设置 Cloud SQL for MySQL 实例的最佳实践
虽然您可以在自己的物理机甚至虚拟机上手动部署 MySQL 并选择自行管理,但越来越流行的选择是使用云服务提供商提供的托管式产品,用于负责管理 MySQL 的许多运营方面。
最佳实践
Cloud SQL for MySQL 是一项全托管式数据库服务,可帮助您在 Google Cloud 上设置、维护、管理和控制 MySQL 关系型数据库。当您准备好创建 Cloud SQL for MySQL 实例时,有几个选项可供选择,包括界面控制台、gcloud CLI、Terraform 和 REST API。您可以参阅我们的文档,详细了解各个路径;但在本文中,我们将通过界面进行举例说明,介绍设置实例的各种最佳实践。
实例信息
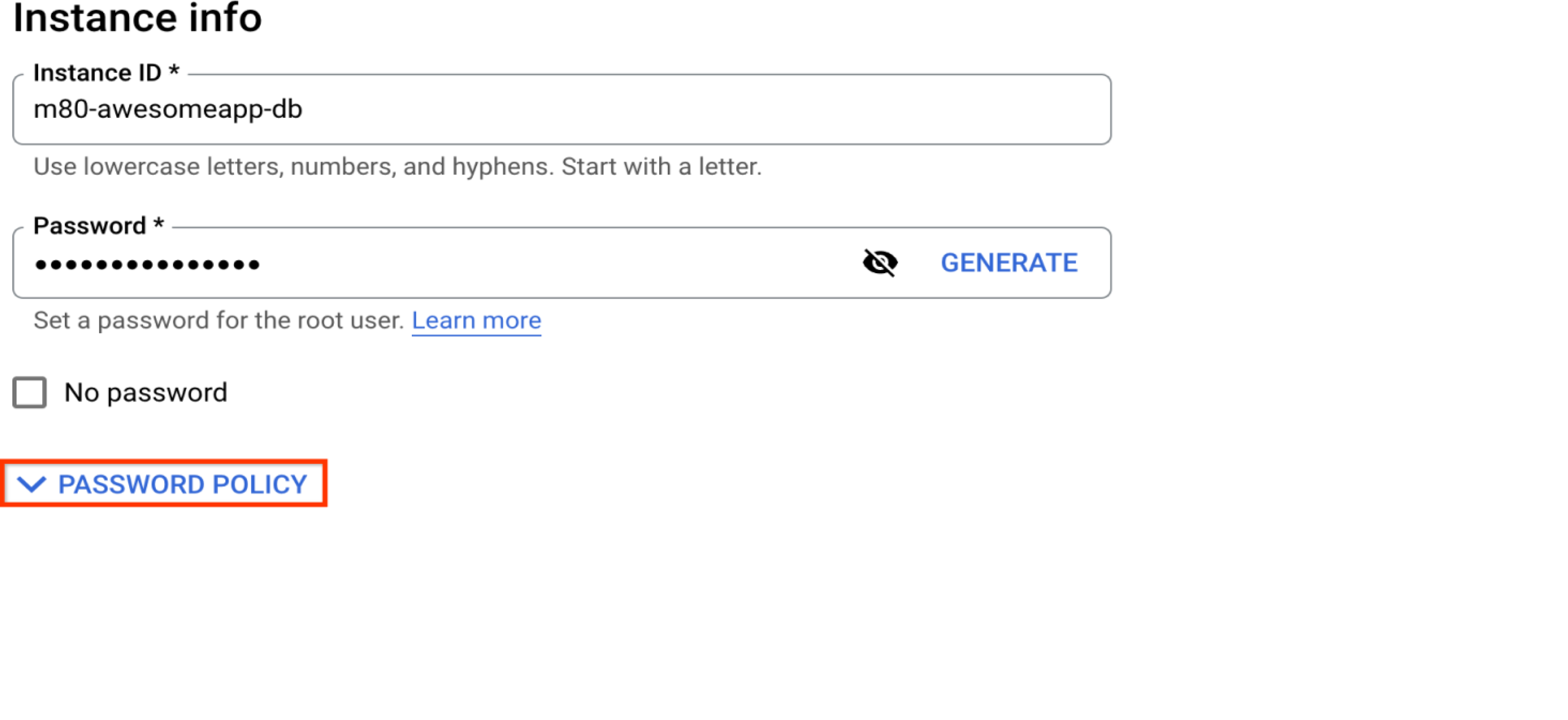
选择安全系数高的密码
这是将随实例创建的默认“root”@”%”数据库用户的密码。如果您打算让根用户继续担任管理员用户,请务必在此处选择一个安全系数高的密码。出于安全考虑,建议使用不常见的管理员用户,而不是“根用户”。请参阅“管理数据库用户”部分。
创建实例级密码政策
密码政策功能可增强数据库安全性。它可让您配置有关密码长度、复杂性、失效日期和限制重复使用的政策。如需了解详情,请参阅加固 MySQL 实例安全。
数据库版本
考虑使用 8.0 版本以获得更好的性能
Cloud SQL MySQL 支持多个 8.0 次要版本,其中 v8.0.26 是当前默认版本。一系列机器类型的基准测试显示 8.0 默认版本比 5.7 和 5.6 版本有更好的查询吞吐量。
请勿将生产实例置于最新的正式版
尽管 Oracle 和 Cloud SQL 做了所有测试,但 MySQL 的更新版本并未通过复杂的实际场景的全面审核。因此,我们建议您将生产实例保持为稳定版,并使用开发和预演实例在 Cloud SQL for MySQL 中测试最新的次要版本升级。
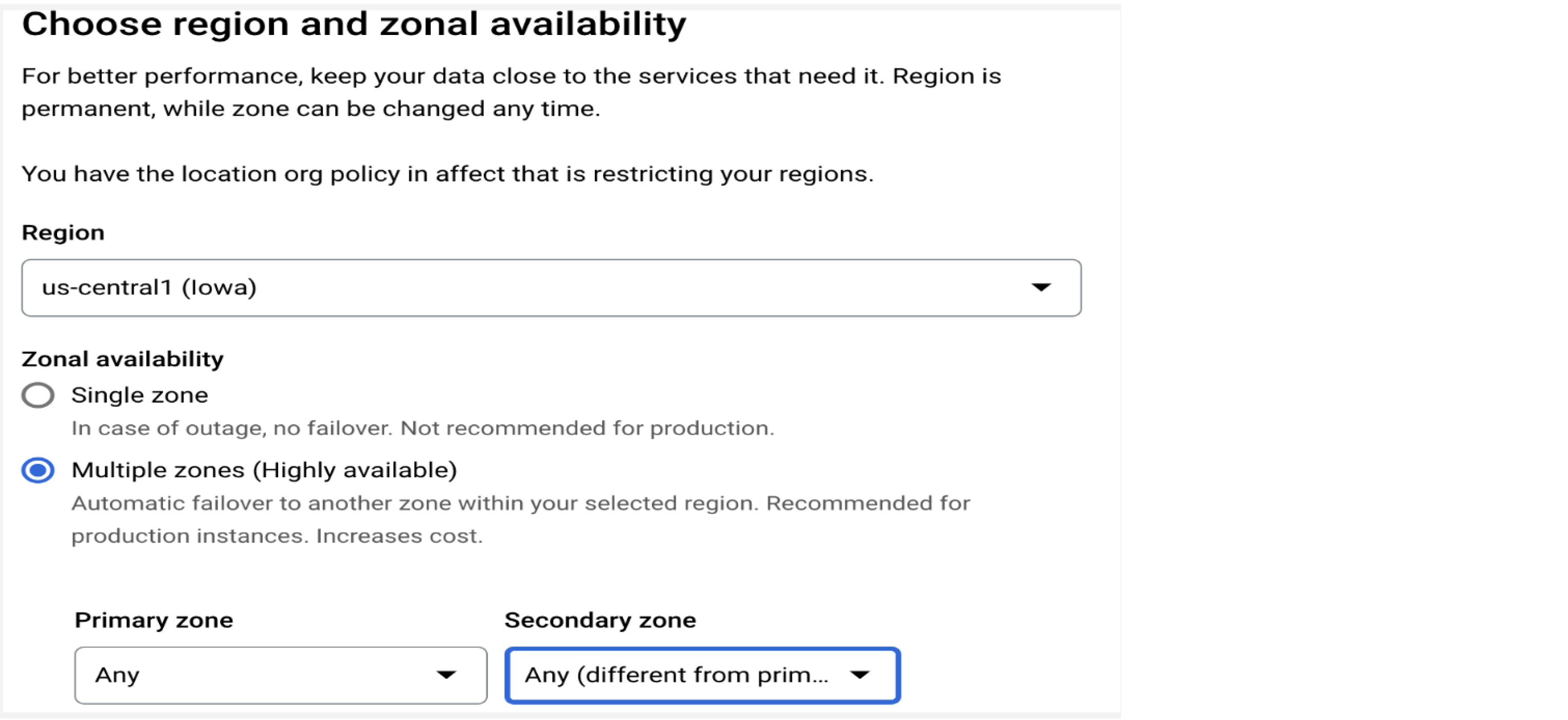
高可用性
为生产实例配置多个可用区
