Merancang ulang ke solusi berbasis cloud
Menurut riset DevOps Research and Assessment (DORA), tim DevOps elit melakukan deploy beberapa kali dalam sehari, merilis perubahan ke produksi dalam waktu kurang dari sehari, dan mencatatkan tingkat kegagalan perubahan 0–15%.
Laporan resmi ini menunjukkan cara untuk mendesain ulang arsitektur aplikasi Anda dari sudut pandang (paradigma) berbasis cloud sehingga Anda dapat mempercepat pengiriman fitur baru sambil menumbuhkan tim, sekaligus meningkatkan kualitas software dan mencapai level stabilitas serta ketersediaan yang lebih tinggi.
Mengapa harus beralih ke arsitektur berbasis cloud?
Ada banyak perusahaan yang membangun layanan software kustomnya menggunakan arsitektur monolitik. Pendekatan ini memiliki keunggulan: sistem monolitik relatif sederhana untuk didesain dan di-deploy, setidaknya pada awalnya. Namun, pendekatan ini dapat mempersulit upaya untuk mempertahankan produktivitas developer dan kecepatan deployment ketika aplikasi tumbuh menjadi semakin kompleks, sehingga menghasilkan sistem yang mahal, memakan banyak waktu untuk diubah, serta berisiko saat di-deploy.
Seiring pertumbuhan layanan serta tim yang bertanggung jawab atasnya, layanan biasanya akan menjadi lebih kompleks dan semakin sulit untuk dikembangkan dan dioperasikan. Pengujian dan deployment menjadi semakin menyusahkan, penambahan fitur baru menjadi lebih sulit, dan pemeliharaan reliabilitas serta ketersediaan bisa jadi merepotkan.
Berdasarkan riset tim DORA dari Google, Anda dapat mencapai level throughput pengiriman software yang tinggi serta stabilitas dan ketersediaan layanan di seluruh organisasi baik besar maupun kecil dan dari semua domain. Tim yang berperforma tinggi dapat melakukan deployment beberapa kali dalam sehari, mengirimkan perubahan ke tahap produksi dalam waktu kurang dari sehari, memulihkan layanan dalam waktu kurang dari satu jam, serta menjaga tingkat kegagalan perubahan di kisaran 0-15%.1
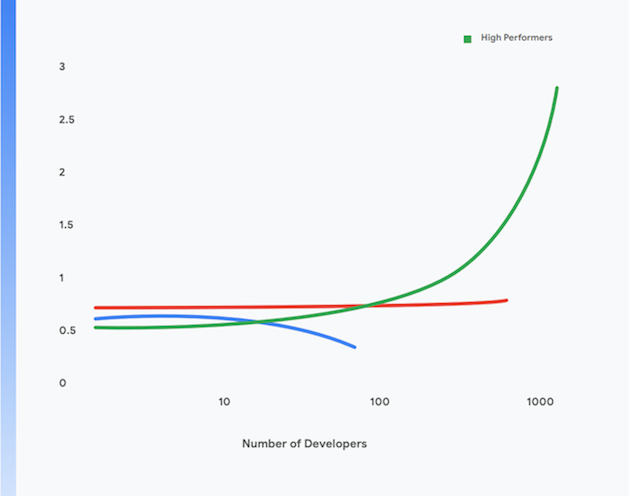
Lebih lanjut, tim yang berperforma tinggi juga dapat mencapai level produktivitas developer yang lebih tinggi lagi, yang diukur menurut deployment per developer per hari, bahkan ketika ukuran tim ditingkatkan. Ini ditunjukkan dalam Gambar 1.
Bagian selanjutnya dari halaman ini akan menjelaskan cara memigrasikan aplikasi Anda ke paradigma berbasis cloud modern untuk membantu mencapai hasil tersebut. Dengan menerapkan praktik-praktik teknis yang dipaparkan dalam laporan ini, Anda dapat mencapai tujuan berikut:
- Peningkatan produktivitas developer, bahkan seiring Anda meningkatkan ukuran tim
- Waktu penyiapan produk yang lebih cepat: menambahkan fitur baru dan memperbaiki kerusakan dengan lebih cepat
- Ketersediaan yang lebih tinggi: meningkatkan waktu operasional software Anda, menurunkan tingkat kegagalan deployment, serta memangkas waktu pemulihan jika terjadi insiden
- Keamanan yang ditingkatkan: mengurangi area permukaan serangan pada aplikasi Anda, memudahkan proses deteksi, dan merespons serangan maupun kerentanan baru dengan cepat
- Skalabilitas yang lebih baik: platform dan aplikasi berbasis cloud mempermudah penskalaan secara horizontal ketika diperlukan, begitu pula jika skalanya perlu diperkecil
- Menurunkan biaya: proses pengiriman software yang sederhana dapat menurunkan biaya pengiriman fitur baru, dan penggunaan platform cloud yang efektif dapat mengurangi biaya pengoperasian layanan Anda secara signifikan
1 Cari tahu performa tim Anda berdasarkan keempat metrik utama tersebut di https://cloud.google.com/devops/
Apa yang dimaksud dengan arsitektur berbasis cloud?
Aplikasi monolitik harus di-build, diuji, dan di-deploy sebagai unit tunggal. Sering kali, sistem operasi, middleware, dan stack bahasa untuk aplikasi disesuaikan atau dikonfigurasi secara khusus untuk masing-masing aplikasi. Skrip dan proses build, pengujian, serta deployment biasanya juga dibuat khusus untuk masing-masing aplikasi. Hal ini sederhana dan efektif untuk aplikasi yang masih baru, tetapi seiring pertumbuhan aplikasi tersebut, akan semakin sulit untuk mengubah, menguji, men-deploy, dan mengoperasikan sistemnya.
Lebih lanjut, seiring pertumbuhan sistem, ukuran dan kompleksitas tim yang mem-build, menguji, men-deploy, dan mengoperasikan layanan juga ikut bertumbuh. Terkait hal ini, sebuah pendekatan yang umum dilakukan tetapi memiliki kelemahan adalah dengan membagi tim menurut fungsinya. Hal ini mengakibatkan adanya proses serah-terima antar-tim yang cenderung memperpanjang waktu pengerjaan dan memperbesar ukuran batch, sehingga berujung pada jumlah pengerjaan ulang yang signifikan. Riset DORA menunjukkan bahwa tim yang berperforma tinggi dapat mengembangkan dan mengirimkan software dua kali lipat lebih banyak dalam satu tim lintas-fungsi.
Gejala dari masalah ini meliputi:
- Proses build yang lama dan sering error
- Siklus pengujian dan integrasi yang jarang
- Meningkatnya upaya yang diperlukan untuk mendukung proses build dan pengujian
- Hilangnya produktivitas developer
- Proses deployment yang menyusahkan dan harus dilakukan di luar jam kerja, sehingga membutuhkan periode nonaktif terjadwal
- Upaya yang signifikan dalam mengelola konfigurasi lingkungan produksi dan pengujian
Sebaliknya, dalam paradigma berbasis cloud³:
- Sistem kompleks diuraikan menjadi layanan yang dapat diuji dan di-deploy secara independen di runtime yang dipisah-pisah menggunakan container (berupa microservice atau arsitektur berorientasi layanan)
- Aplikasi menggunakan layanan standar yang disediakan platform, seperti sistem pengelolaan database (DBMS), penyimpanan blob, fitur pesan, CDN, dan penghentian SSL
- Platform cloud yang terstandardisasi dapat mengatasi banyak masalah operasional seperti deployment, penskalaan otomatis, konfigurasi, pengelolaan rahasia (secret), pemantauan, dan pemberitahuan. Layanan-layanan tersebut dapat diakses secara on-demand oleh tim pengembangan aplikasi
- Sistem operasi, middleware, dan stack khusus bahasa yang terstandardisasi disediakan untuk developer aplikasi, dan pemeliharaan serta patching stack tersebut dilakukan secara out-of-band oleh penyedia platform atau tim terpisah
- Satu tim lintas-fungsi dapat bertanggung jawab untuk keseluruhan siklus proses pengiriman software dari setiap layanan
3 Ini bukanlah penjabaran lengkap dari makna "berbasis cloud": untuk pembahasan beberapa prinsip arsitektur berbasis cloud, buka https://cloud.google.com/blog/products/ application-development/5-principles-for-cloud-native-architecture-what-it-is-and-how-to-master-it.
Paradigma ini memberikan banyak manfaat:
Pengiriman yang lebih cepat | Rilis yang andal | Biaya yang lebih rendah |
Karena layanan kini berukuran kecil dan dikaitkan secara longgar, tim yang terkait dengan layanan tersebut dapat bekerja secara otonom. Hal ini meningkatkan produktivitas developer dan kecepatan pengembangan. | Developer dapat dengan cepat mem-build, menguji, dan men-deploy layanan baru maupun yang sudah ada di lingkungan pengujian yang mirip dengan lingkungan produksi. Deployment ke produksi juga menjadi aktivitas kecil yang sederhana. Ini mempercepat proses pengiriman software dan mengurangi risiko deployment secara signifikan. | Biaya dan kompleksitas lingkungan pengujian dan produksi berkurang signifikan karena layanan standar yang digunakan bersama disediakan oleh platform dan karena aplikasi dijalankan di infrastruktur fisik yang digunakan bersama. |
Keamanan yang lebih baik | Ketersediaan lebih tinggi | Kepatuhan yang lebih sederhana dan lebih murah |
Vendor kini bertanggung jawab untuk menjaga agar layanan yang digunakan bersama, seperti DBMS dan infrastruktur untuk fitur pesan, tetap terbaru, di-patch, serta patuh. Di samping itu, juga jauh lebih mudah untuk menjaga aplikasi tetap di-patch dan terbaru karena ada cara standar untuk men-deploy dan mengelola aplikasi | Ketersediaan dan reliabilitas aplikasi meningkat karena kompleksitas lingkungan operasional berkurang, perubahan konfigurasi menjadi mudah dilakukan, dan penskalaan otomatis serta autohealing di level platform dapat ditangani. | Sebagian besar kontrol keamanan informasi dapat diterapkan di lapisan platform, sehingga membuatnya jauh lebih murah dan mudah untuk diterapkan serta menunjukkan kepatuhan. Banyak penyedia cloud menjaga kepatuhan dengan framework pengelolaan risiko, seperti SOC2 dan FedRAMP, yang berarti aplikasi yang di-deploy di layanannya hanya perlu menunjukkan kepatuhan dengan sisa kontrol yang tidak diimplementasikan di lapisan platform. |
Pengiriman yang lebih cepat
Rilis yang andal
Biaya yang lebih rendah
Karena layanan kini berukuran kecil dan dikaitkan secara longgar, tim yang terkait dengan layanan tersebut dapat bekerja secara otonom. Hal ini meningkatkan produktivitas developer dan kecepatan pengembangan.
