Accelerate: 2021 年の State of DevOps
パフォーマンスが最も高いソフトウェア チームと最も低いチームを分けている要素は何でしょうか。2021 年のレポートでは、ソフトウェア デリバリーと運用のパフォーマンスを向上させる活動について詳しく調べており、所属する組織と卓越したパフォーマンスのグループとの比較が可能です。そこから得られた知見を活かし、主要な成果を改善してイノベーションを加速させ、他社を一歩リードできます。
概要
Google Cloud の DevOps Research and Assessment(DORA)チームが作成した今年の Accelerate State of DevOps レポートは、32,000 を超える全世界の専門家に対する 7 年間の調査と、それらから得られたデータを示すものです。
私たちの調査では、ソフトウェア デリバリー、運用、および組織的なパフォーマンスを推進する能力とプラクティスを調べました。 厳密な統計的技法を活用して、テクノロジーの提供における優越性と、ビジネスの優れた結果を導くことのできる、プラクティスへの理解を目指しました。 この目標に向けて、テクノロジーを開発、提供する最も効果的で効率的な方法について、データドリブンな分析情報を提示します。
この調査により、ソフトウェア デリバリーと運用で高いパフォーマンスを上げている場合、技術変革における組織的なパフォーマンスが向上することがあらためて実証されました。チームが自分たちを業界と比較してベンチマークできるようにするため、私たちはクラスタ分析を使用して意味のあるパフォーマンス カテゴリを形成しました(低、中、高い、エリートというパフォーマンス別のグループなど)。 チームが、自分たちの現在のパフォーマンスが業界と比べてどの程度のものかを認識した後で、私たちの予測分析で発見された事項を使用して、主要な結果を改善し、最終的に自分たちの相対的な地位が向上するよう、プラクティスと能力の目標を設定できます。 今年は、信頼性のターゲットを満たし、ソフトウェアのサプライ チェーン全体にわたってセキュリティを統合して、高品質の内部ドキュメントを作成し、クラウドのポテンシャルを最大限に活用することの重要性を強調しています。 また、肯定的なチーム文化が、COVID-19(新型コロナウイルス感染症)パンデミックの結果としてリモートで勤務することの影響を軽減できるかどうかも探求しました。
意味のある改善を行うには、チームが継続的な改善という原理を採用する必要があります。 ベンチマークを使用して現在の状況を測定し、調査された能力に基づいて制約を識別し、それらの制約を緩和するための改善を試みてください。 探求には勝利と失敗の両方が伴いますが、どちらの場合もチームは得られた教訓の結果として有意義な行動をとることができます。
主な調査結果
最もパフォーマンスが高いグループは成長し続け、水準はさらに上がっています。
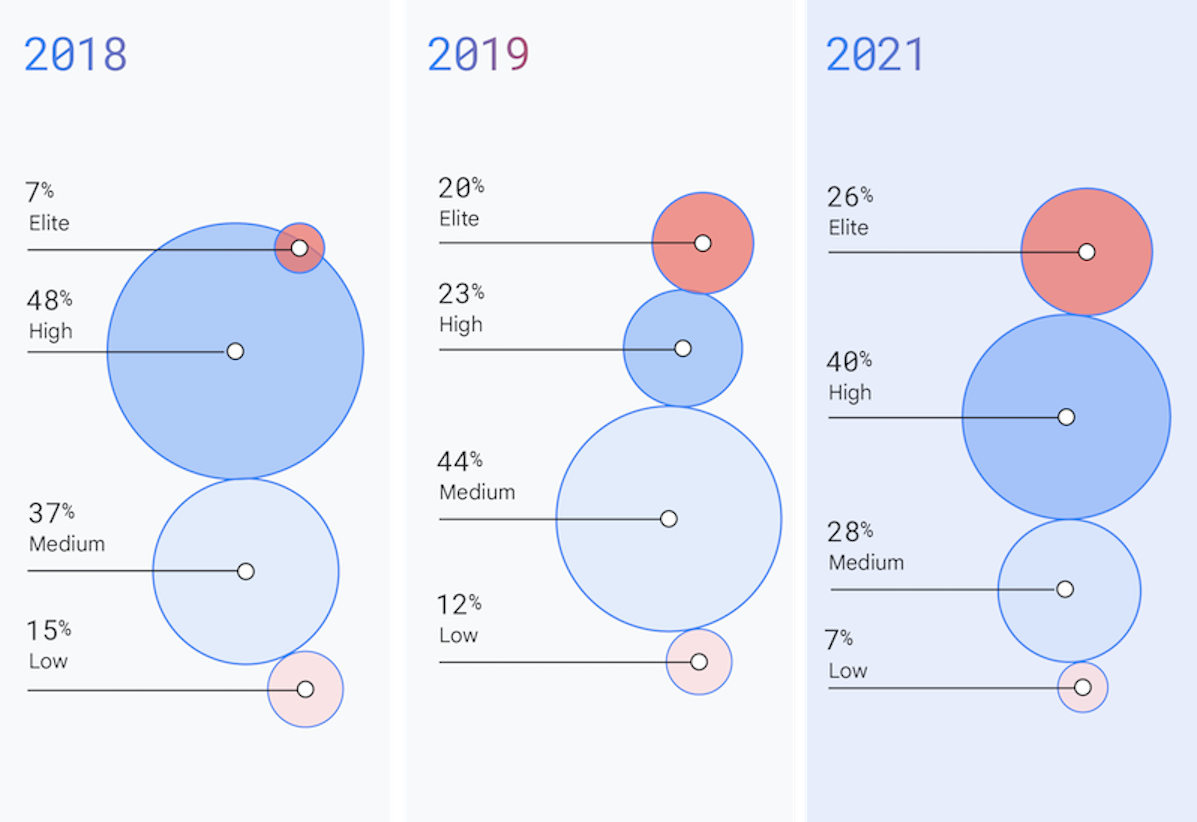
調査では、卓越したパフォーマンスのグループが全体の 26% を占めるようになり、本番環境の変更に関するリードタイムは短縮されています。業界はさらに加速し続けており、チームはそれによって有意義な利益を受けています。
SRE と DevOps は相補的な理念です。
サイト信頼性エンジニアリング(SRE)で概説されている最新の運用プラクティスを活用しているチームは、より高い運用パフォーマンスを報告しています。デリバリーのパフォーマンスと運用のパフォーマンスの両方を重視するチームは、組織的なパフォーマンスが最も高くなることが報告されています。
より多くのチームがクラウドを活用し、それによって大きな恩恵を受けています。
各チームはワークロードをクラウドに移行し続けており、クラウドの 5 つの能力すべてを活用したチームにはソフトウェア デリバリーと運用(SDO)のパフォーマンスや、組織としてのパフォーマンスの向上が見られました。 マルチクラウドの導入も増加傾向にあり、チームが各プロバイダ独自の機能を活用できるようになってきています。
安全なソフトウェア サプライ チェーンは不可欠であると同時に、パフォーマンスを引き上げます。
近年における悪意のある攻撃の大幅な増加を踏まえて、組織は事後対応的なプラクティスから予防的および診断的な方式に転換していく必要があります。 ソフトウェアのサプライ チェーン全体にセキュリティ プラクティスを統合したチームは、ソフトウェアを迅速に、高い信頼性で、安全に提供しています。
良質なドキュメントの作成は、DevOps を効果的に機能させるための基礎です。
今回の調査では初めて、内部ドキュメントの品質と、その品質を実現するために採用されたプラクティスを測定しました。 高品質のドキュメントを保有するチームは、技術的なプラクティスをより的確に実装でき、全体的なパフォーマンスも優れています。
チームに肯定的な文化があれば、困難な状況での燃え尽き症候群を軽減できます。
チームの文化は、チームがソフトウェアを提供し、組織的な目標を達成する、またはそれを超えた成果を得るうえで大きな差異をもたらします。生成1,2 文化を持つ包括的なチームは、COVID-19(新型コロナウイルス感染症)パンデミックの最中にも燃え尽き症候群はあまり発生しませんでした。
____________________________
1. Westrum の類型論の組織文化によると、生成チーム文化とは、協調性が高く、分断化を排除して、失敗を調査につなげ、意思決定のリスクを共有するようなチームとされています。
2. Westrum, R. (2004). 「A typology of organizational cultures」(英語)BMJ Quality & Safety、13(suppl 2)、ii22-ii27。
比較方法
自分のチームが業界の他のチームと比較するとどの程度だろうかとお考えでしょうか? このセクションでは、DevOps のパフォーマンスに関する最新のベンチマーク評価について説明します。
チームがソフトウェア システムをどのように開発、デリバリー、運用するかを調べ、回答者をエリート、高、中、低パフォーマンスの 4 つに分類しました。 チームのパフォーマンスを各クラスタのパフォーマンスと比較することで、このレポート全体で解説している調査結果に関して自分のチームがどのような位置にあるかを把握できます。
ソフトウェア デリバリーと運用パフォーマンス
変化し続ける業界からの要求に対応するため、組織はソフトウェアを迅速に、高い信頼性で提供し、運用する必要があります。 チームがソフトウェアへの変更を迅速に行えるほど、お客様に早く価値を提供し、実験を行い、貴重なフィードバックを得ることができます。 Google は 7 年間にわたってデータの収集と調査を行った結果、ソフトウェア デリバリーのパフォーマンスを測定するための 4 つの指標を作成し、検証しました。 2018 年から、組織の能力を捕捉するため 5 つ目の指標も追加しました。
5 つの基準すべてに秀でているチームは、組織として非常に優れたパフォーマンスを示しています。 Google は、これら 5 つの基準をソフトウェア デリバリーと運用(SDO)のパフォーマンスと呼んでいます。これらの指標はシステムレベルの成果に重点を置いたものです。ソフトウェア指標の一般的な落とし穴、たとえば機能が互いに相反する、ローカルな最適化により総合的な性能が低下するといった事態を避けるために役立ちます。
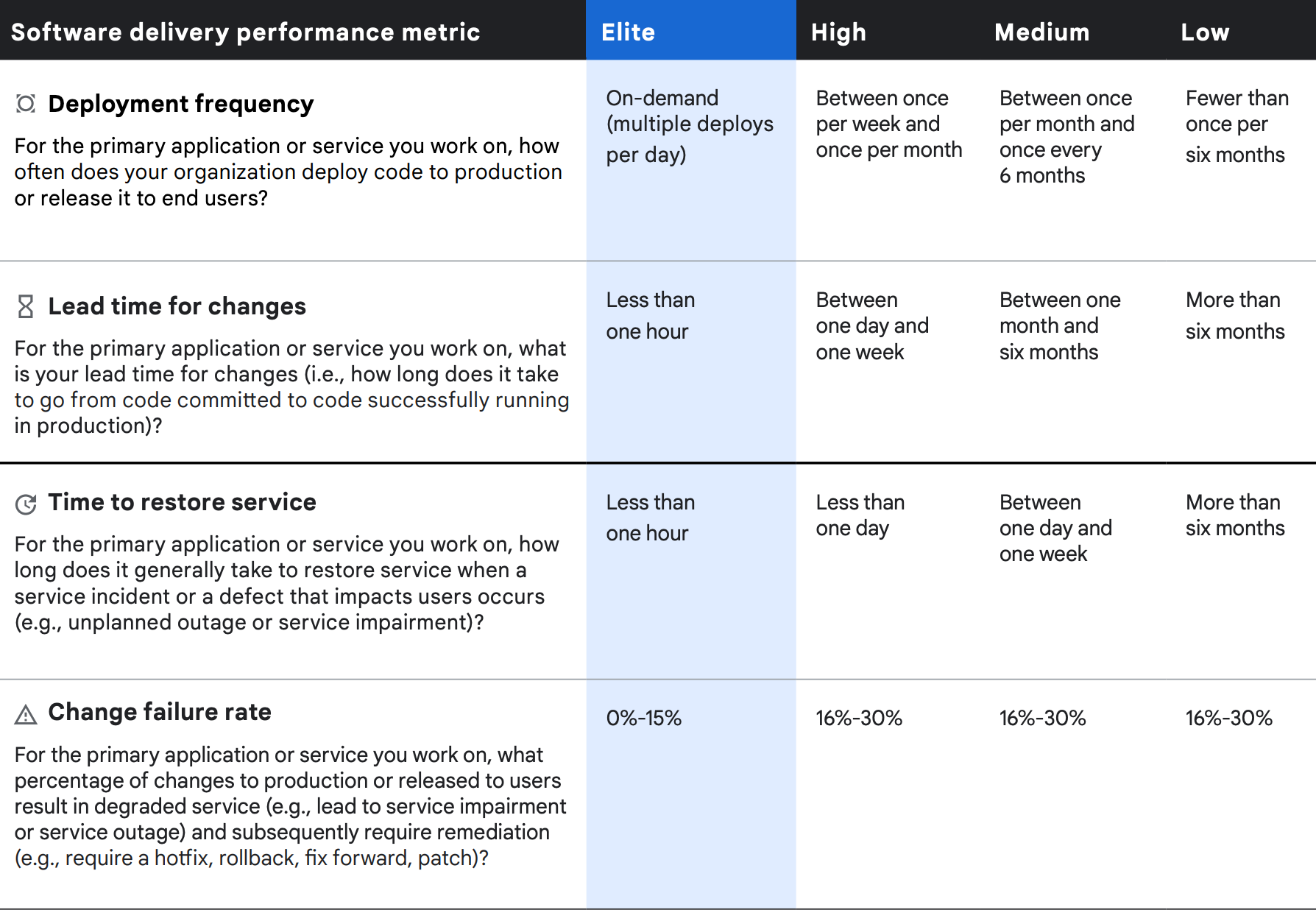
デリバリー パフォーマンスの 4 つの指標
ソフトウェア デリバリーのパフォーマンスに関する 4 つの指標は、スループットと安定性に関するものと考えることができます。 調査では、コード変更のリードタイム(すなわち、コードの commit から本番環境へのリリースまで)とデプロイの頻度を使用してスループットを測定しました。安定性は、インシデント発生後のサービス復旧時間と変更時の障害発生率を使用して測定しました。
ここでも、4 つのソフトウェア デリバリー指標を分析することで、エリート、高、中、低という 4 つの異なるパフォーマンス プロファイルが明らかになりました。これらのグループ間にはスループットと安定性の測定値において統計的に有意な差が見られます。これまでの年と同様に、最もパフォーマンスの高いチームは 4 つの指標すべてにおいて明確に優れており、パフォーマンスの低いチームはすべての分野において明確に劣っています。
5 番目の指標: 可用性から信頼性まで
5 番目の指標は運用のパフォーマンスを表すもので、最新の運用プラクティスを測定します。運用パフォーマンスの主な指標は信頼性で、チームが運用するソフトウェアについての期待と主張をどの程度満たすことができるかを示します。これまでの調査では信頼性ではなく可用性を測定してきましたが、可用性は信頼性エンジニアリングに特有の指標であるため、測定の幅を信頼性まで広げました。これにより、可用性、レイテンシ、パフォーマンス、スケーラビリティがより広く示されるようになりました。 具体的には、回答者に、信頼性に関する目標を達成または上回る能力を評価するように依頼しました。デリバリーのパフォーマンス レベルの異なる複数のチームで、デリバリーだけでなく運用のパフォーマンスも重視する場合に、より優れた結果を得られることが確認されました。
