Modificar la arquitectura a nativa de la nube
Según un estudio del programa de investigación y evaluación de DevOps (DevOps Research and Assessment o DORA), los equipos de DevOps de élite pueden realizar despliegues varias veces al día, lanzar cambios a la fase de producción en menos de 24 horas y alcanzar unas tasas de fallo que varían del 0 % al 15 %.
En este informe se explica cómo puedes rediseñar tu aplicaciones para un paradigma nativo de la nube que te permita acelerar la entrega de nuevas funciones incluso si aumentas tus equipos, al tiempo que mejoras la calidad del software y alcanzas mayores niveles de estabilidad y disponibilidad.
¿Por qué migrar a una arquitectura nativa de la nube?
Muchas empresas crean sus servicios de software personalizados utilizando arquitecturas monolíticas. Este enfoque tiene algunas ventajas: los sistemas monolíticos son relativamente sencillos de diseñar y desplegar, al menos al principio. Sin embargo, puede resultar difícil mantener la productividad de los desarrolladores y la velocidad de despliegue a medida que las aplicaciones se vuelven más complejas, haciendo que los sistemas sean caros, que lleve mucho tiempo desplegar los cambios y que sea arriesgado.
A medida que crecen los servicios, y los equipos responsables de dichos servicios, tienden a volverse más complejos y difíciles de evolucionar y operar. Las pruebas y el despliegue cuestan más, es más difícil añadir nuevas funciones y mantener la fiabilidad y la disponibilidad puede convertirse en un problema.
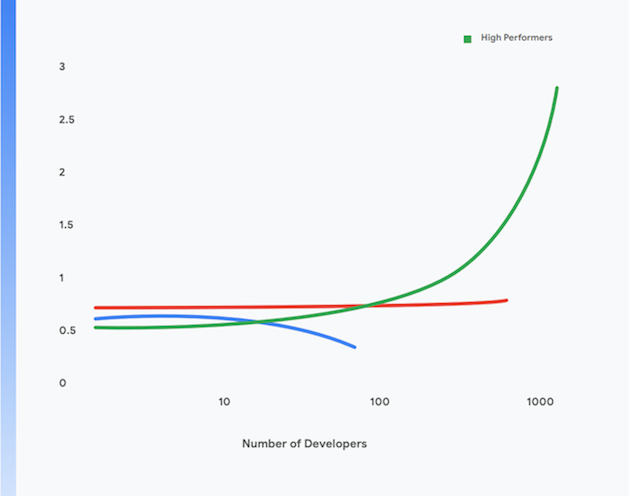
La investigación realizada por el equipo DORA de Google muestra que es posible conseguir altos niveles de rendimiento de envío de software, así como estabilidad y disponibilidad del servicio en organizaciones de todos los tamaños y sectores. Los equipos de alto rendimiento son capaces de realizar despliegues varias veces al día, lanzar cambios a la fase de producción en menos de un día, restaurar el servicio en menos de una hora y alcanzar unas tasas de fallo de entre el 0 % y el 15 %.1
Además, estos equipos pueden lograr niveles más altos de productividad de desarrollador, que se miden en términos de despliegues por desarrollador por día, incluso cuando aumentan el tamaño de sus equipos. Esto se muestra en la figura 1.
El resto de esta publicación muestra cómo migrar aplicaciones a un paradigma moderno nativo de la nube para ayudar a conseguir estos resultados. Al desplegar las prácticas técnicas descritas en este documento, puedes alcanzar los siguientes objetivos:
- Mayor productividad para los desarrolladores: incluso aunque aumente el tamaño de tu equipo.
- Menor tiempo de lanzamiento: añade nuevas funciones y corrige los defectos más rápido.
- Mayor disponibilidad: aumenta el tiempo de funcionamiento de tu software, reduce la tasa de fallos de despliegue y reduce el tiempo de restauración en caso de incidentes.
- Seguridad mejorada: reduce el área de superficie de ataque de tus aplicaciones y facilita la detección y la respuesta rápida a los ataques y las vulnerabilidades recién descubiertas.
- Mejor escalabilidad: las plataformas y aplicaciones nativas de la nube facilitan el escalado horizontal donde sea necesario, y también la reducción vertical.
- Reducción de costes: un proceso de envío de software optimizado reduce los gastos de entrega de nuevas funciones, y el uso eficaz de las plataformas en la nube reduce sustancialmente los costes operativos de tus servicios.
1 Descubre cómo está rindiendo tu equipo en función de estas cuatro métricas clave en https://cloud.google.com/devops/
¿Qué es una arquitectura nativa de la nube?
Las aplicaciones monolíticas deben construirse, probarse y desplegarse como una sola unidad. A menudo, el sistema operativo, el middleware y la pila de idiomas de la aplicación se personalizan o configuran de forma personalizada para cada aplicación. Los procesos y secuencias de comandos de compilación, prueba y despliegue también suelen ser únicos para cada aplicación. Este método es sencillo y eficaz en el caso de las aplicaciones nuevas, pero a medida que crecen, es más difícil cambiar, probar, desplegar y operar dichos sistemas.
Además, a medida que los sistemas crecen, también lo hace el tamaño y la complejidad de los equipos que construyen, prueban, despliegan y operan el servicio. Un método común, pero incorrecto, es dividir a los equipos por funciones, lo que lleva a traspasos entre equipos que tienden a aumentar los plazos de entrega y el tamaño de los lotes y dan lugar a numerosas reelaboraciones. La investigación de DORA revela que los equipos de alto rendimiento tienen el doble de probabilidades de desarrollar y enviar software en un solo equipo multifuncional.
Entre los síntomas de este problema se encuentran:
- Procesos de compilación largos y que se interrumpen con frecuencia
- Ciclos de prueba e integración poco frecuentes
- Se requiere un mayor esfuerzo para respaldar los procesos de construcción y prueba
- Pérdida de productividad de los desarrolladores
- Procesos de despliegue complicados que deben realizarse fuera del horario laboral y que requieren un tiempo de inactividad programado
- Esfuerzo significativo en la gestión de la configuración de entornos de prueba y producción.
En el paradigma nativo de la nube, en contraste³:
- Los sistemas complejos se descomponen en servicios que se pueden probar y desplegar de forma independiente en un tiempo de ejecución en contenedores (un microservicio o una arquitectura orientada a servicios de envío).
- Las aplicaciones utilizan servicios estándar proporcionados por la plataforma, como sistemas de gestión de bases de datos, almacenamiento de blobs, mensajería, CDN y terminación SSL.
- Una plataforma en la nube estandarizada se ocupa de muchas cuestiones operativas, como el despliegue, el ajuste de escala automático, la configuración, la gestión de secretos, la supervisión y las alertas. Los equipos de desarrollo de aplicaciones pueden acceder a estos servicios bajo demanda.
- Se proporcionan pilas estandarizadas de sistema operativo, middleware y lenguajes específicos a los desarrolladores de aplicaciones, y el mantenimiento y el parcheo de estas pilas se realizan fuera de banda por el proveedor de la plataforma o un equipo aparte.
- Un solo equipo multifuncional puede ser responsable de todo el ciclo de vida del envío de software de cada servicio.
3 Esto no pretende ser una descripción completa de lo que significa "nativo de la nube": para debatir algunos de los principios de la arquitectura nativa de la nube, visita https://cloud.google.com/blog/products/ application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it.
Este paradigma tiene muchas ventajas:
Entrega más rápida | Lanzamientos fiables | Costes más bajos |
dado que los servicios ahora son pequeños y con bajo acoplamiento, los equipos asociados con esos servicios pueden trabajar de forma autónoma. Esto aumenta la productividad de los desarrolladores y la velocidad de desarrollo. | los desarrolladores pueden crear, probar y desplegar rápidamente servicios nuevos y existentes en entornos de prueba similares a los de producción. El despliegue en la producción también es una actividad atómica sencilla. Esto acelera sustancialmente el proceso de entrega de software y reduce los riesgos de los despliegues. | El coste y la complejidad de los entornos de prueba y producción se reducen sustancialmente porque la plataforma proporciona servicios compartidos y estandarizados, y porque las aplicaciones se ejecutan en una infraestructura física compartida. |
Más seguridad | Mayor disponibilidad | Cumplimiento normativo más sencillo y económico |
los proveedores ahora son responsables de mantener los servicios compartidos, como el sistema de gestión de bases de datos y la infraestructura de mensajería, actualizados, parcheados y compatibles. También es mucho más fácil mantener las aplicaciones parcheadas y actualizadas porque existe una forma estándar de desplegar y gestionar aplicaciones. | La disponibilidad y la fiabilidad de las aplicaciones aumentan debido a la menor complejidad del entorno operativo, la facilidad para realizar cambios de configuración y la capacidad de gestionar el autoescalado y la reparación automática a nivel de plataforma. | La mayoría de los controles de seguridad de la información se pueden implementar en la capa de la plataforma, lo que la hace significativamente más barata y fácil de implementar, y demostrar el cumplimiento normativo. Muchos proveedores de la nube cumplen con los marcos de gestión de riesgos como SOC2 y FedRAMP, lo que significa que las aplicaciones desplegadas sobre ellos solo tienen que demostrar el cumplimiento de los controles residuales no desplegados en la capa de la plataforma. |
Entrega más rápida
Lanzamientos fiables
Costes más bajos
dado que los servicios ahora son pequeños y con bajo acoplamiento, los equipos asociados con esos servicios pueden trabajar de forma autónoma. Esto aumenta la productividad de los desarrolladores y la velocidad de desarrollo.
los desarrolladores pueden crear, probar y desplegar rápidamente servicios nuevos y existentes en entornos de prueba similares a los de producción. El despliegue en la producción también es una actividad atómica sencilla. Esto acelera sustancialmente el proceso de entrega de software y reduce los riesgos de los despliegues.
