Auf eine cloudnative Umgebung setzen
Forschungsergebnisse von DevOps Research and Assessment (DORA) zeigen, dass besonders leistungsfähige DevOps-Teams mehrmals am Tag bereitstellen, Änderungen in Produktionsumgebungen in weniger als 24 Stunden veröffentlichen und eine Änderungsausfallrate von 0 bis 15 % vorweisen.
In diesem Whitepaper erfahren Sie, wie Sie Ihre Anwendungen auf ein cloudnatives Modell umstellen. Damit lassen sich neue Features auch dann schneller bereitstellen, wenn Sie Ihre Teams noch erweitern. Außerdem können Sie zusätzlich die Softwarequalität verbessern sowie eine höhere Stabilität und Verfügbarkeit erzielen.
Warum zu einer cloudnativen Architektur wechseln?
Viele Unternehmen erstellen ihre benutzerdefinierten Softwaredienste mithilfe von monolithischen Architekturen. Dieser Ansatz bietet gewisse Vorteile: Monolithische Systeme lassen sich relativ leicht entwerfen und bereitstellen – zumindest anfangs. Wenn die Anwendungen jedoch zunehmend komplexer werden, kann es schwierig werden, das Produktivitätslevel der Entwickler:innen und die Deployment-Geschwindigkeit aufrechtzuerhalten. Das wiederum macht es teuer und zeitaufwendig, diese Systeme zu verändern, und risikoreich, sie bereitzustellen.
Wenn der Umfang von Diensten – und der dafür zuständigen Teams – zunimmt, werden sie meist komplexer und es wird schwieriger, sie weiterzuentwickeln und einzusetzen. Das macht es mühsamer, sie zu testen und bereitzustellen, und schwieriger, neue Features hinzuzufügen. Für Verlässlichkeit und Verfügbarkeit zu sorgen kann zu einer wahren Herausforderung werden.
Laut Untersuchungen des DORA-Teams von Google ist es für Organisationen aller Größen und Branchen möglich, bei der Softwarebereitstellung hohe Durchsatzraten sowie ein hohes Maß an Dienststabilität und -verfügbarkeit zu erzielen. Besonders leistungsfähige Teams stellen mehrmals am Tag bereit, veröffentlichen Änderungen in Produktionsumgebungen in weniger als einem Tag, stellen Dienste in weniger als einer Stunde wieder her und weisen eine Änderungsausfallrate von nur 0 bis 15 % vor.1
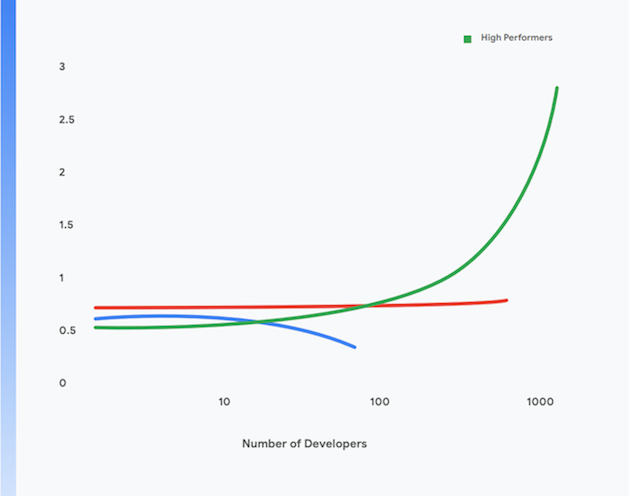
Darüber hinaus schaffen es leistungsstarke Entwicklerinnen und Entwickler, selbst dann noch ein höheres Maß an Produktivität zu erzielen, wenn ihre Teams größer werden. Ihre Produktivität wird dabei an den Deployments pro Entwickler:in pro Tag gemessen. Dies ist in Abbildung 1 dargestellt.
Im restlichen Teil dieser Seite geht es darum, wie Sie Ihre Anwendungen in ein modernes cloudnatives Modell migrieren, um diesen Zielen näher zu kommen. Indem Sie die technischen Best Practices implementieren, die im weiteren Verlauf beschrieben sind, können Sie folgende Ziele erreichen:
- Gesteigerte Produktivität der Entwickler*innen, selbst dann, wenn die Anzahl der Teammitglieder zunimmt.
- Kürzere Produkteinführungszeit: Neue Features schneller hinzufügen und Probleme schneller beheben.
- Höhere Verfügbarkeit: Verfügbarkeit Ihrer Software erhöhen, Quote fehlgeschlagener Deployments senken und Zeit bis zur Wiederherstellung nach Vorfällen verkürzen.
- Verbesserte Sicherheit: Angriffsfläche Ihrer Anwendungen verkleinern und es leichter machen, Angriffe und Sicherheitslücken schneller zu erkennen und darauf zu reagieren.
- Bessere Skalierbarkeit: Mit cloudnativen Plattformen und Anwendungen leicht horizontal skalieren, falls nötig, und auch problemlos herunterskalieren.
- Geringere Kosten: Durch einen optimierten Prozess zur Softwarebereitstellung neue Features günstiger bereitstellen sowie Cloud-Plattformen effizient verwenden, um deutlich geringere Dienstbetriebskosten zu erzielen.
1 Unter folgendem Link können Sie herausfinden, wie Ihr Team in Bezug auf diese vier wichtigen Messwerte abschneidet: https://cloud.google.com/devops/
Was ist mit einer cloudnativen Architektur gemeint?
Monolithische Anwendungen müssen als eine Einheit erstellt, getestet und bereitgestellt werden. Häufig werden das Betriebssystem, die Middleware und der Sprach-Stack speziell an die Anwendung angepasst oder für jede Anwendung benutzerdefiniert konfiguriert. Außerdem gibt es für jede Anwendung meist eigene Build-, Test- und Deployment-Skripts und -prozesse. Das ist bei Greenfield-Anwendungen einfach und effektiv, aber wenn ihr Umfang weiter zunimmt, wird es schwieriger, solche Systeme zu ändern, zu testen, bereitzustellen und einzusetzen.
Hinzu kommt, dass mit größer werdenden Systemen auch der Umfang und die Komplexität der Teams zunimmt, die die Dienste erstellen, testen, bereitstellen und einsetzen. Ein gängiger, aber nicht empfehlenswerter Ansatz lautet, die Teams den einzelnen Funktionen zuzuordnen. Das bedingt jedoch Übergaben zwischen den einzelnen Teams, was tendenziell dazu führt, dass die für die Auftragsbearbeitung benötigte Zeit und die Batchgrößen zunehmen – genau wie die Menge an Revisionen. Aus den Studien von DORA geht hervor, dass leistungsstarke Teams Software mit doppelt so hoher Wahrscheinlichkeit als funktionsübergreifendes Team entwickeln und ausliefern.
Zu den Symptomen dieses Problems zählen unter anderem:
- Lange, häufig fehlerhafte Build-Prozesse
- Unregelmäßige Integrations- und Testzyklen
- Mehr Aufwand für die Unterstützung von Build- und Testprozessen
- Produktivitätsverluste der Entwickler:innen
- Mühsame Deployment-Prozesse, die außerhalb der Geschäftszeiten durchgeführt werden müssen, was geplante Ausfallzeiten erfordert
- Enorm aufwendige Konfigurationsverwaltung der Test- und Produktionsumgebungen
Beim cloudnativen Modell sieht es dagegen so aus:³
- Komplexe Systeme werden in Dienste zerlegt, die unabhängig voneinander auf einer containerisierten Laufzeit (einer mikrodienstbasierten oder dienstorientierten Architektur) getestet und bereitgestellt werden können.
- Die Anwendungen verwenden von der Plattform bereitgestellte Standarddienste wie Systeme zur Datenbankverwaltung (Database Management Systems, DBMS), Dienste zum Speichern von Blobs, für das Messaging, für das CDN und für die SSL-Terminierung.
- Eine standardisierte Cloud-Plattform übernimmt viele für den Betrieb wichtige Aufgaben wie das Deployment, das Autoscaling, das Konfigurieren, das Verwalten von Secrets, das Monitoring und das Senden von Benachrichtigungen. Auf diese Dienste können die Teams bei Bedarf für die Anwendungsentwicklung zugreifen.
- Für die Anwendungsentwickler:innen werden ein standardisiertes Betriebssystem, standardisierte Middleware und sprachspezifische Stacks bereitgestellt. Die Wartung und das Patchen dieser Stacks werden entweder vom Plattformanbieter oder einem separaten Team „Out-of-Band“ durchgeführt.
- Ein funktionsübergreifendes Team kann für den ganzen Softwarebereitstellungszyklus aller Dienste verantwortlich sein.
3 Das ist keine erschöpfende Erklärung des Begriffs „cloudnativ“: Eine Erörterung einiger der Prinzipien der cloudnativen Architektur finden Sie unter https://cloud.google.com/blog/products/ application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it.
Dieses Modell bietet viele Vorteile:
Schnellere Bereitstellung | Verlässliche Releases | Geringere Kosten |
Da die Dienste jetzt klein und lose gekoppelt sind, können die zuständigen Teams unabhängig voneinander arbeiten. Dies erhöht die Produktivität der Entwickler:innen und die Bereitstellungsgeschwindigkeit. | Entwickler:innen können neue und vorhandene Dienste schnell auf produktionsähnlichen Testumgebungen erstellen, testen und bereitstellen. Das Bereitstellen in der Produktionsumgebung ist auch ein leichter, atomarer Vorgang. Dadurch wird der Softwarebereitstellungsprozess deutlich beschleunigt und das Risiko von Deployments gesenkt. | Die Kosten und die Komplexität der Test- und Produktionsumgebungen sind deutlich geringer, da die Plattform gemeinsam genutzte, standardisierte Dienste bereitstellt und Anwendungen in einer gemeinsam genutzten physischen Infrastruktur ausgeführt werden. |
Mehr Sicherheit | Höhere Verfügbarkeit | Einfachere, kostengünstigere Compliance |
Die Anbieter sind jetzt dafür verantwortlich, dass gemeinsam genutzte Dienste wie DBMS und die Messaging-Infrastruktur aktuell und konform sind und über die neuesten Patches verfügen. Gleichzeitig ist es viel einfacher, Anwendungen gepatcht und auf dem neuesten Stand zu halten, da eine standardisierte Methode zum Bereitstellen und Verwalten von Anwendungen existiert. | Die Verfügbarkeit und Zuverlässigkeit der Anwendungen erhöhen sich, da die Betriebsumgebung weniger komplex ist, Konfigurationsänderungen leicht vorgenommen und Autoscaling sowie die automatische Reparatur auf Plattformebene erledigt werden können. | Die meisten Maßnahmen zur Informationssicherheit können auf Plattformebene implementiert werden, sodass sich Compliance deutlich günstiger und leichter umsetzen und nachweisen lässt. Viele Cloud-Anbieter wahren die Compliance mithilfe von Risikomanagement-Frameworks wie SOC2 und FedRAMP. Das bedeutet, dass Anwendungen, die auf diesen bereitgestellt werden, nur Compliance mit den verbleibenden nicht auf der Plattformebene implementierten Maßnahmen nachweisen müssen. |
Schnellere Bereitstellung
Verlässliche Releases
Geringere Kosten
Da die Dienste jetzt klein und lose gekoppelt sind, können die zuständigen Teams unabhängig voneinander arbeiten. Dies erhöht die Produktivität der Entwickler:innen und die Bereitstellungsgeschwindigkeit.
