Como migrar para uma arquitetura nativa da nuvem
De acordo com a pesquisa do DevOps Research and Assessment (DORA, na sigla em inglês), as equipes de elite do DevOps fazem implantações diversas vezes ao dia, liberam mudanças na produção em menos de um dia e têm taxas de erros entre 0 e 15%.
Neste documento, mostraremos como reestruturar a arquitetura dos seus aplicativos para um paradigma nativo da nuvem que permita acelerar a entrega de novos recursos, mesmo quando suas equipes crescerem, além de melhorar a qualidade dos softwares e atingir níveis maiores de estabilidade e disponibilidade.
Por que mudar para uma arquitetura nativa da nuvem?
Muitas empresas criam serviços de software personalizados usando arquiteturas monolíticas. Essa abordagem tem vantagens: os sistemas monolíticos são relativamente simples de projetar e implantar. Pelo menos, no início. No entanto, pode se tornar difícil manter a produtividade do desenvolvedor e a velocidade da implantação à medida que os aplicativos ficam mais complexos, levando a sistemas que são caros e demorados para serem alterados e arriscados para serem implantados.
À medida que os serviços (e as equipes responsáveis por eles) crescem, tendem a ficar mais complexos e difíceis de evoluir e operar. A realização de testes e implantações se torna mais penosa, a inclusão de novos recursos fica mais difícil e a manutenção da confiabilidade e da disponibilidade pode ser complicada.
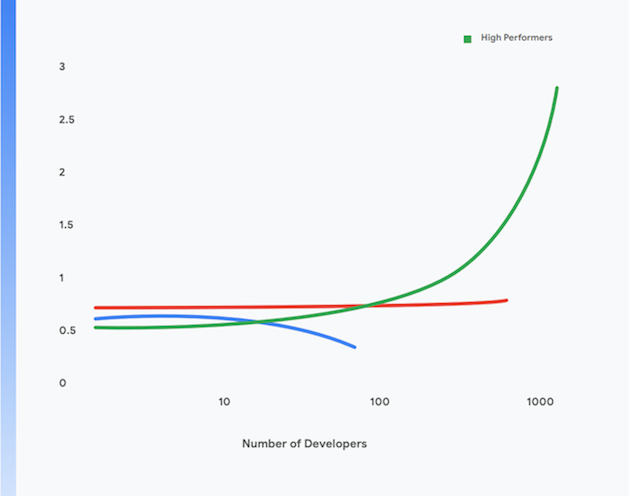
Uma pesquisa da equipe DORA do Google mostra que é possível alcançar altos níveis de capacidade de processamento para entrega de software e estabilidade e disponibilidade de serviços em organizações de todos os tamanhos e domínios. Equipes de alto desempenho são capazes de fazer implantações várias vezes por dia, modificar a produção em menos de um dia, restaurar o serviço em menos de uma hora e atingir uma taxa de falha de alteração de 0 a 15%.1
Além disso, as equipes com melhor desempenho são capazes de atingir níveis maiores de produtividade do desenvolvedor, medidos em termos de implantações por desenvolvedor por dia, mesmo quando elas aumentam de tamanho. Isso é mostrado na figura 1.
No restante desta página, mostraremos como migrar seus aplicativos para um paradigma moderno nativo da nuvem com o objetivo de ajudar a atingir esses resultados. Após a implementação das práticas técnicas descritas neste documento, é possível atingir os seguintes objetivos:
- Aumento da produtividade do desenvolvedor, mesmo quando você aumenta o tamanho da sua equipe.
- Tempo de lançamento mais rápido: inclua novos recursos e corrija defeitos mais rapidamente.
- Maior disponibilidade: aumente o tempo de atividade do seu software, reduza a taxa de falhas de implantação e diminua o tempo de restauração em caso de incidentes.
- Segurança aprimorada: reduza a área de superfície de ataque de seus aplicativos e facilite a detecção e resposta rápidas a vulnerabilidades recém-descobertas e ataques.
- Melhor escalonabilidade: as plataformas e os aplicativos nativos da nuvem facilitam o escalonamento horizontal e o vertical quando necessário.
- Redução de custos: um processo simplificado de entrega de software reduz os custos de entrega de novos recursos, e o uso eficaz de plataformas em nuvem reduz substancialmente os custos operacionais de seus serviços.
1 Descubra o desempenho de sua equipe com base nessas quatro métricas principais em https://cloud.google.com/devops/
O que é uma arquitetura nativa da nuvem?
Os aplicativos monolíticos precisam ser criados, testados e implantados como uma única unidade. Com frequência, o sistema operacional, o middleware e a pilha de linguagens do aplicativo são personalizados ou configurados de maneira única para cada aplicativo. Os processos e scripts de criação, teste e implantação também são exclusivos de cada aplicativo. Isso é simples e eficaz para aplicativos novos, mas, à medida que eles crescem, fica mais difícil alterar, testar, implantar e operar esses sistemas.
Além disso, conforme os sistemas crescem, também aumentam o tamanho e a complexidade das equipes que criam, testam, implantam e operam o serviço. Uma abordagem comum, mas falha, é dividir as equipes por função, levando a reatribuições de tarefas entre as equipes, que tendem a aumentar os tempos de lead e os tamanhos dos lotes e levar a uma quantidade significativa de retrabalho. Na pesquisa da DORA, podemos ver que equipes de alto desempenho têm duas vezes mais chances de desenvolver e entregar softwares em uma única equipe multifuncional.
Veja quais são os sintomas desse problema:
- Processos de compilação longos e frequentemente interrompidos
- Ciclos de teste e integração não frequentes
- Maior esforço necessário para apoiar os processos de compilação e teste
- Perda de produtividade dos desenvolvedores
- Processos de implantação complicados que precisam ser realizados fora do horário, exigindo inatividades programadas
- Esforço significativo no gerenciamento da configuração dos ambientes de teste e produção
No paradigma nativo da nuvem, em contraste³:
- Sistemas complexos são decompostos em serviços que podem ser testados de maneira independente e implantados em um ambiente de execução em contêiner (uma arquitetura orientada a serviços ou microsserviços)
- Os aplicativos usam serviços fornecidos pela plataforma padrão, como sistemas de gerenciamento de banco de dados (DBMS, na sigla em inglês), armazenamento de blob, mensagens, CDN e terminação SSL
- Uma plataforma de nuvem padronizada lida com muitas questões operacionais, como implantação, escalonamento automático, configuração, gerenciamento de secrets, monitoramento e alerta. Esses serviços podem ser acessados sob demanda por equipes de desenvolvimento de aplicativos
- Pilhas de linguagens específicas, middlewares e sistemas operacionais padronizados são fornecidos aos desenvolvedores de aplicativos, e a manutenção e correção dessas pilhas são feitas fora da banda pelo provedor da plataforma ou por uma equipe separada
- Uma única equipe multifuncional pode ser responsável por todo o ciclo de vida de entrega de software de cada serviço
3 Esta não pretende ser uma descrição completa do que “nativo da nuvem” significa: para uma discussão sobre alguns dos princípios da arquitetura nativa da nuvem, acesse https://cloud.google.com/blog/products/application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it.
Esse paradigma oferece muitos benefícios:
Entrega mais rápida | Versões confiáveis | Custos mais baixos |
como os serviços agora são pequenos e acoplados com flexibilidade, as equipes associadas a eles podem trabalhar de maneira autônoma. Isso aumenta a produtividade do desenvolvedor e a velocidade do desenvolvimento. | os desenvolvedores podem criar, testar e implantar rapidamente serviços novos e atuais em ambientes de teste semelhantes à produção. A implantação na produção também é uma atividade simples e atômica. Isso acelera de modo substancial o processo de entrega de software e reduz o risco das implantações. | O custo e a complexidade dos ambientes de teste e produção são reduzidos de modo substancial porque serviços compartilhados e padronizados são fornecidos pela plataforma e porque os aplicativos são executados em uma infraestrutura física compartilhada. |
Mais segurança | Maior disponibilidade | Conformidade mais simples e barata |
os fornecedores agora são responsáveis por manter os serviços compartilhados (como DBMS e infraestrutura de mensagens) atualizados, com os patches aplicados e em conformidade. Também é muito mais fácil manter os aplicativos com patches e atualizados porque há uma maneira padrão de implantar e gerenciar aplicativos. | A disponibilidade e a confiabilidade dos aplicativos são aumentadas devido à complexidade reduzida do ambiente operacional, à facilidade de fazer alterações na configuração e à capacidade de lidar com o escalonamento automático e a recuperação automática no nível da plataforma. | A maioria dos controles de segurança da informação pode ser implementada na camada da plataforma, tornando-a significativamente mais barata e fácil de implementar e demonstrar conformidade. Muitos provedores de nuvem mantêm conformidade com frameworks de gerenciamento de risco, como SOC2 e FedRAMP, o que significa que os aplicativos implantados com base neles precisam apenas demonstrar conformidade com controles residuais não implementados na camada da plataforma. |
Entrega mais rápida
Versões confiáveis
Custos mais baixos
como os serviços agora são pequenos e acoplados com flexibilidade, as equipes associadas a eles podem trabalhar de maneira autônoma. Isso aumenta a produtividade do desenvolvedor e a velocidade do desenvolvimento.
os desenvolvedores podem criar, testar e implantar rapidamente serviços novos e atuais em ambientes de teste semelhantes à produção. A implantação na produção também é uma atividade simples e atômica. Isso acelera de modo substancial o processo de entrega de software e reduz o risco das implantações.
