Prácticas recomendadas de configuración de una instancia de Cloud SQL para MySQL
Si bien puedes implementar MySQL de forma manual en tu propia máquina física o incluso en una máquina virtual y optar por administrarla automáticamente, una opción cada vez más popular es usar una oferta administrada de un proveedor de servicios en la nube, que maneja los diversos aspectos operativos de la administración de MySQL.
Artículos relacionados
Prácticas recomendadas
Cloud SQL para MySQL es un servicio de base de datos completamente administrado que te ayuda a configurar, mantener, controlar y administrar tus bases de datos relacionales de MySQL en Google Cloud. Cuando estés listo para crear una instancia de Cloud SQL para MySQL, tienes algunas opciones, que incluyen la consola de IU, gcloud CLI, Terraform y una API de REST. Puedes seguir nuestra documentación a fin de obtener detalles sobre cada una de estas rutas, sin embargo, a los efectos de este artículo, usaremos la IU para ilustrar a medida que vemos una variedad de prácticas recomendadas para configurar una instancia.
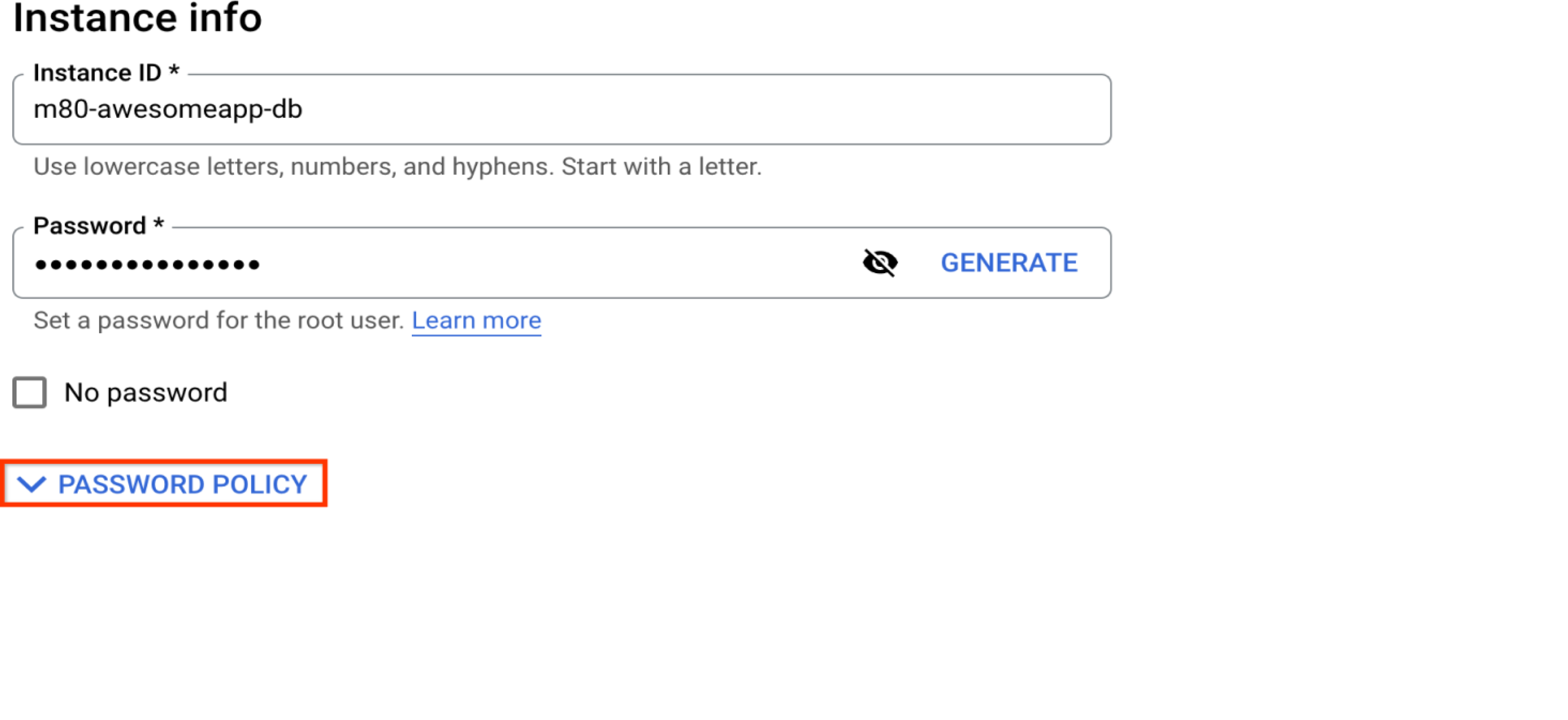
Información de la instancia
Cómo elegir una contraseña segura
Esta es la contraseña para el usuario predeterminado de la base de datos “root”@”%”, que se creará con la instancia. Si deseas conservar al usuario raíz como administrador, asegúrate de elegir una contraseña segura aquí. Se recomienda emplear un usuario administrador que no sea tan común en lugar de "root", por temas de seguridad. Consulta la sección “Administra los usuarios de la base de datos”.
