Riprogettare l'architettura rendendola cloud-native
Secondo la ricerca DORA (DevOps Research and Assessment), i team di DevOps di maggiore successo eseguono diversi deployment al giorno, pubblicano modifiche in produzione in meno di un giorno e hanno una percentuale di errore sulle modifiche tra lo 0 e il 15%.
Questo white paper spiega come riprogettare l'architettura delle applicazioni passando a un paradigma cloud-native, che consente di accelerare la distribuzione di nuove funzionalità anche mentre i team crescono, migliorando la qualità del software e garantendo livelli più elevati di stabilità e disponibilità.
Perché passare a un'architettura cloud-native?
Molte aziende creano servizi software personalizzati utilizzando architetture monolitiche. Questo approccio presenta alcuni vantaggi: progettare sistemi monolitici ed eseguirne il deployment è relativamente semplice, almeno all'inizio. Tuttavia, può diventare difficile mantenere la produttività degli sviluppatori e la velocità di deployment man mano che le applicazioni diventano più complesse. Di conseguenza, la modifica dei sistemi risulta dispendiosa in termini di tempo e denaro, ed è rischioso eseguirne il deployment.
Man mano che crescono, i servizi e i relativi team tendono a diventare più complessi e difficili da gestire e far evolvere. I test e il deployment diventano più problematici, l'aggiunta di nuove funzionalità più difficoltosa e il mantenimento dell'affidabilità e della disponibilità più faticoso.
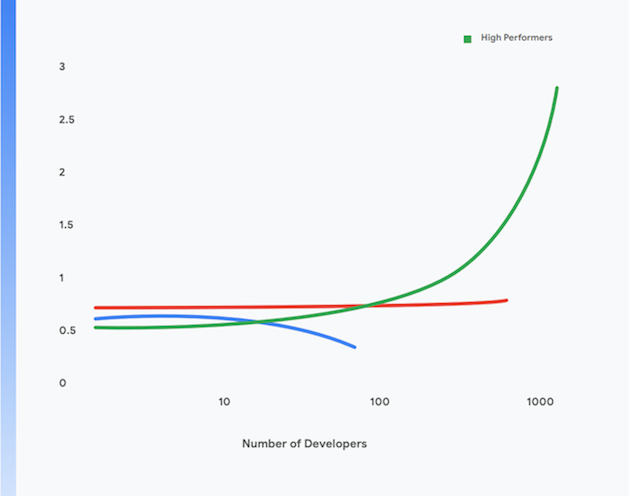
Una ricerca del team DORA di Google mostra che è possibile raggiungere livelli elevati di velocità effettiva di distribuzione del software, oltre che stabilità e disponibilità dei servizi, in organizzazioni di qualsiasi dimensione e dominio. I team ad alte prestazioni sono in grado di eseguire più deployment al giorno, pubblicare modifiche in produzione in meno di un giorno, ripristinare il servizio in meno di un'ora e ottenere una percentuale di errore sulle modifiche tra lo 0 e il 15%.1
Tali team riescono inoltre a raggiungere livelli più elevati di produttività degli sviluppatori, misurata in termini di deployment per sviluppatore al giorno, anche quando le dimensioni dei team crescono. Ciò si può osservare nella Figura 1.
Il resto di questa pagina spiega come eseguire la migrazione delle applicazioni a un paradigma cloud-native moderno per ottenere questi risultati. Implementando le tecniche descritte in questo documento, puoi raggiungere i seguenti obiettivi:
- Aumento della produttività degli sviluppatori, anche se aumenti le dimensioni dei team
- Velocizzazione del time-to-market: aggiungi nuove funzionalità e risolvi i problemi più rapidamente
- Aumento della disponibilità: aumenta il tempo di attività del software, riduci la percentuale di errori di deployment e il tempo di ripristino in caso di incidenti
- Miglioramento della sicurezza: riduci l'area della superficie d'attacco delle applicazioni e semplifica il rilevamento di attacchi, assicurando una risposta rapida agli stessi e alle nuove vulnerabilità individuate
- Miglioramento della scalabilità: le piattaforme e le applicazioni cloud-native semplificano la scalabilità orizzontale laddove necessaria, oltre che lo scale down
- Riduzione dei costi: un processo di distribuzione del software semplificato riduce i costi della distribuzione di nuove funzionalità, mentre l'uso efficace delle piattaforme cloud riduce significativamente i costi operativi dei servizi
1 Scopri quali sono le prestazioni del tuo team in base a queste quattro metriche chiave visitando la pagina https://cloud.google.com/devops/
Che cos'è un'architettura cloud-native?
Le applicazioni monolitiche devono essere create, testate e se ne deve eseguire il deployment come una singola unità. Spesso, gli stack del sistema operativo, del middleware e del linguaggio dell'applicazione sono configurati in maniera personalizzata per ogni applicazione. Anche gli script e i processi di creazione, test e deployment sono in genere univoci per ogni applicazione. Si tratta di un metodo semplice ed efficace per le applicazioni nate da poco, ma, man mano che crescono, diventa più difficile modificare, testare, eseguire il deployment e gestire tali sistemi.
Inoltre, insieme ai sistemi, crescono le dimensioni e la complessità dei team che creano, testano, eseguono il deployment e gestiscono il servizio. Un approccio comune ma errato consiste nel suddividere i team in base alla funzione, il che comporta consegne tra i team che tendono a far aumentare i tempi di risposta e le dimensioni dei batch e portano a quantità significative di rilavorazione. La ricerca di DORA evidenzia come i team ad alte prestazioni hanno il doppio delle probabilità di sviluppare e distribuire software in un singolo team interfunzionale.
I sintomi di questo problema includono:
- Processi di compilazione lunghi e spesso non funzionanti
- Cicli di integrazione e test poco frequenti
- Aumento dell'impegno necessario per supportare i processi di compilazione e test
- Perdita di produttività degli sviluppatori
- Processi di deployment difficoltosi che devono essere eseguiti al di fuori dell'orario di lavoro, rendendo necessari tempi di inattività pianificati
- Impegno significativo nella gestione della configurazione degli ambienti di test e produzione
Nel paradigma cloud-native, invece³:
- I sistemi complessi vengono scomposti in servizi che possono essere testati e di cui può essere eseguito il deployment in maniera indipendente su un runtime containerizzato (un'architettura orientata ai microservizi o ai servizi);
- Le applicazioni utilizzano servizi standard forniti dalla piattaforma, ad esempio sistemi di gestione di database (DBMS), archiviazione blob, messaggistica, CDN e terminazione SSL;
- Una piattaforma cloud standardizzata si occupa di numerosi problemi operativi, ad esempio il deployment, la scalabilità automatica, la configurazione, la gestione dei segreti, il monitoraggio e gli avvisi. Questi servizi sono accessibili on demand dai team di sviluppo delle applicazioni.
- Agli sviluppatori di applicazioni vengono forniti gli stack standardizzati del sistema operativo, del middleware e specifici per linguaggio e la manutenzione e l'applicazione di patch di questi stack vengono effettuate fuori banda dal provide della piattaforma o da un team separato;
- Un singolo team interfunzionale può essere responsabile dell'intero ciclo di vita della distribuzione del software di ogni servizio.
3 Questa non è da intendersi come una descrizione completa di ciò che significa "cloud-native": per un'analisi di alcuni dei principi dell'architettura cloud-native, visita https://cloud.google.com/blog/products/ application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it..
Questo paradigma offre numerosi vantaggi:
Distribuzione più rapida | Release affidabili | Riduzione dei costi |
poiché i servizi sono ora di piccole dimensioni e a basso accoppiamento, i team a essi associati possono lavorare in maniera autonoma. Di conseguenza aumentano la produttività degli sviluppatori e la velocità di sviluppo. | gli sviluppatori possono rapidamente creare, testare ed eseguire il deployment di servizi nuovi ed esistenti su ambienti di test simili a quelli di produzione. Anche il deployment in produzione è un'attività semplice e atomica. Ciò consente di velocizzare il processo di distribuzione e ridurre il rischio dei deployment in modo considerevole. | Il costo e la complessità degli ambienti di test e produzione è notevolmente ridotto, poiché i servizi condivisi e standardizzati sono forniti dalla piattaforma e perché le applicazioni vengono eseguite su un'infrastruttura fisica condivisa. |
Maggiore sicurezza | Maggiore disponibilità | Conformità più semplice ed economica |
i fornitori ora sono responsabili degli aggiornamenti, delle patch e della conformità dei servizi condivisi, ad esempio i DBMS e l'infrastruttura di messaggistica. Anche applicare patch alle applicazioni e mantenerle aggiornate è molto più semplice, poiché esiste un modo standard di eseguire il deployment e gestire le applicazioni. | La disponibilità e l'affidabilità delle applicazioni aumentano grazie alla ridotta complessità dell'ambiente operativo, alla semplicità delle modifiche di configurazione e alla capacità di gestire la scalabilità e la riparazione automatiche a livello di piattaforma. | Gran parte dei controlli di sicurezza delle informazioni possono essere implementati a livello di piattaforma, rendendo significativamente più semplici e più economiche l'implementazione e la dimostrazione della conformità. Molti cloud provider mantengono la conformità con framework di gestione dei rischi come SOC2 e FedRAMP, il che significa che le applicazioni di cui viene eseguito il deployment su di essi devono dimostrare la conformità solo con controlli residui non implementati al livello di piattaforma. |
Distribuzione più rapida
Release affidabili
Riduzione dei costi
poiché i servizi sono ora di piccole dimensioni e a basso accoppiamento, i team a essi associati possono lavorare in maniera autonoma. Di conseguenza aumentano la produttività degli sviluppatori e la velocità di sviluppo.
gli sviluppatori possono rapidamente creare, testare ed eseguire il deployment di servizi nuovi ed esistenti su ambienti di test simili a quelli di produzione. Anche il deployment in produzione è un'attività semplice e atomica. Ciò consente di velocizzare il processo di distribuzione e ridurre il rischio dei deployment in modo considerevole.
