Modifier l'architecture pour une exploitation cloud native
Selon une étude réalisée par DevOps Research and Assessment (DORA), les meilleures équipes DevOps effectuent des déploiements plusieurs fois par jour, apportent des modifications aux environnements de production en moins d'une journée et enregistrent des taux d'échec liés aux modifications de 0 à 15 %.
Ce livre blanc vous explique comment modifier l'architecture de vos applications pour adopter un modèle cloud natif, qui vous permet de livrer de nouvelles fonctionnalités plus rapidement même lorsque vos équipes s'étoffent, tout en améliorant la qualité logicielle et en assurant un meilleur niveau de stabilité et de disponibilité.
Pourquoi adopter une architecture cloud native ?
De nombreuses entreprises créent leurs services logiciels personnalisés à l'aide d'architectures monolithiques. Cette approche présente certains avantages : les systèmes monolithiques sont relativement simples à concevoir et à déployer, dans un premier temps tout au moins. Cependant, il peut devenir difficile de maintenir la productivité des développeurs et la vitesse de déploiement lorsque les applications se complexifient. On se retrouve alors avec des systèmes coûteux, qui prennent du temps lorsqu'il faut les changer et qui présentent des risques en termes de déploiement.
Lorsque les services (et les équipes qui en sont responsables) se développent, ils ont tendance à se complexifier et il devient plus difficile de les faire évoluer et fonctionner. Les tests et le déploiement deviennent plus délicats, l'ajout de fonctionnalités se complique, et il peut être difficile d'assurer la fiabilité et la disponibilité.
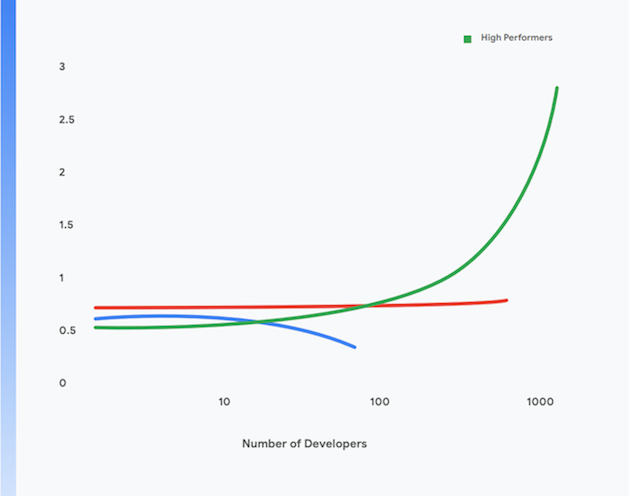
Les recherches de l'équipe DORA de Google ont montré qu'il était possible de livrer des logiciels à une cadence soutenue, ainsi que d'assurer la stabilité et la disponibilité des services dans des entreprises de toutes les tailles et de tous les secteurs. Les équipes performantes sont capables d'effectuer des déploiements plusieurs fois par jour, d'apporter des modifications aux environnements de production en moins d'une journée, de rétablir le service en moins d'une heure en cas de panne et d'enregistrer des taux d'échec des modifications de 0 à 15 %1.
De plus, les équipes les plus performantes affichent une meilleure productivité des développeurs, qui se mesure au nombre de déploiements quotidiens par développeur, même lorsque leur taille augmente. C'est ce qu'illustre la figure 1.
Dans la suite de ce document, nous verrons comment faire migrer vos applications vers un modèle cloud natif pour parvenir à ce résultat. En mettant en œuvre les pratiques techniques présentées dans ce document, vous pourrez atteindre les objectifs suivants :
- Une augmentation de la productivité des développeurs, même lorsque la taille des équipes augmente.
- Un délai de mise sur le marché accéléré : ajoutez des fonctionnalités et réparez les défauts plus rapidement.
- Une meilleure disponibilité : augmentez le temps d'activité de votre logiciel, et réduisez le taux d'échec de vos déploiements et le délai de restauration du service en cas d'incident.
- Une amélioration de la sécurité : réduisez la surface d'attaque de vos applications, et facilitez la détection et la réaction rapide aux attaques et aux nouvelles failles découvertes.
- Une meilleure évolutivité : les plates-formes et applications cloud natives permettent d'effectuer facilement un scaling horizontal lorsque cela est nécessaire, ainsi que d'effectuer un scaling à la baisse.
- Une réduction des coûts : un processus de livraison de logiciels rationalisé fait baisser le coût d'intégration de nouvelles fonctionnalités, et une utilisation efficace des plates-formes cloud réduit considérablement les coûts d'exploitation de vos services.
1 Évaluez les performances de votre équipe à l'aide de ces quatre métriques clés à l'adresse https://cloud.google.com/devops/.
Qu'est-ce qu'une architecture cloud native ?
Les applications monolithiques doivent être créées, testées et déployées comme une seule unité. Souvent, le système d'exploitation, le middleware et la pile de langages de l'application sont personnalisés ou configurés sur mesure pour chaque application. Par ailleurs, les scripts et processus de compilation, de test et de déploiement sont généralement spécifiques à chaque application. Cette façon de procéder est simple et efficace pour les toutes nouvelles applications, mais plus elles se développent, plus il devient difficile de modifier, de tester, de déployer et de faire fonctionner de tels systèmes.
De plus, lorsque ces systèmes se développent, la taille et la complexité des équipes qui compilent, testent, déploient et font fonctionner le service augmentent elles aussi. Une approche courante, mais erronée, consiste à diviser les équipes par fonction. Cela entraîne des transferts entre les équipes qui ont tendance à rallonger les délais de livraison et à augmenter la taille des lots, et entraînent à leur tour de nombreuses tâches de retraitement. Les recherches de DORA montrent que les équipes performantes sont deux fois plus à même de développer et livrer un logiciel si elles travaillent dans une équipe pluridisciplinaire unique.
Ce problème se manifeste par :
- des processus de compilation longs et souvent défectueux ;
- des cycles d'intégration et de tests rares ;
- des efforts supplémentaires nécessaires pour assurer les processus de compilation et de test ;
- une baisse de la productivité des développeurs ;
- des processus de déploiement délicats qui doivent intervenir en dehors des heures de travail et nécessitent des temps d'arrêt programmés ;
- des efforts considérables pour gérer la configuration des environnements de test et de production.
Dans un modèle cloud natif, en revanche³ :
- Les systèmes complexes sont décomposés en services qui peuvent être testés et déployés de façon indépendante dans un environnement d'exécution conteneurisé (architecture de microservices ou orientée services).
- Les applications utilisent les services standards fournis par la plate-forme, tels que les systèmes de gestion de bases de données, le stockage de blobs, la messagerie, le CDN et la terminaison SSL.
- Une plate-forme cloud standardisée prend en charge de nombreuses problématiques opérationnelles, comme le déploiement, l'autoscaling, la configuration, la gestion des secrets, la surveillance et les alertes. Les équipes de développement d'applications peuvent accéder à la demande à ces services.
- Le système d'exploitation, le middleware et les piles propres aux langages de programmation sont standardisés et fournis aux développeurs d'applications. La maintenance de ces piles, ainsi que la fourniture de correctifs, sont assurées hors bande soit par le fournisseur de la plate-forme, soit par une équipe distincte.
- Une équipe pluridisciplinaire unique peut être chargée de l'ensemble du cycle de livraison des logiciels pour chaque service.
3 Ceci n'est pas une description complète de la signification de "cloud natif". Pour en savoir plus sur les principes de l'architecture cloud native, voir https://cloud.google.com/blog/products/ application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it.
Ce modèle procure de nombreux avantages :
Une livraison accélérée | Des versions fiables | Réduction des coûts |
les services étant plus petits et faiblement couplés, les équipes qui leur sont associées peuvent travailler de façon autonome. De ce fait, la productivité des développeurs augmente et le développement s'accélère. | les développeurs peuvent compiler, tester et déployer rapidement de nouveaux services, ainsi que des services existants, dans des environnements de test semblables à ceux de production. Par ailleurs, le déploiement en production est simple et demande peu de travail. Cela accélère considérablement le processus de livraison de logiciels et diminue les risques liés aux déploiements. | Le coût et la complexité des environnements de test et de production diminuent fortement, car les services partagés et standardisés sont fournis par la plate-forme et les applications s'exécutent sur une infrastructure physique partagée. |
Une sécurité renforcée | Disponibilité élevée | Une mise en conformité plus simple et moins chère |
il revient désormais aux fournisseurs d'assurer la mise à jour et la conformité des services partagés, tels que les systèmes de gestion de bases de données et l'infrastructure de messagerie, ainsi que d'appliquer les correctifs. Il est également beaucoup plus simple de mettre à jour les applications et de les corriger, puisqu'il existe une méthode standard pour déployer et gérer les applications. | la disponibilité et la fiabilité des applications augmentent, puisque l'environnement opérationnel est moins complexe, que la configuration peut être modifiée facilement, et que l'autoscaling et l'autoréparation peuvent être gérés au niveau de la plate-forme. | la plupart des contrôles de sécurité des informations peuvent être implémentés au niveau de la plate-forme. Il est donc beaucoup moins cher et plus facile de rendre les applications conformes et de le démontrer. De nombreux fournisseurs cloud assurent la conformité à l'aide de frameworks de gestion des risques tels que SOC2 et FedRAMP. Par conséquent, les applications déployées sur leur plate-forme doivent seulement démontrer qu'elles sont conformes aux contrôles qui ne sont pas déjà intégrés à la plate-forme. |
Une livraison accélérée
Des versions fiables
Réduction des coûts
les services étant plus petits et faiblement couplés, les équipes qui leur sont associées peuvent travailler de façon autonome. De ce fait, la productivité des développeurs augmente et le développement s'accélère.
les développeurs peuvent compiler, tester et déployer rapidement de nouveaux services, ainsi que des services existants, dans des environnements de test semblables à ceux de production. Par ailleurs, le déploiement en production est simple et demande peu de travail. Cela accélère considérablement le processus de livraison de logiciels et diminue les risques liés aux déploiements.