Entwickler:innen können neue und vorhandene Dienste schnell auf produktionsähnlichen Testumgebungen erstellen, testen und bereitstellen. Das Bereitstellen in der Produktionsumgebung ist auch ein leichter, atomarer Vorgang. Dadurch wird der Softwarebereitstellungsprozess deutlich beschleunigt und das Risiko von Deployments gesenkt.
Die Kosten und die Komplexität der Test- und Produktionsumgebungen sind deutlich geringer, da die Plattform gemeinsam genutzte, standardisierte Dienste bereitstellt und Anwendungen in einer gemeinsam genutzten physischen Infrastruktur ausgeführt werden.
Mehr Sicherheit
Höhere Verfügbarkeit
Einfachere, kostengünstigere Compliance
Die Anbieter sind jetzt dafür verantwortlich, dass gemeinsam genutzte Dienste wie DBMS und die Messaging-Infrastruktur aktuell und konform sind und über die neuesten Patches verfügen. Gleichzeitig ist es viel einfacher, Anwendungen gepatcht und auf dem neuesten Stand zu halten, da eine standardisierte Methode zum Bereitstellen und Verwalten von Anwendungen existiert.
Die Verfügbarkeit und Zuverlässigkeit der Anwendungen erhöhen sich, da die Betriebsumgebung weniger komplex ist, Konfigurationsänderungen leicht vorgenommen und Autoscaling sowie die automatische Reparatur auf Plattformebene erledigt werden können.
Die meisten Maßnahmen zur Informationssicherheit können auf Plattformebene implementiert werden, sodass sich Compliance deutlich günstiger und leichter umsetzen und nachweisen lässt. Viele Cloud-Anbieter wahren die Compliance mithilfe von Risikomanagement-Frameworks wie SOC2 und FedRAMP. Das bedeutet, dass Anwendungen, die auf diesen bereitgestellt werden, nur Compliance mit den verbleibenden nicht auf der Plattformebene implementierten Maßnahmen nachweisen müssen.
Mit dem cloudnativen Modell sind jedoch auch gewisse Abstriche in Kauf zu nehmen:
- Alle Anwendungen sind jetzt verteilte Systeme. Sie führen also im Rahmen ihrer Funktionsweise eine relative hohe Anzahl an Remoteaufrufen aus. Das bedeutet, dass Sie sich sorgfältig überlegen sollten, wie mit Netzwerkfehlern und Leistungsproblemen umgegangen werden soll und wie Probleme in der Produktionsumgebung debuggt werden sollen.
- Entwickler:innen müssen das standardisierte Betriebssystem, die standardisierte Middleware und die standardisierten Anwendungs-Stacks der Plattform verwenden. Das erschwert die lokale Entwicklung.
- Architekt:innen müssen für das Entwerfen von Systemen auf einen ereignisgesteuerten Ansatz setzen und auch die Eventual Consistency bereitwillig akzeptieren.
Zu cloudnativer Architektur migrieren
Viele Organisationen verfolgen für das Verschieben von Diensten in die Cloud einen Lift-and-Shift-Ansatz. Bei diesem Ansatz müssen an den Systemen nur kleine Änderungen vorgenommen werden und die Cloud wird im Grunde wie ein herkömmliches Rechenzentrum behandelt, das jedoch vergleichsweise deutlich bessere APIs, Dienste und Managementtools bietet. Der Lift-and-Shift-Vorgang allein bietet jedoch keinen der Vorteile des oben beschriebenen cloudnativen Modells.
Viele Organisationen zögern beim Lift-and-Shift-Vorgang, da es ein teurer und komplexer Prozess ist, ihre Anwendungen in eine cloudnative Architektur zu verschieben: Von der Anwendungsarchitektur über Produktionsvorgänge bis hin zum Softwarebereitstellungszyklus muss eine Reihe von Bereichen neu überdacht werden. Und die Angst ist nicht ganz unbegründet: Zahlreiche große Organisationen haben sich an fehlgeschlagenen mehrjährigen „Big-Bang“-Migrationen in Sachen Plattformwechsel die Finger verbrannt.
Die Lösung ist, Ihre Systeme mit einem inkrementellen, iterativen und evolutionären Ansatz in ein cloudnatives Modell zu überführen, sodass Ihre Teams lernen, wie sie mit diesem neuen Modell effektiv arbeiten und dennoch weiterhin neue Funktionen liefern können. Diesen Ansatz nennen wir „Move-and-Improve“.
Ein Schlüsselmuster der Evolutionsarchitektur ist als Strangler Fig Application4 bekannt. Anstatt Systeme von Grund auf umzuschreiben, schreiben Sie damit auf moderne, cloudnative Weise neue Funktionen, die dennoch mit der ursprünglichen monolithischen Anwendung in Kontakt stehen, um vorhandene Funktionen aufrecht zu erhalten. Sie verschieben die bestehenden Funktionen dann im Laufe der Zeit nach und nach, so wie es für die konzeptionelle Integrität der neuen Dienste erforderlich ist. In Abbildung 2 wird dieser Ansatz dargestellt.
4 Beschrieben unter https://martinfowler.com/bliki/StranglerFigApplication.html
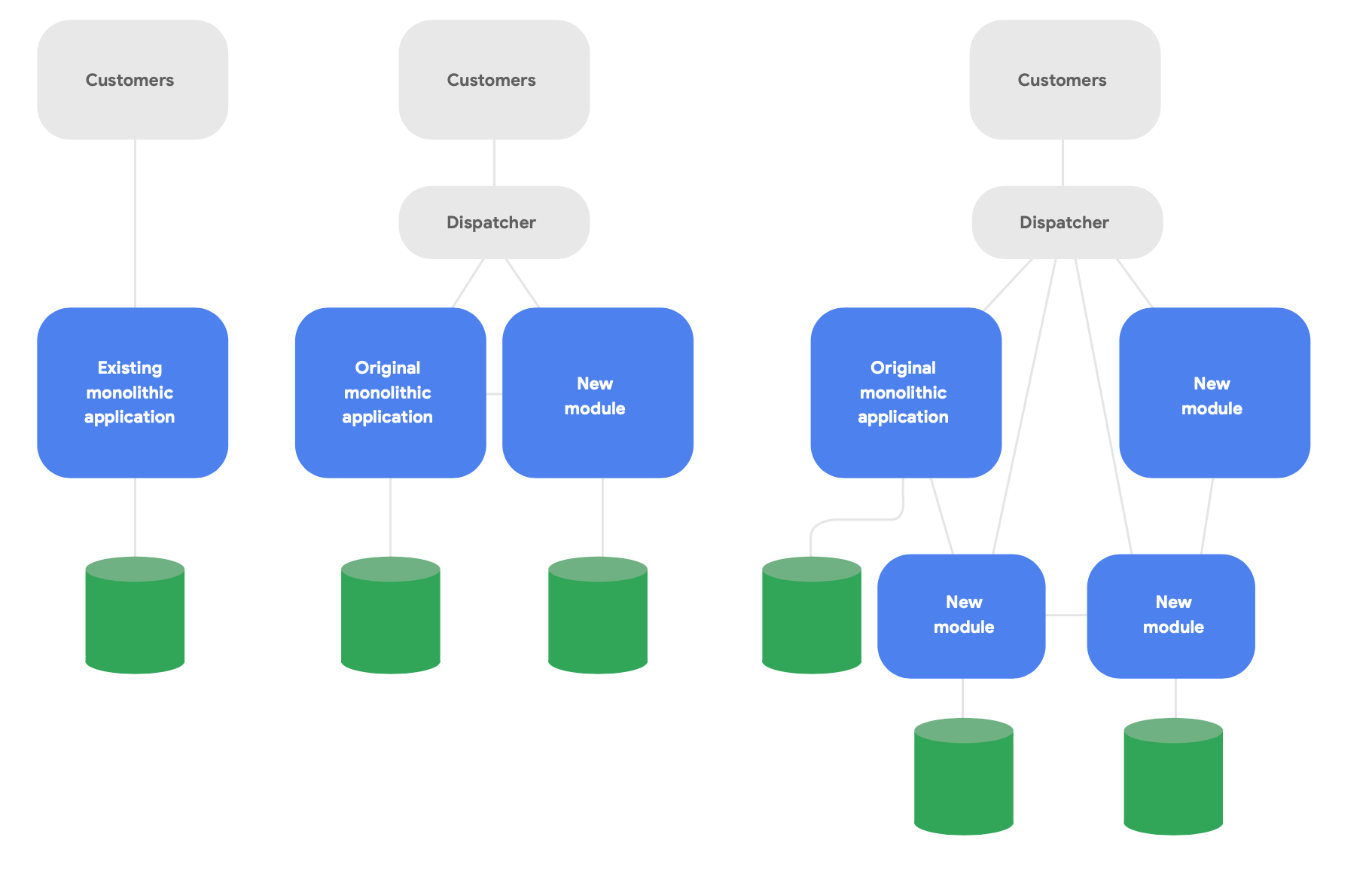
Im Folgenden finden Sie drei wichtige Leitlinien zum erfolgreichen Umgestalten:
Zuerst konzentrieren Sie sich am besten darauf, schnell neue Funktionen zu liefern, statt die vorhandenen zu reproduzieren. Der wichtigste Messwert ist, wie bald Sie damit beginnen können, neue Funktionen mithilfe neuer Dienste bereitzustellen. Sie sollten sich schnell mit der Arbeit in diesem Modell vertraut machen und in der Lage sein, daraus gewonnene Ansätze weiterzugeben. Schrauben Sie den Umfang drastisch herunter, damit Sie Ihren Endnutzer*innen in Wochen statt Monaten etwas Greifbares bieten können.