Crea una política de contraseñas a nivel de instancia
La función de política de contraseñas permite una mayor seguridad de la base de datos. Te permite configurar políticas sobre la longitud, la complejidad, el vencimiento y la reutilización restringida de las contraseñas. Consulta Endurecimiento de una instancia de MySQL para obtener más detalles.
Versión de la base de datos
Considera la versión 8.0 para obtener un mejor rendimiento
MySQL de Cloud SQL admite varias versiones secundarias de 8.0, y la versión 8.0.26 es la predeterminada actual. Las pruebas comparativas en un rango de tipos de máquinas muestran una mejor capacidad de procesamiento de consultas con la versión predeterminada 8.0 que con las versiones 5.7 y 5.6.
No coloques la instancia de producción en la versión más reciente de DG
A pesar de todos los esfuerzos de prueba de Oracle y Cloud SQL, las versiones de actualización de MySQL no están aprobadas por completo en situaciones complejas del mundo real. Por lo tanto, recomendamos mantener las instancias de producción en una versión estable y usar las instancias de desarrollo y etapa de pruebas para probar las actualizaciones de la versión secundaria más recientes en Cloud SQL para MySQL.
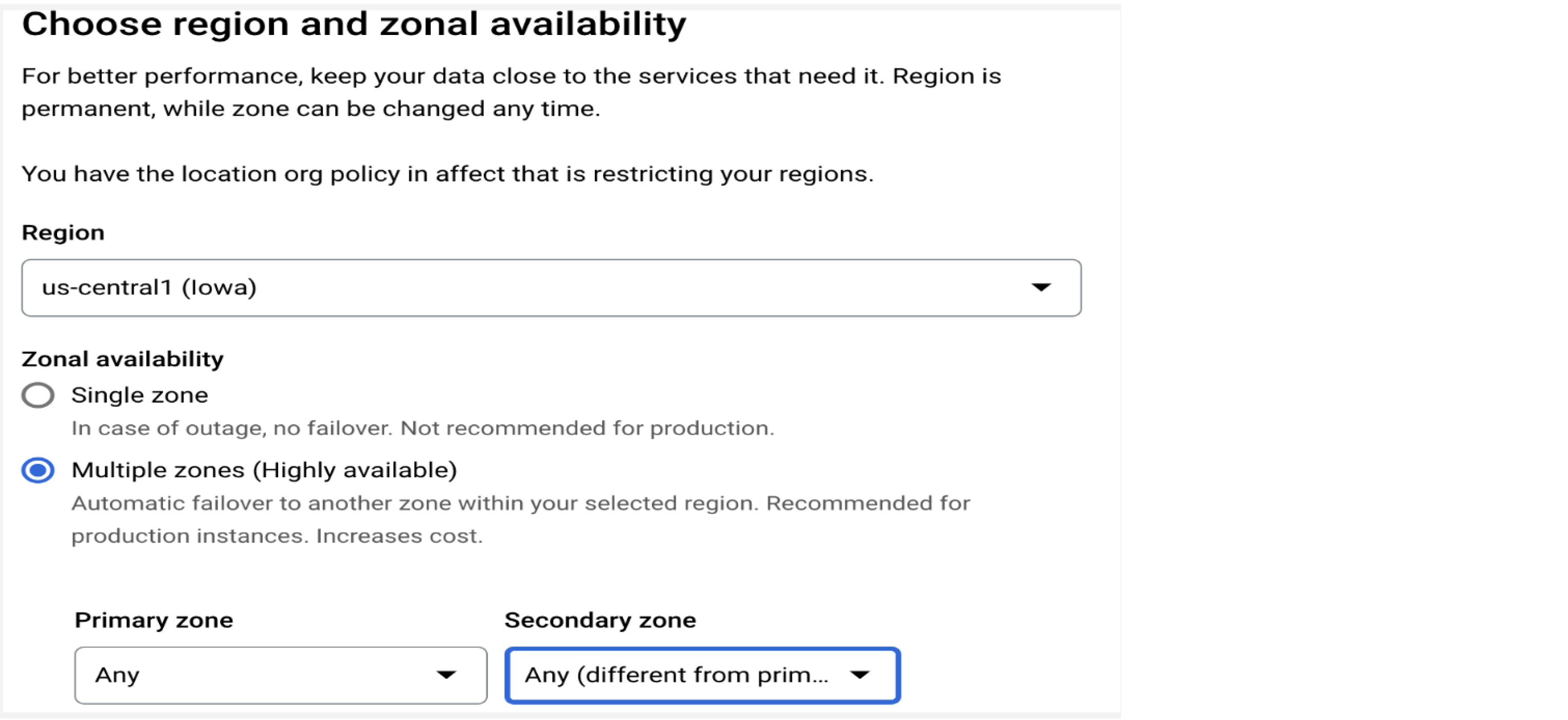
Alta disponibilidad
Configura varias zonas para la instancia de producción
Cloud SQL para MySQL ofrece disponibilidad regional a través de la conmutación por error automática a una segunda zona como una solución de alta disponibilidad. A fin de obtener la mejor disponibilidad, configura la opción de varias zonas para instancias de producción a fin de que tengas automáticamente copias de seguridad diarias y recuperación de un momento determinado (consulta la sección “Programa de copia de seguridad” para obtener más información).