Le coût et la complexité des environnements de test et de production diminuent fortement, car les services partagés et standardisés sont fournis par la plate-forme et les applications s'exécutent sur une infrastructure physique partagée.
Une sécurité renforcée
Disponibilité élevée
Une mise en conformité plus simple et moins chère
il revient désormais aux fournisseurs d'assurer la mise à jour et la conformité des services partagés, tels que les systèmes de gestion de bases de données et l'infrastructure de messagerie, ainsi que d'appliquer les correctifs. Il est également beaucoup plus simple de mettre à jour les applications et de les corriger, puisqu'il existe une méthode standard pour déployer et gérer les applications.
la disponibilité et la fiabilité des applications augmentent, puisque l'environnement opérationnel est moins complexe, que la configuration peut être modifiée facilement, et que l'autoscaling et l'autoréparation peuvent être gérés au niveau de la plate-forme.
la plupart des contrôles de sécurité des informations peuvent être implémentés au niveau de la plate-forme. Il est donc beaucoup moins cher et plus facile de rendre les applications conformes et de le démontrer. De nombreux fournisseurs cloud assurent la conformité à l'aide de frameworks de gestion des risques tels que SOC2 et FedRAMP. Par conséquent, les applications déployées sur leur plate-forme doivent seulement démontrer qu'elles sont conformes aux contrôles qui ne sont pas déjà intégrés à la plate-forme.
Cependant, le modèle cloud natif implique certains compromis :
- Toutes les applications deviennent des systèmes distribués. Elles effectuent donc un grand nombre d'appels distants pour fonctionner. En conséquence, il faut bien réfléchir à la façon de gérer les défaillances du réseau et les problèmes de performances, ainsi qu'aux moyens de résoudre les problèmes en production.
- Les développeurs sont contraints d'utiliser le système d'exploitation, le middleware et les piles d'applications standardisés fournis par la plate-forme. Cela complique le développement local.
- Les architectes doivent adopter une approche de la conception de systèmes basée sur des événements, ainsi que la cohérence à terme.
Migrer vers une architecture cloud native
Pour migrer des services vers le cloud, de nombreuses organisations ont opté pour l'approche "Lift and Shift". Dans cette approche, il ne faut apporter que des modifications mineures aux systèmes et le cloud est traité comme un centre de données traditionnel, bien qu'il fournisse de bien meilleurs services, API et outils de gestion. Cependant, la migration Lift and Shift en elle-même ne procure aucun des avantages du modèle cloud natif décrit ci-dessus.
Bon nombre d'organisations s'en tiennent à la migration Lift and Shift, car faire migrer leurs applications vers une architecture cloud native est un processus coûteux et complexe, qui nécessite de tout repenser : l'architecture des applications, les opérations de production et bien sûr l'ensemble du cycle de livraison des logiciels. Cette crainte est tout à fait rationnelle : beaucoup de grandes entreprises ont souffert d'avoir tenté sans succès pendant plusieurs années de modifier radicalement leur plate-forme.
La solution est d'adopter une approche incrémentielle, itérative et évolutive lorsque l'on souhaite adopter une architecture cloud native pour ses systèmes. Les équipes peuvent ainsi apprendre à travailler efficacement dans ce nouveau modèle tout en continuant à fournir de nouvelles fonctionnalités. Nous appelons cette approche "Move and Improve" (migration et amélioration).
Un modèle clé de l'architecture évolutive est connu sous le nom d'application de type "figuier étrangleur"4. Au lieu de réécrire complètement les systèmes, écrivez de nouvelles fonctionnalités dans un style cloud natif moderne, mais faites en sorte qu'elles communiquent avec l'application monolithique d'origine pour les fonctionnalités existantes. Migrez graduellement les fonctionnalités existantes de façon à préserver l'intégrité conceptuelle des nouveaux services, comme l'illustre la figure 2.
4 Ce modèle est décrit à l'adresse https://martinfowler.com/bliki/StranglerFigApplication.html.
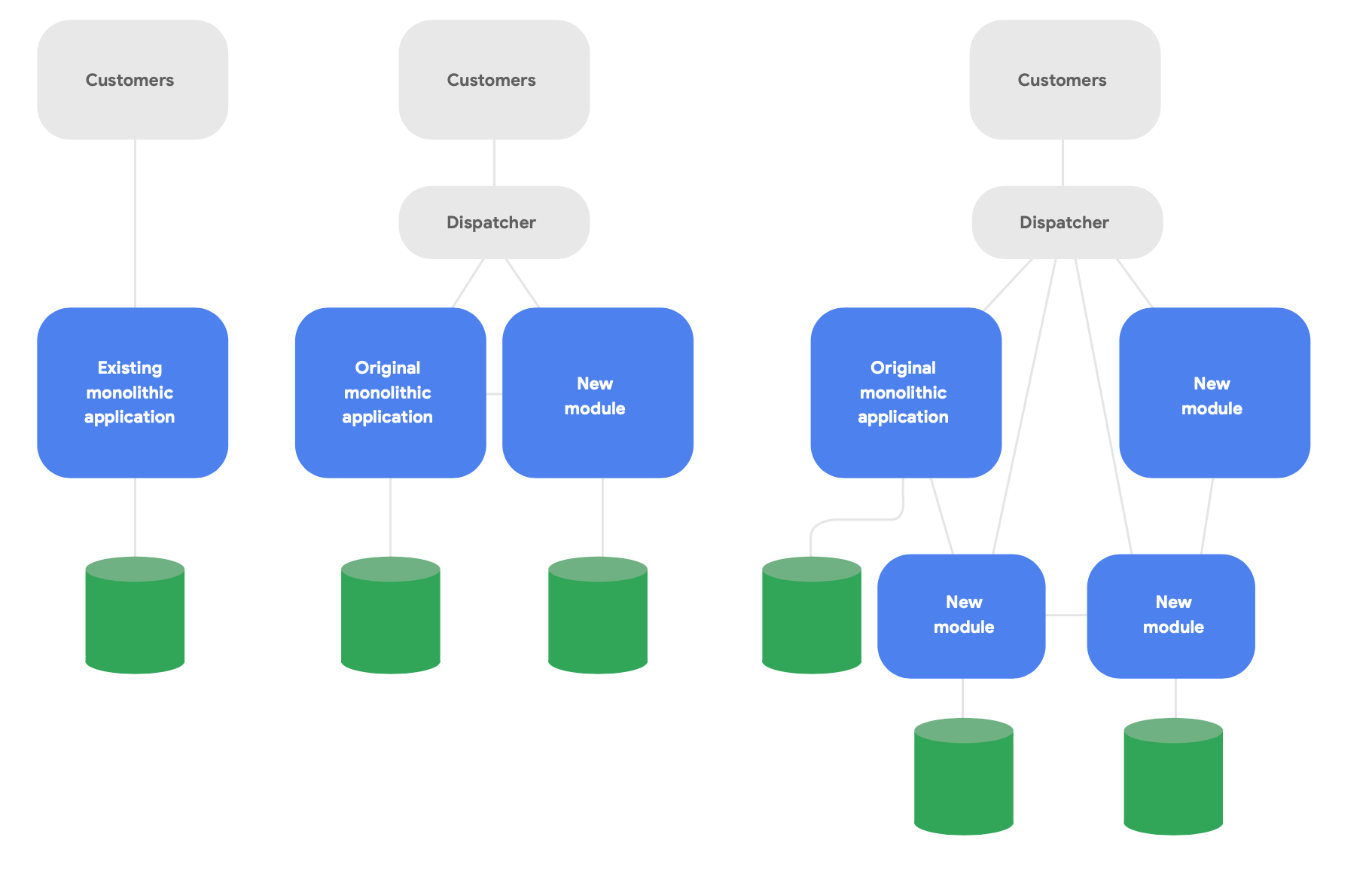
Voici trois consignes importantes pour réussir la modification de votre architecture :
Tout d'abord, commencez par proposer rapidement de nouvelles fonctionnalités plutôt que de reproduire les fonctionnalités existantes. La métrique clé est la vitesse à laquelle vous pouvez proposer de nouvelles fonctionnalités à l'aide des nouveaux services. Vous devez vous familiariser rapidement avec le travail dans ce modèle et pouvoir communiquer les bonnes pratiques que vous en tirez. Réduisez radicalement votre objectif : vous devez proposer quelque chose à vos utilisateurs réels en quelques semaines, et non en quelques mois.