以前のレポートと同様に、エリートの評価を得たチームと評価の低いチームとを比較し、特定の能力がどのような影響を及ぼすかを明らかにしました。 しかし今年は、運用のパフォーマンスの影響も考慮に入れることを目指しました。 デリバリー パフォーマンスのすべてのカテゴリ(低からエリートまで)において、自らの信頼性目標を満たした、または超えたチームでは、複数の結果にわたって大きな利益が見られました。
ますます加速していく業界
業界は年々進化し続け、ソフトウェアをより迅速に、より高い安定性で提供する能力が進歩していきます。 調査開始以降初めて、回答者の 2/3 が高およびエリートのパフォーマンスを挙げているチームとなりました。 さらに、今年エリートの成績を挙げたチームはさらに水準が上がり、以前の評価と比べても変更のリードタイムが短縮されました(たとえば、2019 年には 1 日未満だったものが、2021 年には 1 時間以内になりました)。 また、これも初めてのこととして、エリートの成績を挙げたチームだけが変更の障害率を最小化しました。今年以前では中や高の成績を挙げたチームも変更の障害率を最小化していました。
スループットと安定性
スループット
デプロイの頻度
これまでの年と同様に、エリートのグループは常時オンデマンドでデプロイを行い、1 日に何回もデプロイを行っていると報告しました。これに対して、低のパフォーマンスだったグループはデプロイが 6 か月に 1 回未満(1 年に 2 回未満)だと報告しており、同様に 2019 年と比較してパフォーマンスが低下しています。 正規化された年間デプロイ回数は、最もパフォーマンスの高いグループで 1,460 回(1 日 4 回 × 365 日と計算)、低のパフォーマンスだったグループでは年間 1.5 回(年に 2 回と 1 回の平均)でした。 この分析から、エリートのパフォーマンスを得たグループは、低のパフォーマンスのグループよりもコードを約 973 倍の頻度でデプロイしていることが示されました。
変更のリードタイム
2019 年からの改善点として、エリートのパフォーマンスのグループはリードタイムが 1 時間未満になりました。このリードタイムは、コードが commit されてから、本番環境に正しくデプロイされるまでの時間で計測したものです。 2019 年に最も高いパフォーマンスだったグループの報告したリードタイムは 1 日未満だったため、これと比べてもパフォーマンスが向上しています。 エリートのパフォーマンスのグループと比べて、低のパフォーマンスのグループは 6 か月を超えるリードタイムを必要としていました。 リードタイムが、エリートのパフォーマンスのグループでは 1 時間(「1 時間未満」を多めにみた推定値)なのに対して、低のパフォーマンスのグループでは 6,570 時間(1 年の 8,760 時間と 6 か月分の 4,380 時間の平均で計算)で、エリートのグループは低のグループよりも変更のリードタイムが 6,570 倍速くなっています。
安定性
サービス復旧時間
エリートのグループはサービス復旧時間が 1 時間未満だと報告したのに対して、低のグループは 6 か月を超えると報告しました。 この計算では、控えめな推定時間として、高のパフォーマンスのグループでは 1 時間、低のパフォーマンスのグループでは 1 年(8,760 時間)と 6 か月(4,380 時間)の中間値としました。 これらの数値に基づいて、エリートのグループは低のグループよりも 6,570 倍も速くサービスを復旧できます。 2019 年と比べて、サービス復旧時間のパフォーマンスはエリートのパフォーマンスのグループでは変化なしで、低のパフォーマンスのグループでは増加しました。
変更時の障害率
エリートのパフォーマンスのグループでは変更時の障害率が 0%~15% なのに対して、低のパフォーマンスのグループでは変更時の障害率が 16%~30% です。 これら 2 つの範囲の値に対する中間値では、エリートのパフォーマンスのグループでは変更時の障害率が 7.5%、低のパフォーマンスのグループでは 23% になります。 エリートのパフォーマンスのグループでは、低のパフォーマンスのグループと比べて、変更時の障害率が 1/3 です。 今年、エリートのパフォーマンスのグループでは障害率が変化せず、低のパフォーマンスのグループでは 2019 年よりも改善されましたが、その中間のグループでは悪化しました。
エリート パフォーマンスのグループ
パフォーマンスがエリートのグループと低のグループを比べると、エリートのグループは次の点で優れています。
- コードのデプロイ頻度が 973 倍
- commit からデプロイまでのリードタイムの高速化が 6570 倍
- 変更時の障害率の低さ(変更が失敗する可能性が 1/3)が 3 倍
- インシデントからの回復時間の短縮が 6570 倍
改善のための提案
SDO と組織的なパフォーマンスを改善するにはどうしたらいいでしょうか?調査結果から、パフォーマンスを推進する能力に集中するために役立つ、証拠に基づいたガイドを提供します。
今年のレポートでは、クラウド、SRE プラクティス、セキュリティ、技術的な実践方式、文化の影響について調べました。 このセクションを通して、これらの能力のそれぞれについて紹介し、それらが各種の結果にどのような影響を与えるかについて言及します。 DORA の State of DevOps 調査モデルについてご存じの方のために、今年のモデルと、過去のモデルすべてをホストしたオンライン リソースを作成しました。3
____________________________
3. https://devops-research.com/models.htm
____________________________
クラウド
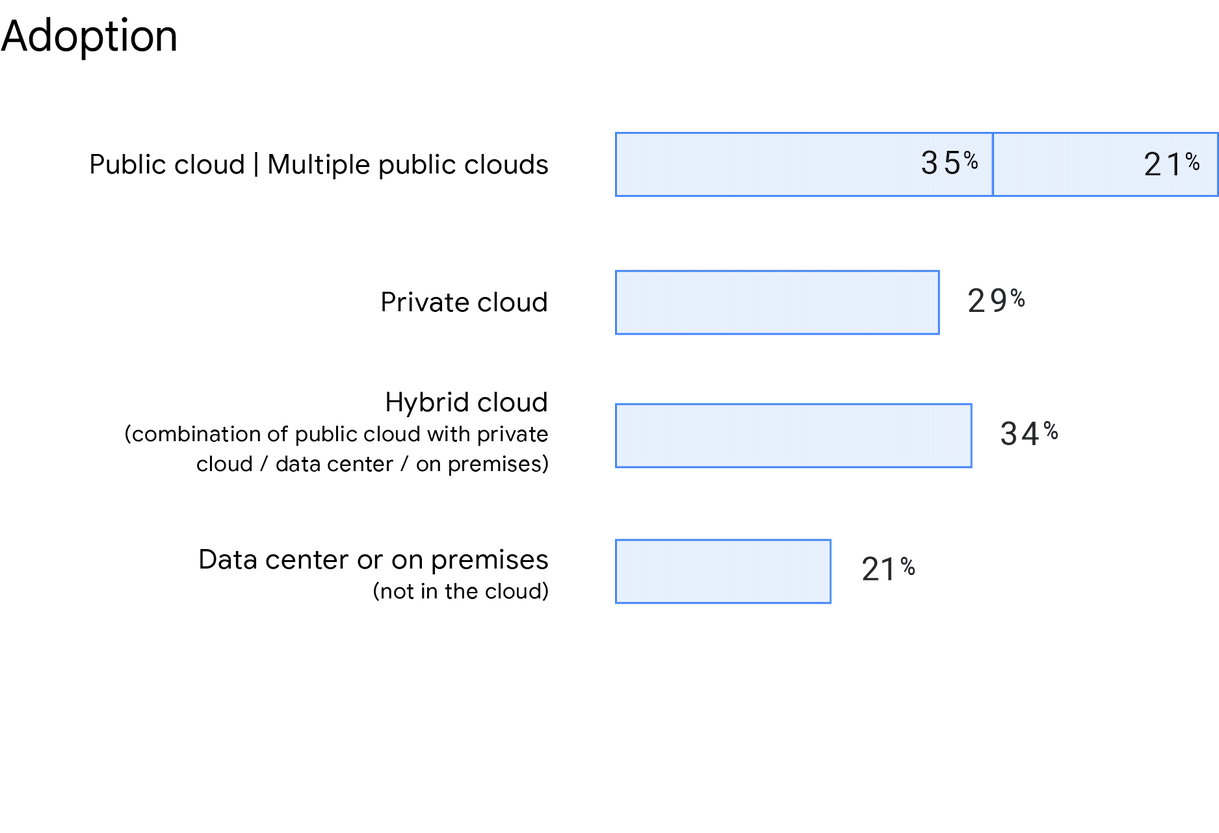
Accelerate State of DevOps 2019 のときと同様に、マルチクラウドやハイブリッド クラウド ソリューションを選択する組織の数は増え続けています。Google のアンケートで、メインのサービスまたはアプリケーションがホストされる場所を回答者に質問したところ、パブリック クラウドの利用が増加していました。 回答者の 56% はパブリック クラウド(複数のパブリック クラウドを使用している回答者も含む)を使用していると回答し、これは 2019 年よりも 5% 増えています。 今年はマルチクラウドの使用についても別の質問を行い、回答者の 21% は複数のパブリック クラウドにデプロイしていると回答しました。回答者の 21% はクラウドを使用しておらず、代わりにデータセンターやオンプレミスのソリューションを使用していると回答しました。 最後に、回答者の 34% はハイブリッド クラウドを、29% はプライベート クラウドを使用していると回答しました。
ハイブリッドやマルチクラウドによってビジネスの成果を促進
今年見られたのは、ハイブリッドやマルチクラウドの増加で、ビジネスにとって重要な成果にも明確な影響を及ぼしています。ハイブリッドやマルチクラウドを使用している回答者は、使用していない回答者よりも、組織のパフォーマンス目標を超える割合が 1.6 倍も高くなっています。また、SDO への強い影響も見られました。ハイブリッドやマルチクラウドのユーザーは、デプロイの頻度、変更のリードタイム、復旧時間、変更時の障害率、信頼性について優れている可能性が 1.4 倍高くなっています。
なぜマルチクラウドなのか?
2018 年の評価と同様に、複数のパブリック クラウド プロバイダを使用する理論的根拠を回答者にたずねました。 今年は、該当する選択肢をすべて選んでもらうのではなく、複数のプロバイダを使用する一番の理由について回答してもらいました。 回答者の 1/4 以上(26%)は、各クラウド プロバイダに固有の利点を活用するために、複数のプロバイダを使用していました。 すなわち、回答者が追加のプロバイダを選択するときは、現在のプロバイダと他の選択肢との差別化要因を探していると推定されます。 マルチクラウドに移行する理由として 2 番目に多かったのは可用性です(22%)。複数のクラウド プロバイダを採用した回答者において、自分たちの信頼性目標を満たす、または超えている割合が 1.5 倍も高かったことは驚くにあたりません。
複数のプロバイダを利用する主な理由
各プロバイダ固有の利点の活用 | 26% |
可用性 | 22% |
障害復旧 | 17% |
法令遵守 | 13% |
その他 | 08% |
交渉戦術または調達要件 | 08% |
プロバイダ 1 社では信頼できない | 06% |
各プロバイダ固有の利点の活用
26%
可用性
22%
障害復旧
17%
法令遵守
13%
その他
08%
交渉戦術または調達要件
08%
プロバイダ 1 社では信頼できない
06%
ベンチマークの変更
クラウド インフラストラクチャの実装方法が重要