Tipo de máquina
Evalúa el uso actual de la CPU y la memoria a fin de tomar decisiones fundamentadas para la migración
Cuando migras una instancia existente a Cloud SQL, la carga de trabajo actual puede ayudarte a elegir el tamaño de VM adecuado.
- CPU: ¿Cuál es tu uso de CPU en condiciones normales de carga de trabajo? ¿Qué sucede con las cargas de trabajo máximas? ¿La instancia está vinculada a la CPU o a E/S? Si el porcentaje de CPU del usuario o del sistema es relativamente alto, es una indicación de una carga de trabajo vinculada a la CPU. Si el porcentaje de E/S es relativamente alto, es una indicación de una carga de trabajo vinculada a E/S.
- Memoria: Del mismo modo, ¿cuál es el uso normal de memoria de la instancia y cuál es su uso máximo?
A modo de referencia, 1 CPU virtual en Cloud SQL para MySQL puede admitir hasta 6.5 GB de memoria.
Planifica entre un 20% y un 50% de espacio adicional para la CPU y la memoria
Incluso en una instancia generalmente estable, planifica al menos un 20% de espacio adicional para la CPU y la memoria, a fin de absorber los aumentos repentinos no planificados. Esto es aún más importante para una empresa en crecimiento, por lo que debes considerar un 50% adicional.
Cloud SQL facilita la actualización de tu tipo de máquina. Solo ten en cuenta que hay un tiempo de inactividad asociado con una actualización.
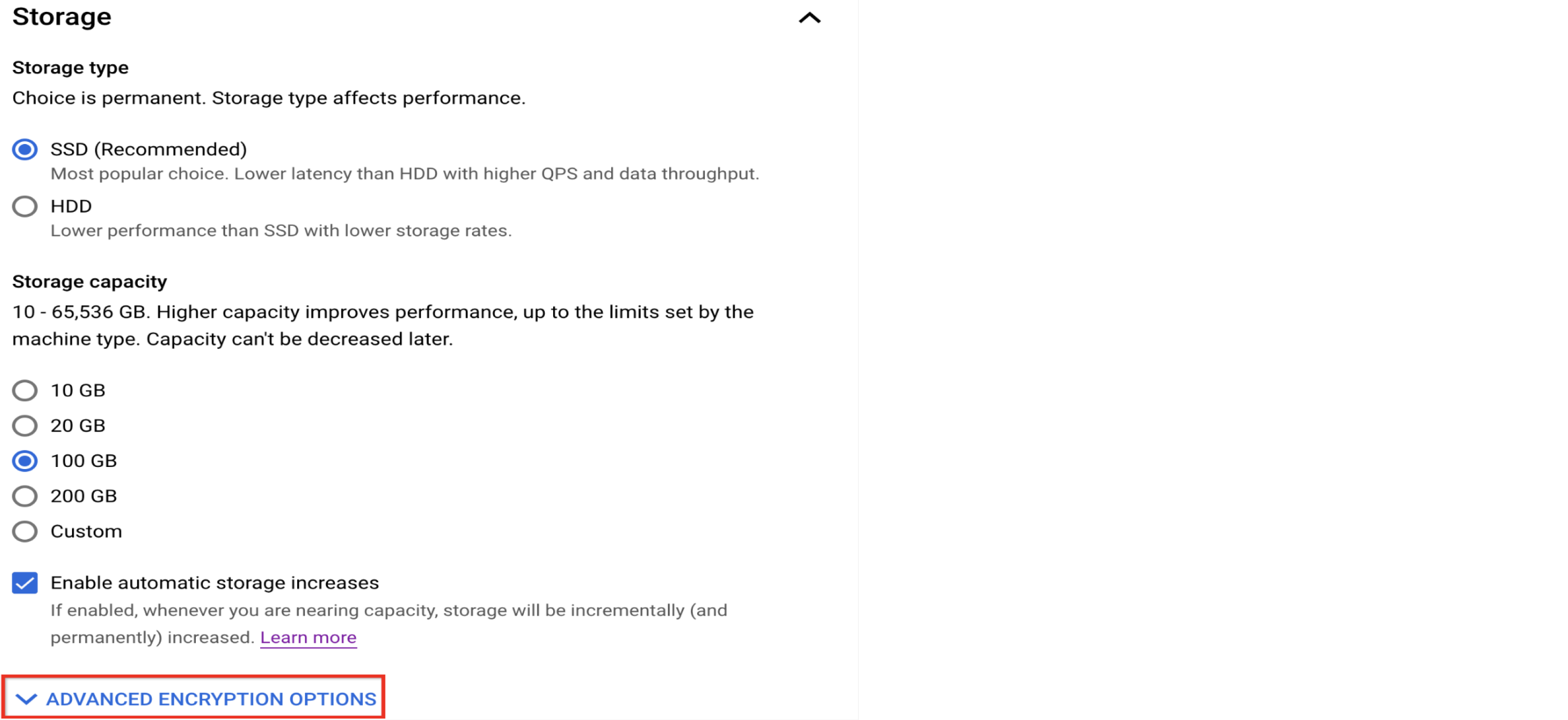
Personaliza el almacenamiento
Usa SSD para mejorar el rendimiento de la base de datos
Cloud SQL para MySQL ofrece HDD como una opción de almacenamiento económico, pero si sabes que necesitas una base de datos de alto rendimiento, elige la opción SSD. Aquí se incluye una comparación del rendimiento de E/S.
Planifica un equilibrio entre el rendimiento y el costo cuando se trata de la capacidad de almacenamiento
Las IOPS y la capacidad de procesamiento del disco se correlacionan con el tamaño del disco persistente. Una capacidad más alta brinda más IOPS y capacidad de procesamiento dentro del límite de instancias.
Para SSD, las configuraciones zonales y regionales afectarán el rendimiento. Consulta los datos de rendimiento de SSD zonales frente a los regionales para obtener más detalles. Si seleccionaste disponibilidad de varias zonas, consulta los datos de rendimiento de SSD regionales. En resumen, las IOPS de lectura y escritura son de 30 por GB y la capacidad de procesamiento es de 0.48 MB por GB. Con SSD regional, los datos de rendimiento son similares, excepto que las IOPS de escritura por instancia y la capacidad de procesamiento de escritura son más bajas.
Ten en cuenta que el tamaño máximo de almacenamiento admitido es de 64 TB en una instancia de Cloud SQL.
Habilita el aumento automático del almacenamiento y supervisa el crecimiento del disco
Cloud SQL tiene una característica de aumento de almacenamiento automático para evitar que las instancias se queden sin espacio en el disco (OOD). Cuando la función está habilitada, se verifica el almacenamiento cada 30 segundos y se agrega capacidad de almacenamiento incremental cuando es necesario.
Si bien esta característica te protege contra problemas de OOD, el aumento de capacidad es permanente y no puedes reducir el tamaño de la instancia más adelante. Primero, configura alertas en el tamaño del disco para poder administrar y planificar la capacidad de almacenamiento.
