Bonnes pratiques en matière de configuration d'une instance Cloud SQL pour MySQL
Bien que vous puissiez déployer MySQL manuellement sur votre propre machine physique ou même sur une machine virtuelle, et choisir de le gérer vous-même, une option de plus en plus populaire consiste à utiliser une offre gérée issue d'un fournisseur de services cloud, qui prend en charge les nombreux aspects opérationnels de la gestion de MySQL.
Articles associés
Bonnes pratiques
Cloud SQL pour MySQL est un service de base de données entièrement géré qui vous aide à configurer, entretenir, gérer et administrer vos bases de données relationnelles MySQL sur Google Cloud. Lorsque vous êtes prêt à créer une instance Cloud SQL pour MySQL, vous disposez de plusieurs options, y compris la console d'interface utilisateur, la CLI gcloud, Terraform et une API REST. Vous pouvez consulter notre documentation pour en savoir plus sur chacune de ces solutions. Toutefois, pour les besoins de cet article, nous utiliserons l'interface utilisateur à des fins de démonstration tandis que nous aborderons diverses bonnes pratiques de configuration d'instance.
Informations sur l'instance
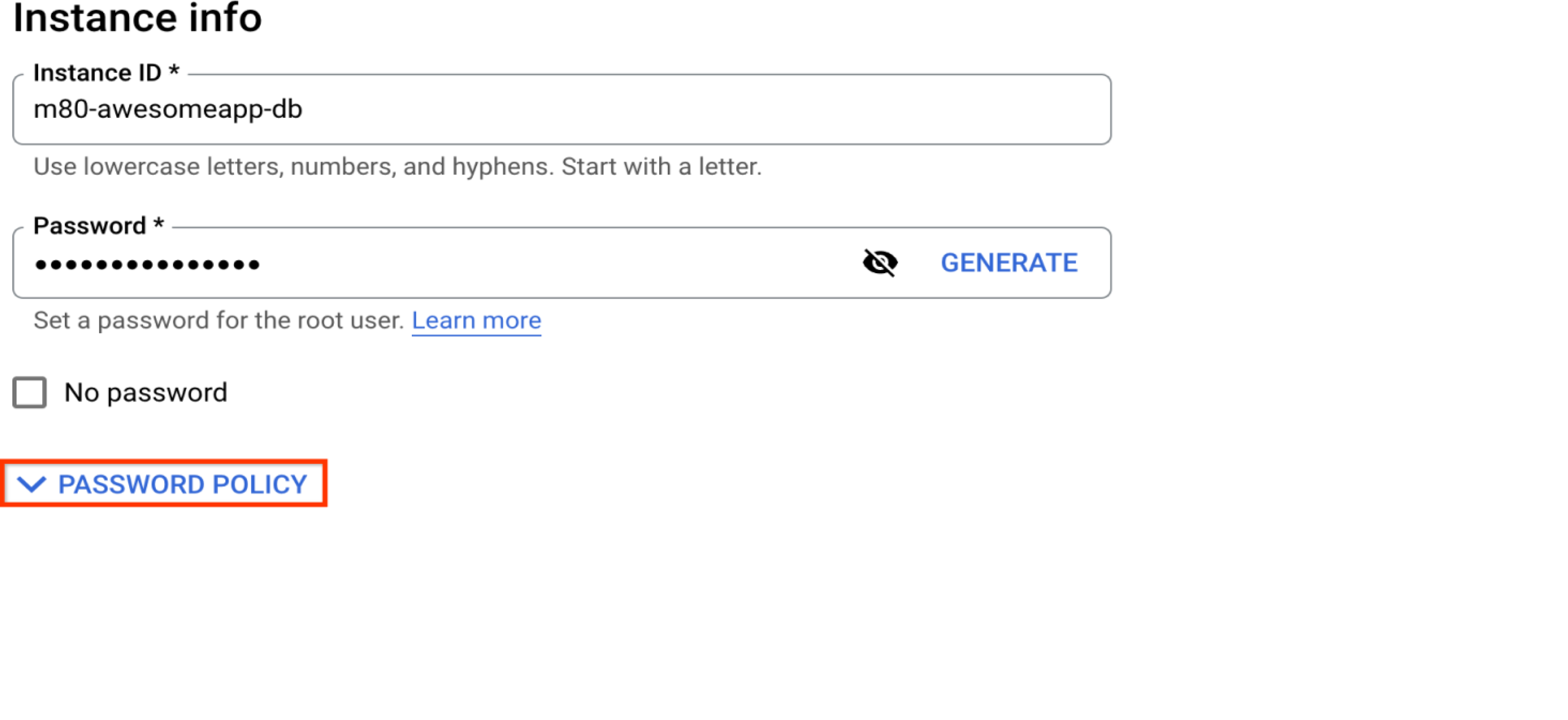
Choisir un mot de passe suffisamment sécurisé
Il s'agit du mot de passe de l'utilisateur de base de données "root"@"%" par défaut qui sera créé avec l'instance. Si vous avez l'intention de conserver l'utilisateur "root" en tant qu'administrateur, veillez à choisir ici un mot de passe sécurisé. Pour des questions de sécurité, il est conseillé d'utiliser un administrateur moins courant plutôt que "root". Veuillez vous reporter à la section "Gérer les utilisateurs de bases de données".