これまでの調査で、すべての回答者がクラウドを同じ方法で採用しているわけではないことが判明しています。 このため、クラウドの採用がどれだけビジネス成果に有効となるかという点について差異が発生します。 この調査では、米国国立標準技術研究所(NIST)で定義されたクラウド コンピューティングの本質的な特性に的を絞り、これを指針とすることで、この制限に対処します。NIST によるクラウド コンピューティングの定義を使用して、クラウド採用が SDO に及ぼす影響を調査するだけでなく、重要なプラクティスが SDO のパフォーマンスに及ぼす影響を調査しました。
本当に重要なのは、チームがクラウド テクノロジーを使用するというだけではなく、チームがどのようにクラウド サービスを実装するかだということが、ここでも明らかになっています。 エリートのパフォーマンスのグループは、すべての本質的な NIST クラウド特性を満たしている割合が 3.5 倍も高くなっています。 クラウド インフラストラクチャを使用していると回答した回答者のうち、NIST により定義されたクラウド コンピューティングの本質的な特性 5 つのすべてを満たしているかという点について、そう思う、または非常にそう思うと答えたのはわずか 32% で、2019 年よりも 3% 増加しています。 全体として、NIST が定義するクラウド コンピューティングの特性を使用している割合は 14~19% 増加しており、そのうち「迅速な弾力性」が最も増加しています。
オンデマンド、セルフサービス
ユーザーは、必要に応じてコンピューティング リソースを自動的にプロビジョニングでき、プロバイダ側で人手による介入は必要ありません。
回答者の 73% がオンデマンドのセルフサービスを使用しており、2019 年よりも 16% 増加しました。
広範なネットワーク アクセス
機能が広範に利用でき、スマートフォン、タブレット、ノートパソコン、ワークステーションなど複数のクライアントからアクセス可能です。
回答者の 74% が広範なネットワーク アクセスを使用しており、2019 年から 14% 増加しました。
リソースプール
プロバイダのリソースはマルチテナント モデルでプールされ、物理および仮想リソースがオンデマンドで動的に割り当ておよび再割り当てされます。顧客は一般に、提供されるリソースの正確な場所を直接コントロールできませんが、より高レベルの抽象化で、たとえば国、州、データセンターなどの場所を指定できます。
回答者の 73% がリソースプールを使用しており、2019 年から 15% 増加しました。
迅速な弾力性
能力を弾力的にプロビジョニングしてリリースし、必要に応じて迅速にスケールアウトまたはスケールインできます。 ユーザーからは、無制限の能力がプロビジョニング可能で、いつでもどれだけでも充当できるように見えます。
回答者の 77% が迅速な弾力性を使用しており、2019 年から 18% 増加しました。
メジャード サービス
クラウド システムは、サービスのタイプに適切なレベルの抽象化、たとえばストレージ、処理、帯域幅、アクティブなユーザー アカウントなどで測定機能を利用し、リソースの使用を自動的にコントロールして最適化できます。 リソースの使用をモニタリング、コントロール、報告することで透明性を実現できます。
回答者の 78% がメジャード サービスを利用しており、2019 年から 16% 増加しました。
SRE と DevOps
DevOps コミュニティが公共の会議や話題に登場し始めたころ、Google の中でも同じ志の運動であるサイト信頼性エンジニアリング(SRE)が形成されていました。 SRE や、Facebook のプロダクション エンジニアリング分野など同様な手法は、DevOps を動機付けたのと同じ目標と技法の多くを取り入れています。 SRE は 2016 年に、サイト信頼性エンジニアリングに関する最初の本4 が刊行されたとき、一般的に知られるようになりました。それ以後にこの運動は成長し、今日では SRE 実務者が技術的な運用のプラクティスに関して協力し合う国際的なコミュニティとなりました。
おそらく必然でしょうが、混乱も生まれました。SRE と DevOps との相違は何なのか? どちらかを選ぶ必要があるのか? どちらの方が良いものなのか? 実際のところ、この 2 つは競合するものではありません。SRE と DevOps は補完性が高いもので、調査から双方の連携が示されています。 SRE は学習の規律で、職能間にわたる連絡と心理的な安全性を優先しています。これらはエリート DevOps チームに典型的な、パフォーマンス指向の生成文化の中核をなすものと同じ価値です。 SRE はその中核的な規律を拡大し、サービスレベル指標 / サービスレベル目標(SLI / SLO)指標フレームワークを含む実践的な技法を提供しています。 リーン プロダクト フレームワークで、Google の調査で明らかになった迅速な顧客フィードバック サイクルを達成する方法が指定されているように、SRE フレームワークでは、チームがユーザーに対する約束を常に果たし続ける能力を向上させるための実践とツールが定義されています。
Google は 2021 年に、運用への質問の幅を、サービスの可用性の分析から、信頼性のより一般的なカテゴリへと拡大しました。 今年の調査では、SRE の実践からヒントを得て、チームが次のような行動をどの程度まで行っているかを評価するため、いくつかの項目を付け加えました。
- ユーザーへの対応に関して信頼性を定義する
- SLI / SLO 指標フレームワークを採用して、エラー バジェットにより作業に優先順位を付ける
- 自動化を利用して、手作業と、仕事の妨げになるアラートを削減する
- インシデント対応のプロトコルと、対応準備をテストするための演習を定義する
- ソフトウェア デリバリーのライフサイクル全体にわたり、信頼性に関する原則を取り入れる(「信頼性のシフトレフト」)
結果を分析すると、このような最新のオペレーションのプラクティスに優れているチームは、優れた SDO パフォーマンスを報告する可能性が 1.4 倍も高く、ビジネス上の良好な成果を報告する可能性も 1.8 倍高いことが明らかになりました。
SRE のプラクティスは、調査対象となったチームの大部分に取り入れられていました。回答者の 52% は、これらのプラクティスをある程度の範囲で使用していると報告しましたが、どの程度採用しているかはチーム間で大きく異なっています。データから、これらの手法を使用することで、より高い信頼性と、より高い総合的な SDO パフォーマンスを期待できます。SRE により DevOps の成功を促進できます。
さらに、開発者とオペレータがどの程度共同で信頼性に取り組むかに反映される運用責任の共有モデルは、信頼性に関しても良い結果を期待できることが明らかになりました。
パフォーマンスの目標となる測定値の改善だけでなく、SRE によって作業の実務担当者向けの環境も改善されます。 一般に、運用タスクの過剰な負荷を負わされた人物は燃え尽き症候群になりやすいものですが、SRE はプラス効果があります。 チームが SRE プラクティスを採用するほど、メンバーが燃え尽き症候群を体験する可能性が低くなることを発見しました。 SRE はリソースの最適化にも役立ちます。SRE プラクティスの適用によって信頼性目標を満たしたチームは、SRE プラクティスを実践していないチームよりも多くの時間をコードの作成に費やしていると報告しています。
調査により、低からエリートまで、どの SDO パフォーマンス レベルのチームも、SRE プラクティスの使用を増やすことで恩恵を受けられる可能性が高いことが明らかになりました。チームのパフォーマンスが高いほど、現代的な運用モードを採用する可能性も高くなります。エリートのパフォーマンスのグループは、低のパフォーマンスのグループよりも、SRE プラクティスを使用していると回答する割合が 2.1 倍も高くなっています。しかし、最高レベルで運用を行っているチームでも成長の余地はあります。エリート回答者のうち、Google が調査したすべての SRE プラクティスを完全に実装していたことが示されたのはわずか 10% です。各産業における SDO パフォーマンスが進歩し続けるにつれ、各チームの運用の手法は、継続的な DevOps 改善の重要な推進力となります。
____________________________
4. Betsy Beyer その他による共同編集、「Site Reliability Engineering」(英語)(O’Reilly Media、2016 年)。
____________________________
ドキュメントとセキュリティ
ドキュメント
今年の調査では、内部ドキュメントの品質を調査しました。これは、チームが扱っているサービスやアプリケーションのマニュアル、README、コードのコメントなどのドキュメントを意味します。ドキュメントの品質は、そのドキュメントが次の条件をどの程度満たしているかで測定されました。
- 読者が目的を達成するため役立つ
- 正確かつ最新の内容で、理解しやすい