Il costo e la complessità degli ambienti di test e produzione è notevolmente ridotto, poiché i servizi condivisi e standardizzati sono forniti dalla piattaforma e perché le applicazioni vengono eseguite su un'infrastruttura fisica condivisa.
Maggiore sicurezza
Maggiore disponibilità
Conformità più semplice ed economica
i fornitori ora sono responsabili degli aggiornamenti, delle patch e della conformità dei servizi condivisi, ad esempio i DBMS e l'infrastruttura di messaggistica. Anche applicare patch alle applicazioni e mantenerle aggiornate è molto più semplice, poiché esiste un modo standard di eseguire il deployment e gestire le applicazioni.
La disponibilità e l'affidabilità delle applicazioni aumentano grazie alla ridotta complessità dell'ambiente operativo, alla semplicità delle modifiche di configurazione e alla capacità di gestire la scalabilità e la riparazione automatiche a livello di piattaforma.
Gran parte dei controlli di sicurezza delle informazioni possono essere implementati a livello di piattaforma, rendendo significativamente più semplici e più economiche l'implementazione e la dimostrazione della conformità. Molti cloud provider mantengono la conformità con framework di gestione dei rischi come SOC2 e FedRAMP, il che significa che le applicazioni di cui viene eseguito il deployment su di essi devono dimostrare la conformità solo con controlli residui non implementati al livello di piattaforma.
Tuttavia, esistono alcuni compromessi associati al modello cloud-native:
- Tutte le applicazioni sono ora sistemi distribuiti, il che significa che eseguono un numero significativo di chiamate remote come parte delle loro operazioni. Ciò comporta un'attenta riflessione su come gestire gli errori di rete e i problemi relativi alle prestazioni e su come eseguire il debug dei problemi in produzione.
- Gli sviluppatori devono utilizzare gli stack standardizzati del sistema operativo, del middleware e delle applicazioni forniti dalla piattaforma. Ciò rende più difficoltoso lo sviluppo locale.
- Gli architetti devono adottare un approccio alla progettazione di sistemi basato sugli eventi, inclusa l'adozione della coerenza finale.
Eseguire la migrazione a un'architettura cloud native
Molte organizzazioni hanno adottato un approccio "lift and shift" al trasferimento dei servizi sul cloud. In questo approccio, sono richieste solo piccole modifiche ai sistemi e il cloud viene praticamente considerato come un data center tradizionale, sebbene fornisca API, servizi e strumenti di gestione notevolmente migliori rispetto ai data center tradizionali. Tuttavia, il lift and shift da solo non fornisce alcun vantaggio di quelli del paradigma cloud-native descritti sopra.
Molte organizzazioni si fermano al lift and shift a causa del costo e della complessità dello spostamento delle applicazioni su un'architettura cloud-native, che richiede un ripensamento totale, dall'architettura delle applicazioni alle operazioni di produzione e all'intero ciclo di vita di distribuzione del software. Questa paura è razionale: molte grandi organizzazioni sono rimaste scottate da sconvolgenti tentativi pluriennali falliti di sostituzione della piattaforma.
La soluzione è adottare un approccio incrementale, iterativo ed evolutivo alla riprogettazione dell'architettura dei sistemi per renderla cloud-native, consentendo ai team di imparare come lavorare in modo efficace in questo nuovo paradigma continuando a distribuire nuove funzionalità: un approccio che chiamiamo "move-and-improve".
Un pattern chiave nell'architettura evolutiva è noto come applicazione di Strangler Fig.4 Invece di riscrivere completamente i sistemi da zero, scrivi nuove funzionalità in uno stile moderno e cloud-native, ma falle dialogare con l'applicazione monolitica originale per le funzionalità esistenti. Sposta gradualmente nel corso del tempo le funzionalità esistenti in base alle necessità dell'integrità concettuale dei nuovi servizi, come mostrato nella Figura 2.
4 Descritto in https://martinfowler.com/bliki/StranglerFigApplication.html
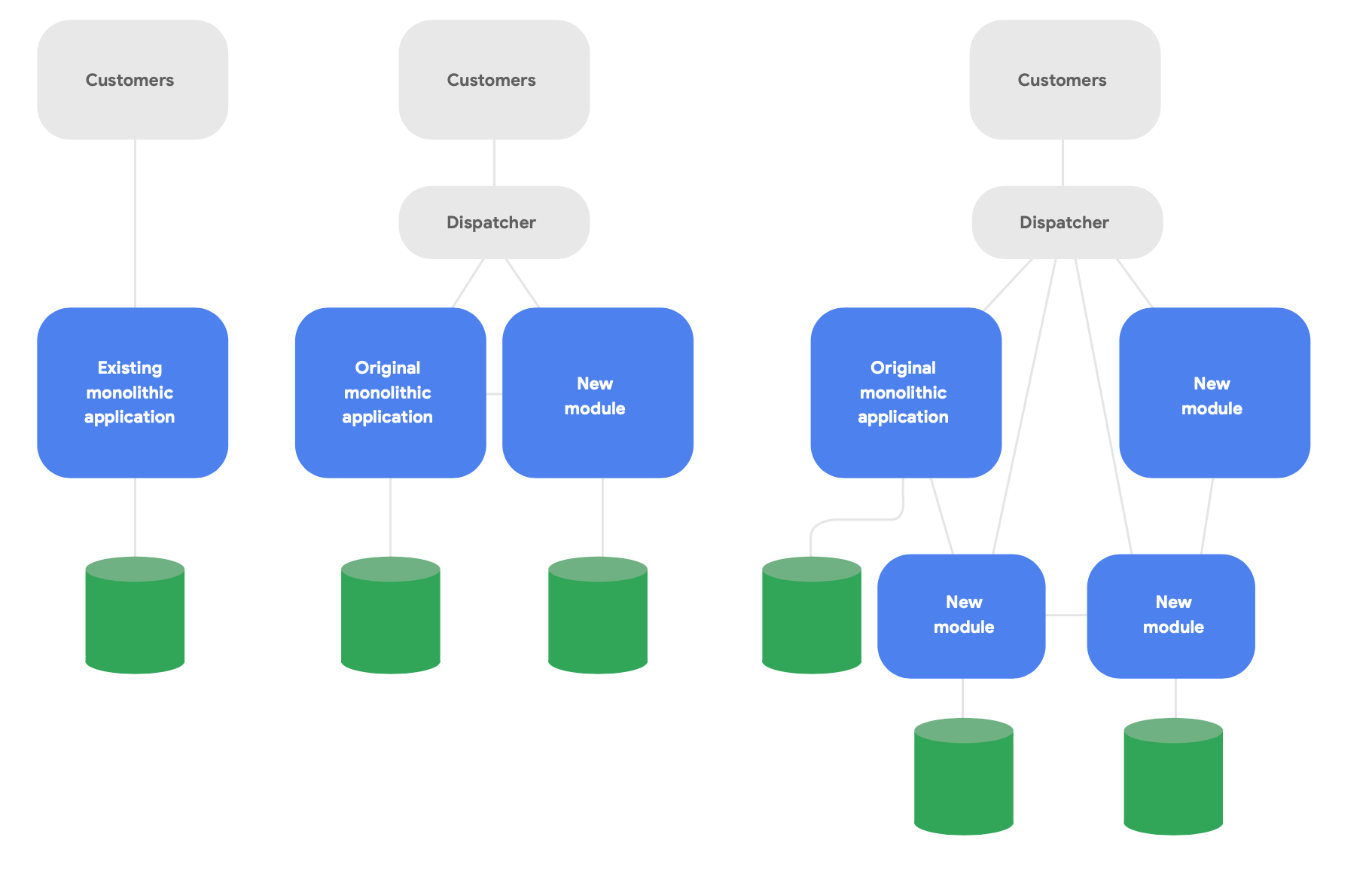
Di seguito sono elencate tre importanti linee guida per riprogettare con successo l'architettura:
Per prima cosa, inizia distribuendo velocemente nuove funzionalità invece di riprodurre quelle esistenti. La metrica fondamentale è la velocità con cui sei in grado di iniziare a distribuire nuove funzionalità usando i nuovi servizi, in modo da poter imparare velocemente e comunicare la buona prassi acquisita lavorando effettivamente all'interno di questo paradigma. Restringi drasticamente l'ambito con l'obiettivo di distribuire qualcosa agli utenti reali in settimane, non mesi.