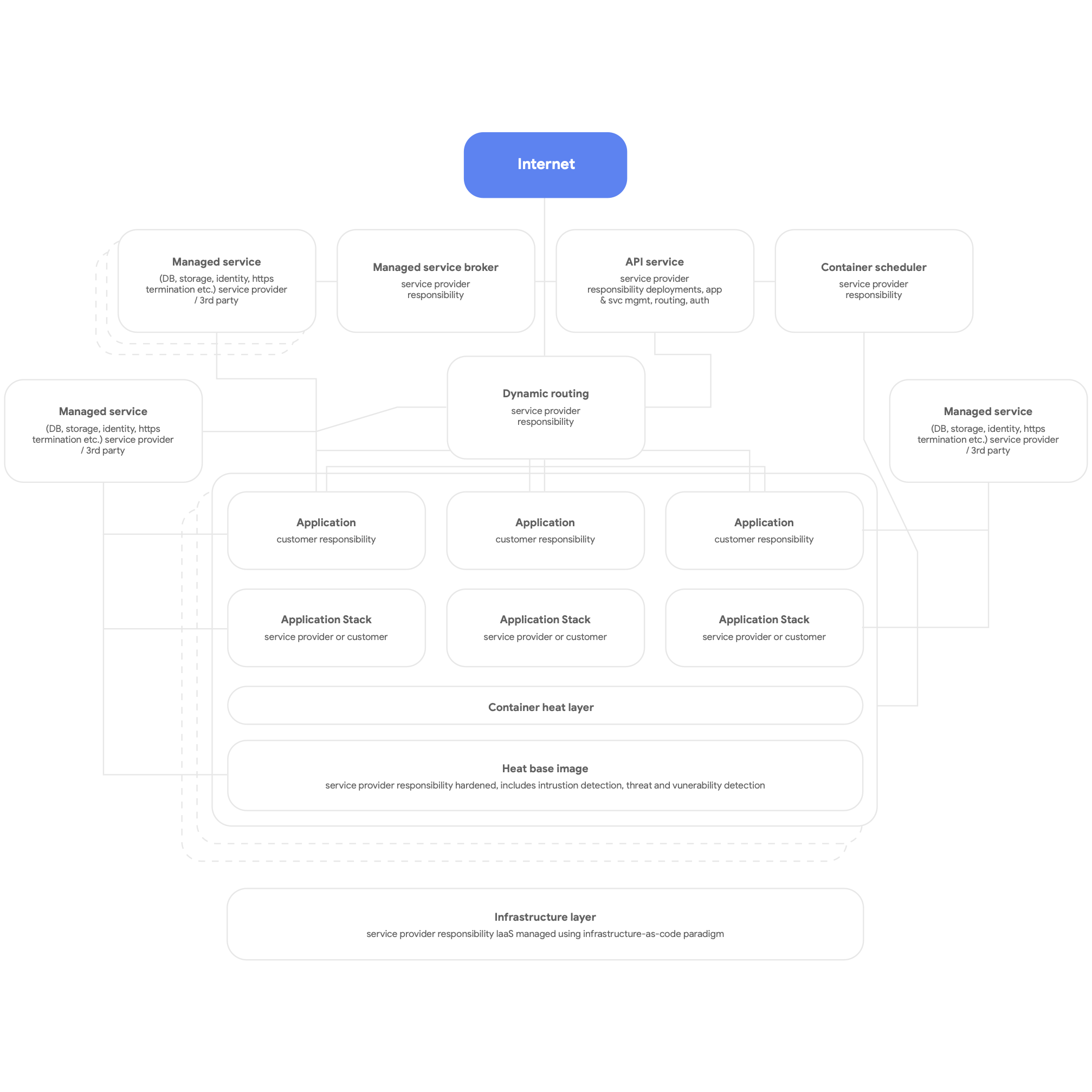
Danach entwickeln Sie Dienste für die cloudnative Architektur. Das bedeutet, dass Sie die nativen Dienste der Cloud-Plattform für DBMS, Messaging, das CDN, Netzwerke oder zum Speichern von Blobs nutzen und (wann immer möglich) standardisierte, von der Plattform bereitgestellte Anwendungs-Stacks verwenden. Die Dienste sollten containerisiert sein und nach Möglichkeit das serverlose Modell nutzen. Außerdem sollten die Build-, Test- und Bereitstellungsprozesse vollständig automatisiert sein. Alle Anwendungen sollten für Logging, Monitoring und Benachrichtigungen von der Plattform bereitgestellte, gemeinsam genutzte Dienste verwenden. Diese Art von Plattformarchitektur kann übrigens für jede mandantenfähige Anwendungsplattform gewinnbringend bereitgestellt werden, einschließlich einer lokalen Bare-Metal-Umgebung. Die folgende Abbildung 3 zeigt eine allgemeine schematische Darstellung einer cloudnativen Plattform.
Anschließend achten Sie bei der Entwicklung darauf, dass sie auf autonome, lose in Kontakt stehende Teams ausgerichtet ist, die ihre Dienste selbst testen und bereitstellen können. Aus unserer Forschung geht hervor, dass die wichtigsten Ergebnisse in puncto Architektur darin bestehen, ob die Softwarebereitstellungsteams folgende sechs Fragen mit „Ja“ beantworten können:
- Wir sind in der Lage, am Design unseres Systems umfangreiche Änderungen vorzunehmen, ohne die Erlaubnis einer Person einzuholen, die nicht unserem Team angehört.
- Wir können am Design unseres Systems umfangreiche Änderungen vornehmen, ohne darauf angewiesen zu sein, dass andere Teams an ihren Systemen Änderungen vornehmen und ohne dass für andere Teams ein beträchtlicher Arbeitsaufwand anfällt.
- Wir können unsere Arbeit abschließen, ohne mit Personen, die nicht unserem Team angehören, zu kommunizieren und ohne uns mit ihnen abzustimmen.
- Wir können unser Produkt bzw. unseren Dienst bei Bedarf bereitstellen und veröffentlichen, und zwar ungeachtet anderer Dienste, zu denen eine Abhängigkeit besteht.
- Wir können die meisten unserer Tests bei Bedarf durchführen, ohne dass eine integrierte Testumgebung erforderlich ist.
- Wir können Deployments während der normalen Geschäftszeiten vornehmen, ohne dass es zu nennenswerten Ausfallzeiten kommt.
Prüfen Sie regelmäßig, ob die Teams auf diese Ziele hinarbeiten, und legen Sie den Fokus darauf, sie zu erreichen. Das erfordert meistens, die Organisations- und Unternehmensarchitektur zu überdenken.
Am Erstellen, Testen und Bereitstellen von Software sind viele verschiedene Personengruppen beteiligt. Insbesondere ist es unverzichtbar, die Teams (einschließlich der Produktmanager:innen) so zu strukturieren, dass all ihre Mitglieder effektiv zusammenarbeiten und moderne Produktmanagementpraktiken verwenden können, um Dienste zu erstellen und weiterzuentwickeln. Dazu sind nicht zwingend Änderungen an der Organisationsstruktur nötig. Wenn diese Personen zusammen als Team und wenn möglich am gleichen Ort arbeiten, statt dass Entwickler*innen, Tester*innen und Release-Teams unabhängig voneinander agieren, kann sich das deutlich auf die Produktivität auswirken.
Aus unserer Forschung geht auch hervor, dass sich aufgrund des Umfangs, in dem die Teams diesen Aussagen zustimmten, gut vorhersagen ließ, ob sie eine hohe Softwareleistung erbringen konnten, also die Fähigkeit besaßen, mehrmals pro Tag zuverlässige, hochverfügbare Dienste bereitzustellen. Dies wiederum ermöglicht es leistungsstarken Teams, die Produktivität ihrer Entwickler*innen (gemessen an der Zahl der Deployments pro Entwickler*in pro Tag) auch dann zu erhöhen, wenn die Zahl der Beteiligten zunimmt.
Prinzipien und Praktiken
Mikrodienstarchitektur – Prinzipien und Best Practices
Wenn Sie auf eine mikrodienstbasierte oder dienstorientierte Architektur umsteigen, gibt es einige wichtige Prinzipien und Best Practices zu beachten. Es empfiehlt sich, sich von Anfang an genau daran zu halten, da es teurer ist, die entsprechenden Anpassungen später vorzunehmen.
- Jeder Dienst sollte sein eigenes Datenbankschema haben. Egal, ob Sie eine relationale Datenbank oder eine NoSQL-Lösung verwenden, jeder Dienst sollte sein eigenes Schema haben, auf das kein anderer Dienst zugreift. Wenn mehrere Dienste mit demselben Schema kommunizieren, sind sie nach einer Weile auf der Datenbankebene eng gekoppelt. Diese Abhängigkeiten verhindern, dass Dienste unabhängig voneinander getestet und bereitgestellt werden können, wodurch sie schwerer zu ändern sind und es riskanter wird, sie bereitzustellen.
- Dienste sollten nur mithilfe ihrer öffentlichen APIs über das Netzwerk kommunizieren. Alle Dienste sollten ihr Verhalten über öffentliche APIs verfügbar machen und nur über diese APIs miteinander kommunizieren. Es sollte kein „Hintertür“-Zugriff möglich sein oder dass Dienste direkt mit den Datenbanken anderer Dienste kommunizieren. So vermeiden Sie eine enge Kopplung der Dienste. Außerdem wird sichergestellt, dass für die Kommunikation zwischen den Diensten gut dokumentierte und unterstützte APIs verwendet werden.