Cloud SQL for MySQL 作为高可用性解决方案,通过自动故障切换到第二个可用区,从而实现区域可用性。为了获得最佳可用性,请为生产实例配置多个可用区选项,以便自动进行每日备份和时间点恢复(如需了解详情,请参阅“备份时间表”部分)。
机器类型
评估当前的 CPU/内存用量,以做出明智的迁移决策
将现有实例迁移到 Cloud SQL 时,当前工作负载可帮助您选择合适的虚拟机大小。
- CPU:在正常工作负载条件下,您的 CPU 使用率是多少?峰值工作负载会怎样?实例受 CPU 限制还是受 I/O 限制?如果用户和/或系统的 CPU 百分比相对较高,则表示工作负载受 CPU 限制。如果 I/O 的百分比相对较高,则表示工作负载受 I/O 限制。
- 内存:同理,实例的正常内存用量是多少?峰值用量是多少?
作为参考,Cloud SQL for MySQL 中的 1 个 vCPU 最多可支持 6.5GB 的内存。
规划 20%-50% 的额外 CPU 和内存空间
即使在通常稳定的实例中,也应规划至少 20% 的额外 CPU 和内存空间来吸收计划外高峰。这对于成长型企业而言更为重要,请考虑额外增加 50%。
Cloud SQL 可让您轻松升级机器类型。请注意,升级会导致停机。
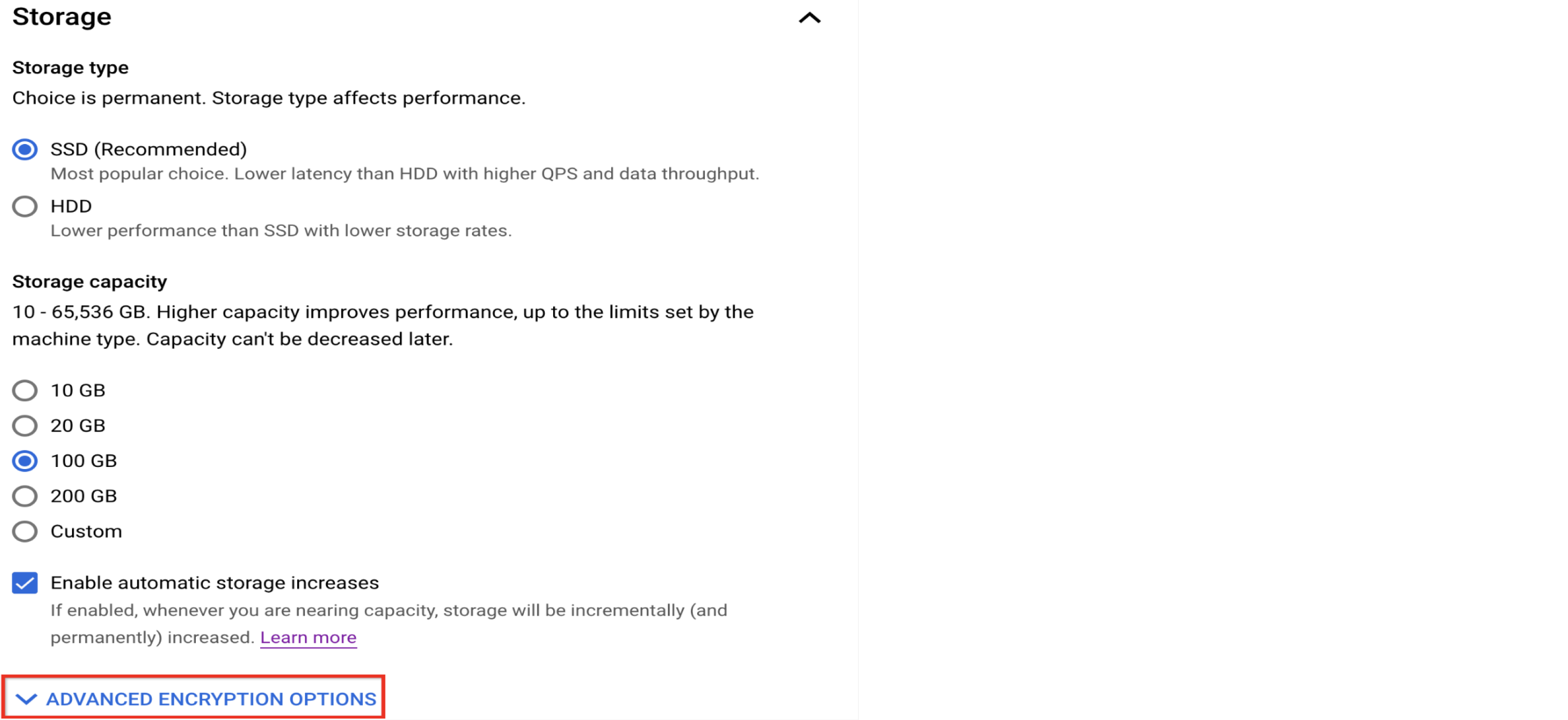
自定义存储空间
使用 SSD 以提高数据库性能
Cloud SQL for MySQL 提供 HDD 作为经济实惠的存储选项,但如果您知道自己需要高性能数据库,请选择 SSD 选项。以下是 I/O 性能的比较。
计划在存储容量方面均衡性能与成本
磁盘 IOPS 和吞吐量与永久性磁盘大小相关。较大的容量可在实例限制范围内提供较高的 IOPS 和吞吐量。
对于 SSD,可用区级和区域级配置会影响性能。如需了解详情,请参阅可用区级与区域级 SSD 性能数据。如果您选择了多个可用区可用性,请参阅区域级 SSD 性能数据。简而言之,读写 IOPS 均为每 GB 30,吞吐量为每 GB 0.48MB。使用区域级 SSD 时,性能数据类似,但每个实例的写入 IOPS 和写入吞吐量较低。