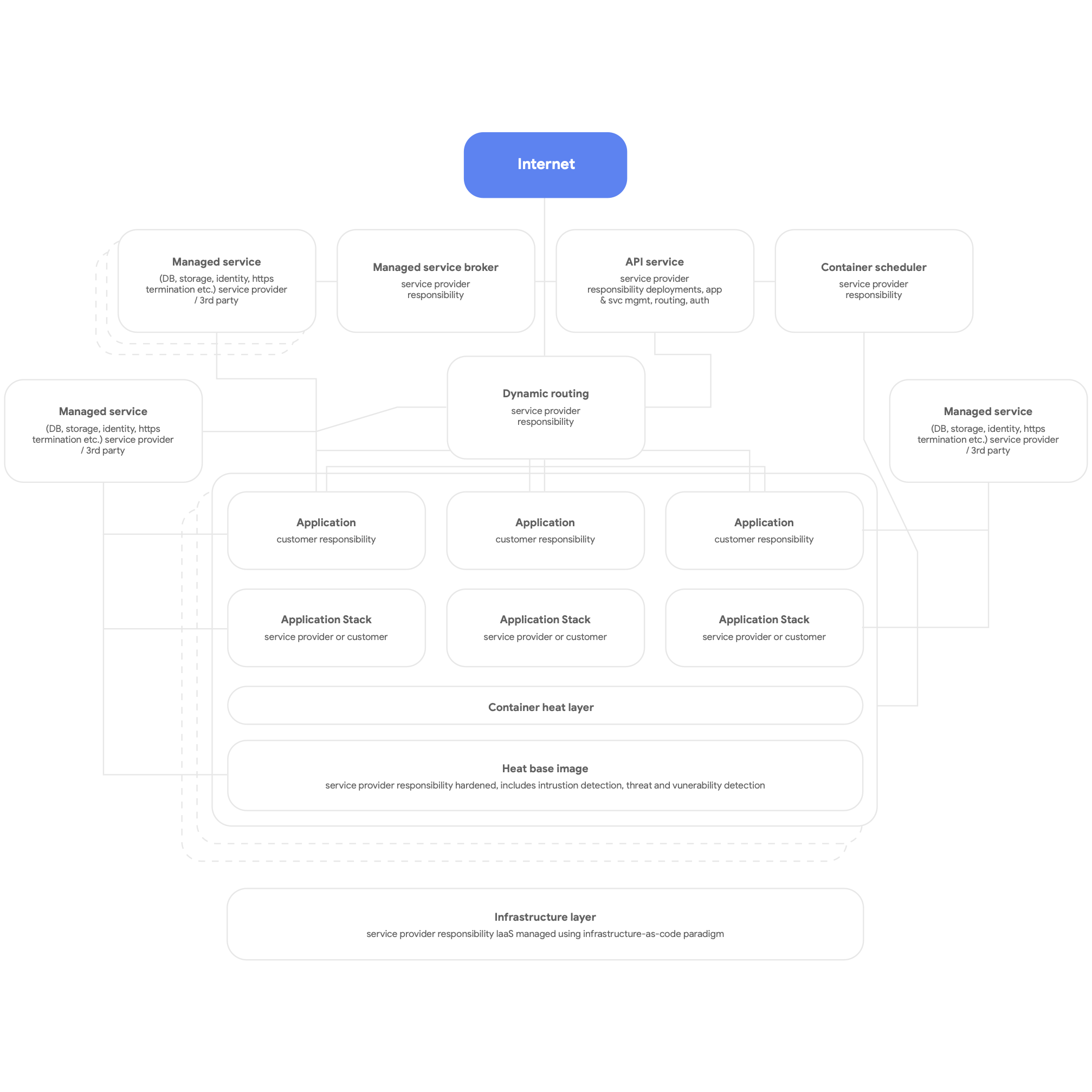
In secondo luogo, progetta in maniera cloud-native. Ciò vuol dire utilizzare i servizi nativi della piattaforma cloud per DBMS, messaggistica, CDN, networking, archiviazione blob e così via e utilizzare il più possibile stack delle applicazioni standardizzati e forniti dalla piattaforma. I servizi devono essere containerizzati e utilizzare il più possibile il paradigma serverless e il processo di compilazione, test e deployment deve essere completamente automatizzato. Fai in modo che tutte le applicazioni utilizzino i servizi condivisi forniti dalla piattaforma per logging, monitoraggio e avvisi (vale la pena ricordare che il deployment di questo tipo di architettura della piattaforma è adatto a qualsiasi piattaforma di applicazioni multi-tenant, incluso un ambiente on-premise bare-metal). Un quadro di alto livello di una piattaforma cloud-native è mostrato nella Figure 3 sottostante.
Infine, progetta in modo da avere team autonomi e a basso accoppiamento in grado di testare ed eseguire il deployment dei propri servizi. La nostra ricerca mostra che i risultati architetturali più importanti riguardano la capacità dei team di distribuzione del software di rispondere "sì" alle seguenti sei domande:
- Siamo in grado di effettuare modifiche su larga scala alla progettazione del nostro sistema senza l'autorizzazione di qualcuno esterno al team?
- Siamo in grado di effettuare modifiche alla progettazione del nostro sistema senza dipendere dalle modifiche da parte di altri team ai loro sistemi o creare lavoro significativo per altri team?
- Siamo in grado di completare il nostro lavoro senza comunicare e coordinarci con altre persone esterne al team?
- Siamo in grado di eseguire il deployment e il rilascio del nostro prodotto o servizio on demand, indipendentemente da altri servizi a cui è collegato?
- Siamo in grado di eseguire gran parte dei nostri test on demand, senza il bisogno di un ambiente di test integrato?
- Siamo in grado di eseguire i deployment durante il normale orario di lavoro con un tempo di inattività trascurabile?
Verifica regolarmente se i team stanno lavorando per raggiungere questi obiettivi e assicurati che abbiano la priorità sul resto. Ciò in genere comporta il ripensamento dell'architettura sia a livello organizzativo che aziendale.
In particolare, è fondamentale organizzare i team in modo che tutti i ruoli necessari per creare, testare ed eseguire il deployment del software, inclusi i product manager, lavorino insieme e usino pratiche di product management moderne per creare e far evolvere i servizi di cui si occupano. Questo non implica modifiche alla struttura organizzativa. Già il fatto che tali persone lavorino insieme ogni giorno (condividendo uno spazio fisico, se possibile), invece di avere sviluppatori, tester e team di rilascio che operano in modo indipendente, fa una grande differenza per la produttività.
La nostra ricerca mostra che la misura in cui i team rispondono affermativamente a queste domande ha consentito di prevedere con certezza prestazioni di software elevate: la capacità di distribuire servizi affidabili e a disponibilità elevata più volte al giorno. Questo, a sua volta, è ciò che consente ai team ad alte prestazioni di aumentare la produttività degli sviluppatori (misurata in termini di numero di deployment per sviluppatore al giorno) anche se il numero di team aumenta.
Principi e best practice
Principi e best practice dell'architettura basata su microservizi
Quando si adotta un'architettura orientata ai microservizi o ai servizi, esistono alcuni importanti principi e best practice che è bene seguire. Conviene essere rigorosi nel seguirli dall'inizio poiché è più costoso applicarli in seguito.
- Ogni servizio deve avere il suo schema di database. Che tu stia utilizzando un database relazionale o una soluzione nosql, ogni servizio deve avere il suo schema a cui nessun altro servizio accede. Quando più servizi dialogano con lo stesso schema, nel corso del tempo diventano altamente accoppiati a livello di database. Queste dipendenze impediscono i test e i deployment indipendenti dei servizi, rendendo le loro modifiche più difficoltose e il loro deployment più rischioso.
- I servizi devono comunicare solo tramite le loro API pubbliche sulla rete. Tutti i servizi devono esporre il proprio comportamento tramite API pubbliche e dialogare tra loro solo tramite tali API. Non deve esserci alcun accesso "back door" o servizi che dialogano direttamente con i database di altri servizi. Ciò previene che i servizi diventino altamente accoppiati e assicura che la comunicazione tra servizi utilizzi API ben documentate e supportate.