O custo e a complexidade dos ambientes de teste e produção são reduzidos de modo substancial porque serviços compartilhados e padronizados são fornecidos pela plataforma e porque os aplicativos são executados em uma infraestrutura física compartilhada.
Mais segurança
Maior disponibilidade
Conformidade mais simples e barata
os fornecedores agora são responsáveis por manter os serviços compartilhados (como DBMS e infraestrutura de mensagens) atualizados, com os patches aplicados e em conformidade. Também é muito mais fácil manter os aplicativos com patches e atualizados porque há uma maneira padrão de implantar e gerenciar aplicativos.
A disponibilidade e a confiabilidade dos aplicativos são aumentadas devido à complexidade reduzida do ambiente operacional, à facilidade de fazer alterações na configuração e à capacidade de lidar com o escalonamento automático e a recuperação automática no nível da plataforma.
A maioria dos controles de segurança da informação pode ser implementada na camada da plataforma, tornando-a significativamente mais barata e fácil de implementar e demonstrar conformidade. Muitos provedores de nuvem mantêm conformidade com frameworks de gerenciamento de risco, como SOC2 e FedRAMP, o que significa que os aplicativos implantados com base neles precisam apenas demonstrar conformidade com controles residuais não implementados na camada da plataforma.
No entanto, há algumas desvantagens associadas ao modelo nativo da nuvem:
- Todos os aplicativos agora são sistemas distribuídos, o que significa que eles fazem um número significativo de chamadas remotas como parte da operação. Isso significa pensar com cuidado sobre como lidar com falhas de rede e problemas de desempenho e como depurar problemas na produção.
- Os desenvolvedores precisam usar o sistema operacional padronizado, o middleware e as pilhas de aplicativos fornecidos pela plataforma. Isso deixa o desenvolvimento local mais difícil.
- Os arquitetos precisam adotar uma abordagem orientada a eventos para o projeto de sistemas, incluindo a adoção da consistência posterior.
Como migrar para a nuvem
Muitas organizações adotaram uma abordagem de migração “lift-and-shift” para mover os serviços para a nuvem. Nela, apenas pequenas alterações são necessárias nos sistemas, e a nuvem é basicamente tratada como um data center tradicional, mesmo que ofereça APIs, serviços e ferramentas de gestão substancialmente melhores em comparação aos data centers tradicionais. No entanto, a migração lift-and-shift por si só não oferece nenhum dos benefícios do paradigma nativo da nuvem descrito acima.
Muitas organizações param na migração lift-and-shift devido ao custo e à complexidade de mover os aplicativos para uma arquitetura nativa da nuvem, o que exige repensar tudo, desde a arquitetura dos aplicativos até as operações de produção e, na verdade, todo o ciclo de vida de entrega de software. Esse medo é racional: muitas organizações de grande porte perderam dinheiro por causa de esforços fracassados de reforma do tipo “big bang” com vários anos de duração.
A solução é adotar uma abordagem incremental, iterativa e evolutiva para reestruturar seus sistemas para deixá-los nativos da nuvem, permitindo que as equipes aprendam a trabalhar de maneira eficaz neste novo paradigma enquanto entrega novas funcionalidades: uma abordagem que chamamos de "migrar e melhorar".
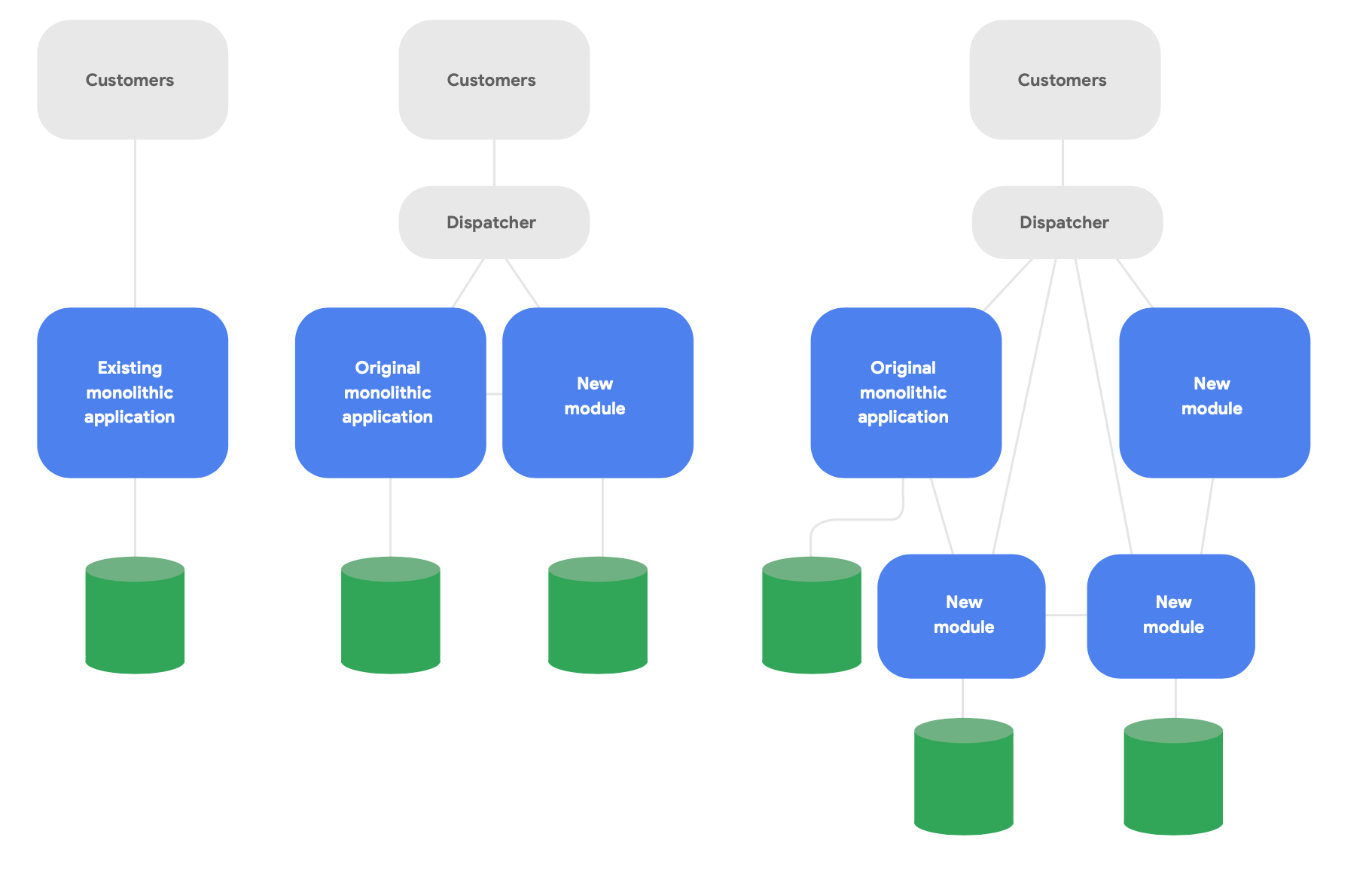
Um padrão importante na arquitetura evolucionária é conhecido como o aplicativo strangler fig.4 Em vez de reescrever completamente os sistemas do zero, escreva recursos novos em um estilo moderno nativo da nuvem, mas faça com que eles “conversem” com o aplicativo monolítico original para ter a funcionalidade atual. Mude gradualmente a funcionalidade atual ao longo do tempo conforme necessário para ter a integridade conceitual dos serviços novos, conforme mostrado na Figura 2.
4 Descrito em https://martinfowler.com/bliki/StranglerFigApplication.html
Veja aqui três diretrizes importantes para uma reestruturação bem-sucedida:
Primeiro, comece entregando novas funcionalidades rapidamente em vez de reproduzir a funcionalidade atual. A métrica principal é a rapidez com que é possível começar a entregar novas funcionalidades usando novos serviços, para que seja possível aprender e comunicar rapidamente as práticas recomendadas conquistadas ao trabalhar nesse paradigma. Corte o escopo de modo contundente com o objetivo de entregar algo para usuários reais em semanas, não em meses.
