En este documento, se describe cómo consultar, ver y analizar entradas de registro con la consola de Google Cloud. Existen dos interfaces disponibles: el Explorador y el Análisis de registros. Puedes consultar, ver y analizar registros con ambas interfaces. Sin embargo, usan diferentes lenguajes de consulta y tienen capacidades diferentes. Para solucionar problemas y explorar datos de registro, te recomendamos usar el Explorador de registros. Para generar estadísticas y tendencias, te recomendamos que uses el Análisis de registros. Para consultar los registros y guardar tus consultas, emite los comandos de la API de Logging. También puedes consultar tus registros con Google Cloud CLI.
Explorador de registros
El Explorador de registros está diseñado para ayudarte a solucionar problemas y analizar el rendimiento de tus servicios y aplicaciones. Por ejemplo, en un histograma se muestra la tasa de errores. Si observas un aumento repentino de errores o algo interesante, puedes ubicar y ver las entradas de registro correspondientes. Cuando una entrada de registro se asocia con un grupo de errores, esta se anota con un menú de opciones que te permiten acceder a más información sobre el grupo de errores.
La API de Cloud Logging, Google Cloud CLI y el Explorador de registros admiten el mismo lenguaje de consulta. Para simplificar la construcción de consultas cuando usas el Explorador de registros, puedes crear consultas con menús, mediante la entrada de texto y, en algunos casos, con las opciones incluidas en la visualización de una entrada de registro individual.
El Explorador de registros no admite operaciones de agregación, como contar la cantidad de entradas de registro que contienen un patrón específico. Para realizar operaciones agregadas, habilita las estadísticas en el bucket de registros y, luego, usa el Análisis de registros.
Para obtener más información sobre cómo buscar y ver registros con el Explorador de registros, consulta Visualiza los registros con el Explorador de registros.
Análisis de registros
Con el Análisis de registros, puedes ejecutar consultas que analizan tus datos de registro y, luego, puedes ver o diagramar los resultados de la consulta. Los gráficos te permiten identificar patrones y tendencias en tus registros a lo largo del tiempo. En la siguiente captura de pantalla, se ilustran las capacidades de generación de gráficos en el Análisis de registros:
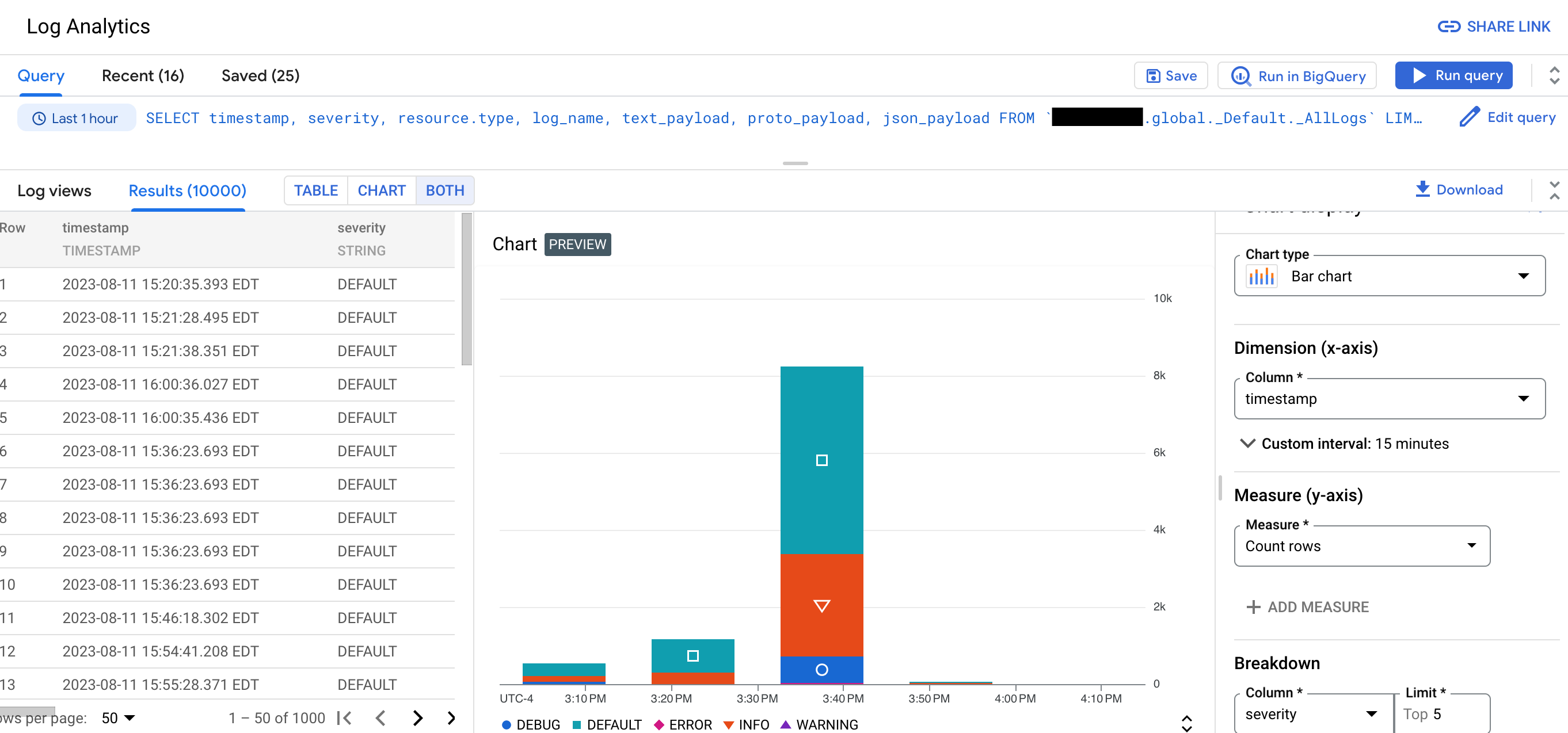
Por ejemplo, supongamos que estás solucionando un problema y deseas conocer la latencia promedio de las solicitudes HTTP enviadas a una URL específica a lo largo del tiempo. Cuando se actualiza un bucket de registros para usar el Análisis de registros, puedes usar consultas SQL para consultar los registros almacenados en tu bucket de registros. Si agrupas y agregas tus registros, puedes obtener estadísticas de tus datos de registro, lo que puede ayudarte a reducir el tiempo dedicado a solucionar problemas.