Ensuite, concevez votre architecture pour une exploitation cloud native. Utilisez les services natifs de la plate-forme cloud pour les systèmes de gestion de bases de données, la messagerie, le CDN, la mise en réseau, le stockage de blobs, etc., et utilisez les piles d'applications standardisées fournies par la plate-forme autant que possible. Les services doivent être conteneurisés et exploiter au maximum le modèle sans serveur. Le processus de compilation, de test et de déploiement doit être entièrement automatisé. Faites en sorte que toutes les applications utilisent les services partagés fournis par la plate-forme pour la journalisation, la surveillance et les alertes. (Il est intéressant de noter que ce genre d'architecture de plate-forme peut être avantageusement déployé pour n'importe quelle plate-forme d'applications mutualisée, y compris dans un environnement Bare Metal sur site.) La figure 3 ci-dessous donne une vue d'ensemble d'une plate-forme cloud native.
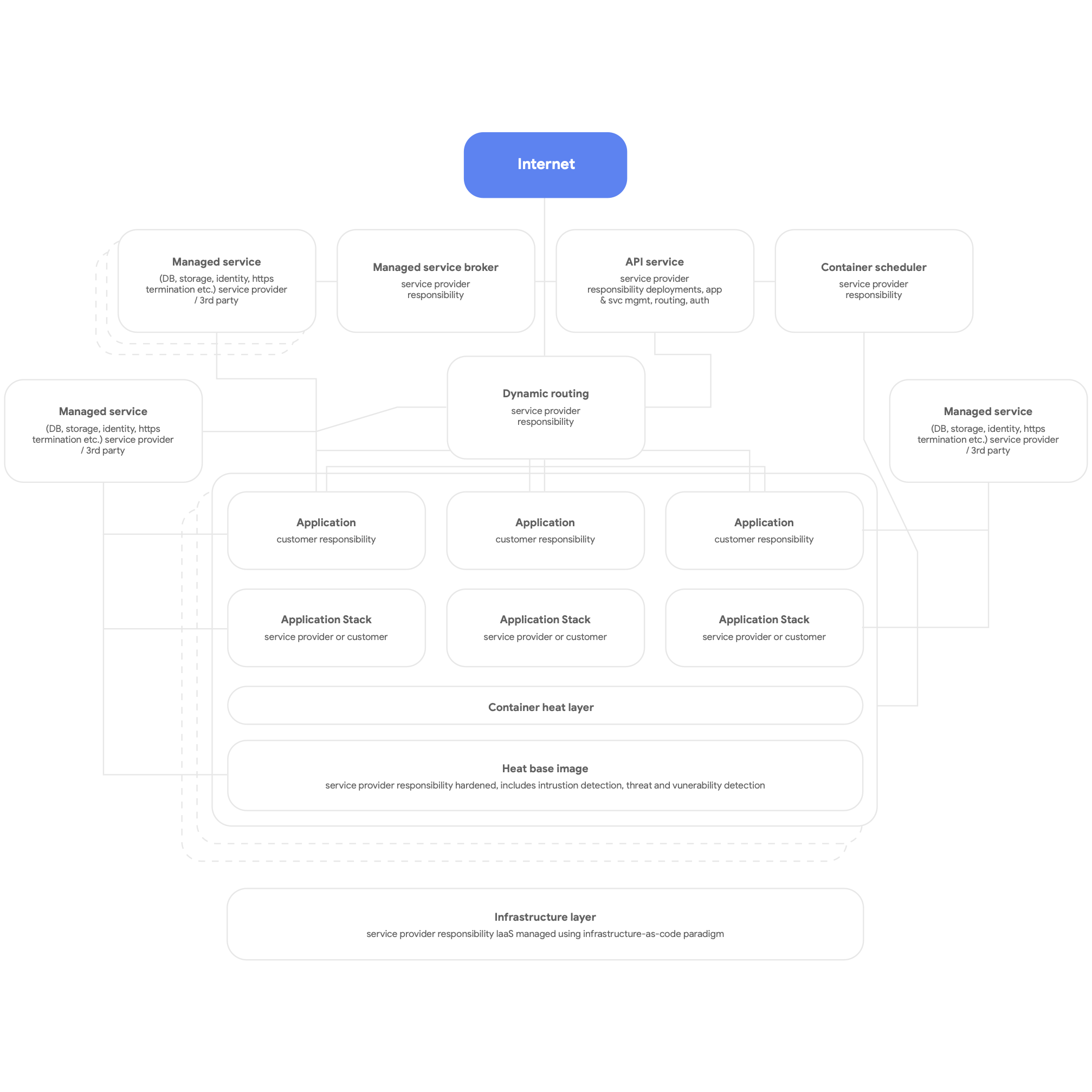
Enfin, concevez votre architecture pour des équipes autonomes et faiblement couplées qui peuvent tester et déployer leurs propres services. Nos recherches montrent que le plus important pour bien modifier son architecture est que les équipes de livraison de logiciels puissent approuver ces six affirmations :
- Nous pouvons modifier à grande échelle la conception de notre système sans demander l'autorisation d'une personne extérieure à l'équipe.
- Nous pouvons modifier à grande échelle la conception de notre système sans dépendre de modifications apportées par d'autres équipes à leurs systèmes ni accroître la charge de travail d'autres équipes.
- Nous pouvons faire notre travail sans avoir besoin de communiquer ni de nous coordonner avec des personnes extérieures à l'équipe.
- Nous pouvons déployer et lancer un produit ou un service à la demande, quels que soient les autres services dont il dépend.
- Nous pouvons effectuer la plupart de nos tests à la demande, sans avoir besoin d'un environnement de test intégré.
- Nous pouvons effectuer des déploiements pendant les heures de travail normales avec un temps d'arrêt négligeable.
Vérifiez régulièrement que les équipes s'attachent à atteindre ces objectifs et leur donnent la priorité. Cela implique généralement de repenser son architecture organisationnelle et d'entreprise.
En particulier, il est crucial d'organiser les équipes de façon que les différents rôles nécessaires pour compiler, tester et déployer le logiciel, y compris les responsables produit, collaborent et utilisent des pratiques de gestion de produits modernes pour concevoir et faire évoluer les services sur lesquels ils travaillent. La structure organisationnelle n'a pas nécessairement besoin d'être modifiée. Le simple fait de faire travailler ces différentes personnes en équipe au quotidien (et de leur faire partager un même espace physique lorsque c'est possible), plutôt que de faire travailler indépendamment les développeurs, les testeurs et les équipes de lancement, peut avoir un impact de taille sur la productivité.
D'après nos recherches, les équipes qui répondent "oui" à ces questions sont très souvent performantes : elles peuvent fournir des services logiciels fiables et à la disponibilité élevée, plusieurs fois par jour. Cela leur permet en retour d'améliorer la productivité des développeurs (mesurée en déploiements quotidiens par développeur) même lorsque le nombre d'équipes augmente.
Principes et pratiques
Principes et pratiques d'une architecture de microservices
Lorsque vous adoptez une architecture de microservices ou orientée services, il est important de suivre des pratiques et des principes essentiels. Mieux vaut les suivre de manière très stricte dès le départ, car il coûte plus cher de les adapter par la suite.
- Chaque service doit avoir son propre schéma de base de données. Que vous utilisiez une base de données relationnelle ou une solution NoSQL, chaque service doit disposer de son propre schéma auquel les autres services n'ont pas accès. Lorsque plusieurs services communiquent avec le même schéma, un couplage fort des services finit par se mettre en place au niveau de la base de données. Ces dépendances empêchent de tester et de déployer indépendamment les services. Il est donc plus difficile de les modifier et plus risqué de les déployer.
- Les services doivent uniquement communiquer via leurs API publiques sur le réseau. Tous les services doivent divulguer leur comportement via des API publiques, et ne communiquer entre eux que via ces API. Il ne doit pas exister de moyen d'accès "détourné" ni de services qui communiquent directement avec les bases de données d'autres services. Cela permet d'éviter un couplage fort des services, et garantit que la communication entre les services utilise des API bien documentées et compatibles.
- Les services sont responsables de la rétrocompatibilité pour leurs clients. L'équipe qui crée et fait fonctionner un service est chargée de s'assurer que les mises à jour n'ont pas d'impact sur les utilisateurs. Il est donc nécessaire de planifier la gestion des versions et les tests de rétrocompatibilité de l'API, de sorte que le lancement de nouvelles versions n'entraîne pas de dysfonctionnements pour les clients existants. Les équipes peuvent déployer une version Canary pour valider ce point. Cela implique également de s'assurer que les déploiements n'occasionnent pas de temps d'arrêt, à l'aide de techniques comme les déploiements bleu-vert ou les déploiements par étapes.
