Google Cloud databases
Google Cloud offers industry-leading databases built on planet-scale infrastructure, with AI at its core. Experience unmatched reliability, price-performance, security, and global scale for all your AI agents and applications.
And with Google’s Agentic Data Cloud, you now have a unified platform that integrates models, analytics, and operational databases into a single, AI-native system.

Relational databases store and organize data in tables with defined relationships, making it easy to understand how data structures relate to each other
- Cloud SQL: Highly flexible, fully managed database service for MySQL, PostgreSQL, and SQL Server workloads, offering superior performance, availability, and manageability.
- AlloyDB for PostgreSQL: 100% PostgreSQL-compatible database that runs anywhere, and offers superior performance, availability, and scale for your most demanding workloads.
- Spanner: The always-on, globally consistent, multi-model, and virtually unlimited scale database that powers Google’s billion user products such as Google Search, Gmail, and YouTube. Offers up to 99.999% availability SLA.
Non-relational databases, also known as NoSQL databases, store data in a flexible, non-tabular format
- Bigtable: Highly flexible, NoSQL database for high throughput, low-latency applications at scale, that powers Google’s billion user products such as Google Search, Ads, and YouTube. Offers up to 99.999% availability SLA.
- Memorystore: Fully managed, in-memory database service for Valkey, Redis*, and Memcached, offering sub-millisecond data access, scalability, and high availability.
- Firestore: Highly scalable and serverless document database for developing rich applications. Offers up to 99.999% availability SLA.
- Firestore with MongoDB compatibility: Leverage your existing MongoDB expertise with Firestore's serverless scalability, performance, and high availability.
Vector databases allow you to store, index, and query vector embeddings, or numerical representations of unstructured data, such as text, images, or audio
- AlloyDB AI: Build enterprise gen AI apps with the familiar PostgreSQL interface. It integrates with AI tools such as Gemini Enterprise Agent Platform for model inferencing, and open, standard technologies like pgvector and LangChain. And with the new ScaNN index, we're bringing twelve years of Google research to PostgreSQL for improved vector search performance and accuracy.
- Spanner: Build intelligent apps with a single database that brings together relational, graph, key value, full-text search, and vector search, eliminating the need for separate, specialized database solutions. We support storing vectors and searching them using exact nearest neighbor (KNN) or approximate nearest neighbor (ANN) search.
- Cloud SQL: Store vectors in the same Cloud SQL for MySQL and Cloud SQL for PostgreSQL instance you’re already using, and then search against your vector store using either exact nearest neighbor (KNN) or approximate nearest neighbor (ANN) search. Cloud SQL integrates with Gemini Enterprise Agent Platform for model inferencing, and supports open source pgvector for quickly building gen AI apps.
Migrate and modernize databases and applications by moving them to cloud-based services for improved performance, scalability, and cost-efficiency
- Database Migration Service: Simplify migrations from MySQL, PostgreSQL, SQL Server, and Oracle databases to Cloud SQL and AlloyDB. Start migrating in just a few clicks with an integrated, Gemini-assisted conversion and migration experience.
- Datastream: Serverless and easy-to-use change data capture and replication service from MySQL, PostgreSQL, SQL Server, and Oracle databases. With Datastream for BigQuery, you can seamlessly replicate from relational databases directly to BigQuery, enabling near real-time insights on operational data.
- Oracle Database@Google Cloud: Migrate and supercharge Oracle databases and applications in Google Cloud. Deploy the latest database services in a Google Cloud datacenter running on Oracle Cloud Infrastructure (OCI) hardware.
- Bare Metal Solution for Oracle: Run Oracle databases the same way you do it, on-premises on a fully managed end-to-end infrastructure including compute, storage, and networking.
Gain a comprehensive view and supercharge your entire database fleet management with AI. Proactively detect and identify the root cause of problems.
- Database Center: Manage availability, cost, protection, performance, security, and compliance across your entire database fleet. A centralized dashboard provides a unified view of your Cloud SQL, AlloyDB, Spanner, Bigtable, Memorystore and Firestore instances, and now also offers support (in preview) for self-managed databases (MySQL, PostgreSQL, and SQL Server) on Google Compute Engine.
- AI-assisted troubleshooting: Analyze and troubleshoot the performance of your databases and detect anomalies in the execution of the queries, with AI built into Database Center. When Cloud SQL or AlloyDB detect anomalies in query performance or identify high system load, AI-assisted troubleshooting helps you analyze the situation with evidence and provides recommendations.