El coste y la complejidad de los entornos de prueba y producción se reducen sustancialmente porque la plataforma proporciona servicios compartidos y estandarizados, y porque las aplicaciones se ejecutan en una infraestructura física compartida.
Más seguridad
Mayor disponibilidad
Cumplimiento normativo más sencillo y económico
los proveedores ahora son responsables de mantener los servicios compartidos, como el sistema de gestión de bases de datos y la infraestructura de mensajería, actualizados, parcheados y compatibles. También es mucho más fácil mantener las aplicaciones parcheadas y actualizadas porque existe una forma estándar de desplegar y gestionar aplicaciones.
La disponibilidad y la fiabilidad de las aplicaciones aumentan debido a la menor complejidad del entorno operativo, la facilidad para realizar cambios de configuración y la capacidad de gestionar el autoescalado y la reparación automática a nivel de plataforma.
La mayoría de los controles de seguridad de la información se pueden implementar en la capa de la plataforma, lo que la hace significativamente más barata y fácil de implementar, y demostrar el cumplimiento normativo. Muchos proveedores de la nube cumplen con los marcos de gestión de riesgos como SOC2 y FedRAMP, lo que significa que las aplicaciones desplegadas sobre ellos solo tienen que demostrar el cumplimiento de los controles residuales no desplegados en la capa de la plataforma.
Sin embargo, existen algunas compensaciones asociadas con el modelo nativo de la nube:
- Todas las aplicaciones son ahora sistemas distribuidos, lo que significa que realizan un número significativo de llamadas remotas como parte de su funcionamiento. Esto implica pensar detenidamente acerca de cómo gestionar los fallos de la red y los problemas de rendimiento, y cómo depurar los problemas en producción.
- Los desarrolladores deben utilizar el sistema operativo estandarizado, el middleware y las pilas de aplicaciones que proporciona la plataforma. Esto dificulta el desarrollo local.
- Los arquitectos deben adoptar un enfoque basado en eventos para el diseño de sistemas, incluida la adopción de una coherencia retardada.
Migrar a una arquitectura nativa de la nube
Muchas organizaciones han adoptado un enfoque de migración mediante lift-and-shift para trasladar servicios a la nube. En este enfoque, solo se requieren cambios menores en los sistemas, y la nube se trata básicamente como un centro de datos tradicional, que proporciona APIs, servicios y herramientas de gestión sustancialmente mejores en comparación con los centros de datos tradicionales. Sin embargo, migrar mediante lift-and-shift no proporciona ninguna de las ventajas del paradigma nativo de la nube descrito anteriormente.
Muchas organizaciones se estancan en la migración mediante lift-and-shift debido al coste y la complejidad de trasladar sus aplicaciones a una arquitectura nativa de la nube, lo que requiere repensar todo, desde la arquitectura de la aplicación hasta las operaciones de producción y, por supuesto, todo el ciclo de vida del envío de software. Este miedo no es infundado: muchas organizaciones grandes han sufrido el gran desgaste que supone la cantidad de esfuerzos fallidos de ambiciosas iniciativas de migración a otra plataforma a lo largo de varios años.
La solución consiste en adoptar un enfoque de incrementalidad, iterativo y evolutivo para rediseñar sus sistemas para que sean nativos de la nube, lo que permite que los equipos aprendan cómo trabajar de manera eficaz en este nuevo paradigma mientras siguen ofreciendo nuevas funcionalidades: un enfoque que llamamos "migrar y mejorar".
Un patrón clave en la arquitectura evolutiva se conoce como la aplicación Strangler Fig.4 En lugar de reescribir completamente los sistemas desde cero, desarrolla nuevas funciones en un estilo moderno y nativo de la nube, pero haz que se comuniquen con la aplicación monolítica original para conocer las funciones existentes. Cambia gradualmente la funcionalidad existente a lo largo del tiempo según sea necesario para la integridad conceptual de los nuevos servicios, como se muestra en la Figura 2.
4 Descrito en https://martinfowler.com/bliki/StranglerFigApplication.html
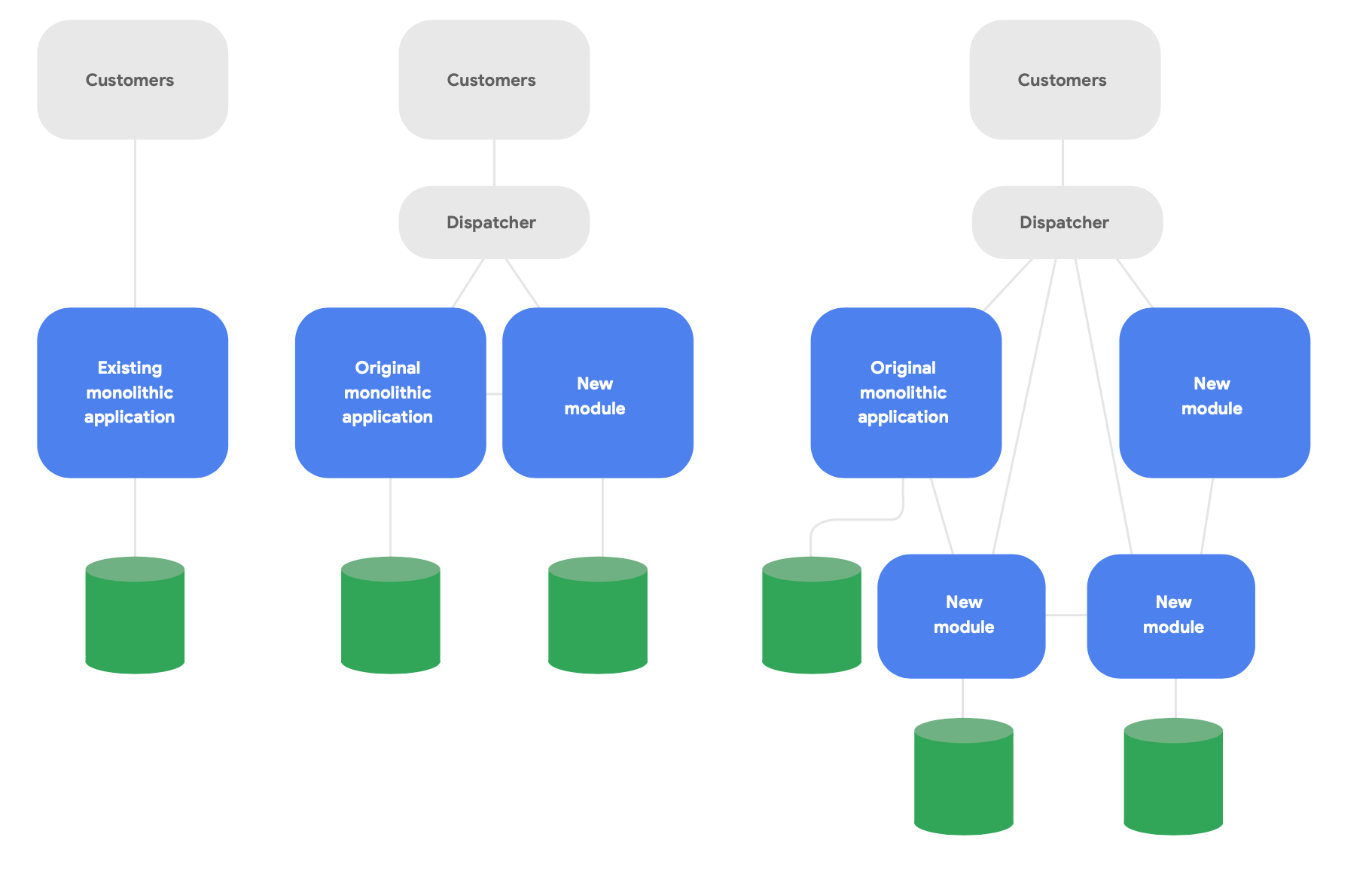
Hay tres pautas importantes para cambiar la arquitectura con éxito:
Primero, empieza por ofrecer nuevas funciones rápidamente, en lugar de reproducir las funciones existentes. La métrica clave es la rapidez con la que puedes empezar a ofrecer nuevas funciones utilizando nuevos servicios, de modo que puedas aprender y comunicar rápidamente las buenas prácticas adquiridas al trabajar realmente dentro de este paradigma. Reduce el alcance de forma agresiva con el objetivo de ofrecer algo a los usuarios reales en semanas, no en meses.
