Security for Google Cloud
Cloud security and AI protection
Security Command Center delivers the best security for Google Cloud environments and the best protection across the entire AI stack.
Join the Security Command Center Community to find answers, build skills, stay up-to-date, and make connections.
Features
AI Protection
Secure the entire AI stack and lifecycle from your agents, data, models, apps, platform, and infrastructure. Discover all AI assets and prioritize risks, secure workloads and agent interactions with Model Armor (protecting against prompt injection, sensitive data leakage, and harmful content), and detect and respond to AI-specific threats across the entire AI stack. Get visibility, control, and security for your AI innovation, from development to runtime.

Built-in threat detection
Detect active threats in near real-time using specialized detectors that are built into the Google Cloud infrastructure. Quickly discover malicious and suspicious activity in Google Cloud services, including Compute Engine, GKE, BigQuery, CloudRun, and more. Protect your organization with the industry's only Cryptomining Protection Program.
Virtual red teaming
Find high-risk gaps in cloud defenses by simulating a sophisticated and determined attacker. Virtual red teaming runs millions of attack permutations against a digital twin model of an organization’s cloud environment and can discover attack paths, toxic combinations, and chokepoints that are unique to each customer’s cloud environment.

Compliance Manager
Combine policy definition, control configuration, enforcement, monitoring, and audit into a unified workflow. Get an end-to-end view of the state compliance with easy monitoring and reporting. Use Audit Manager to automatically generate verifiable evidence to prove compliance to auditors.

Cloud posture management
Automatically scan your cloud environment to identify cloud misconfigurations and software vulnerabilities that could lead to compromise—without having to install or manage agents. High-risk findings are presented on the Security Command Center risk dashboard so you know which issues to prioritize.

Data security posture management
Data Security Posture Management (DSPM), provides governance for security and compliance of sensitive data. Using 150+ AI-driven data classifiers from Sensitive Data Protection, DSPM enables you to discover, secure, and monitor sensitive data. DSPM offers data map visualization for all data resources, advanced data controls for Google Cloud Storage, BigQuery, and Vertex AI. Protect sensitive data from security and compliance risks with DSPM.