- 情報が見つけやすく、よく整理されており、明瞭である 5
内部システムについての情報の記録とアクセスは、チームの技術的な作業の重要な部分です。 調査から、回答者の約 25% が良い品質のドキュメントを保有していることがわかっており、そのドキュメント作業の影響は明白です。高品質のドキュメントを保有しているチームは、ソフトウェア デリバリーと運用(SDO)パフォーマンスも優れている割合が 2.4 倍です。良いドキュメントを保有しているチームは、そうでないチームと比べて、ソフトウェアをより迅速に、高い信頼性で提供できます。 ドキュメントが完璧である必要はありませんが、調査では、ドキュメント品質のどのような改善も、パフォーマンスに肯定的かつ直接的な影響があることが示されています。
今日のテクノロジー環境は、システムとして日々複雑化しつつあり、それらのシステムの異なる側面について専門家や、特化した役割が存在します。 セキュリティからテストまで、ドキュメントは専門のサブチームと、より広範なチームの両方にとって、専門的な知識とガイダンスを共有する主要な方法となります。
ドキュメントの品質から、そのチームが技術的なプラクティスの実装に成功するかどうかを予測できることが明らかになっています。 さらにこれらのプラクティスは、システムの技術的な能力、たとえばオブザーバビリティ、継続的なテスト、デプロイの自動化などの改善も予測できます。 高品質のドキュメントを保有するチームは、次のような優位点があることが判明しました。
- セキュリティ プラクティスを実装する割合が 3.8 倍
- 自らの信頼性目標を満たす、または超える割合が 2.4 倍
- サイト信頼性エンジニアリング(SRE)プラクティスを実装する割合が 3.5 倍
- クラウドを完全に活用する割合が 2.5 倍
ドキュメントの品質改善の方法
技術的な作業には、情報の発見と使用が含まれますが、高品質のドキュメントを作成するにはコンテンツの作成と保守を行う人員が必要です。 2019 年の Google の調査では、内部および外部の情報ソースへのアクセスにより生産性を保つことができることが明らかになりました。 今年の調査ではさらに一歩進めて、アクセスされたドキュメントの品質や、そのドキュメントの品質に影響するプラクティスについて調べました。
調査から、以下のようなプラクティスがドキュメントの品質に大きな好影響をもたらすことが示されました。
プロダクトやサービスの重要なユースケースを文書化する。システムについて何を文書化するかが重要で、読者はユースケースによって情報とシステムを有効に活用することができます。
既存のドキュメントの更新と編集について明確なガイドラインを作成する。 ドキュメントに関する作業の多くは、既存のコンテンツの保守です。 チームのメンバーが、更新の方法や、不正確または古くなった情報を削除する方法を理解していれば、長期的にシステムが変更されても、チームはドキュメントの品質を維持できます。
オーナーを定義する。高品質のドキュメントを持つチームは、ドキュメントの所有権も明確に定義している割合が高くなっています。 所有権により、新しいコンテンツの作成や、既存のコンテンツの更新と変更内容の検証について、責任の所在を明らかにできます。 高品質のドキュメントを持つチームは、取り扱っているアプリケーションのすべての主要な機能についてドキュメントが作成されており、その広範な機能を文書化するために明確な所有権が役立っていると回答する割合が高くなっています。
ソフトウェア開発プロセスの一部としてドキュメントを含める。 ドキュメントを作成した後で、システム変更と同時にドキュメントの更新を行うチームは、より高品質のドキュメントを持っていると言えます。 ドキュメントの作成と保守は、テストと同様に、パフォーマンスの高いソフトウェア開発プロセスに欠かせない部分です。
パフォーマンスのレビューやプロモーション中に、ドキュメント作業を認識する。評価は、ドキュメントの総合的な品質と関連します。 ドキュメントの作成と保守はソフトウェア エンジニアリング作業の中核部分で、正しく扱うことで品質向上に結び付けられます。
高品質のドキュメントを支える他のリソースとして、次のようなものが判明しました。
- ドキュメントの作成と保守の方法についてのトレーニング
- コードサンプルや不完全なドキュメントの自動テスト
- ドキュメントのスタイルガイドや、グローバルな対象層に向けた作成の手引きなどのガイドライン
ドキュメントは、DevOps を効果的に機能させるための基礎です。 高品質のドキュメントにより、DevOps のセキュリティ、信頼性など個別の能力への投資からより大きな結果を引き出し、クラウドを十分に活用できるようになります。 高品質のドキュメントを支えるプラクティスを実行すれば、技術的な能力の強化と、SDO パフォーマンスの向上として見返りが期待できます。
____________________________
5. 技術ドキュメントについての次のような既存の調査から得られた品質指標
— Aghajani, E. 他、(2019 年)。「Software Documentation Issues Unveiled」(英語)、 2019 年の IEEE/ACM 第 41 回ソフトウェア エンジニアリング国際会議の議事録、1199~1210。https://doi.org/10.1109/ICSE.2019.00122
— Plösch, R.、Dautovic, A.、および Saft, M、(2014). 「The Value of Software Documentation Quality」(英語)、 高品質のソフトウェアについての国際会議の議事録、333~342。https://doi.org/10.1109/QSIC.2014.22
— Zhi, J. 他、(2015 年)。「Cost benefits and quality of software development documentation: A systematic mapping」(英語)、Journal of Systems and Software、99(C)、175~198。https://doi.org/10.1016/j.jss.2014.09.042
____________________________
セキュリティ
[シフトレフト] と全体の統合
技術チームが加速・進化し続ける一方で、セキュリティへの脅威も件数が増加し、複雑性も増しています。2020 年には、「Tenable’s 2020 Threat Landscape Retrospective Report」(英語)によれば、220 億レコードを超える機密個人情報やビジネスデータが漏えいしました。6 セキュリティは後付けや、提供前の最後のステップではいけません。ソフトウェア開発プロセスの全体を通じて組み込まれている必要があります。
ソフトウェアを安全に提供するには、悪意のある人物によって使用される技法より速く、セキュリティ プラクティスが進化する必要があります。 2020 年の SolarWinds および Codecov ソフトウェアのサプライ チェーン攻撃において、ハッカーは SolarWinds のビルドシステムと、Codecov の bash アップローダー スクリプトを侵害し7、それらの企業が抱えている数千もの顧客のインフラストラクチャに自分たちのコードを密かに埋め込みました。これらの攻撃の広範な影響を考えれば、業界は予防的な手法から診断的な手法に移行する必要があります。すなわち、ソフトウェア チームは自分たちのシステムがすでに侵害されていると想定し、自分たちのサプライ チェーンにセキュリティを構築するべきです。
以前のレポートと同様に、エリートのパフォーマンスのグループはセキュリティ プラクティスの使用でも優れていることが判明しました。 今年の調査において、エリートのパフォーマンスで信頼性の目標を満たした、または超えたグループは、ソフトウェアの開発プロセスにセキュリティが統合されている割合が 2 倍でした。ここから、信頼性の標準を維持しながら提供を迅速化したチームは、ソフトウェアを迅速に、高い信頼性で提供する能力を犠牲にすることなく、セキュリティ チェックとプラクティスを統合する方法を見つけたことが推測されます。
開発プロセス全体にセキュリティ プラクティスを統合したチームは、提供と運用の高いパフォーマンスを示しただけでなく、組織としての目標を満たす、または超える割合も 1.6 倍高くなっています。セキュリティを採用した開発チームは、ビジネスに多くの価値を生み出しています。
____________________________
6. https://www.tenable.com/cyber-exposure/2020-threat-landscape-retrospective
7. https://www.cybersecuritydive.com/news/codecov-breach-solarwinds-software-supply-chain/598950/
____________________________
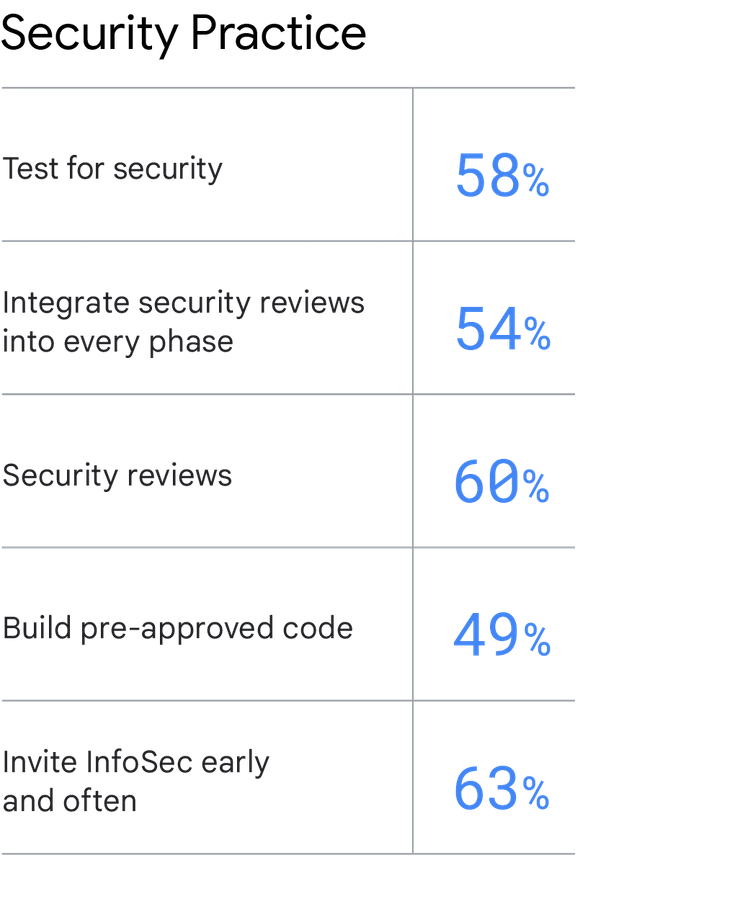