- Créez une méthode standard pour exécuter les services sur les stations de travail de développement. Les développeurs doivent pouvoir mettre en place n'importe quel sous-ensemble de services de production sur des stations de travail de développement à la demande, à l'aide d'une seule commande. Il doit également être possible d'exécuter une version "bouchon" des services à la demande. Veillez à bien utiliser les versions d'émulation des services cloud que de nombreux fournisseurs cloud mettent à votre disposition. L'objectif est de permettre aux développeurs de tester et de déboguer facilement les services localement.
- Investissez dans la surveillance et l'observabilité de la production. De nombreux problèmes rencontrés au niveau de la production, comme ceux de performance, sont dus à des interactions entre plusieurs services. Nos recherches montrent qu'il est important de mettre en place une solution qui rende compte de l'état général des systèmes (par exemple, mes systèmes fonctionnent-ils ? Disposent-ils de suffisamment de ressources ?). Il est par ailleurs essentiel que les équipes aient accès à des outils et des données leur permettant de suivre, de comprendre et de diagnostiquer les problèmes d'infrastructure dans les environnements de production, tels que les interactions entre les services.
- Fixez des objectifs de niveau de service (SLO) pour vos services et effectuez régulièrement des tests de reprise après sinistre. Le fait de définir des SLO pour vos services permet de préciser les performances attendues et de planifier le comportement que doit avoir le système en cas de panne d'un service (un point à ne pas négliger lors de la création de systèmes distribués résilients). Testez le comportement réel de votre système de production avec des techniques comme l'injection de défaillances contrôlées dans votre plan de tests de reprise après sinistre. D'après les recherches menées par DORA, les organisations qui testent la reprise après sinistre à l'aide de ce genre de méthodes peuvent assurer une meilleure disponibilité de leurs services. Plus vous mettez en place ces tests tôt, mieux c'est. Vous pourrez ainsi normaliser cette activité vitale.
Cela fait beaucoup de points à prendre en compte. C'est pourquoi il est important de tester ce type de tâche avec une équipe qui a la capacité et les compétences nécessaires pour évaluer l'implémentation de ces idées. Il y aura des victoires et des échecs. L'essentiel est de tirer des leçons du travail de ces équipes et de les exploiter pour étendre ce nouveau modèle d'architecture à toute votre organisation.
Selon nos recherches, les entreprises qui réussissent font des démonstrations de faisabilité et donnent à leurs équipes l'occasion de partager leurs découvertes, en créant par exemple des groupes de pratique. Donnez aux membres de plusieurs équipes le temps, un lieu et les ressources pour se réunir régulièrement et échanger des idées. Tous vos collaborateurs devront également acquérir de nouvelles compétences et se former à de nouvelles technologies. Investissez dans la formation de vos employés. Accordez-leur un budget pour acheter des livres, suivre des formations ou assister à des conférences. Fournissez l'infrastructure et donnez le temps à vos employés de diffuser le savoir institutionnel et les bonnes pratiques via des listes de diffusion au sein de l'entreprise, des bases de connaissances et des rencontres en personne.
Architecture de référence
Dans cette section, nous décrirons une architecture de référence répondant aux consignes suivantes :
- Utiliser des conteneurs pour les services de production et un planificateur de conteneurs comme Cloud Run ou Kubernetes pour l'orchestration
- Créer des pipelines CI/CD efficaces
- Mettre l'accent sur la sécurité
Conteneuriser les services de production
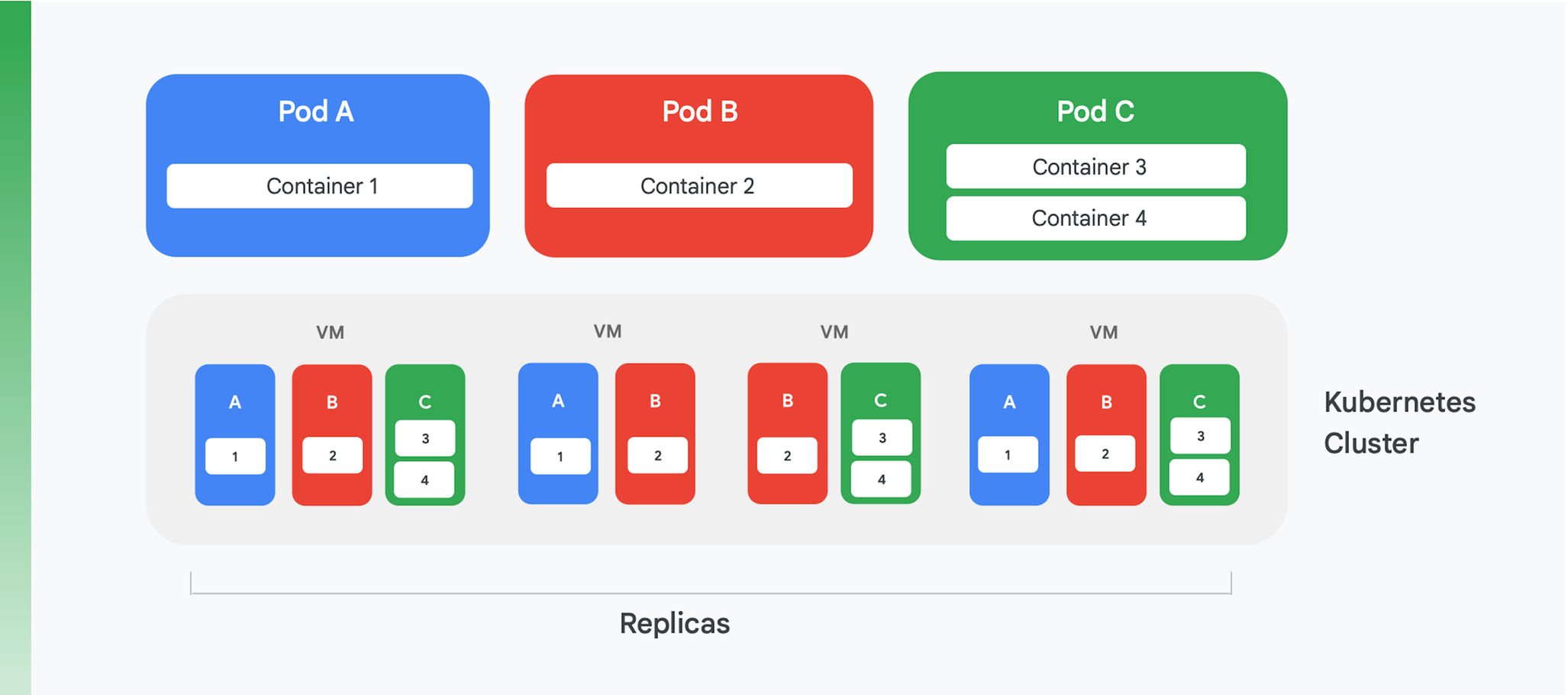
Une application cloud conteneurisée se base sur un service de gestion et d'orchestration de conteneurs. De nombreux services existent, mais un seul se démarque franchement à l'heure actuelle : Kubernetes. Kubernetes constitue désormais la norme en matière d'orchestration de conteneurs dans le secteur. Il accueille une communauté dynamique et s'appuie sur un large éventail de fournisseurs commerciaux de premier plan. La figure 4 schématise la structure logique d'un cluster Kubernetes.
Dans Kubernetes, un pod est une abstraction. Un pod ne contient souvent qu'un seul conteneur, comme les pods A et B de la figure 4, bien qu'il puisse en contenir plusieurs, comme le pod C. Chaque service Kubernetes exécute un cluster contenant un certain nombre de nœuds, qui sont typiquement des machines virtuelles (VM). Seules quatre VM sont représentées sur la figure 4, mais un véritable cluster peut facilement en contenir une centaine ou plus. Quand un pod est déployé sur un cluster Kubernetes, le service détermine sur quelles VM les conteneurs de ce pod doivent s'exécuter. Les conteneurs précisant les ressources dont ils ont besoin, Kubernetes peut attribuer les pods à telle ou telle VM de façon intelligente.
Une partie des informations sur le déploiement d'un pod indique le nombre d'instances dupliquées du pod qui doivent s'exécuter. Le service Kubernetes crée ensuite le nombre d'instances des conteneurs du pod nécessaire et les attribue à des VM. Dans la figure 4, par exemple, le déploiement du pod A nécessitait trois instances dupliquées, tout comme celui du pod C. Pour le déploiement du pod B, en revanche, quatre instances dupliquées étaient nécessaires. Le cluster de l'exemple contient donc quatre instances en cours d'exécution du conteneur 2. Par ailleurs, comme le suggère notre figure, les conteneurs d'un pod contenant plusieurs conteneurs, comme le pod C, seront toujours attribués au même nœud.
Kubernetes offre également d'autres services :
- La surveillance des pods en cours d'exécution pour que le service démarre une nouvelle instance en cas de défaillance d'un conteneur. Cela garantit la disponibilité de toutes les instances dupliquées que nécessite le déploiement d'un pod.