Shift left security
Find security issues before they happen. Developers get access to thousands of software packages tested and validated by Google using Assured Open Source Software. DevOps and DevSecOps teams get posture controls to define and monitor security guardrails in the infrastructure, and can use infrastructure as code (IaC) scanning to implement consistent security policies from code to cloud by validating security controls during the build process.
Cloud Infrastructure and Entitlement Management (CIEM)
Reduce identity-related risks by granting users the minimum level of access and permissions needed to perform their job. Understand which users have access to which cloud resources, get ML-generated recommendations to reduce unused and unnecessary permissions, and use out-of-the box playbooks to accelerate responses to identity-driven vulnerabilities. Compatible with Google Cloud IAM, Entra ID (Azure AD), AWS IAM, and Okta.
Learn more
| Security Command Center | Description | Best for | Activation and pricing |
|---|---|---|---|
Enterprise | Complete multi-cloud security, plus automated case management and remediation playbooks | Protecting Google Cloud, AWS and/or Azure with automated remediations | Subscription-based pricing |
Premium | Best protection for Google Cloud includes: AI security, posture management, virtual red teaming, threat detection, data security, compliance management, and more | Google Cloud customers who want the most comprehensive security coverage | Subscription-based pricing OR Pay-as-you-go pricing with self-service activation |
Standard | Basic security posture management for Google Cloud only | Google Cloud environments with minimal security requirements | No cost self-service activation |
Read about Security Command Center offerings in our documentation.
Enterprise
Complete multi-cloud security, plus automated case management and remediation playbooks
Protecting Google Cloud, AWS and/or Azure with automated remediations
Subscription-based pricing
Premium
Best protection for Google Cloud includes: AI security, posture management, virtual red teaming, threat detection, data security, compliance management, and more
Google Cloud customers who want the most comprehensive security coverage
Subscription-based pricing OR Pay-as-you-go pricing with self-service activation
Standard
Basic security posture management for Google Cloud only
Google Cloud environments with minimal security requirements
No cost self-service activation
Read about Security Command Center offerings in our documentation.
How It Works
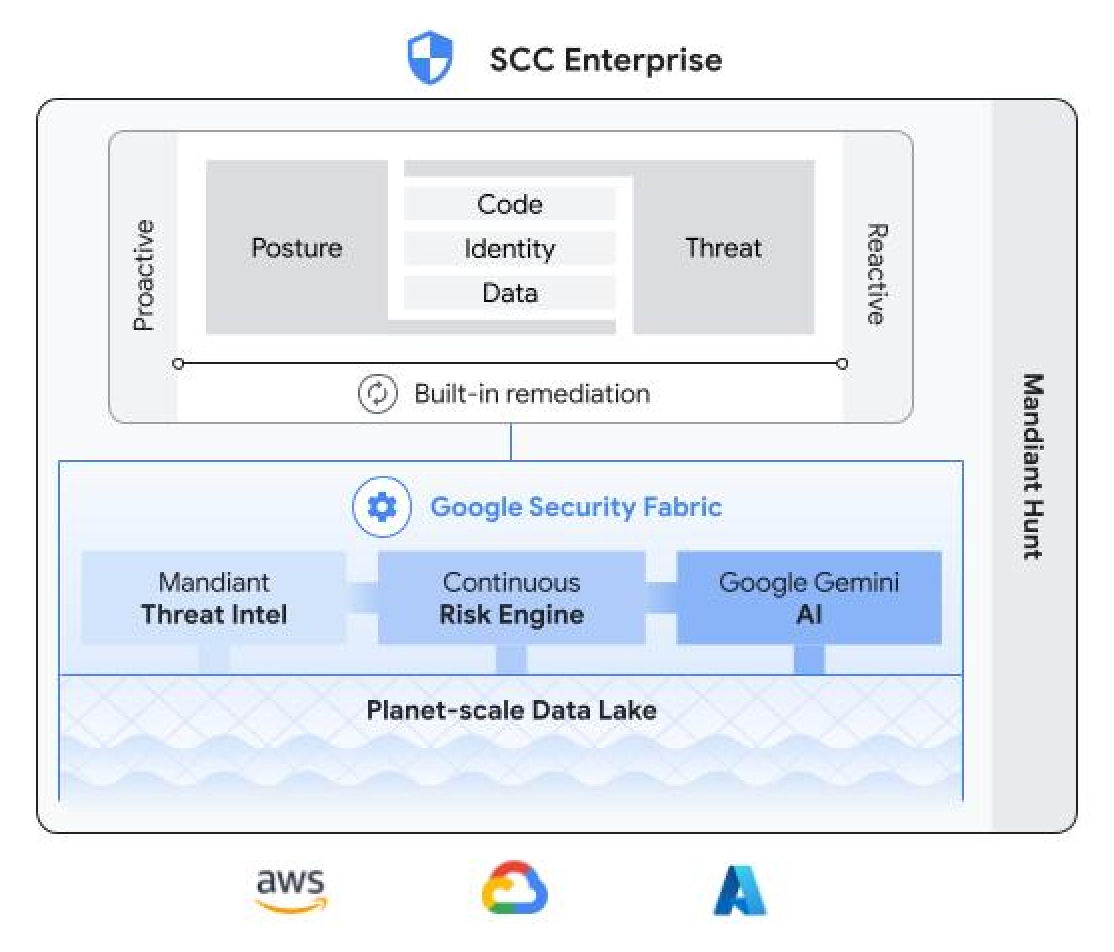
Common Uses
Full lifecycle AI security
Protect your entire AI stack and lifecyle
Learning resources
Protect your entire AI stack and lifecyle
Risk-centric cloud security
Prioritize cloud risks that matter
Prioritize cloud risks that matter
Use virtual red team capabilities to quickly find the high-risk cloud security issues that could lead to significant business impact. Leverage a detailed risk dashboard to view attack path details, toxic combinations of issues, attack exposure scoring, and hand-crafted CVE information from Mandiant to prioritize response efforts.
Tutorials, quickstarts, & labs
Prioritize cloud risks that matter
Prioritize cloud risks that matter
Use virtual red team capabilities to quickly find the high-risk cloud security issues that could lead to significant business impact. Leverage a detailed risk dashboard to view attack path details, toxic combinations of issues, attack exposure scoring, and hand-crafted CVE information from Mandiant to prioritize response efforts.
Cloud workload protection
Detect active attacks
Detect active attacks
Discover when bad actors have infiltrated your cloud environment. Use specialized threat detectors built into Google Cloud and the industry's best threat intelligence to find cyber attacks, including malicious code execution, privilege escalation, data exfiltration, AI threats, and more.
Tutorials, quickstarts, & labs
Detect active attacks
Detect active attacks
Discover when bad actors have infiltrated your cloud environment. Use specialized threat detectors built into Google Cloud and the industry's best threat intelligence to find cyber attacks, including malicious code execution, privilege escalation, data exfiltration, AI threats, and more.
Security posture
Make Google Cloud safe for critical applications and data
Make Google Cloud safe for critical applications and data
Use agentless technology to proactively find vulnerabilities and misconfigurations in your Google Cloud environment before attackers can exploit them to access sensitive cloud resources. Then use virtual red team technology to discover possible attack paths and attack exposure scoring to prioritize the security issues that pose the most risk.
Tutorials, quickstarts, & labs
Make Google Cloud safe for critical applications and data
Make Google Cloud safe for critical applications and data
Use agentless technology to proactively find vulnerabilities and misconfigurations in your Google Cloud environment before attackers can exploit them to access sensitive cloud resources. Then use virtual red team technology to discover possible attack paths and attack exposure scoring to prioritize the security issues that pose the most risk.
Compliance Management
Streamline compliance: configure, monitor, and audit
Learning resources
Streamline compliance: configure, monitor, and audit
Data Security and Compliance
Discover, govern, and protect sensitive data in the cloud
Learning resources
Discover, govern, and protect sensitive data in the cloud
Pricing
| How Security Command Center pricing works | Pricing is based on the total number of assets in the cloud environments being protected. | |
|---|---|---|
| Product tier | Activation | Price USD |
Enterprise | Available with one or multi-year subscription, with built-in term discounts | |
Premium | Available with one or multi-year subscription, or self-service activation with pay-as-you-go consumption pricing, at a project-level or organization-level | |
Standard | Available with self-service activation, at a project-level or organization-level | No cost |
How Security Command Center pricing works
Pricing is based on the total number of assets in the cloud environments being protected.
Enterprise
Available with one or multi-year subscription, with built-in term discounts
Premium
Available with one or multi-year subscription, or self-service activation with pay-as-you-go consumption pricing, at a project-level or organization-level
Standard
Available with self-service activation, at a project-level or organization-level
No cost