Familiarízate con las opciones de encriptación
Cloud SQL encripta los datos en reposo de forma predeterminada. Sin embargo, existe la opción de usar una clave de encriptación administrada por el cliente (CMEK) en lugar de la clave predeterminada propiedad de Google y la clave administrada por Google si eso se adapta mejor a tus necesidades.
Configurar conexiones
Evalúa la compensación entre la IP privada y la IP pública
IP privada e IP pública se refieren a los tipos de direcciones que usan los dispositivos en una red. La IP privada ofrece una mejor seguridad de red y una menor latencia de red en comparación con la IP pública. Sin embargo, la IP privada requiere una configuración adicional de IAM y APIs, y a veces se necesita una IP pública realmente. Si sabes que necesitas usar una IP pública, pero quieres mejorar la seguridad, puedes optar por exigir una red autorizada o usar el proxy de Cloud SQL Auth.
Considerar el proxy de Cloud SQL Auth para conexiones seguras
El proxy de Cloud SQL Auth proporciona acceso seguro a la instancia de Cloud SQL en lugar de configurar SSL o las redes autorizadas. La aplicación se comunica con el cliente del proxy de Auth, que se ejecuta en el entorno local y usa un túnel seguro para comunicarse con el servidor proxy en la instancia de Cloud SQL.
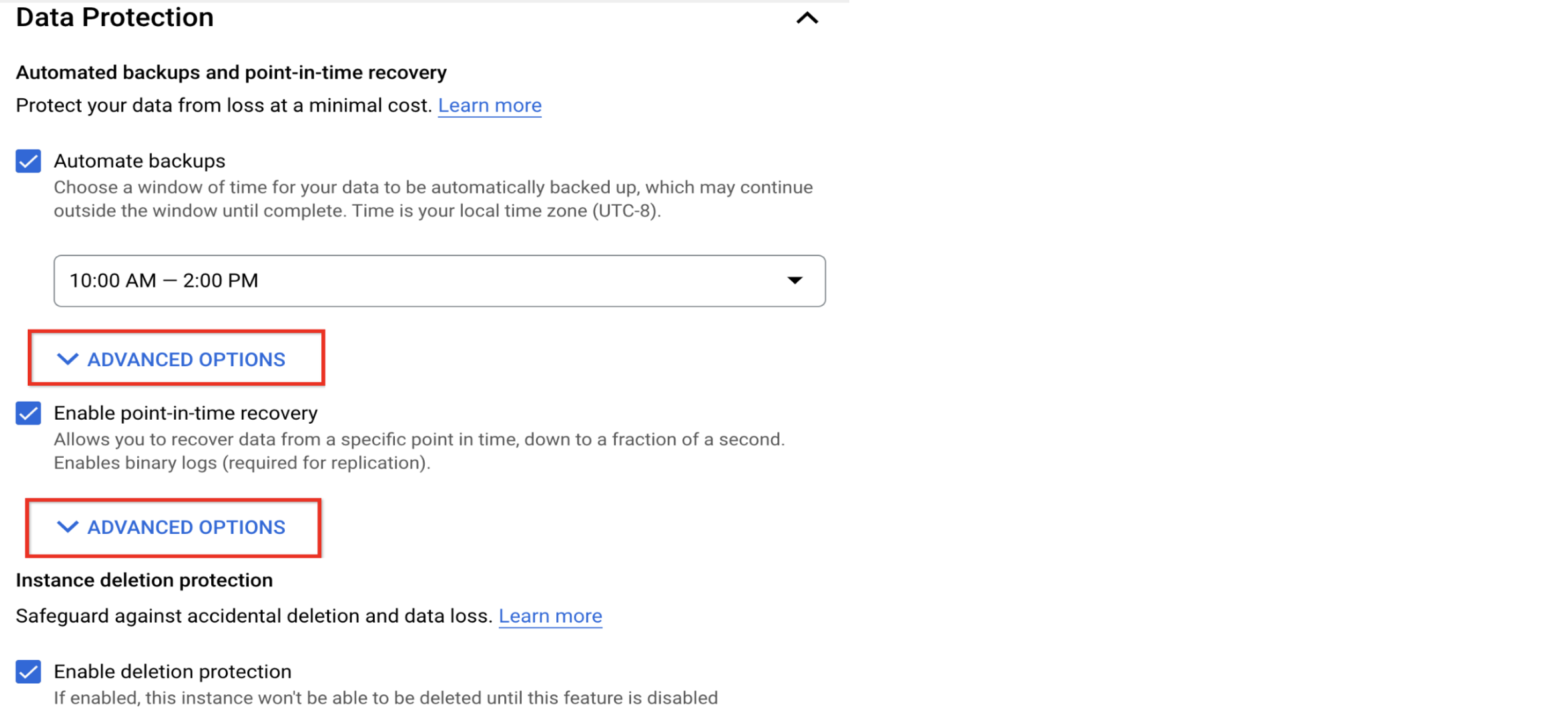
Configura la programación de copias de seguridad y la retención
Habilita las copias de seguridad y la recuperación de un momento determinado, y revisa tu política de retención
Las copias de seguridad de datos frecuentes y la recuperación de datos verificable son fundamentales para la administración de la base de datos en buen estado. Estas prácticas son invaluables en situaciones como la corrupción de datos o las operaciones de datos no deseadas, que no se pueden mitigar mediante la alta disponibilidad.