Créer une règle de mot de passe au niveau de l'instance
La fonctionnalité de règles relatives aux mots de passe permet de renforcer la sécurité de la base de données. Elle vous permet de configurer des règles sur la longueur, la complexité, l'expiration et la réutilisation limitée des mots de passe. Pour en savoir plus, consultez la section Renforcer une instance MySQL.
Version de la base de données
Envisager la version 8.0 pour améliorer vos performances
Cloud SQL MySQL est compatible avec plusieurs versions mineures 8.0, 8.0.26 étant la version par défaut actuelle. Les tests d'analyse comparative de plusieurs types de machines montrent un meilleur débit de requête avec la version 8.0 par défaut par rapport aux versions 5.7 et 5.6.
Ne pas utiliser la version DG la plus récente pour votre instance de production
Malgré tous les tests réalisés par Oracle et Cloud SQL, les versions actualisées de MySQL ne sont pas entièrement approuvées dans des scénarios réels complexes. Nous vous recommandons donc de garder vos instances de production sur une version stable, et d'utiliser vos instances de développement et de préproduction pour tester les dernières mises à niveau de versions mineures dans Cloud SQL pour MySQL.
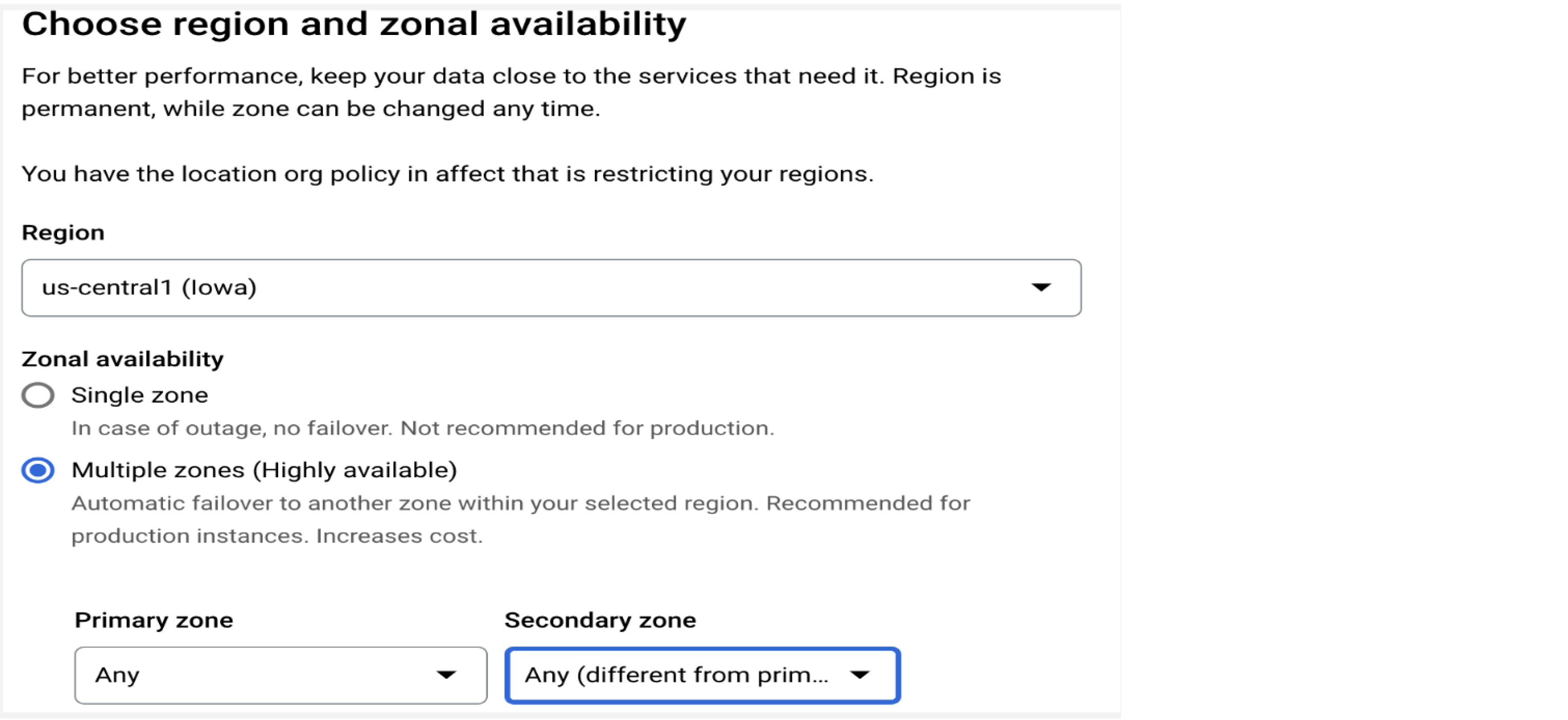
Haute disponibilité
Configurer plusieurs zones pour votre instance de production
Cloud SQL pour MySQL offre une disponibilité régionale par basculement automatique vers une deuxième zone en tant que solution haute disponibilité. Pour une disponibilité optimale, configurez l'option "Plusieurs zones" pour les instances de production afin de disposer automatiquement de sauvegardes quotidiennes et d'une récupération à un moment précis (voir la section "Planning des sauvegardes" pour plus d'informations).
