Crea una piattaforma di dati di analisi unificata e moderna con Google Cloud
Scopri quali sono i punti decisionali necessari per creare una piattaforma di dati di analisi unificata e moderna basata su Google Cloud.
Autori: Firat Tekiner e Susan Pierce

Panoramica
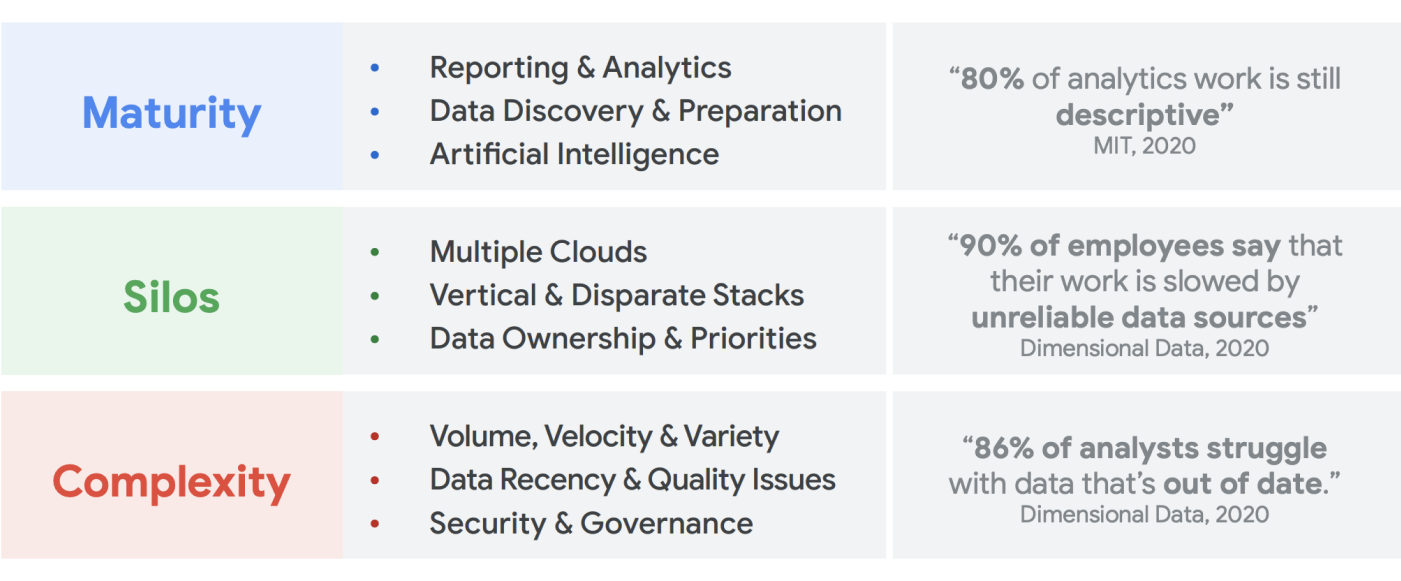
Il volume dei dati che vengono creati è considerevole. Una ricerca di IDC indica che i dati in tutto il mondo aumenteranno fino a 175 zettabyte entro il 2025.1 Il volume di dati generati ogni giorno è impressionante ed è sempre più difficile per le aziende raccoglierli, archiviarli e organizzarli in un modo accessibile e fruibile. Infatti, il 90% dei professionisti dei dati afferma che il proprio lavoro è stato rallentato da origini dati inaffidabili. Circa l'86% degli analisti di dati è alle prese con dati obsoleti e oltre il 60% dei data worker risente del fatto di dover attendere risorse tecniche ogni mese mentre i dati vengono puliti e preparati2.
Strutture organizzative e decisioni architettoniche inefficienti contribuiscono al divario tra l'aggregazione dei dati e il loro utilizzo da parte delle aziende. Le aziende vogliono passare al cloud per modernizzare i propri sistemi di analisi dei dati, ma questo da solo non risolve i problemi di fondo legati a origini dati in silos e pipeline di elaborazione fragili. Le decisioni strategiche sulla proprietà dei dati e le decisioni tecniche sui meccanismi di archiviazione devono essere prese in modo olistico per fare in modo che una piattaforma dati sia più efficiente per l'organizzazione.
In questo articolo vengono illustrati i punti decisionali necessari per la creazione di una piattaforma di dati di analisi unificata e moderna basata su Google Cloud.
Negli ultimi due decenni, i big data hanno creato opportunità straordinarie per le aziende. Tuttavia, per le organizzazioni è difficile fornire dati pertinenti, strategici e tempestivi ai propri utenti aziendali. Gli studi dimostrano che l'86% degli analisti è ancora alle prese con dati obsoleti3 e solo il 32% delle aziende ritiene di realizzare un valore tangibile dai dati4. Il primo problema è l'aggiornamento dei dati. Il secondo problema deriva dalla difficoltà di integrare sistemi eterogenei e legacy in più silos. Le organizzazioni stanno migrando al cloud, ma questo non risolve il vero problema dei vecchi sistemi legacy che potrebbero essere stati strutturati verticalmente per soddisfare le esigenze di una singola unità aziendale.
Nel pianificare le esigenze in materia di dati organizzativi, è facile generalizzare e prendere in considerazione una singola struttura semplificata che presenta un insieme di origini dati coerenti, un data warehouse aziendale, un insieme di semantica e uno strumento per la business intelligence. Potrebbe funzionare per un'organizzazione molto piccola e altamente centralizzata e persino per una singola unità aziendale con un proprio team IT e di data engineering integrato. In realtà, però, nessuna organizzazione è così semplice e ci sono sempre complessità inattese per quanto riguarda l'importazione, l'elaborazione e/o l'utilizzo dei dati che complicano ulteriormente le cose.
Parlando con centinaia di clienti abbiamo riscontrato la necessità di un approccio più olistico ai dati e all'analisi, una piattaforma in grado di soddisfare le esigenze di più unità aziendali e utenti tipo, con il minor numero di passaggi ridondanti possibile per elaborare i dati. Questo comporta più di una nuova architettura o di un insieme di componenti software da acquistare; richiede che le aziende facciano il punto sulla loro maturità complessiva in materia di dati ed effettuino cambiamenti sistemici e organizzativi oltre agli aggiornamenti tecnici.
Entro la fine del 2024, il 75% delle aziende passerà dalla fase pilota alla fase operativa dell'IA, generando un aumento di cinque volte dei dati in streaming e delle infrastrutture di analisi5. È facile pilotare l'AI con un team di data scientist a portata di mano che lavora in un ambiente isolato. Ma la sfida fondamentale che impedisce il rilascio di questi insight nei sistemi di produzione è l'attrito organizzativo e architettonico che mantiene segmentata la proprietà dei dati. Di conseguenza, la maggior parte degli insight incorporati nelle operazioni aziendali di un'organizzazione è di natura descrittiva e l'analisi predittiva resta confinata nell'ambito di un team di ricerca.

Una piattaforma per tutti gli utenti in tutto il ciclo di vita dei dati
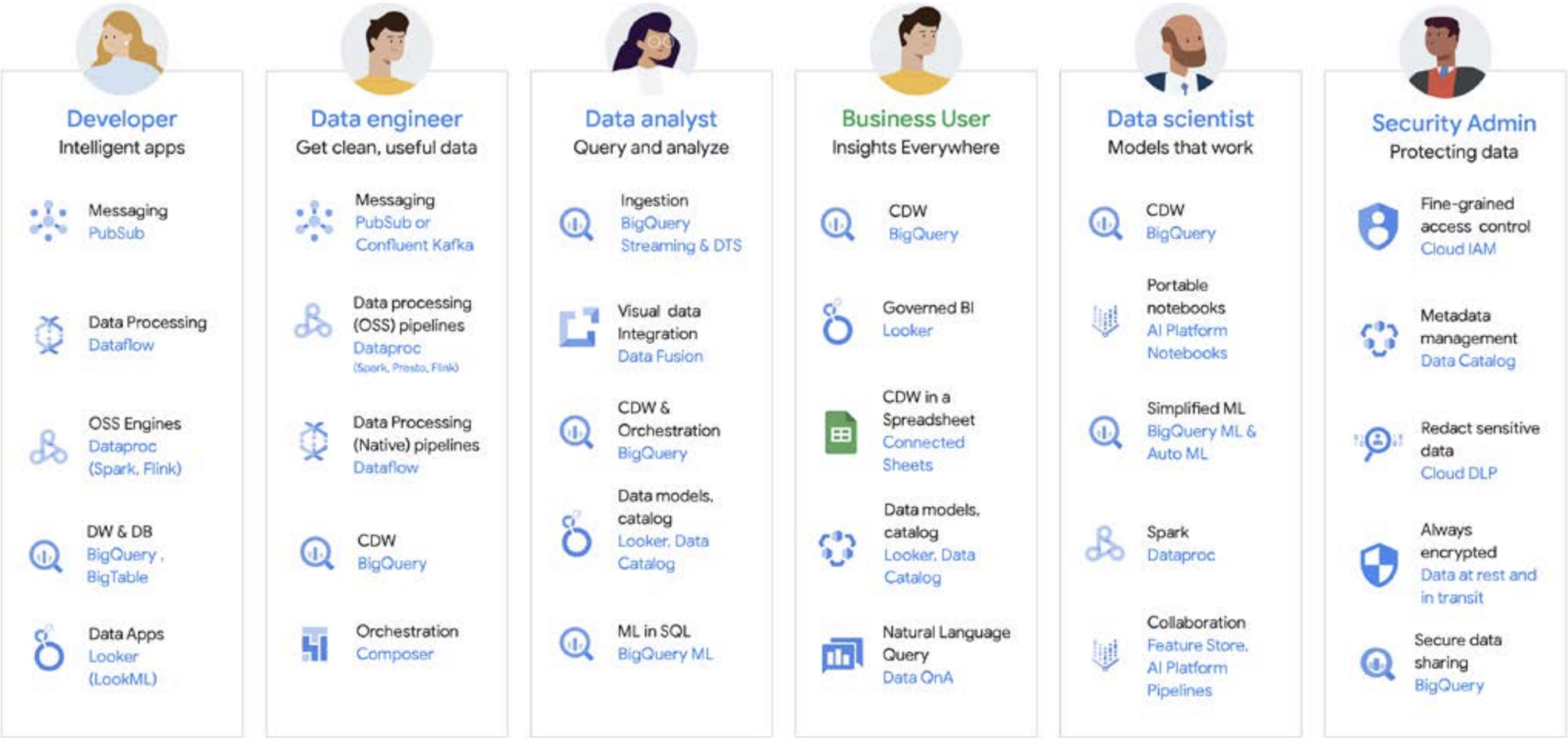
È raro che il lavoro sui dati venga eseguito da una sola persona. In un'organizzazione esistono molti utenti correlati ai dati che ricoprono ruoli importanti nel ciclo di vita dei dati. Ognuno di loro ha una prospettiva diversa su governance dei dati, aggiornamento, rilevabilità, metadati, tempistiche di elaborazione, interrogabilità e altri aspetti. Nella maggior parte dei casi, utilizzano sistemi e software diversi per operare sugli stessi dati, in diverse fasi dell'elaborazione.
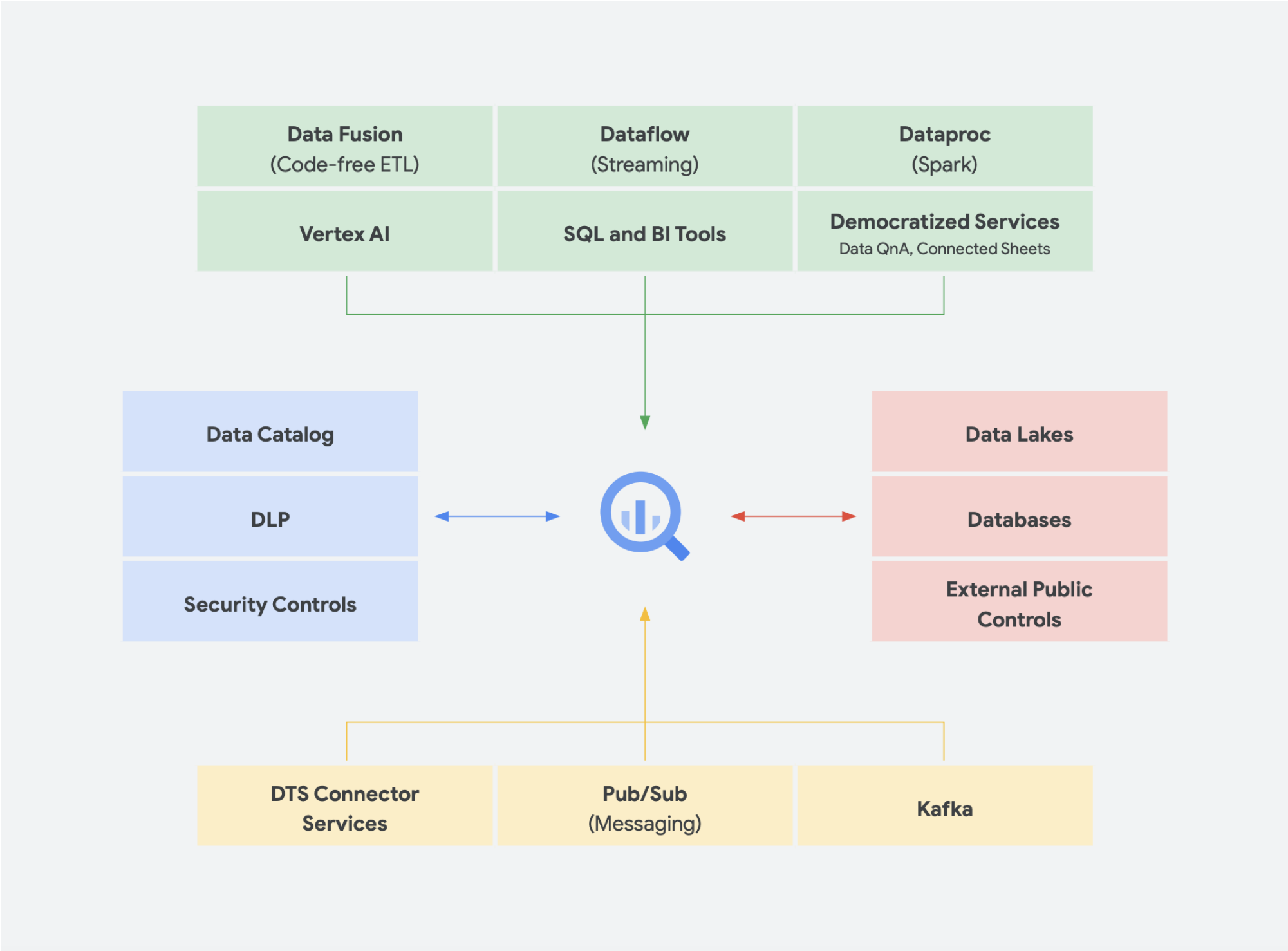
Vediamo ad esempio il ciclo di vita del machine learning. Un data engineer può essere tenuto a garantire che il team di data scientist disponga di dati aggiornati, con adeguati vincoli di sicurezza e privacy. Un data scientist può creare set di dati di addestramento e test sulla base di un insieme di origini dati pre-aggregati fornito dal data engineer, creare e testare modelli e mettere insight a disposizione di un altro team. Un tecnico ML potrebbe essere responsabile della pacchettizzazione del modello per il deployment nei sistemi di produzione, in modo da non disturbare le altre pipeline di elaborazione dati. Un product manager o un business analyst potrebbe controllare gli insight derivati, utilizzando Data QnA (un'interfaccia in linguaggio naturale per l'analisi dei dati di BigQuery) o un software di visualizzazione o eseguire query sul set di risultati direttamente tramite un ambiente IDE o un'interfaccia a riga di comando. Ci sono innumerevoli utenti con esigenze diverse e abbiamo creato una piattaforma completa per soddisfarli tutti. Google Cloud si adatta agli strumenti di cui i clienti dispongono, per soddisfare le esigenze dell'azienda.
La decisione sui big data: data warehouse o data lake?
Quando parliamo con i clienti delle loro esigenze di analisi dei dati, spesso ci viene posta questa domanda: "Mi serve un data lake o un data warehouse?". Data la varietà dei dati e delle esigenze degli utenti all'interno di un'organizzazione, può essere una domanda difficile, perché la risposta dipende dall'utilizzo previsto, dai tipi di dati e dal personale.
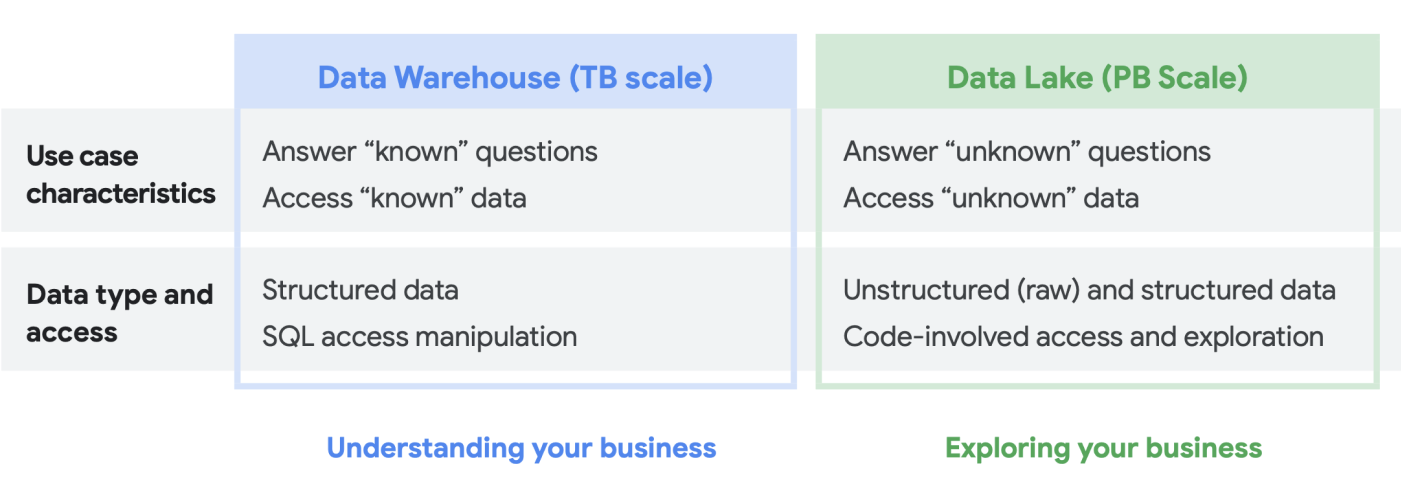
- Se sai quali set di dati devi analizzare, ne comprendi chiaramente la struttura e hai un insieme di domande note alle quali devi rispondere, probabilmente la soluzione migliore per te è un data warehouse.
- Se invece hai bisogno di rilevabilità su più tipi di dati, non sai esattamente quali tipi di analisi eseguire, sei alla ricerca di opportunità da esplorare anziché presentare informazioni e disponi delle risorse per gestire ed esplorare in modo efficace questo ambiente. un data lake può essere più adatto alle tue esigenze.
Ma la decisione non si limita a questi aspetti. Vediamo alcune delle sfide organizzative di ognuna delle due soluzioni. I data warehouse sono spesso difficili da gestire. I sistemi legacy che hanno funzionato bene negli ultimi 40 anni si sono dimostrati molto costosi e presentano molte criticità in termini di aggiornamento dei dati, scalabilità e costi elevati. Inoltre, non possono fornire facilmente funzionalità di AI o in tempo reale, se non aggiungendole a posteriori. Questi problemi non sono presenti solo nei data warehouse legacy on-premise, ma anche nei nuovi data warehouse basati su cloud. Molti non offrono funzionalità di IA integrate, nonostante ciò che dichiarano. Questi nuovi data warehouse sono essenzialmente gli stessi ambienti legacy, ma trasferiti nel cloud. Gli utenti dei data warehouse tendono a essere analisti, spesso inseriti in una specifica unità aziendale. Potrebbero avere idee su set di dati aggiuntivi che sarebbero utili per comprendere più a fondo l'attività. Potrebbero avere idee sui miglioramenti da apportare a livello di analisi, elaborazione dei dati e requisiti per le funzionalità di business intelligence.
Tuttavia, in un’organizzazione tradizionale, spesso non hanno accesso diretto ai proprietari dei dati, né possono facilmente influenzare i responsabili delle decisioni tecniche che decidono i set di dati e gli strumenti. Inoltre, poiché sono tenuti separati dai dati non elaborati, non sono in grado di testare ipotesi o di ottenere una comprensione più approfondita dei dati sottostanti. Anche i data lake presentano criticità specifiche. In teoria sono poco costosi e facilmente scalabili, ma molti dei nostri clienti hanno osservato una realtà diversa nei loro data lake on-premise. La pianificazione e il provisioning di una quantità sufficiente di spazio di archiviazione possono essere costosi e difficili, soprattutto per le organizzazioni che producono quantità di dati molto variabili. I data lake on-premise possono essere fragili e la manutenzione dei sistemi esistenti richiede tempo. In molti casi, gli ingegneri che altrimenti svilupperebbero nuove funzionalità sono relegati alla gestione e al popolamento di cluster di dati. In sostanza, mantengono il valore esistente anziché crearne di nuovo. Il costo totale di proprietà è complessivamente più alto del previsto per molte aziende. Inoltre, il problema della governance non è di facile soluzione in tutti i sistemi, soprattutto quando diverse parti dell'organizzazione utilizzano modelli di sicurezza diversi. Di conseguenza, i data lake diventano silos e segmentati, il che rende difficile la condivisione di dati e modelli tra i team.
Gli utenti del data lake di solito sono più vicini alle origini dati non elaborate e sono dotati di strumenti e funzionalità per esplorare i dati. Nelle organizzazioni tradizionali, questi utenti tendono a concentrarsi sui dati stessi e sono spesso tenuti a distanza dal resto dell'azienda. Questa disconnessione significa che le unità aziendali perdono l'opportunità di trovare informazioni che farebbero avanzare i loro obiettivi commerciali verso maggiori ricavi, minori costi, minori rischi e nuove opportunità. Di fronte a questi compromessi, molte aziende finiscono per adottare un approccio ibrido, in cui viene configurato un data lake per trasferire alcuni dati in un data warehouse oppure un data warehouse ha un data lake laterale per ulteriori test e analisi. Ma con più team che creano le proprie architetture di dati per soddisfare le proprie esigenze individuali, la condivisione e la fedeltà dei dati diventano ancora più complicate per un team IT centrale. Invece di avere team separati con obiettivi distinti, in cui uno esplora il business e l'altro lo comprende, è possibile unire queste funzioni e i relativi sistemi di dati per creare un circolo virtuoso in cui la comprensione più approfondita del business favorisce l'esplorazione e quella esplorazione porta a una migliore comprensione del business.
Tratta lo spazio di archiviazione del data warehouse come un data lake
Puoi creare separatamente un data warehouse o un data lake su Google Cloud, ma non devi necessariamente scegliere l'uno o l'altro. In molti casi, i prodotti di base che i nostri clienti utilizzano sono gli stessi per entrambi e l'unica differenza tra la loro implementazione del data lake e del data warehouse riguarda i criteri di accesso ai dati che vengono utilizzati. I due termini, infatti, stanno iniziando a convergere in un insieme di funzionalità più unificato, una moderna piattaforma di dati di analisi. Vediamo come funziona in Google Cloud.
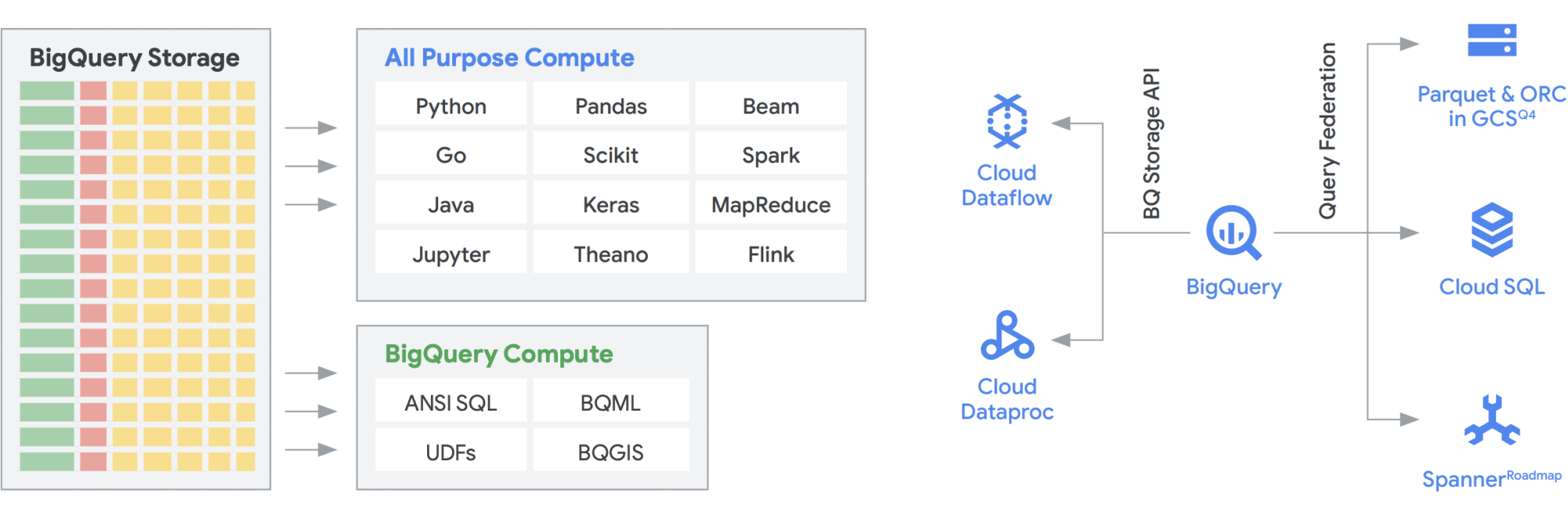
L'API BigQuery Storage offre la possibilità di utilizzare BigQuery Storage come Cloud Storage per una serie di altri sistemi come Dataflow e Managed Service for Apache Spark. Questo consente di abbattere le barriera di dello spazio di archiviazione dei data warehouse e di eseguire frame di dati ad alte prestazioni su BigQuery. In altre parole, l'API BigQuery Storage consente al tuo data warehouse BigQuery di agire come un data lake. Quindi, quali utilizzi pratici può avere questa funzionalità? Ad esempio, abbiamo creato una serie di connettori, come MapReduce, Hive e Spark, per consentirti di eseguire i tuoi carichi di lavoro Hadoop e Spark direttamente sui tuoi dati in BigQuery. Non è più necessario un data lake oltre al data warehouse. Dataflow è incredibilmente potente per l'elaborazione dei flussi e in batch. Oggi puoi eseguire job di Dataflow sui dati di BigQuery, arricchendoli con dati provenienti da Pub/Sub, Spanner o qualsiasi altra origine dati.
BigQuery può ridimensionare le risorse di archiviazione e di elaborazione in modo indipendente, entrambe serverless, consentendo una scalabilità illimitata per soddisfare la domanda a prescindere dall'utilizzo da parte di team, strumenti e modelli di accesso diversi. Tutte le applicazioni indicate sopra possono essere eseguite senza influire sulle prestazioni degli altri job che accedono contemporaneamente a BigQuery. Inoltre, l'API BigQuery Storage fornisce una rete a livello di petabit, spostando i dati tra i nodi per soddisfare una richiesta di query, ottenendo in modo efficace prestazioni simili a quelle di un'operazione in memoria. Consente inoltre la federazione diretta con i formati di dati Hadoop più diffusi, come Parquet e ORC, nonché con i database NoSQL e OLTP. Puoi fare un ulteriore passo avanti con le funzionalità fornite da Dataflow SQL, che è incorporato in BigQuery. Questo ti permette di unire i flussi con tabelle BigQuery o dati che risiedono nei file, creando efficacemente un'architettura lambda, che consente di importare grandi quantità di dati in batch e in flussi, fornendo al contempo un livello di pubblicazione per rispondere alle query. BigQuery BI Engine e le viste materializzate facilitano ancora di più l'incremento dell'efficienza e delle prestazioni in questa architettura multiuso.
La piattaforma di analisi intelligente di Google basata su BigQuery
Le soluzioni dati serverless sono indispensabili per consentire alla tua organizzazione di superare i silos di dati ed entrare nel regno degli insight e dell'azione. Tutti i nostri servizi di analisi dei dati principali sono serverless e strettamente integrati.

La gestione del cambiamento è spesso uno degli aspetti più difficili dell’integrazione di nuove tecnologie in un'organizzazione. Google Cloud cerca di agevolare al massimo i clienti, fornendo strumenti, piattaforme e integrazioni familiari sia per gli sviluppatori che per gli utenti aziendali. La nostra mission è accelerare la capacità della tua organizzazione di trasformare e reimmaginare digitalmente la propria attività attraverso l'innovazione basata sui dati, insieme. Anziché creare vincoli relativi al fornitore, Google Cloud offre alle aziende opzioni per integrazioni semplici e ottimizzate con ambienti on-premise, altre offerte cloud e persino Edge per dare vita a un cloud realmente ibrido:
- BigQuery Omni elimina la necessità di trasferire i dati da un ambiente all'altro e porta invece l'analisi ai dati, indipendentemente dall'ambiente
- Apache Beam, l'SDK utilizzato su Dataflow, offre trasferibilità e portabilità a strumenti come Apache Spark e Apache Flink.
- Per le organizzazioni che desiderano eseguire Apache Spark o Apache Hadoop, Google Cloud fornisce Managed Service for Apache Spark
Alla maggior parte degli utenti dei dati interessano i dati stessi, non il sistema in cui si trovano. Ciò che conta è avere accesso ai dati che servono, nel momento in cui servono. Quindi, nella maggior parte dei casi, il tipo di piattaforma non è rilevante per gli utenti, purché siano in grado di accedere a dati aggiornati e utilizzabili con strumenti familiari, quando esplorano set di dati, gestiscono le origini nei datastore, eseguono query ad hoc o sviluppano strumenti di business intelligence interni per gli stakeholder esecutivi.
Tendenze emergenti
Continuando con l'idea della convergenza di un data lake e di un data warehouse in una piattaforma di dati di analisi unificata, ci sono alcune soluzioni di dati aggiuntive che stanno guadagnando terreno. Sono emersi molti concetti che riguardano, ad esempio, lakehouse e data mesh. Forse hai già sentito nominare alcuni di questi termini. Alcuni non sono nuovi e circolano già da anni in forme e formati diversi. Comunque, funzionano molto bene all'interno dell'ambiente Google Cloud. Vediamo più da vicino come apparirebbero un data mesh e un lakehouse in Google Cloud e cosa significano per la condivisione dei dati all'interno di un'organizzazione. Lakehouse e data mesh non si escludono a vicenda, ma contribuiscono a risolvere sfide diverse all'interno di un'organizzazione. Uno è funzionale all'abilitazione dei dati, l'altro all'abilitazione dei team. Il data mesh consente di evitare di essere vincolati a un singolo team e, di conseguenza, abilita l'intero stack di dati. Suddivide i silos in unità organizzative più piccole in un'architettura che fornisce l'accesso ai dati in modo federato. Il lakehouse riunisce data warehouse e data lake, consentendo diversi tipi di dati e volumi di dati più elevati. Questo porta di fatto a schema-on-read anziché schema-on-write, una funzionalità dei data lake che si pensava potesse colmare alcune lacune di prestazioni nei data warehouse aziendali. Questa architettura offre anche l'ulteriore vantaggio di una governance dei dati più rigorosa, che in genere manca nei data lake.

Lakehouse
Come accennato in precedenza, l'API Storage di BigQuery consente di trattare il data warehouse come un data lake. I job Spark in esecuzione su Managed Service for Apache Spark o ambienti Hadoop simili possono utilizzare i dati archiviati su BigQuery, anziché richiedere un supporto di archiviazione separato effettuando l'archiviazione al di fuori del data warehouse. L'estrema potenza di calcolo, disaccoppiata dall'archiviazione in BigQuery, consente la trasformazione basata su SQL e utilizza visualizzazioni in diversi livelli di queste trasformazioni. Questo porta a un approccio di tipo ELT e rende possibile una piattaforma di elaborazione dati più agile. Sfruttando ELT su ETL, BigQuery consente di archiviare le trasformazioni basate su SQL come visualizzazioni logiche. Mentre il dump di tutti i dati non elaborati nello spazio di archiviazione del data warehouse può essere costoso con un data warehouse tradizionale, lo spazio di archiviazione di BigQuery non prevede addebiti premium. Ha un costo paragonabile all'archiviazione blob in Google Cloud Storage.
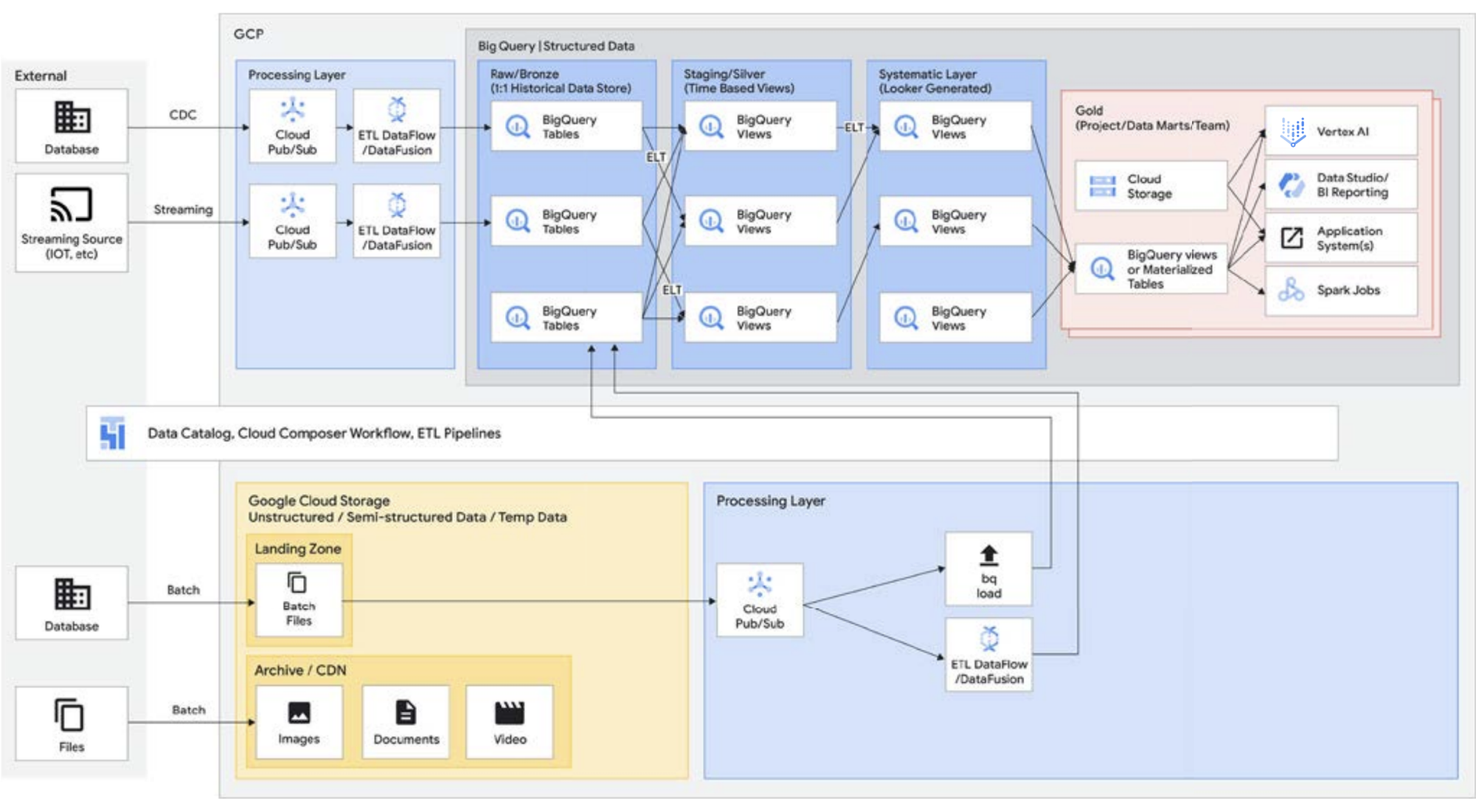
Durante l'esecuzione di operazioni ETL, le trasformazioni avvengono al di fuori di BigQuery, magari in uno strumento non altrettanto scalabile. È possibile che trasformi i dati riga per riga, anziché caricare in contemporanea le query. In alcuni casi i processi Spark o altri processi ETL potrebbero essere già codificati e potrebbe non avere senso modificarli per utilizzarli in nuove tecnologie. Tuttavia, se ci sono trasformazioni che possono essere scritte in SQL, è probabile che BigQuery sia un ottimo posto in cui eseguirle.
Inoltre, questa architettura è supportata da tutti i componenti Google Cloud come Managed Service for Apache Airflow, Data Catalog o Data Fusion. Fornisce uno strato end-to-end per diverse buyer persona. Un altro aspetto importante della riduzione dell'overhead operativo può essere realizzato sfruttando le capacità dell'infrastruttura sottostante. Prendi in considerazione Dataflow e BigQuery: vengono eseguiti su container e consentono di gestire l'uptime e i meccanismi dietro le quinte. Una volta estesa agli strumenti di terze parti e dei partner ,e quando si iniziano a esplorare funzionalità simili come Kubernetes, diventa molto più semplice da gestire e trasferire. Questo, a sua volta, riduce gli overhead operativi e di risorse. Inoltre, a questo può aggiungersi una migliore osservabilità sfruttando le dashboard di monitoraggio con Managed Service for Apache Airflow per garantire l'eccellenza operativa. Non solo è possibile creare un data lake riunendo i dati archiviati in Cloud Storage e BigQuery, senza doverli spostare o duplicare, ma mettiamo a disposizione anche ulteriori funzionalità amministrative per gestire le origini dati. Knowledge Catalog (in precedenza Dataplex) abilita una lakehouse offrendo un livello di gestione centralizzata per coordinare i dati in Cloud Storage e BigQuery. Questo consente di organizzare i dati in base alle esigenze aziendali, evitando le limitazioni riferite alle modalità o al luogo di archiviazione dei dati.