El Análisis de registros también te permite usar BigQuery para consultar tus datos. Por ejemplo, supongamos que deseas usar BigQuery para comparar las URL de tus registros con un conjunto de datos públicos de URL maliciosas conocidas. Si deseas que tus datos de registro sean visibles para BigQuery, actualiza tu bucket a fin de usar el Análisis de registros y, luego, crea un conjunto de datos vinculado.
Puedes seguir solucionando los problemas y ver entradas de registro individuales en buckets de registros actualizados con el Explorador de registros.
Restricciones
No todas las regiones son compatibles con el Análisis de registros. Para obtener más información, consulta Regiones admitidas.
Si quieres actualizar un bucket de registros existente para usar el Análisis de registros, se aplican las siguientes restricciones:
- El bucket de registros está desbloqueado, a menos que sea el bucket
_Required. - No hay actualizaciones pendientes para el bucket.
- No todas las regiones son compatibles con el Análisis de registros. Para obtener más información, consulta Regiones admitidas.
- El bucket de registros está desbloqueado, a menos que sea el bucket
En los buckets de registros que se actualizan para usar el Análisis de registros, no puedes realizar ninguna de las siguientes acciones:
- Se quitará la compatibilidad con el Análisis de registros.
Puedes borrar la vinculación a un conjunto de datos de BigQuery vinculado. Borrar el vínculo no cambia tu capacidad para consultar vistas en el bucket de registros con la página Análisis de registros.
Solo las entradas de registro escritas después de que se completó la actualización están disponibles para las estadísticas.
Precios
Cloud Logging no cobra por enrutar los registros a un destino compatible. Sin embargo, el destino puede aplicar cargos.
A excepción del bucket de registros _Required, Cloud Logging cobra por transmitir registros a buckets de registros y por el almacenamiento más largo que el período de retención predeterminado del bucket de registros.
Cloud Logging no cobra por la copia de registros ni por las consultas emitidas a través de la página Explorador de registros o la página de Análisis de registros.
Para obtener más información, consulta los siguientes documentos:
- Resumen de precios de Cloud Logging
Costos de destino:
- Los cargos de generación de registros de flujo de VPC se aplican cuando envías y, luego, excluyes tus registros de flujo de nube privada virtual de Cloud Logging.
No se aplican costos de transferencia ni almacenamiento de BigQuery cuando actualizas un bucket para usar el Análisis de registros y, luego, creas un conjunto de datos vinculado. Cuando creas un conjunto de datos vinculado para un bucket de registros, no transfieres tus datos de registro a BigQuery. En su lugar, obtienes acceso de lectura a los datos de registro almacenados en tu bucket de registros a través del conjunto de datos vinculado.
Se aplican cargos de análisis de BigQuery cuando ejecutas consultas de SQL en conjuntos de datos vinculados a BigQuery, lo que incluye el uso de la página de BigQuery Studio, la API de BigQuery y la herramienta de línea de comandos de BigQuery.
Blogs
Para obtener más información sobre el Análisis de registros, consulta las siguientes entradas de blog:
- Para obtener una descripción general del Análisis de registros, consulta El análisis de registros en Cloud Logging ahora tiene DG.
- Para obtener información sobre cómo crear gráficos generados por consultas del Análisis de registros y guardarlos en paneles personalizados, consulta Anuncia gráficos y paneles de análisis de registros en Cloud Logging en una vista previa pública.
- Para obtener información sobre el análisis de registros de auditoría con el Análisis de registros, consulta Obtén estadísticas de seguridad de registros de auditoría con el Análisis de registros.
- Si enrutas los registros a BigQuery y deseas comprender la diferencia entre esa solución y el uso del Análisis de registros, consulta Migra al Análisis de registros para usuarios de exportación de BigQuery.
¿Qué sigue?
- Crea un bucket de registros y actualízalo para usar el Análisis de registros
- Actualiza un bucket existente para usar el Análisis de registros
Crea consultas:
Consultas de muestra: