The front door to AI in the workplace—for everyone
The front door to AI in the workplace—for everyone
 Gemini Enterprise Agent PlatformEnable developers to build production-ready AI agents at scale.
Gemini Enterprise Agent PlatformEnable developers to build production-ready AI agents at scale. Gemini Enterprise appEmpower employees to boost productivity with an embedded agentic taskforce.
Gemini Enterprise appEmpower employees to boost productivity with an embedded agentic taskforce. Gemini Enterprise for Customer ExperienceTransform customer journeys with intelligent conversations at every touchpoint.
Gemini Enterprise for Customer ExperienceTransform customer journeys with intelligent conversations at every touchpoint.

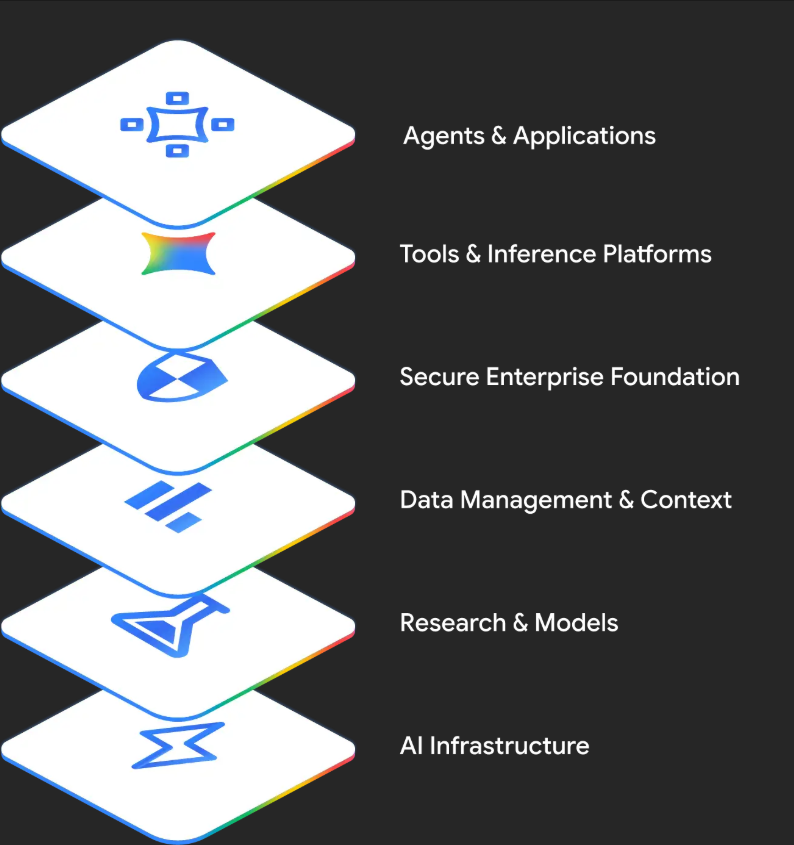
Gemini Enterprise is a unified agentic portfolio for your entire organization
AI value for developers, employees, and customers
Bring agents to life across your entire business and connect everyone with shared context—from the tools that empower your workforce to the experiences that serve your customers.
Gemini Enterprise unites the core Agent Platform your developers require with the intuitive apps your workforce and customers need. Built on Google Cloud’s integrated AI stack, it delivers the unmatched performance and the secure-by-design foundation required to deploy a global digital taskforce.
Full-stack advantage for AI performance
Building an AI agent is one thing, but managing its lifecycle at scale—including security, governance, and cost—is the hard part. We co-design every layer to solve this challenge, enabling you to build, run, and manage AI with optimal efficiency and governance—giving your business a structural edge that a fragmented stack simply can't match.
Gemini Enterprise is a unified agentic portfolio for your entire organization
AI value for developers, employees, and customers
Bring agents to life across your entire business and connect everyone with shared context—from the tools that empower your workforce to the experiences that serve your customers.