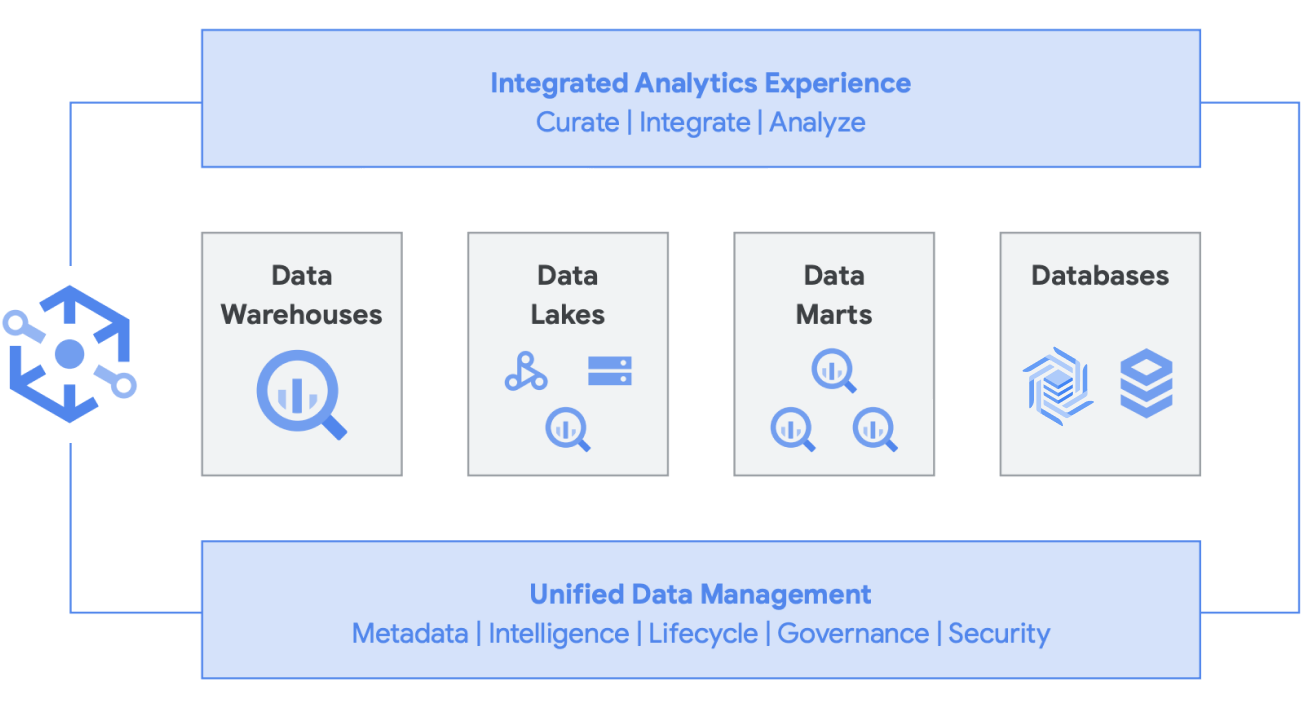
Knowledge Catalog è un data fabric intelligente che consente di mantenere distribuiti i dati con il giusto rapporto prezzo/prestazioni, rendendoli al contempo accessibili in modo sicuro a tutti gli strumenti di analisi. Offre una gestione dei dati basata sui metadati con qualità e governance integrate, che ti consente di dedicare meno tempo ai limiti e alle inefficienze dell'infrastruttura, di considerare affidabili i dati in tuo possesso e di dedicare più tempo a ricavare valore da questi dati. Inoltre, fornisce un'esperienza di analisi integrata, che riunisce il meglio di Google Cloud e dell'open source, per consentirti di organizzare, proteggere, integrare e analizzare rapidamente i dati su larga scala. Infine, puoi creare una strategia di analisi che potenzia l'architettura esistente e si allinea ai tuoi obiettivi di governance finanziaria.
Data mesh
Il data mesh si basa su una lunga storia di innovazione nell'ambito dei data warehouse e data lake, combinata con le straordinarie caratteristiche di scalabilità, prestazioni, modelli di pagamento, API, DevOps e stretta integrazione dei prodotti Google Cloud. Questo approccio consente di creare una soluzione dati on demand in modo efficace. Un data mesh decentralizza la proprietà dei dati tra i proprietari dei dati di dominio, ognuno dei quali è tenuto a fornire i propri dati come prodotto in modo standard. Un data mesh facilita inoltre la comunicazione tra diverse parti dell'organizzazione per distribuire i set di dati in diverse località. In un data mesh, la responsabilità delle generazione di valore dai dati è attribuita alle persone che li comprendono meglio; in altre parole, le persone che hanno creato i dati o li hanno introdotti nell'organizzazione devono essere responsabili della creazione di asset di dati fruibili come prodotti dai dati che creano. In molte organizzazioni è difficile stabilire una Single Source Of Truth o "origine dati autorevole" a causa delle ripetute estrazioni e trasformazioni dei dati in tutta l'organizzazione senza chiare responsabilità di proprietà sui dati di nuova creazione. Nel data mesh, l'origine dati autorevole è il prodotto dati pubblicato dal dominio di origine, con un proprietario e gestore dei dati chiaramente assegnato che ne è responsabile.
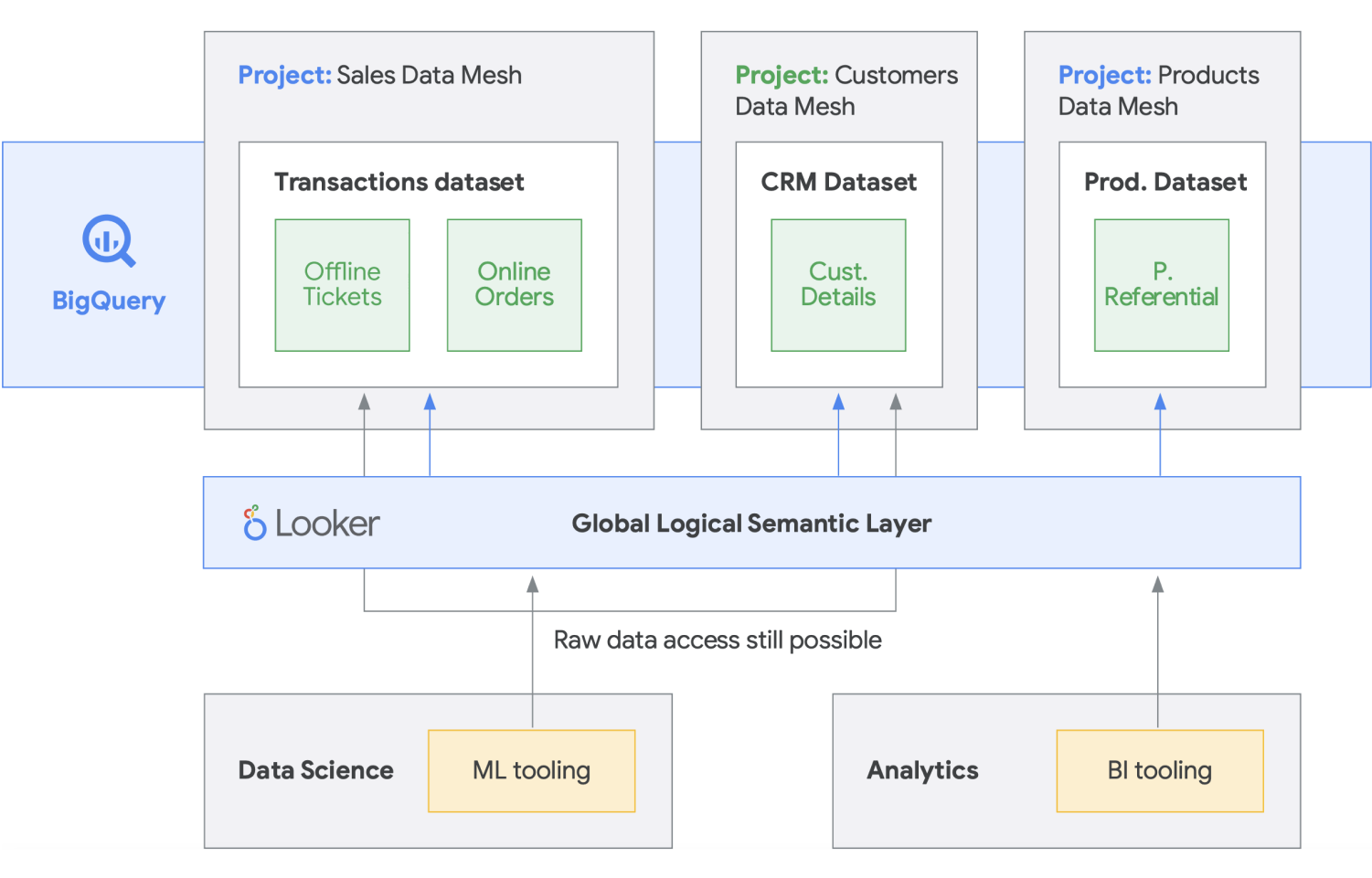
In sintesi, il data mesh promette proprietà e architettura dei dati decentralizzate e orientate al dominio. Ciò è possibile grazie ai livelli di calcolo federato e di accesso, proprio come li forniamo in Google Cloud. Inoltre, se la tua organizzazione sta cercando di ottenere più funzionalità, puoi utilizzare ad esempio Looker, che può fornire un livello unificato per modellare e accedere ai dati. La piattaforma Looker offre una UI a riquadro singolo per accedere alla versione più autentica e aggiornata dei dati della tua azienda e delle definizioni dell'attività. Con questa visione unificata dell'azienda, puoi scegliere o progettare esperienze di dati che garantiscano alle persone e ai sistemi i dati forniti nel modo più adatto alle loro esigenze. Funziona perfettamente in quanto consente a data scientist, analisti e persino utenti aziendali di accedere ai loro dati con un unico modello semantico. I data scientist continuano ad accedere ai dati non elaborati, ma senza lo spostamento e la duplicazione dei dati.