- L'équilibrage de charge du trafic afin de répartir les requêtes adressées à chaque pod de façon intelligente entre les instances répliquées d'un conteneur.
- Le déploiement automatisé des nouveaux conteneurs sans temps d'arrêt, les nouvelles instances remplaçant graduellement les anciennes jusqu'à ce que la nouvelle version soit complètement déployée.
- Le scaling automatisé, un cluster ajoutant ou supprimant des VM de façon autonome en fonction de la demande.
Créer des pipelines CI/CD efficaces
Certains des avantages que procure la refactorisation d'une application monolithique, tels que la réduction des coûts, découlent directement de l'exécution sur Kubernetes. Cependant, l'un des principaux avantages, à savoir la possibilité de mettre à jour votre application plus souvent, n'est possible que si vous modifiez votre façon de créer et de lancer des logiciels. Pour bénéficier de cet avantage, vous devez créer des pipelines CI/CD efficaces dans votre organisation.
L'intégration continue dépend de workflows de compilation et de test automatisés qui fournissent des retours rapides aux développeurs. Elle nécessite que tous les membres d'une équipe travaillent sur le même code (par exemple, le code d'un service unique) afin que leur travail soit régulièrement intégré dans une branche principale ou une jonction partagées. Cette intégration doit se faire au moins une fois par jour pour chaque développeur, chaque intégration étant validée par un processus de compilation comprenant des tests automatisés. La livraison continue a pour objectif de déployer rapidement ce code intégré à moindre risque, principalement en automatisant le processus de compilation, de test et de déploiement. Ainsi, des activités telles que l'évaluation des performances, le contrôle de la sécurité et les tests exploratoires peuvent se faire en continu. En d'autres termes, la CI permet aux développeurs de détecter rapidement les problèmes d'intégration, tandis que la CD fait du déploiement un processus fiable et routinier.
Pour que tout soit bien clair, prenons un exemple concret. La figure 5 montre à quoi peut ressembler un pipeline CI/CD qui utilise des outils Google pour des conteneurs s'exécutant sur Google Kubernetes Engine.
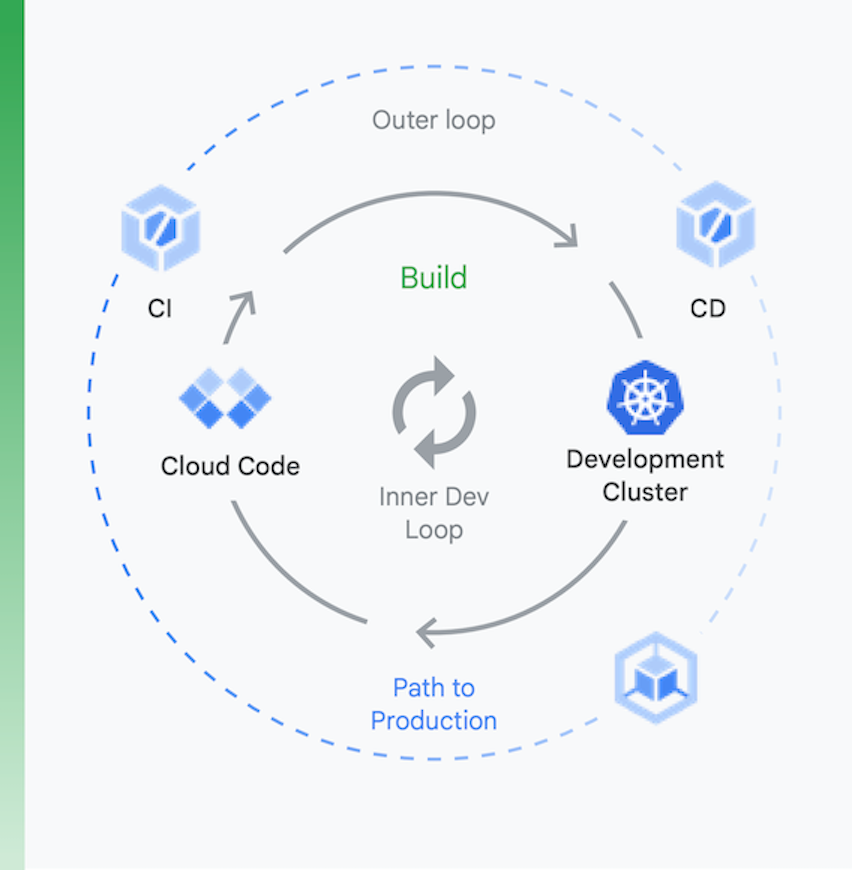
Il est utile d'envisager ce processus en deux parties, comme sur la figure 6 :
Développement local | Développement à distance |
ici, l'objectif est d'accélérer la boucle de développement interne et de fournir aux développeurs des outils leur permettant de recevoir rapidement des retours concernant l'impact de modifications locales de code (par exemple, avec une assistance pour le linting, la saisie semi-automatique pour le YAML et des compilations locales plus rapides). | Lorsqu'une demande d'extraction est envoyée, la boucle de développement à distance est lancée. L'objectif ici est de réduire drastiquement le temps nécessaire pour valider et tester la demande d'extraction via l'intégration continue, et de réaliser d'autres activités comme l'analyse des failles et la signature binaire, tout en pilotant l'approbation des versions de façon automatisée. |
Développement local
Développement à distance
ici, l'objectif est d'accélérer la boucle de développement interne et de fournir aux développeurs des outils leur permettant de recevoir rapidement des retours concernant l'impact de modifications locales de code (par exemple, avec une assistance pour le linting, la saisie semi-automatique pour le YAML et des compilations locales plus rapides).
Lorsqu'une demande d'extraction est envoyée, la boucle de développement à distance est lancée. L'objectif ici est de réduire drastiquement le temps nécessaire pour valider et tester la demande d'extraction via l'intégration continue, et de réaliser d'autres activités comme l'analyse des failles et la signature binaire, tout en pilotant l'approbation des versions de façon automatisée.
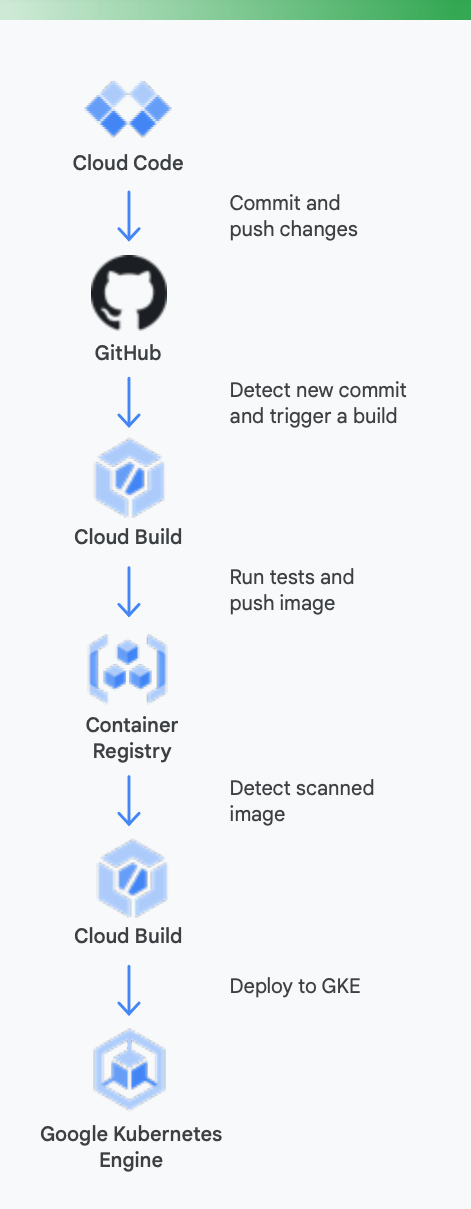
Voici comment les outils Google Cloud peuvent vous aider pendant ce processus
Développement local : il est essentiel que les développeurs soient productifs dans le développement d'applications locales. Ce développement local implique de créer des applications pouvant être déployées sur des clusters locaux et distants. Avant de valider les modifications dans un système de gestion du contrôle des sources comme GitHub, disposer d'une boucle de développement local rapide donne aux développeurs la possibilité de tester et de déployer leurs modifications sur un cluster local.
C'est pourquoi Google Cloud propose Cloud Code. Cloud Code intègre des extensions pour les IDE, comme Visual Studio Code et Intellij, afin de permettre aux développeurs d'itérer, de déboguer et d'exécuter rapidement du code sur Kubernetes. En coulisses, Cloud Code utilise des outils populaires tels que Skaffold, Jib et Kubectl pour offrir aux développeurs un retour continu et en temps réel sur leur code.