Gemini Enterprise unites the core Agent Platform your developers require with the intuitive apps your workforce and customers need. Built on Google Cloud’s integrated AI stack, it delivers the unmatched performance and the secure-by-design foundation required to deploy a global digital taskforce.
Full-stack advantage for AI performance
Building an AI agent is one thing, but managing its lifecycle at scale—including security, governance, and cost—is the hard part. We co-design every layer to solve this challenge, enabling you to build, run, and manage AI with optimal efficiency and governance—giving your business a structural edge that a fragmented stack simply can't match.
The developer hub for building innovative AI agents
Build production-ready agents faster
Give your developers the ultimate toolkit to create sophisticated agents using over 200 world-class models—including Gemini, Claude, and more—alongside our Agent Development Kit (ADK) and Agent Studio.
Scale agents effectively
Clear the path to production with our upgraded Agent Runtime, which supports complex workflows that run for up to seven days. And with our Memory Bank, your agents get persistent, long-term context so interactions always feel highly personalized and recall past history.
Govern agents with confidence
Centrally manage your entire fleet of agents through a single source of truth using Agent Identity, Agent Registry, and Agent Gateway—enforcing zero-trust security and preventing prompt injections right at the infrastructure level.
Optimize agents
To ensure quality, we give you tools for agent simulation, evaluation, and observability. This provides full execution traces and a real-time, 'glass-box' lens into your agents' reasoning loops so you can debug issues as they happen and continuously improve performance.
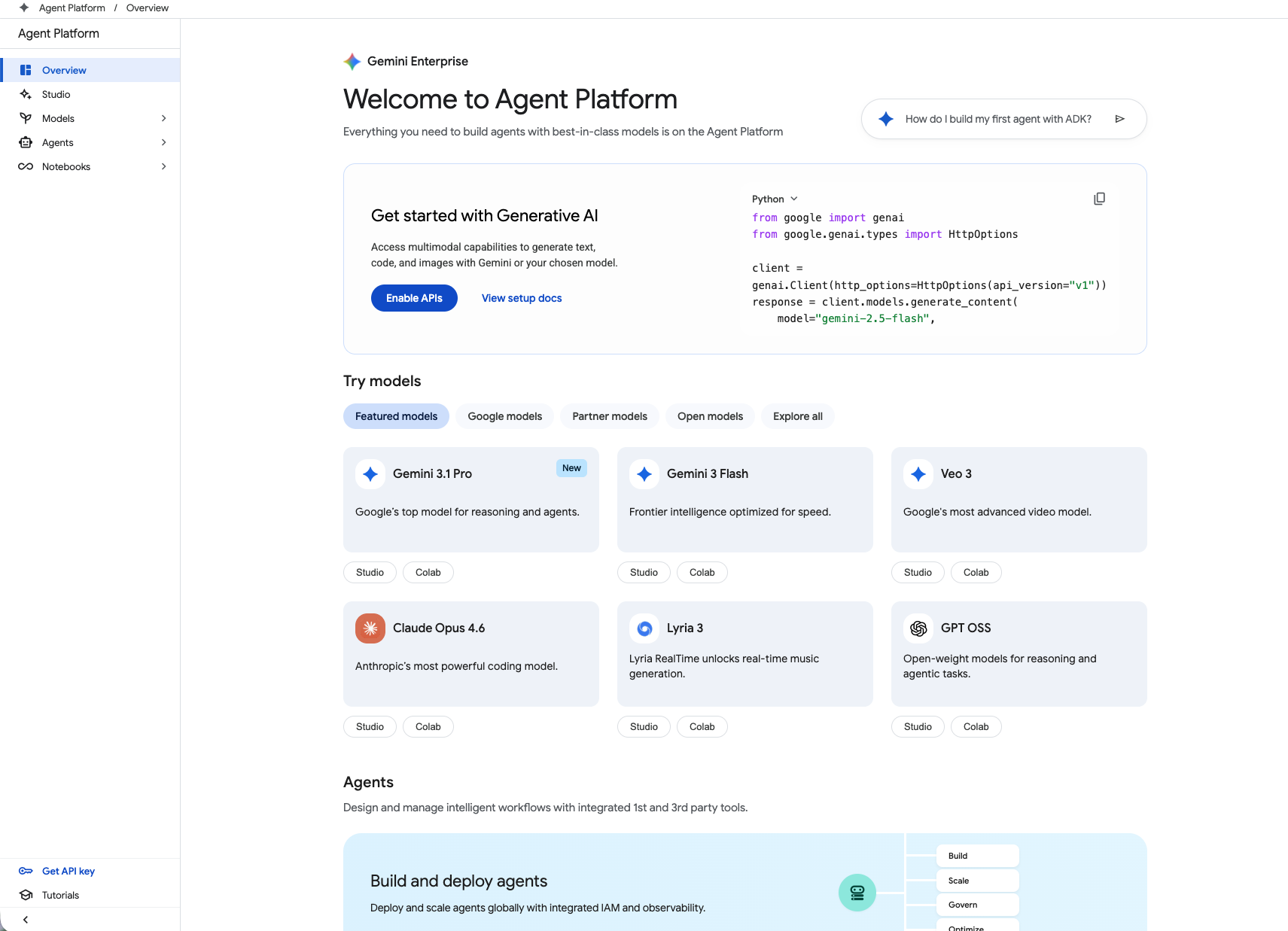
Scale agents effectively
Scale agents effectively
Clear the path to production with our upgraded Agent Runtime, which supports complex workflows that run for up to seven days. And with our Memory Bank, your agents get persistent, long-term context so interactions always feel highly personalized and recall past history.
Govern agents with confidence
Govern agents with confidence
Centrally manage your entire fleet of agents through a single source of truth using Agent Identity, Agent Registry, and Agent Gateway—enforcing zero-trust security and preventing prompt injections right at the infrastructure level.
