Data Science-Lösungen
Einheitliche Plattform für Daten, Analysen und ML für Ihre KI-Workflows
Entlasten Sie Ihre Datenteams, indem Sie die Komplexität auf eine einheitliche Daten- und KI-Plattform verlagern. Mit der umfassenden Palette an verwalteten Diensten und integrierten Workflows von Google Cloud lassen sich Data-Science-Lösungen ganz einfach erstellen, verwalten und skalieren.
Überblick
Was sind Data-Science-Lösungen?
Data-Science-Lösungen sind umfassende, technologiegetriebene Ansätze, die Machine Learning, KI und statistische Modellierung nutzen, um komplexe geschäftliche Herausforderungen zu lösen und die operative Effizienz zu steigern. Der Fokus verschiebt sich von der grundlegenden Datenanalyse hin zur unternehmensweiten Ausführung des gesamten Lebenszyklus. Dabei wird ein Kernprozess aus Data Engineering, prädiktiver Modellierung und MLOps hervorgehoben, um Rohdaten in einen automatisierten, strategischen Vorteil zu verwandeln.
Warum Google Cloud für Data Science?
So steigern Sie die Geschwindigkeit und Agilität Ihres Unternehmens und schaffen kurz- und langfristige Mehrwerte. Bei herkömmlichen Ansätzen müssen oft 5–7 separate Tools zusammengeführt werden. Die Data Science-Plattform von Google Cloud deckt jedoch den gesamten Lebenszyklus ab – von der Datenaufnahme bis zur Modellbereitstellung – und basiert auf einer einzigen multimodalen Datenbasis, die eine einheitliche Governance ermöglicht.
Data-Science-Lösungen für jede geschäftliche Herausforderung
Ganz gleich, ob Sie den Umsatz steigern, Kosten senken oder Risiken verwalten möchten – Google Cloud bietet die Tools, um Datenmodelle zu industrialisieren und den Fokus von isolierten Experimenten auf reale MLOps-Pipelines zu verlagern.
Funktionsweise
- Personalisierung und schnellere Entscheidungen: Kundenzufriedenheit mit KI/ML in Echtzeit steigern
- Full-Stack-Unternehmensintegration: Open-Source-KI in Produktionsumgebungen mit robuster Ausführung über den gesamten Lebenszyklus bereitstellen
- Skalierbare Datenverarbeitung: Nutzen Sie mehrere Engines wie BigQuery SQL und Spark mit einer einheitlichen Datenkopie.
- Personalisierung und schnellere Entscheidungen: Kundenzufriedenheit mit KI/ML in Echtzeit steigern
- Full-Stack-Unternehmensintegration: Open-Source-KI in Produktionsumgebungen mit robuster Ausführung über den gesamten Lebenszyklus bereitstellen
- Skalierbare Datenverarbeitung: Nutzen Sie mehrere Engines wie BigQuery SQL und Spark mit einer einheitlichen Datenkopie.