- Die Dienste sollten abwärtskompatibel sein. Das Team, das einen Dienst erstellt und betreibt, muss dafür sorgen, dass Updates keine negativen Auswirkungen auf seine Nutzerinnen und Nutzer haben. Es ist daher notwendig, eine API-Versionsverwaltung und Tests zur Abwärtskompatibilität einzuplanen, damit bei der Einführung neuer Versionen keine Fehlfunktionen für bestehende Kund:innen verursacht werden. Teams können dies mithilfe von Canary-Releases überprüfen. Das bedeutet auch, dass mit Verfahren wie Blau/Grün-Bereitstellungen oder gestaffelten Roll-outs dafür gesorgt werden sollte, dass Deployments keine Ausfallzeiten nach sich ziehen.
- Konzipieren Sie eine Standardmethode, um Dienste auf Entwicklungs-Workstations auszuführen. Entwickler*innen müssen in der Lage sein, bei Bedarf jede Teilgruppe von Produktionsdiensten mithilfe eines einzigen Befehls auf Entwicklungs-Workstations zu erstellen. Außerdem sollte es möglich sein, bei Bedarf Stub-Versionen von Diensten auszuführen. Verwenden Sie dafür emulierte Versionen der Cloud-Dienste, die viele Cloud-Anbieter bereitstellen. Das Ziel ist, dass Entwickler*innen Dienste leicht lokal testen und debuggen können.
- Investieren Sie in Monitoring für die Produktionsumgebung sowie Beobachtbarkeit. Viele Probleme in der Produktionsumgebung, einschließlich Leistungsproblemen, sind akut und werden durch Interaktionen zwischen mehreren Diensten verursacht. Aus unserer Forschung geht hervor, dass Sie unbedingt eine Lösung verwenden sollten, die Daten zum Gesamtzustand der Systeme liefert (z. B. Funktionieren meine Systeme? Stehen in meinen Systemen genügend Ressourcen zur Verfügung?) und dass Teams auf Tools und Daten zugreifen können, mit denen sie Infrastrukturprobleme in Produktionsumgebungen verfolgen, verstehen und diagnostizieren können. Dazu gehören auch Interaktionen zwischen Diensten.
- Legen Sie Service Level Objectives (SLOs) für Ihre Dienste fest und führen Sie regelmäßig Notfallwiederherstellungstests durch. Wenn Sie für die Dienste SLOs festlegen, stellen Sie Ansprüche an deren Leistung und können besser planen, wie sich das System verhalten soll, wenn ein Dienst ausfällt. Beim Erstellen stabiler verteilter Systeme ist das ein wichtiger Faktor. Testen Sie mit Verfahren wie dem kontrollierten Einschleusen von Fehlern im Rahmen Ihres Testplans für die Notfallwiederherstellung, wie sich Ihr Produktionssystem in der Realität verhält – die Forschungsergebnisse des DORA-Teams zeigen, dass Organisationen, die mit solchen Methoden Tests zur Notfallwiederherstellung durchführen, mit größerer Wahrscheinlichkeit ein höheres Maß an Dienstverfügbarkeit aufweisen. Je früher Sie damit anfangen, desto besser ist es, denn dann können Sie solche entscheidenden Tätigkeiten Teil der Routine werden lassen.
Da gibt es viel zu bedenken. Deswegen ist ein Team wichtig, das die Kapazitäten und Fähigkeiten hat, mit dem Implementieren dieser Ideen zu experimentieren. Sie werden Erfolge feiern und müssen mit Fehlschlägen rechnen. Sie sollten daher auf den gesammelten Erfahrungen dieser Teams aufbauen und diese berücksichtigen, wenn Sie das neue Architekturmodell auf die gesamte Organisation ausweiten.
Unsere Studien haben ergeben, dass erfolgreiche Unternehmen Proof of Concepts nutzen und den Teams die Möglichkeit geben, sich über ihre Lernerfahrungen auszutauschen, beispielsweise, indem Communitys of Practice geschaffen werden. Legen Sie einen Zeitraum fest und stellen Sie einen Raum sowie Ressourcen zur Verfügung, damit sich die Mitglieder verschiedener Teams regelmäßig treffen und Ideen austauschen können. Alle Beteiligten werden sich auch neue Kompetenzen aneignen und sich in neue Technologien einarbeiten müssen. Investieren Sie in die Entwicklung Ihrer Mitarbeiterinnen und Mitarbeiter, indem Sie ein Budget bereitstellen, das für Bücher, Schulungskurse und die Teilnahme an Konferenzen verwendet werden kann. Schaffen Sie die Infrastruktur und die Zeit, damit Ihre Mitarbeiter:innen das institutionelle Wissen und die Best Practices mithilfe von Unternehmensmailinglisten, Wissensdatenbanken und persönlichen Treffen unter die Belegschaft bringen können.
Referenzarchitektur
In diesem Abschnitt wird eine Referenzarchitektur beschrieben, die auf den folgenden Leitlinien basiert:
- Container für Produktionsdienste und einen Container-Planer wie Cloud Run oder Kubernetes für die Orchestrierung verwenden
- Wirkungsvolle CI-/CD-Pipelines erstellen
- Fokus auf Sicherheit legen
Produktionsdienste containerisieren
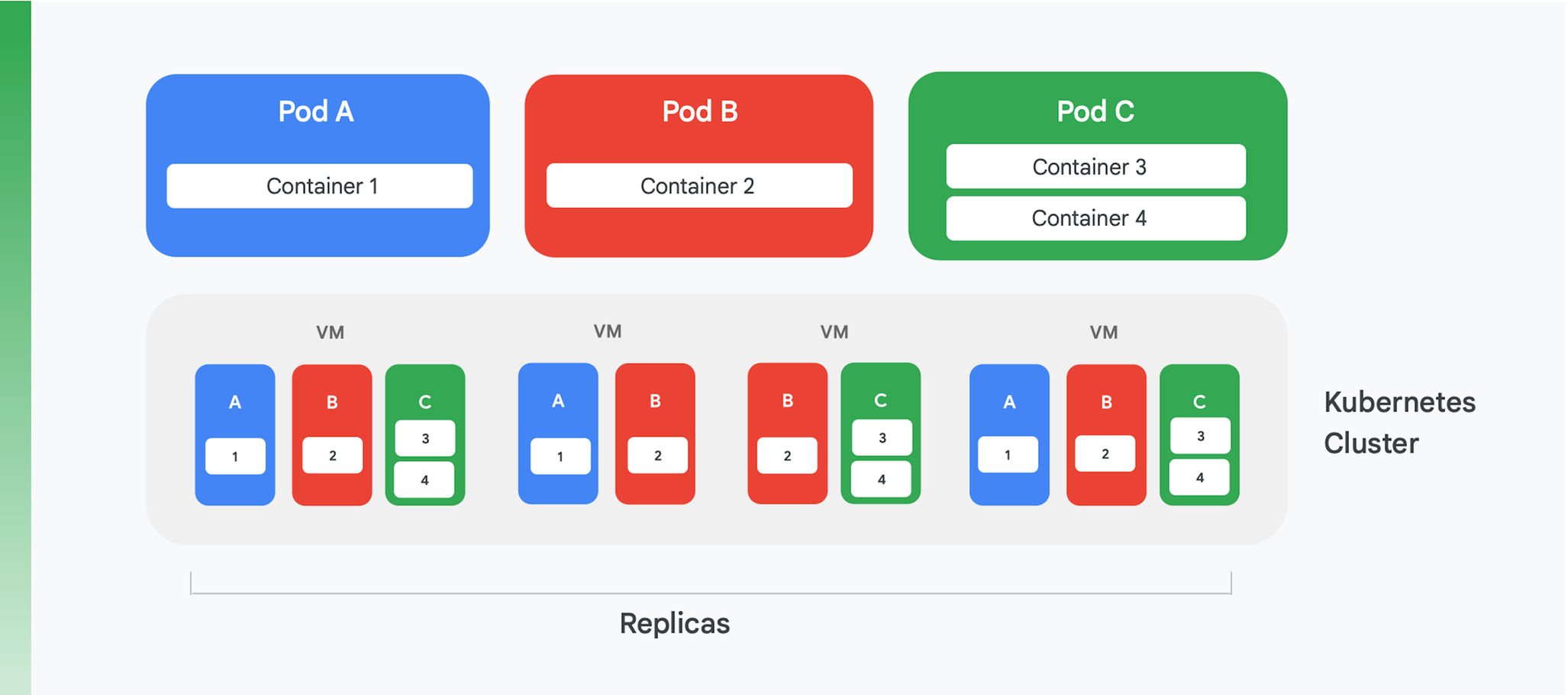
Die Grundlage einer containerisierten Cloud-Anwendung bildet ein Dienst, mit dem die Container verwaltet und orchestriert werden. Zu diesem Zweck wurden viele unterschiedliche Dienste erstellt, aber einer besetzt aktuell eindeutig die Spitzenposition: Kubernetes. Kubernetes setzt jetzt den Standard für die Containerorchestrierung in der Branche und bietet eine lebhafte Community sowie Unterstützung von vielen führenden kommerziellen Anbietern. In Abbildung 4 wird die logische Struktur eines Kubernetes-Clusters veranschaulicht.
Kubernetes verwendet eine Abstraktion, die Pod genannt wird. Die einzelnen Pods enthalten oft nur einen Container, wie die Pods A und B in Abbildung 4 zeigen. Ein Pod kann jedoch auch mehr als einen Container enthalten, wie es bei Pod C der Fall ist. Jeder Kubernetes-Dienst führt einen Cluster aus, der eine gewisse Anzahl an Knoten enthält, von denen in der Regel jeder eine virtuelle Maschine (VM) darstellt. Abbildung 4 zeigt nur vier VMs, aber ein echter Cluster kann problemlos 100 VMs oder mehr enthalten. Wenn ein Pod auf einem Kubernetes-Cluster bereitgestellt wird, bestimmt der Dienst, auf welchen VMs die Container jenes Pods ausgeführt werden sollen. Da Container die Ressourcen angeben, die sie benötigen, kann Kubernetes auf intelligente Weise entscheiden, welche Pods den einzelnen VMs zugewiesen werden.