正しく行う方法
セキュリティの重要性を強調し、チームでセキュリティを優先する必要があると勧告するのは簡単ですが、それを行うには従来型の情報セキュリティ手法にいくつかの変更を加える必要があります。 以下のようなプラクティスを活用することで、セキュリティを統合し、ソフトウェアのデリバリーと運用のパフォーマンスを改善して、組織としてのパフォーマンスも改善できます。
テストにセキュリティを含める。 自動化されたテストプロセスの一部としてセキュリティ要件をテストします。事前に承認されたコードを使用する必要がある領域もテストの対象になります。
すべてのフェーズにセキュリティ レビューを統合する。 情報セキュリティ(InfoSec)を、ソフトウェア デリバリーのライフサイクル全体で日常業務に統合します。 これには、アプリケーションの設計とアーキテクチャのフェーズで InfoSec チームがアドバイスを提供する、ソフトウェアのデモに参加する、デモ中にフィードバックを行うことが含まれます。
セキュリティのレビュー。 主要な機能のすべてについて、セキュリティのレビューを行います。 事前に承認されたコードをビルドする。InfoSec チームが事前承認済みの使いやすいライブラリ、パッケージ、ツールチェーン、プロセスを構築し、開発者や IT オペレータが作業で使えるようにします。 早期から InfoSec を頻繁に関与。アプリケーション開発の計画の段階、および以後のすべてのフェーズに InfoSec を含め、セキュリティ関連の弱点を早期に見つけられるようにします。これによってチームは、その弱点を修正するため十分な時間を費やせるようになります。
事前に承認されたコードをビルドする。InfoSec チームが事前承認済みの使いやすいライブラリ、パッケージ、ツールチェーン、プロセスを構築し、開発者や IT オペレータが作業で使えるようにします。
早期から InfoSec を頻繁に関与アプリケーション開発の計画の段階、および以後のすべてのフェーズに InfoSec を含め、セキュリティ関連の弱点を早期に見つけられるようにします。これによってチームは、その弱点を修正するため十分な時間を費やせるようになります。
以前に言及したように、高品質のドキュメントによってさまざまな側面において好影響が生まれます。セキュリティも例外ではありません。 高品質のドキュメントを持つチームは、開発プロセス全体にセキュリティを統合している割合が 3.8 倍でした。 組織のすべての人々が暗号の専門技術を持っているわけではありません。 そうした専門技術は、文書化されたセキュリティ プラクティスという形により、組織内で最も効果的に共有されます。
技術面の DevOps 機能
調査から、継続的デリバリーを採用して DevOps 変換を遂行した組織は、高品質、低リスクで、費用対効果の大きいプロセスを保有している割合が高いことが示されました。
具体的には、次の技術的なプラクティスを測定しました。
- 疎結合アーキテクチャ
- トランクベース開発
- 継続的なテスト
- 継続的インテグレーション
- オープンソース テクノロジーの使用
- モニタリングとオブザーバビリティのプラクティス
- データベースの変更管理
- デプロイの自動化
これらのプラクティスはすべて継続的デリバリーの改善に効果がありますが、疎結合アーキテクチャと継続的なテストが最も大きな影響を持つことが判明しました。 たとえば、エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、低パフォーマンスのグループよりも、疎結合アーキテクチャを採用している割合が 3 倍も高くなっています。
疎結合アーキテクチャ
この調査ではさらに、サービスとチームとの間で粒度の細かい依存関係を減らすよう作業することで、IT パフォーマンスを改善できることを示します。 実際のところ、これは継続的デリバリーの成功を予測するうえで最も強い要素の 1 つです。 疎結合アーキテクチャを使用することで、チームはスケーリング、失敗、テスト、デプロイを互いに独立して行うことができます。 チームはそれぞれ独自のペースで手順を進められ、より小さなバッチで作業を行え、技術的な負債が少なくなり、障害から迅速に回復できるようになります。
継続的テストと継続的インテグレーション
以前の年の調査で判明したことと同様に、継続的テストが継続的デリバリーの成功を予測する強い要因であることが示されました。 エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、継続的テストを活用している割合が 3.7 倍です。 デリバリー プロセス全体を通して早期かつ頻繁なテストを取り入れ、常にテスト担当者と開発者がともに作業を行うようにすることで、チームはプロダクト、サービス、アプリケーションへの反復処理や変更を迅速に行えるようになります。 このフィードバック ループを使用して、顧客に価値を提供するとともに、自動テストや継続的インテグレーションなどのプラクティスを簡単に組み入れられるようになります。
継続的インテグレーションにより、継続的デリバリーも改善されます。 エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、継続的インテグレーションを活用している割合が 5.8 倍です。 継続的インテグレーションでは、commit のたびにソフトウェアのビルドがトリガーされ、一連の自動テストが行われて、数分以内にフィードバックが得られます。 継続的インテグレーションによって、正しく統合を行うために必要な手動の、そして複雑になることが多い調整を減らすことができます。
継続的インテグレーションは Kent Beck とエクストリーム プログラミング コミュニティで生まれたもので、その定義によれば、次に説明するトランクベースの開発のプラクティスが含まれます。7
トランクベース開発
調査では、パフォーマンスの高い組織は、トランクベース開発、すなわち開発者が小さなバッチで作業を行い、各自の作業を定期的に共有トランクに結合する方式が使用されている割合が高いことが、一貫して示されています。実際に、エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、トランクベース開発を使用している割合が 2.3 倍です。 パフォーマンスの低いグループは、ブランチを長く使用し、結合が遅れる傾向があります。
チームは、作業を最低でも 1 日に 1 回、できれば 1 日に何回も結合するべきです。トランクベース開発は継続的インテグレーションと密接に関連しているため、これら 2 つの技術的プラクティスを同時に取り入れることが望まれます。一緒に使用されることで、最大の影響を生み出すことができます。
デプロイの自動化
理想的な作業環境では、パソコンが反復作業を行い、人間は問題の解決に集中します。 デプロイ自動化の導入により、チームはその目標に近づくことができます。
ソフトウェアをテストから本番環境へ自動的に移行できれば、より高速で効率的なデプロイが可能となり、リードタイムを短縮できます。 また、デプロイでエラーが発生する可能性も、手動でのデプロイに比べて減らすことができます。 チームでデプロイの自動化を使用すると、フィードバックが直ちに得られ、サービスやプロダクトをはるかに迅速に改善できるようになります。 継続的なテスト、継続的インテグレーション、自動デプロイを同時に導入する必要はありませんが、これら 3 つのプラクティスを一緒に使用すれば、より大きな改善を期待できます。
データベースのチェンジ マネジメント
バージョン管理による変更のトラッキングは、コードの作成と保守、データベース管理の重要な部分です。 調査では、エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、パフォーマンスの低いグループと比べて、データベースのチェンジ マネジメントを実施している割合が 3.4 倍です。 さらに、データベースのチェンジ マネジメントを正しく行うには、関係するすべてのチーム間での共同作業、連絡、透明性が鍵となります。 導入する実際の手法はいくつか選択できますが、データベースに変更を加える必要があるときは必ず、データベースを更新する前にチームが集合して変更内容をレビューすることをおすすめします。
____________________________
8. Beck, K.(2000 年). 「Extreme programming explained: Embrace change」(英語)、Addison-Wesley Professional
____________________________
モニタリングとオブザーバビリティ