- I servizi sono responsabili della compatibilità con le versioni precedenti per i propri clienti. Il team che crea e gestisce un servizio è responsabile che gli aggiornamenti del servizio non provochino malfunzionamenti per i consumatori. Ciò significa pianificare il controllo delle versioni e i test delle API per garantire la compatibilità con le versioni precedenti, in modo che quando si rilasciano nuove versioni non siano causati malfunzionamenti per i clienti esistenti. I team possono convalidare ciò utilizzando le versioni canary. Questo vuol dire anche assicurarsi che i deployment non introducano tempi di inattività, usando tecniche come i deployment blu/verdi o l'implementazione graduale.
- Crea un modo standard di eseguire i servizi su workstation di sviluppo. Gli sviluppatori devono essere in grado di implementare on demand qualsiasi sottoinsieme di servizi di produzione su workstation di sviluppo utilizzando un singolo comando. Deve essere possibile anche eseguire on demand versioni stub dei servizi. Assicurati di usare versioni emulate dei servizi cloud che molti cloud provider forniscono per aiutarti. L'obiettivo è semplificare per gli sviluppatori le operazioni di test e debug locali dei servizi.
- Investi nel monitoraggio e nell'osservabilità della produzione. Molti problemi in produzione, inclusi quelli relativi alle prestazioni, derivano e sono causati dalle interazioni tra più servizi. La nostra ricerca mostra che è importante avere una soluzione che segnali l'integrità generale dei sistemi (ad esempio, i sistemi funzionano? Hanno a disposizione sufficienti risorse?) e che i team abbiano accesso a strumenti e dati che li aiutino a tracciare, comprendere e diagnosticare problemi infrastrutturali negli ambienti di produzione, incluse le interazioni tra i servizi.
- Imposta obiettivi del livello di servizio (SLO) per i servizi ed esegui regolarmente dei test di ripristino di emergenza. Impostare gli SLO per i servizi consente di stabilire delle aspettative sulle loro prestazioni e ti aiuta a pianificare il modo in cui il sistema deve comportarsi se un servizio smette di funzionare (una considerazione fondamentale quando si creano sistemi distribuiti resilienti). Fai dei test per vedere come il sistema si comporta nel mondo reale utilizzando tecniche come l'inserimento controllato di errori come parte del piano di test di ripristino di emergenza. La ricerca di DORA mostra che le organizzazioni che conducono test di ripristino di emergenza usando metodi come questo hanno maggiori probabilità di ottenere livelli più elevati di disponibilità del servizio. Conviene iniziare a farlo il prima possibile, così da poter normalizzare questo tipo di attività fondamentale.
Si tratta di numerosi elementi su cui riflettere, per questo è importante guidare questo tipo di lavoro con un team che ha la capacità di sperimentare con l'implementazione di queste idee. Ci saranno successi e fallimenti: è importante apprendere da questi team e sfruttare ciò che impari man mano che espandi il nuovo paradigma architetturale nell'organizzazione.
La nostra ricerca mostra che le società che hanno successo utilizzano proof of concept e forniscono opportunità ai team di condividere le proprie conoscenze, ad esempio creando community sulle pratiche. Fornisci tempo, spazio e risorse per consentire alle persone di più team di incontrarsi regolarmente e scambiare idee. Tutti avranno inoltre bisogno di apprendere nuove competenze e tecnologie. Investi nella crescita dei dipendenti mettendo a loro disposizione un budget per acquistare libri, seguire corsi di formazione e partecipare a conferenze. Fornisci l'infrastruttura e il tempo per consentire alle persone di diffondere conoscenze istituzionali e buone pratiche tramite mailing list della società, knowledge base e incontri di persona.
Architettura di riferimento
In questa sezione, descriveremo un'architettura di riferimento basata sulle seguenti linee guida:
- Utilizzare container per i servizi di produzione e uno scheduler di container come Cloud Run o Kubernetes per l'orchestrazione
- Creare pipeline CI/CD efficaci
- Concentrarsi sulla sicurezza
Containerizzare i servizi di produzione
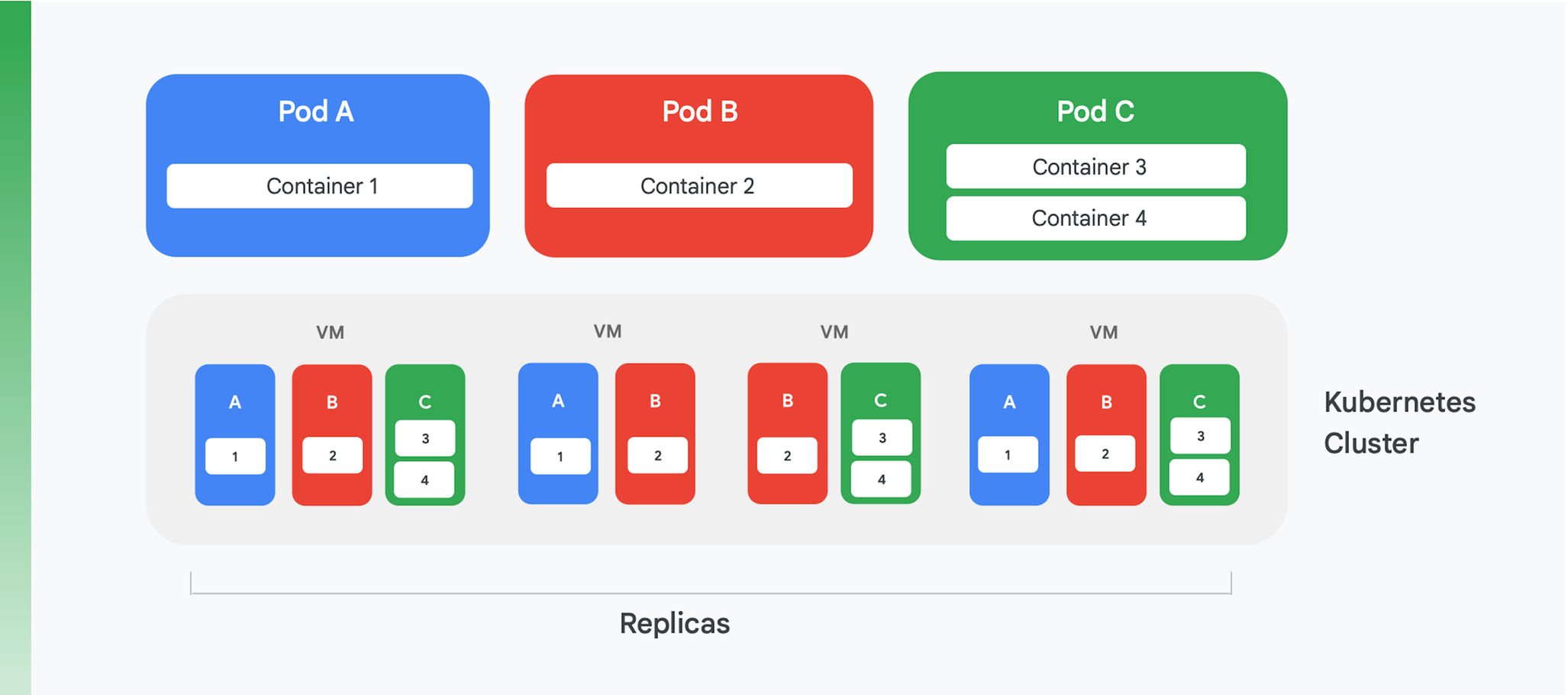
La base di un'applicazione cloud containerizzata è un servizio di gestione e orchestrazione dei container. Sono stati creati molti servizi, ma uno è oggi ampiamente dominante: Kubernetes. Kubernetes rappresenta lo standard di settore per l'orchestrazione dei container, con una vivace community e il supporto di gran parte dei principali fornitori commerciali. La Figura 4 riassume la struttura logica di un cluster Kubernetes.
Kubernetes definisce un'astrazione chiamata pod. Ogni pod spesso include solo un container, come i pod A e B nella Figura 4, anche se un pod può contenerne più di uno, come nel caso del pod C. Ogni servizio Kubernetes esegue un cluster contenente un certo numero di nodi, ognuno dei quali è di solito una macchina virtuale (VM). La Figura 4 mostra solo quattro VM, ma un cluster reale potrebbe facilmente contenerne un centinaio o più. Quando viene eseguito il deployment di un pod su un cluster Kubernetes, il servizio determina in quali VM dovrebbero essere eseguiti i container di quel pod. Poiché i container specificano le risorse di cui hanno bisogno, Kubernetes può fare delle scelte intelligenti riguardo a quali pod vengono assegnati a ogni VM.
Parte delle informazioni di deployment di un pod indica quante istanze, o repliche, del pod devono essere eseguite. Il servizio Kubernetes crea quindi tale numero di istanze dei container del pod e le assegna alle VM. Nella Figure 4, ad esempio, il deployment del pod A ha richiesto tre repliche, così come quello del pod C. Il deployment del pod B, invece, ha richiesto quattro repliche, quindi questo cluster di esempio contiene quattro istanze in esecuzione del container 2. Inoltre, come suggeriscono le cifre, un pod con più di un container, ad esempio il pod C, vedrà tali container assegnati sempre allo stesso nodo.