Zu den Deployment-Informationen eines Pods gehört auch die Angabe, wie viele Instanzen – Replikate – des Pods ausgeführt werden sollen. Der Kubernetes-Dienst erstellt dann die gewünschte Anzahl von Instanzen der Pod-Container und weist den VMs diese zu. In Abbildung 4 wurden in den Deployment-Informationen für Pod A und für Pod C beispielsweise drei Replikate angefordert. In den Deployment-Informationen für Pod B wurden jedoch vier Replikate angefordert, sodass dieser Beispielcluster vier ausgeführte Instanzen von Container 2 enthält. Und wie aus der Abbildung hervorgeht, sind die Container eines Pods mit mehr als einem Container, wie bei Pod C, immer demselben Knoten zugewiesen.
Kubernetes bietet noch weitere Dienste, z. B.:
- Monitoring für ausgeführte Pods, sodass der Dienst beim Fehlschlagen eines Containers eine neue Instanz startet. Das sorgt dafür, dass alle Replikate, die in den Deployment-Informationen eines Pods angefordert wurden, verfügbar bleiben.
- Load-Balancing von Traffic, wodurch die an die einzelnen Pods gestellten Anfragen intelligent auf die Replikate eines Containers verteilt werden.
- Automatisiertes Roll-out neuer Container ohne Ausfallzeiten, wobei die neuen Instanzen nach und nach die vorhandenen Instanzen ersetzen, bis die neue Version vollständig bereitgestellt wurde.
- Automatisierte Skalierung, wobei ein Cluster eigenständig bedarfsgerecht VMs hinzufügt bzw. löscht.
Wirkungsvolle CI-/CD-Pipelines erstellen
Einige der Vorteile, die das Refaktorieren einer monolithischen Anwendung mit sich bringt, wie niedrigere Kosten resultieren direkt daraus, dass sie auf Kubernetes ausgeführt wird. Einer der wichtigsten Vorzüge – die Fähigkeit, eine Anwendung häufiger zu aktualisieren – lässt sich jedoch nur realisieren, wenn Sie die Art verändern, wie Sie Software erstellen und veröffentlichen. Um von diesem Vorteil zu profitieren, ist es wichtig, dass Sie in Ihrer Organisation wirkungsvolle CI-/CD-Pipelines erstellen.
Continuous Integration (CI) basiert auf automatisierten Build- und Test-Workflows, die Entwicklungsteams schnelles Feedback bieten. Dazu muss jedes Teammitglied am selben Code arbeiten (z. B. am Code für einen einzelnen Dienst), sodass alle Teammitglieder ihre Arbeit regelmäßig in einer gemeinsam genutzten Hauptpipeline oder einem gemeinsam genutzten Hauptentwicklungszweig zusammenführen. Das Zusammenführen sollte jede Entwicklerin bzw. jeder Entwickler mindestens täglich übernehmen; jede Zusammenführung wird dann durch einen Build-Prozess verifiziert, der automatisierte Tests umfasst. Continuous Delivery (CD) zielt darauf ab, das schnelle und risikoarme Deployment dieses zusammengeführten Codes zu ermöglichen. Dies wird hauptsächlich durch Automatisieren des Build-, Test- und Deployment-Prozesses erreicht, damit Aktivitäten wie Leistungs-, Sicherheits- und explorative Tests kontinuierlich durchgeführt werden können. Einfach ausgedrückt: Die CI hilft Entwickler:innen, Probleme beim Zusammenführen schnell zu erkennen, und die CD ermöglicht verlässliche und routinierte Deployments.
Es bietet sich an, sich hier ein konkretes Beispiel anzuschauen. Abbildung 5 zeigt, wie eine CI-/CD-Pipeline aussehen könnte, wenn für Container, die in Google Kubernetes Engine ausgeführt werden, Tools von Google verwendet werden.
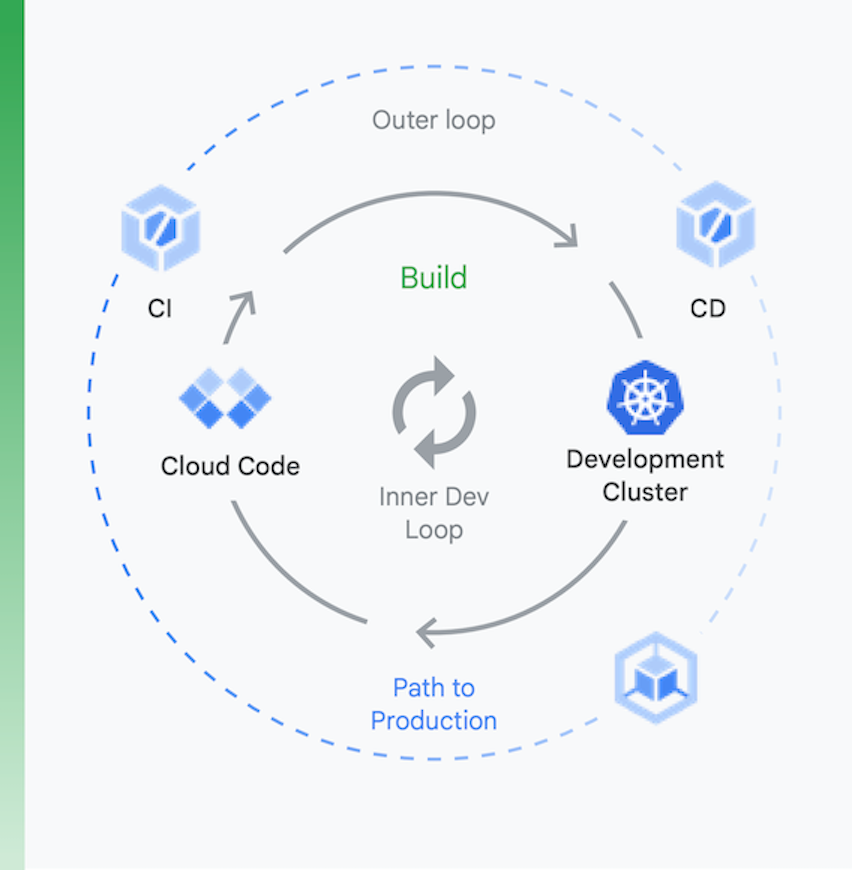
Es ist hilfreich, den Prozess gedanklich in zwei Blöcke aufzuteilen, wie in Abbildung 6 gezeigt:
Lokale Entwicklung | Remote-Entwicklung |
Hierbei lautet das Ziel, die Abläufe der inneren Entwicklungsschleife zu beschleunigen und Entwickler:innen mit gewissen Tools auszustatten, sodass sie zu den Auswirkungen lokaler Codeänderungen schnelles Feedback erhalten. Dies umfasst Support für Linting, die automatische Vervollständigung für YAML-Dateien und für schnellere lokale Builds. | Wenn eine Pull-Anfrage (Pull Request, PR) eingeht, wird die Remote-Entwicklungsschleife gestartet. Hier ist das Ziel, den Zeitaufwand für das Validieren und Testen der PR durch die CI drastisch zu reduzieren und auch andere Aktivitäten wie das Scannen auf Sicherheitslücken und das Signieren von Binärdaten zu beschleunigen. Gleichzeitig soll die Freigabe von Releases automatisiert ablaufen. |
Lokale Entwicklung
Remote-Entwicklung
Hierbei lautet das Ziel, die Abläufe der inneren Entwicklungsschleife zu beschleunigen und Entwickler:innen mit gewissen Tools auszustatten, sodass sie zu den Auswirkungen lokaler Codeänderungen schnelles Feedback erhalten. Dies umfasst Support für Linting, die automatische Vervollständigung für YAML-Dateien und für schnellere lokale Builds.
Wenn eine Pull-Anfrage (Pull Request, PR) eingeht, wird die Remote-Entwicklungsschleife gestartet. Hier ist das Ziel, den Zeitaufwand für das Validieren und Testen der PR durch die CI drastisch zu reduzieren und auch andere Aktivitäten wie das Scannen auf Sicherheitslücken und das Signieren von Binärdaten zu beschleunigen. Gleichzeitig soll die Freigabe von Releases automatisiert ablaufen.
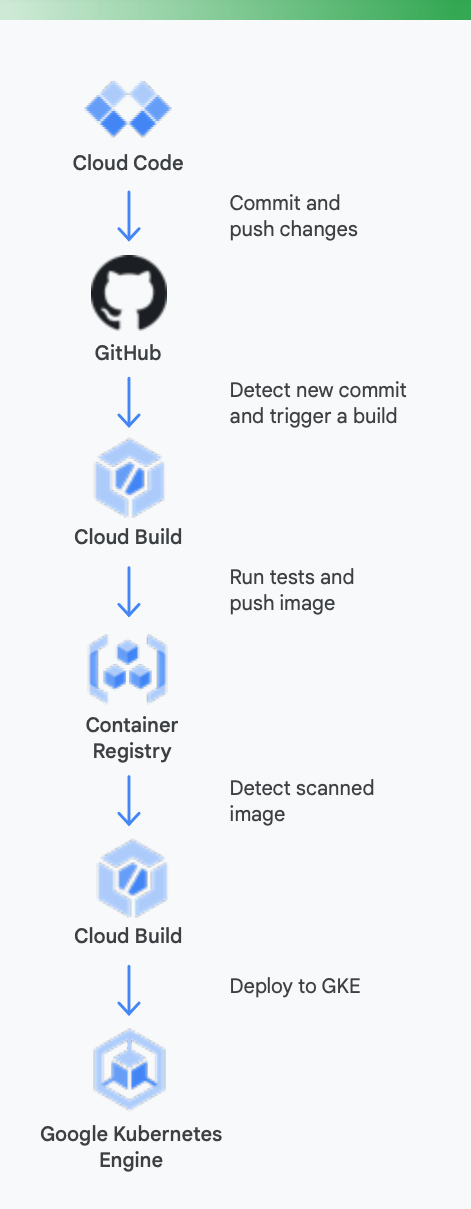
Die Tools von Google Cloud können Sie während dieses Prozesses auf folgende Weise unterstützen
Lokale Entwicklung: Es ist unabdingbar, die Produktivität von Entwicklern durch lokale Anwendungsentwicklung zu fördern. Lokale Entwicklung umfasst dabei das Erstellen von Anwendungen, die auf lokalen Clustern und Remote-Clustern bereitgestellt werden können. Bevor Änderungen per Commit in einem Versionsverwaltungssystem wie GitHub festgeschrieben werden, kann mit einer schnellen lokalen Entwicklungsschleife sichergestellt werden, dass Entwickler:innen ihre Änderungen vorab in einem lokalen Cluster testen und bereitstellen können.