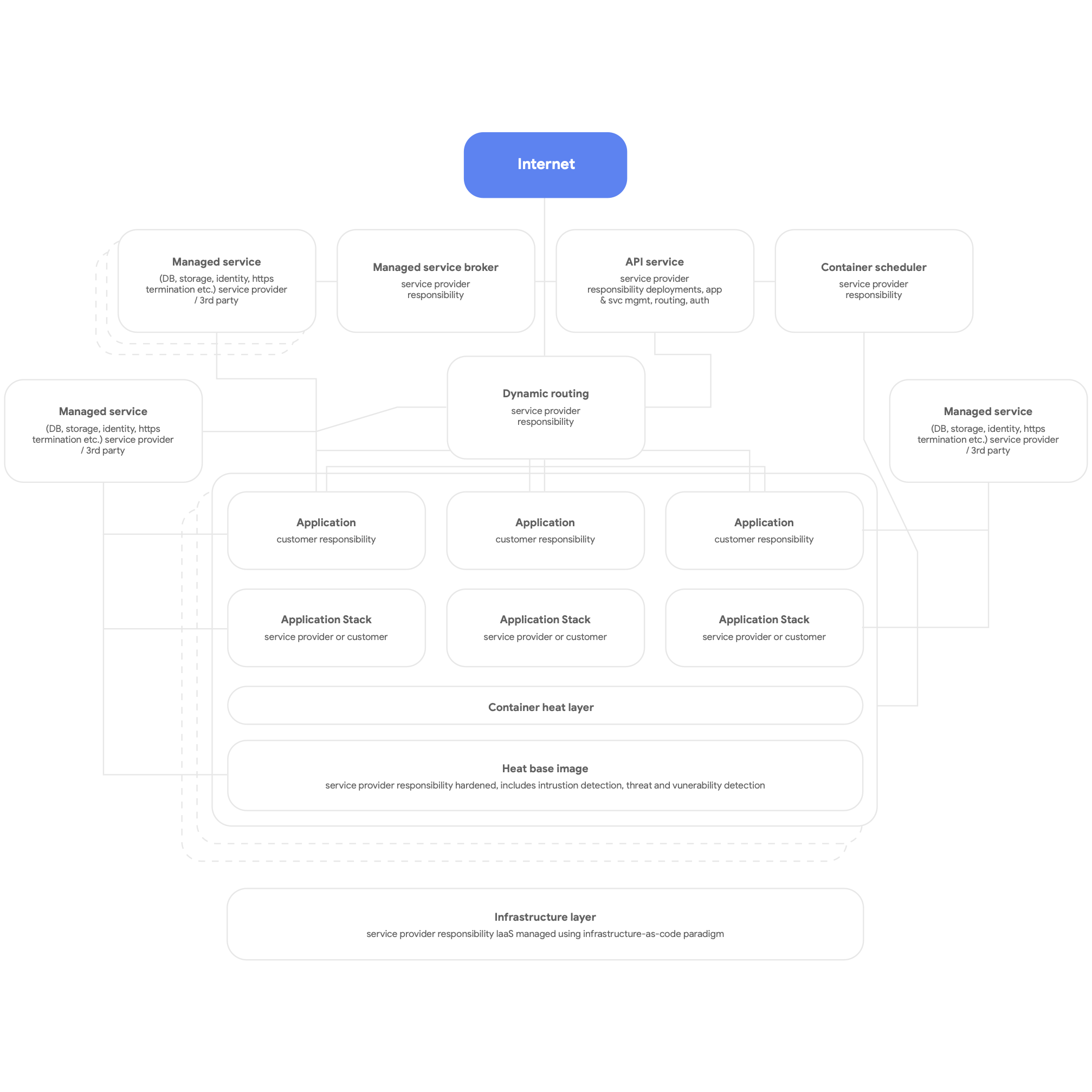
Em segundo lugar, projete para algo nativo da nuvem. Isso significa usar os serviços nativos da plataforma de nuvem para DBMS, mensagens, CDN, rede, armazenamento de blob e assim por diante e, sempre que possível, usar pilhas de aplicativos padronizadas e fornecidas pela plataforma. Os serviços precisam ser armazenados em contêineres, fazendo uso do paradigma sem servidor sempre que possível, e o processo de compilação, teste e implantação precisa ser totalmente automatizado. Faça com que todos os aplicativos usem serviços compartilhados e fornecidos pela plataforma para geração de registros, monitoramento e alerta. Esse tipo de arquitetura de plataforma pode ser implantado de maneira útil para qualquer plataforma de aplicativo multilocatário, incluindo um ambiente local bare-metal. Uma imagem geral de uma plataforma nativa da nuvem é mostrada na Figura 3, abaixo.
Por fim, projete para equipes autônomas e acopladas com flexibilidade que podem testar e implantar os próprios serviços. Nossa pesquisa mostra que os resultados arquitetônicos mais importantes vêm do fato de as equipes de entrega de software conseguirem responder “sim” a estas seis perguntas:
- Podemos fazer alterações em grande escala no projeto de nosso sistema sem a permissão de alguém de fora da equipe?
- Conseguimos fazer alterações em grande escala no projeto de nosso sistema sem depender de outras equipes para fazer alterações nos sistemas deles ou criar trabalho significativo para outras equipes?
- Podemos concluir nosso trabalho sem nos comunicar e coordenar com pessoas de fora da equipe?
- Conseguimos implantar e lançar nosso produto ou serviço sob demanda, independentemente de outros serviços dos quais ele depende?
- Podemos fazer a maioria dos nossos testes sob demanda sem exigir um ambiente de teste integrado?
- Conseguimos realizar implantações durante o horário comercial normal com inatividade insignificante?
Verifique regularmente se as equipes estão trabalhando para atingir essas metas e priorize o cumprimento delas. Isso geralmente envolve repensar a arquitetura organizacional e corporativa.
Em particular, é crucial organizar equipes para que todos os vários papéis necessários para compilar, testar e implantar softwares, incluindo gerentes de produto, trabalhem juntos e usem práticas modernas de gerenciamento de produtos para criar e desenvolver os serviços nos quais estão trabalhando. Isso não precisa envolver mudanças na estrutura organizacional. Conseguir que essas pessoas trabalhem juntas como uma equipe no dia a dia (compartilhando um espaço físico onde isso for possível) em vez de ter desenvolvedores, testadores e equipes de lançamento operando de maneira independente pode fazer uma grande diferença na produtividade.
Nossa pesquisa mostra que o grau em que as equipes concordaram com essas afirmações previu muito o alto desempenho do software: a capacidade de fornecer serviços confiáveis e altamente disponíveis várias vezes por dia. Isso, por sua vez, é o que permite que equipes de alto desempenho aumentem a produtividade dos desenvolvedores (medida em termos de número de implantações por desenvolvedor por dia), mesmo com o aumento do número de equipes.
Princípios e práticas
Princípios e práticas da arquitetura de microsserviços
Ao se adotar uma arquitetura orientada a serviços ou microsserviços, há alguns princípios e práticas importantes que precisam ser seguidos. É melhor ser muito rigoroso em relação a segui-los desde o início, pois é mais caro atualizá-los posteriormente.
- Cada serviço precisa ter o próprio esquema de banco de dados. Esteja você usando um banco de dados relacional ou uma solução NoSQL, cada serviço precisa ter o próprio esquema que nenhum outro serviço acesse. Quando vários serviços se comunicam com o mesmo esquema, com o tempo eles ficam com um acoplamento rígido na camada de banco de dados. Essas dependências evitam que os serviços sejam testados e implantados de maneira independente, deixando-os mais difíceis de serem alterados e mais arriscados de serem implantados.
- Os serviços precisam se comunicar apenas pelas APIs públicas na rede. Todos os serviços precisam expor o comportamento por APIs públicas e precisam se comunicar apenas usando essas APIs. Não pode haver nenhum acesso por uma “porta dos fundos” nem serviços se comunicando diretamente com bancos de dados de outros serviços. Isso evita que os serviços se tornem rigidamente acoplados e garante que a comunicação entre eles use APIs bem documentadas e compatíveis.
- Os serviços são responsáveis pela compatibilidade com versões anteriores dos clientes. A equipe de compilação e operação de um serviço é responsável por garantir que as atualizações dele não prejudiquem os consumidores. Isso significa planejar o controle de versões da API e testar a compatibilidade com versões anteriores, de modo que, ao lançar versões novas, você não prejudique os clientes atuais. As equipes podem validar isso usando a versão canário. Isso também significa garantir que as implantações não introduzam inatividade, usando técnicas como implantações azul/verde ou lançamentos graduais.