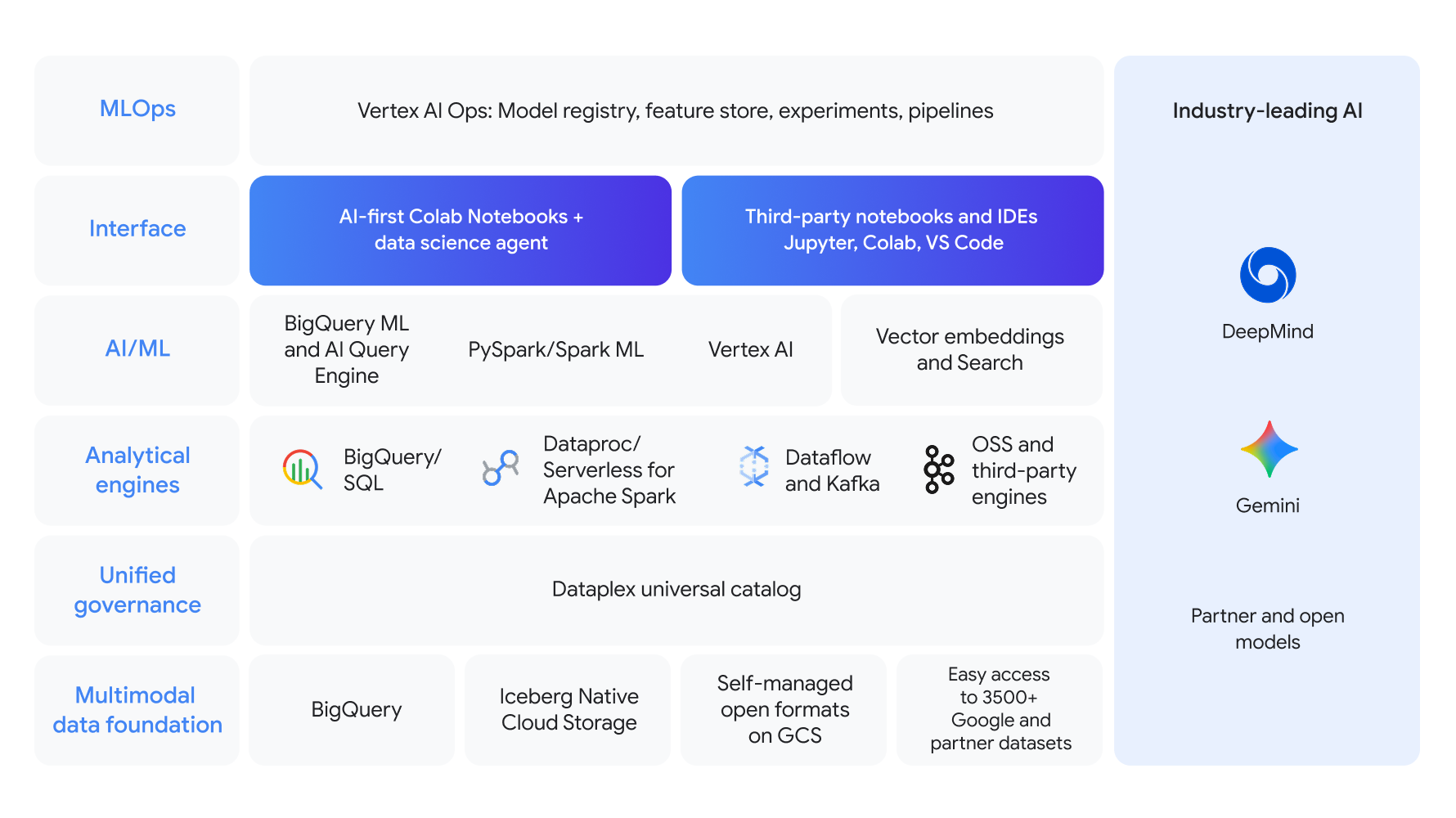
Einheitliche Plattform für End-to-End-Workflows im Bereich Data Science
Einheitliche Lösung für den gesamten Data Science- und Machine Learning-Lebenszyklus, die auf einer multimodalen Datenbasis aufbaut und eine einheitliche Governance ermöglicht
Nutzen Sie leistungsstarke Analyse-Engines wie BigQuery SQL und Apache Spark und erstellen Sie dann Modelle mit BigQuery ML oder der Gemini Enterprise Agent Platform. Mit dem AI-first Colab Enterprise-Notebook und robusten MLOps, unterstützt durch branchenführende KI, können Sie die Entwicklung optimieren.
Anleitungen
Einheitliche Lösung für den gesamten Data Science- und Machine Learning-Lebenszyklus, die auf einer multimodalen Datenbasis aufbaut und eine einheitliche Governance ermöglicht
Nutzen Sie leistungsstarke Analyse-Engines wie BigQuery SQL und Apache Spark und erstellen Sie dann Modelle mit BigQuery ML oder der Gemini Enterprise Agent Platform. Mit dem AI-first Colab Enterprise-Notebook und robusten MLOps, unterstützt durch branchenführende KI, können Sie die Entwicklung optimieren.
Zentralisierter Arbeitsbereich mit KI-basierten Notebooks
Es stehen mehrere Notebook-Lösungen für Data Science in Unternehmen zur Verfügung.