Google Cloud bietet daher Cloud Code an. Cloud Code enthält Erweiterungen für IDEs wie Visual Studio Code und IntelliJ, damit Entwickler*innen in Kubernetes schnell Code iterieren, debuggen und ausführen können. Cloud Code verwendet beliebte Tools wie Skaffold, Jib und Kubectl, damit Entwickler:innen ein kontinuierliches Feedback zu ihrem Code in Echtzeit erhalten können.
Continuous Integration: Mit der neuen Cloud Build-GitHub-Anwendung können Teams Builds für verschiedene Repository-Ereignisse auslösen – beispielsweise Pull-Anfragen, Zweige oder Tag-Events direkt aus GitHub. Cloud Build ist eine vollständig serverlose Plattform und führt je nach Last eine automatische Skalierung durch, ohne dass vorab Server bereitgestellt oder Vorauszahlungen für zusätzliche Kapazitäten geleistet werden müssen. Builds, die über die GitHub-Anwendung ausgelöst werden, melden ihren Status automatisch an GitHub zurück. Das Feedback wird direkt im GitHub-Workflow für Entwickler:innen berücksichtigt, sodass weniger Kontextwechsel nötig sind.
Artefaktverwaltung: Container Registry ist ein zentraler Ort, an dem Ihr Team Docker-Images verwalten, auf Sicherheitslücken scannen und detailgenau entscheiden kann, wer worauf Zugriff erhält. Da Entwickler:innen direkt in Cloud Build die Möglichkeit haben, auf Sicherheitslücken zu scannen, können sie Sicherheitsbedrohungen identifizieren, sobald Cloud Build ein Image erstellt und es in Container Registry gespeichert hat.
Continuous Delivery: Cloud Build verwendet Build-Schritte, damit Sie die Schritte festlegen können, die im Rahmen des Erstellungs-, Test- und Bereitstellungsprozesses ausgeführt werden sollen. Sobald beispielsweise ein neuer Container erstellt und in Container Registry übertragen wurde, kann er in einem späteren Build-Schritt in Google Kubernetes Engine (GKE) oder Cloud Run übertragen werden – zusammen mit der zugehörigen Konfiguration und Richtlinie. Sie können auch in den Clouds anderer Anbieter Bereitstellungen vornehmen, falls Sie eine Multi-Cloud-Strategie verfolgen. Und falls Sie die Continuous Delivery im GitOps-Stil anstreben, können Sie Ihre Deployments in Cloud Build deklarativ mithilfe von Dateien (z. B. Kubernetes-Manifesten) beschreiben, die in einem Git-Repository gespeichert sind.
Mit dem Bereitstellen von Code endet Ihre Aufgabe jedoch nicht. Organisationen müssen den Code zusätzlich noch verwalten, während er ausgeführt wird. Zu diesem Zweck bietet Google Cloud Betriebsteams Tools wie Cloud Monitoring und Cloud Logging an.
Sie müssen GKE natürlich nicht in Kombination mit den CI-/CD-Tools von Google verwenden, sondern können auch problemlos andere Toolchains nutzen. Beispielsweise können Sie Jenkins für die CI/CD oder Artifactory zum Verwalten von Artefakten verwenden.
Wenn es Ihnen wie den meisten Organisationen mit VM-basierten Cloud-Anwendungen geht, haben Sie vermutlich noch kein reibungslos laufendes CI-/CD-System. Es ist unabdingbar, ein solches System zu implementieren, wenn Sie von den Vorteilen Ihrer umgestalteten Anwendung profitieren möchten. Das ist jedoch mit Arbeit verbunden. Die Technologien, die notwendig sind, um die entsprechenden Pipelines zu erstellen, sind bereits vorhanden, was teilweise an der Reife von Kubernetes liegt. Aber die Veränderungen, die auf menschlicher Ebene noch notwendig sind, können beträchtlich sein. Ihre Bereitstellungsteams müssen funktionsübergreifend aufgestellt werden, das heißt, Kompetenzen in Bezug auf die Entwicklung, Tests und den Geschäftsbetrieb aufweisen können. Ein Paradigmenwechsel in der Unternehmenskultur braucht Zeit. Daher sollten Sie während der Umstellung auf CI/CD bereit sein, Zeit aufzuwenden, um das Wissen Ihrer Belegschaft zu erweitern und Änderungen an bestehenden Verhaltensweisen anzuregen.
Fokus auf Sicherheit legen
Es stellt eine große Veränderung dar, monolithische Anwendungen in ein cloudnatives Modell umzuwandeln. Kein Wunder, dass dies neue Sicherheitsherausforderungen nach sich zieht, die Sie berücksichtigen sollten. Zwei der wichtigsten sind folgende:
- Zugriff zwischen Containern sichern
- Für eine sichere Softwarelieferkette sorgen
Die erste dieser Herausforderungen ergibt sich aus einer Tatsache, die auf der Hand liegt: Wenn Sie die Anwendung in containerisierte Dienste und möglicherweise in Mikrodienste aufteilen, müssen diese Dienste auf irgendeine Art miteinander kommunizieren. Und obwohl sie möglicherweise alle auf demselben Kubernetes-Cluster ausgeführt werden, müssen Sie sich dennoch Gedanken darüber machen, wie Sie den Zugriff zwischen diesen steuern. Es könnte schließlich sein, dass noch weitere Anwendungen diesen Kubernetes-Cluster verwenden. Sie können Ihre Container dann nicht einfach ungesichert lassen und diesen Anwendungen somit ungehinderten Zugriff darauf gewähren.
Wenn Sie den Zugriff auf einen Container steuern möchten, müssen Sie seine Aufrufer authentifizieren und dann festlegen, welche 17 Anfragen die anderen Container senden dürfen. Heutzutage werden dieses Problem wie auch diverse andere typischerweise mithilfe eines Service Mesh gelöst. Dafür ist Istio ein führendes Beispiel. Das ist ein Open-Source-Projekt von Google, IBM und anderen Unternehmen. Abbildung 7 zeigt, wie sich Istio in einen Kubernetes-Cluster einfügt.
Wie Sie an der Abbildung sehen können, fängt der Istio-Proxy den gesamten Traffic zwischen den Containern Ihrer Anwendung ab. Dadurch kann das Service Mesh einige nützliche Dienste bereitstellen, ohne dass Änderungen am Code der Anwendung erforderlich sind. Dazu gehören:
- Sicherheit, sowohl Dienst-zu-Dienst-Authentifizierung via TLS als auch Authentifizierung von Endnutzer*innen
- Trafficverwaltung, sodass Sie steuern können, wie Anfragen zwischen den Containern Ihrer Anwendung weitergeleitet werden
- Beobachtbarkeit, dass also zur Kommunikation zwischen den Containern Logs angelegt und Messwerte erfasst werden
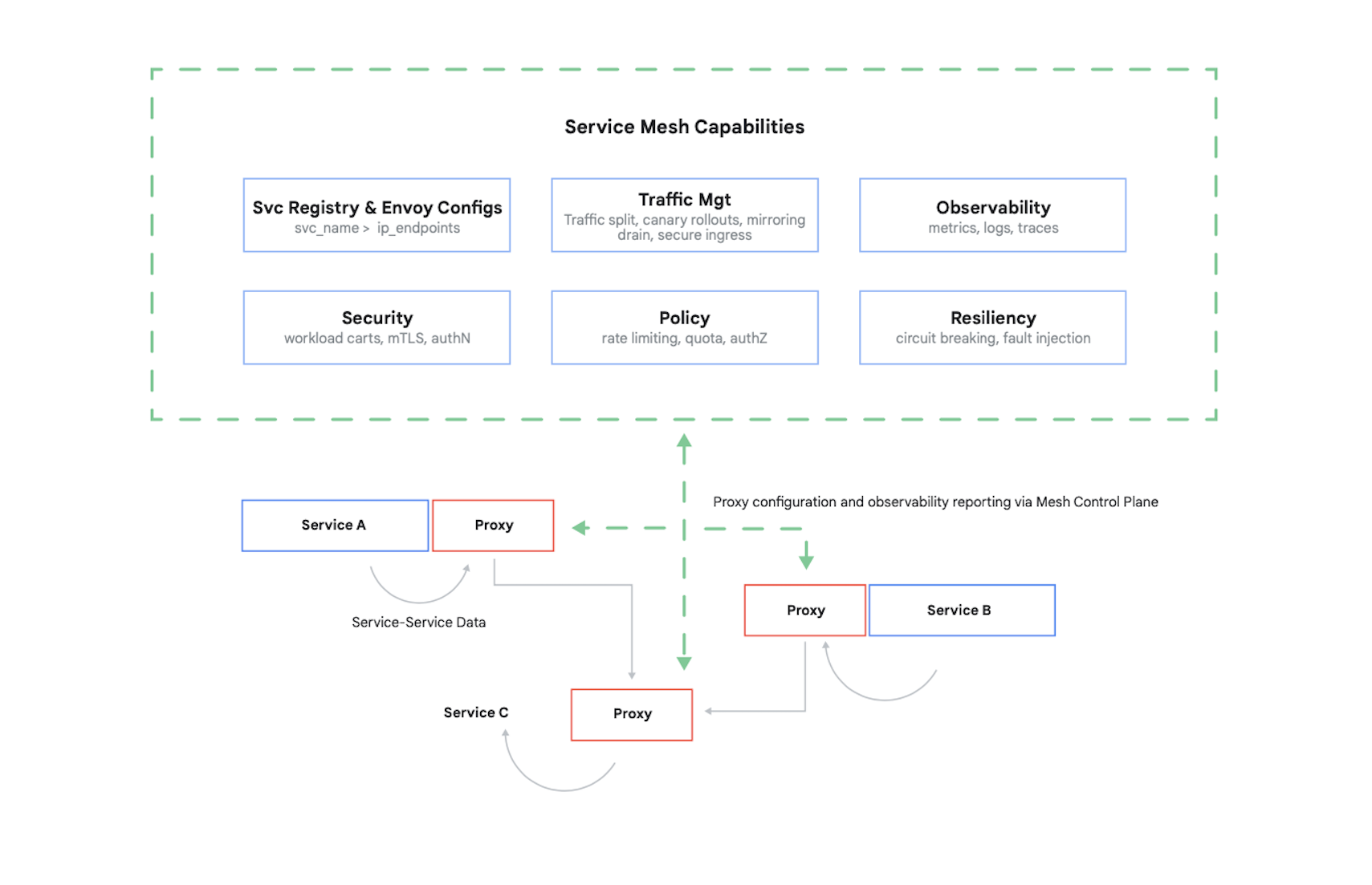
Mit Google Cloud können Sie einem GKE-Cluster Istio hinzufügen. Und obwohl es nicht erforderlich ist, ein Service Mesh zu verwenden, kann es sein, dass gut informierte Kund:innen, die Ihre Cloud-Anwendungen nutzen, danach fragen, ob deren Sicherheit mit dem Level von Istio mithalten kann. Kundinnen und Kunden ist Sicherheit allgemein sehr wichtig – und in einer containerbasierten Welt leistet Istio dahingehend einen wichtigen Beitrag.