Optimize agents
Optimize agents
To ensure quality, we give you tools for agent simulation, evaluation, and observability. This provides full execution traces and a real-time, 'glass-box' lens into your agents' reasoning loops so you can debug issues as they happen and continuously improve performance.
The developer hub for building innovative AI agents
Scale agents effectively
Scale agents effectively
Clear the path to production with our upgraded Agent Runtime, which supports complex workflows that run for up to seven days. And with our Memory Bank, your agents get persistent, long-term context so interactions always feel highly personalized and recall past history.
Govern agents with confidence
Govern agents with confidence
Centrally manage your entire fleet of agents through a single source of truth using Agent Identity, Agent Registry, and Agent Gateway—enforcing zero-trust security and preventing prompt injections right at the infrastructure level.
Optimize agents
Optimize agents
To ensure quality, we give you tools for agent simulation, evaluation, and observability. This provides full execution traces and a real-time, 'glass-box' lens into your agents' reasoning loops so you can debug issues as they happen and continuously improve performance.
Build production-ready agents faster
Give your developers the ultimate toolkit to create sophisticated agents using over 200 world-class models—including Gemini, Claude, and more—alongside our Agent Development Kit (ADK) and Agent Studio.
Scale agents effectively
Clear the path to production with our upgraded Agent Runtime, which supports complex workflows that run for up to seven days. And with our Memory Bank, your agents get persistent, long-term context so interactions always feel highly personalized and recall past history.
Govern agents with confidence
Centrally manage your entire fleet of agents through a single source of truth using Agent Identity, Agent Registry, and Agent Gateway—enforcing zero-trust security and preventing prompt injections right at the infrastructure level.
Optimize agents
To ensure quality, we give you tools for agent simulation, evaluation, and observability. This provides full execution traces and a real-time, 'glass-box' lens into your agents' reasoning loops so you can debug issues as they happen and continuously improve performance.