これまでの年と同様に、モニタリングとオブザーバビリティのプラクティスが継続的デリバリーの維持に役立っていることが判明しました。 エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、システム全体の健全性にオブザーバビリティを組み入れたソリューションを保有している割合が 4.1 倍です。 オブザーバビリティのプラクティスにより、チームはシステムをより的確に理解でき、問題点の識別とトラブルシューティングに必要な時間が短縮されます。 また調査では、優れたオブザーバビリティのプラクティスを持つチームは、コーディングにより多くの時間を費やしていることも示されています。 この発見について可能な説明の 1 つは、オブザーバビリティのプラクティスを導入することで、開発者が問題の原因を調べるのに必要な時間が減少し、その時間をトラブルシューティングに、最終的にはコーディングに振り分けられるようになったということです。
オープンソース テクノロジー
多くの開発者はすでにオープンソース テクノロジーを活用しており、それらのツールを使い慣れていることが組織にとって長所となります。 クローズド ソース テクノロジーの主な欠点は、組織と外部との間で知識の移転が制限されることです。 たとえば、自組織のツールをすでに使い慣れている人材を雇用することはできず、開発者は獲得した知識を他の組織に移転できません。 これに対して、ほとんどのオープンソース テクノロジーは、それを取り巻くコミュニティが存在し、開発者はそれらをサポートとして利用できます。 オープンソース テクノロジーはより広範にアクセス可能で、比較的コストが低く、カスタマイズ可能です。エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、オープンソース テクノロジーを利用している割合が 2.4 倍です。 DevOps 変革を導入するときは、オープンソース ソフトウェアの使用を増やすことをおすすめします。
技術的な DevOps 能力の詳細については、https://cloud.google.com/devops/capabilities で DORA 能力についてご覧ください
COVID-19 と文化
COVID-19
今年は、COVID-19(新型コロナウイルス感染症)パンデミックの禍中におけるチームのパフォーマンスに影響した要因を調査しました。 具体的には、COVID-19 のパンデミックはソフトウェア デリバリーと運用(SDO)のパフォーマンスに悪影響を及ぼしたのか? その結果、チームで燃え尽き症候群が増えたのか? 最後に、燃え尽き症候群を減らすにはどのような要素が有望か?という内容です。
まず、パンデミックがデリバリーと運用のパフォーマンスに与えた影響を把握するための調査を行いました。 多くの組織では、市場の劇的な変化(たとえば、対面での購入からオンラインへの移行)に対応するためのモダナイゼーションを優先させました。 「比較方法」の章では、ソフトウェア業界でのパフォーマンスが大幅に加速し、さらに加速し続けていることについて解説しています。 現在では、調査対象のサンプルの大多数がパフォーマンスの高いチームで、エリートのパフォーマンスのグループは引き続き水準を押し上げ、より短いリードタイムで頻繁にデプロイを行い、復旧時間が短く、変更時の障害率は低下しています。同様に、GitHub の調査員による調査でも、2020 年を通してデベロッパーのアクティビティ(すなわち、push、pull リクエスト、レビューされた pull リクエスト、およびユーザーごとのコメントされた問題数9)の増加が示されています。おそらく業界はパンデミックの結果というよりも、パンデミックにもかかわらず加速し続けていると考えられます。この未曾有な期間において SDO パフォーマンスの低下傾向がみられなかったのは特筆すべきでしょう。
パンデミックにより人々の勤務形態が変化し、多くの人々にとっては勤務場所も変化しました。 このため、パンデミックの結果であるリモート勤務の影響を調べました。 調査の結果、回答者の 89% はパンデミックのため在宅勤務していることが判明しました。パンデミックの前から在宅勤務の経験があると回答したのは、20% にすぎませんでした。 リモート作業環境への移行は、ソフトウェアの開発、ビジネスの運用、共同作業の方法に明確な影響を及ぼしました。 多くの人にとって、在宅勤務により廊下で偶然会って会話したり、対面で共同作業したりといったつながりを持つことができなくなりました。
____________________________
9. https://octoverse.github.com/
____________________________
燃え尽き症候群を減らした要因
それにもかかわらず、リモート作業の結果としてチームに燃え尽き症候群が生じたかどうかを大きく左右する要因が見つかりました。それは文化です。 生成チーム文化を持ち、自分がチームに受け入れられており、チームに属していると感じる人々で構成されたチームは、パンデミックの最中に燃え尽き症候群を経験する割合が半分でした。この発見は、チームと文化の優先順位付けの重要性の裏付けとなりました。 良い業績を挙げているチームは、チーム全体と個人の両方にプレッシャーをもたらす困難な期間を乗り切る手段を持ち合わせています。
文化
一般的な話として、文化はあらゆる組織において避けられない、対人関係の底にある流れです。 従業員が組織に対して、および互いについてどのように考え、感じ、行動するかに影響を及ぼす何かです。 どの組織にも独自の文化があり、調査の発見事項から、組織と IT のパフォーマンスを推進する最も重要な要素の 1 つが文化であることが一貫して示されています。 具体的には、分析から生成文化は、これは Westrum の組織文化の類型論と、人々がその組織に属し、含まれているという感覚によって測定されるものですが、より高いソフトウェア デリバリーと運用(SDO)パフォーマンスを期待できることが示されています。たとえば、エリートのパフォーマンスで、自らの信頼性の目標を満たしたグループは、パフォーマンスの低いグループと比べて、生成チーム文化を持っている割合が 2.9 倍であることが判明しました。 同様に、生成文化では組織的なパフォーマンスが高く、従業員の燃え尽き症候群の割合は低いことが予測されます。 つまり、文化は非常に重要です。 さいわい文化は流動的で、多くの面を持ち、常に変化し続けているため、変えていくことが可能です。
DevOps を正しく運用するには、組織のチームが共同で、他部門と連携して作業を行う必要があります。 Google は 2018 年に、パフォーマンスの高いチームは単一の、他部門と連携するチームでソフトウェアを開発してデリバリーする割合が 2 倍だということを発見しました。これは、あらゆる組織の成功には共同作業と協力が最も重要だということを補強するものです。 重要な質問があります。他部門と連携する共同作業を奨励し、褒賞する環境を作り上げるには、どのような要素が関係するのでしょうか?
Google は何年にもわたり、文化のなりたちを明白にし、文化が組織と IT のパフォーマンスに及ぼす影響を DevOps コミュニティが的確に理解できるようにするべく務めてきました。 最初の段階として、Westrum の組織文化の類型論を使用して、文化を運用的に定義しました。 同氏は組織について、パワー指向、ルール指向、パフォーマンス指向の 3 つの類型を識別しました。 Google はこのフレームワークを調査に使用し、パフォーマンス指向で、情報の流れ、信頼、イノベーション、リスク共有を最適化する組織文化が、高い SDO パフォーマンスを期待できることを発見しました。
文化と DevOps に関する理解が進化するにつれ、Google は文化の最初の定義を拡大し、心理的な安全性など他の心理社会的な要素も含める作業を行いました。パフォーマンスの高い組織は、従業員が悪い結果を恐れることなく、計算された妥当なリスクを冒すことを奨励する文化を持っている可能性が高いものです。
帰属と受け入れ
文化が常に大きな影響をパフォーマンスに及ぼすことを前提として、今年はモデルを拡大し、従業員が組織に属しており、受け入れられているという認識が、文化からパフォーマンスへの有益な影響を生み出すかどうかを調査しました。
心理的な調査から、人々は他者との強く安定した関係を形成し、維持するよう生得的に動機付けされていることが示されました。10 人々は、他者とつながっており、自分が所属しているさまざまなグループに受け入れられていることを感じたいと動機付けられています。帰属の感覚は、広範な好ましい身体的および心理的な結果をもたらします。 たとえば、帰属の感覚は動機付けに良い影響を与え、学業成績の向上に結び付くことが研究で示されています。11
このつながっているという感覚の根底には、人々が無理なく自分らしさをもって仕事するべきであり、各人の経験や背景が評価され、尊重されていると感じるべきだという考えがあります。12 組織内にインクルーシブで帰属意識がある文化を作り上げることに集中すると、繁栄し、多様性があり、動機付けされた労働力を生み出すために役立ちます。
調査の結果では、パフォーマンス指向で、帰属とインクルーシブネスを重視する組織は、肯定的でない組織文化を持つ組織と比べて、従業員の燃え尽き症候群のレベルが低い可能性が高いことが示されています。
心理社会的な要素が SDO パフォーマンスと、従業員の間での燃え尽き症候群のレベルに影響を及ぼすという証拠から、DevOps 改革を成功させるには、改革作業の一部として、文化に関連する問題点の対処に力を注ぐことをおすすめします。