Developer dapat dengan cepat mem-build, menguji, dan men-deploy layanan baru maupun yang sudah ada di lingkungan pengujian yang mirip dengan lingkungan produksi. Deployment ke produksi juga menjadi aktivitas kecil yang sederhana. Ini mempercepat proses pengiriman software dan mengurangi risiko deployment secara signifikan.
Biaya dan kompleksitas lingkungan pengujian dan produksi berkurang signifikan karena layanan standar yang digunakan bersama disediakan oleh platform dan karena aplikasi dijalankan di infrastruktur fisik yang digunakan bersama.
Keamanan yang lebih baik
Ketersediaan lebih tinggi
Kepatuhan yang lebih sederhana dan lebih murah
Vendor kini bertanggung jawab untuk menjaga agar layanan yang digunakan bersama, seperti DBMS dan infrastruktur untuk fitur pesan, tetap terbaru, di-patch, serta patuh. Di samping itu, juga jauh lebih mudah untuk menjaga aplikasi tetap di-patch dan terbaru karena ada cara standar untuk men-deploy dan mengelola aplikasi
Ketersediaan dan reliabilitas aplikasi meningkat karena kompleksitas lingkungan operasional berkurang, perubahan konfigurasi menjadi mudah dilakukan, dan penskalaan otomatis serta autohealing di level platform dapat ditangani.
Sebagian besar kontrol keamanan informasi dapat diterapkan di lapisan platform, sehingga membuatnya jauh lebih murah dan mudah untuk diterapkan serta menunjukkan kepatuhan. Banyak penyedia cloud menjaga kepatuhan dengan framework pengelolaan risiko, seperti SOC2 dan FedRAMP, yang berarti aplikasi yang di-deploy di layanannya hanya perlu menunjukkan kepatuhan dengan sisa kontrol yang tidak diimplementasikan di lapisan platform.
Namun, ada beberapa kompromi terkait model berbasis cloud:
- Semua aplikasi kini merupakan sistem terdistribusi, yang berarti aplikasi tersebut dapat membuat panggilan jarak jauh dalam jumlah yang signifikan sebagai bagian dari operasinya. Dengan demikian, Anda harus benar-benar memikirkan cara menangani kegagalan jaringan dan masalah performa, serta cara men-debug masalah di lingkungan produksi.
- Developer harus menggunakan sistem operasi, middleware, dan stack aplikasi standar yang disediakan oleh platform. Hal ini membuat pengembangan lokal menjadi lebih sulit.
- Arsitek perlu menggunakan pendekatan berbasis peristiwa pada desain sistem, termasuk menggunakan model konsistensi tertunda (eventual consistency).
Melakukan migrasi ke arsitektur berbasis cloud
Banyak organisasi menerapkan pendekatan “lift-and-shift” untuk memindahkan layanan ke cloud. Dalam pendekatan ini, sistem hanya memerlukan perubahan kecil dan cloud pada dasarnya diperlakukan sebagai pusat data tradisional, meskipun menyediakan API, layanan, dan alat manajemen yang jauh lebih baik dibandingkan dengan pusat data tradisional. Namun, pendekatan lift-and-shift tidak memberikan manfaat apa pun dari paradigma berbasis cloud yang telah dijelaskan sebelumnya.
Ada banyak organisasi yang terjebak oleh pendekatan lift-and-shift akibat biaya dan kompleksitas untuk memindahkan aplikasinya ke arsitektur berbasis cloud, karena perlu mempertimbangkan kembali segala sesuatunya mulai dari arsitektur aplikasi hingga operasi produksi, dan tentu saja seluruh siklus proses pengiriman software. Kekhawatiran ini rasional: banyak organisasi besar kandas karena gagal memindahkan platform secara total (biasa disebut 'big bang') setelah beberapa tahun berjalan.
Solusinya adalah menggunakan pendekatan bertahap, berulang, dan evolusioner untuk mendesain ulang arsitektur sistem Anda menjadi berbasis cloud, agar tim dapat mempelajari cara kerja yang efektif dalam paradigma baru ini sambil terus menghadirkan fungsi baru. Pendekatan ini kami sebut sebagai move-and-improve.
Salah satu pola utama dalam arsitektur evolusioner dikenal sebagai aplikasi "strangler fig".4 Alih-alih menulis ulang sistem sepenuhnya dari awal, tulis fitur baru dengan gaya modern berbasis cloud, tetapi minta mereka berkomunikasi dengan aplikasi monolitik asli untuk fungsionalitas yang ada. Secara bertahap, geser fungsi yang sudah ada seiring waktu sesuai keperluan demi integritas konseptual layanan baru, seperti yang ditunjukkan dalam Gambar 2.
4 Diuraikan dalam https://martinfowler.com/bliki/StranglerFigApplication.html
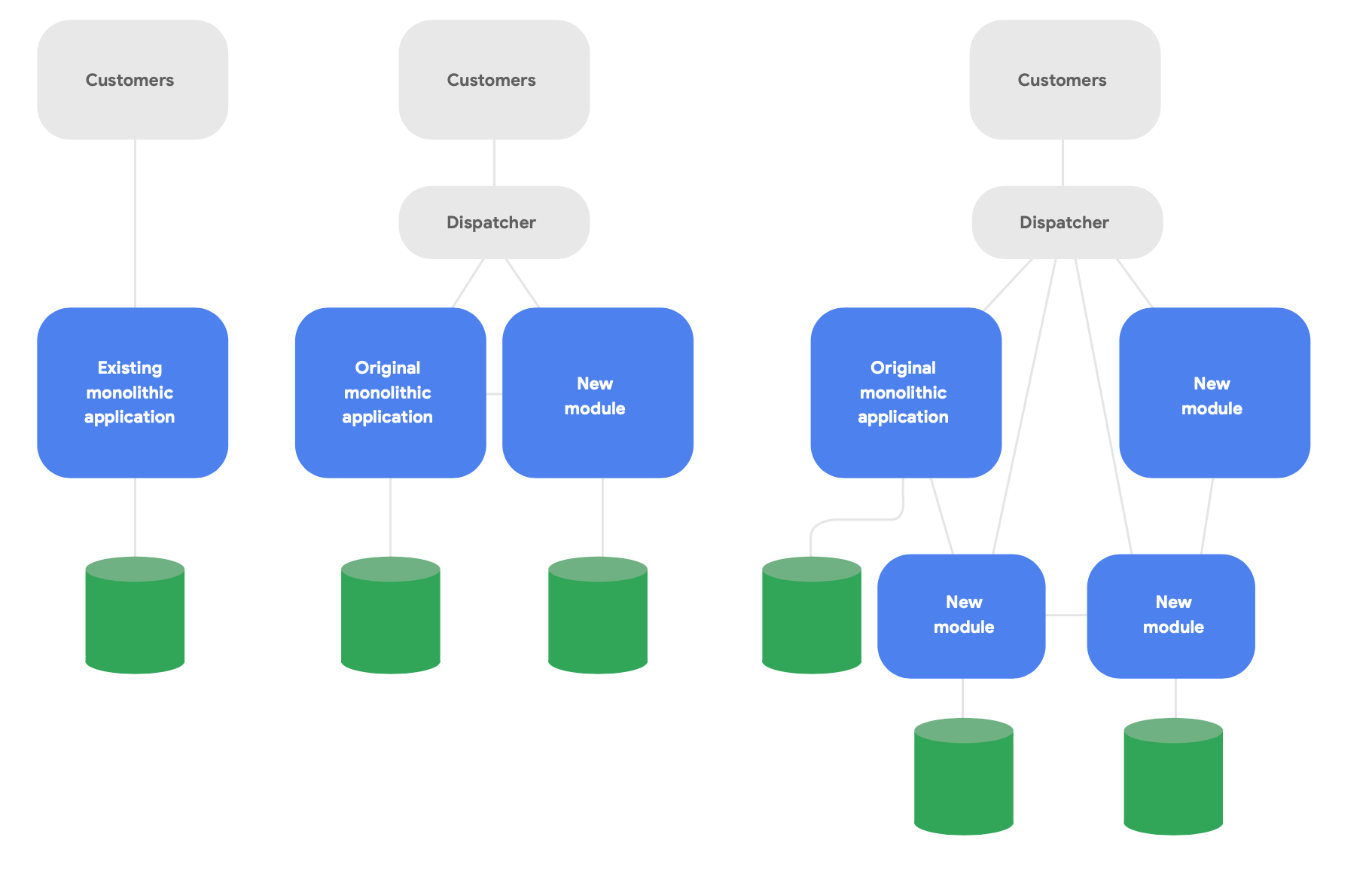
Berikut tiga panduan penting untuk mendesain ulang arsitektur dengan sukses:
Pertama, mulailah dengan mengirim fungsi baru dengan cepat alih-alih memproduksi ulang fungsi yang sudah ada. Metrik utamanya adalah seberapa cepat Anda dapat mulai mengirim fungsi baru menggunakan layanan baru, sehingga Anda dapat dengan cepat mempelajari dan mengomunikasikan praktik dengan baik yang diperoleh dari bekerja dalam paradigma ini. Pangkas cakupan secara agresif dengan tujuan untuk mengirim sesuatu kepada pengguna sungguhan dalam hitungan minggu, bukan bulan.