Intégration continue : grâce à la nouvelle application GitHub Cloud Build, les équipes peuvent déclencher des compilations pour différents événements du dépôt (événements de demande d'extraction, de branche ou de tag) directement sur GitHub. Cloud Build est une plate-forme entièrement sans serveur qui effectue des scalings à la hausse ou à la baisse en fonction de la charge, sans qu'il soit nécessaire de préprovisionner les serveurs ou de payer à l'avance pour une capacité supplémentaire. Les compilations déclenchées via l'application GitHub publient automatiquement leur état sur GitHub. Les retours sont directement intégrés dans le workflow du développeur sur GitHub, ce qui lui évite de changer de contexte.
Gestion des artefacts : avec Container Registry, votre équipe dispose d'un outil centralisé qui lui permet de gérer les images Docker, d'analyser les failles et de définir avec une grande précision les droits d'accès de chaque utilisateur. L'intégration de l'analyse des failles dans Cloud Build permet aux développeurs d'identifier les menaces pour la sécurité dès que Cloud Build crée une image et la stocke dans Container Registry.
Livraison continue : Cloud Build utilise des étapes de compilation, ce qui vous permet de définir les étapes spécifiques à suivre pour la compilation, le test et le déploiement. Par exemple, une fois qu'un conteneur a été créé et transféré vers Container Registry, une étape de compilation ultérieure peut le déployer sur Google Kubernetes Engine (GKE) ou sur Cloud Run avec la configuration et la règle associées. Vous pouvez également le déployer sur les plates-formes d'autres fournisseurs cloud si vous avez adopté une stratégie multicloud. Enfin, si vous avez un objectif de livraison continue de type GitOps, Cloud Build vous permet de décrire vos déploiements de manière déclarative à l'aide de fichiers (par exemple, des fichiers manifestes Kubernetes) stockés dans un dépôt Git.
Cependant, une fois le code déployé, le travail n'est pas terminé. Les organisations doivent également gérer ce code pendant qu'il s'exécute. Pour cela, Google Cloud met à la disposition des équipes en charge des opérations des outils comme Cloud Monitoring et Cloud Logging.
Il n'est pas indispensable d'employer les outils CI/CD de Google avec GKE. Vous pouvez utiliser d'autres chaînes d'outils si vous le souhaitez. Vous pouvez par exemple exploiter Jenkins pour la CI/CD ou Artifactory pour la gestion des artefacts.
Votre système CI/CD actuel n'est sans doute pas parfaitement rodé, comme dans beaucoup d'organisations ayant des applications cloud basées sur des VM. Il est essentiel de mettre en place ce genre de système si vous souhaitez profiter des avantages de la nouvelle architecture de votre application, mais cela demande du travail. Les technologies dont vous avez besoin pour créer vos pipelines existent, en partie grâce à la maturité de Kubernetes. Néanmoins, les changements nécessaires sur le plan humain peuvent être considérables. Le personnel de vos équipes de livraison doit acquérir des compétences transversales en développement, en test et en exploitation du nouveau système. Transformer sa culture prend du temps. Vous devez donc être prêt à vous investir pour faire évoluer les connaissances et les comportements de vos employés lorsque vous passez à la CI/CD.
Mettre l'accent sur la sécurité
Modifier l'architecture de ses applications monolithiques pour passer au modèle cloud natif est un changement conséquent. Sans surprise, cela soulève de nouveaux problèmes de sécurité auxquels vous devrez faire face. Deux des problèmes les plus importants sont :
- de sécuriser l'accès entre les conteneurs ;
- de garantir une chaîne d'approvisionnement logicielle sécurisée.
Le premier point découle d'une évidence : si vous divisez votre application en services conteneurisés (voire en microservices), ces services doivent avoir un moyen de communiquer. Et même s'ils s'exécutent potentiellement sur le même cluster Kubernetes, vous devez tout de même vous soucier de contrôler l'accès entre eux. En effet, vous partagez peut-être ce cluster Kubernetes avec d'autres applications, qui ne doivent pas avoir accès à vos conteneurs.
Pour contrôler l'accès à un conteneur, il faut authentifier les conteneurs qui l'appellent, puis déterminer les 17 requêtes qu'ils sont autorisés à lui envoyer. Aujourd'hui, on utilise classiquement un maillage de services pour résoudre ce problème (et plusieurs autres), le principal étant Istio, un projet Open Source conçu par Google et IBM, entre autres. La figure 7 illustre la façon dont Istio s'intègre à un cluster Kubernetes.
Comme nous pouvons le voir sur la figure, le proxy Istio intercepte tout le trafic entre les conteneurs de votre application. Le maillage de services peut ainsi offrir plusieurs services utiles sans que votre code d'application soit modifié. Parmi ces services, nous pouvons citer :
- la sécurité, avec à la fois l'authentification de service à service utilisant le protocole TLS et l'authentification de l'utilisateur final ;
- la gestion du trafic, qui vous permet de contrôler le routage des requêtes entre les conteneurs de votre application ;
- l'observabilité, avec l'enregistrement des journaux et métriques de communication entre vos conteneurs.
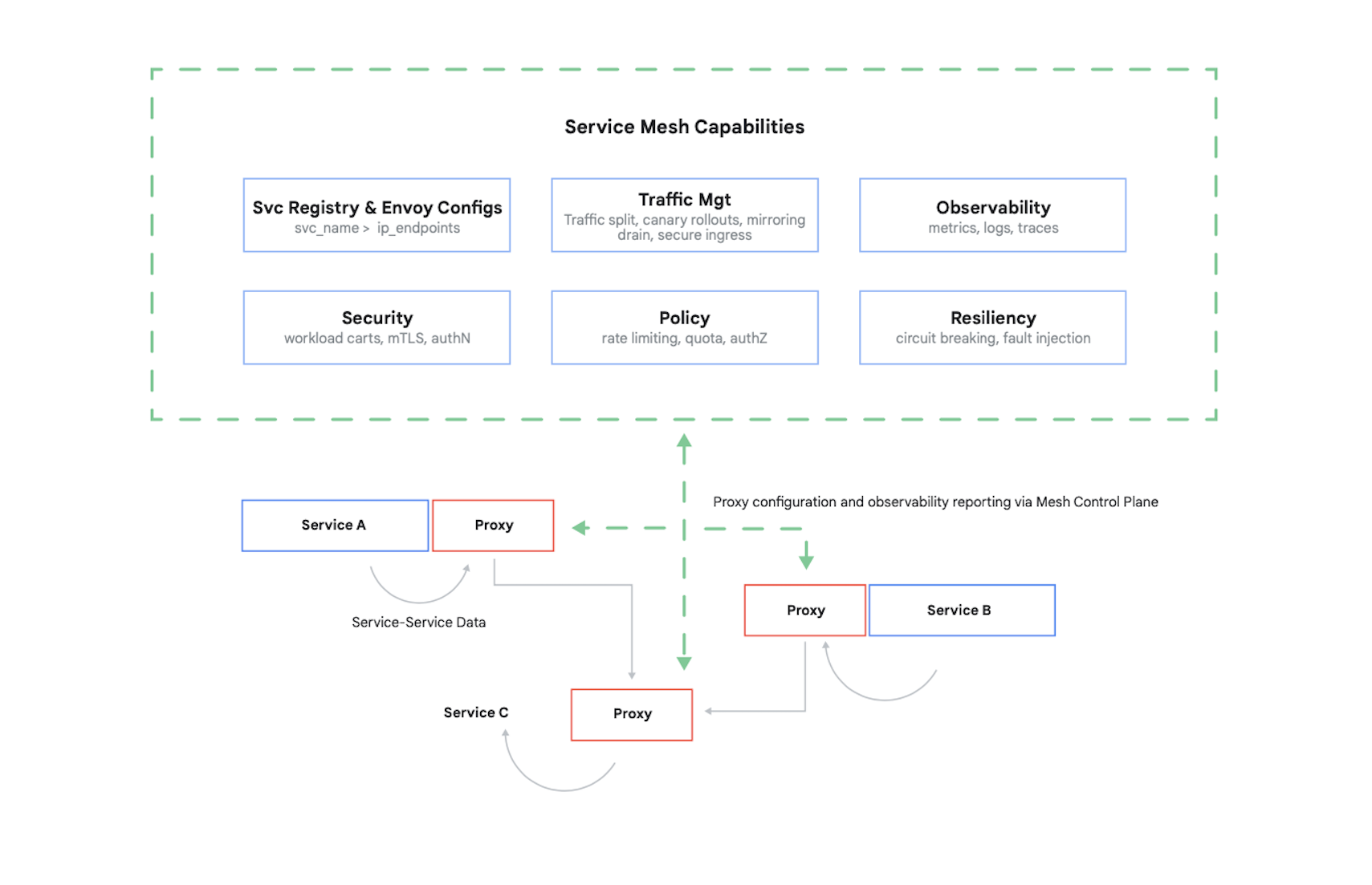
Google Cloud vous permet d'ajouter Istio à un cluster GKE. Et bien qu'il ne soit pas indispensable d'utiliser un maillage de services, ne soyez pas surpris si les clients de vos applications cloud les mieux informés vous demandent si vous offrez le même niveau de sécurité qu'Istio. La sécurité est une préoccupation majeure pour les clients. Dans un environnement basé sur des conteneurs, Istio est un des principaux moyens de la garantir.