Luego, diseña para nativos de la nube. Esto significa usar los servicios nativos de la plataforma en la nube para sistemas de gestión de bases de datos, mensajes, CDN, redes, almacenamiento de blobs, etc., y usar pilas de aplicaciones proporcionadas por la plataforma estandarizadas cuando se pueda. Los servicios deben estar en contenedores, haciendo uso del paradigma sin servidor siempre que sea posible, y el proceso de construcción, prueba y despliegue debe estar completamente automatizado. Consigue que todas las aplicaciones utilicen servicios compartidos de la plataforma para registrar, supervisar y alertar. Vale la pena señalar que este tipo de arquitectura de plataforma se puede desplegar de manera útil para cualquier plataforma de aplicaciones de múltiples clientes, incluido un entorno on-premise sin sistema operativo. En la Figura 3, a continuación, se muestra una imagen general de una plataforma nativa de la nube.
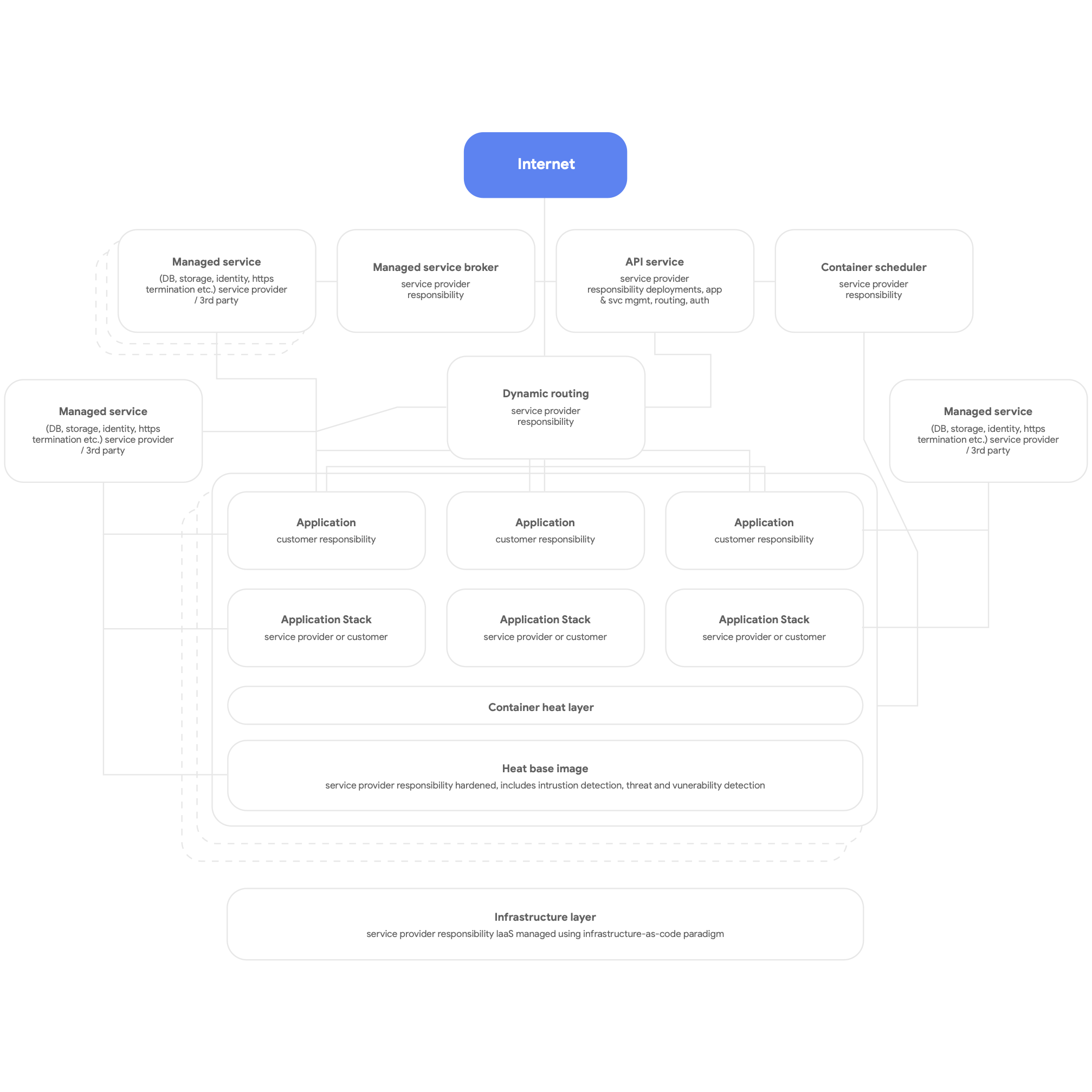
Por último, diseña para equipos autónomos y con bajo acoplamiento que pueden probar y desplegar sus propios servicios. Según nuestra investigación, los resultados más importantes desde el punto de vista de la arquitectura ocurren si los equipos de envío de software pueden responder "sí" a estas seis afirmaciones:
- Podemos realizar cambios a gran escala en el diseño de nuestro sistema sin el permiso de alguien ajeno al equipo.
- Podemos realizar cambios a gran escala en el diseño de nuestro sistema sin depender de otros equipos para realizar cambios en sus sistemas o crear un trabajo significativo para otros equipos.
- Podemos completar nuestro trabajo sin tener que comunicarnos y coordinarnos con personas ajenas al equipo.
- Podemos desplegar y lanzar nuestro producto o servicio bajo demanda, independientemente de otros servicios de los que dependa.
- Podemos realizar la mayoría de nuestras pruebas bajo demanda, sin requerir un entorno de prueba integrado.
- Podemos realizar despliegues durante el horario comercial normal con un periodo de inactividad insignificante.
Comprueba regularmente si los equipos están trabajando para alcanzar estos objetivos y es una prioridad para ellos. Por lo general, esto implica repensar la arquitectura organizativa y empresarial.
En particular, es crucial organizar equipos para que todos los roles que sea necesario construir, probar y desplegar software, incluidos los gerentes de producto, trabajen juntos y utilicen prácticas modernas de administración de productos para construir y desarrollar los servicios en los que están trabajando. No es necesario que esto implique cambios en la estructura organizativa. El simple hecho de que esas personas trabajen en equipo todos los días (compartiendo un espacio físico cuando sea posible), en vez de tener desarrolladores, evaluadores y equipos de lanzamiento que operen de forma independiente, puede marcar una gran diferencia en la productividad.
Según nuestra investigación, si los equipos estaban de acuerdo con estas afirmaciones se podía predecir claramente un alto rendimiento del software: la capacidad de ofrecer servicios fiables y de alta disponibilidad varias veces al día. Esto, a su vez, es lo que permite que los equipos de alto rendimiento aumenten la productividad de los desarrolladores (que se mide en términos de número de despliegues por desarrollador y día) incluso aunque aumente el número de equipos.
Principios y prácticas
Principios y prácticas de la arquitectura de microservicios
Al adoptar una arquitectura de microservicios u orientada a servicios, hay algunos principios y prácticas importantes que debes asegurarse de seguir. Es mejor seguirlos estrictamente desde el principio, ya que es más costoso adaptarlos más adelante.
- Cada servicio debe tener su propio esquema de base de datos. Tanto si estás utilizando una base de datos relacional como una solución NoSQL, cada servicio debe tener su propio esquema al que ningún otro servicio puede acceder. Cuando varios servicios se comunican con el mismo esquema, con el tiempo, los servicios se acoplan estrechamente en la capa de la base de datos. Estas dependencias evitan que los servicios se prueben y desplieguen de forma independiente, consiguiendo que sea más difícil desplegar los cambios y que sea arriesgado.
- Los servicios solo deben comunicarse a través de sus APIs públicas a través de la red. Todos los servicios deben exponer su comportamiento a través de APIs públicas, y los servicios solo deben comunicarse entre sí a través de estas APIs. No debe haber acceso por la "puerta trasera" ni servicios que se comuniquen directamente con las bases de datos de otros servicios. Esto evita que los servicios se acoplen estrechamente y garantiza que la comunicación entre servicios utilice APIs bien documentadas y compatibles.