____________________________
10. Baumeister & Leary、1995 年。 「The need to belong: Desire for interpersonal attachments as a fundamental human motivation」(英語)、Psychological Bulletin、117(3)、497~529。https://doi.org/10.1037/0033-2909.117.3.497
11. Walton 他、2012. 「Mere belonging: the power of social connections」(英語)、 Journal of Personality and Social Psychology、102(3):513~32。https://doi.org/10.1037/a0025731
12. Mor Barak & Daya、2014年。「Managing diversity: Toward a globally inclusive workplace」(英語)、Sage. Shore、Cleveland、& Sanchez、2018年、「Inclusive workplaces: A review and model」(英語)、Human Resources Review。https://doi.org/10.1016/j.hrmr.2017.07.003
調査対象者
Accelerate State of DevOps 2021 では、7 年間の調査と、業界専門家からの 32,000 を超える調査回答者を基に、チームと組織が最も成功するようなソフトウェア開発と DevOps のプラクティスを示します。
今年は、全世界から各種の業界に属する 1,200 人の現役の専門家が、より高いパフォーマンスを促進する要素についての Google の理解を助けるため、自らの経験を共有してくれました。 全体として、さまざまなユーザー属性と企業特性にわたる回答者層は引き続き一貫性の高いものです。
これまでの年と同様に、それぞれの調査回答者について、ユーザー属性の情報を収集しました。 カテゴリには、性別グループ、障がいグループ、社会的地位の低いグループがあります。
ユーザー属性と企業特性
今年は、会社のサイズ、産業、地域など、企業特性間にわたって、これまでのレポートと一貫した構成比率が見られました。 ここでも、回答者の 60% 以上はエンジニアまたはマネージャーとして勤務しており、1/3 はテクノロジー業界に勤務しています。 金融サービス、小売、工業 / 製造業の会社からも回答を頂いています。
____________________________
13. https://www.washingtongroup-disability.com/question-sets/wg-short-set-on-functioning-wg-ss/
____________________________
人種や性別などの属性
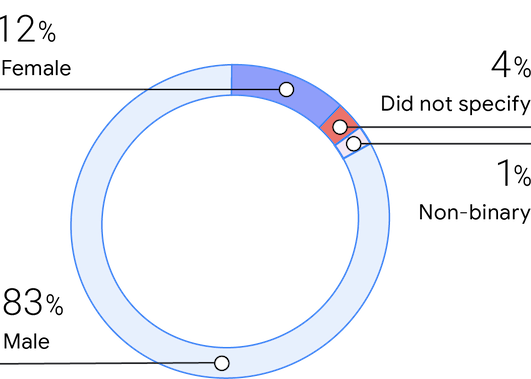
Gender
今年のサンプルは以前の調査と同様に、83% が男性、12% が女性、1% がノンバイナリーです。 回答者は、チームの約 25% が女性だと回答しました。これは、2019 年(16%)よりも大きく増えており、2018 年の数値(25%)と並ぶものです。
障がい
障がいについては、Washington Group Short Set13 の基準に従い、6 つの観点で識別しました。障がいについての質問を行うのは今年で 3 年目です。障がいを持つ人員の割合は、2019 年のレポートと変わらず 9% です。
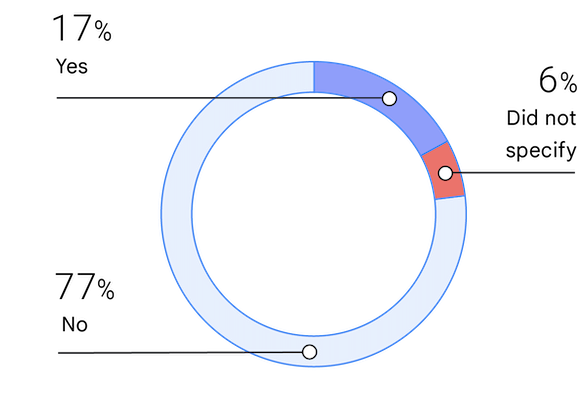
社会的地位の低いグループ
過小評価グループのメンバーであるという認識は、人種、性別、その他の特性に関連している場合があります。 社会的地位の低さについての質問を行うのは、今年で 4 年目です。 「社会的地位が低い」として識別される人員の割合は 2019 年の 13.7% から多少増えて、2021 年には 17% でした。
経験年数
今年の調査の回答者は高度な経験を持ち、41% は 16 年間以上の経験がありました。 回答者の 85% 以上は少なくとも 6 年間の経験がありました。
企業特性
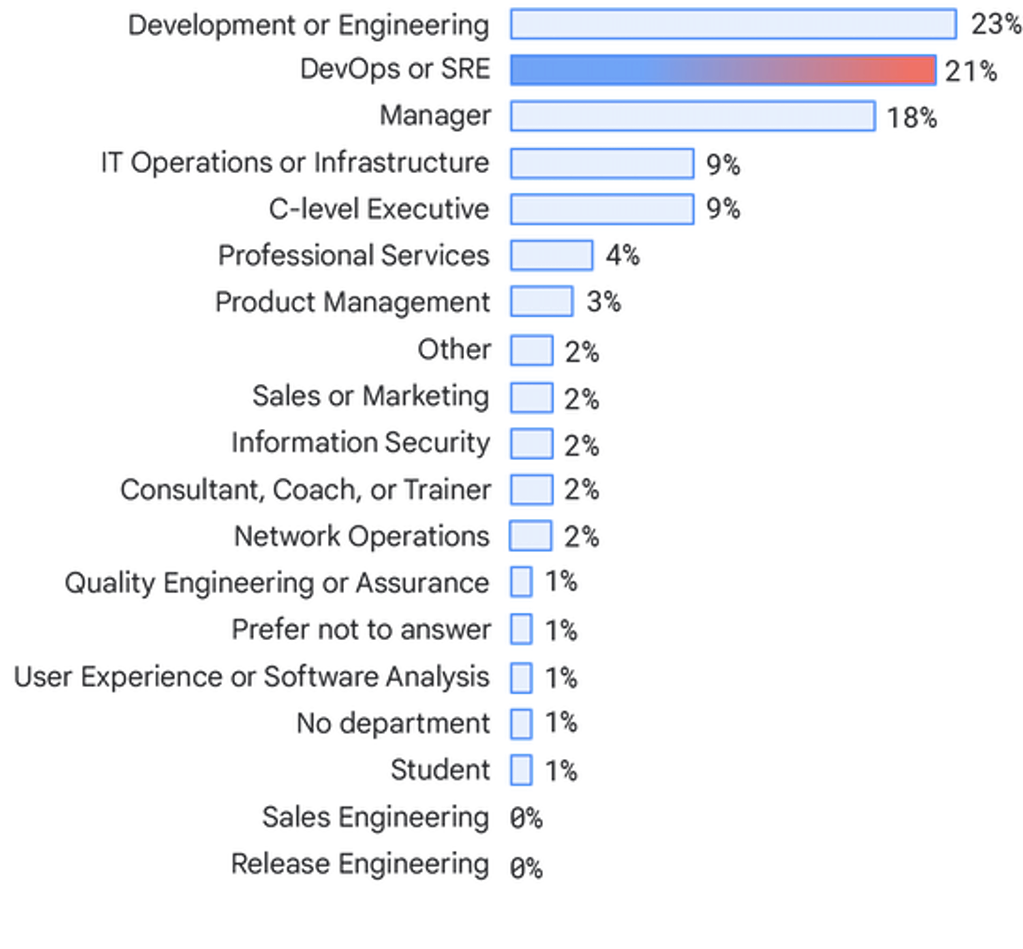
部門
回答者は主に、エンジニアリング チーム(23%)、DevOps と SRE チーム(21%)、マネージャー(18%)、および IT の運用とインフラストラクチャ チーム(9%)の業務に携わる個人です。 コンサルタントの割合が減少し(2019 年の 4% から 2% に)、最高経営幹部の割合が増えています(2019 年の 4% から 9% に)。
業種
以前の Accelerate State of DevOps レポートと同様に、テクノロジー業界に従事している回答者が最も多く、その後に金融サービス、小売などが続いています。
従業員
以前の Accelerate State of DevOps レポートと同様に、回答者の所属する組織の規模はさまざまです。 回答者の 22% は従業員数が 10,000 人を超える企業に勤務しており、7% は従業員数が 5,000~9,999 人の企業に勤務しています。 さらに 15% の回答者は、従業員数が 2,000~4,999 人の組織に属しています。 従業員数が 500~1,999 人の組織が 13%、100~499 人が 15%、最後に 20~99 人が 15% と、さまざまな規模の組織から幅広い回答を得ました。
チームの規模
回答者の半数以上(62%)はメンバーが 10 人以下のチームに属しています(6~10 人が 28%、2~5 人が 27%、1 人だけのチームが 6%)。 他の 19% は、メンバーが 11~20 人のチームに属しています。
地域
今年の調査では、北米の回答者の割合が減少しました(2019 年の 50% から 2021 年には 39% に)。 その代わりに、欧州(2019 年の 29% から 2021 年には 32% に)、アジア(2019 年の 9% から 2021 年には 13% に)、オセアニア(2019 年の 4% から 2021 年には 6% に)、南米(2019 年の 2% から 2021 年には 4% に)の回答者の割合が増加しました。
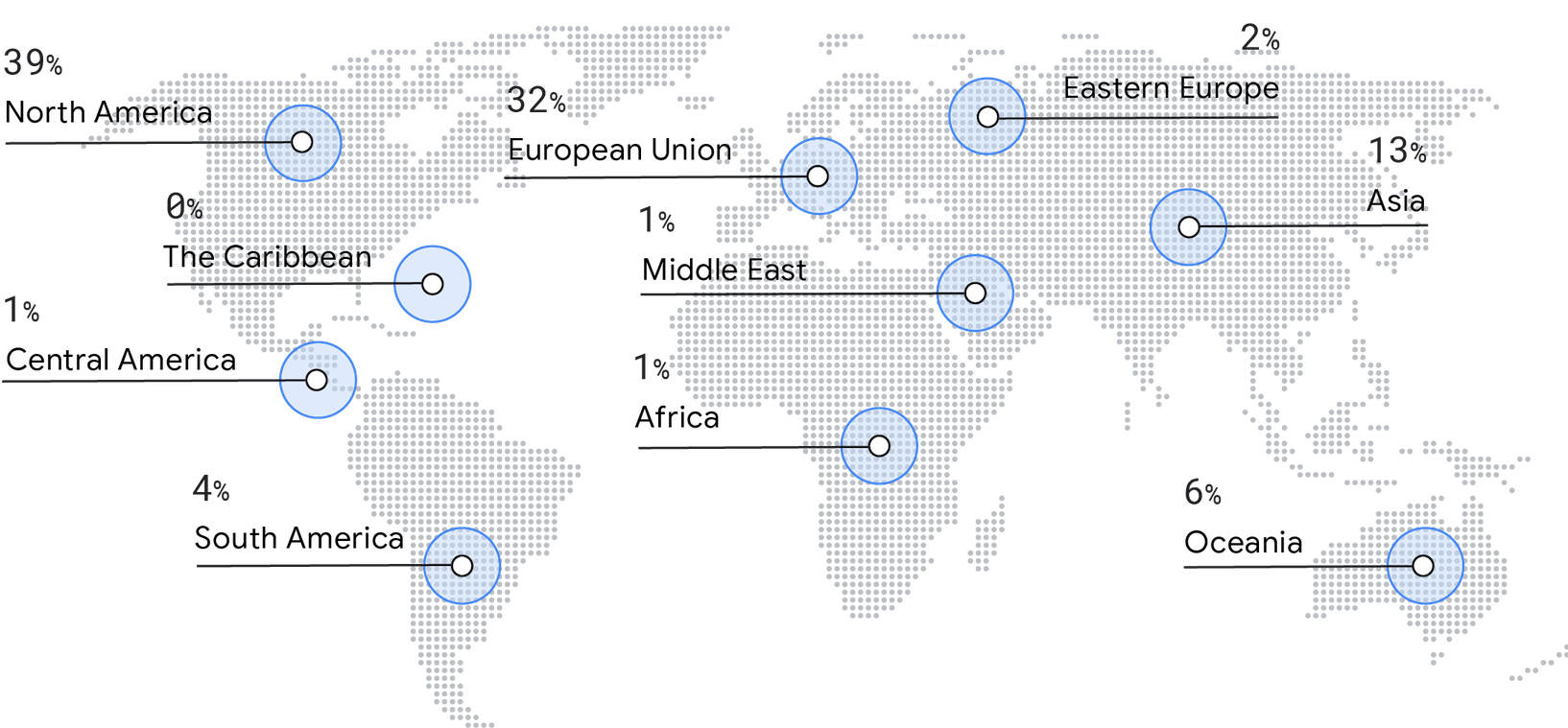
オペレーティング システム
オペレーティング システムの構成比も、以前の State of DevOps レポートと一貫しています。 Google のオペレーティング システムのリストを更新すべきであることを指摘してくださった回答者の皆様に感謝申し上げます。
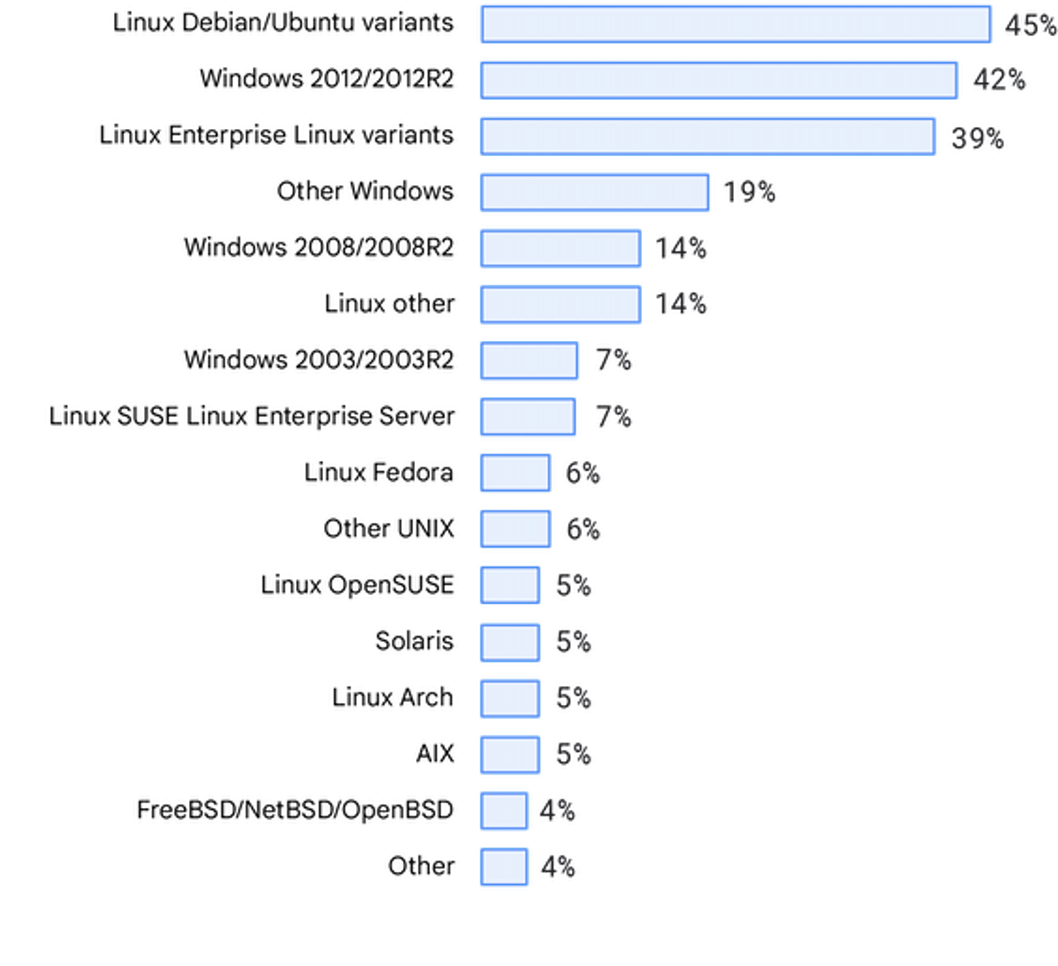
デプロイ ターゲット
今年は、回答者が取り扱う主なサービスやアプリケーションを、どこにデプロイしているかを調べました。 驚くべきことに、回答者の大部分はコンテナを使用しており(64%)、48% は仮想マシン(VM)を使用しています。 これは、業界でのより新しいデプロイ ターゲット技術への移行を反映している可能性があります。 企業の規模による相違を調べましたが、デプロイ ターゲット間で有意な差異は見られませんでした。
最後に
7 年間にわたる調査から、DevOps が組織にもたらす利益は依然として明白です。 組織は年々加速し、改善され続けています。
DevOps の原則と能力を取り入れたチームは、ソフトウェアを迅速に、高い信頼性で提供でき、同時にビジネスへと価値を直接推進できます。 今年は、SRE プラクティス、安全なソフトウェアのサプライ チェーン、高品質のドキュメントの影響を調査し、クラウドの活用の探求も再び調査しました。 それぞれの分野で、人員とチームはより効果を上げることが可能です。 ソリューションの構造に人員を適応させるのではなく、ソリューションの能力を利用する人員に適した構造を作り上げることの重要性に重点を置きました。
今年の調査に参加してくださったすべての方々に感謝申し上げるとともに、この調査が皆様とその組織において、より良いチームとより良いソフトウェアを構築し、同時にワークライフ バランスを維持するため役立つことを望んでおります。
謝辞
今年のレポートは、多数の貢献者の熱意により実現しました。 このレポートは、調査の質問設定、分析、著述、編集、レポートのデザインなどの作業の担当者なしには完成できませんでした。 著者一同、こうした協力者から今年のレポートのために頂いた協力とインプットに感謝します。 以下の名前はアルファベット順です。

著者
Dustin Smith