En plus d'être compatible avec le projet Open Source Istio, Google Cloud vous donne accès à Traffic Director, un plan de contrôle du maillage de services entièrement géré par Google Cloud. Il effectue un équilibrage de charge mondial sur les clusters et instances de VM dans plusieurs régions, décharge les proxys de service des vérifications d'état, et offre une gestion avancée du trafic ainsi que d'autres fonctionnalités décrites plus haut.
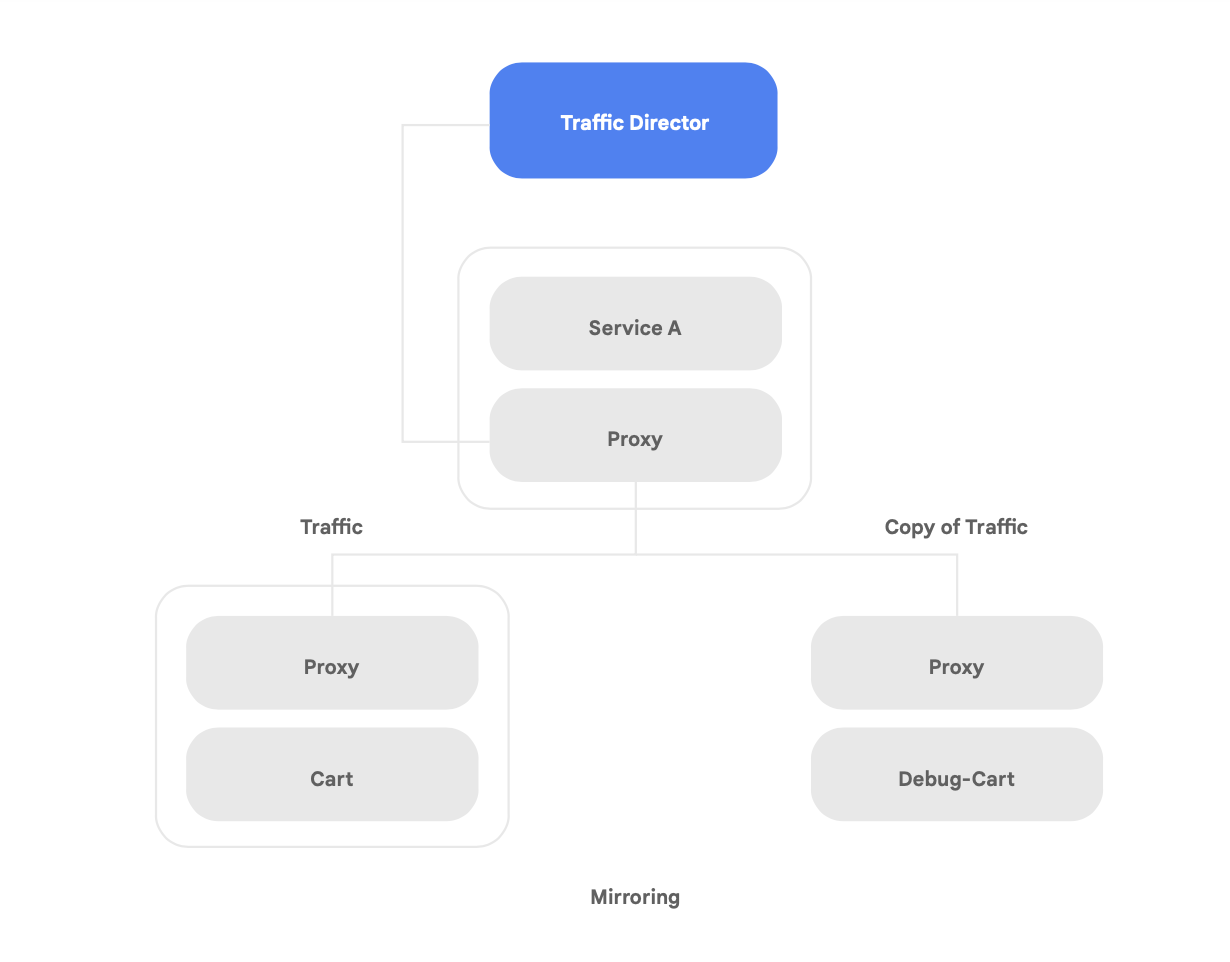
L'une des capacités uniques de Traffic Director est le basculement et le débordement automatiques entre régions pour les microservices du réseau maillé (comme l'illustre la figure 8).
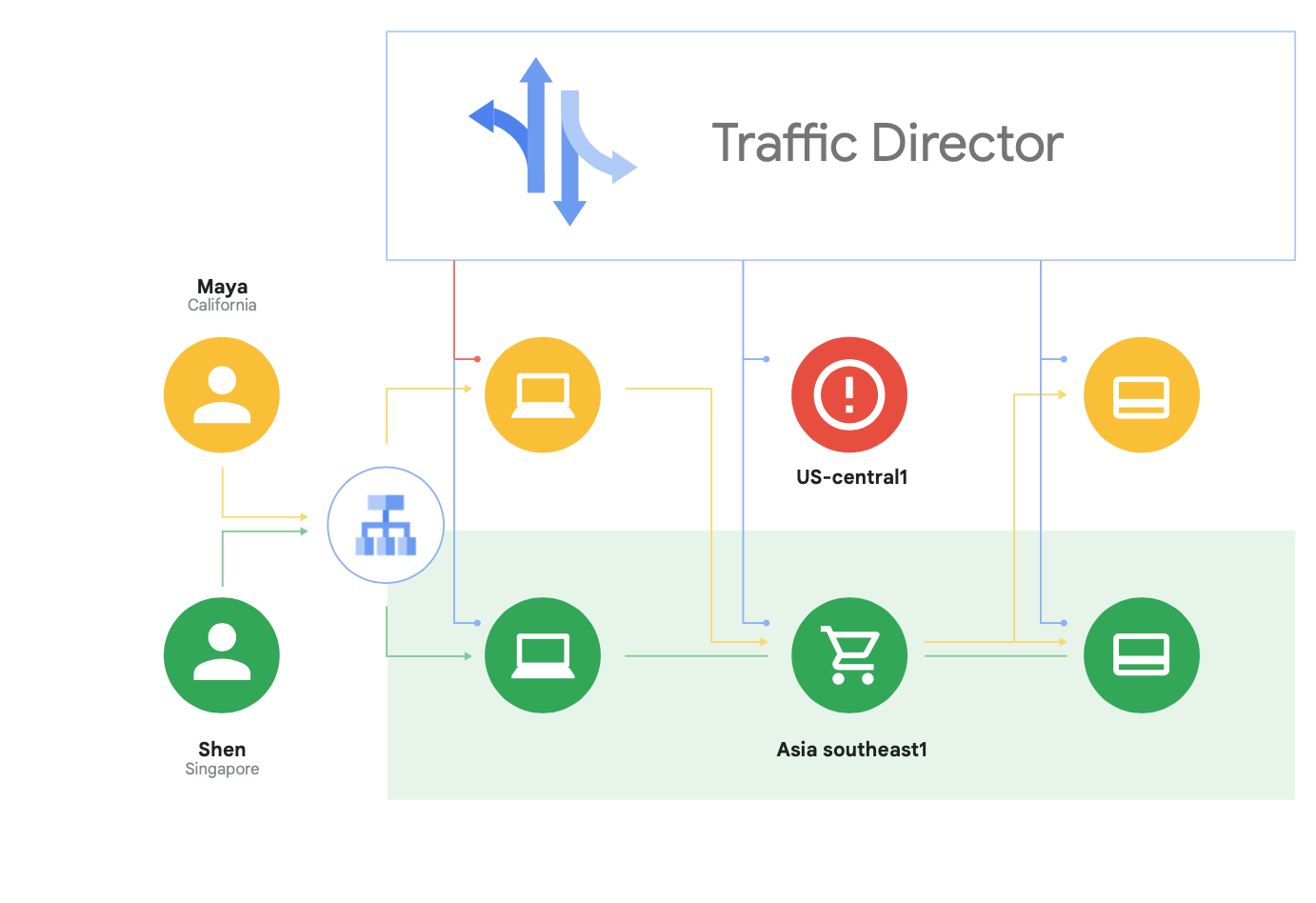
Grâce à cette capacité, vous pouvez associer résilience mondiale et sécurité pour vos services du maillage de services.
Traffic Director offre plusieurs fonctionnalités de gestion du trafic qui peuvent vous aider à améliorer la stratégie de sécurité de votre maillage de services. Par exemple, la fonctionnalité de mise en miroir du trafic illustrée figure 9 peut facilement être définie comme règle pour permettre à une application parallèle de recevoir une copie du trafic réel traité par la version principale de l'application. La copie des réponses reçues par le service parallèle est supprimée après le traitement. La mise en miroir du trafic est un outil particulièrement utile pour effectuer des tests en vue de détecter des anomalies de sécurité et pour corriger les erreurs affectant le trafic de production sans avoir d'impact sur ce dernier ni même y toucher.