Type de machine
Évaluer votre utilisation actuelle du processeur et de la mémoire pour prendre des décisions éclairées concernant la migration
Lors de la migration d'une instance existante vers Cloud SQL, votre charge de travail actuelle peut vous aider à choisir la taille de VM appropriée.
- Processeur : quelle est votre utilisation du processeur dans des conditions de charge de travail normales ? Qu'en est-il de votre charge de travail maximale ? L'instance est-elle liée au processeur ou aux E/S ? Si le pourcentage d'utilisation du processeur de l'utilisateur et/ou du système est relativement élevé, cela indique une charge de travail liée au processeur. Si le pourcentage d'E/S est relativement élevé, cela indique une charge de travail liée aux E/S.
- Mémoire : de même, quelle est l'utilisation normale de la mémoire de l'instance, et l'utilisation maximale ?
À titre de référence, 1 processeur virtuel dans Cloud SQL pour MySQL peut gérer jusqu'à 6,5 Go de mémoire.
Prévoir 20 à 50 % d'espace supplémentaire pour le processeur et la mémoire
Même dans une instance généralement stable, prévoyez au moins 20 % d'espace supplémentaire pour que le processeur et la mémoire puissent absorber les pics non planifiés. C'est d'autant plus important pour une entreprise en pleine croissance ; prévoyez dans ce cas une augmentation de 50 %.
Cloud SQL facilite la mise à niveau de votre type de machine. Notez simplement qu'une mise à niveau requiert un temps d'arrêt.
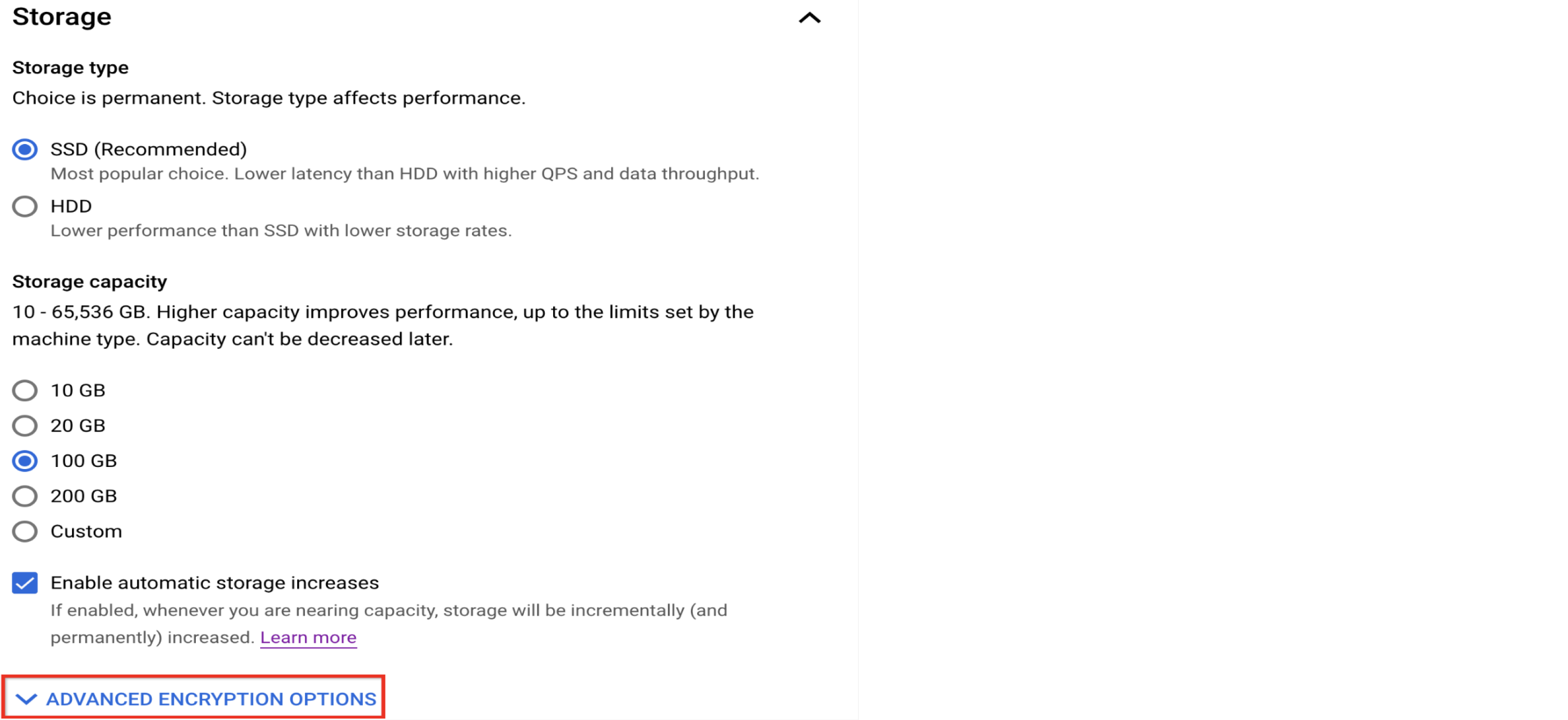
Personnaliser l'espace de stockage
Utiliser le stockage SSD pour améliorer les performances des bases de données
Cloud SQL pour MySQL propose l'option de stockage économique HDD, mais si vous savez que vous avez besoin d'une base de données hautes performances, optez pour l'option SSD. Voici un comparatif des performances d'E/S.