Stiamo sviluppando funzionalità aggiuntive oltre ai nostri prodotti fondamentali come BigQuery, per semplificare la creazione e la gestione dei set di dati. Analytics Hub consente di creare scambi di dati privati, in cui gli amministratori di una piattaforma di scambio (noti anche come curatori di dati) concedono le autorizzazioni per pubblicare e sottoscrivere i dati in cambio di specifici individui o gruppi sia all'interno dell'azienda che all'esterno di partner commerciali o acquirenti.
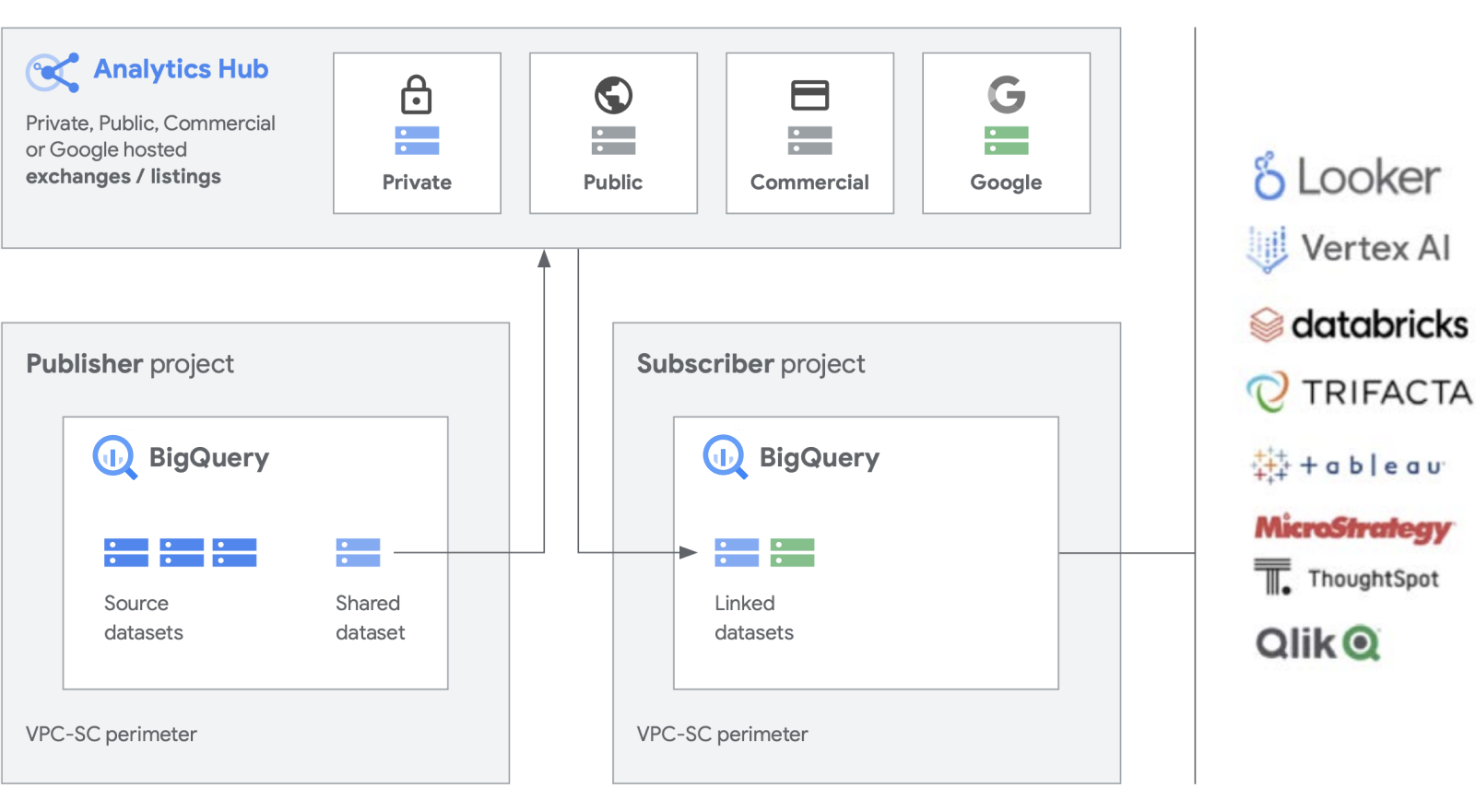
Pubblica, scopri e iscriviti ad asset condivisi, inclusi formati open source, basati sulla scalabilità di BigQuery. I publisher possono visualizzare metriche di utilizzo aggregate. I fornitori di dati possono raggiungere i clienti aziendali di BigQuery con dati, approfondimenti, modelli di ML o visualizzazioni e sfruttare Cloud Marketplace per monetizzare le proprie app, insight o modelli. Questo processo è simile anche al modo in cui i set di dati pubblici di BigQuery vengono gestiti tramite una piattaforma di scambio pubblicitario gestita da Google. Promuovi l'innovazione con l'accesso a set di dati unici di Google, a set di dati commerciali/industriali, a set di dati pubblici o a scambi di dati curati dalla tua organizzazione o dall'ecosistema di partner.
Come gestire i sistemi legacy
Anche se sembra fantastico creare una piattaforma di dati completamente nuova, siamo consapevoli che non tutte le aziende avranno modo di farlo. La maggior parte ha a che fare con sistemi legacy esistenti di cui deve eseguire la migrazione, la portabilità o l'applicazione di patch fino a quando non potranno essere sostituiti. Abbiamo lavorato con i clienti in ogni fase del percorso della loro piattaforma dati e siamo in grado di offrire soluzioni per ogni tua situazione.
Tra i clienti notiamo in genere tre categorie di migrazione: lift and replatforming, lift and rehome e modernizzazione completa. Alla maggior parte delle aziende consigliamo di iniziare con lift and replatforming, in quanto offre una migrazione ad alto impatto con il minor numero possibile di interruzioni e rischi. Questa strategia consente di eseguire la migrazione dei dati in BigQuery o Managed Service for Apache Spark dai data warehouse legacy e dai cluster Hadoop. Una volta spostati i dati, puoi ottimizzare le pipeline di dati e le query per migliorare le prestazioni. Con una strategia di migrazione lift and replatforming, puoi eseguire questa operazione per fasi, in base alla complessità dei tuoi carichi di lavoro. Consigliamo questo approccio alle grandi imprese con IT centralizzati e più unità aziendali, data la loro complessità.