Dustin Smith はヒューマン ファクターズ心理学者で、Google のユーザー エクスペリエンス調査マネージャーを務めており、3 年間にわたって DORA プロジェクトに従事してきました。 過去 7 年間にわたって、人々が周囲のシステムや環境によってどのような影響を受けるかを、ソフトウェア エンジニアリング、無料プレイのゲーム、医療、軍事といったさまざまな分野で調査してきました。 Google における彼の調査から、ソフトウェア開発者が開発をより快適に行い、生産性を高められる分野が識別されました。 彼は 2 年間にわたって DORA プロジェクトに従事しました。 Dustin はウィチタ州立大学から、ヒューマン ファクターズ心理学で博士号を授与されています。
Daniella Villalba
Daniella Villalba は、DORA プロジェクト専任のユーザー エクスペリエンス調査員です。 開発者が快適に作業を行い、生産性を高めるための要素を理解するため注力しています。 彼女は Google に入社する前、瞑想トレーニングの利点、大学生の体験に影響を及ぼす心理社会的な要素、目撃記憶、虚偽の自白について研究してきました。 Daniella はフロリダ国際大学から、実験心理学で博士号を授与されています。
Michelle Irvine
Michelle Irvine は Google のテクニカル ライターで、デベロッパー ツールと、それを使用する人々との橋渡しをする作業を行っています。 Google に入社する前は教育系出版社で勤務経験があり、また、物理シミュレーション ソフトウェアのテクニカル ライター職に従事していました。 Michelle はウォータールー大学から物理学の理学士号と、レトリックおよびコミュニケーション設計の修士号を授与されています。
Dave Stanke
Dave Stanke は Google のデベロッパー リレーション エンジニアで、DevOps と SRE を採用するためのプラクティスについてお客様にアドバイスしています。 職歴を通して、スタートアップの CTO、プロダクト マネージャー、カスタマー サポート、ソフトウェア開発者、システム管理者、グラフィック デザイナーなど、あらゆる職務を経験してきました。 Dave はコロンビア大学からテクノロジー管理の修士号を授与されています。
Nathen Harvey
Nathen Harvey は Google のデベロッパー リレーション エンジニアで、チームがその可能性を実現し、同時にテクノロジーとビジネスの成果を同期できるよう支援する作業を行ってきました。 これまでに数々の優れたチームやオープンソース コミュニティとともに仕事をする機会を得て、DevOps と SRE の原則とプラクティスを適用するための支援を行いました。 Nathen は O’Reilly 2020 の「97 Things Every Cloud Engineer Should Know」(英語)を共同で編集し、寄稿しました。
手法
調査方法の設計
この調査では、セクション間にまたがる、理論に基づいた設計を採用しました。 理論に基づいた設計は推論予測と呼ばれ、今日行われるビジネスやテクノロジーの調査のうち、最も一般的なタイプの 1 つです。 純粋に実験的な設計が不可能で、現場での試験が好まれるときは、推論設計が使用されます。
対象層とサンプリング
この調査における対象層は、テクノロジーと変換の内部、またはその近くで作業を行っている実務担当者とリーダー、特に DevOps に馴染んでいる人々です。 調査はメーリング リスト、オンライン プロモーション、オンライン パネルでプロモートされ、対象の人々に対して、各自のネットワークでアンケートを共有するように求めました(雪だるま式サンプリングです)。
潜在的な構成の作成
可能な場合は、以前に検証済みの構成を使用して、仮説と構成を定式化しました。 新しい構成は理論、定義、専門家の意見に基づいて作成しました。 その後で、意図を明確にし、アンケートによって収集されるデータの妥当性と有効性が高くなるよう、追加手順を行いました。14
統計分析の方法
クラスタ分析。ソフトウェア デリバリー パフォーマンスのプロファイルを、デプロイの頻度、リードタイム、サービス復旧時間、変更時の障害率に基づいて識別するため、クラスタ分析を使用しました。潜在クラス分析15 を使用しました。これは、あらかじめクラスタの数を決定する業界的または理論的な理由がなく、クラスタの最適な数を決定するためにベイズ情報量基準16 を使用したためです。
測定モデル。分析を行う前に、探索的因子分析と、バリマックス回転を使用する主成分分析を使用して構成を識別しました。17 抽出された平均分散(AVE)、相関、クロンバックのアルファ 18 、複合信頼性を使用して、収束的妥当性および発散的妥当性と信頼性の統計テストを確認しました。
構造方程式のモデリング。構造方程式のモデリング(SEM)は部分的最小二乗(PLS)分析を使用してテストしました。これは、相関に基づく SEM です。19
________________________
14. Churchill Jr, G. A、「A paradigm for developing better measures of marketing constructs(英語)」Journal of Marketing Research 16:1、(1979 年)、64~73。
15. Hagenaars, J. A. および McCutcheon, A. L.(編集) (2002). 「Applied latent class analysis(英語)」、Cambridge University Press
16. Vrieze, S. I(2012). 「Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC)」(英語)、 Psychological methods、17(2)、228。
17. Straub, D.、Boudreau, M. C.、および Gefen, D、(2004). 「Validation guidelines for IS positivist research」(英語)、 Communications of the Association for Information systems、13(1)、24。
18. Nunnally, J.C.、「Psychometric Theory」(英語)、 ニューヨーク: McGraw-Hill、1978 年
19. Hair Jr、J. F, Hult、G. T. M.、Ringle、C. M.、および Sarstedt, M、(2021 年)。「A primer on partial least squares structural equation modeling (PLS-SEM)」(英語)、Sage publications
関連情報
DevOps 機能の詳細については、https://cloud.google.com/devops/capabilities をご覧ください
サイト信頼性エンジニアリング(SRE)のリソース:
DevOps のクイック チェック:
https://www.devops-research.com/quickcheck.html
DevOps 調査プログラムについて調べる:
https://www.devops-research.com/research.html
Google Cloud Application Modernization Program について調べる:
https://cloud.google.com/solutions/camp
ホワイトペーパー「DevOps 変革の ROI: モダナイゼーション イニシアチブの効果を数値化する方法」を読む:
https://cloud.google.com/resources/roi-of-devops-transformation-whitepaper
過去の State of DevOps レポート:
State of DevOps 2014(英語): https://services.google.com/fh/files/misc/state-of-devops-2014.pdf
State of DevOps 2015(英語): https://services.google.com/fh/files/misc/state-of-devops-2015.pdf
State of DevOps 2016(英語): https://services.google.com/fh/files/misc/state-of-devops-2016.pdf
State of DevOps 2017(英語): https://services.google.com/fh/files/misc/state-of-devops-2017.pdf
Accelerate State of DevOps 2018: https://services.google.com/fh/files/misc/state-of-devops-2018.pdf
Accelerate: 2019 年の State of DevOps
https://services.google.com/fh/files/misc/state-of-devops-2019.pdf


