- Crie uma maneira padrão de executar serviços em estações de trabalho de desenvolvimento. Os desenvolvedores precisam conseguir manter qualquer subconjunto de serviços de produção em estações de trabalho de desenvolvimento sob demanda com o uso de um único comando. Também é preciso que seja possível executar versões stub de serviços sob demanda. Use versões emuladas de serviços em nuvem que muitos provedores de nuvem oferecem para ajudar você. A meta é facilitar o teste e a depuração locais de serviços por parte dos desenvolvedores.
- Invista em monitoramento e observabilidade da produção. Muitos problemas na produção, incluindo problemas de desempenho, são emergentes e causados por interações entre vários serviços. Nossa pesquisa mostra que é importante ter uma solução que informe sobre a integridade geral dos sistemas (por exemplo, meus sistemas estão funcionando? Meus sistemas têm recursos suficientes disponíveis?) e que as equipes têm acesso a ferramentas e dados que ajudam a rastrear, entender e diagnosticar problemas de infraestrutura em ambientes de produção, incluindo interações entre serviços.
- Defina objetivos de nível de serviço (SLOs) para seus serviços e realize testes de recuperação de desastres regularmente. A configuração de SLOs para seus serviços define as expectativas sobre como será o desempenho e ajuda a planejar como seu sistema precisa se comportar se um serviço ficar inativo (uma consideração importante ao criar sistemas distribuídos resilientes). Teste como seu sistema de produção se comporta em ação usando técnicas como injeção de falha controlada como parte de seu plano de teste de recuperação de desastres. A pesquisa da DORA mostra que as organizações que realizam testes de recuperação de desastres usando métodos como este estão mais propensas a ter níveis maiores de disponibilidade de serviço. Quanto mais cedo você começar com isso, melhor será possível normalizar esse tipo de atividade vital.
Isso é muito para se pensar, por isso é importante fazer um teste piloto desse tipo de trabalho com uma equipe que tenha a capacidade e os recursos para testar a implementação dessas ideias. Haverá sucessos e fracassos. É importante tirar lições dessas equipes e aproveitá-las à medida que você espalha o paradigma arquitetônico novo pela organização.
Nossa pesquisa mostra que as empresas bem-sucedidas usam provas de conceito e oferecem oportunidades para as equipes compartilharem aprendizados, por exemplo, criando comunidades de prática. Forneça tempo, espaço e recursos para que pessoas de várias equipes se reúnam regularmente e troquem ideias. Todos também precisarão aprender novas habilidades e tecnologias. Invista no crescimento de sua equipe, proporcionando a ela orçamento para comprar livros, fazer treinamentos e participar de conferências. Ofereça infraestrutura e tempo para que as pessoas espalhem o conhecimento institucional e as práticas recomendadas por bases de conhecimento, encontros presenciais e listas de e-mails da empresa.
Arquitetura de referência
Nesta seção, descreveremos uma arquitetura de referência com base nas diretrizes a seguir:
- Usar contêineres para serviços de produção e um programador de contêineres, como o Cloud Run ou o Kubernetes, para orquestração
- Criar pipelines de CI/CD eficazes
- Concentrar-se na segurança
Conteinerizar serviços de produção
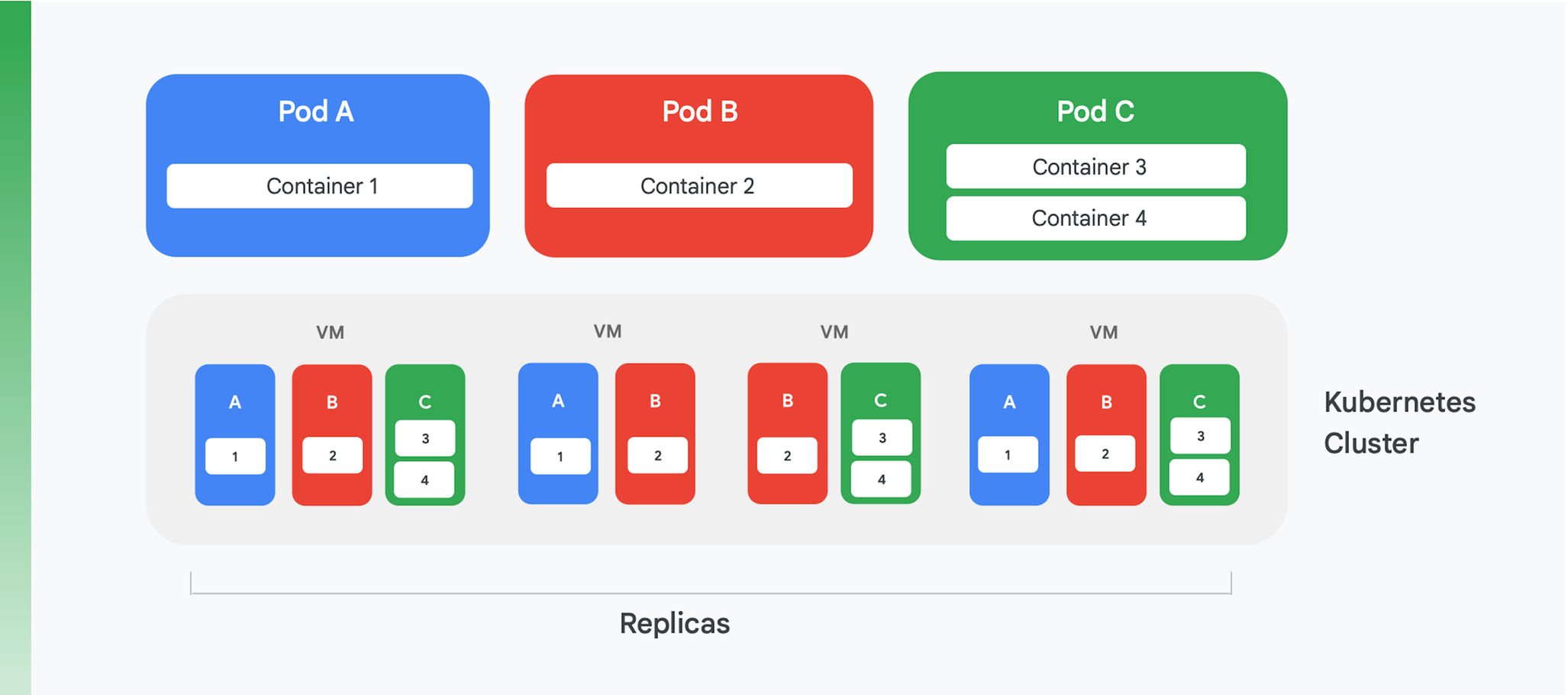
A base de um aplicativo em nuvem conteinerizado é um serviço de orquestração e gerenciamento de contêineres. Muitos serviços diferentes já foram criados, mas um é claramente dominante hoje: Kubernetes. O Kubernetes agora define o padrão para a orquestração de contêineres no setor, hospedando uma comunidade animada e reunindo suporte de muitos fornecedores comerciais líderes. Na Figura 4, resumimos a estrutura lógica de um cluster do Kubernetes.
O Kubernetes define uma abstração chamada pod. Cada pod geralmente inclui apenas um contêiner, como os pods A e B da Figura 4, embora um pod possa conter mais de um, como no caso C. Cada serviço do Kubernetes executa um cluster que contém algum número de nós, e cada um deles normalmente é uma máquina virtual (VM). Na Figura 4, mostramos apenas quatro VMs, mas um cluster real pode facilmente conter mais de cem. Quando um pod é implantado em um cluster do Kubernetes, o serviço determina em quais VMs os contêineres do pod precisam ser executados. Como os contêineres especificam os recursos de que precisam, o Kubernetes pode fazer escolhas inteligentes sobre quais pods são atribuídos a cada VM.
Parte das informações de implantação de um pod é uma indicação de quantas instâncias (réplicas) do pod serão executadas. O serviço do Kubernetes, então, cria essas muitas instâncias dos contêineres do pod e as atribui às VMs. Na Figura 4, por exemplo, a implantação do pod A solicitou três réplicas, assim como a do pod C. A implantação do pod B, no entanto, solicitou quatro réplicas e, portanto, esse exemplo de cluster contém quatro instâncias em execução do contêiner 2. E, como a figura sugere, um pod com mais de um contêiner, como o C, sempre terá os contêineres atribuídos ao mesmo nó.
O Kubernetes também oferece outros serviços, entre eles os seguintes:
- Monitoramento dos pods em execução para que, se um contêiner falhar, o serviço inicie uma instância nova. Isso garante que todas as réplicas solicitadas na implantação de um pod permaneçam disponíveis.