- Los servicios son responsables de la compatibilidad con versiones anteriores para sus clientes. La formación de equipos y la operación de un servicio es responsable de asegurarse de que las actualizaciones del servicio no perjudiquen a sus consumidores. Esto significa planificar el control de versiones de las APIs y probar la compatibilidad con versiones anteriores, de modo que cuando se lancen nuevas versiones, no se rompa con los clientes actuales. Los equipos pueden validarlo con la versión canary. También implica asegurarse de que los despliegues no introduzcan tiempos de inactividad, utilizando técnicas como despliegues azul-verde o progresivos.
- Crear una forma estándar de ejecutar servicios en estaciones de trabajo de desarrollo. Los desarrolladores deben poder instalar cualquier subconjunto de servicios de producción en estaciones de trabajo de desarrollo bajo demanda con un solo comando. También debería ser posible ejecutar versiones stub de servicios bajo demanda; asegúrate de utilizar versiones emuladas de servicios en la nube que muchos proveedores de la nube ofrecen para ayudarte. El objetivo es facilitar a los desarrolladores la tarea de probar y depurar servicios localmente.
- Invertir en seguimiento y observabilidad de la producción. Muchos problemas en la producción, incluidos los problemas de rendimiento, son emergentes y están causados por interacciones entre múltiples servicios. Según nuestra investigación, es importante tener una solución que informe sobre el estado general de los sistemas (por ejemplo, "¿Están funcionando mis sistemas?" o "¿Tienen mis sistemas suficientes recursos disponibles?") y que los equipos tengan acceso a herramientas y datos que les ayuden a rastrear, comprender y diagnosticar problemas de infraestructura en entornos de producción, incluidas las interacciones entre servicios.
- Fijar objetivos de nivel para tus servicios y realizar pruebas de recuperación tras fallos con regularidad. Definir objetivos de nivel en tus servicios es una manera de fijar las expectativas sobre su rendimiento y te ayuda a planificar cómo debe comportarse el sistema si un servicio falla (una consideración clave cuando se construyen sistemas distribuidos resilientes). Prueba cómo se comporta tu sistema de producción en la vida real utilizando técnicas como la inserción controlada de fallos como parte del plan de pruebas de recuperación tras fallos. La investigación de DORA demuestra que las organizaciones que hacen pruebas utilizando métodos como este tienen más probabilidades de tener niveles más altos de disponibilidad de servicio. Cuanto antes empieces, mejor: así podrás normalizar este tipo de actividad vital.
Hay muchas cosas en las que pensar, por lo que es importante poner a prueba este tipo de trabajo con un equipo que tenga la capacidad de experimentar implementando estas ideas. Habrá éxitos y fracasos; es importante aprender las lecciones de estos equipos y aprovecharlas a medida que difundes el nuevo paradigma arquitectónico en tu organización.
Nuestra investigación demuestra que las empresas que tienen éxito utilizan pruebas de concepto y ofrecen oportunidades para que los equipos compartan aprendizajes, por ejemplo, creando comunidades de práctica. Proporciona el tiempo, el espacio y los recursos necesarios para que las personas de varios equipos se reúnan regularmente e intercambien ideas. Todo el mundo necesitará aprender nuevas habilidades y tecnologías. Invierte en el crecimiento de tu personal asignando un presupuesto para libros, cursos de formación y conferencias. Proporcionar infraestructura y tiempo para que las personas difundan el conocimiento institucional y las buenas prácticas a través de listas de distribución de la empresa, bases de conocimientos y reuniones presenciales.
Arquitectura de referencia
En esta sección, describiremos una arquitectura de referencia basada en las siguientes pautas:
- Usar contenedores para servicios de producción y un programador de contenedores como Cloud Run o Kubernetes para la orquestación
- Crear flujos de procesamiento de CI/CD eficaces
- Centrarse en la seguridad
Servicios de producción en contenedores
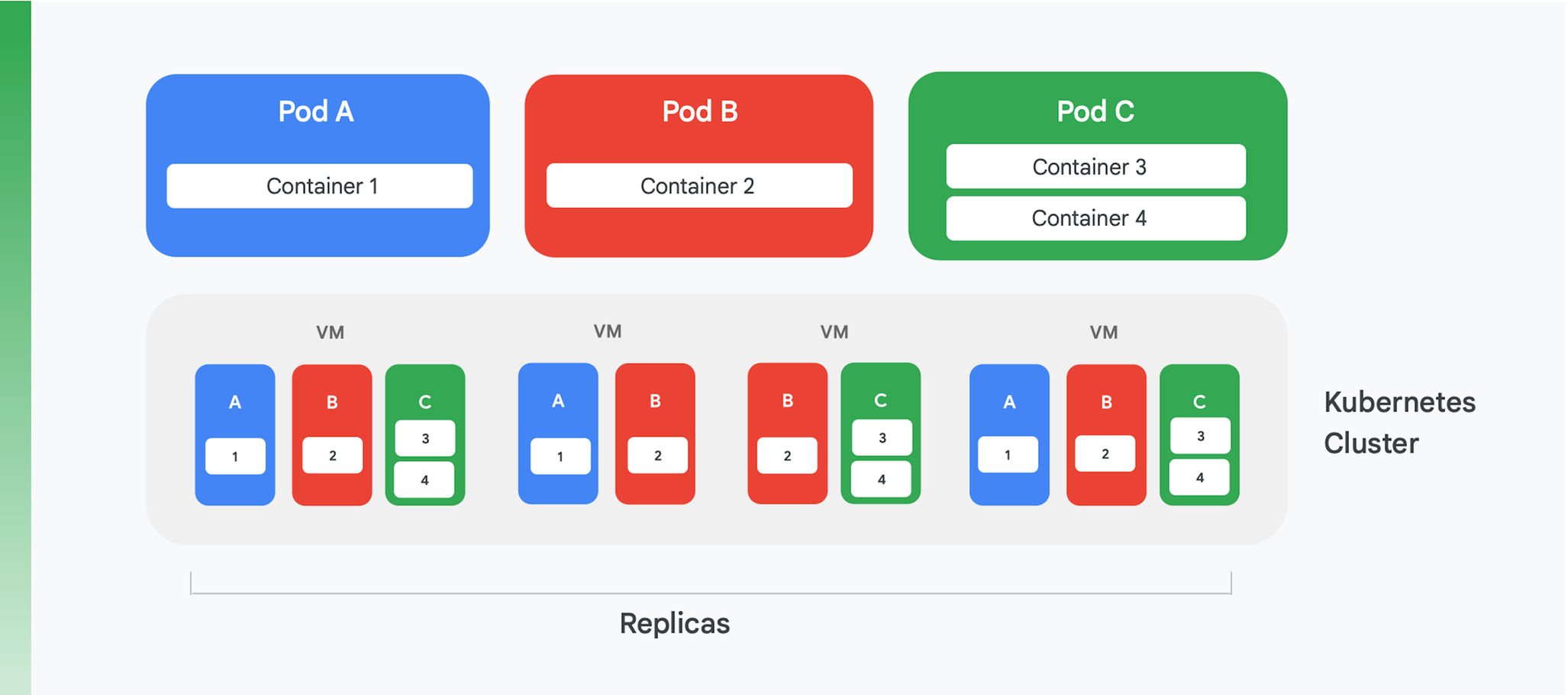
La base de una aplicación en la nube en contenedores es un servicio de orquestación y gestión de contenedores. Aunque se hayan creado muchos servicios diferentes, hay uno que es claramente dominante en la actualidad: Kubernetes. Ahora, Kubernetes establece el estándar para la orquestación de contenedores en el sector, fomentando una comunidad activa y recopilando la ayuda de muchos de los principales proveedores comerciales. La Figura 4 resume la estructura lógica de un clúster de Kubernetes.
Kubernetes define una abstracción llamada pod. Cada pod suele incluir solo un contenedor, como los pods A y B de la Figura 4, aunque un pod puede contener más de uno, como en el pod C. Cada servicio de Kubernetes ejecuta un clúster que contiene una cierta cantidad de nodos, cada uno de los cuales suele ser una máquina virtual. En la Figura 4 solo aparecen cuatro máquinas virtuales, pero un clúster real puede contener fácilmente cien o más. Cuando se despliega un pod en un clúster de Kubernetes, el servicio determina en qué máquinas virtuales se deben ejecutar los contenedores del pod. Como los contenedores especifican los recursos que necesitan, Kubernetes puede tomar decisiones inteligentes sobre qué pods se asignan a cada máquina virtual.
Parte de la información de despliegue de un pod es una indicación de cuántas instancias (réplicas) del pod deben ejecutarse. Luego, el servicio de Kubernetes crea esa cantidad de instancias de los contenedores del pod y las asigna a las máquinas virtuales. En la Figura 4, por ejemplo, el despliegue del pod A requirió tres réplicas, al igual que el despliegue del pod C. Sin embargo, para el despliegue del pod B hicieron falta cuatro réplicas, por lo que este clúster de ejemplo contiene cuatro instancias de ejecución del contenedor 2. Y como sugiere la figura, un pod con más de un contenedor, como el pod C, siempre tendrá sus contenedores asignados al mismo nodo.
