzung.
Anwendungsszenario
Erfahren Sie, wie andere Unternehmen mit Spanner innovative Apps entwickelt haben, um eine hervorragende Nutzererfahrung zu bieten, die Kosten zu senken und den ROI zu steigern.
- Die Total Economic Impact™-Studie von Forrester zeigt, dass Spanner einen ROI von 132 % und eine Amortisierungszeit von 9 Monaten bietet und einem repräsentativen Modellunternehmen Vorteile in Millionenhöhe verschafft. Laden Sie die Studie herunter, um mehr zu erfahren.
- Gartner® nennt 13 wichtige Funktionen für operative Datenbanken und stuft Spanner als beste Lösung für Anwendungsfälle mit einfachen Transaktionen ein. Zum vollständigen Bericht.

So skaliert Uber auf Millionen von gleichzeitigen Anfragen
So hat Uber seine Plattform für die Auftragsausführung mithilfe von Spanner neu gestaltet.



Vorteile und Kunden
Bauen Sie Ihr Unternehmen aus mit innovativen Anwendungen, die sich unbegrenzt skalieren lassen, um alle Anforderungen zu erfüllen.
Geringere Gesamtbetriebskosten und Ihre Entwickler müssen nicht schwerfällige Abläufe bewältigen, sodass sie groß träumen und schneller entwickeln können.
Hervorragendes Preis-Leistungs-Verhältnis und zahlen Sie für nur das, was Sie nutzen – schon ab 40 $ pro Monat.















Partner und Integration
Nutzen Sie Partner mit Spanner-Fachkenntnissen, um Sie bei jedem Schritt der Reise zu unterstützen – von Bewertungen und Anwendungsszenario bis hin zu Migrationen und der Entwicklung neuer Anwendungen auf Spanner.












Systemintegratoren
Spanner-Partner unterstützen Sie bei der Modernisierung von Anwendungen und der nahtlosen Migration in die Cloud. In unserem Verzeichnis finden Sie den idealen Partner oder die passende Drittanbieterintegration.
Weitere Ressourcen und Support
FAQs
Ist Cloud Spanner eine relationale oder eine nicht relationale Datenbank?
Cloud Spanner vereinfacht Ihre Datenarchitektur, indem es relationale, Schlüssel/Wert-Paar-, Graph- und Vektorsucharbeitslasten in einer einzigen Datenbank zusammenführt. Cloud Spanner ist eine hoch skalierbare Datenbank, die unbegrenzte Skalierbarkeit mit relationaler Semantik kombiniert. Dazu gehören sekundäre Indexe, strikte Konsistenz, Schemas und SQL, die eine Verfügbarkeit von 99,999 % in einer einfachen Lösung bieten. Daher ist es sowohl für relationale als auch für nicht relationale Arbeitslasten geeignet.
Was ist Spanner Omni?
Spanner Omni ist eine herunterladbare Version von Spanner, die dieselben Kernfunktionen bietet und Kunden die Flexibilität gibt, sie überall bereitzustellen. Weitere Informationen finden Sie unter https://cloud.google.com/products/spanner/omni.
Verwendet Cloud Spanner SQL?
Cloud Spanner bietet zwei ANSI-basierte SQL-Dialekte für denselben umfassenden Satz an Funktionen: GoogleSQL und PostgreSQL. Google SQL teilt Syntax mit BigQuery damit Teams ihre Workflows zur Datenverwaltung standardisieren können. Die PostgreSQL-Oberfläche bietet Vertrautheit für Teams, die PostgreSQL kennen, sowie die Portabilität von Schemas und Abfragen in andere PostgreSQL-Umgebungen. Weitere Informationen zur PostgreSQL-Oberfläche von Cloud Spanner finden Sie in der Dokumentation.
Wie migriere ich Datenbanken zu Spanner?
Durch die Migration vorhandener Arbeitslasten zu Spanner schaffen Sie die Grundlage für zukünftiges Wachstum, ohne Kompromisse bei Zuverlässigkeit oder Preis-Leistungs-Verhältnis eingehen zu müssen. Die Multimodell-Schnittstelle von Spanner wird heute von innovativen Unternehmen aus verschiedenen Branchen mit operativen Arbeitslasten verwendet, die aus relationalen Datenbanken wie MySQL und SQL Server, Key-Value-Speichern stammen, darunter Cassandra oder DynamoDB. Weiter kommen Graph-, Such- und Dokumententools zum Einsatz. Der konkrete Ansatz für eine Migration hängt von den Anforderungen an Datenvolumen, Leistungs-SLOs und Verfügbarkeit ab. Das Spanner-Migrationstool bietet End-to-End-Bewertungen, Schema- und Datenmigrationen, die Umstellung mit geringer Ausfallzeit für partitionierte MySQL- und Cassandra-Datenbanken sowie Bewertungen und Migrationen für PostgreSQL. Ein qualifiziertes Netzwerk von Technologie- und Servicepartnern kann Migrationen aus nahezu jeder Quelle beschleunigen.
Was sind die wichtigsten Überlegungen zum Einsatz von Spanner?
Spanner ist eine vollständig verwaltete Datenbank, die automatisch umfassende Features zur Infrastrukturverwaltung bereitstellt. Je nach Arbeitslast sind jedoch möglicherweise einige anwendungsspezifische Verwaltungsaktionen erforderlich. Sie müssen daher Benachrichtigungen und Monitoring ordnungsgemäß einrichten und diese genau beobachten, damit die Produktion immer reibungslos verläuft. Sie müssen wissen, welche Maßnahmen Sie ergreifen müssen, wenn der Traffic im Laufe der Zeit organisch zunimmt oder ob Sie Traffic-Spitzen erwarten. Außerdem müssen Sie wissen, wie Sie mit Datenbeschädigungen aufgrund von Anwendungsfehlern umgehen und wie Sie Leistungsprobleme beheben und Sie müssen verstehen, welche Komponenten für erhöhte Latenzen verantwortlich sind.


