Prévoir d'équilibrer les performances et les coûts en termes de capacité de stockage
Les IOPS et le débit du disque sont corrélés à la taille du disque persistant. Une capacité plus élevée permet d'obtenir plus d'IOPS et de débit dans les limites de l'instance.
Pour le stockage SSD, les configurations zonales et régionales auront une incidence sur les performances. Pour en savoir plus, consultez les données sur les performances des disques SSD zonaux et régionaux. Si vous avez sélectionné la disponibilité pour plusieurs zones, consultez les données de performances des disques SSD régionaux. En résumé, le nombre d'IOPS en lecture et en écriture est de 30 par Go, et le débit est de 0,48 Mo par Go. Avec un SSD régional, les données sur les performances sont similaires, sauf que les IOPS en écriture par instance et le débit en écriture sont inférieurs.
Notez que la taille de stockage maximale acceptée est de 64 To sur une instance Cloud SQL.
Activer l'augmentation automatique de l'espace de stockage et surveiller la croissance du disque
Cloud SQL dispose d'une fonctionnalité d'augmentation automatique de l'espace de stockage pour éviter que les instances ne manquent d'espace disque. Lorsque cette fonctionnalité est activée, l'espace de stockage est vérifié toutes les 30 secondes et une capacité de stockage incrémentielle est ajoutée si nécessaire.
Bien que cette fonctionnalité vous empêche de manquer d'espace disque, l'augmentation de la capacité est définitive : vous ne pourrez pas réduire la taille de votre instance par la suite. Commencez par configurer des alertes sur la taille de votre disque afin de pouvoir gérer et planifier la capacité de stockage.
Se familiariser avec les options de chiffrement
Cloud SQL chiffre les données au repos par défaut. Toutefois, il est possible d'utiliser une clé de chiffrement gérée par le client (CMEK) au lieu de la clé par défaut détenue ou gérée par Google, si cela répond le mieux à vos besoins.
Configurer les connexions
Évaluer le compromis entre adresse IP privée et adresse IP publique
Les adresses IP privées et publiques font référence aux types d'adresses utilisés par les appareils d'un réseau. Une adresse IP privée offre une meilleure sécurité réseau et une latence réseau plus faible qu'une adresse IP publique. Toutefois, l'utilisation d'adresses IP privées nécessite des configurations IAM et d'API supplémentaires. De plus, certaines situations exigent d'utiliser une adresse IP publique. Si vous savez que vous devez utiliser une adresse IP publique mais que vous souhaitez renforcer la sécurité, vous pouvez choisir d'exiger un réseau autorisé ou utiliser le proxy d'authentification Cloud SQL.
Envisager d'utiliser le proxy d'authentification Cloud SQL pour les connexions sécurisées
Le proxy d'authentification Cloud SQL fournit un accès sécurisé à l'instance Cloud SQL sans avoir à configurer SSL ou des réseaux autorisés. L'application communique avec le client proxy d'authentification, qui s'exécute dans l'environnement local et utilise un tunnel sécurisé pour communiquer avec le serveur proxy sur l'instance Cloud SQL.
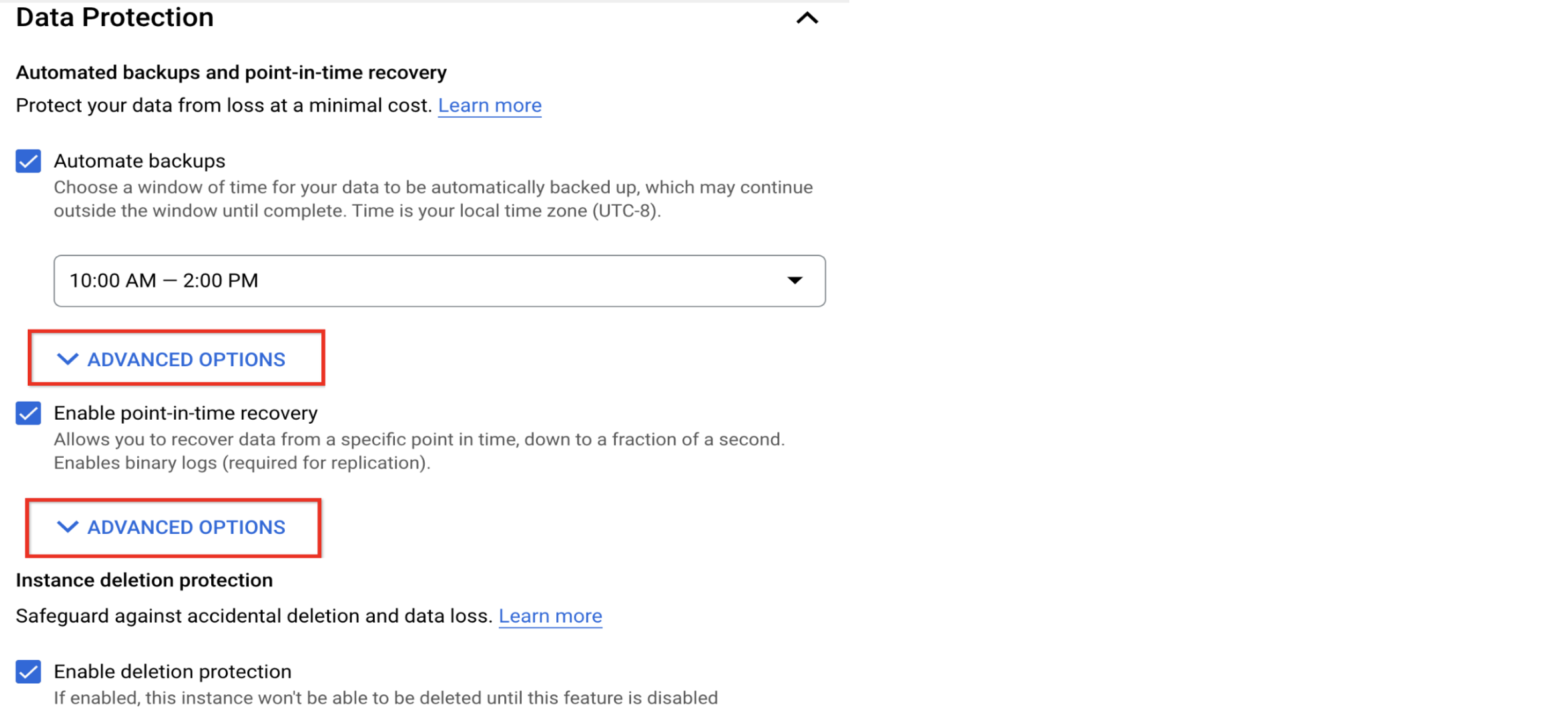
Configurer le planning des sauvegardes et la conservation