Kubernetes también ofrece otros servicios, entre los que se incluyen:
- Monitorizar los pods en ejecución, por lo que si un contenedor falla, el servicio iniciará una nueva instancia. Esto asegura que todas las réplicas solicitadas en el despliegue de un pod sigan disponibles.
- Equilibrar la carga del tráfico, distribuir las solicitudes realizadas a cada pod de forma inteligente en las réplicas de un contenedor.
- Desplegar contenedores nuevos de forma automatizada y sin tiempo de inactividad, con nuevas instancias que reemplazan gradualmente las instancias existentes hasta que una nueva versión esté completamente desplegada.
- Llevar a cabo un escalado automatizado, con un clúster que añade o elimina máquinas virtuales de forma autónoma según la demanda.
Crear flujos de procesamiento de CI/CD eficaces
Algunas de las ventajas de refactorizar una aplicación monolítica, como reducción de costes, se derivan directamente de la ejecución en Kubernetes. Pero uno de los beneficios más importantes, la capacidad de actualizar tu aplicación con más frecuencia, solo es posible si cambias la forma de crear y lanzar el software. Para disfrutar de él, es necesario crear canalizaciones de CI/CD eficaces en tu organización.
La integración continua se basa en flujos de trabajo de prueba y compilación automatizados que brindan comentarios rápidamente a los desarrolladores. Requiere que todos los miembros de un equipo que trabajen en el mismo código (por ejemplo, el código para un solo servicio) integren regularmente su trabajo en una línea principal o troncal compartida. Esta integración debe ocurrir al menos una vez al día por desarrollador, con cada integración verificada por un proceso de compilación que incluye pruebas automatizadas. La entrega continua tiene como objetivo hacer que el despliegue de este código integrado sea rápido y de bajo riesgo, en gran parte mediante la automatización del proceso de compilación, prueba y despliegue para que las actividades como el rendimiento, la seguridad y las pruebas exploratorias se puedan realizar de forma ininterrumpida. En pocas palabras, CI ayuda a los desarrolladores a detectar problemas de integración rápidamente, mientras que CD hace que el despliegue sea fiable y rutinario.
Para aclarar esto, es útil mirar un ejemplo concreto. La Figura 5 muestra cómo podría verse una canalización de CI/CD con las herramientas de Google para contenedores que se ejecutan en Google Kubernetes Engine.
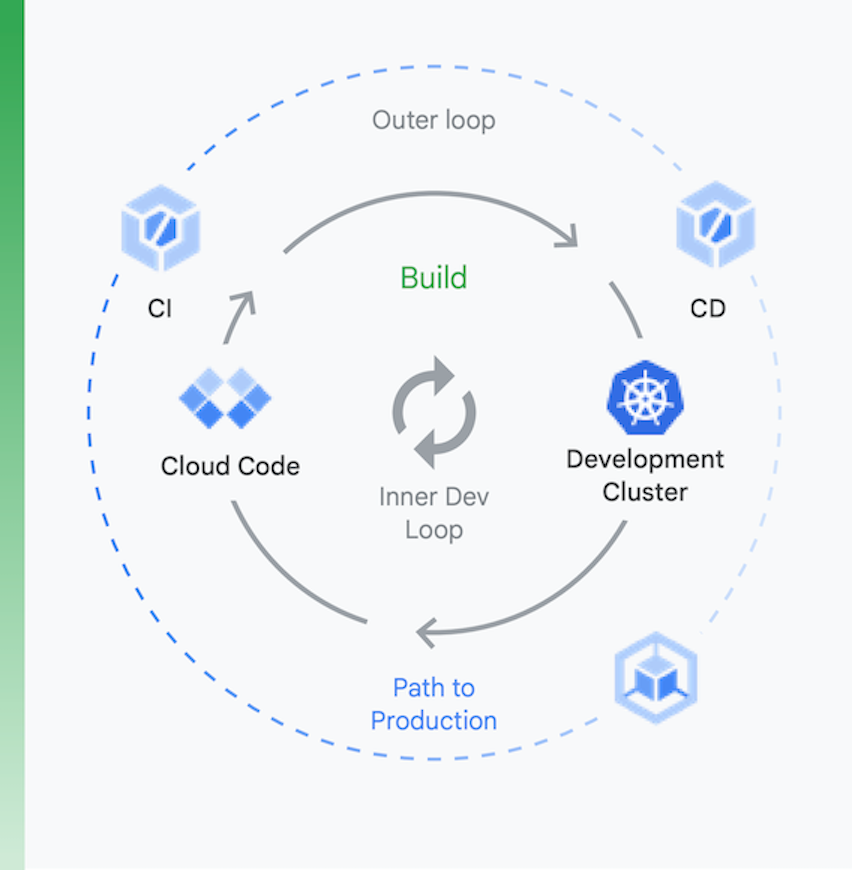
Es útil pensar en el proceso en dos partes, como se muestra en la Figura 6:
Desarrollo local | Desarrollo remoto |
el objetivo aquí es acelerar un ciclo de desarrollo interno y proporcionar a los desarrolladores herramientas para obtener rápidamente información sobre el impacto de los cambios en el código local. Esto incluye compatibilidad con linting, autocompletado para YAML y compilaciones locales más rápidas. | Cuando se envía una solicitud de extracción, se inicia el bucle de desarrollo remoto. El objetivo aquí es reducir drásticamente el tiempo que lleva validar y probar la solicitud de extracción mediante CI y realizar otras actividades como análisis de vulnerabilidades y firma binaria, al mismo tiempo que se impulsan las aprobaciones para versiones de manera automatizada. |
Desarrollo local
Desarrollo remoto
el objetivo aquí es acelerar un ciclo de desarrollo interno y proporcionar a los desarrolladores herramientas para obtener rápidamente información sobre el impacto de los cambios en el código local. Esto incluye compatibilidad con linting, autocompletado para YAML y compilaciones locales más rápidas.
Cuando se envía una solicitud de extracción, se inicia el bucle de desarrollo remoto. El objetivo aquí es reducir drásticamente el tiempo que lleva validar y probar la solicitud de extracción mediante CI y realizar otras actividades como análisis de vulnerabilidades y firma binaria, al mismo tiempo que se impulsan las aprobaciones para versiones de manera automatizada.
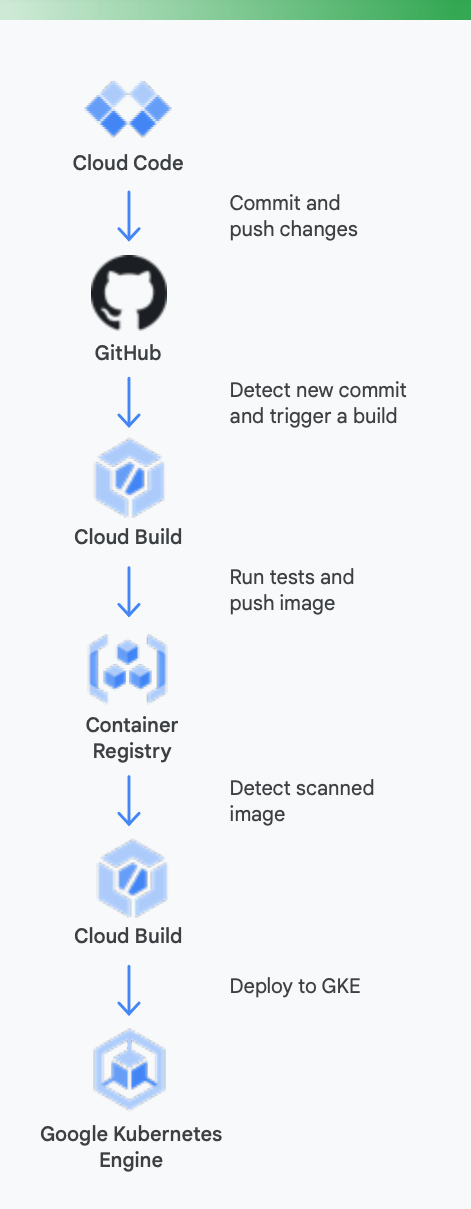
Así es como las herramientas de Google Cloud pueden ayudar en este proceso
Desarrollo local: es esencial que los desarrolladores sean productivos con el desarrollo de aplicaciones locales. Este desarrollo local implica la creación de aplicaciones que se pueden desplegar en clústeres locales y remotos. Antes de realizar cambios en un sistema de gestión de control de fuente como GitHub, tener un ciclo de desarrollo local rápido puede garantizar que los desarrolladores puedan probar y desplegar sus cambios en un clúster local.