- Tráfego de balanceamento de carga, espalhando solicitações feitas a cada pod de maneira inteligente nas réplicas de um contêiner.
- Lançamento automatizado de novos contêineres com inatividade zero, com instâncias novas substituindo gradualmente as atuais até que uma versão nova seja totalmente implantada.
- Escalonamento automatizado, com um cluster adicionando ou excluindo VMs de maneira autônoma com base na demanda.
Criar pipelines de CI/CD eficazes
Alguns dos benefícios da refatoração de um aplicativo monolítico, como custos menores, saem diretamente da execução no Kubernetes. No entanto, um dos benefícios mais importantes (a capacidade de atualizar seu aplicativo com mais frequência) só é possível se você mudar a forma como compila e lança softwares. Conseguir esse benefício exige que você crie pipelines de CI/CD eficazes em sua organização.
A integração contínua depende de fluxos de trabalho de teste e build automatizados que forneçam feedback rápido aos desenvolvedores. Isso exige que cada participante de uma equipe que trabalha no mesmo código (por exemplo, o código de um único serviço) integre regularmente o trabalho que está fazendo em uma linha principal ou um tronco compartilhado. Essa integração precisa acontecer pelo menos diariamente por desenvolvedor, com cada integração verificada por um processo de compilação que inclui testes automatizados. A entrega contínua tem por objetivo deixar a implantação desse código integrado rápida e com risco baixo, em grande parte automatizando o processo de compilação, teste e implantação para que atividades como desempenho, segurança e testes exploratórios possam ser realizados de maneira contínua. Simplificando, a integração contínua (CI) ajuda os desenvolvedores a detectar problemas de integração rapidamente, enquanto a entrega contínua (CD) torna a implantação confiável e rotineira.
Para deixar isso mais claro, é útil olhar para um exemplo concreto. A Figura 5 mostra a aparência de um pipeline de CI/CD com o uso das ferramentas do Google para contêineres em execução no Google Kubernetes Engine.
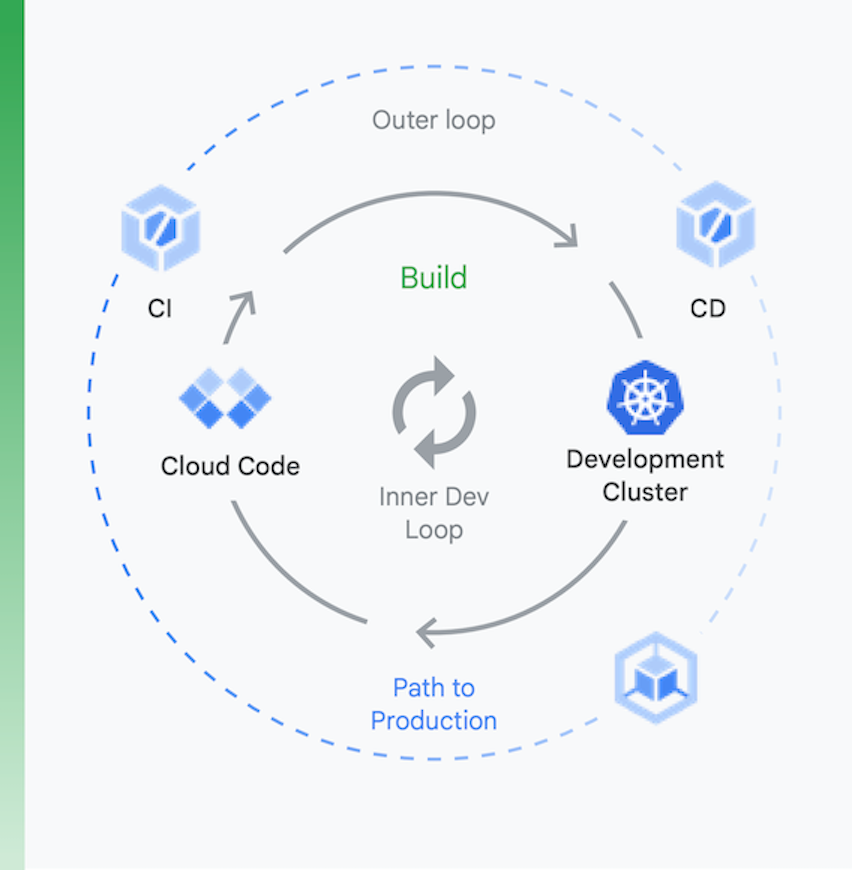
É útil pensar no processo em dois blocos, conforme mostrado na Figura 6:
Desenvolvimento local | Desenvolvimento remoto |
a meta aqui é acelerar um loop de desenvolvimento interno e oferecer aos desenvolvedores ferramentas para conseguir um feedback rápido sobre o impacto das alterações de código locais. Isso inclui compatibilidade com inspeção, preenchimento automático para YAML e builds locais mais rápidos. | Quando uma solicitação de envio (PR, na sigla em inglês) é enviada, o loop de desenvolvimento remoto é iniciado. A meta é reduzir consideravelmente o tempo necessário para validar e testar a PR pela CI e realizar outras atividades, como verificação de vulnerabilidades e assinatura binária, além de impulsionar aprovações de lançamentos de maneira automatizada. |
Desenvolvimento local
Desenvolvimento remoto
a meta aqui é acelerar um loop de desenvolvimento interno e oferecer aos desenvolvedores ferramentas para conseguir um feedback rápido sobre o impacto das alterações de código locais. Isso inclui compatibilidade com inspeção, preenchimento automático para YAML e builds locais mais rápidos.
Quando uma solicitação de envio (PR, na sigla em inglês) é enviada, o loop de desenvolvimento remoto é iniciado. A meta é reduzir consideravelmente o tempo necessário para validar e testar a PR pela CI e realizar outras atividades, como verificação de vulnerabilidades e assinatura binária, além de impulsionar aprovações de lançamentos de maneira automatizada.
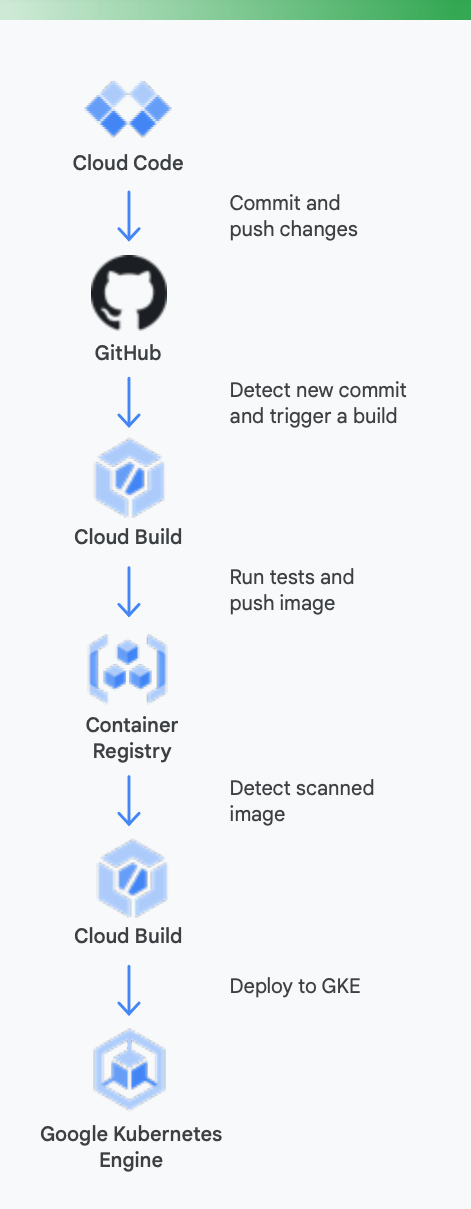
Veja como as ferramentas do Google Cloud podem ajudar durante esse processo
Desenvolvimento local: tornar os desenvolvedores produtivos com o desenvolvimento local de aplicativos é essencial. Esse desenvolvimento local envolve a criação de aplicativos que possam ser implantados em clusters locais e remotos. Antes de comprometer alterações em um sistema de gerenciamento de controle de origem como o GitHub, ter um loop de desenvolvimento local rápido pode garantir que os desenvolvedores testem e implantem as alterações em um cluster local.
Como resultado, o Google Cloud oferece o Cloud Code, que vem com extensões para ambientes de desenvolvimento integrado, como Visual Studio Code e Intellij, para permitir que os desenvolvedores iterem, depurem e executem códigos rapidamente no Kubernetes. Em segundo plano, o Cloud Code usa ferramentas conhecidas, como Skaffold, Jib e Kubectl, para permitir que os desenvolvedores consigam feedback contínuo sobre o código em tempo real.