Activer les sauvegardes et la récupération à un moment précis, puis examiner votre règle de conservation
Les sauvegardes de données régulières et les plans de récupération de données vérifiables sont essentiels à la gestion saine des bases de données. Ces pratiques sont inestimables dans des situations telles que la corruption de données ou les opérations de données involontaires, qui ne peuvent pas être atténuées par la haute disponibilité.
Cloud SQL propose des sauvegardes automatiques, la vérification des sauvegardes et la récupération à un moment précis (PITR). Elles sont activées par défaut et sont obligatoires pour les instances comportant plusieurs zones. Les sauvegardes automatiques sont effectuées quotidiennement. La règle de conservation par défaut est de sept copies des sauvegardes et de sept jours pour les journaux binaires (conditions obligatoires pour la récupération à un moment précis). Vous pouvez modifier la règle de conservation dans la section "Options avancées".
Configurer des options de base de données
Les indicateurs de base de données sont des configurations de serveur qui accèdent au fichier my.cnf. Il existe une liste des indicateurs de bases de données que vous pouvez configurer. Toutefois, certains indicateurs gérés ne sont pas configurables. Il est recommandé d'examiner les indicateurs de base de données et de les configurer sur la valeur appropriée au moment de la création de l'instance. Certains indicateurs de base de données ne sont pas dynamiques, ce qui implique que leur modification déclenche un redémarrage de l'instance.
Vérifier character_set_server
Sur les instances Cloud SQL pour MySQL, la valeur de character_set_server par défaut est utf8 sur les versions 5.6 et 5.7, et utf8mb4 sur les versions 8.0. La variable character_set_server définit character_set_server, character_set_server, character_set_server et character_set_server sur la même valeur. La valeur de character_set_system, est définie par défaut sur utf8mb3 pour les versions 8.0.
Si vous migrez une instance et que la configuration actuelle utilise un autre jeu de caractères (par exemple, latin1), veillez à définir explicitement character_set_server sur la nouvelle instance.
Vérifier time_zone
Le fuseau horaire par défaut est system_time_zone, qui correspond à UTC. Si vous souhaitez utiliser un autre fuseau horaire, définissez-le dans default_time_zone. Cet indicateur accepte deux formats : le décalage de fuseau horaire (par exemple, +08:00) et le nom de fuseau horaire (par exemple, America/Los_Angeles). Lorsque le fuseau horaire est défini par son nom, il passe automatiquement à l'heure d'été (le cas échéant). L'indicateur default_time_zone n'est pas dynamique. Pour le modifier, vous devez redémarrer l'instance de base de données.
Activer le journal de requête lente
Par défaut, la fonction slow_query_log est désactivée. Nous vous recommandons vivement d'activer le journal de requête lente et de définir slow_query_log sur un seuil pertinent pour l'application. Le journal de requête lente permet de capturer les requêtes de longue durée à des fins d'analyse et d'optimisation. Ces informations participent non seulement au traitement des requêtes individuelles, mais aussi au débit global du serveur et à l'analyse rétrospective des charges de travail inattendues.