Kubernetes offre anche altri servizi, tra cui:
- Monitoraggio dei pod in esecuzione, in modo che se in un container si verifica un errore, il servizio avvierà una nuova istanza. Ciò assicura che tutte le repliche richieste nel deployment di un pod restino disponibili.
- Bilanciamento del carico del traffico, espandendo in maniera intelligente nelle repliche di un container le richieste effettuate a ogni pod.
- Rollout automatizzato senza tempo di inattività, in cui le nuove istanze sostituiscono gradualmente quelle esistenti fino al deployment completo di una nuova versione.
- Scalabilità automatizzata, grazie alla quale un cluster aggiunge o elimina autonomamente le VM in base alla domanda.
Creare pipeline CI/CD efficaci
Alcuni dei vantaggi del refactoring di un'applicazione monolitica, ad esempio i costi ridotti, derivano direttamente dall'esecuzione su Kubernetes. Però, uno dei vantaggi più importanti, cioè la capacità di aggiornare l'applicazione con più frequenza, è possibile solo se modifichi il modo in cui crei e rilasci software. Per ottenere questo vantaggio è necessario creare pipeline CI/CD efficaci all'interno dell'organizzazione.
L'integrazione continua si basa sui flussi di lavoro di creazione e test automatizzati che forniscono un feedback rapido agli sviluppatori. Richiede che ogni membro di un team che lavora sullo stesso codice (ad esempio, il codice di un singolo servizio) integri regolarmente il proprio lavoro in una linea principale condivisa o trunk condiviso. Questa integrazione deve avvenire almeno quotidianamente per ogni sviluppatore e ogni integrazione deve essere verificata da un processo di compilazione che include test automatizzati. La distribuzione continua punta a rendere il deployment di questo codice integrato rapido e poco rischioso, principalmente automatizzando il processo di compilazione, test e deployment in modo che le attività come prestazioni sicurezza e test di esplorazione possano essere eseguite continuamente. Detto in maniera più semplice, la CI aiuta gli sviluppatori a rilevare velocemente problemi di integrazione, mentre la CD rende il deployment affidabile e lo trasforma in un'attività di routine.
Perché tutto ciò sia più chiaro, è utile esaminare un esempio concreto. La Figura 5 mostra come potrebbe apparire una pipeline CI/CD utilizzando gli strumenti di Google per i container in esecuzione su Google Kubernetes Engine.
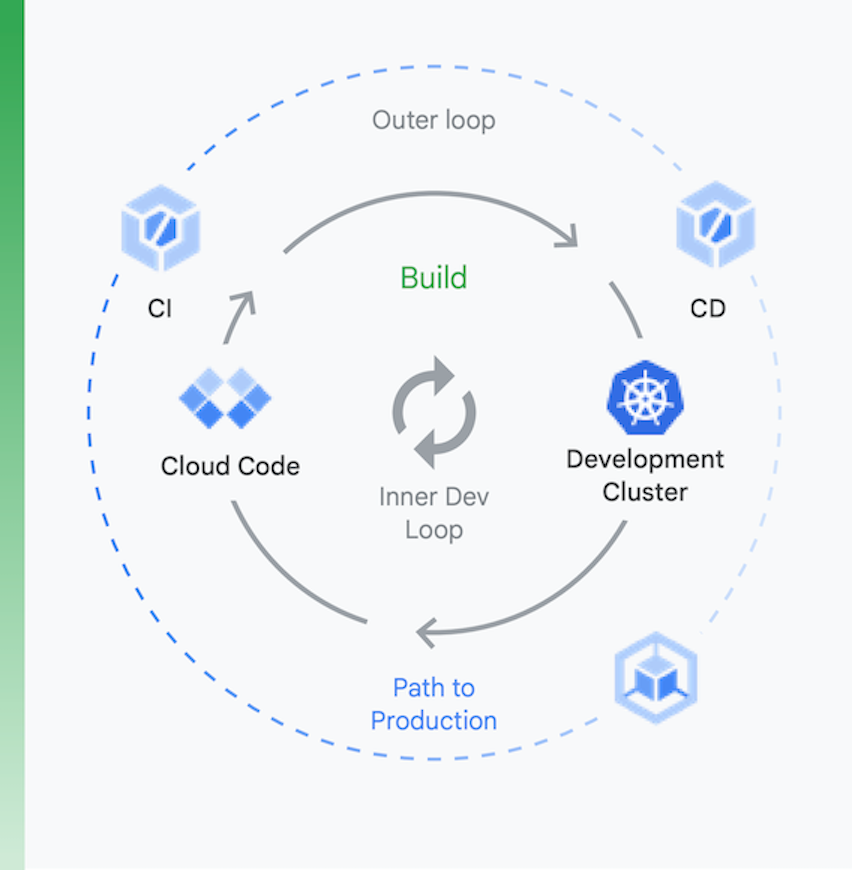
È utile pensare al processo suddividendolo in due blocchi, come mostrato nella Figura 6:
Sviluppo locale | Sviluppo remoto |
l'obiettivo qui è velocizzare un loop di sviluppo interno e fornire agli sviluppatori gli strumenti per ottenere rapidamente un feedback sull'impatto delle modifiche al codice locale. Ciò include supporto dell'analisi tramite lint, completamento automatico per YAML e build locali più rapide. | Quando una richiesta di pull (PR) viene inviata, si avvia il loop di sviluppo. L'obiettivo qui è ridurre drasticamente il tempo necessario per convalidare e testare le PR tramite CI ed eseguire altre attività come l'analisi delle vulnerabilità e la firma dei file binari, generando al contempo approvazioni in maniera automatizzata. |
Sviluppo locale
Sviluppo remoto
l'obiettivo qui è velocizzare un loop di sviluppo interno e fornire agli sviluppatori gli strumenti per ottenere rapidamente un feedback sull'impatto delle modifiche al codice locale. Ciò include supporto dell'analisi tramite lint, completamento automatico per YAML e build locali più rapide.
Quando una richiesta di pull (PR) viene inviata, si avvia il loop di sviluppo. L'obiettivo qui è ridurre drasticamente il tempo necessario per convalidare e testare le PR tramite CI ed eseguire altre attività come l'analisi delle vulnerabilità e la firma dei file binari, generando al contempo approvazioni in maniera automatizzata.
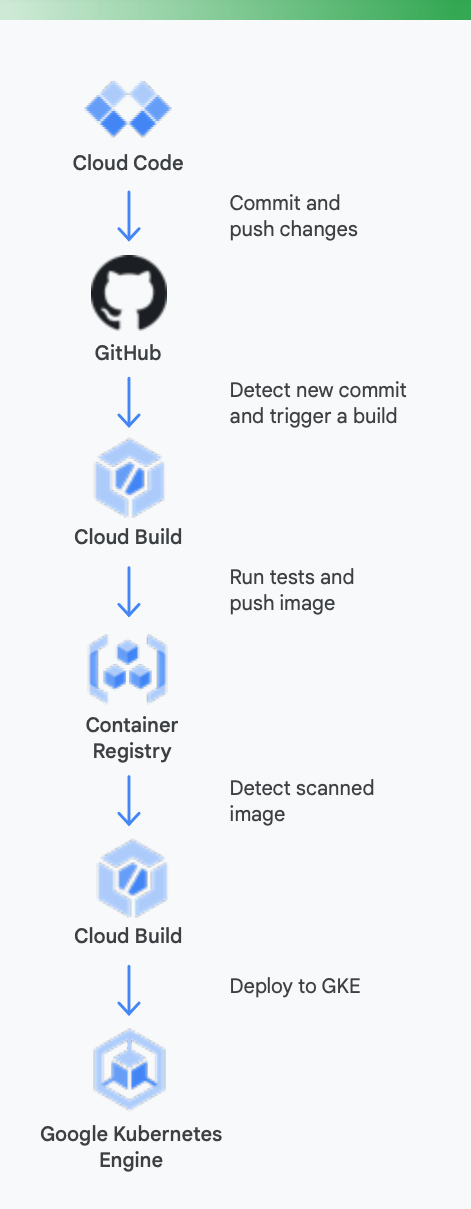
Ecco come gli strumenti di Google Cloud possono essere d'aiuto in questo processo
Sviluppo locale: è fondamentale rendere gli sviluppatori produttivi con lo sviluppo di applicazioni locale. Questo sviluppo locale comporta la creazione di applicazioni il cui deployment può essere eseguito su cluster locali e remoti. Prima di eseguire il commit delle modifiche a un sistema di controllo sorgente come GitHub, avere un loop di sviluppo locale può far sì che gli sviluppatori abbiano la possibilità di testare le modifiche ed eseguirne il deployment su un cluster locale.