Colab Enterprise bietet eine sichere, verwaltete Umgebung, die in die Gemini Enterprise Agent Platform und BigQuery eingebunden ist. Workbenches bieten anpassbare JupyterLab-Instanzen, während Cloud Workstations vollständige IDEs unterstützen. Außerdem können Sie mit Erweiterungen selbst gehostete Tools direkt mit den Google Cloud-Diensten verbinden.

Anleitungen
Es stehen mehrere Notebook-Lösungen für Data Science in Unternehmen zur Verfügung.
Colab Enterprise bietet eine sichere, verwaltete Umgebung, die in die Gemini Enterprise Agent Platform und BigQuery eingebunden ist. Workbenches bieten anpassbare JupyterLab-Instanzen, während Cloud Workstations vollständige IDEs unterstützen. Außerdem können Sie mit Erweiterungen selbst gehostete Tools direkt mit den Google Cloud-Diensten verbinden.
Integrierter Data Science Agent
Beschleunigen Sie die Data-Science-Entwicklung mit agentischen Funktionen, die die Datenexploration, ‑transformation und ML-Modellierung erleichtern.
Beginnen Sie mit einem allgemeinen Ziel in natürlicher Sprache. Der Data-Science-Agent erstellt dann einen detaillierten Plan, der alle Aspekte der Data-Science-Modellierung abdeckt: Daten laden, untersuchen, bereinigen, visualisieren, Feature Engineering, Daten aufteilen, Modell trainieren/optimieren und bewerten.

Anleitungen
Beschleunigen Sie die Data-Science-Entwicklung mit agentischen Funktionen, die die Datenexploration, ‑transformation und ML-Modellierung erleichtern.
Beginnen Sie mit einem allgemeinen Ziel in natürlicher Sprache. Der Data-Science-Agent erstellt dann einen detaillierten Plan, der alle Aspekte der Data-Science-Modellierung abdeckt: Daten laden, untersuchen, bereinigen, visualisieren, Feature Engineering, Daten aufteilen, Modell trainieren/optimieren und bewerten.
KI-gestützte Datenvorbereitung ohne Silos
Nutzen Sie eine einheitliche Datenbasis, um sowohl strukturierte als auch unstrukturierte Daten (Bilder, Dokumente usw.) mit SQL für die Analyse und KI-Funktionen für die Verarbeitung zu verwalten.
Die KI-gestützte Datenvorbereitung stellt Vorschläge für die Datenbereinigung und ‑transformation bereit. Der Data Engineering Agent automatisiert Data-Engineering-Aufgaben wie die Datenaufnahme und die Pipeline-Erstellung durch Anweisungen in natürlicher Sprache.

Anleitungen
Nutzen Sie eine einheitliche Datenbasis, um sowohl strukturierte als auch unstrukturierte Daten (Bilder, Dokumente usw.) mit SQL für die Analyse und KI-Funktionen für die Verarbeitung zu verwalten.
Die KI-gestützte Datenvorbereitung stellt Vorschläge für die Datenbereinigung und ‑transformation bereit. Der Data Engineering Agent automatisiert Data-Engineering-Aufgaben wie die Datenaufnahme und die Pipeline-Erstellung durch Anweisungen in natürlicher Sprache.
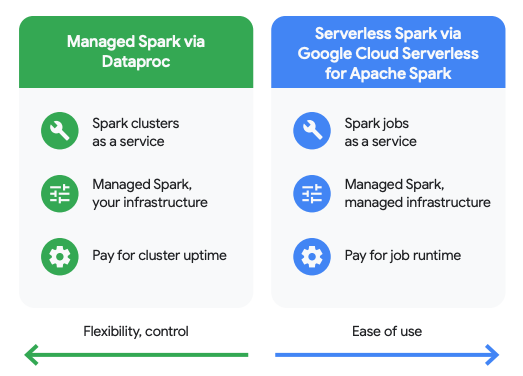
Flexible Datenverarbeitung mit mehreren Engines
Einheitliche Datenkopie
Sie können eine beliebige Verarbeitungs-Engine auswählen – die SQL-Engine von BigQuery oder ein Open-Source-Framework wie Apache Spark – und direkt mit einer einzigen, einheitlichen Datenkopie arbeiten. Dadurch müssen Sie keine separaten Datenkopien für verschiedene Systeme verwalten.