Cloud SQL ofrece copias de seguridad automáticas, verificación de copias de seguridad y recuperación de un momento determinado (PITR). Están habilitados de forma predeterminada y son obligatorios en las instancias con varias zonas. Las copias de seguridad automáticas se realizan a diario y la política de retención predeterminada es de siete copias de seguridad y siete días de registros binarios (obligatorios para PITR). Puedes ajustar la política de retención en la sección Opciones avanzadas.
Configurar marcas de bases de datos
Las marcas de base de datos son configuraciones de servidor que van al archivo my.cnf. Hay una lista de marcas de base de datos que se pueden configurar, y ciertas marcas administradas no se pueden configurar. Se recomienda revisar las marcas de base de datos y configurarlas con el valor adecuado en el momento de la creación de la instancia. Esto se debe a que algunas marcas de base de datos no son dinámicas, lo que significa que, si se cambian, se activaría un reinicio de instancia.
Revisa character_set_server
En las instancias de Cloud SQL para MySQL, el character_set_server predeterminado es utf8 en las versiones 5.6 y 5.7, y utf8mb4 en las versiones 8.0. El character_set_server establece character_set_server, character_set_server, character_set_server y character_set_server con el mismo valor. Para character_set_system, el valor predeterminado es utf8mb3 en la versión 8.0.
Si migras una instancia y la configuración actual usa un grupo de caracteres diferente (por ejemplo, latin1), asegúrate de configurar character_set_server de forma explícita en la instancia nueva.
Revisar time_zone
La zona horaria predeterminada es system_time_zone, que es UTC. Si quieres usar un valor distinto para time_zone, configúrala mediante default_time_zone. Esta marca tiene dos formatos: el retraso de la zona horaria, por ejemplo, +08:00, y nombres de zonas horarias, por ejemplo, "America/Los_Angeles". Cuando la zona horaria está definida por nombres de zona horaria, se ajusta automáticamente al horario de verano (si corresponde). La marca default_time_zone no es dinámica y es necesario reiniciar la instancia de base de datos para hacer un cambio.
Habilita el registro de consultas lentas
De forma predeterminada, el parámetro slow_query_log está desactivado. Te recomendamos habilitar el registro de consultas lentas y configurar slow_query_log con un umbral que tenga sentido para la aplicación. El registro de consultas lentas ayuda a capturar consultas de larga duración para el análisis y la optimización. Esta información ayuda no solo a las consultas individuales, sino también a la capacidad de procesamiento general del servidor y el análisis retrospectivo de las cargas de trabajo inesperadas.
Revisa innodb_buffer_pool_size
Esta es la configuración más eficaz para el rendimiento de InnoDB. Cuantos más datos se puedan almacenar en el búfer de la memoria, mejor será el rendimiento del servidor. Al mismo tiempo, debe haber suficientes memorias reservadas para los búferes globales y los búferes dinámicos por subproceso.
En Cloud SQL, los valores predeterminados, máximos y mínimos permitidos de la marca innodb_buffer_pool_size dependen de la memoria de la instancia, como se describe en la documentación.