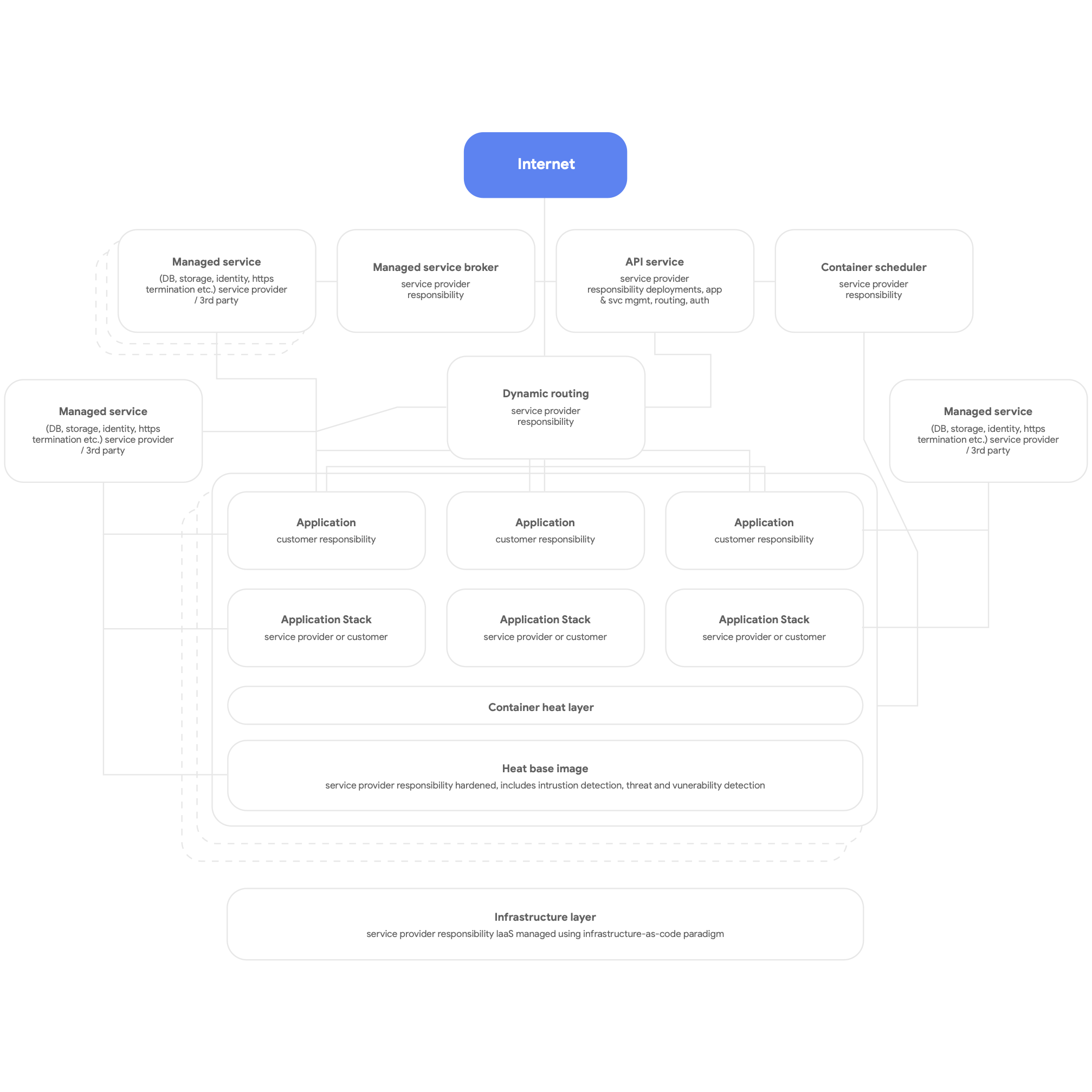
Kedua, desain agar berbasis cloud. Ini berarti Anda harus menggunakan layanan native berbasis platform cloud untuk DBMS, fitur pesan, CDN, networking, penyimpanan blob, dan sebagainya, serta menggunakan stack aplikasi yang disediakan platform standar jika memungkinkan. Layanan harus dipisah-pisah menggunakan container, memanfaatkan paradigma tanpa server jika memungkinkan, dan proses build, pengujian, serta deployment harus sepenuhnya otomatis. Buat agar semua aplikasi menggunakan layanan bersama yang disediakan platform untuk logging, pemantauan, dan pemberitahuan. (Perlu diperhatikan bahwa arsitektur platform semacam ini dapat digunakan dan dimanfaatkan untuk platform aplikasi multi-tenant apa pun, termasuk lingkungan server bare-metal yang tersedia secara lokal.) Gambar rangkuman platform berbasis cloud ditunjukkan dalam Gambar 3 di bawah.
Ketiga, desain dengan mengutamakan tim-tim otonom yang dikaitkan secara longgar agar mereka dapat menguji dan men-deploy layanannya sendiri. Riset kami menunjukkan bahwa arsitektur dinilai memenuhi ekspektasi jika tim pengiriman software dapat menjawab “ya” pada enam pernyataan berikut:
- Kami dapat membuat perubahan skala besar terhadap desain sistem kami tanpa izin dari orang di luar tim
- Kami dapat membuat perubahan skala besar terhadap desain sistem kami tanpa bergantung pada tim lain untuk melakukan perubahan pada sistem mereka atau tanpa mengakibatkan pekerjaan yang signifikan bagi tim lain
- Kami dapat menyelesaikan pekerjaan kami tanpa berkomunikasi dan berkoordinasi dengan orang di luar tim
- Kami dapat men-deploy dan merilis produk atau layanan kami secara on demand, terlepas dari layanan lain tempat produk atau layanan tersebut bergantung
- Kami dapat melakukan sebagian besar pengujian kami secara on demand, tanpa membutuhkan lingkungan pengujian terintegrasi
- Kami dapat melakukan deployment selama jam kerja normal dengan periode nonaktif yang dapat diabaikan
Periksa secara rutin apakah tim berusaha mencapai tujuan ini dan memprioritaskan upayanya untuk mencapai tujuan tersebut. Dalam hal ini, biasanya Anda perlu mempertimbangkan kembali arsitektur organisasi maupun perusahaan.
Secara khusus, sangat penting untuk mengatur tim agar semua peran yang diperlukan untuk mem-build, menguji, serta men-deploy software, termasuk product manager, dapat bekerja sama dan menerapkan praktik manajemen produk modern saat mem-build serta mengembangkan layanan yang mereka kerjakan. Hal ini tidak memerlukan perubahan pada struktur organisasi. Cukup atur agar developer, penguji, dan tim rilis bekerja sama sebagai tim setiap harinya (dan berada di ruangan yang sama jika memungkinkan) daripada memiliki developer, penguji, dan tim rilis yang beroperasi secara independen karena hal ini dapat membuat perbedaan besar pada produktivitas.
Riset kami menunjukkan bahwa semakin banyak jawaban "ya" diberikan oleh tim terhadap pernyataan-pernyataan tersebut, semakin besar kemungkinan untuk menghasilkan performa software yang tinggi: kemampuan untuk menghadirkan layanan andal dengan ketersediaan tinggi, beberapa kali per hari. Pada gilirannya, bekerja sama sebagai tim akan memungkinkan tim berperforma tinggi untuk meningkatkan produktivitas developer (diukur dalam jumlah deployment per developer per hari) bahkan ketika jumlah tim meningkat.
Prinsip dan praktik
Prinsip dan praktik arsitektur microservice
Ketika mengadopsi arsitektur berorientasi layanan atau microservice, ada beberapa prinsip dan praktik penting yang harus Anda ikuti. Sebaiknya Anda mengikuti prinsip dan praktik ini secara ketat sejak awal, karena untuk mengubahnya di kemudian hari biayanya akan jauh lebih mahal.
- Setiap layanan harus memiliki skema database-nya sendiri. Baik menggunakan database relasional maupun solusi NoSQL, setiap layanan harus memiliki skemanya sendiri yang tidak dapat diakses oleh layanan lain. Jika beberapa layanan berkomunikasi ke skema yang sama, seiring waktu layanan tersebut akan saling terkait erat di lapisan database. Dependensi ini menghambat layanan untuk bisa diuji dan di-deploy secara independen, yang akan membuat layanan tersebut semakin sulit diubah dan lebih berisiko saat di-deploy.
- Layanan hanya boleh berkomunikasi di jaringan melalui API publiknya masing-masing. Semua layanan harus menunjukkan perilakunya melalui API publik, dan layanan hanya boleh saling berkomunikasi melalui API tersebut. Tidak boleh ada akses “pintu belakang” (backdoor) atau layanan yang berkomunikasi langsung dengan database layanan lain. Hal ini diperlukan agar layanan tidak saling terkait erat, dan untuk memastikan bahwa komunikasi antarlayanan menggunakan API yang didukung dan terdokumentasi dengan baik.