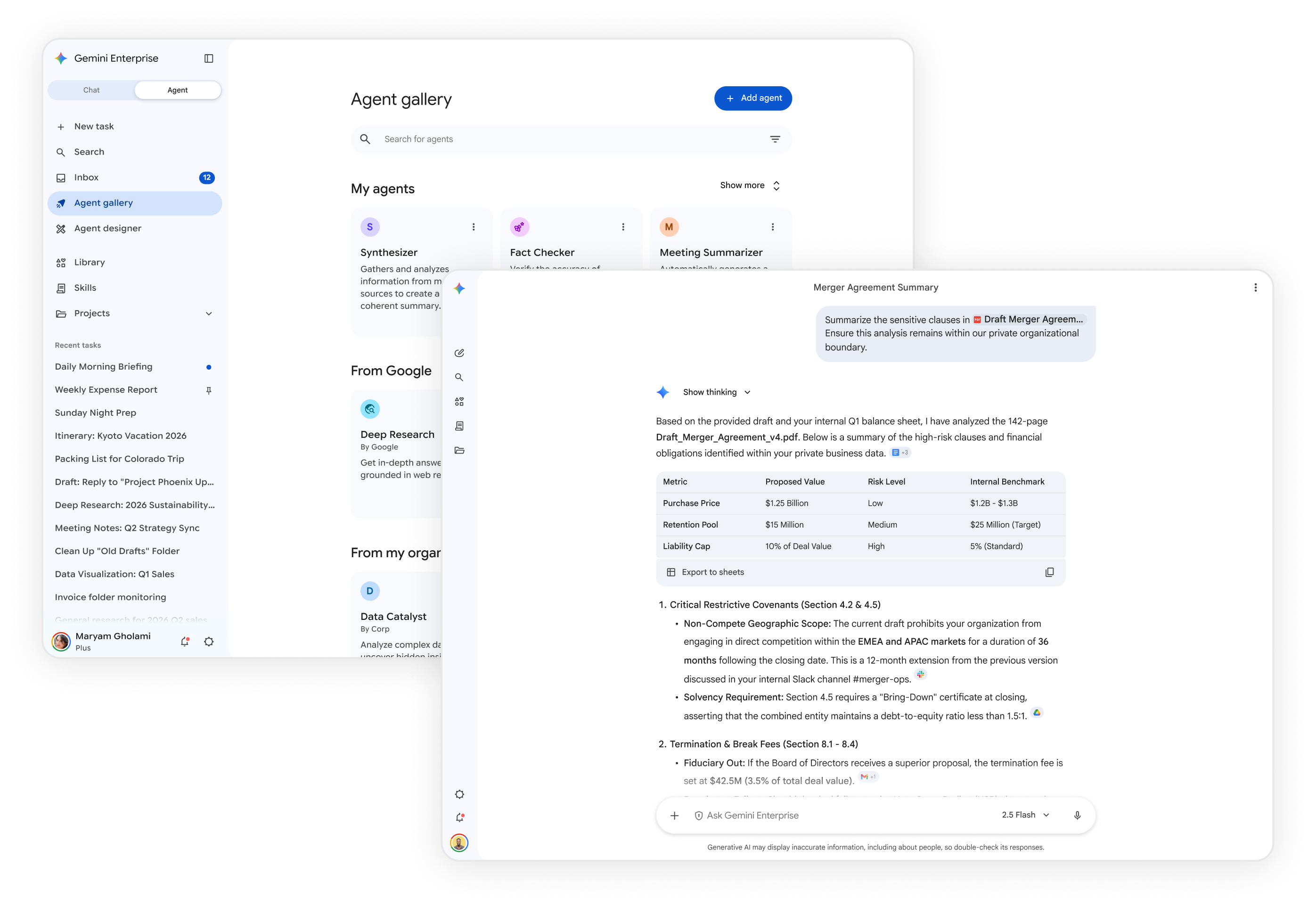
Collaborate with persistent team memory
Collaborate with persistent team memory
Ensure context is never lost, even as teams evolve. Establish shared, data-grounded knowledge bases through Projects. Pair this memory with Canvas Mode to co-create and refine documents in a dynamic, real-time environment.