Perciò Google Cloud fornisce Cloud Code. Cloud Code include estensioni agli IDE, come Visual Studio Code e Intellij, per permettere agli sviluppatori di eseguire rapidamente l'iterazione, il debug e il codice su Kubernetes. Cloud Code utilizza strumenti diffusi come Skaffold, Jib e Kubectl per consentire agli sviluppatori di ricevere un feedback continuo sul codice in tempo reale.
Integrazione continua: con la nuova app per GitHub di Cloud Build, i team possono attivare build su diversi eventi di repository, ad esempio eventi relativi a richieste di pull, rami o tag, direttamente da GitHub. Cloud Build è una piattaforma completamente serverless e fa lo scale up e lo scale down in risposta al carico senza requisiti per il pre-provisioning dei server o pagamenti in anticipo per capacità aggiuntiva. Le build attivate tramite l'app di GitHub pubblicano automaticamente lo stato su GitHub. Il feedback è integrato direttamente nel flusso di lavoro degli sviluppatori di GitHub, riducendo il cambio di contesto.
Gestione degli artefatti: Container Registry offre una singola posizione da cui il tuo team può gestire le immagini Docker, eseguire l'analisi delle vulnerabilità e decidere chi ha accesso a cosa grazie al controllo granulare dell'accesso. L'integrazione dell'analisi delle vulnerabilità con Cloud Build consente agli sviluppatori di identificare le minacce non appena Cloud Build crea un'immagine e la archivia in Container Registry.
Distribuzione continua: Cloud Build utilizza passi di build per consentirti di definire i passaggi specifici da eseguire come parte della creazione, del test e del deployment. Ad esempio, una volta che un nuovo container è stato creato e inviato a Container Registry, un passaggio di build successivo può eseguirne il deployment su Google Kubernetes Engine (GKE) o Cloud Run, insieme alla configurazione e al criterio relativi. Puoi anche eseguire il deployment su altri cloud provider nel caso tu stia perseguendo una strategia multi-cloud. Infine, se desideri perseguire una distribuzione continua in stile GitOps, Cloud Build ti consente di descrivere i deployment in modo dichiarativo utilizzando file (ad esempio manifest di Kubernetes) archiviati in un repository Git.
Il deployment del codice, però, non è la conclusione. Le organizzazioni devono anche gestire tale codice mentre è in esecuzione. Per farlo, Google Cloud fornisce ai team operativi strumenti come Cloud Monitoring and Cloud Logging.
L'uso degli strumenti CI/CD di Google ovviamente non è obbligatorio in GKE, puoi utilizzare liberamente toolchain alternative se lo desideri. Alcuni esempi includono lo sfruttamento di Jenkins for CI/CD o di Artifactory per la gestione degli artefatti.
Se la tua organizzazione somiglia a gran parte di quelle con applicazioni basate su VM, probabilmente al momento non dispone di un sistema di CI/CD efficiente. Realizzarne uno è una parte fondamentale del processo per ottenere i vantaggi dell'applicazione riprogettata, ma richiede lavoro. Le tecnologie necessarie per creare le tue pipelines sono disponibili, in parte grazie alla maturità di Kubernetes. Le modifiche umane possono però essere considerevoli. I membri dei team di distribuzione devono diventare interfunzionali, anche relativamente alle competenze di sviluppo, di test e operative. Il cambio di cultura richiede tempo, perciò preparati a impegnarti per modificare le conoscenze e i comportamenti dei tuoi dipendenti durante il loro passaggio al mondo CI/CD.
Concentrarsi sulla sicurezza
La riprogettazione dell'architettura di applicazioni monolitiche per passare a un paradigma cloud-native rappresenta un grande cambiamento. Com'è facile prevedere, fare ciò introduce nuove sfide di sicurezza che sarà necessario affrontare. Due delle più importanti sono:
- Protezione dell'accesso tra container
- Protezione della catena di fornitura del software
La prima di queste sfide nasce da un fatto ovvio: suddividere l'applicazione in servizi containerizzati (e magari microservizi) rende necessario un modo che permetta a tali servizi di comunicare. Inoltre, anche se potenzialmente sono tutti in esecuzione sullo stesso cluster Kubernetes, devi comunque preoccuparti di controllare l'accesso tra essi. Dopo tutto, potresti condividere quel cluster Kubernetes con altre applicazioni alle quali non puoi lasciare i container aperti.
Il controllo degli accessi a un container richiede l'autenticazione di chi effettua le chiamate e la determinazione di quali richieste questi altri container sono autorizzati a effettuare. Oggi questo problema (e diversi altri) si risolve in genere utilizzando un mesh di servizi. Un esempio principale di ciò è Istio, un progetto open source creato da Google, IBM e altri. La Figura 7 mostra in che modo Istio viene utilizzato in un cluster Kubernetes.
Come mostra la figura, il proxy di Istio intercetta tutto il traffico tra i container nell'applicazione. Ciò consente al mesh di servizi di fornire diversi servizi utili senza alcuna modifica al codice dell'applicazione. Questi servizi includono:
- Sicurezza, con autenticazione tra servizi tramite TLS e autenticazione degli utenti finali
- Gestione del traffico, che ti consente di controllare in che modo le richieste vengono instradate tra i container nell'applicazione
- Osservabilità, grazie all'acquisizione di logs e metriche di comunicazione tra i container
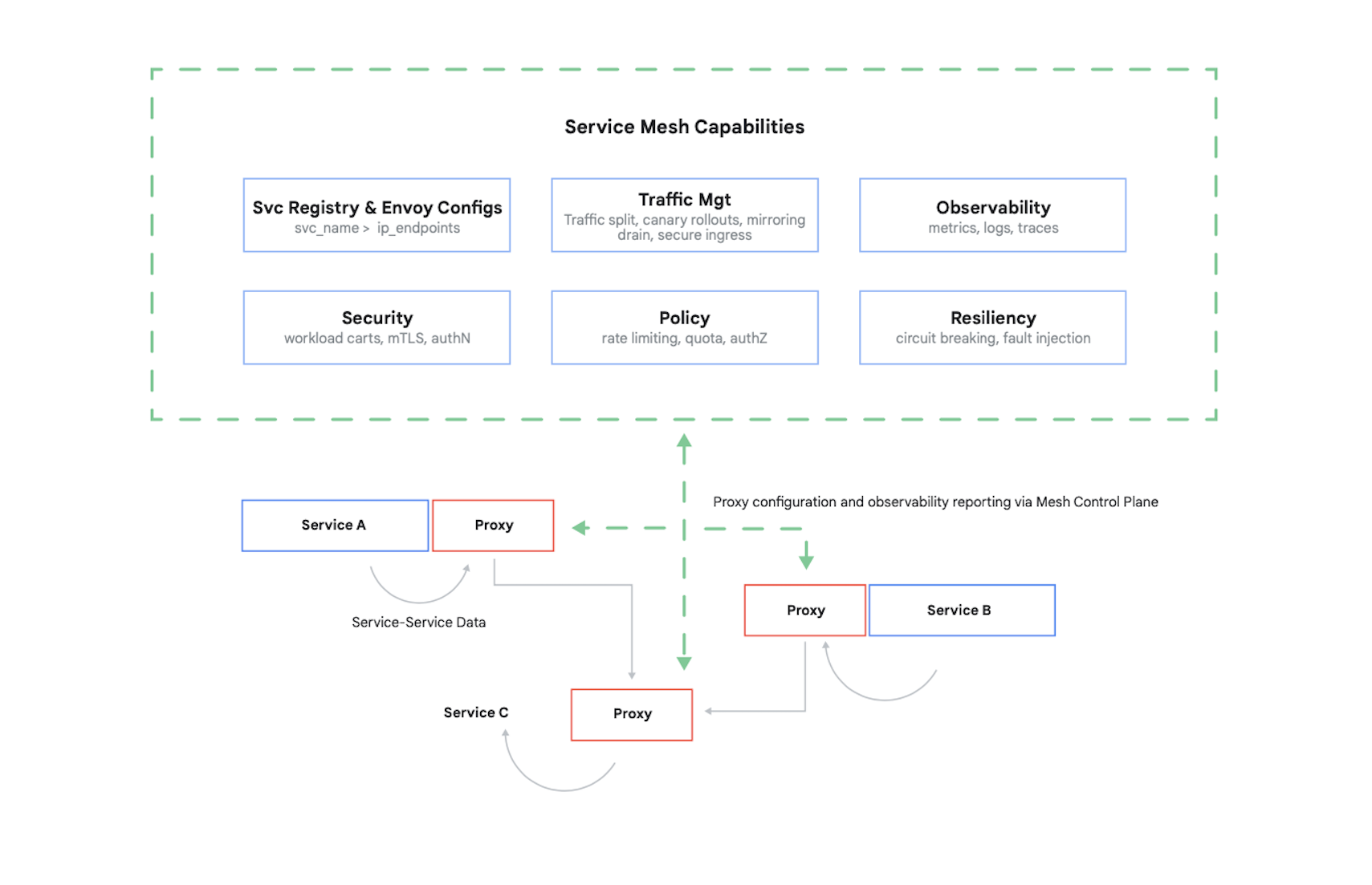
Google Cloud ti consente di aggiungere Istio a un cluster GKE. Inoltre, anche se l'utilizzo di un mesh di servizi non è obbligatorio, non sorprenderti se i clienti ben informati delle tue applicazioni cloud iniziano a chiedere se la tua sicurezza è allo stesso livello di quella fornita da Istio. I clienti tengono molto alla sicurezza e, in un mondo basato su container, Istio è un elemento importante che la fornisce.