La protection des interactions de vos conteneurs n'est toutefois pas le seul problème de sécurité qu'apporte une application refactorisée. Il faut également vérifier que les images de conteneurs que vous exécutez sont fiables. Pour cela, vous devez vous assurer que votre chaîne d'approvisionnement logicielle intègre la sécurité et la conformité.
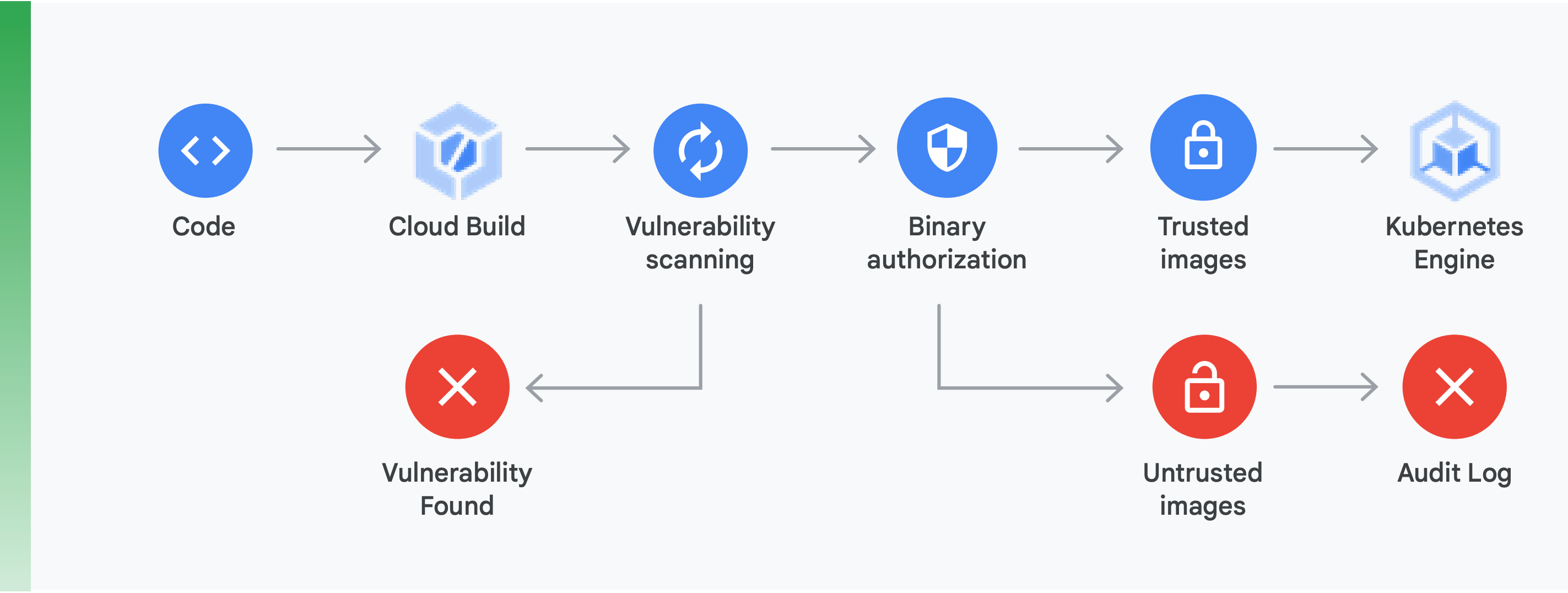
Cette vérification nécessite principalement deux choses de votre part (comme l'illustre la figure 10) :
Analyse des failles : l'analyse des failles de Container Registry vous permet d'obtenir rapidement des retours sur les menaces potentielles et d'identifier les problèmes dès que vos conteneurs sont compilés par Cloud Build et stockés dans Container Registry. Les failles des paquets pour Ubuntu, Debian et Alpine sont identifiées dès le développement de l'application. Ce sera bientôt aussi le cas pour CentOS et RHEL. Cela permet d'éviter des inefficacités coûteuses et de réduire le temps nécessaire pour corriger les failles connues.
Autorisation binaire : en intégrant l'autorisation binaire et l'analyse des failles de Container Registry à votre règle de déploiement globale, vous pouvez verrouiller les déploiements en fonction des résultats de l'analyse des failles. L'autorisation binaire est un contrôle de sécurité intervenant au moment du déploiement qui garantit que seules des images de conteneur fiables sont déployées sur GKE sans intervention manuelle.
La sécurisation de l'accès entre les conteneurs à l'aide d'un maillage de services et la mise en place d'une chaîne d'approvisionnement logicielle sécurisée sont deux aspects essentiels de la création d'applications basées sur des conteneurs sécurisées. Bien d'autres aspects sont à prendre en compte, tels que vérifier la sécurité de l'infrastructure de la plate-forme cloud sur laquelle vous créez vos applications. L'essentiel, cependant, est de prendre conscience que passer d'une application monolithique à un modèle cloud natif moderne soulève de nouveaux problèmes de sécurité. Pour réussir cette transition, il vous faudra bien cerner ces problèmes, puis concevoir une stratégie concrète pour répondre à chacun d'entre eux.
Premiers pas
Ne traitez pas le passage à une architecture cloud native comme un projet de transformation radicale sur plusieurs années.
Au contraire, montez dès maintenant une équipe qui a la capacité et l'expertise nécessaires pour commencer une démonstration de faisabilité, ou trouvez-en une qui l'a déjà fait. Prenez ensuite note des enseignements qu'elle en tire et partagez-les avec l'ensemble de votre organisation. Demandez à vos équipes de suivre le modèle du "figuier étrangleur", et de transférer les services vers une architecture cloud native de manière progressive et itérative, tout en continuant à livrer de nouvelles fonctionnalités.
Pour réussir, il est essentiel que les équipes aient les capacités, les ressources et l'autorité nécessaires pour que faire évoluer l'architecture de leurs systèmes fasse partie de leur travail quotidien. Fixez des objectifs architecturaux clairs pour cette nouvelle tâche, en suivant les six conditions architecturales présentées précédemment, mais laissez à vos équipes la liberté de décider comment y parvenir.
Plus important encore, n'attendez pas pour vous lancer ! Améliorer la productivité et l'agilité de vos équipes, ainsi que la sécurité et la stabilité de vos services deviendra de plus en plus capital pour la réussite de votre organisation. Les équipes qui obtiennent les meilleures performances sont celles qui intègrent rigoureusement l'expérimentation et l'amélioration à leurs tâches quotidiennes.
Google a inventé Kubernetes en se basant sur un logiciel utilisé en interne par son personnel depuis des années. C'est pourquoi nous avons plus d'expérience que nos concurrents dans la technologie cloud native.
Google Cloud met particulièrement l'accent sur les applications conteneurisées, comme en témoignent nos offres de CI/CD et de sécurité. La vérité est simple : Google Cloud est aujourd'hui le leader dans la prise en charge des applications conteneurisées.
Nous vous invitons à vous rendre sur cloud.google.com/devops et à passer l'évaluation rapide pour faire le point sur votre situation. Vous obtiendrez également des conseils sur la façon de procéder, par exemple pour savoir comment mettre en place les modèles présentés dans ce livre blanc tels que l'architecture faiblement couplée.
De nombreux partenaires Google Cloud ont déjà aidé des entreprises comme la vôtre à effectuer cette transition. Pourquoi vous engager seul dans une modification d'architecture alors que nous pouvons vous mettre en contact avec un guide expérimenté ?
Pour commencer, contactez-nous pour convenir d'un rendez-vous avec un architecte de solutions Google. Nous pouvons vous aider à comprendre cette transition, puis vous accompagner dans sa mise en place.
Documentation complémentaire
https://cloud.google.com/devops : six années de rapports sur l'état du DevOps, un ensemble d'articles présentant de façon détaillée les fonctionnalités qui prédisent les performances en livraison de logiciels, ainsi qu'une évaluation rapide pour faire le point sur votre situation et découvrir comment l'améliorer.
Site Reliability Engineering: How Google Runs Production Systems (O'Reilly 2016) (Ingénierie en fiabilité des sites : Comment Google exécute des système de production)
The Site Reliability Workbook: Practical Ways to Implement SRE (O'Reilly 2018) (Livret pratique de la fiabilité des sites : Appliquer les principes et pratiques SRE)
Best Practices for Designing, Implementing and Maintaining Systems (O'Reilly 2020) (Créer des systèmes sécurisés et fiables : Bonnes pratiques pour concevoir, implémenter et gérer des systèmes)
"How to break a Monolith into Microservices: What to decouple and when" (Comment décomposer une application monolithe en microservices) : que dissocier et quand), Zhamak Dehghani
"Microservices: a definition of this new architectural term" (Microservices : définition de ce nouveau terme architectural), Martin Fowler
"Strangler Fig Application" (Application de type "figuier étrangleur", Martin Fowler
Prêt à passer aux étapes suivantes ?
Remplissez le formulaire, et nous vous contacterons. Contactez le service commercial


