- Database agents: The Database Onboarding Agent evaluates user requirements to recommend the best Google Cloud database and guides users through the provisioning process. The Database Observability Agent proactively monitors database fleet performance, identifies anomalies, and provides intelligent recommendations and multi-turn remediation workflows for troubleshooting and optimization.
Relational databases
Relational databases store and organize data in tables with defined relationships, making it easy to understand how data structures relate to each other
- Cloud SQL: Highly flexible, fully managed database service for MySQL, PostgreSQL, and SQL Server workloads, offering superior performance, availability, and manageability.
- AlloyDB for PostgreSQL: 100% PostgreSQL-compatible database that runs anywhere, and offers superior performance, availability, and scale for your most demanding workloads.
- Spanner: The always-on, globally consistent, multi-model, and virtually unlimited scale database that powers Google’s billion user products such as Google Search, Gmail, and YouTube. Offers up to 99.999% availability SLA.
Non-relational databases
Non-relational databases, also known as NoSQL databases, store data in a flexible, non-tabular format
- Bigtable: Highly flexible, NoSQL database for high throughput, low-latency applications at scale, that powers Google’s billion user products such as Google Search, Ads, and YouTube. Offers up to 99.999% availability SLA.
- Memorystore: Fully managed, in-memory database service for Valkey, Redis*, and Memcached, offering sub-millisecond data access, scalability, and high availability.
- Firestore: Highly scalable and serverless document database for developing rich applications. Offers up to 99.999% availability SLA.
- Firestore with MongoDB compatibility: Leverage your existing MongoDB expertise with Firestore's serverless scalability, performance, and high availability.
Vector databases
Vector databases allow you to store, index, and query vector embeddings, or numerical representations of unstructured data, such as text, images, or audio
- AlloyDB AI: Build enterprise gen AI apps with the familiar PostgreSQL interface. It integrates with AI tools such as Gemini Enterprise Agent Platform for model inferencing, and open, standard technologies like pgvector and LangChain. And with the new ScaNN index, we're bringing twelve years of Google research to PostgreSQL for improved vector search performance and accuracy.
- Spanner: Build intelligent apps with a single database that brings together relational, graph, key value, full-text search, and vector search, eliminating the need for separate, specialized database solutions. We support storing vectors and searching them using exact nearest neighbor (KNN) or approximate nearest neighbor (ANN) search.
- Cloud SQL: Store vectors in the same Cloud SQL for MySQL and Cloud SQL for PostgreSQL instance you’re already using, and then search against your vector store using either exact nearest neighbor (KNN) or approximate nearest neighbor (ANN) search. Cloud SQL integrates with Gemini Enterprise Agent Platform for model inferencing, and supports open source pgvector for quickly building gen AI apps.
Migrate and modernize
Migrate and modernize databases and applications by moving them to cloud-based services for improved performance, scalability, and cost-efficiency
- Database Migration Service: Simplify migrations from MySQL, PostgreSQL, SQL Server, and Oracle databases to Cloud SQL and AlloyDB. Start migrating in just a few clicks with an integrated, Gemini-assisted conversion and migration experience.
- Datastream: Serverless and easy-to-use change data capture and replication service from MySQL, PostgreSQL, SQL Server, and Oracle databases. With Datastream for BigQuery, you can seamlessly replicate from relational databases directly to BigQuery, enabling near real-time insights on operational data.
- Oracle Database@Google Cloud: Migrate and supercharge Oracle databases and applications in Google Cloud. Deploy the latest database services in a Google Cloud datacenter running on Oracle Cloud Infrastructure (OCI) hardware.
- Bare Metal Solution for Oracle: Run Oracle databases the same way you do it, on-premises on a fully managed end-to-end infrastructure including compute, storage, and networking.
Fleet management
Gain a comprehensive view and supercharge your entire database fleet management with AI. Proactively detect and identify the root cause of problems.
- Database Center: Manage availability, cost, protection, performance, security, and compliance across your entire database fleet. A centralized dashboard provides a unified view of your Cloud SQL, AlloyDB, Spanner, Bigtable, Memorystore and Firestore instances, and now also offers support (in preview) for self-managed databases (MySQL, PostgreSQL, and SQL Server) on Google Compute Engine.
- AI-assisted troubleshooting: Analyze and troubleshoot the performance of your databases and detect anomalies in the execution of the queries, with AI built into Database Center. When Cloud SQL or AlloyDB detect anomalies in query performance or identify high system load, AI-assisted troubleshooting helps you analyze the situation with evidence and provides recommendations.
- Database agents: The Database Onboarding Agent evaluates user requirements to recommend the best Google Cloud database and guides users through the provisioning process. The Database Observability Agent proactively monitors database fleet performance, identifies anomalies, and provides intelligent recommendations and multi-turn remediation workflows for troubleshooting and optimization.