- Layanan bertanggung jawab untuk memberikan kemampuan kompatibilitas mundur (backward compatibility) kepada kliennya. Tim yang membuat dan mengoperasikan suatu layanan bertanggung jawab untuk memastikan update ke layanan tidak merusak konsumennya. Itu berarti harus ada perencanaan untuk pembuatan versi API dan pengujian untuk kompatibilitas mundur, agar ketika Anda merilis versi aplikasi baru, Anda tidak merusak konsumen yang sudah ada. Tim dapat memvalidasi rilis baru menggunakan perilisan terbatas. Selain itu, juga harus dipastikan bahwa deployment tidak menimbulkan periode nonaktif, yang bisa dilakukan dengan teknik seperti blue-green deployment atau peluncuran bertahap.
- Buat cara standar untuk menjalankan layanan di workstation pengembangan. Developer harus dapat menjalankan subset layanan produksi apa pun di workstation pengembangan secara on demand menggunakan satu perintah. Selain itu, Anda juga seharusnya dapat menjalankan layanan versi stub secara on demand. Jadi, pastikan Anda menggunakan emulasi layanan cloud yang diberikan oleh banyak penyedia cloud untuk membantu Anda. Tujuannya adalah memudahkan developer untuk menguji dan men-debug layanan secara lokal.
- Berinvestasilah dalam kemampuan observasi dan pemantauan produksi. Ada banyak masalah di lingkungan produksi, termasuk masalah performa, yang muncul dan disebabkan oleh interaksi antara beberapa layanan. Riset kami menunjukkan bahwa penting untuk memiliki solusi yang melaporkan kesehatan sistem secara keseluruhan (misalnya, apakah sistem saya berfungsi? Apakah sistem saya memiliki resource yang memadai?) dan tim dapat mengakses alat dan data yang membantu mereka melacak, memahami, serta mendiagnosis masalah infrastruktur di lingkungan produksi, termasuk interaksi di antara layanan.
- Tetapkan tujuan tingkat layanan (SLO) untuk layanan Anda dan lakukan uji pemulihan dari bencana (disaster recovery) secara rutin. Menetapkan SLO untuk layanan Anda akan menentukan ekspektasi terkait bagaimana layanan akan berjalan. Penetapan ini juga dapat membantu Anda merencanakan perilaku sistem jika ada layanan yang mati (pertimbangan utama ketika mem-build sistem terdistribusi yang tangguh). Uji bagaimana sistem akan berperilaku dalam situasi sungguhan dengan teknik seperti injeksi kegagalan terkendali, dan masukkan itu ke rencana uji pemulihan dari bencana Anda. Riset DORA menunjukkan bahwa organisasi yang melakukan pengujian disaster recovery dengan metode seperti ini lebih berpeluang untuk memiliki tingkat ketersediaan layanan yang lebih tinggi. Semakin awal Anda memulai pengujian ini semakin baik, agar Anda dapat menormalisasi aktivitas vital semacam ini.
Ada banyak hal yang harus dipikirkan. Itulah sebabnya, penting untuk menguji coba tugas ini dengan tim yang memiliki kapasitas dan kemampuan untuk bereksperimen dengan menerapkan ide-ide ini. Hasilnya bisa sukses bisa gagal. Namun, penting untuk mengambil pelajaran dari tim-tim yang melakukan pengujian ini dan memanfaatkannya seiring Anda menyebarluaskan paradigma arsitektur baru di seluruh organisasi Anda.
Riset kami menunjukkan bahwa perusahaan yang sukses, menggunakan bukti konsep dan memberikan kesempatan kepada tim untuk membagikan pelajaran yang didapat. Misalnya dengan menciptakan komunitas praktik. Berikan waktu, ruang, dan sumber daya kepada orang-orang dari berbagai tim untuk bertemu secara rutin dan saling bertukar ide. Semua orang di organisasi Anda juga perlu mempelajari keahlian dan teknologi baru. Berinvestasilah pada pertumbuhan sumber daya manusia Anda dengan mengalokasikan anggaran bagi mereka untuk membeli buku, mengikuti kursus pelatihan, dan mengikuti konferensi. Berikan infrastruktur dan waktu kepada mereka untuk menyebarkan pengetahuan institusional dan praktik yang baik melalui milis perusahaan, pusat informasi, dan pertemuan tatap muka.
Arsitektur referensi
Di bagian ini, kami akan mendeskripsikan arsitektur referensi berdasarkan panduan berikut:
- Menggunakan container untuk layanan produksi dan scheduler container seperti Cloud Run atau Kubernetes untuk pengaturan alur kerja
- Membuat pipeline CI/CD yang efektif
- Fokus pada keamanan
Memisahkan layanan produksi menggunakan container
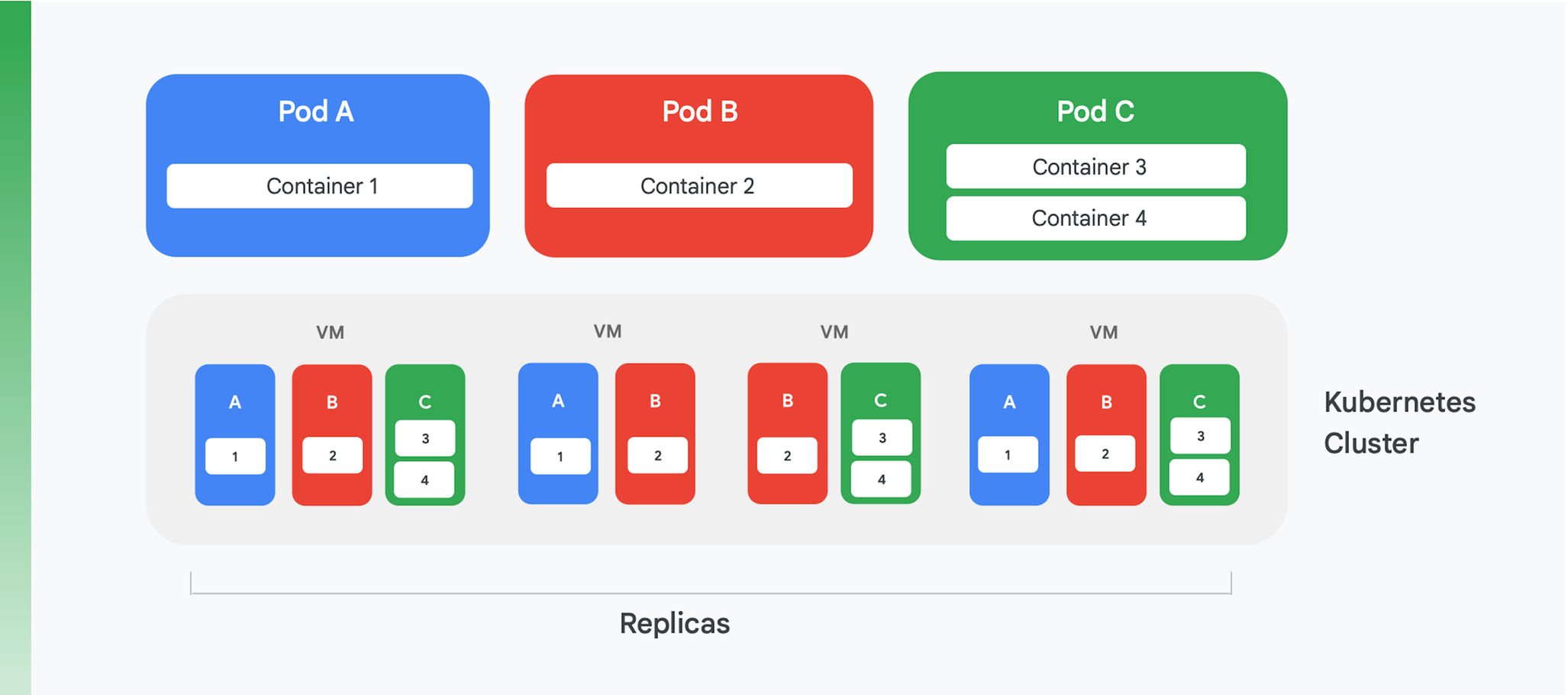
Landasan penting bagi pemisahan aplikasi cloud menggunakan container adalah pengelolaan container dan layanan pengaturan alur kerja. Meskipun sudah ada banyak layanan yang telah diciptakan, hanya ada satu layanan yang tetap dominan saat ini: Kubernetes. Kubernetes kini menetapkan standar orkestrasi container dalam industri, yang menampung komunitas yang aktif dan memperoleh dukungan dari banyak vendor komersial terkemuka. Rangkuman struktur logis dari cluster Kubernetes dapat dilihat di Gambar 4.
Kubernetes mendefinisikan suatu abstraksi yang disebut pod. Masing-masing pod sering kali berisi hanya satu container, seperti pod A dan B dalam Gambar 4, meskipun satu pod dapat berisi lebih dari satu container, seperti pod C. Setiap layanan Kubernetes menjalankan suatu cluster yang berisi sejumlah node, yang masing-masing biasanya merupakan mesin virtual (VM). Gambar 4 hanya menampilkan empat VM, tetapi cluster sungguhan dapat berisi seratus VM atau lebih. Ketika satu pod di-deploy di cluster Kubernetes, layanan akan menentukan VM mana yang harus dijalankan oleh container pod. Karena container menentukan resource yang diperlukan VM, Kubernetes dapat dengan cerdas memilih pod mana yang akan ditugaskan untuk masing-masing VM.