请注意,Cloud SQL 实例支持的存储空间大小上限为 64TB。
启用存储空间自动扩容功能并监控磁盘容量增长
Cloud SQL 具有存储空间自动扩容功能,可防止实例耗尽磁盘可用空间 (OOD)。启用此功能后,系统会每 30 秒检查一次存储空间,并在需要时增加存储空间容量。
虽然此功能可防止 OOD,但增加的容量是永久性的,您以后将无法缩减实例的大小。首先设置磁盘大小提醒,以便管理和规划存储容量。
熟悉加密选项
Cloud SQL 默认加密静态数据。不过,您可以选择使用客户管理的加密密钥 (CMEK),而不是默认的 Google 拥有和 Google 管理的密钥(如果 CMEK 更符合您的需求)。
配置连接
评估专用 IP 地址和公共 IP 地址之间的权衡
专用 IP 地址和公共 IP 地址是指网络中设备使用的地址类型。与公共 IP 地址相比,专用 IP 地址可提高网络安全性并缩短网络延迟时间。 但是,专用 IP 地址需要额外的 API 和 IAM 配置来设置,有时还需要公共 IP 地址。如果您知道需要使用公共 IP 地址但想要提高安全性,则可以选择要求设置已获授权的网络或使用 Cloud SQL Auth 代理。
考虑使用 Cloud SQL Auth 代理实现安全连接
Cloud SQL Auth 代理可提供对 Cloud SQL 实例的安全访问,而无需配置 SSL 或已获授权的网络。该应用会与在本地环境中运行的 Auth 代理客户端进行通信,并使用安全隧道与 Cloud SQL 实例上的代理服务器进行通信。
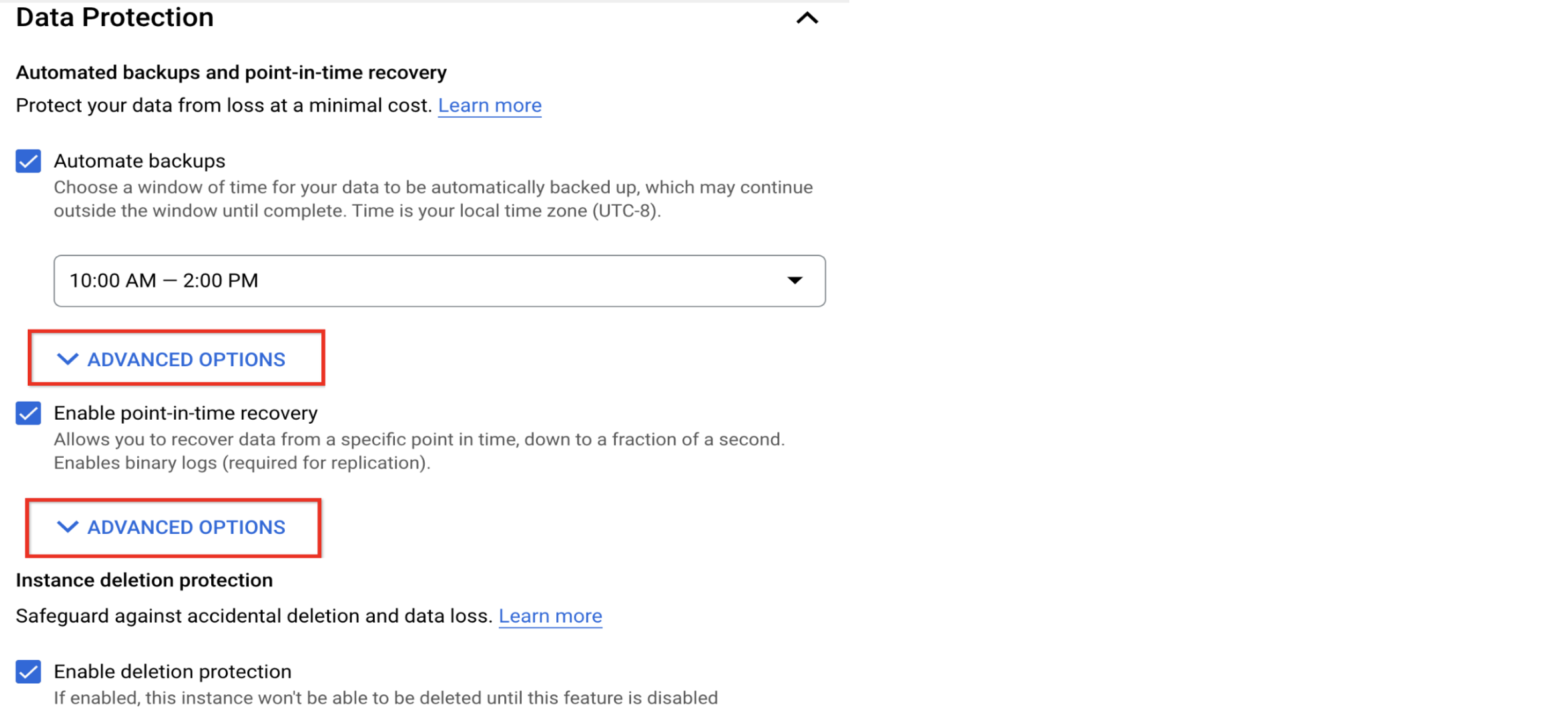
设置备份时间表和保留
启用备份和时间点恢复并查看保留政策
定期数据备份和可验证的数据恢复对于健康的数据库管理至关重要。在数据损坏或意外数据操作等情况下,这些做法非常有用,但这两种情况都无法通过高可用性来缓解。
Cloud SQL 提供自动备份、备份验证和时间点恢复 (PITR) 功能。这些功能默认处于启用状态,对于具有多个可用区的实例是必需的。系统每天执行一次自动备份,默认保留政策为 7 个备份副本和 7 天的二进制日志(PITR 需要)。您可以在“高级选项”部分调整保留政策。