Customer success stories






 Fastweb + VodafoneWith Spanner, BigQuery, and Gemini, the company simplified its architecture and introduced AI-assisted engineering workflows.
Fastweb + VodafoneWith Spanner, BigQuery, and Gemini, the company simplified its architecture and introduced AI-assisted engineering workflows.5-min read
 Deutsche BankUses Spanner for its high availability, external consistency, and infinite horizontal scalability for their online banking platform.
Deutsche BankUses Spanner for its high availability, external consistency, and infinite horizontal scalability for their online banking platform.5-min read
 Chess.comWith Cloud SQL Enterprise Plus edition, Chess.com can now seamlessly connect millions of chess players worldwide at a lower price-performance.
Chess.comWith Cloud SQL Enterprise Plus edition, Chess.com can now seamlessly connect millions of chess players worldwide at a lower price-performance.5-min read
Developer resources
- Gen AI for developers white paperYour guide to AI application and agent development with operational databases.
10-min read
- Data agents guidebookLearn more about what are data agents and what we offer at Google Cloud.
10-min read
- A practical guide to data scienceLearn how AI unlocks a wave of new use cases for data scientists.
10-min read
Why Google Cloud databases
Build gen AI apps and agents with your trusted enterprise data
Quickly build gen AI applications and agents with your own trusted enterprise data. Easily enhance your AI apps with knowledge graphs and Graph-based Retrieval Augmented Generation (RAG) for high-value use cases. Seamless integrations with leading AI tools like Gemini Enterprise Agent Platform and MCP Toolbox empower you to rapidly build apps and agents that are securely connected to your operational data. Get started with the Data Agent Kit to streamline your data engineering and data science workflows in a single, open-source package.

95%
More than 95% of Google Cloud's top 100 customers use Cloud SQL.
4x
AlloyDB is 4x faster than standard PostgreSQL for transactional workloads.
2x
AlloyDB provides up to 2x better price-performance compared to self-managed PostgreSQL.
Modernize legacy apps with the most open data platform
Seamlessly modernize your legacy applications and databases with the most open data platform for flexibility and portability, without vendor lock-in. We support the most popular open source and commercial engines such as MySQL, PostgreSQL, Valkey, Oracle, and SQL Server, ensuring operational efficiency, accelerated development, and lower total-cost-of-ownership (TCO), allowing you to modernize efficiently at your own pace.
Supercharge database development and management with AI
Supercharge database development and management with Gemini for Google Cloud. We’re bringing AI-powered capabilities to assist you with development, performance optimization, fleet management, governance, and migrations. The Database Onboarding Agent evaluates user requirements to recommend the best Google Cloud database and guides users through the provisioning process. The Database Observability Agent proactively monitors database fleet performance, identifies anomalies, and provides intelligent recommendations and multi-turn remediation workflows for troubleshooting and optimization.
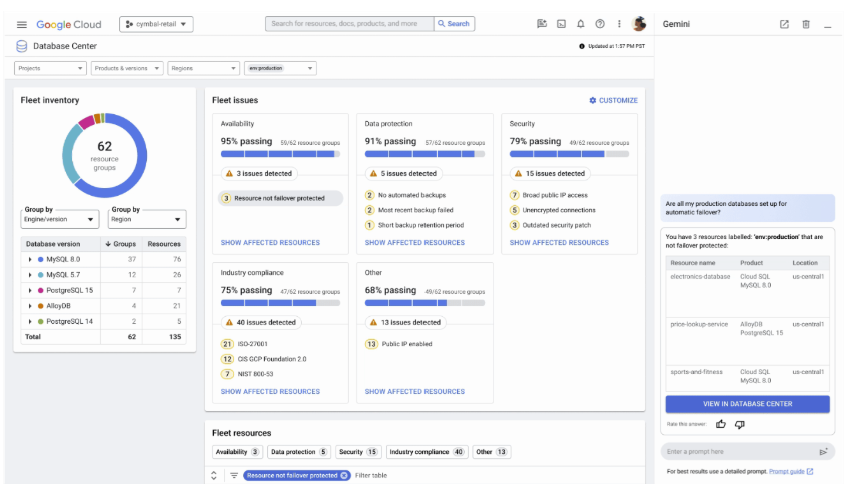
With Gemini in Databases, we can get answers on fleet health in seconds and proactively mitigate potential risks to our applications more swiftly than ever before.
Bogdan Capatina, Technical Expert in Database Technologies, Ford Motor Company



