Empower any employee to build custom agents
Empower any employee to build custom agents
Turn business expertise into automated action without writing a single line of code. Anyone can build robust, multi-system agents using natural language in the Agent Designer, seamlessly stitching long-running autonomous nodes together to execute custom business logic.
Govern your digital workforce centrally
Govern your digital workforce centrally
Give IT the control to innovate safely. Powered by the underlying Agent Platform, you can maintain centralized oversight through a searchable, secure directory. Utilize the unified Inbox as a command center to monitor all agent activity, handle human-in-the-loop approvals, and route alerts seamlessly—ensuring no-code AI creation remains strictly within your enterprise guardrails.
The employee hub for automating everyday work with an agentic taskforce
Drive outcomes with a curated digital taskforce
Move from individual tasks to end-to-end automation. Access specialized Google-made agents, like Deep Research and Data Insights, alongside a rich Marketplace of partner-made agents to instantly tackle complex operations. Deploy long-running agents that work autonomously in isolated sandboxes to complete mission-critical workflows over hours or days.
Collaborate with persistent team memory
Ensure context is never lost, even as teams evolve. Establish shared, data-grounded knowledge bases through Projects. Pair this memory with Canvas Mode to co-create and refine documents in a dynamic, real-time environment.
Empower any employee to build custom agents
Turn business expertise into automated action without writing a single line of code. Anyone can build robust, multi-system agents using natural language in the Agent Designer, seamlessly stitching long-running autonomous nodes together to execute custom business logic.
Govern your digital workforce centrally
Give IT the control to innovate safely. Powered by the underlying Agent Platform, you can maintain centralized oversight through a searchable, secure directory. Utilize the unified Inbox as a command center to monitor all agent activity, handle human-in-the-loop approvals, and route alerts seamlessly—ensuring no-code AI creation remains strictly within your enterprise guardrails.
The employee hub for automating everyday work with an agentic taskforce
Collaborate with persistent team memory
Collaborate with persistent team memory
Ensure context is never lost, even as teams evolve. Establish shared, data-grounded knowledge bases through Projects. Pair this memory with Canvas Mode to co-create and refine documents in a dynamic, real-time environment.
Empower any employee to build custom agents
Empower any employee to build custom agents
Turn business expertise into automated action without writing a single line of code. Anyone can build robust, multi-system agents using natural language in the Agent Designer, seamlessly stitching long-running autonomous nodes together to execute custom business logic.
Govern your digital workforce centrally
Govern your digital workforce centrally
Give IT the control to innovate safely. Powered by the underlying Agent Platform, you can maintain centralized oversight through a searchable, secure directory. Utilize the unified Inbox as a command center to monitor all agent activity, handle human-in-the-loop approvals, and route alerts seamlessly—ensuring no-code AI creation remains strictly within your enterprise guardrails.
Drive outcomes with a curated digital taskforce
Move from individual tasks to end-to-end automation. Access specialized Google-made agents, like Deep Research and Data Insights, alongside a rich Marketplace of partner-made agents to instantly tackle complex operations. Deploy long-running agents that work autonomously in isolated sandboxes to complete mission-critical workflows over hours or days.
Collaborate with persistent team memory
Ensure context is never lost, even as teams evolve. Establish shared, data-grounded knowledge bases through Projects. Pair this memory with Canvas Mode to co-create and refine documents in a dynamic, real-time environment.
Empower any employee to build custom agents
Turn business expertise into automated action without writing a single line of code. Anyone can build robust, multi-system agents using natural language in the Agent Designer, seamlessly stitching long-running autonomous nodes together to execute custom business logic.
Govern your digital workforce centrally
Give IT the control to innovate safely. Powered by the underlying Agent Platform, you can maintain centralized oversight through a searchable, secure directory. Utilize the unified Inbox as a command center to monitor all agent activity, handle human-in-the-loop approvals, and route alerts seamlessly—ensuring no-code AI creation remains strictly within your enterprise guardrails.