配置数据库标志
数据库标志是指向 my.cnf 文件的服务器配置。有一系列 db 标志是可配置的,某些托管式标志是不可配置的。建议在创建实例时查看数据库标志并将其配置为正确的值。因为某些数据库标志不是动态的,这意味着更改这些标志会触发实例重启。
查看 character_set_server
在 Cloud SQL for MySQL 实例上,character_set_server 在 v5.6 和 v5.7 中默认为 utf8,在 v8.0 中默认为 utf8mb4。character_set_server 将 character_set_client、character_set_connection、character_set_database、character_set_results 设置为相同的值。对于 character_set_system,在 v8.0 中默认为 utf8mb3。
如果您要迁移实例,并且当前配置使用不同的字符集(例如,latin1),请务必在新实例上明确设置 character_set_server。
查看 time_zone
时区默认为 system_time_zone,即世界协调时间 (UTC)。如果您想使用其他 time_zone,请通过 default_time_zone 进行设置。此标志采用两种格式:时区偏移量(例如 +08:00)和时区名称(例如 America/Los_Angeles)。如果时区由时区名称定义,则系统会自动将其调整为夏令时(如果相关)。default_time_zone 标志不是动态的,需要重启数据库实例才能进行更改。
启用慢查询日志
默认情况下,slow_query_log 设置为 OFF。我们强烈建议启用慢查询日志,并将 long_query_time 设置为适合应用的阈值。慢查询日志有助于捕获长时间运行的查询以进行分析和优化。此信息不仅有助于处理各个查询,还有助于了解总体服务器吞吐量和对意外工作负载的回顾性分析。
此标志是提高 InnoDB 性能的最有效配置。内存中可缓冲的数据越多,服务器性能就会越好。同时,还需要为全局缓冲区和各线程的动态缓冲区预留足够的内存。