Integração contínua: com o novo app GitHub do Cloud Build, as equipes podem acionar builds em diferentes eventos de repositório: solicitações de envio, ramificação ou tag diretamente no GitHub. O Cloud Build é uma plataforma totalmente sem servidor e escalona vertical e horizontalmente em resposta à carga, sem a necessidade de pré-provisionar servidores ou pagar antecipadamente por capacidade extra. Builds acionados pelo app GitHub postam automaticamente o status de volta ao GitHub. O feedback é integrado diretamente ao fluxo de trabalho do desenvolvedor do GitHub, reduzindo a troca de contexto.
Gerenciamento de artefatos:Container Registry é uma central para sua equipe gerenciar imagens do Docker, realizar verificações de vulnerabilidades e decidir quem pode acessar o quê com controle de acesso refinado. A integração da verificação de vulnerabilidades com o Cloud Build permite que os desenvolvedores identifiquem ameaças à segurança assim que o Cloud Build cria uma imagem e a armazena no Container Registry.
Entrega contínua: o Cloud Build usa etapas de compilação para permitir que você defina etapas específicas a serem realizadas como parte dos processos de compilação, teste e implantação. Por exemplo, depois que um contêiner novo é criado e enviado ao Container Registry, uma etapa de compilação posterior pode implantar esse contêiner no Google Kubernetes Engine (GKE) ou no Cloud Run, com a configuração e a política relacionadas. Também é possível implantar em outros provedores de nuvem, caso você esteja buscando uma estratégia de várias nuvens. Por fim, se você quer buscar uma entrega contínua de estilo GitOps, o Cloud Build possibilita descrever suas implantações de maneira declarativa usando arquivos (por exemplo, manifestos do Kubernetes) armazenados em um repositório do Git.
No entanto, implantar códigos não é o fim da história. As organizações também precisam gerenciar esse código enquanto ele é executado. Para fazer isso, o Google Cloud fornece ferramentas às equipes de operações, como o Cloud Monitoring e o Cloud Logging.
Usar as ferramentas de CI/CD do Google certamente não é necessário com o GKE. Você pode usar conjuntos de ferramentas alternativos, se preferir. Os exemplos incluem aproveitar o Jenkins para CI/CD ou o Artifactory para gerenciamento de artefatos.
Se você é como a maioria das organizações com aplicativos em nuvem com base em VM, provavelmente não tem um sistema de CI/CD potente hoje em dia. Implementar um sistema assim é uma parte essencial para conseguir benefícios de seu aplicativo reestruturado, mas dá trabalho. As tecnologias necessárias para criar seus pipelines estão disponíveis, em parte graças à maturidade do Kubernetes. Mas as mudanças humanas podem ser substanciais. As pessoas em suas equipes de entrega precisam se tornar multifuncionais, incluindo desenvolvimento, teste e habilidades operacionais. Mudar a cultura leva tempo. Portanto, prepare-se para dedicar esforços com o objetivo de mudar o conhecimento e o comportamento de sua equipe conforme ela muda para um mundo de CI/CD.
Concentrar-se na segurança
A reestruturação de aplicativos monolíticos para um paradigma nativo da nuvem é uma mudança grande. É claro que isso apresenta novos desafios de segurança que você precisará resolver. Dois dos mais importantes são estes:
- Proteção do acesso entre contêineres
- Garantia de uma cadeia de suprimentos de software segura
O primeiro desses desafios decorre de um fato óbvio: dividir seu aplicativo em serviços (e talvez microsserviços) conteinerizados exige alguma forma de comunicação desses serviços. E, mesmo que todos estejam potencialmente em execução no mesmo cluster do Kubernetes, você ainda precisa se preocupar em controlar o acesso entre eles. Afinal, é possível compartilhar esse cluster do Kubernetes com outros aplicativos, e você não pode deixar seus contêineres abertos para esses outros apps.
Para controlar o acesso a um contêiner, é preciso autenticar os autores da chamada e determinar quais 17 solicitações esses outros contêineres estão autorizados a fazer. É comum hoje em dia resolver esse problema (e vários outros) com o uso de uma malha de serviço. Um exemplo importante disso é o Istio, um projeto de código aberto criado pelo Google, IBM e outras empresas. Na Figura 7, mostramos onde o Istio se encaixa em um cluster do Kubernetes.
Como mostra a figura, o proxy Istio intercepta todo o tráfego entre contêineres em seu aplicativo. Isso permite que a malha de serviço forneça vários serviços úteis sem nenhuma alteração no código do aplicativo. Esses serviços incluem o seguinte:
- Segurança, com autenticação serviço a serviço usando TLS e autenticação do usuário final.
- Gerenciamento de tráfego, permitindo que você controle como as solicitações são roteadas entre os contêineres em seu aplicativo.
- Observabilidade, capturando registros e métricas de comunicação entre seus contêineres.
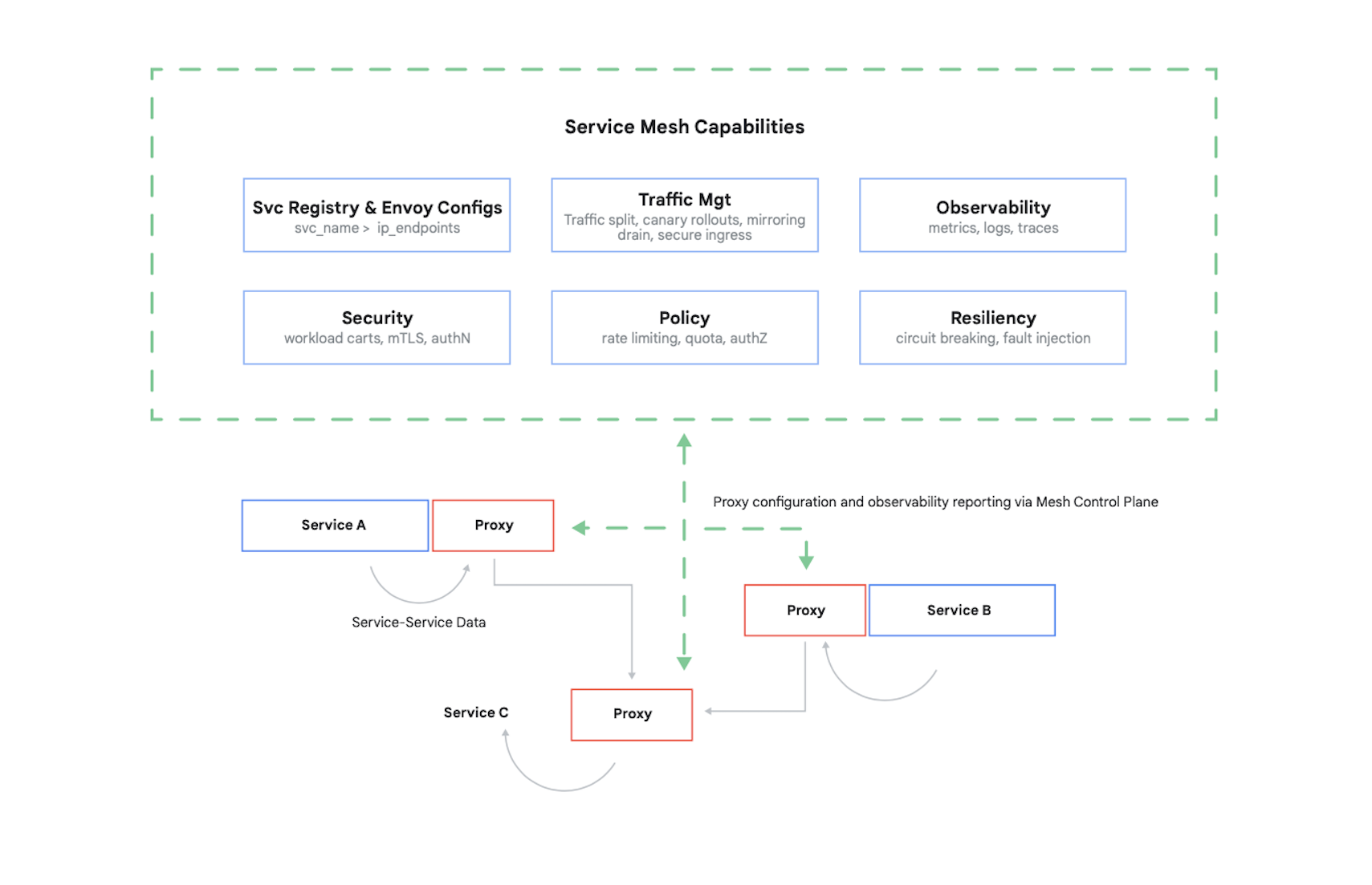
O Google Cloud permite adicionar o Istio a um cluster do GKE. O uso de uma malha de serviço não é obrigatório, mas não se surpreenda se clientes bem informados sobre seus aplicativos em nuvem começarem a se perguntar se sua segurança está no nível que o Istio oferece. Os clientes se preocupam muito com segurança, e o Istio é uma parte importante para oferecê-la em um mundo com base em contêineres.