Anleitungen
Einheitliche Datenkopie
Sie können eine beliebige Verarbeitungs-Engine auswählen – die SQL-Engine von BigQuery oder ein Open-Source-Framework wie Apache Spark – und direkt mit einer einzigen, einheitlichen Datenkopie arbeiten. Dadurch müssen Sie keine separaten Datenkopien für verschiedene Systeme verwalten.
Data Science mit BigQuery DataFrames für Python skalieren
Sie bevorzugen native Python-Bibliotheken?
BigQuery DataFrames bieten eine Pandas-ähnliche API, die Python-Code in optimiertes SQL für die Ausführung in der BigQuery-Engine übersetzt. So können Sie das richtige Tool für die jeweilige Aufgabe verwenden, ob SQL, PySpark oder ein DataFrame im Pandas-Stil, und dabei immer mit denselben zugrunde liegenden Daten arbeiten.

Anleitungen
Sie bevorzugen native Python-Bibliotheken?
BigQuery DataFrames bieten eine Pandas-ähnliche API, die Python-Code in optimiertes SQL für die Ausführung in der BigQuery-Engine übersetzt. So können Sie das richtige Tool für die jeweilige Aufgabe verwenden, ob SQL, PySpark oder ein DataFrame im Pandas-Stil, und dabei immer mit denselben zugrunde liegenden Daten arbeiten.
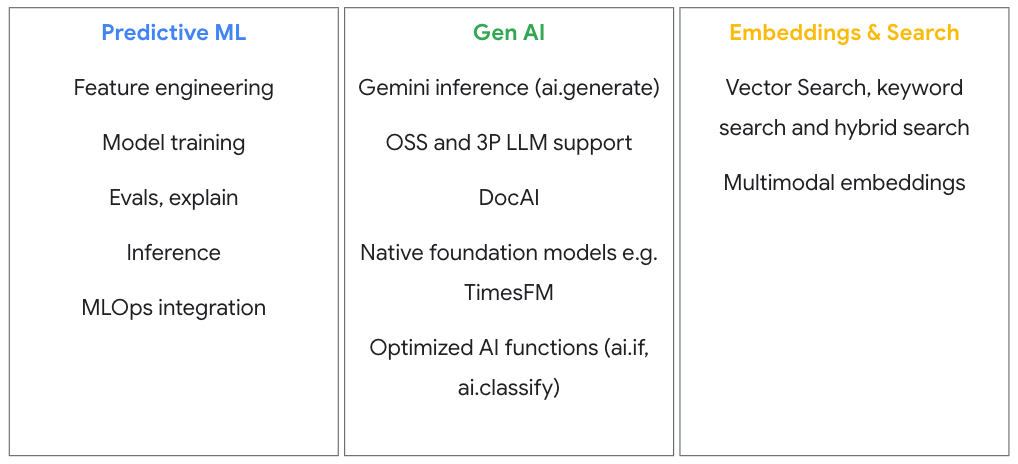
ML-Modelle erstellen, trainieren, abstimmen und ausführen
Modelle mit BigQuery ML und SQL erstellen, trainieren, bewerten und bereitstellen, ohne Daten verschieben zu müssen
Nutzen Sie eingebundene, vortrainierte Modelle oder SQL-Funktionen, die Gemini für die Datenanalyse/Datenanreicherung aufrufen. Für benutzerdefinierte Modelle unterstützt die Agent Platform PyTorch, TensorFlow und andere ML-Bibliotheken. Die nahtlose Einbindung ermöglicht das Feature Engineering in BigQuery, das Training benutzerdefinierter Modelle in der Agent Platform und die Inferenz zurück in BigQuery über SQL.
Anleitungen
Modelle mit BigQuery ML und SQL erstellen, trainieren, bewerten und bereitstellen, ohne Daten verschieben zu müssen
Nutzen Sie eingebundene, vortrainierte Modelle oder SQL-Funktionen, die Gemini für die Datenanalyse/Datenanreicherung aufrufen. Für benutzerdefinierte Modelle unterstützt die Agent Platform PyTorch, TensorFlow und andere ML-Bibliotheken. Die nahtlose Einbindung ermöglicht das Feature Engineering in BigQuery, das Training benutzerdefinierter Modelle in der Agent Platform und die Inferenz zurück in BigQuery über SQL.