Google Cloud unterstützt nicht nur das Open-Source-Service-Mesh Istio, sondern bietet auch Traffic Director an. Das ist eine vollständig durch Google Cloud verwaltete Service-Mesh-Steuerungsebene. Traffic Director stellt globales Load-Balancing für Cluster und VM-Instanzen in mehreren Regionen bereit, entlastet die Dienst-Proxys von der Systemdiagnose und bietet anspruchsvolle Traffic-Verwaltung sowie weitere bereits oben beschriebene Funktionen.
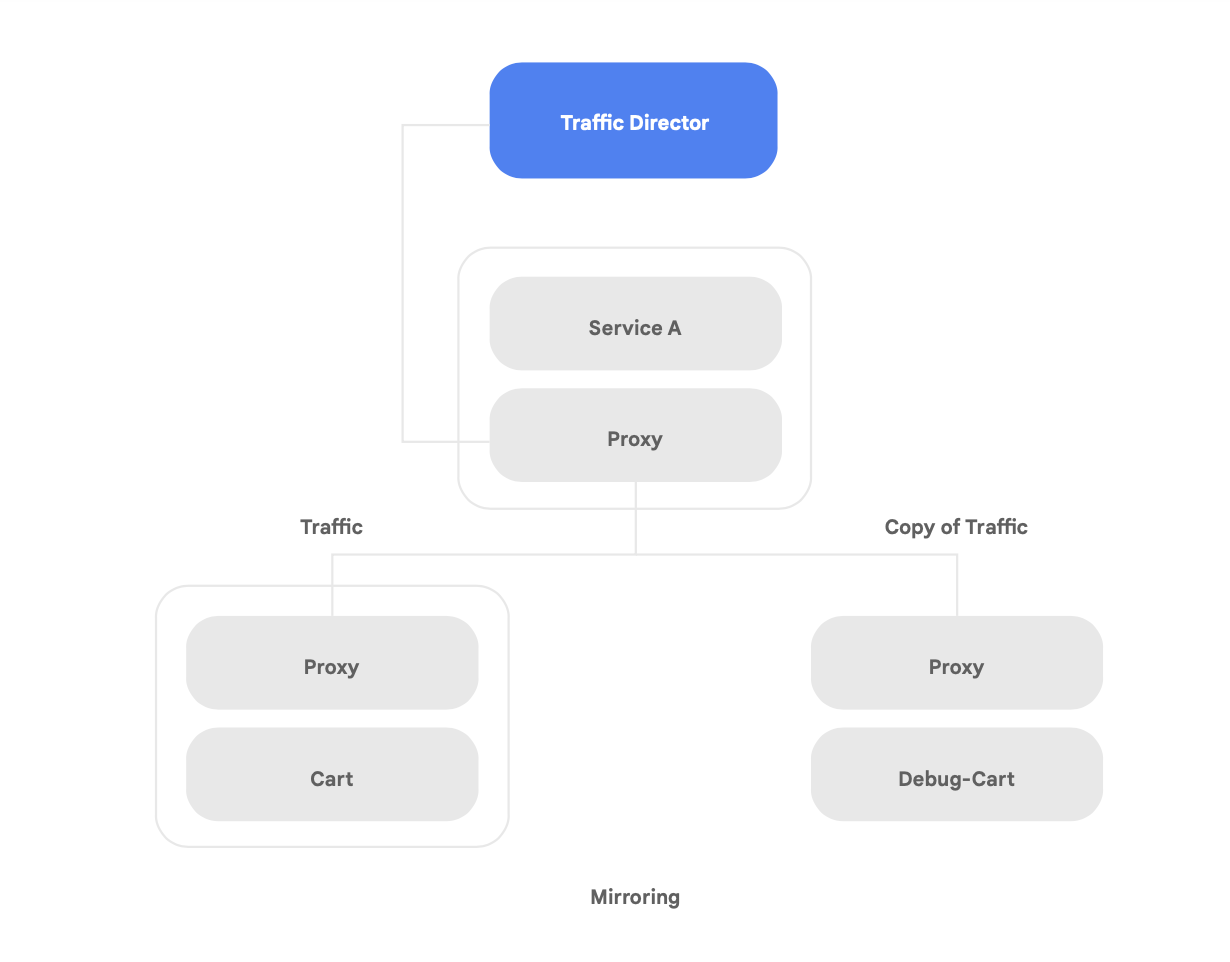
Zu den einzigartigen Funktionen von Traffic Director gehört der automatische regionsübergreifende Failover mit Überlauf für Mikrodienste im Mesh-Netzwerk (in Abbildung 8 zu sehen).
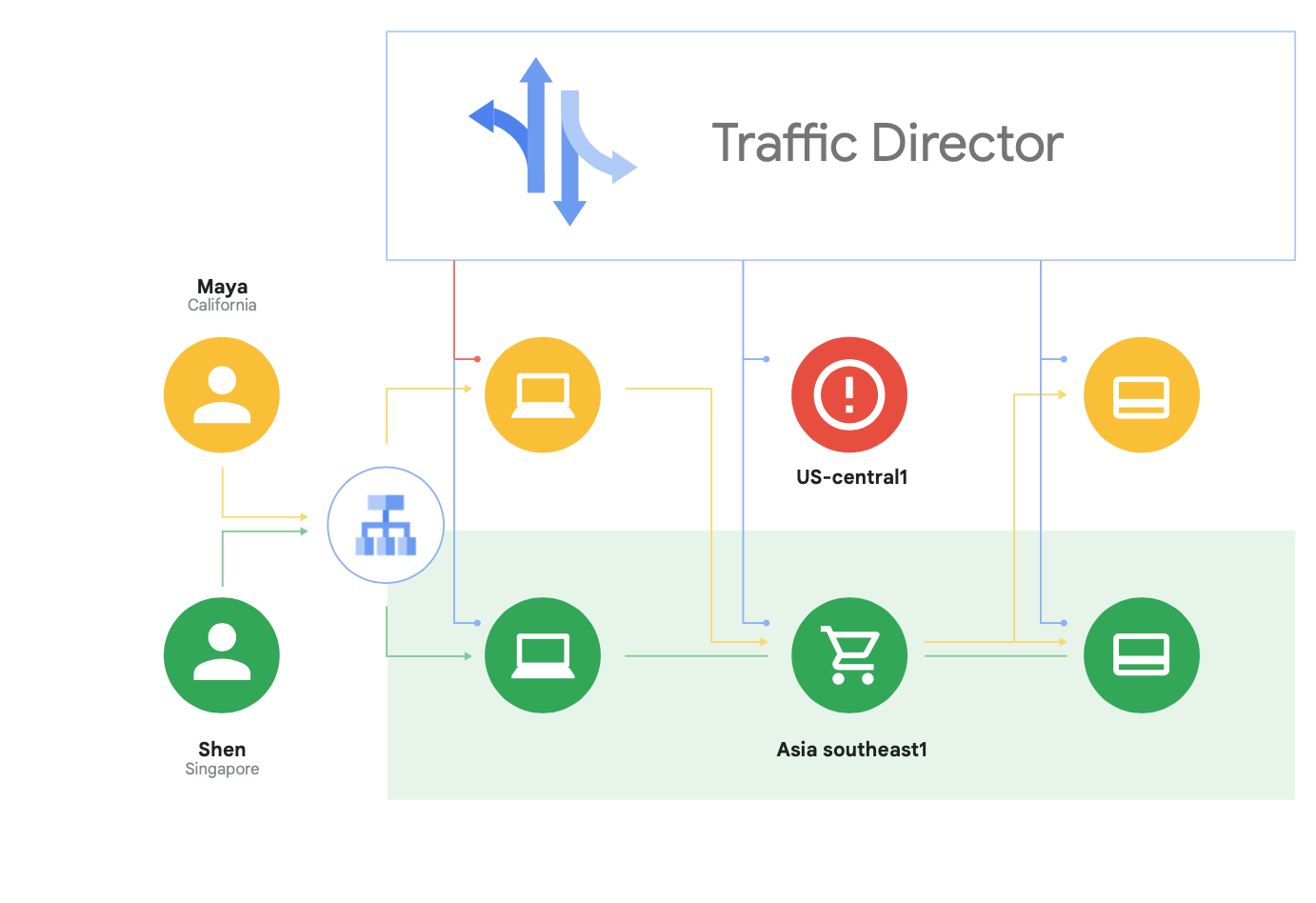
Mithilfe dieser Funktion können Sie für Ihre Dienste im Service Mesh zugleich globale Ausfallsicherheit und Sicherheit erzielen.