Salah satu bagian informasi deployment yang diterima sebuah pod adalah indikasi banyaknya jumlah instance, atau replika, pod yang harus dijalankan. Layanan Kubernetes kemudian membuat instance pada container pod sebanyak angka yang diindikasikan tersebut dan menugaskannya ke VM. Misalnya dalam Gambar 4, deployment pod A meminta tiga replika, begitu pula deployment pod C. Namun, deployment pod B meminta empat replika, dan karenanya cluster contoh ini berisi empat instance yang sedang berjalan pada container 2. Dan seperti ditunjukkan oleh gambar, container-container pada pod yang memiliki lebih dari satu container, seperti pod C, akan selalu ditetapkan ke node yang sama.
Kubernetes juga menyediakan layanan lain, termasuk:
- Pemantauan pod yang sedang berjalan, sehingga jika ada container mengalami kegagalan, layanan akan memulai instance baru. Tindakan ini untuk memastikan bahwa semua replika yang diminta dalam deployment pod tetap tersedia.
- Melakukan load balancing pada traffic, yakni dengan cerdas menyebarkan permintaan yang dibuat ke setiap pod ke seluruh replika pada suatu container.
- Peluncuran nol periode nonaktif otomatis pada container baru, di mana instance baru mengganti instance yang sudah ada secara bertahap sampai versi baru di-deploy sepenuhnya.
- Penskalaan otomatis, di mana penambahan atau penghapusan VM dilakukan oleh cluster secara otonom sesuai permintaan.
Membuat pipeline CI/CD yang efektif
Sejumlah manfaat melakukan pemfaktoran ulang aplikasi monolitik, seperti biaya yang lebih rendah, dapat langsung diperoleh dengan menjalankan aplikasi di Kubernetes. Namun, salah satu manfaat yang paling penting, yakni kemampuan untuk lebih sering mengupdate aplikasi Anda, hanya bisa didapatkan jika Anda mengubah cara mem-build dan merilis software. Untuk mendapatkan manfaat ini, Anda harus membuat pipeline CI/CD yang efektif di organisasi Anda.
Continuous integration mengandalkan build otomatis dan alur kerja pengujian yang memberikan masukan cepat bagi developer. Semua anggota tim harus mengerjakan kode yang sama (misalnya, kode untuk sebuah layanan) agar dapat mengintegrasikan pekerjaan secara rutin menjadi "trunk" atau mainline bersama. Integrasi ini harus dilakukan setidaknya setiap hari per developer, dengan masing-masing integrasi diverifikasi oleh proses build yang mencakup pengujian otomatis. Continuous delivery bertujuan membuat deployment kode terintegrasi ini menjadi cepat dan berisiko rendah, terutama dengan mengotomatiskan proses build, pengujian, dan deployment sehingga aktivitas seperti performa, keamanan, dan pengujian yang bersifat eksploratif dapat dilakukan secara berkelanjutan. Sederhananya, Continuous Integration (CI) membantu developer mendeteksi masalah integrasi dengan cepat, sedangkan Continuous Delivery (CD) membuat deployment dapat diandalkan dan dapat dilakukan secara rutin.
Agar lebih jelas, mari kita lihat contoh nyatanya. Gambar 5 menunjukkan tampilan pipeline CI/CD menggunakan alat Google untuk container yang dijalankan di Google Kubernetes Engine.
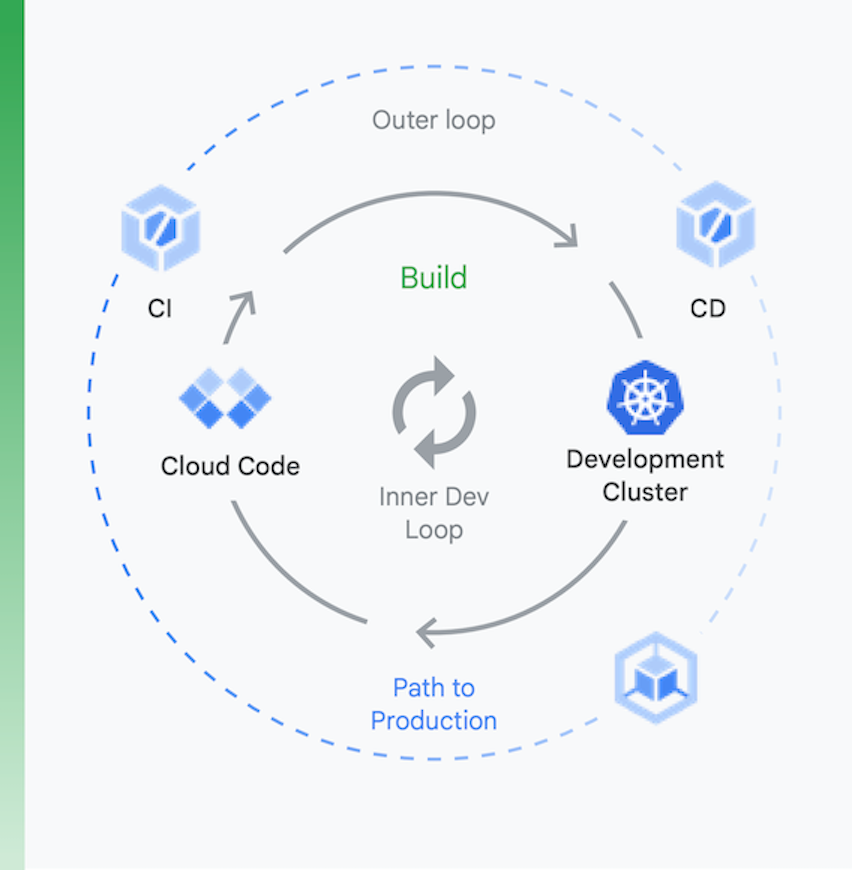
Sebaiknya kita lihat proses ini dalam dua bagian, seperti yang ditunjukkan dalam Gambar 6:
Pengembangan lokal | Pengembangan jarak jauh |
Di sini, tujuannya adalah mempercepat loop pengembangan di bagian dalam dan memberikan alat kepada developer untuk mendapatkan masukan dengan cepat terkait dampak perubahan kode lokal. Ini mencakup dukungan untuk analisis lint, pelengkapan otomatis untuk YAML, dan build lokal yang lebih cepat. | Saat permintaan pull (PR) dikirimkan, loop pengembangan jarak jauh akan dimulai. Tujuannya di sini adalah untuk secara drastis mengurangi waktu yang dibutuhkan untuk memvalidasi dan menguji PR melalui CI serta melakukan aktivitas lain seperti pemindaian kerentanan dan penandatanganan program biner, sekaligus mendorong persetujuan rilis secara otomatis. |
Pengembangan lokal
Pengembangan jarak jauh
Di sini, tujuannya adalah mempercepat loop pengembangan di bagian dalam dan memberikan alat kepada developer untuk mendapatkan masukan dengan cepat terkait dampak perubahan kode lokal. Ini mencakup dukungan untuk analisis lint, pelengkapan otomatis untuk YAML, dan build lokal yang lebih cepat.
Saat permintaan pull (PR) dikirimkan, loop pengembangan jarak jauh akan dimulai. Tujuannya di sini adalah untuk secara drastis mengurangi waktu yang dibutuhkan untuk memvalidasi dan menguji PR melalui CI serta melakukan aktivitas lain seperti pemindaian kerentanan dan penandatanganan program biner, sekaligus mendorong persetujuan rilis secara otomatis.
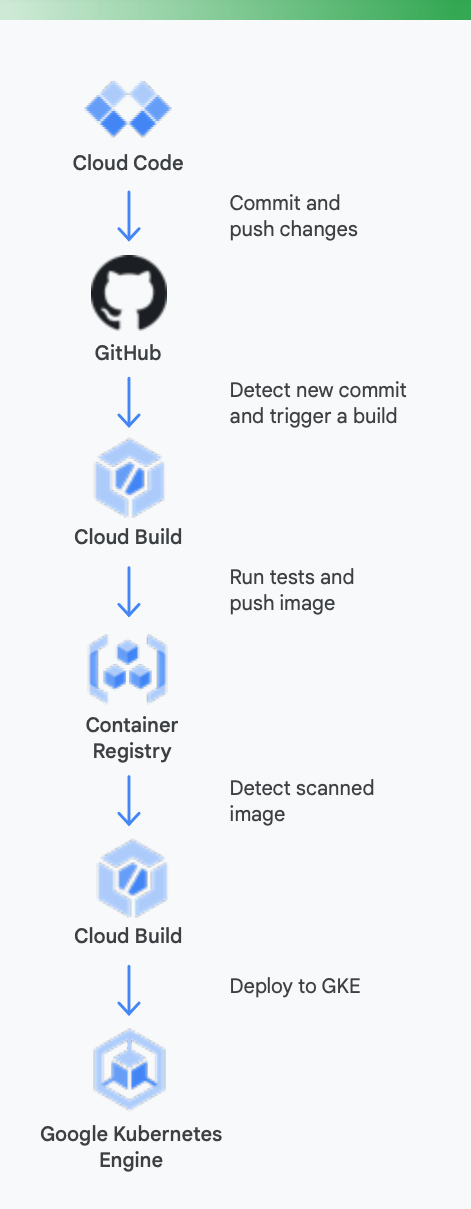
Berikut cara alat Google Cloud dapat membantu selama proses ini
Pengembangan lokal: Penting untuk membuat developer tetap produktif dengan pengembangan aplikasi lokal. Pengembangan lokal ini termasuk mem-build aplikasi yang dapat di-deploy ke cluster lokal dan jarak jauh. Jadi, sebelum melakukan perubahan pada sistem pengelolaan kontrol kode sumber seperti GitHub, Anda harus memiliki loop pengembangan lokal yang cepat untuk memastikan developer bisa menguji dan men-deploy perubahan ke cluster lokal.