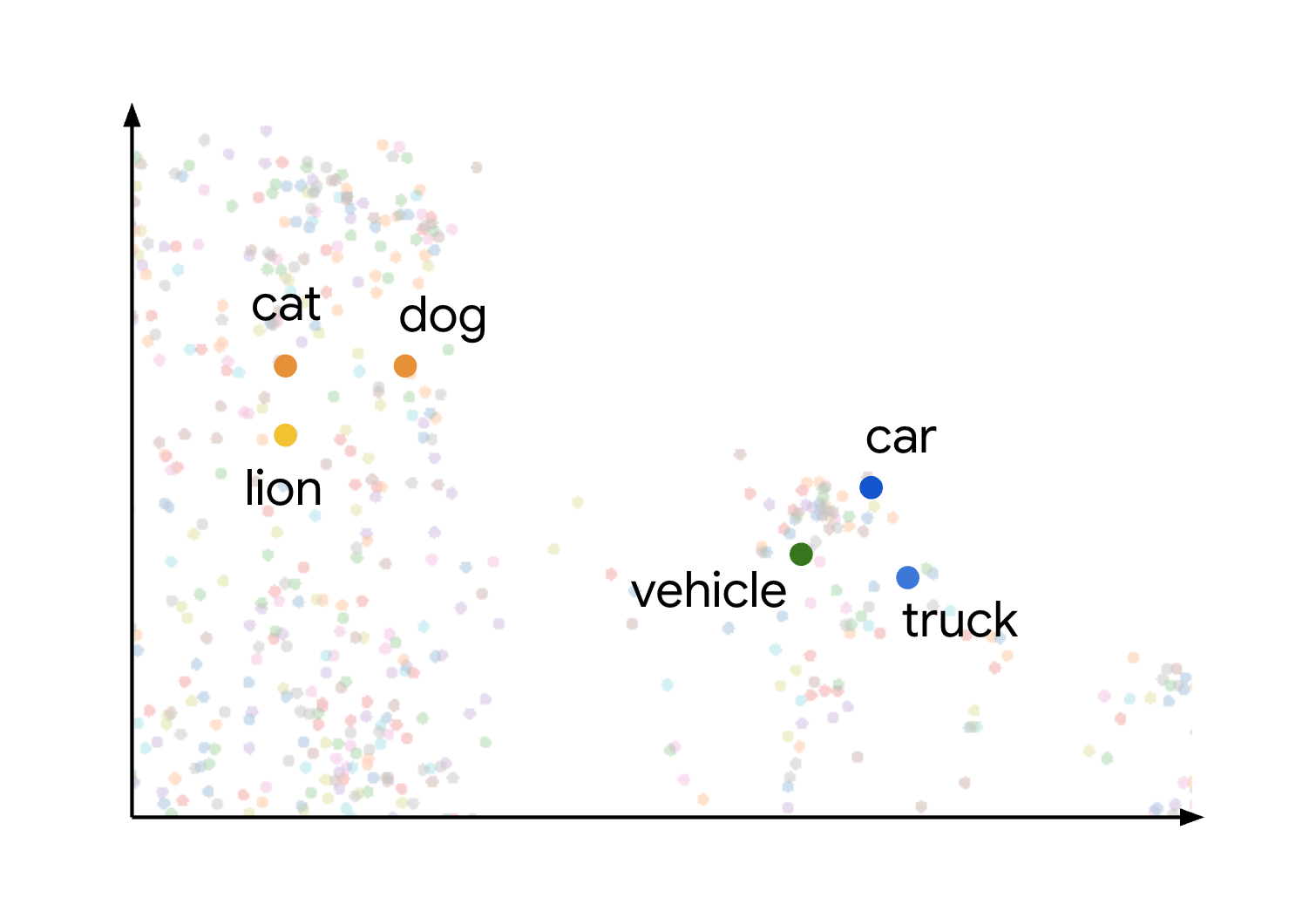
Einbettungen generieren und Vektorsuche aktivieren
Generieren und verwenden Sie multimodale Einbettungen, um eine Vektorsuche durchzuführen. So lassen sich multimodale Daten semantisch verstehen und anhand der Ähnlichkeit abrufen. So können Sie ausgefeilte Systeme für semantische Suchen, Empfehlungen oder Segmentierungen erstellen, ohne eine separate, spezialisierte Vektordatenbank verwalten zu müssen.