Transform your customer journeys with intelligent conversations
Increase revenue with active, agent discovery
Deploy a shopping agent that plans, reasons, and acts to guide your customers from a vague idea to a perfect match—across text, voice, and image. We offer specialized agents for every commerce vertical—from Shopping Agents for retail and ecommerce, to Food Ordering Agents for restaurants and grocery.
Build loyalty through personalized, multimodal journeys
Always-on agents retain context across every channel—so when a customer moves from search to chat to phone, they never have to start over. And because every interaction is scored and analyzed, your data activates in real time to deliver recommendations that feel known.
Innovate faster on a single, secure platform
Use our low-code CX Agent Studio and over 100 prebuilt connectors to launch service and support agents in days, not months—seamlessly connecting AI with your human teams and existing systems like Salesforce. Your data never trains our foundational model.
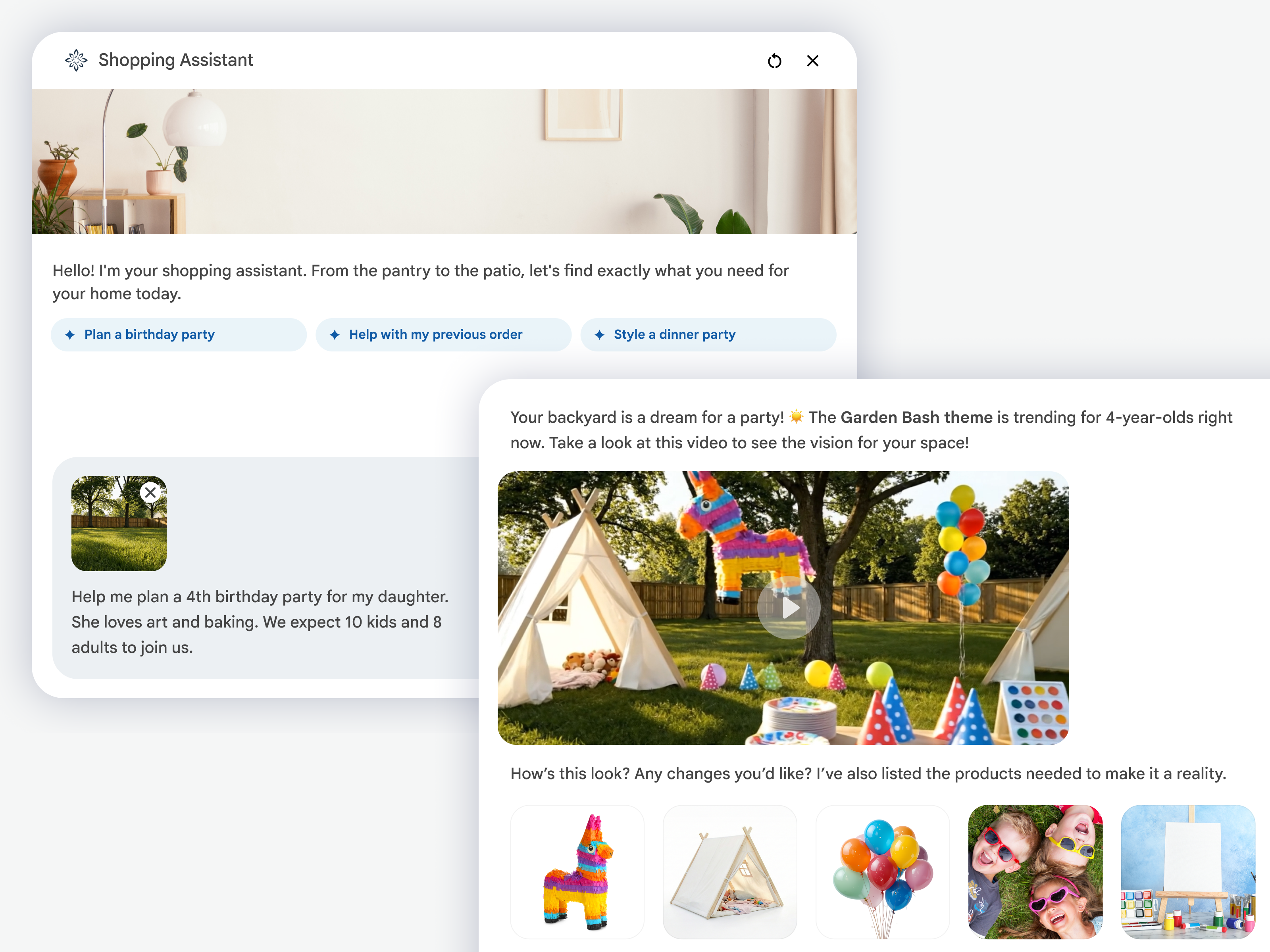
Build loyalty through personalized, multimodal journeys
Build loyalty through personalized, multimodal journeys
Always-on agents retain context across every channel—so when a customer moves from search to chat to phone, they never have to start over. And because every interaction is scored and analyzed, your data activates in real time to deliver recommendations that feel known.
Innovate faster on a single, secure platform
Innovate faster on a single, secure platform
Use our low-code CX Agent Studio and over 100 prebuilt connectors to launch service and support agents in days, not months—seamlessly connecting AI with your human teams and existing systems like Salesforce. Your data never trains our foundational model.
Transform your customer journeys with intelligent conversations
Build loyalty through personalized, multimodal journeys
Build loyalty through personalized, multimodal journeys
Always-on agents retain context across every channel—so when a customer moves from search to chat to phone, they never have to start over. And because every interaction is scored and analyzed, your data activates in real time to deliver recommendations that feel known.