Além da compatibilidade com o Istio de código aberto, o Google Cloud oferece o Traffic Director, um plano de controle de malha de serviço totalmente gerenciado pelo Google Cloud que oferece balanceamento de carga global entre clusters e instâncias de VM em várias regiões, se livra da verificação de integridade de proxies de serviço e fornece gerenciamento de tráfego sofisticado e outros recursos descritos acima.
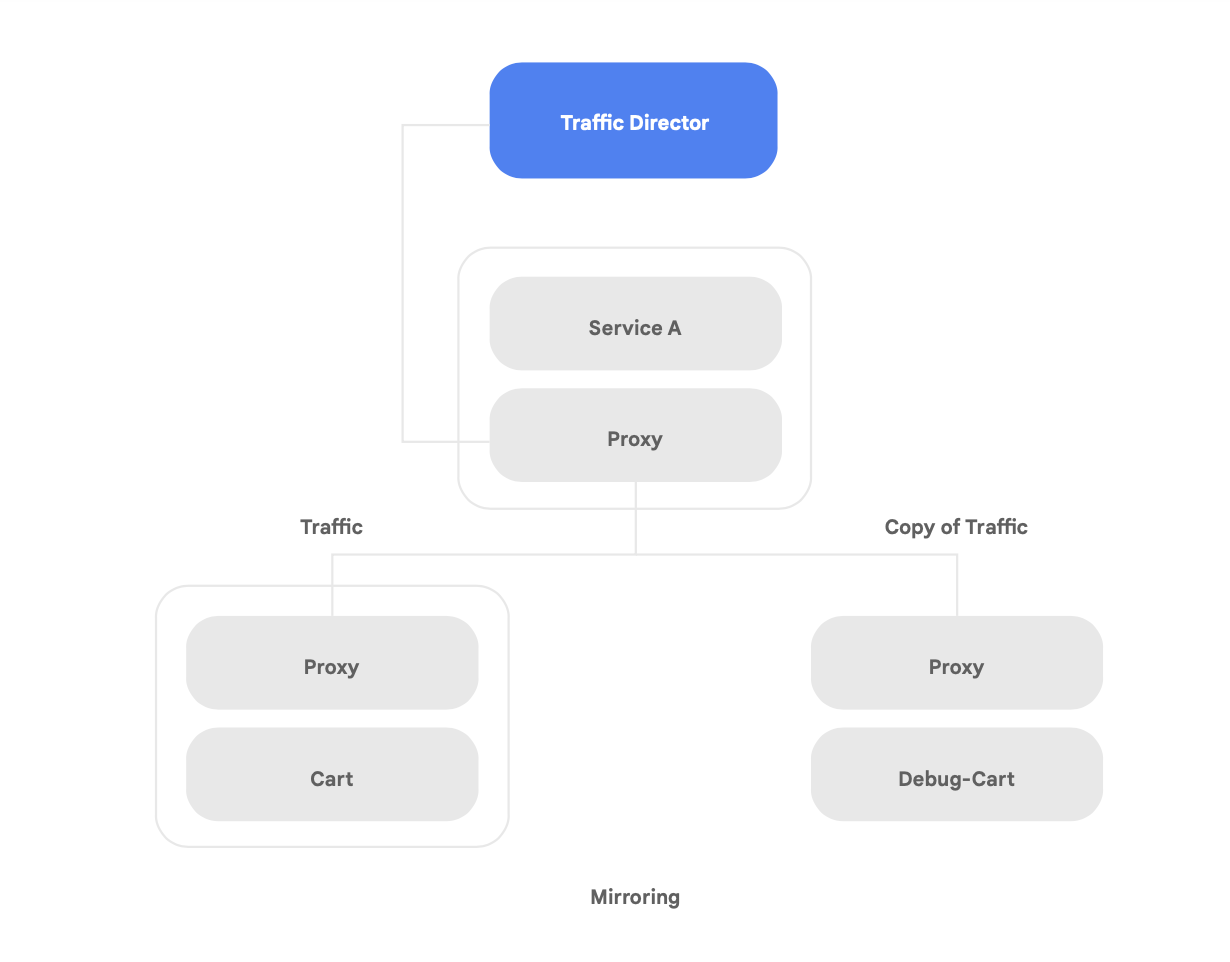
Um dos recursos exclusivos do Traffic Director é o failover e estouro automáticos entre regiões para microsserviços na malha (mostrado na Figura 8).
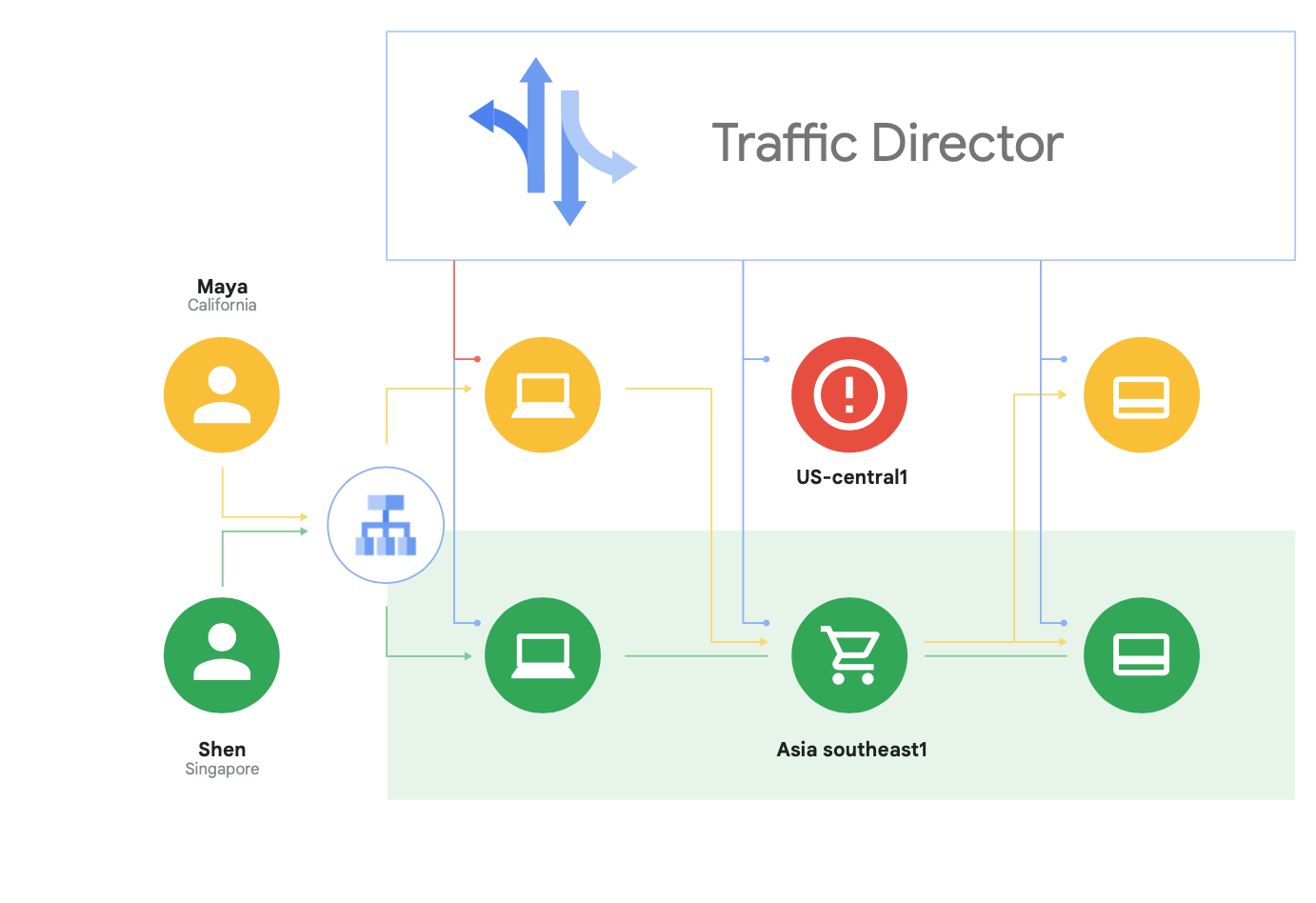
É possível acoplar resiliência global com segurança para seus serviços na malha de serviço com esse recurso.