Consulter innodb_buffer_pool_size
Il s'agit de la configuration la plus efficace pour optimiser les performances d'InnoDB. Plus le volume de données pouvant être mises en mémoire tampon sera important, meilleures seront les performances du serveur. Dans le même temps, il doit y avoir suffisamment de mémoire réservée pour la mémoire tampon globale ainsi que pour la mémoire tampon dynamique de chaque thread.
Dans Cloud SQL, les valeurs par défaut, et les valeurs minimales et maximales autorisées de l'indicateur innodb_buffer_pool_size dépendent de la mémoire de l'instance, comme décrit dans la documentation.
Un indicateur "innodb_buffer_pool_size" correctement défini ne doit pas nécessairement contenir toutes les données, mais uniquement celles auxquelles on accède fréquemment. Les variables d'état qui reflètent l'efficacité du pool de mémoire tampon sont Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests. La variable Innodb_buffer_pool_read_requests correspond au nombre de requêtes de lecture logiques, et Innodb_buffer_pool_read_requests au nombre de lectures logiques non satisfaites à partir du pool de mémoire tampon et devant être lues sur le disque. Dans un cas idéal où les données se trouvent entièrement dans le pool de mémoire tampon, le ratio de la variable Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests est proche de zéro. Surveiller ces variables permet de se faire une idée de l'efficacité du pool de mémoire tampon InnoDB. Si la valeur innodb_buffer_pool_size est à la valeur maximale autorisée, que l'efficacité du pool de mémoire tampon n'est pas bonne et que l'application rencontre des problèmes de performances des requêtes, envisagez de mettre à niveau votre instance pour augmenter la mémoire.
Cette variable devient dynamique dans MySQL versions 5.7 et 8.0, tandis que dans la version 5.6, un redémarrage de l'instance est nécessaire pour modifier la variable.
Consulter innodb_log_file_size
Avant la version 8.0.30, les variables innodb_log_file_size et innodb_log_file_size n'étaient pas dynamiques, et la modification de la variable innodb_log_file_size nécessitait un arrêt normal. Dans la version 8.0.30, la variable innodb_redo_log_capacity a été introduite pour remplacer innodb_redo_log_capacity et innodb_redo_log_capacity.
Les instances Cloud SQL pour MySQL sont configurées avec la valeur innodb_log_file_size= 512 Mo, innodb_log_file_size= 2 (ou innodb_log_file_size= 1 Go). Cela permet à InnoDB de stocker plus de modifications dans le pool de mémoire tampon sans synchroniser avec le disque, ce qui améliore les performances du serveur. L'inconvénient des grands fichiers journaux de rétablissement est qu'ils augmentent le temps de récupération après un plantage. En fonction des exigences de haute disponibilité et de la configuration de l'instance, cette décision nécessite un équilibre entre performances et disponibilité.
En règle générale, nous recommandons d'avoir des fichiers journaux de rétablissement suffisamment volumineux pour contenir l'équivalent d'une heure d'activités d'écriture. Pour cela, vous pouvez observer la valeur Innodb_os_log_written tout au long de la journée, puis vous assurer que Innodb_os_log_written * Innodb_os_log_written est suffisamment volumineux pour l'heure de pointe observée.
Consulter innodb_log_buffer_size
Dans MySQL versions 5.6 et 5.7, la variable innodb_log_buffer_size n'est pas dynamique. Toute modification nécessite un redémarrage de l'instance. Par conséquent, il est préférable de la définir lors de l'initialisation.
Lorsque la valeur de innodb_log_buffer_size est suffisamment élevée pour contenir l'intégralité de la transaction, il n'y a pas de vidage supplémentaire sur le disque pendant l'exécution de la transaction. Par défaut, la valeur innodb_log_buffer_size est définie sur 16 Mo, ce qui est généralement suffisant. Toutefois, pour savoir si une transaction volumineuse peut nécessiter un tampon plus important, surveillez la variable d'état Innodb_log_waits lorsque vous émettez une transaction volumineuse. Si la valeur de innodb_log_buffer_size est trop faible et doit attendre un vidage, la valeur de innodb_log_buffer_size augmentera de un.
Ajuster les variables dynamiques au fur et à mesure
Certains indicateurs de base de données liés aux performances sont dynamiques, comme table_open_cache et thread_cache_size. Bien qu'il soit recommandé d'utiliser une taille adaptée dès le départ, nous vous conseillons d'établir des mesures et d'ajuster la taille si nécessaire.
La variable table_open_cache indique le nombre de tables ouvertes. Un cache suffisant permet de réduire le temps d'ouverture des tables et donc d'améliorer les performances des requêtes. La variable d'état Opened_tables indique le nombre de tables qui ont été ouvertes. Si la valeur Opened_tables ne cesse de croître, envisagez d'augmenter la valeur de table_open_cache.
La valeur thread_cache_size est destinée à la mise en cache des threads en vue de leur réutilisation après la déconnexion des clients. Si une instance attend un grand nombre de nouvelles connexions simultanées, définissez une taille plus importante. Le ratio des variables d'état Threads_created et "Connections" (Connexions) indique l'efficacité du cache de threads. Plus le ratio est faible, plus les performances sont bonnes.