Traffic Director bietet verschiedene Features zum Verwalten von Traffic, mit denen Sie die Sicherheit des Service Mesh erhöhen können. Beispielsweise kann das in Abbildung 9 gezeigte Feature zur Trafficspiegelung leicht als Richtlinie eingerichtet werden, damit eine Schattenanwendung eine Kopie des Traffics erhalten darf, der gerade von der Hauptversion der Anwendung verarbeitet wird. Die Kopien der vom Schattendienst empfangenen Antworten werden nach dem Verarbeiten verworfen. Die Trafficspiegelung kann ein leistungsstarkes Tool darstellen, um auf Sicherheitsanomalien zu testen und Fehler im Produktionstraffic zu debuggen, ohne dass sich das auf den Produktionstraffic auswirkt oder Sie in diesen eingreifen müssen.
Jedoch ist das Schützen der Interaktionen zwischen den Containern nicht die einzige neue Sicherheitsherausforderung, die eine refaktorierte Anwendung mit sich bringt. Sie sollten zusätzlich darauf achten, dass die Container-Images, die Sie ausführen, vertrauenswürdig sind. Dazu müssen Sie dafür sorgen, dass bei Ihrer Softwarelieferkette Sicherheit und Compliance gewahrt sind.
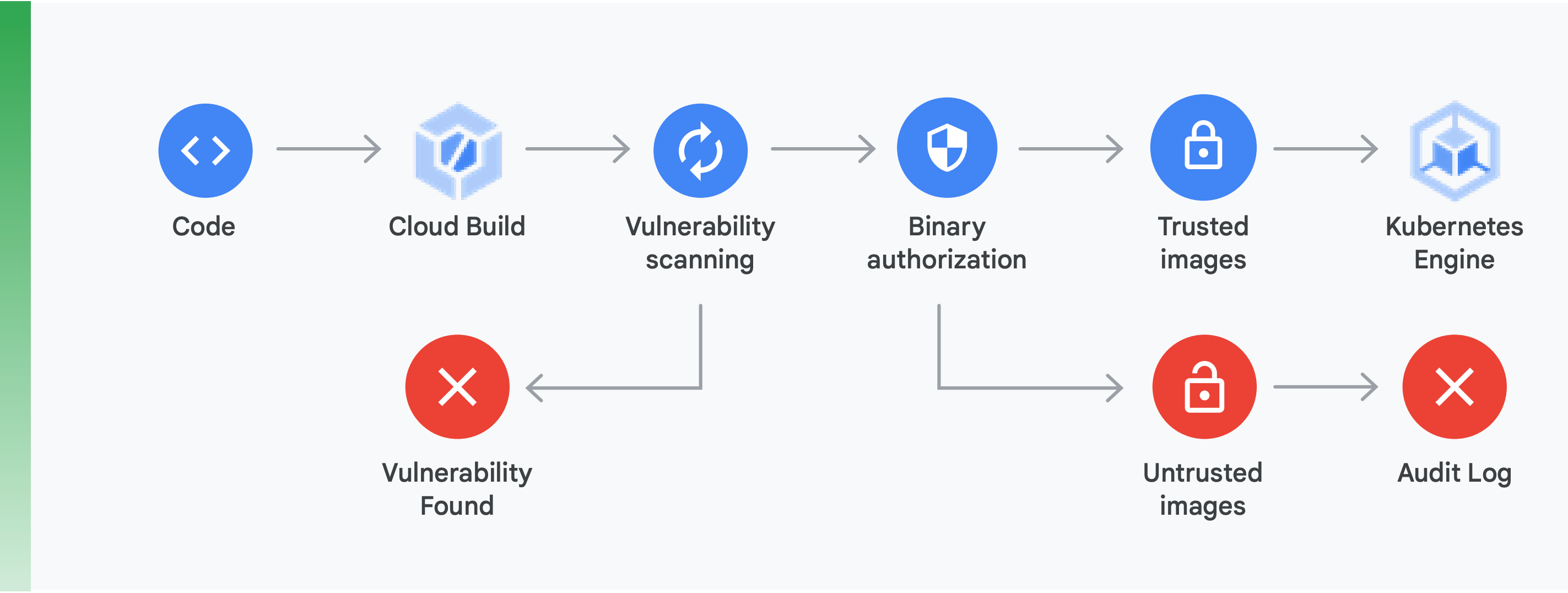
Zwei Dinge sind hier besonders wichtig, wie in Abbildung 10 gezeigt:
Scannen auf Sicherheitslücken: Mit der Funktion zum Scannen auf Sicherheitslücken von Container Registry erhalten Sie schnelles Feedback zu möglichen Bedrohungen und können Probleme identifizieren, sobald die Container durch Cloud Build erstellt und in Container Registry gespeichert wurden. Sicherheitslücken von Paketen für Ubuntu, Debian und Alpine werden direkt während des Anwendungsentwicklungsprozesses identifiziert. Die Unterstützung für CentOS und RHEL ist in Arbeit. So werden teure Ineffizienzen vermieden und die Zeit verringert, die erforderlich ist, um bekannte Sicherheitslücken zu beheben.
Binärautorisierung: Wenn Sie die Binärautorisierung und das Feature zum Scannen auf Sicherheitslücken von Container Registry einsetzen, können Sie als Teil Ihrer allgemeinen Bereitstellungsrichtlinie Deployments anhand der Ergebnisse isolieren bzw. zurückhalten, die sich beim Scan ergeben haben. Mit der Binärautorisierung wird die Sicherheit beim Deployment überprüft. So können Sie garantieren, dass nur vertrauenswürdige Container-Images in Google Kubernetes Engine bereitgestellt werden.
Wenn Sie den Zugriff zwischen Containern mithilfe eines Service Mesh sichern und für eine sichere Softwarelieferkette sorgen, haben Sie bereits einen wichtigen Beitrag geleistet, um sichere containerbasierte Anwendungen zu schaffen. Sie können dahingehend noch viel mehr tun, z. B. die Sicherheit der Cloud-Plattforminfrastruktur verifizieren, mit der Sie arbeiten. Am wichtigsten ist jedoch, sich klarzumachen, dass der Wechsel von einer monolithischen Anwendung zu einem modernen, cloudnativen Modell neue Sicherheitsherausforderungen mit sich bringt. Damit der Wechsel erfolgreich gelingt, sollten Sie verstehen, welche das sind und dann einen konkreten Plan erstellen, um jede Herausforderung separat anzugehen.
Erste Schritte
Ziehen Sie den Wechsel zu einer cloudnativen Architektur nicht als mehrjähriges „Big-Bang“-Projekt auf.
Fangen Sie lieber gleich an. Setzen Sie entweder auf ein Team, das die nötigen Kapazitäten und das Fachwissen hat, um ein Proof of Concept auszuarbeiten, oder eines, das dies bereits erledigt hat. Machen Sie anschließend die daraus gezogenen Erkenntnisse in Ihrer Organisation publik. Bringen Sie Ihre Teams dazu, das Strangler Fig-Muster einzusetzen, also die Dienste inkrementell und iterativ in eine cloudnative Architektur zu verschieben, während sie zeitgleich weiterhin neue Funktionen bereitstellen.
Damit das Ganze von Erfolg gekrönt ist, müssen die Teams die Kapazitäten, Ressourcen und Autorität haben, um das Weiterentwickeln der Systemarchitektur in ihre tägliche Arbeit einzubinden. Legen Sie für neue Aufgaben eindeutige Architekturziele fest und orientieren Sie sich dazu an den sechs Ergebnissen in puncto Architektur, die zuvor beschrieben wurden. Lassen Sie den Teams jedoch den Freiraum, zu entscheiden, wie sie diese erreichen wollen.
In erster Linie gilt jedoch, dass Sie keine Zeit verlieren sollten. Es wird immer entscheidender für den Erfolg Ihrer Organisation, die Produktivität und Agilität Ihrer Teams und die Sicherheit und Stabilität Ihrer Dienste zu erhöhen. Die erfolgreichsten Teams binden das Durchführen von Experimenten und das Verbessern von bestehenden Strukturen konsequent in ihre tägliche Arbeit ein.
Google hat Kubernetes auf Basis von Software entwickelt, die unternehmensintern bereits seit Jahren verwendet wurde. Cloudnative Technologie liegt uns im Blut.
Wie sich anhand unseres CI-/CD- und Sicherheitsangebots erkennen lässt, ist die Google Cloud stark auf containerisierte Anwendungen ausgerichtet. Und eines ist klar: Google Cloud ist heute führend bei der Unterstützung für Containeranwendungen.
Unter cloud.google.com/devops können Sie unsere Schnellprüfung durchführen, um herauszufinden, wie in Ihrem Unternehmen der Stand der Dinge ist. Außerdem erhalten Sie dort Tipps, welche nächsten Schritte sich anbieten. Unter anderem wird erläutert, wie Sie die in diesem Whitepaper beschriebenen Muster implementieren, z. B. eine lose gekoppelte Architektur.
Viele Google Cloud Partner haben bereits Organisationen wie die Ihre bei dieser Umstellung unterstützt. Warum sollten Sie sich damit abmühen, das Umgestalten auf eigene Faust anzugehen, wenn wir Ihnen eine erfahrene Expertin oder einen erfahrenen Experten zur Seite stellen können?
Wenn Sie gleich loslegen möchten, können Sie uns jederzeit kontaktieren, um einen Termin mit einem Google Solutions Architect zu vereinbaren. Wir helfen Ihnen dabei, die Umstellung zu überschauen und arbeiten dann gemeinsam mit Ihnen daran, wie sie sich in die Tat umsetzen lässt.
Weitere Informationen
https://cloud.google.com/devops – Sechs Jahre Bericht des State of DevOps, eine Reihe von Artikeln mit ausführlichen Informationen zu den Funktionen, die die Leistung von Softwarebereitstellung vorhersagen können, und eine schnelle Prüfung, mit der Sie herausfinden können, wie Sie sich schlagen und wie Sie es besser machen können.
Site Reliability Engineering: How Google Runs Production Systems (O'Reilly 2016)
The Site Reliability Workbook: Practical Ways to Implement SRE (O'Reilly 2018)
“How to break a Monolith into Microservices: What to decouple and when” von Zhamak Dehghani
“Microservices: a definition of this new architectural term” von Martin Fowler
“Strangler Fig Application” von Martin Fowler
Sind Sie bereit für die nächsten Schritte?
Füllen Sie das Formular aus. Wir melden uns bald bei Ihnen. Vertrieb kontaktieren


