Oltre a supportare Istio open source, Google Cloud offre Traffic Director, un piano di controllo del mesh di servizi completamente gestito da Google Cloud, che fornisce il bilanciamento del carico globale nei cluster e nelle istanze VM in più aree geografiche, il trasferimento del controllo di integrità dai proxy dei servizi, una gestione del traffico sofisticata e altre funzionalità descritte sopra.
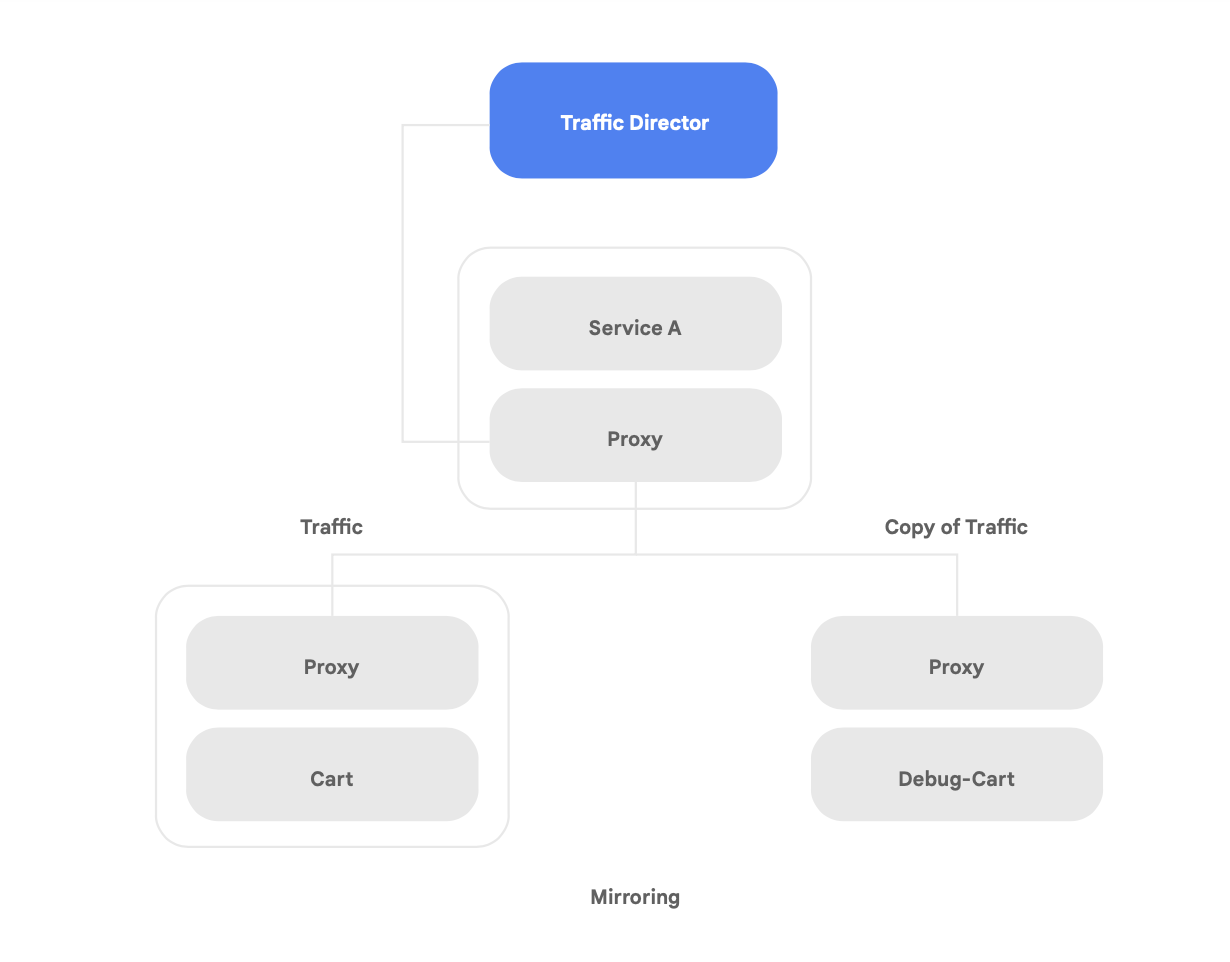
Tra le funzionalità uniche di Traffic Director vi sono failover e overflow automatici tra aree geografiche per i microservizi nel mesh (mostrate nella Figura 8).
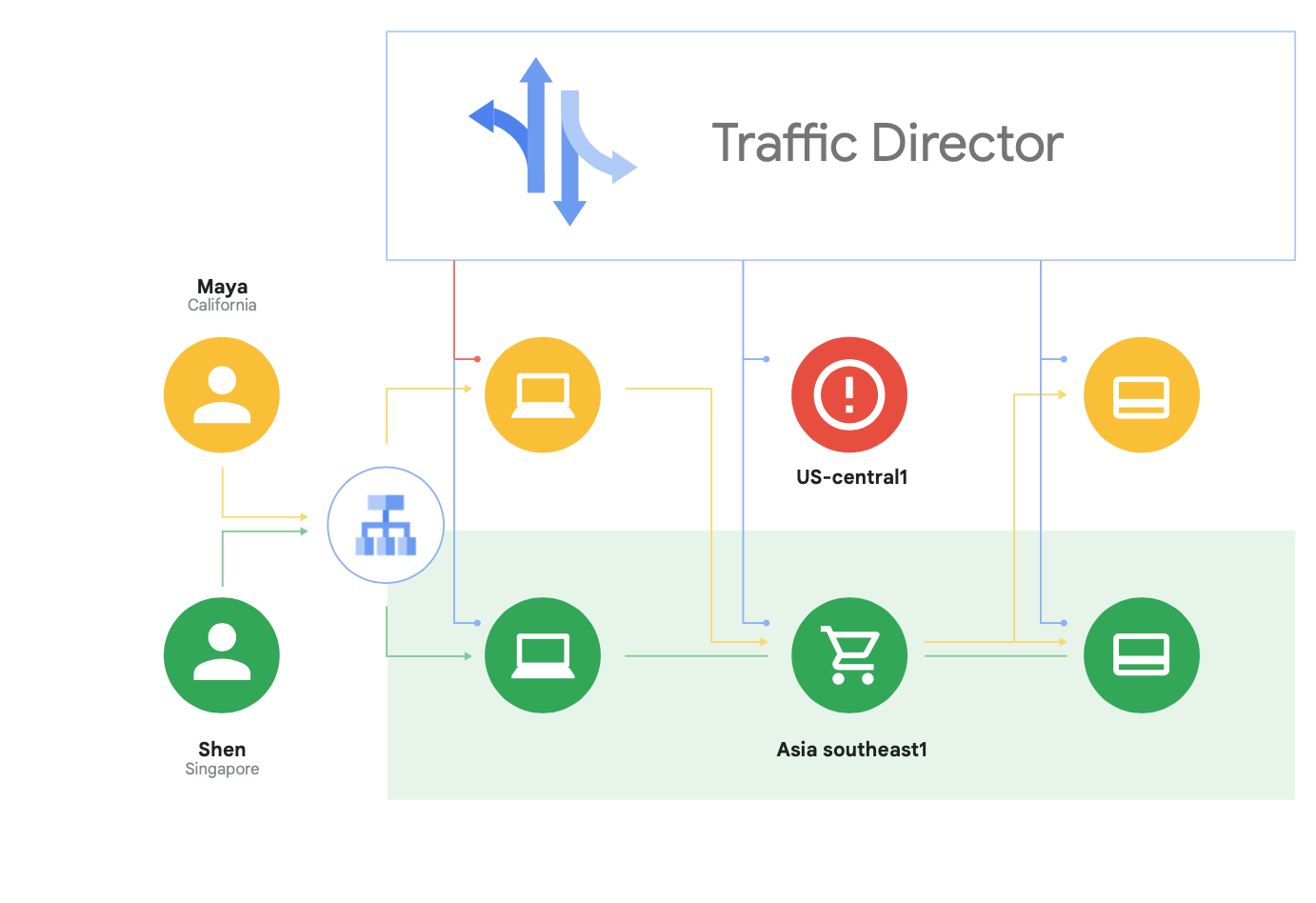
Puoi abbinare la resilienza globale alla sicurezza per i tuoi servizi nel mesh di servizi utilizzando questa funzionalità.