Así, Google Cloud proporciona Cloud Code. Cloud Code incluye extensiones para IDEs, como Visual Studio Code e Intellij, que permiten que los desarrolladores iteren, depuren y ejecuten código en Kubernetes rápidamente. Cloud Code recurre en segundo plano a herramientas populares (como Skaffold, Jib y kubectl) que permiten que los desarrolladores tengan comentarios sobre el código de forma continua y en tiempo real.
Integración continua: con la nueva aplicación de GitHub para Cloud Build, los equipos pueden activar compilaciones en diferentes eventos de repositorio: solicitudes de extracción, ramas o eventos de etiquetas directamente desde GitHub. Cloud Build es una plataforma completamente sin servidor y se escala y desescala verticalmente en respuesta a la carga sin necesidad de aprovisionar previamente los servidores o pagar por adelantado para tener más capacidad. Las compilaciones activadas a través de la aplicación GitHub publican automáticamente el estado en GitHub. La información recibida se integra directamente en el flujo de trabajo de los desarrolladores de GitHub, lo que reduce el cambio de contexto.
Gestión de artefactos: Container Registry es un lugar único para que tu equipo pueda gestionar imágenes Docker, analizar vulnerabilidades y decidir quién tiene acceso a qué elementos con un control de acceso pormenorizado. La integración del análisis de vulnerabilidades con Cloud Build permite que los desarrolladores identifiquen amenazas de seguridad tan pronto como Cloud Build cree una imagen y la almacene en el Container Registry.
Entrega continua: Cloud Build usa los pasos de compilación para que puedas definir los pasos específicos que deben seguirse para compilar, probar y desplegar. Por ejemplo, cuando se haya creado un nuevo contenedor y se haya enviado a Container Registry, un paso de compilación posterior puede desplegar ese contenedor en Google Kubernetes Engine (GKE) o Cloud Run, junto con su configuración y política. También puedes desplegar en otros proveedores de servicios en la nube en caso de que estés siguiendo una estrategia multinube. Finalmente, si te interesa ofrecer una entrega continua al estilo de GitOps, Cloud Build te permite describir los despliegues de manera declarativa usando archivos (por ejemplo, archivos de manifiesto de Kubernetes) almacenados en un repositorio de Git.
Sin embargo, desplegar código no es el final. Las organizaciones también necesitan administrar ese código mientras se ejecuta. Para ello, Google Cloud proporciona a los equipos de operaciones herramientas, como Cloud Monitoring y Cloud Logging.
Es cierto que no es necesario usar las herramientas de CI/CD de Google con GKE; puedes usar cadenas de herramientas alternativas si prefieres. Los ejemplos incluyen aprovechar Jenkins para CI/CD o Artifactory para la gestión de artefactos.
Si eres como la mayoría de las organizaciones con aplicaciones en la nube basadas en máquinas virtuales, probablemente no tengas un sistema de CI/CD bien engrasado. Desplegar uno es una parte esencial para obtener beneficios de la aplicación rediseñada, pero requiere trabajo. Las tecnologías necesarias para crear flujo de procesamiento ya están disponibles, gracias en parte a la madurez de Kubernetes. Pero los cambios humanos pueden ser sustanciales. El personal de tus equipos de entrega debe ser multifuncional, con capacidades de desarrollo, pruebas y operaciones. Cambiar la cultura lleva tiempo, así que prepárate para dedicar esfuerzos a cambiar el conocimiento y los comportamientos de tu gente a medida que se trasladan a un mundo de CI/CD.
Centrarse en la seguridad
Rediseñar las aplicaciones monolíticas hacia un paradigma nativo de la nube es un gran cambio. Como era de esperar, presenta nuevos retos de seguridad a los que habrá que enfrentarse. Dos de los retos más importantes son:
- Asegurar el acceso entre contenedores
- Garantizar una cadena de suministro de software segura
El primero de estos retos surge de un hecho obvio: dividir su aplicación en servicios en contenedores (y quizás microservicios) requiere de alguna forma para que esos servicios se comuniquen. Y aunque potencialmente todos se ejecutan en el mismo clúster de Kubernetes, aún debes preocuparte por controlar el acceso entre ellos. Después de todo, es posible que estés compartiendo ese clúster de Kubernetes con otras aplicaciones y no puedes dejar los contenedores abiertos a estas otras aplicaciones.
Controlar el acceso a un contenedor requiere autenticar a los llamadores y luego determinar qué 17 solicitudes están autorizados a realizar estos otros contenedores. Hoy en día, es típico resolver este problema (y varios otros) mediante el uso de una malla de servicios. Un ejemplo destacado de esto es Istio, un proyecto de código abierto creado por Google, IBM y otros colaboradores. La Figura 7 muestra dónde encaja Istio en un clúster de Kubernetes.
Como muestra la figura, el proxy de Istio intercepta todo el tráfico entre contenedores en su aplicación. Esto permite que la malla de servicios proporcione varios servicios útiles sin ningún cambio en el código de su aplicación. Entre ellos se incluyen:
- Seguridad, con autenticación de servicio a servicio mediante TLS y autenticación de usuario final
- Gestión de tráfico, que te permite controlar cómo se enrutan las solicitudes entre los contenedores en la aplicación
- Observabilidad, captura de registros y métricas de comunicación entre tus contenedores
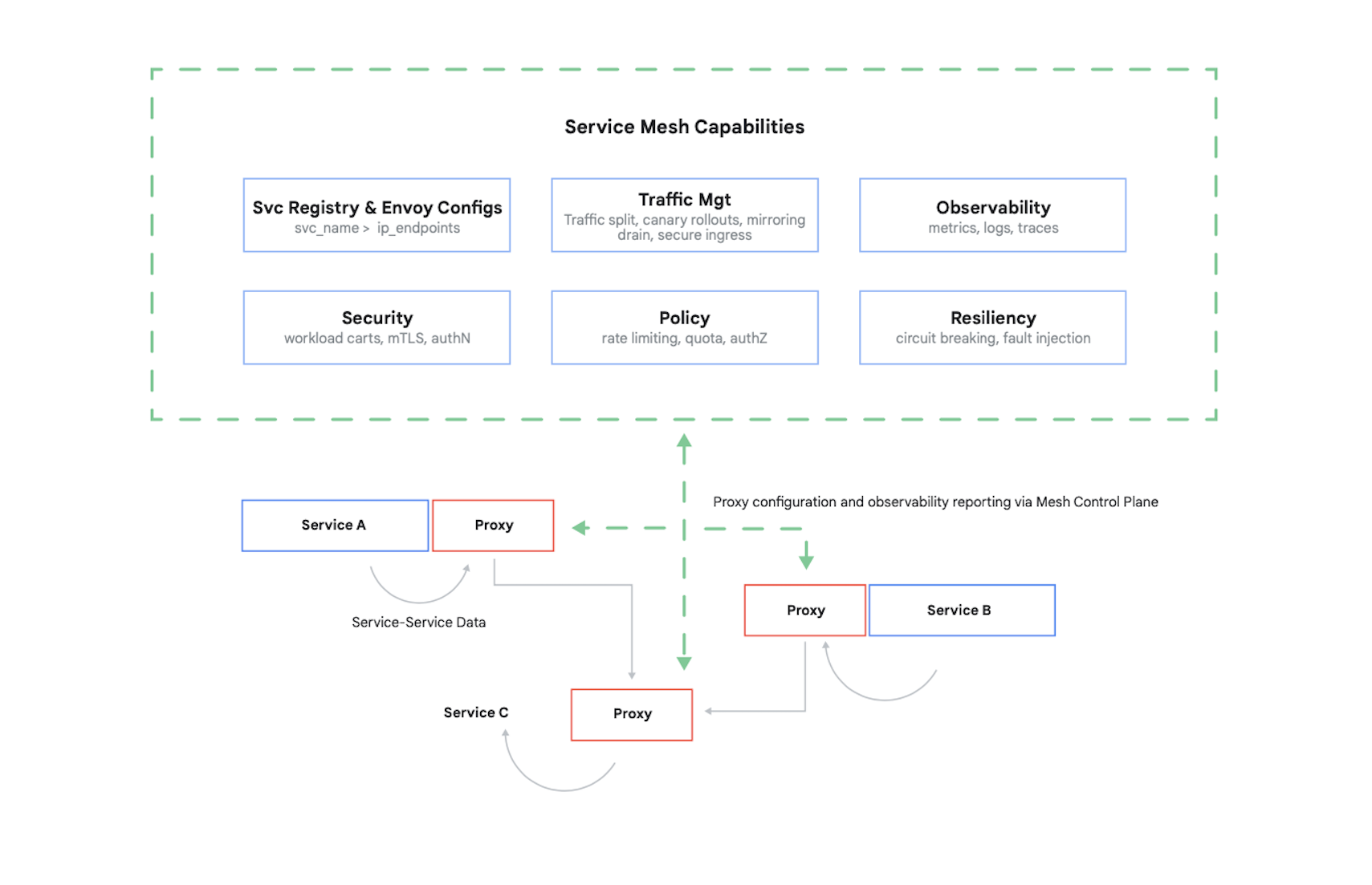
Google Cloud te permite añadir Istio a un clúster de GKE. Y aunque no sea necesario utilizar una malla de servicios, no te sorprendas si los clientes conocedores de tus aplicaciones en la nube comienzan a preguntarse si tu seguridad está al nivel que ofrece Istio. Los clientes se preocupan profundamente por la seguridad y, en un mundo basado en contenedores, Istio es una parte importante de su provisión.