La seconda strategia di migrazione che osserviamo più spesso è una modernizzazione completa come primo passo. In questo modo si dà un taglio netto con il passato, perché si adotta un approccio cloud-native. È costruita in modo nativo su Google Cloud, ma poiché si cambia tutto in un'unica soluzione, la migrazione può essere più lenta se si dispone di più ambienti legacy di grandi dimensioni.

Un'interruzione netta dei sistemi legacy richiede la riscrittura dei job e la modifica di diverse applicazioni. Tuttavia, garantisce anche maggiore velocità e agilità e il costo totale di proprietà più basso sul lungo periodo rispetto agli altri approcci. Questo è dovuto a due motivi principali: le applicazioni sono già ottimizzate e non devono essere riadattate e, una volta eseguita la migrazione delle origini dati, non devi gestire due ambienti contemporaneamente. Questo approccio è più adatto per nativi digitali o organizzazioni guidate da ingegneri con pochi ambienti legacy.
Infine, l'approccio più conservativo è il "lift and rehome", che consigliamo come soluzione tattica a breve termine per spostare la tua infrastruttura dati nel cloud. Puoi eseguire il "lift and rehome" delle piattaforme esistenti e continuare a utilizzarle come prima, ma nell'ambiente Google Cloud. Questo principio è applicabile ad ambienti come Teradata e Databricks, ad esempio, per ridurre il rischio iniziale e consentire l'esecuzione delle applicazioni. Tuttavia, in questo modo l'ambiente isolato esistente viene portato nel cloud anziché trasformarlo, per cui non trarrai vantaggio dalle prestazioni di una piattaforma creata in modo nativo su Google Cloud. In ogni caso, possiamo aiutarti con una migrazione completa ai prodotti nativi di Google Cloud, in modo da poter sfruttare l'interoperabilità e creare una piattaforma di dati di analisi completamente moderna su Google Cloud.
Tattica o strategia?
Riteniamo che i principali elementi di differenziazione di una piattaforma di dati analitici costruita su Google Cloud siano l'apertura, l'intelligenza, la flessibilità e la perfetta integrazione. Esistono molte soluzioni sul mercato che offrono soluzioni tattiche che possono sembrare convenienti e familiari. Tuttavia, forniscono generalmente una soluzione a breve termine e agiscono semplicemente sui problemi di organizzazione e tecnici nel corso del tempo.
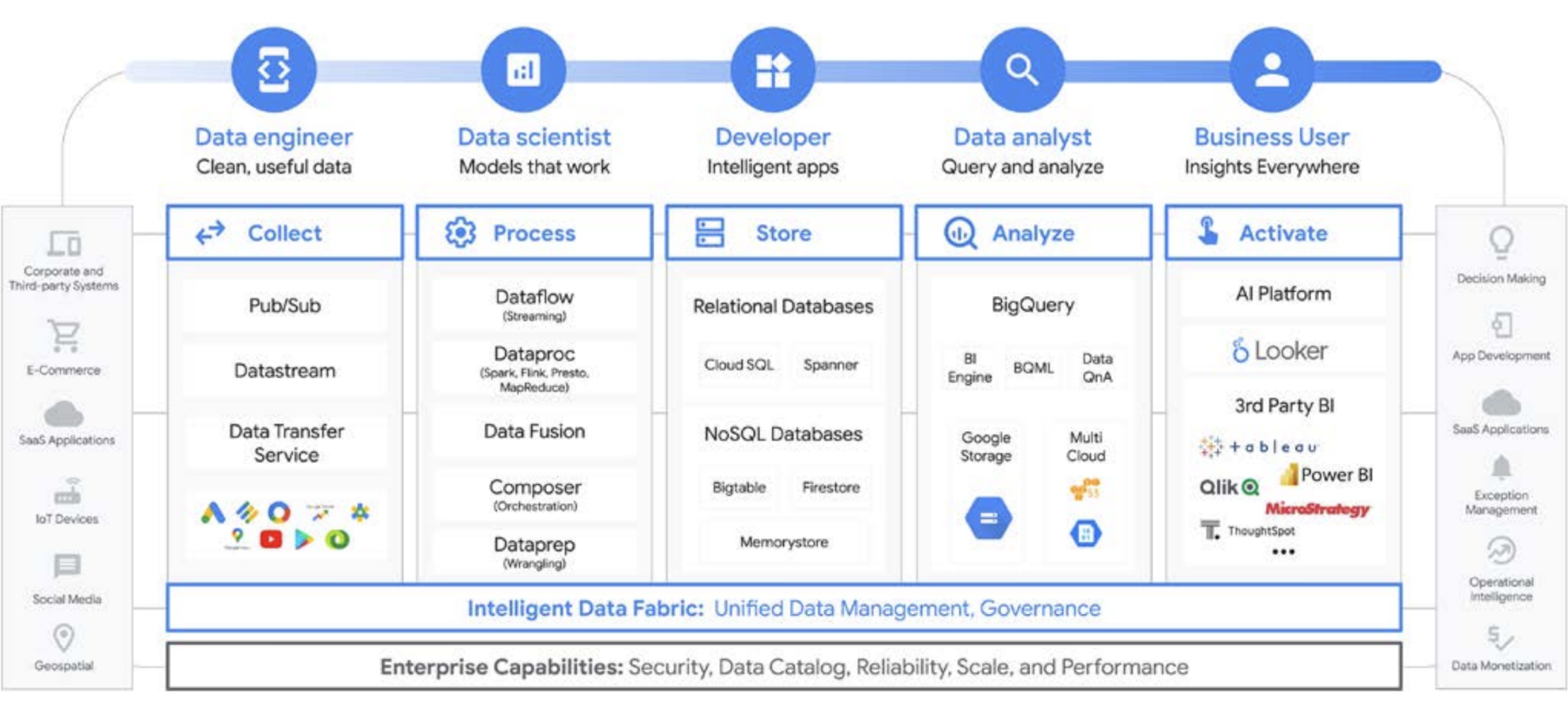
Google Cloud semplifica notevolmente l'analisi dei dati. Puoi sbloccare il potenziale nascosto nei dati con un approccio serverless e cloud-native che disaccoppia lo spazio di archiviazione dal calcolo e ti consente di analizzare da gigabyte a petabyte di dati in pochi minuti. Ciò consente di eliminare i tradizionali vincoli in termini di scalabilità, prestazioni e costo per porre qualsiasi domanda sui dati e risolvere i problemi aziendali. Di conseguenza, diventa più facile rendere operativi gli insight in tutta l'azienda con un unico data fabric affidabile.
Quali sono i vantaggi?
- Ti consente di concentrarti esclusivamente sull'analisi anziché sull'infrastruttura
- Risolve ogni fase del ciclo di vita dell'analisi dei dati, dall'importazione alla trasformazione e all'analisi, fino alla business intelligence e altro ancora.
- Crea una solida base di dati su cui operativizzare il machine learning
- Consente di sfruttare le migliori tecnologie open source per la tua organizzazione
- Scala per soddisfare le esigenze dell'azienda, in particolare con l'aumento dell'utilizzo dei dati per la gestione del business e la trasformazione digitale
Una piattaforma di dati di analisi unificata e moderna basata su Google Cloud offre le migliori funzionalità di un data lake e di un data warehouse, ma con una maggiore integrazione in AI Platform. Puoi elaborare automaticamente dati in tempo reale da miliardi di eventi in streaming, fornire insight in pochi millisecondi e rispondere al mutare delle esigenze dei clienti. I nostri servizi AI leader del settore possono ottimizzare il processo decisionale dell'organizzazione e la customer experience, aiutandoti a colmare il divario tra analisi descrittiva e prescrittiva senza dover assumere un nuovo team. Puoi potenziare le competenze esistenti per scalare l'impatto dell'AI con un'intelligence automatizzata e integrata.
Fai un passo avanti
Ti interessa scoprire di più su come la piattaforma di dati di Google può trasformare il modo in cui la tua azienda gestisce i dati? Contattaci per iniziare.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti


