Oleh karena itu, Google Cloud menyediakan Cloud Code. Cloud Code dilengkapi dengan ekstensi ke IDE, seperti Visual Studio Code dan intellij, agar developer dapat dengan cepat melakukan iterasi, melakukan debug, serta menjalankan kode di Kubernetes. Untuk menjalankan fungsinya, Cloud Code menggunakan beragam alat populer, seperti Skaffold, Jib, dan Kubectl, agar developer dapat menerima masukan secara terus-menerus terkait kode secara real time.
Continuous integration: Dengan Aplikasi GitHub Cloud Build yang baru, tim dapat memicu build pada peristiwa repo yang berbeda, seperti permintaan pull (pull request), pencabangan (branch), atau peristiwa tag (tag event) langsung dari GitHub. Cloud Build adalah platform yang sepenuhnya serverless dan dapat menaikkan maupun menurunkan penskalaan menurut beban tanpa harus menyediakan server sebelumnya atau membayar di muka untuk mendapatkan kapasitas ekstra. Build yang dipicu melalui Aplikasi GitHub secara otomatis memposting status kembali ke GitHub. Masukan ini terintegrasi langsung ke alur kerja developer GitHub, sehingga mengurangi pengalihan konteks.
Artifact Management: Container Registry adalah tempat terpusat bagi tim Anda untuk mengelola image Docker, menjalankan pemindaian kerentanan, dan menentukan siapa yang dapat mengakses dengan kontrol akses yang terperinci. Berkat integrasi pemindaian kerentanan dengan Cloud Build, developer dapat mengidentifikasi ancaman keamanan segera setelah Cloud Build membuat image dan menyimpannya di Container Registry.
Continuous delivery: Cloud Build menggunakan langkah-langkah build agar Anda dapat mendefinisikan langkah-langkah spesifik untuk dilakukan sebagai bagian dari proses build, pengujian, dan deployment. Misalnya, setelah container baru dibuat dan didorong ke Container Registry, langkah build berikutnya dapat men-deploy container tersebut ke Google Kubernetes Engine (GKE) atau Cloud Run—bersama konfigurasi dan kebijakan terkait. Anda juga dapat men-deploy ke penyedia cloud lain jika Anda ingin menggunakan strategi multicloud. Akhirnya, jika Anda menginginkan continuous delivery yang bergaya GitOps, dengan Cloud Build Anda juga dapat mendeskripsikan deployment secara deklaratif menggunakan file (misalnya, manifes Kubernetes) yang disimpan dalam repositori Git.
Namun, men-deploy kode bukanlah langkah terakhir. Organisasi juga harus mengelola kode saat kode tersebut dijalankan. Untuk melakukannya, Google Cloud menyediakan alat seperti Cloud Monitoring dan Cloud Logging kepada tim operasi.
Di GKE, Anda tidak perlu menggunakan CI/CD dari Google. Anda bebas untuk menggunakan toolchain alternatif jika menginginkannya. Misalnya, Anda dapat menggunakan Jenkins untuk CI/CD atau Artifactory untuk pengelolaan artefak.
Jika organisasi Anda seperti kebanyakan organisasi lain yang menggunakan aplikasi cloud berbasis VM, mungkin saat ini Anda belum memiliki sistem CI/CD yang berfungsi dengan baik. Anda harus memiliki sistem CI/CD yang baik jika ingin memperoleh hasil dari aplikasi Anda yang diarsitektur ulang, tetapi hal ini membutuhkan usaha lebih agar berhasil. Teknologi yang dibutuhkan untuk membuat pipeline sudah tersedia, sebagian berkat kematangan platform Kubernetes. Namun, perubahan yang dilakukan oleh manusia bisa jadi berperan penting di sini. Sumber daya manusia di tim pengiriman Anda harus bisa bekerja lintas-fungsi, termasuk untuk fungsi pengembangan, pengujian, dan pengoperasian. Mengganti budaya kerja memang membutuhkan waktu, jadi bersiaplah mendedikasikan upaya Anda untuk mengubah pengetahuan dan perilaku sumber daya manusia di organisasi Anda seiring mereka beralih ke ranah CI/CD.
Fokus pada keamanan
Mendesain ulang arsitektur aplikasi monolitik ke paradigma berbasis cloud adalah sebuah perubahan besar. Maka itu, tidak heran jika proses desain ulang ini memunculkan tantangan keamanan baru yang harus Anda tangani. Dua tantangan keamanan yang paling penting adalah:
- Mengamankan akses antar-container
- Memastikan supply chain software yang aman
Tantangan pertama berasal dari fakta yang sudah jelas: memecah aplikasi Anda menjadi layanan-layanan (dan mungkin microservice) di dalam container membutuhkan cara agar layanan-layanan tersebut dapat berkomunikasi satu sama lain. Dan walaupun semua layanan berpotensi dijalankan di cluster Kubernetes yang sama, Anda masih perlu memikirkan cara untuk mengontrol akses di antara layanan-layanan tersebut. Lagi pula, Anda mungkin juga membagikan cluster Kubernetes itu ke aplikasi lain, dan Anda tidak boleh membiarkan aplikasi lain tersebut mengakses container Anda.
Untuk mengontrol akses ke suatu container, Anda perlu mengautentikasi pemanggilnya, kemudian menentukan 17 permintaan apa yang dapat dibuat oleh container lain tersebut. Saat ini, biasanya masalah tersebut (dan sejumlah masalah lainnya) dapat diatasi menggunakan mesh layanan. Contoh utamanya adalah Istio, sebuah project open source yang dibuat oleh Google, IBM, dan perusahaan lainnya. Gambar 7 menunjukkan posisi Istio di dalam cluster Kubernetes.
Seperti yang ditunjukkan dalam gambar, proxy Istio mencegat semua traffic antar-container yang ada di aplikasi Anda. Hal ini memungkinkan mesh layanan untuk menyediakan beberapa layanan yang bermanfaat tanpa perlu mengubah kode aplikasi Anda. Layanan tersebut meliputi:
- Keamanan, dengan autentikasi service-to-service menggunakan TLS maupun autentikasi pengguna akhir
- Pengelolaan traffic, membuat Anda dapat mengontrol cara permintaan diarahkan di antara container di aplikasi Anda
- Kemampuan observasi, menangkap metrik komunikasi dan log di antara container Anda
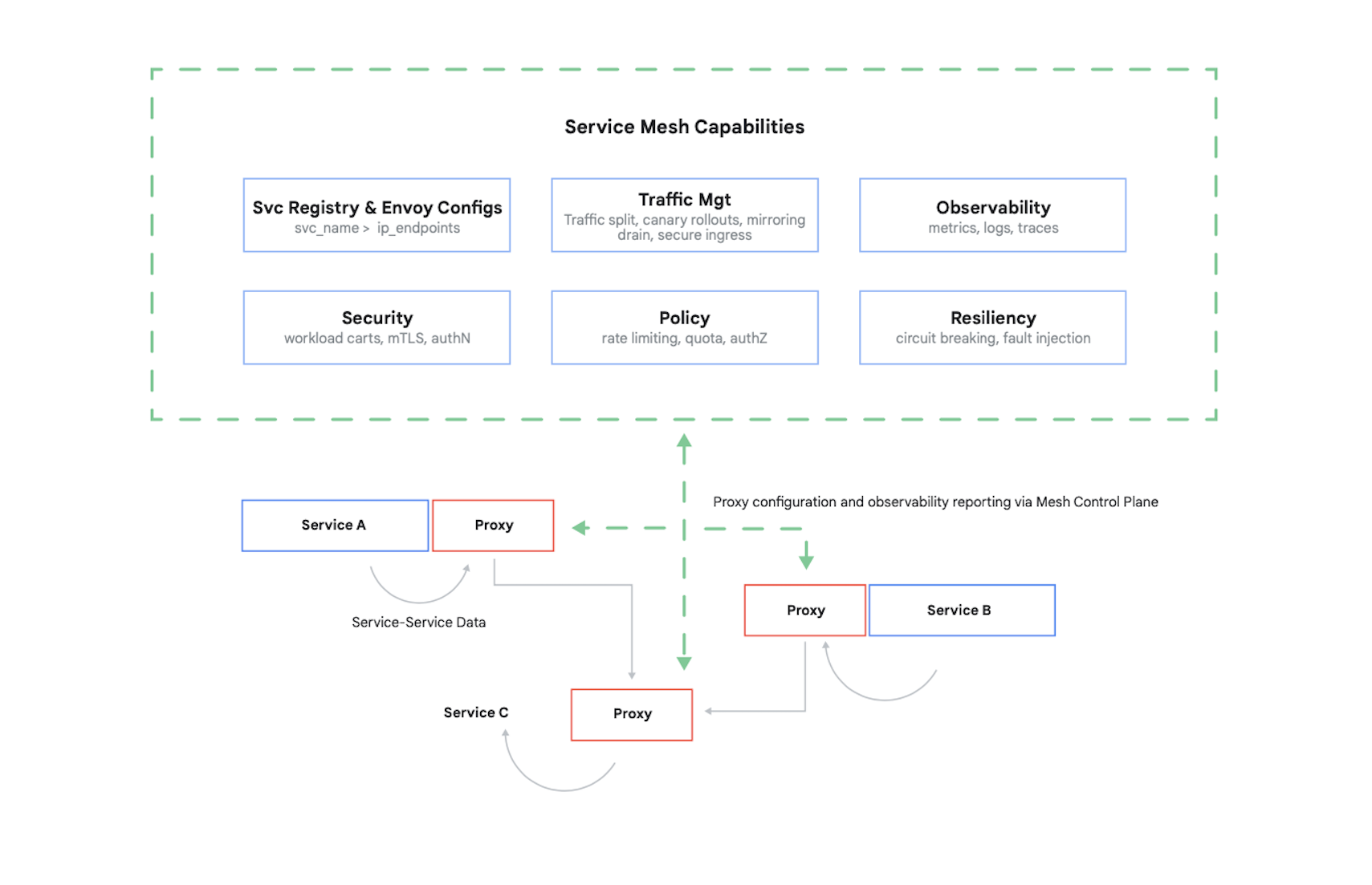
Google Cloud memungkinkan Anda menambahkan Istio ke cluster GKE. Dan meskipun penggunaan mesh layanan tidak diperlukan, jangan heran jika pelanggan yang sudah paham dengan aplikasi cloud Anda mulai menanyakan apakah keamanan aplikasi Anda sesuai dengan tingkat yang disediakan Istio atau tidak. Pelanggan sangat peduli soal keamanan, dan di dunia aplikasi yang berbasis container seperti sekarang ini, Istio berperan penting dalam memberikan rasa aman.