Soyez prudent avec les options de mémoire par thread
Certains tampons de mémoire par thread ont un impact sur les performances des requêtes. Exemples : tmp_table_size, tmp_table_size, tmp_table_size et tmp_table_size, etc. Ces variables ont une portée globale et de session. Le portée globale définit la valeur par thread pour toutes les nouvelles connexions, tandis que la portée de session s'applique pour les requêtes suivantes lors de la session en cours. Une plus grande mémoire pour des paramètres de ce type améliore les performances des requêtes. Toutefois, comme ces variables sont dynamiques et qu'elles allouent un ou plusieurs tampons de mémoire par thread, elles peuvent entraîner des problèmes de mémoire insuffisante.
Il est préférable d'utiliser des nombres modérés pour les valeurs globales et de réserver les nombres plus élevés à des sessions spécifiques afin d'obtenir de meilleures performances de manière contrôlée.
Envisager d'utiliser performance_schema
La valeur performance_schema est désactivée par défaut avant les versions 8.0.26 de MySQL et son activation nécessite un redémarrage. La valeur performance_schema permet d'utiliser diverses instrumentations et fournit un ensemble complet de données pour analyser les opérations du serveur. Toutefois, elle entraîne des coûts liés aux performances et à la mémoire. Les instrumentations par défaut génèrent des baisses de performances d'environ 5 %, et ce chiffre augmente à mesure que d'autres instruments sont ajoutés. Effectuez un benchmark des instrumentations avec votre charge de travail, car la consommation de mémoire peut atteindre 1 Go ou plus. Vous pouvez observer cette consommation de mémoire dans la table memory_summary_global_by_event_name.
Gérer les utilisateurs de bases de données
Une fois l'instance Cloud SQL créée, un utilisateur de base de données est disponible : "root'@'%". Vous devrez probablement créer des utilisateurs de base de données supplémentaires.
Restreindre l'accès des utilisateurs aux opérations nécessaires
Limitez toujours l'accès des utilisateurs aux besoins de base.
Lorsque vous créez un utilisateur via la CLI de MySQL, vous devez explicitement lui accorder des droits.
Lorsque vous créez un utilisateur via la console Cloud, il dispose des mêmes droits que l'utilisateur "root'@'%". Dans MySQL versions 5.6 et 5.7, les droits par défaut incluent tous les droits associés à l'option d'attribution, à l'exception des droits SUPER et FILE. Dans la version 8.0, l'utilisateur dispose de droits dynamiques. Bien que les droits SUPER et FILE soient toujours limités, d'autres rôles d'administrateur sont disponibles pour les utilisateurs (par exemple, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN et APPLICATION_PASSWORD_ADMIN). Vous devrez révoquer tous les droits inutiles via la CLI MySQL. Sur les instances en version 8.0, la variable partial_revokes est activée.
Envisager de remplacer "root'@'%" par un administrateur spécifique
L'utilisateur "root'@'%" est le super-utilisateur par défaut le plus populaire. Il est donc souvent ciblé par des pirates informatiques. Nous vous recommandons de créer vos propres administrateurs avec le même ensemble de droits que l'utilisateur "root'@'%", puis de remplacer ce dernier pour renforcer la sécurité.
Configurer la surveillance
Il est très important de surveiller divers aspects des opérations de base de données et des ressources système. Cela vous permet d'examiner et d'analyser l'état opérationnel de votre instance au fil du temps, ce qui peut également faciliter la planification des ressources.
- La page de présentation de la console Cloud contient une liste de métriques de base.
- Cloud Monitoring propose des métriques supplémentaires. Vous pouvez créer un tableau de bord avec des métriques sélectionnées pour vos instances de base de données. Dans la console Cloud, dans le menu de navigation en haut à gauche, sélectionnez OPERATIONS --> Monitoring to access Cloud Monitoring (OPÉRATIONS --> Surveillance pour accéder à Cloud Monitoring).
- Utilisez les Insights sur les requêtes dans Cloud SQL pour analyser les performances des requêtes. La section de présentation affiche la charge de processeur segmentée par base de données, utilisateur ou adresse client. L'utilisation du processeur est également ventilée pour indiquer l'attente d'E/S et l'attente de verrouillage. Vous verrez également la liste des requêtes les plus fréquentes en fonction de leur condensé. Pour chaque récapitulatif des requêtes, vous pouvez voir la durée moyenne d'exécution, le nombre de requêtes et le nombre moyen de lignes analysées et renvoyées. Ces métriques sont très utiles pour identifier les points chauds et les requêtes à optimiser.
- Vous pouvez également compléter les recommandations qui précèdent en utilisant des outils de surveillance développés en interne et/ou des outils tiers. L'objectif principal est de comprendre les opérations de votre base de données pouvant influer à la fois l'optimisation et le dépannage des serveurs et des requêtes.
Configurer les alertes
Des alertes appropriées sont essentielles à la bonne santé du serveur. Elles permettent d'éviter les interruptions de service telles que la saturation de la mémoire (OOM) ou les blocages du système en raison de la saturation du processeur.
Si vous utilisez Cloud Monitoring, vous pouvez créer des alertes basées sur des métriques. Consultez la documentation pour en savoir plus.
Si vous utilisez d'autres outils de surveillance, veillez à configurer des alertes.