Innovate faster on a single, secure platform
Innovate faster on a single, secure platform
Use our low-code CX Agent Studio and over 100 prebuilt connectors to launch service and support agents in days, not months—seamlessly connecting AI with your human teams and existing systems like Salesforce. Your data never trains our foundational model.
Increase revenue with active, agent discovery
Deploy a shopping agent that plans, reasons, and acts to guide your customers from a vague idea to a perfect match—across text, voice, and image. We offer specialized agents for every commerce vertical—from Shopping Agents for retail and ecommerce, to Food Ordering Agents for restaurants and grocery.
Build loyalty through personalized, multimodal journeys
Always-on agents retain context across every channel—so when a customer moves from search to chat to phone, they never have to start over. And because every interaction is scored and analyzed, your data activates in real time to deliver recommendations that feel known.
Innovate faster on a single, secure platform
Use our low-code CX Agent Studio and over 100 prebuilt connectors to launch service and support agents in days, not months—seamlessly connecting AI with your human teams and existing systems like Salesforce. Your data never trains our foundational model.
Gemini Enterprise enables real-world innovation
Gemini Enterprise enables real-world innovation





Browse resources
- The new Gemini Enterprise: one platform for agent development, orchestration, and governanceRead the blog
- Gemini Enterprise app: Introducing long-running agents, agentic collaboration spaces, advanced governance, and moreRead the blog
- Introducing Gemini Enterprise Agent Platform, powering the next wave of agentsRead the blog









What's new
- The new Gemini Enterprise: one platform for agent development, orchestration, and governanceRead the blog
- Gemini Enterprise app: Introducing long-running agents, agentic collaboration spaces, advanced governance, and moreRead the blog
- Introducing Gemini Enterprise Agent Platform, powering the next wave of agentsRead the blog
Reports
Events

Gemini Enterprise Agent Platform
Get startedGemini Enterprise app
Start 30-day trialGemini Enterprise for Customer Experience
Learn more

