Traffic Director offre diverse funzionalità di gestione del traffico in grado di migliorare la strategia di sicurezza del mesh di servizi. Ad esempio, la funzionalità di mirroring del traffico mostrata nella Figura 9 può essere facilmente configurata come criterio per consentire a un'applicazione shadow di ricevere una copia del traffico reale elaborato dalla versione principale dell'app. Le risposte della copia ricevute dal servizio shadow vengono eliminate dopo l'elaborazione. Il mirroring del traffico può costituire uno strumento potente per verificare la presenza di anomalie di sicurezza ed eseguire il debug degli errori nel traffico di produzione senza alcun impatto o intervento su di esso.
La protezione delle interazioni tra i container, però, non è l'unica nuova sfida di sicurezza che un'applicazione sottoposta a refactoring comporta. Un'altra preoccupazione è quella di assicurare che le immagini dei container che esegui siano affidabili. Per farlo, devi assicurarti che la catena di fornitura del software integri sicurezza e conformità.
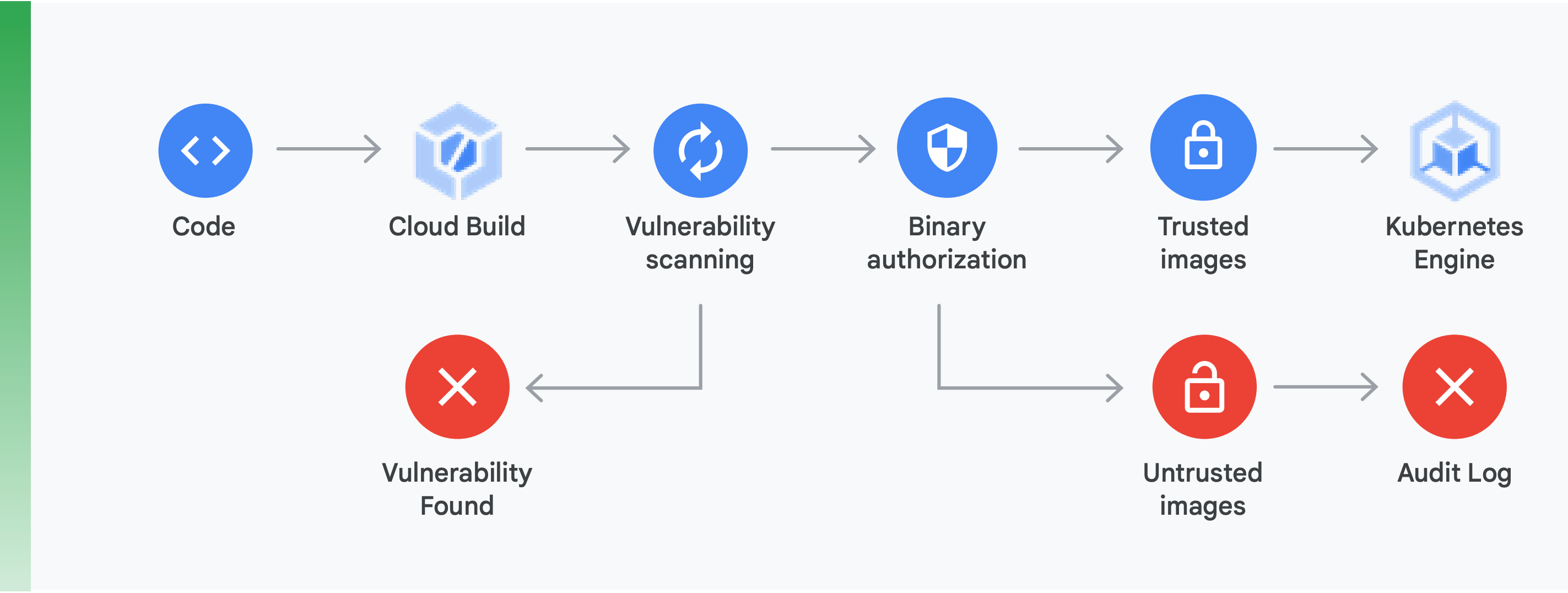
Per fare ciò è necessario effettuare due operazioni principali (mostrate nella Figura 10):
Analisi delle vulnerabilità:l'analisi delle vulnerabilità di Container Registry ti consente di ottenere un rapido feedback su potenziali minacce e identificare i problemi non appena i container vengono creati da Cloud Build e archiviati in Container Registry. Le vulnerabilità dei pacchetti per Ubuntu, Debian e Alpine vengono identificate direttamente durante il processo di sviluppo dell'applicazione e presto saranno supportati anche CentOS e RHEL. Ciò aiuta a evitare le inefficienze in termini di costi e riduce il tempo necessario per porre rimedio alle vulnerabilità note.
Autorizzazione binaria: integrando l'autorizzazione binaria e l'analisi delle vulnerabilità di Container Registry, puoi tenere sotto controllo i deployment in base ai risultati dell'analisi delle vulnerabilità come parte del criterio globale di deployment. L'Autorizzazione binaria è un controllo di sicurezza da utilizzare al momento del deployment che assicura che il deployment delle immagini dei container sia eseguito su GKE senza alcun intervento manuale.
Proteggere l'accesso tra container con un mesh di servizi e garantire la sicurezza della catena di valore del software sono aspetti importanti della creazione di applicazioni basate su container sicure. Ne esistono molti altri, inclusa la verifica della sicurezza dell'infrastruttura della piattaforma cloud su cui esegui la creazione. La cosa più importante, però, è comprendere che passare da un'applicazione monolitica a un moderno paradigma cloud-native introduce nuove sfide relative alla sicurezza. Per effettuare con successo questa transizione, dovrai capire quali sono e quindi creare un piano concreto per affrontare ognuna.
Per iniziare
Non considerare il passaggio a un'architettura cloud-native come uno sconvolgente progetto pluriennale.
Piuttosto, inizia ora trovando un team con la capacità e le competenze di iniziare con una proof of concept, oppure trovane uno che l'ha già fatto. Poi, sfrutta le conoscenze apprese e diffondile all'interno dell'organizzazione. Fai adottare ai team il pattern di Strangler Fig, spostando i servizi in maniera incrementale e iterativa su un'architettura cloud-native, mentre continuano a distribuire nuove funzionalità.
Per avere successo, è fondamentale che i team abbiano la capacità, le risorse e l'autorità per far diventare l'evoluzione dell'architettura dei sistemi parte integrante del loro lavoro quotidiano. Fissa obiettivi architetturali chiari per il nuovo lavoro seguendo i sei risultati architetturali illustrati in precedenza, ma concedi ai team la libertà di decidere come raggiungerli.
Infine, la cosa più importante: inizia subito! Aumentare la produttività e l'agilità dei team e la sicurezza e la stabilità dei servizi sarà sempre più essenziale per il successo della tua organizzazione. I team che lavorano meglio sono quelli che rendono la sperimentazione e il miglioramento disciplinati parte integrante del loro lavoro quotidiano.
Google ha inventato Kubernetes, basato su software che abbiamo utilizzato internamente per anni, per questo possediamo l'esperienza più approfondita con la tecnologia cloud-native.
Google Cloud si concentra in particolare sulle applicazioni containerizzate, come dimostrato dalle nostre offerte di CI/CD e sicurezza. La verità è inequivocabile: Google Cloud è attualmente leader nel supporto di applicazioni containerizzate.
Visita cloud.google.com/devops per svolgere il nostro controllo rapido e scoprire come te la stai cavando e ricevere consigli su come procedere, inclusi i pattern di implementazione illustrati in questo white paper, ad esempio l'architettura a basso accoppiamento.
Molti partner Google Cloud hanno già aiutato organizzazioni come la tua a effettuare questa transizione. Perché affrontare un percorso di riprogettazione dell'architettura in solitario quando possiamo metterti in contatto con una guida esperta?
Per iniziare, contattaci per organizzare una riunione con un solutions architect di Google. Possiamo aiutarti a comprendere il cambiamento e quindi lavorare con te su come realizzarlo.
Per approfondire
https://cloud.google.com/devops: sei anni del report State of DevOps, una serie di articoli con informazioni approfondite sulle funzionalità che prevedono le prestazioni di distribuzione del software e un controllo rapido per aiutarti a capire come te la stai cavando e come migliorare.
Site Reliability Engineering: How Google Runs Production Systems (O'Reilly 2016)
The Site Reliability Workbook: Practical Ways to Implement SRE (O'Reilly 2018)
"How to break a Monolith into Microservices: What to decouple and when" di Zhamak Dehghani
"Microservices: a definition of this new architectural term" di Martin Fowler
"Strangler Fig Application" di Martin Fowler


