Selain mendukung Istio yang bersifat open source, Google Cloud juga menawarkan Traffic Director, yaitu sebuah bidang kontrol mesh layanan yang sepenuhnya dikelola oleh Google Cloud yang menghadirkan kemampuan load balancing global di seluruh cluster dan instance VM di beberapa region, menurunkan health check dari proxy layanan, dan menyediakan manajemen traffic yang canggih serta kemampuan lain yang dijelaskan di atas.
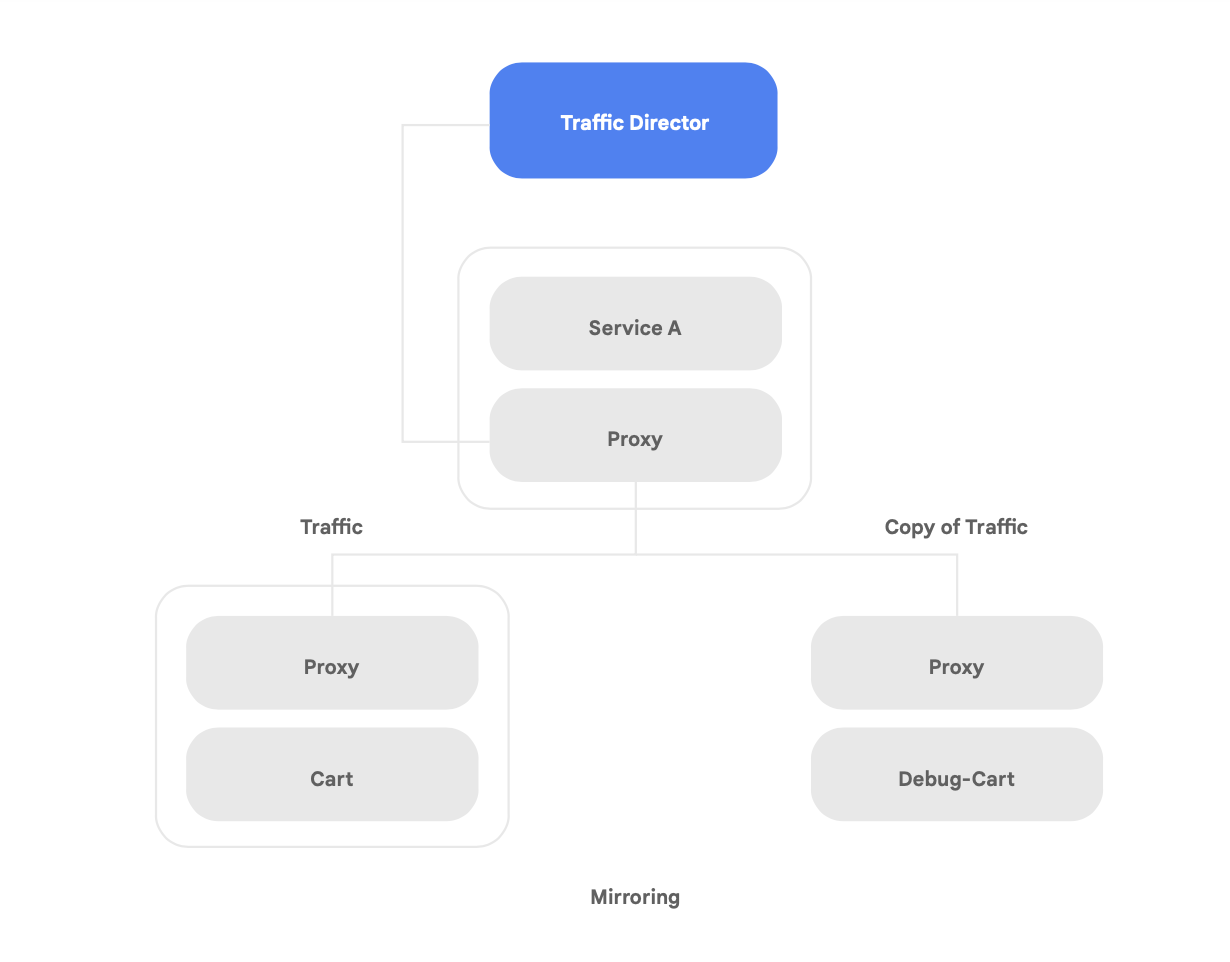
Salah satu kemampuan unik Traffic Director adalah overflow dan failover lintas-region otomatis untuk microservice di mesh (ditunjukkan dalam Gambar 8).
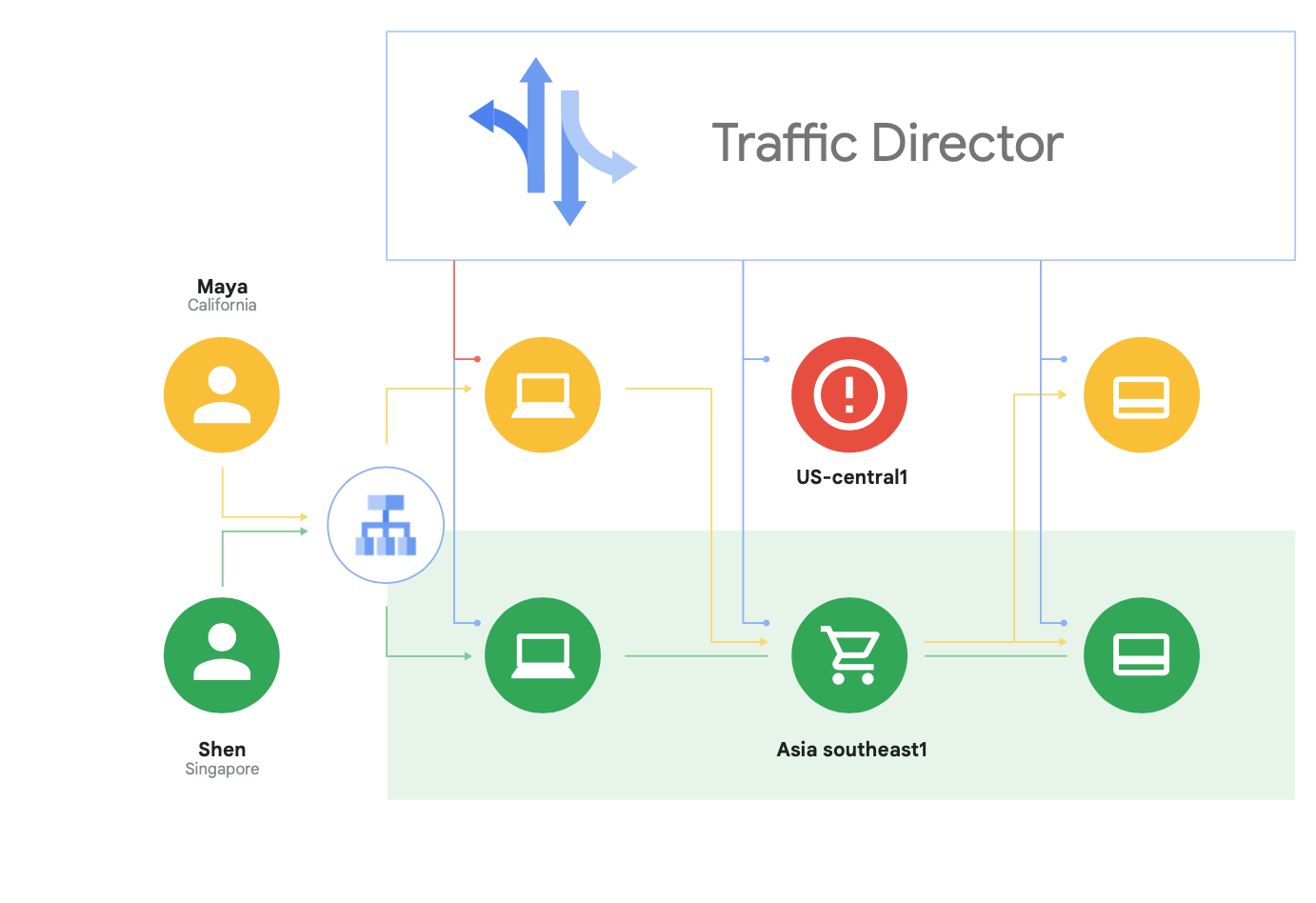
Dengan kemampuan ini, Anda dapat memadukan ketangguhan global dengan keamanan untuk layanan Anda di mesh layanan.