Anleitungen
Generieren und verwenden Sie multimodale Einbettungen, um eine Vektorsuche durchzuführen. So lassen sich multimodale Daten semantisch verstehen und anhand der Ähnlichkeit abrufen. So können Sie ausgefeilte Systeme für semantische Suchen, Empfehlungen oder Segmentierungen erstellen, ohne eine separate, spezialisierte Vektordatenbank verwalten zu müssen.
Mit integrierten MLOps vom Modell zur Produktion
BigQuery und die Gemini Enterprise Agent Platform lassen sich einbinden, um MLOps zu optimieren.
Zentralisieren Sie Features im Gemini Enterprise Agent Platform Feature Store, um Trainings-Serving-Skew und redundante Arbeit zu vermeiden. Mit AutoML können Sie die Modellerstellung für tabellarische Daten automatisieren. Alle Modelle, ob aus BigQuery ML oder der Gemini Enterprise Agent Platform, werden automatisch in der Model Registry der Plattform registriert. Anschließend können Sie sie ganz einfach versionieren, auswerten und bereitstellen und so einen nahtlosen End-to-End-Lebenszyklus auf nur einer Plattform schaffen.

Anleitungen
BigQuery und die Gemini Enterprise Agent Platform lassen sich einbinden, um MLOps zu optimieren.
Zentralisieren Sie Features im Gemini Enterprise Agent Platform Feature Store, um Trainings-Serving-Skew und redundante Arbeit zu vermeiden. Mit AutoML können Sie die Modellerstellung für tabellarische Daten automatisieren. Alle Modelle, ob aus BigQuery ML oder der Gemini Enterprise Agent Platform, werden automatisch in der Model Registry der Plattform registriert. Anschließend können Sie sie ganz einfach versionieren, auswerten und bereitstellen und so einen nahtlosen End-to-End-Lebenszyklus auf nur einer Plattform schaffen.
Mit Google Cloud gelingt der nächste Schritt.
Anwendungsszenario
Erfolg durch Ergebnisorientierung




Mehr anzeigen
Von Legacy zu Cloud: Warum die Deutsche Telekom von PySpark zu BigQuery DataFrames wechselte
„Von Monaten zu Minuten: Mit KI mehr als 20 Millionen Kundenrezensionen in Erkenntnisse umwandeln“
KI/ML in Echtzeit für personalisierte Kundenerlebnisse und effiziente Abläufe aktivieren





Für alle Rollen im Data-Science-Team
Für alle Rollen im Data-Science-Team
FAQs
Für Data Scientists und ML-Entwickler
Der Fokus liegt auf der Entwicklerfreundlichkeit mit Colab Enterprise-Notebooks, Unterstützung für Frameworks wie PyTorch und TensorFlow sowie BigQuery DataFrames. Teams können Notebooks, Datenverbindungen und Rechenressourcen projektübergreifend freigeben. Damit ist Google Cloud eine echte Plattform für die kollaborative Datenwissenschaft.
Für Führungskräfte im Bereich Daten und Analysen
Maximieren Sie ROI und Governance. Eine einheitliche Plattform reduziert die Tool-Landschaft und die Kosten für Anbieter und bietet integrierte Governance. Modelle werden ohne ein separates MLOps-Team vom Notebook in die Produktion überführt, was die Leistungsstatistiken von 3x/4x/10x direkt unterstützt.
Für Data Engineers und Architekten
Profitieren Sie von Integration und Flexibilität. Die Unterstützung von Open-Source-Kompatibilität (Apache Spark, Airflow und Kafka) und die Verarbeitung mit mehreren Engines auf einer Datenkopie sorgen dafür, dass Sie nicht an Frameworks gebunden sind.


