O Traffic Director oferece vários recursos de gerenciamento de tráfego que podem ajudar a melhorar a postura de segurança de sua malha de serviço. Por exemplo: o recurso de espelhamento de tráfego mostrado na Figura 9 pode ser facilmente configurado como uma política para permitir que um aplicativo de sombra receba uma cópia do tráfego real que está sendo processado pela versão principal do. As respostas de cópia recebidas pelo serviço de sombra são descartadas após o processamento. O espelhamento de tráfego pode ser uma ferramenta poderosa para testar anomalias de segurança e erros de depuração no tráfego de produção sem impactar ou tocar no tráfego de produção.
Mas proteger as interações entre seus contêineres não é o único desafio de segurança novo que um aplicativo refatorado traz consigo. Outra preocupação é garantir que as imagens de contêiner executadas sejam confiáveis. Para isso, certifique-se de que sua cadeia de suprimentos de software tem segurança e conformidade integradas.
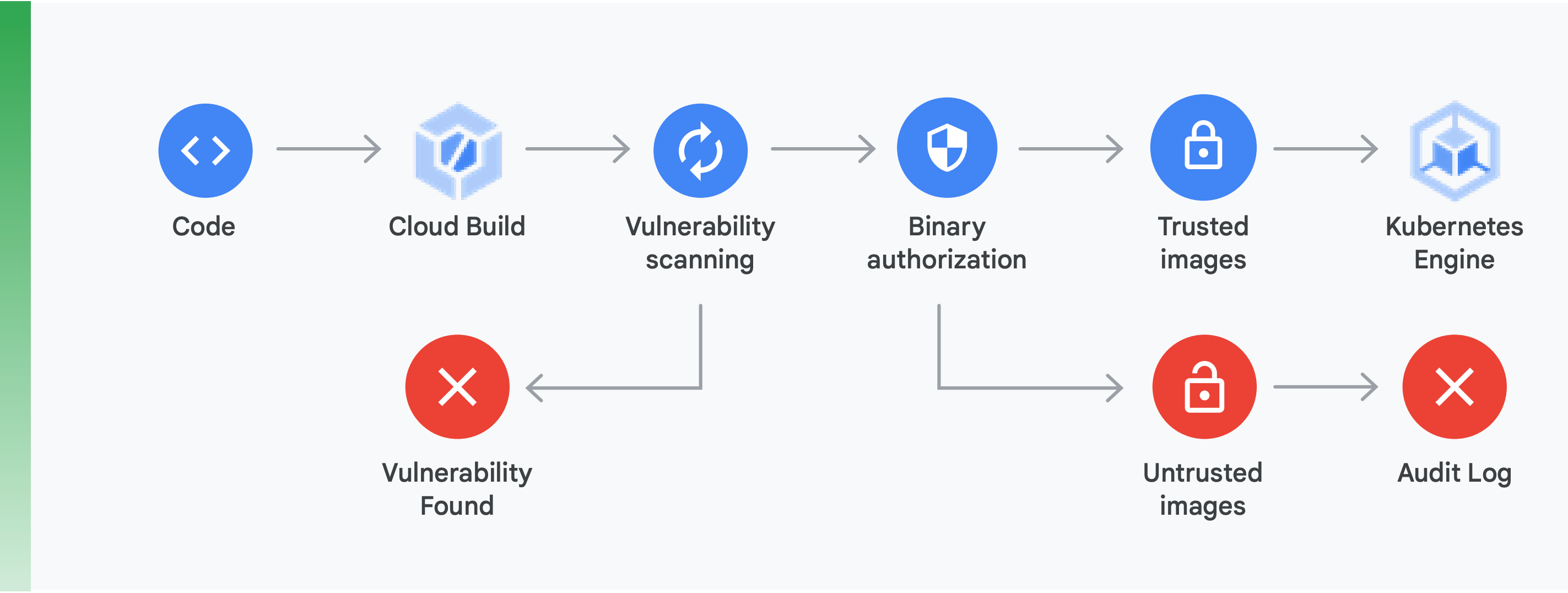
Isso requer dois itens principais (mostrados na Figura 10):
Verificação de vulnerabilidades: a verificação de vulnerabilidades do Container Registry permite que você receba feedback rápido sobre ameaças em potencial e identifique problemas assim que seus contêineres são criados pelo Cloud Build e armazenados no Container Registry. Vulnerabilidades em pacotes para Ubuntu, Debian e Alpine são identificadas durante o processo de desenvolvimento do aplicativo, e a compatibilidade com CentOS e RHEL está a caminho. Isso ajuda a evitar ineficiências caras e reduz o tempo necessário para corrigir vulnerabilidades conhecidas.
Autorização binária: ao integrar a autorização binária e a verificação de vulnerabilidades do Container Registry, é possível bloquear implementações com base nas descobertas da verificação como parte da política de implementação geral. A autorização binária é um controle de segurança no momento da implantação que garante que apenas imagens de contêiner confiáveis sejam implantadas no GKE sem nenhuma intervenção manual.
Proteger o acesso entre contêineres com uma malha de serviço e garantir uma cadeia de suprimentos de software segura são aspectos importantes da criação de aplicativos com base em contêiner seguros. Há muito mais, incluindo a verificação da segurança da infraestrutura da plataforma em nuvem que você está criando. O mais importante, porém, é perceber que mudar de um aplicativo monolítico para um paradigma moderno nativo da nuvem apresenta novos desafios de segurança. Para fazer essa transição com sucesso, será preciso compreender o que são eles e criar um plano concreto para abordar cada um deles.
Como começar
Não trate a mudança para uma arquitetura nativa da nuvem como um projeto big-bang com duração de vários anos.
Em vez disso, comece agora encontrando uma equipe com capacidade e experiência para começar com uma prova de conceito ou encontre uma que já tenha feito isso. Em seguida, pegue as lições aprendidas e comece a divulgá-las por toda a organização. Faça com que as equipes adotem o padrão strangler fig, movendo os serviços de maneira incremental e iterativa para uma arquitetura nativa da nuvem à medida que continuam a oferecer funcionalidades novas.
Para ter sucesso, é essencial que as equipes tenham a capacidade, os recursos e a autoridade para fazer da evolução da arquitetura dos sistemas uma parte do trabalho diário. Defina metas arquitetônicas claras para o novo trabalho, seguindo os seis resultados arquitetônicos apresentados anteriormente, mas dê às equipes liberdade para decidir como chegar lá.
O mais importante de tudo é não esperar para começar. Aumentar a produtividade e a agilidade de suas equipes e a segurança e a estabilidade de seus serviços será cada vez mais fundamental para o sucesso de sua organização. As equipes que se saem melhor são as que fazem da experimentação disciplinada e do aprimoramento parte do trabalho diário.
O Google inventou o Kubernetes, com base no software que usamos internamente há anos, e é por isso que temos a mais profunda experiência com tecnologia nativa da nuvem.
O Google Cloud tem um foco grande em aplicativos conteinerizados, conforme evidenciado por nossas ofertas de segurança e CI/CD. A verdade é clara: o Google Cloud é hoje o líder em suporte para aplicativos conteinerizados.
Acesse cloud.google.com/devops para fazer nossa verificação rápida e descobrir como você está indo e receber conselhos sobre como prosseguir, incluindo padrões de implementação discutidos neste artigo, como uma arquitetura acoplada com flexibilidade.
Muitos parceiros do Google Cloud já ajudaram organizações como a sua a fazer essa transição. Por que trilhar um caminho de reestruturação por conta própria quando podemos conectar você a um guia experiente?
Para começar, entre em contato conosco para marcar uma reunião com um arquiteto de soluções do Google. Podemos ajudar a compreender a mudança e, em seguida, trabalhar com você para que ela aconteça.
Sugestões de leitura
https://cloud.google.com/devops: seis anos do relatório State of DevOps, um conjunto de artigos com informações detalhadas sobre os recursos que preveem o desempenho da entrega de software e uma verificação rápida para ajudar você a descobrir como está se saindo e como melhorar.
Site Reliability Engineering: How Google Run Production Systems (O'Reilly 2016) (em inglês)
Manual de confiabilidade do site: maneiras práticas de implementar SRE (O'Reilly 2018)
"Como dividir um monolítico em microsserviços: o que separar e quando" de Zhamak Dehghani
“Microsserviços: uma definição deste novo termo arquitetônico” por Martin Fowler
“Strangler Fig Application” de Martin Fowler
Tudo pronto para prosseguir?
Preencha o formulário para entrarmos em contato com você. Entre em contato com a equipe de vendas