Además de admitir Istio de código abierto, Google Cloud ofrece Traffic Director, un plano de control de malla de servicios completamente gestionado por Google Cloud que ofrece balanceo de carga global entre clústeres e instancias de máquinas virtuales en múltiples regiones, descarga la comprobación de estado de los proxies de servicio y proporciona una gestión de tráfico sofisticada y otras capacidades descritas anteriormente.
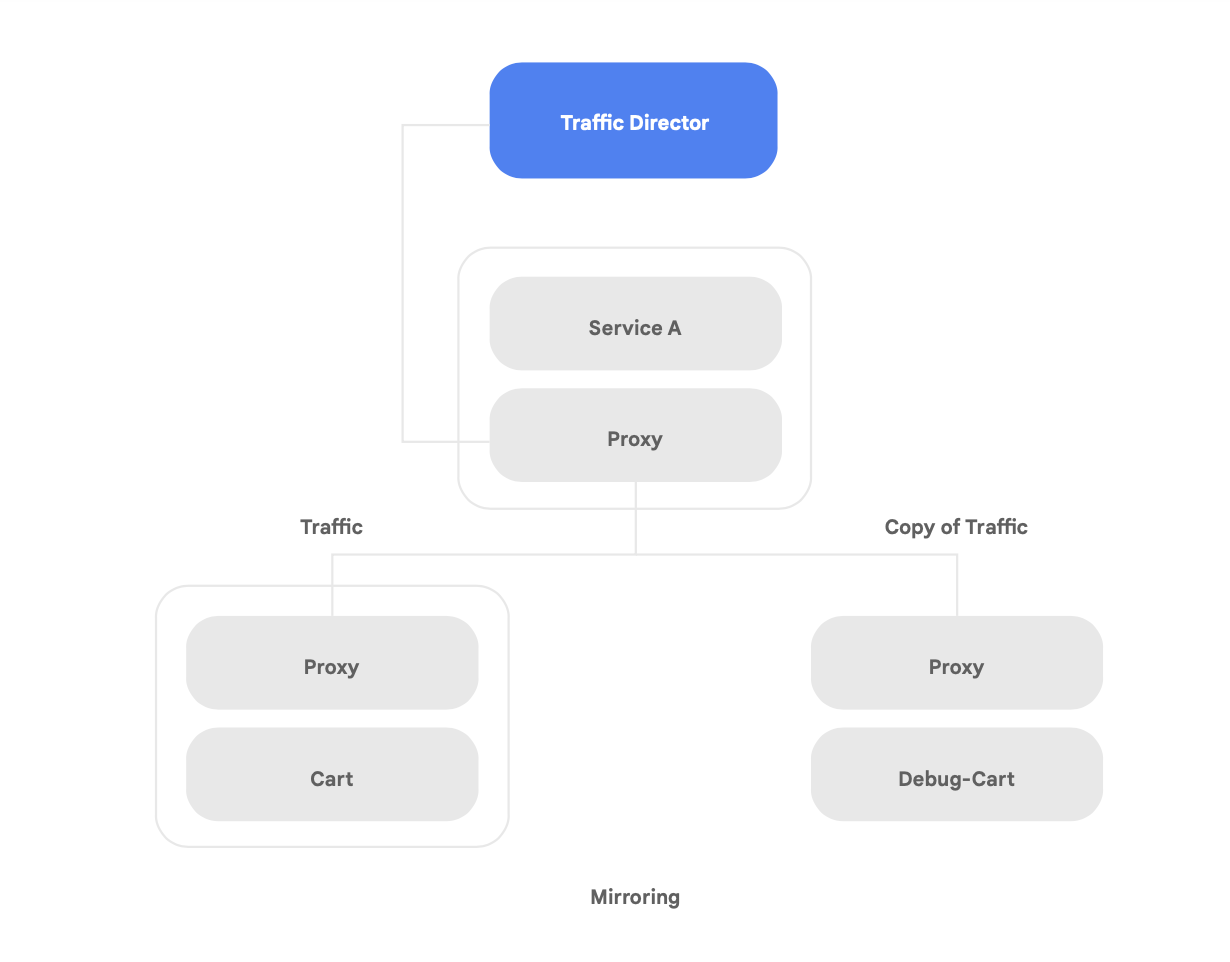
Una de las capacidades únicas de Traffic Director es la conmutación por error y el desbordamiento automáticos entre regiones para los microservicios en la malla (que se muestra en la Figura 8).
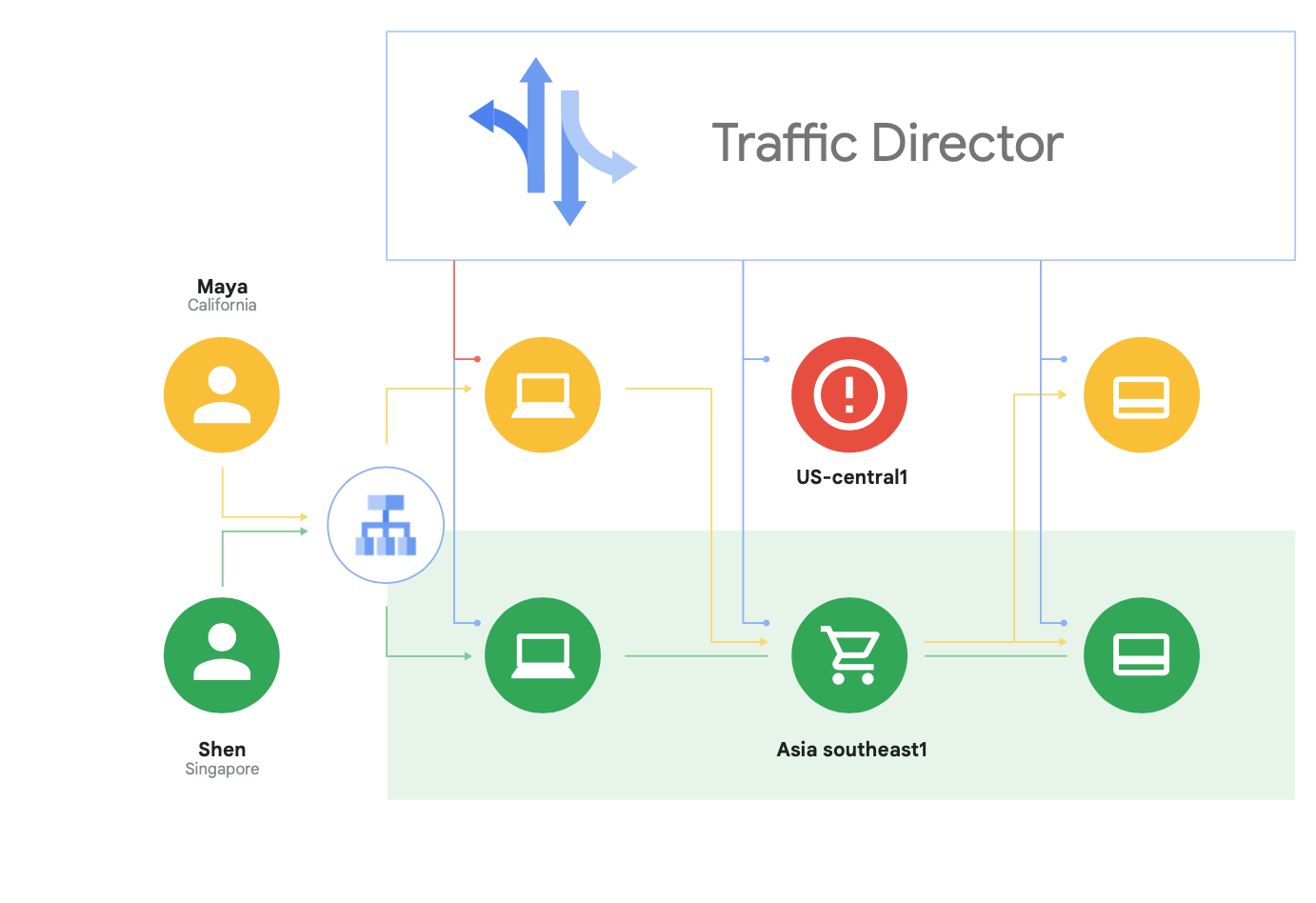
Puedes combinar la resiliencia global con la seguridad de tus servicios en la malla de servicios utilizando esta capacidad.