在 Cloud SQL 中,innodb_buffer_pool_size 标志的默认值、最小允许值和最大允许值取决于实例的内存,如文档中所述。
合适的 innodb_buffer_pool_size 不必包含所有数据,只需包含经常访问的数据。反映缓冲区池效率的状态变量为 Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests。Innodb_buffer_pool_read_requests 是逻辑读取请求的数量,Innodb_buffer_pool_reads 是从缓冲区池中未满足而必须从磁盘读取的逻辑读取的数量。在数据完全位于缓冲区池的理想情况下,Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests 的比率将接近零。监控这些变量可让您大致了解 InnoDB 缓冲区池的效率。如果 innodb_buffer_pool_size 已达到允许的最大值,但缓冲区池效率不理想,且应用出现查询性能问题,请考虑升级实例以增加内存。
此变量在 MySQL v5.7 和 v8.0 中会变为动态变量,而在 v5.6 中,更改此变量需要重启实例。
在 8.0.30 之前,innodb_log_file_size 和 innodb_log_file_size 不是动态的,并且更改 innodb_log_file_size 需要彻底关停。8.0.30 中引入了 innodb_redo_log_capacity,以取代 innodb_log_file_size 和 innodb_log_files_in_group。
Cloud SQL for MySQL 实例的配置为 innodb_log_file_size=512MB、innodb_log_file_size=2(或 innodb_log_file_size=1GB)。这让 InnoDB 可在缓冲区池中保存更多更改,而无需同步到磁盘,从而提高服务器性能。大型重做日志文件的缺点是崩溃恢复时间增加。根据实例的高可用性要求和设置,此决策需要在性能和可用性之间取得平衡。