Configurer des instances répliquées
Pour effectuer un scaling des lectures, envisagez d'ajouter des instances répliquées avec accès en lecture. Vous pouvez utiliser HAProxy, ProxySQL ou un autre équilibreur de charge pour répartir les lectures entre plusieurs instances répliquées avec accès en lecture.
Cloud SQL est également compatible avec la réplication en chaîne, que vous pouvez découvrir dans la section Instances répliquées en cascade.
Les instances répliquées avec accès en lecture sont créées avec la même version de MySQL que l'instance principale. Après la création, vous pouvez choisir de mettre à niveau l'instance répliquées vers l'instance principale.
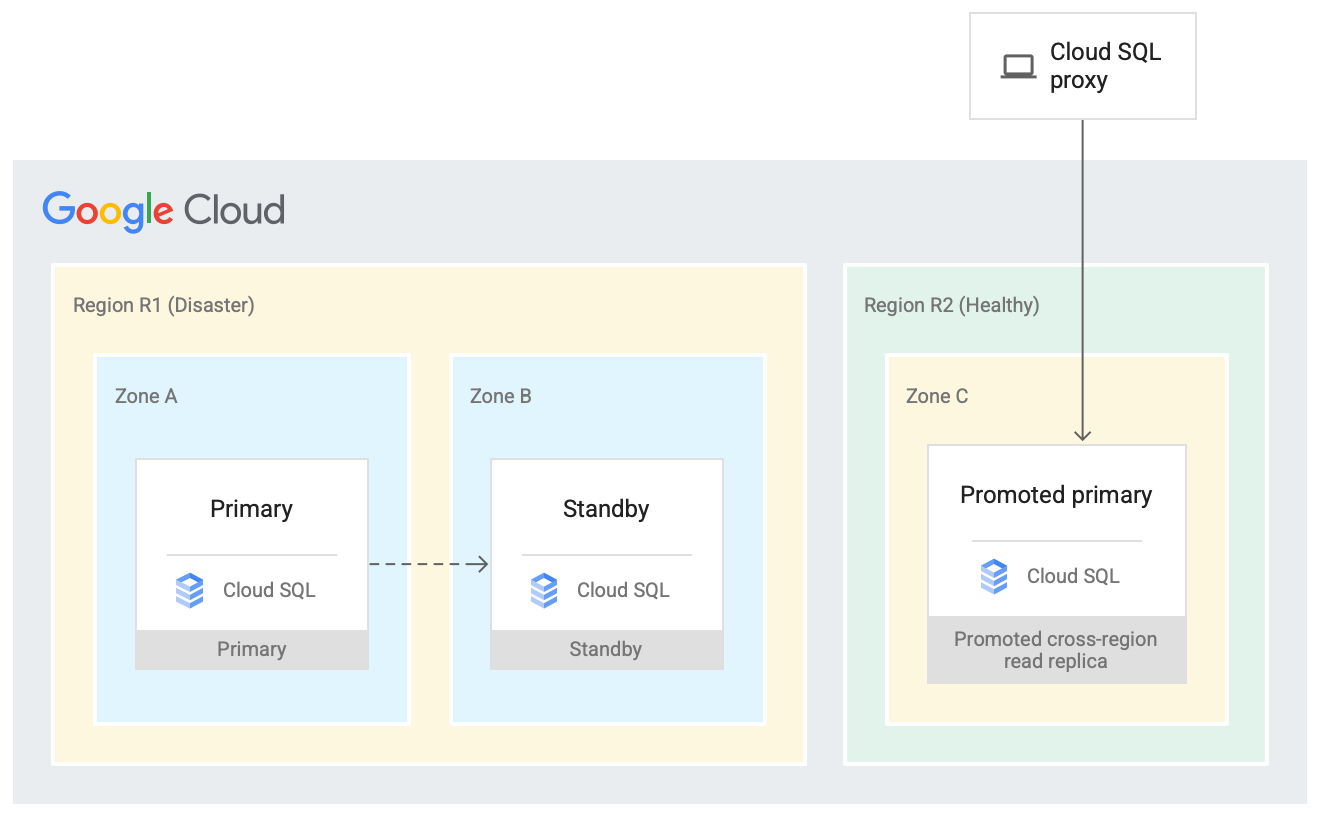
Planifier la reprise après sinistre
La solution haute disponibilité assure la redondance des données dans une zone secondaire de la même région. En cas de sinistre, une région peut devenir indisponible. Les instances répliquées interrégionales avec accès en lecture constituent une ressource efficace dans un plan de reprise après sinistre, car elles peuvent être promues en instance principale si nécessaire. Consultez la documentation pour en savoir plus.
Produits et services associés
Google Cloud propose une base de données MySQL gérée conçue pour répondre aux besoins de votre entreprise, de la suppression de votre centre de données sur site à l'exécution d'applications SaaS, en passant par la migration de systèmes d'entreprise de base.
Passez à l'étape suivante
Profitez de 300 $ de crédits gratuits et de plus de 20 produits Always Free pour commencer à créer des applications sur Google Cloud.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouvez un partenairePoursuivez vos recherches
Voir tous les produits