Traffic Director ofrece varias funciones de gestión del tráfico que pueden ayudar a mejorar la postura de seguridad de la malla de servicios. Por ejemplo, la función de proyección de tráfico que se muestra en la Figura 9 se puede configurar fácilmente como una política para permitir que una aplicación en la sombra reciba una copia del tráfico real que está procesando la versión principal de la aplicación. Las respuestas de copia recibidas por el servicio de sombra se descartan después del procesamiento. La proyección de tráfico puede ser una herramienta poderosa para probar anomalías de seguridad y depurar errores en el tráfico de producción sin afectarlo o tocarlo.
Pero proteger las interacciones entre tus contenedores no es el único reto de seguridad nuevo que trae una aplicación refactorizada. Otra preocupación es asegurarse de que las imágenes de contenedor que ejecutas sean fiables. Para ello, debes asegurarte de que tu cadena de suministro de software tenga funciones integradas de seguridad y cumplimiento normativo.
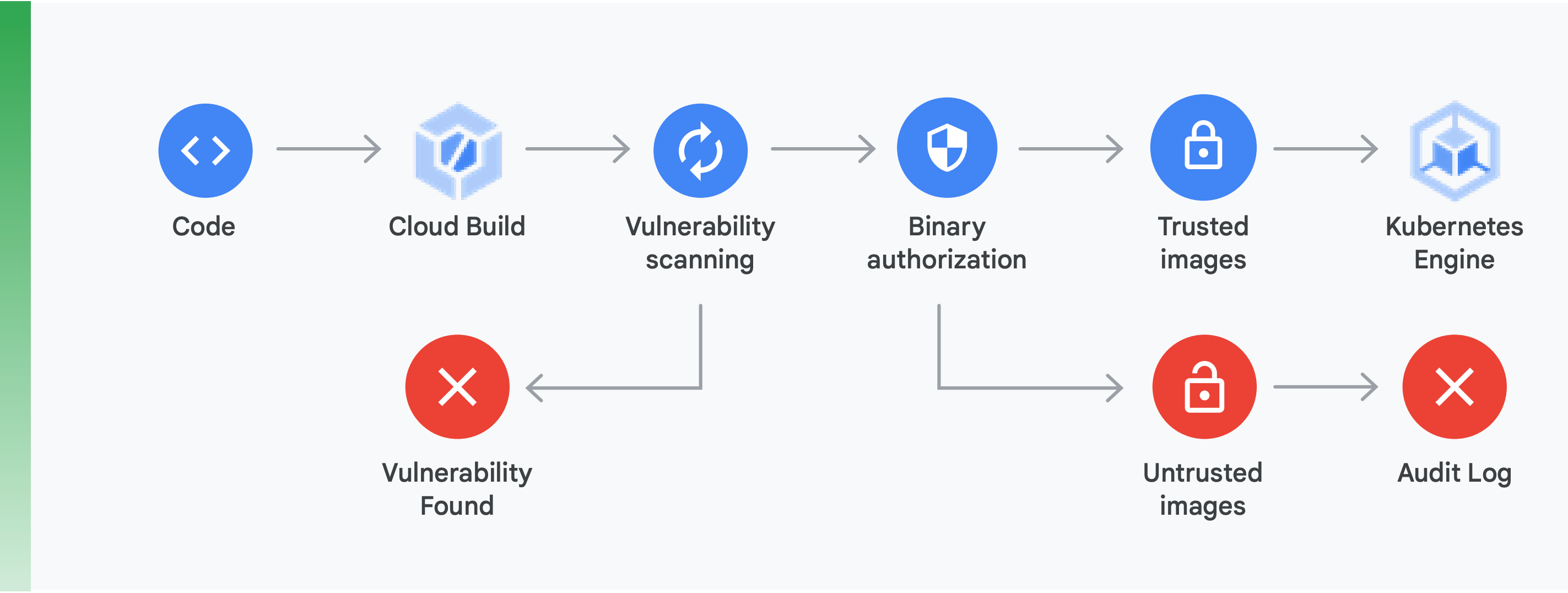
Hacer esto requiere hacer dos cosas principales (que se muestran en la Figura 10):
Análisis de vulnerabilidades: el análisis de vulnerabilidades de Container Registry te permite recibir información rápida sobre posibles amenazas e identificar problemas tan pronto como Cloud Build crea tus contenedores y los almacena en Container Registry. Las vulnerabilidades de los paquetes para Ubuntu, Debian y Alpine se identifican justo durante el proceso de desarrollo de la aplicación, con soporte para CentOS y RHEL en camino. Esto ayuda a evitar costosas ineficiencias y reduce el tiempo necesario para remediar las vulnerabilidades que ya se conocen.
Autorización binaria: al integrar la autorización binaria y el análisis de vulnerabilidades de Container Registry, puedes controlar los despliegues en función de lo que se encuentre en el análisis de vulnerabilidades como parte de la política de despliegue general. La autorización binaria es un control de seguridad en el momento del despliegue que garantiza que solo se desplieguen imágenes de contenedores fiables en GKE sin intervención manual.
Asegurar el acceso entre contenedores con una malla de servicio y garantizar una cadena de suministro de software segura son aspectos importantes en la creación de aplicaciones seguras basadas en contenedores. Hay muchas más, incluida la verificación de la seguridad de la infraestructura de la plataforma en la nube que estás construyendo. Sin embargo, lo más importante es darse cuenta de que pasar de una aplicación monolítica a un paradigma moderno nativo de la nube presenta nuevos retos de seguridad. Para llevar correctamente a cabo esta transición, deberás comprender cuáles son y luego crear un plan concreto para abordar cada uno de ellos.
Primeros pasos
No trates el cambio a una arquitectura nativa de la nube como un gran proyecto de varios años.
En vez de eso, empieza ahora a buscar un equipo con la capacidad y la experiencia necesaria para empezar con una prueba de concepto, o encuentra una que ya hayas hecho. Luego, toma las lecciones aprendidas y empieza a difundirlas por toda la organización. Consigue que los equipos adopten el patrón Strangler Fig, cambiando los servicios de manera incremental e iterativa hacia una arquitectura nativa de la nube a medida que sigan ofreciendo nuevas funcionalidades.
Para tener éxito, es esencial que los equipos tengan la capacidad, los recursos y la autoridad para hacer que la evolución de la arquitectura de sus sistemas sea parte de su trabajo diario. Define objetivos arquitectónicos claros para el nuevo trabajo, siguiendo los seis resultados arquitectónicos presentados anteriormente, pero dales a los equipos la libertad de decidir cómo llegar ahí.
Lo más importante de todo es que no esperes para empezar. Aumentar la productividad y la agilidad de tus equipos y la seguridad y estabilidad de tus servicios será cada vez más importante para el éxito de tu organización. Los equipos que obtienen mejores resultados son los que hacen que la experimentación y mejora disciplinada sea parte de su trabajo diario.
Google inventó Kubernetes, basándose en software que hemos utilizado internamente durante años, por lo que tenemos la experiencia más profunda con tecnología nativa de la nube.
Google Cloud tiene un fuerte enfoque en aplicaciones en contenedores, como lo demuestran nuestras ofertas de seguridad y CI/CD. La verdad está clara: Google Cloud es el líder actual en soporte para aplicaciones en contenedores.
Visita cloud.google.com/devops para realizar nuestra revisión rápida, saber cómo te va y tener consejos sobre cómo proceder, incluyendo el despliegue de los patrones que se analizan en este informe técnico, como una arquitectura con bajo acoplamiento.
Muchos partners de Google Cloud ya han ayudado a organizaciones como la tuya a realizar esta transición. ¿Por qué abrir un camino de reestructuración por tu cuenta cuando podemos ponerte en contacto con un guía experimentado?
Para empezar, ponte en contacto con nosotros para concertar una reunión con un arquitecto de soluciones de Google. Podemos ayudarte a comprender el cambio y luego trabajar contigo para que suceda.
Más información
https://cloud.google.com/devops - Seis años del informe State of DevOps, un conjunto de artículos con información detallada sobre las capacidades que predicen el rendimiento del envío de software y una comprobación rápida para ayudarte a descubrir cómo te va y cómo mejorar.
Site Reliability Engineering: cómo gestiona Google los sistemas de producción (O'Reilly 2016)
La hoja de cálculo sobre fiabilidad del sitio: maneras prácticas de desplegar SRE (O'Reilly 2018)
"Cómo dividir un monolito en microservicios: qué desacoplar y cuándo", de Zhamak Dehghani
Microservicios: una definición de ese nuevo término arquitectónico", de Martin Fowler
"Aplicación Strangler Fig", de Martin Fowler
¿Todo listo para dar los siguientes pasos?
Rellena el formulario y nos pondremos en contacto contigo. Contactar con Ventas


