通常,我们建议让重做日志文件具有足够大小,以容纳一小时写入活动的数据量。衡量方式的一种方法是,全天观察 Innodb_os_log_written,然后确保 Innodb_os_log_written * Innodb_os_log_written 足够大,足以应对观察到的高峰时段。
在 MySQL v5.6 和 v5.7 中,innodb_log_buffer_size 不是动态的,进行更改需要重启实例。因此,最好在初始化时进行设置。
如果 innodb_log_buffer_size 足够大,可以容纳整个事务,则事务执行期间不会再刷新磁盘。默认情况下,innodb_log_buffer_size 设置为 16MB,这一般已经足够。但是,如需了解大型事务是否需要更大的缓冲区,请在发出大型事务时监控 Innodb_log_waits 状态变量。如果 innodb_log_buffer_size 过小且需要等待刷新,则 innodb_log_buffer_size 将增加 1。
随时调整动态变量
某些与性能相关的数据库标志是动态的,例如 table_open_cache、thread_cache_size。开始时先使用正确的大小,但建议您建立测量结果并根据需要进行调整。
table_open_cache 用于保存打开的表数量。有足够的缓存有助于缩短表打开时间,从而提升查询性能。Opened_tables 状态变量会显示已打开的表的数量。如果 Opened_tables 持续增长,请考虑增加 table_open_cache。
thread_cache_size 用于缓存线程,以便在客户端断开连接后重复使用。如果实例预计会同时获得大量新连接,请设置较大的大小。状态变量 Threads_created 和 Connections 的比率显示了线程缓存的效率。比率越低越好。
谨慎对待各线程的内存标志
有些线程内存缓冲区会影响查询性能,例如 tmp_table_size、max_heap_table_size、join_buffer_size、sort_buffer_size,等等。这些变量同时具有全局范围和会话范围。全局范围为所有新连接设置各线程的值,而会话范围对当前会话中的后续查询有效。对于此类设置,使用更大的内存可以提高查询性能。但是,由于它们是动态的,并且会为每个线程分配一个或多个,因此可能会导致内存不足 (OOM)。