Traffic Director menawarkan beberapa fitur pengelolaan traffic yang dapat membantu meningkatkan postur keamanan mesh layanan Anda. Misalnya—fitur pencerminan traffic yang ditampilkan pada Gambar 9 dapat dengan mudah disiapkan sebagai kebijakan untuk mengizinkan aplikasi bayangan menerima salinan traffic sungguhan yang sedang diproses oleh aplikasi versi utama. Respons salinan yang diterima oleh layanan bayangan akan dihapus setelah pemrosesan. Pencerminan traffic dapat menjadi alat yang canggih untuk menguji anomali keamanan dan error debug dalam traffic produksi tanpa memengaruhi atau menyentuh traffic produksi.
Namun, melindungi interaksi di antara container Anda bukan satu-satunya tantangan keamanan baru yang muncul akibat pemfaktoran ulang aplikasi. Masalah lainnya adalah memastikan bahwa image container yang Anda jalankan dapat dipercaya. Untuk melakukannya, Anda harus memastikan bahwa supply chain software Anda aman dan patuh.
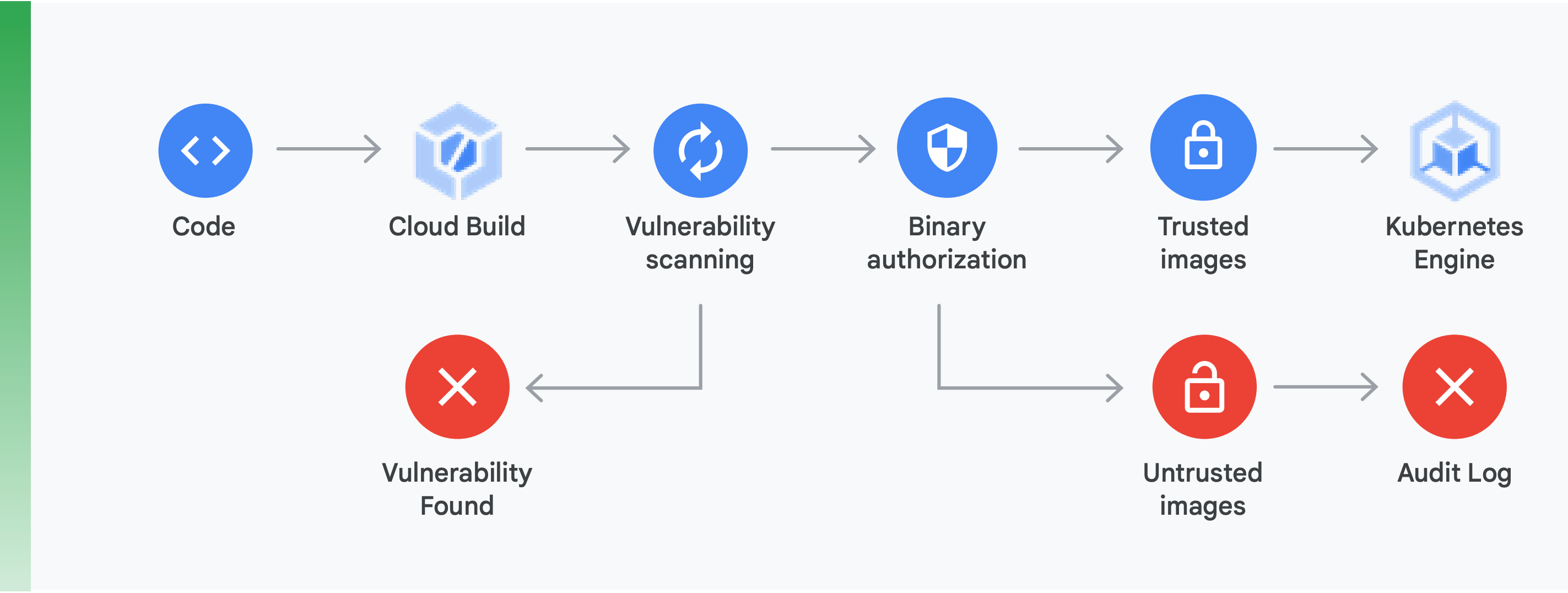
Untuk melakukan ini, Anda harus melakukan dua hal utama (ditunjukkan dalam Gambar 10):
Pemindaian kerentanan: Dengan pemindaian kerentanan Container Registry, Anda bisa mendapatkan masukan dengan cepat terkait ancaman potensial dan mengidentifikasi masalah sesegera mungkin setelah container Anda dibangun menggunakan Cloud Build dan disimpan di Container Registry. Kerentanan paket untuk Ubuntu, Debian, dan Alpine diidentifikasi langsung selama proses pengembangan aplikasi, dengan dukungan untuk CentOS dan RHEL yang akan segera hadir. Hal ini membantu menghindari inefisiensi yang memakan biaya tinggi dan mempersingkat waktu yang diperlukan untuk memperbaiki kerentanan yang telah diketahui.
Otorisasi Biner: Dengan memadukan pemindaian kerentanan Container Registry dan Otorisasi Biner, Anda dapat mengatur deployment berdasarkan temuan pemindaian kerentanan sebagai bagian dari keseluruhan kebijakan deployment. Otorisasi Biner adalah kontrol keamanan berdasarkan waktu deployment untuk memastikan bahwa hanya image container tepercaya yang di-deploy di GKE tanpa ada intervensi manual apa pun.
Mengamankan akses di antara container dengan mesh layanan dan memastikan supply chain software yang aman merupakan aspek penting dari pembuatan aplikasi berbasis container yang aman. Masih ada aspek lainnya, termasuk memverifikasi keamanan infrastruktur platform cloud yang Anda build. Namun, aspek terpentingnya adalah menyadari bahwa melakukan peralihan dari aplikasi monolitik ke paradigma modern berbasis cloud akan memunculkan tantangan keamanan baru. Agar transisi ini sukses, Anda harus memahami apa saja tantangan tersebut, lalu menyusun rencana konkret untuk mengatasinya.
Memulai
Jangan memperlakukan peralihan ke arsitektur berbasis cloud sebagai project "big-bang" yang dilakukan beberapa tahun sekali.
Sebaliknya, mulailah dari sekarang dengan mencari tim yang memiliki kapasitas dan keahlian untuk memulai prosesnya dengan bukti konsep, atau temukan tim yang sudah pernah melakukan peralihan ini. Lalu, ambil pelajaran dari hasil yang diperoleh dan mulailah menyebarkannya ke seluruh organisasi Anda. Minta tim untuk menerapkan pola "strangler fig", pindahkan layanan secara bertahap dan berulang ke arsitektur berbasis cloud sambil terus menghadirkan fungsi baru.
Agar berhasil, penting bagi tim untuk memiliki kapasitas, sumber daya, dan otoritas yang diperlukan untuk membuat proses pengembangan arsitektur sistem menjadi bagian dari pekerjaan sehari-harinya. Tetapkan tujuan arsitektur yang jelas untuk pekerjaan baru ini dengan mengikuti enam hasil arsitektur yang telah diuraikan sebelumnya. Namun, berikan kebebasan kepada tim untuk memilih cara mencapai tujuan tersebut.
Yang terpenting, jangan menunda-nunda untuk memulai! Peningkatan produktivitas dan kelincahan tim Anda serta keamanan dan stabilitas layanan Anda akan menjadi semakin penting bagi kesuksesan organisasi Anda. Tim terbaik adalah tim yang menjadikan eksperimen dan peningkatan secara disiplin sebagai bagian dari pekerjaan sehari-harinya.
Google-lah yang menciptakan Kubernetes, berdasarkan software yang telah kami gunakan secara internal selama bertahun-tahun. Itulah sebabnya kami memiliki pengalaman paling mendalam terkait teknologi berbasis cloud.
Google Cloud sangat berfokus pada aplikasi dalam container, seperti yang telah dibuktikan oleh solusi keamanan dan CI/CD yang kami tawarkan. Faktanya sudah jelas: Google Cloud saat ini adalah pemimpin dalam dukungan untuk aplikasi dalam container.
Buka cloud.google.com/devops untuk melakukan Pemeriksaan Cepat dan mengetahui performa organisasi Anda serta mendapatkan saran untuk melanjutkan proses peralihan, termasuk mengimplementasikan pola yang dibahas dalam laporan resmi ini, seperti arsitektur yang dikaitkan secara longgar.
Banyak partner Google Cloud telah membantu organisasi seperti milik Anda melakukan transisi ini. Untuk apa Anda mendesain ulang sendiri arsitektur jika kami dapat menghubungkan Anda dengan pemandu berpengalaman?
Untuk memulai, hubungi kami agar dapat mengatur pertemuan dengan arsitek solusi Google. Kami dapat membantu Anda memahami perubahan, lalu bekerja sama dengan Anda untuk mewujudkannya.
Bacaan lebih lanjut
https://cloud.google.com/devops - Laporan State of DevOps Report selama enam tahun, sebuah kumpulan artikel yang berisi informasi mendalam mengenai kemampuan untuk memprediksi performa pengiriman software, dilengkapi pemeriksaan cepat untuk membantu Anda mengetahui performa organisasi Anda dan cara meningkatkannya.
Site Reliability Engineering: How Google Runs Production Systems (O'Reilly 2016)
The Site Reliability Workbook: Practical Ways to Implement SRE (O'Reilly 2018)
“How to break a Monolith into Microservices: What to decouple and when” oleh Zhamak Dehghani
“Microservices: a definition of this new architectural term” oleh Martin Fowler
“Strangler Fig Application” oleh Martin Fowler
Siap untuk mengambil langkah berikutnya?
Isi formulir dan kami akan menghubungi Anda. Hubungi Bagian Penjualan