最好为全局值使用适中的数字,而为特定会话预留较大的数字,从而以可控的方式实现更好的性能。
考虑 performance_schema
在 MySQL v8.0.26 之前,performance_schema 默认为 OFF,并且需要重启才能将其开启。performance_schema 支持各种插桩,并提供丰富的数据用于分析服务器操作,但性能会受到影响,内存消耗量也会增加。默认插桩会导致性能下降约 5%,并且随着更多插桩的添加,下降幅度还会更大。使用工作负载对插桩进行基准测试,因为内存消耗量可能会增至 1GB 或更多。您可以在 memory_summary_global_by_event_name 表中观察此内存消耗量。
管理数据库用户
创建 Cloud SQL 实例后,有一个数据库用户可用,即“root”@”%”。您可能需要创建其他数据库用户。
限制用户只能执行所需操作
请始终限制用户只能执行所需的最低操作。
通过 MySQL CLI 创建用户时,您需要明确授予权限。
通过 Cloud 控制台创建用户时,该用户将拥有与“root”@”%”用户相同的权限。在 MySQL v5.6 和 v5.7 中,默认权限包括所有具有授予选项的权限(SUPER 和 FILE 权限除外)。在 v8.0 中,用户拥有动态权限,虽然 SUPER 和 FILE 权限仍然受限,但是用户可以拥有更多管理员角色(例如,APPLICATION_PASSWORD_ADMIN、APPLICATION_PASSWORD_ADMIN、APPLICATION_PASSWORD_ADMIN、APPLICATION_PASSWORD_ADMIN 和 APPLICATION_PASSWORD_ADMIN)。您需要通过 MySQL CLI 撤消任何不必要的权限。在 v8.0 实例上,partial_revokes 变量处于启用状态。
考虑将“root”@”%”替换为特定管理员用户
“root”@”%”是默认且最常用的超级用户,因此经常成为黑客的攻击目标。我们建议您创建自己的管理员用户,并为其授予与“root”@”%”用户相同的权限集,然后将其替换,以提升安全性。
设置监控
监控和跟踪数据库操作和系统资源的各个方面非常重要。通过它,您可以查看和分析实例随时间的运行状况,这也有助于进行资源规划。
- Cloud 控制台概览页面包含一系列核心指标。
- Cloud Monitoring 提供了其他指标。您可以创建一个信息中心,其中包含为数据库实例选择的指标。在 Cloud 控制台左上角的导航菜单中,选择“操作”-->“Monitoring”来访问 Cloud Monitoring。
- 使用 Cloud SQL 中的 Query Insights 进行查询性能分析。其概览部分显示按数据库、用户或客户端地址划分的 CPU 负载。CPU 使用率也细分为显示 I/O 等待和锁定等待。它还会按查询摘要列出热门查询。对于每个查询摘要,您可以查看平均执行时间、查询数以及扫描和返回的平均行数。这些指标对于确定要优化的热点和查询非常有用。
- 您还可以使用自有的监控工具和/或第三方工具对上述内容进行补充。主要目标是了解可能影响服务器和查询优化及问题排查的数据库操作。
设置提醒
适当的提醒对于服务器健康状况至关重要。它们有助于防止服务中断,例如因内存不足 (OOM) 或系统因 CPU 饱和问题而停止。
如果您使用 Cloud Monitoring,则可以创建基于指标的提醒。如需了解详情,请参阅相关文档。
如果您使用其他监控工具,请务必配置提醒。
配置副本
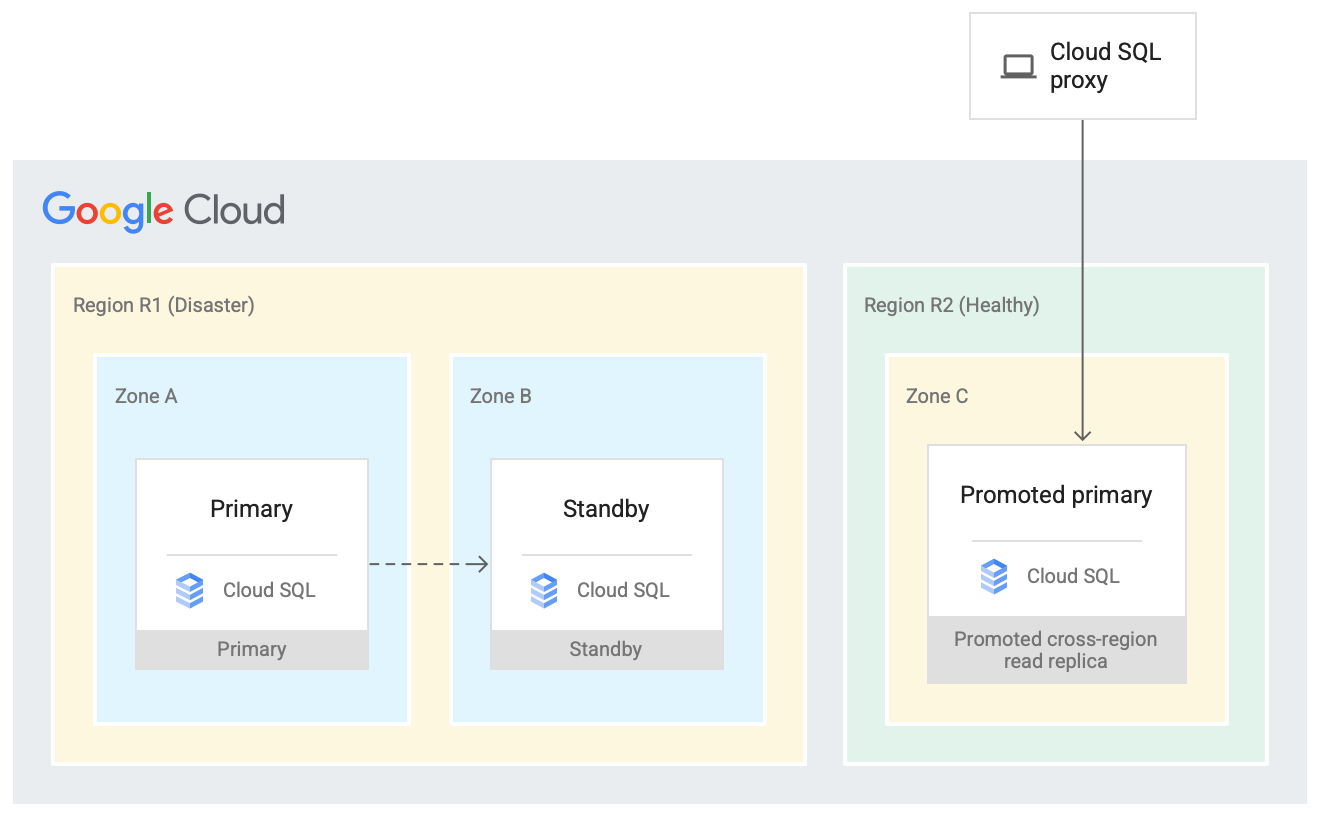
规划灾难恢复
高可用性解决方案在同一区域内的次要可用区提供数据冗余。在灾难中,一个区域可能会变得不可用。跨区域读取副本是灾难恢复方案中的强大资源,可以在需要时提升为主实例。如需了解详情,请参阅文档。
相关产品和服务
Google Cloud 提供旨在满足您业务需求的托管式 MySQL 数据库,可以完成包括弃用本地数据中心、运行 SaaS 应用和迁移核心业务系统在内的各种任务。