Un buen valor de innodb_buffer_pool_size no tiene que contener todos los datos, sino solo los datos a los que se accede con frecuencia. Las variables de estado que reflejan la eficiencia del grupo de búferes son Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests. Innodb_buffer_pool_read_requests es la cantidad de solicitudes de lectura lógicas, y Innodb_buffer_pool_read_requests es la cantidad de lecturas lógicas que no satisface el grupo de búferes y que debieron leerse del disco. En un caso ideal en el que los datos estén completamente en el grupo de búferes, la proporción de Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests sería cercana a cero. Supervisar estas variables daría una idea de la eficiencia del grupo de búferes de InnoDB. Si el valor de innodb_buffer_pool_size está en el valor máximo permitido y la eficiencia del grupo de búferes no es buena y la aplicación tiene problemas de rendimiento de consulta, considera actualizar tu instancia y aumentar su memoria.
Esta variable se vuelve dinámica en las versiones 5.7 y 8.0 de MySQL, mientras que en la versión 5.6 es necesario reiniciar la instancia.
Revisa innodb_log_file_size
Antes de la versión 8.0.30, innodb_log_file_size y innodb_log_file_size no eran dinámicos, y cambiar innodb_log_file_size requería un cierre limpio. En la versión 8.0.30, se introdujo innodb_redo_log_capacity para reemplazar innodb_redo_log_capacity e innodb_redo_log_capacity.
Las instancias de Cloud SQL para MySQL están configuradas con innodb_log_file_size=512 MB, innodb_log_file_size=2 (o innodb_log_file_size=1 GB). Esto permite que InnoDB realice más cambios en el grupo de búferes sin sincronizarse con el disco, lo que mejora el rendimiento del servidor. La desventaja de los archivos de registro de rehacer grandes es el aumento en el tiempo de recuperación ante fallas. Según los requisitos y la configuración de HA de la instancia, esta decisión requiere un equilibrio entre el rendimiento y la disponibilidad.
En general, recomendamos que los archivos de registro de rehacer sean lo suficientemente grandes como para contener una hora de actividades de escritura. Una forma de medir esto es observar Innodb_os_log_written durante todo un día y, luego, asegurarte de que Innodb_os_log_written * Innodb_os_log_written sea lo suficientemente grande para la hora de máxima actividad observada.
Revisa innodb_log_buffer_size
En las versiones de MySQL 5.6 y 5.7, innodb_log_buffer_size no es dinámico, y para cambiarlo se debe reiniciar la instancia. Por lo tanto, es mejor configurarla durante la inicialización.
Cuando innodb_log_buffer_size es lo suficientemente grande para contener toda la transacción, no habrá limpieza adicional en el disco durante la ejecución de la transacción. De forma predeterminada, innodb_log_buffer_size se establece en 16 MB, que suele ser suficiente. Sin embargo, para tener una idea de si es posible que una transacción grande necesite un búfer más grande, supervisa la variable de estado Innodb_log_waits cuando emitas una transacción grande. Si el innodb_log_buffer_size es demasiado pequeño y necesita esperar una limpieza, innodb_log_buffer_size aumentará en uno.
Ajusta las variables dinámicas sobre la marcha
Algunas marcas de base de datos relacionadas con el rendimiento son dinámicas, como table_open_cache y thread_cache_size. Es bueno tener el tamaño adecuado para comenzar, mientras que se recomienda establecer mediciones y ajustar lo necesario.
La marca table_open_cache corresponde a la cantidad de tablas abiertas. Tener suficiente caché ayuda a reducir el tiempo de apertura de las tablas, por lo que mejora el rendimiento de las consultas. La variable de estado Opened_tables muestra la cantidad de tablas que se abrieron. Si Opened_tables sigue creciendo, considera aumentar Opened_tables.
La marca thread_cache_size es para almacenar en caché los subprocesos a fin de volver a usarlos después de que los clientes se desconectan. Si una instancia espera muchas conexiones nuevas simultáneas, establece un tamaño mayor. La proporción de variables de estado Threads_created y Connections muestra la eficiencia de la caché de subprocesos. Una proporción baja es mejor.
Adopta una estrategia conservadora con las marcas de memoria por subproceso
Hay búferes de memoria por subproceso que afectan el rendimiento de las consultas, por ejemplo, tmp_table_size, tmp_table_size, tmp_table_size, tmp_table_size y más. Estas variables tienen alcance global y de sesión. El alcance global establece el valor por subproceso para todas las conexiones nuevas, mientras que el alcance de sesión es eficaz para las consultas posteriores en la sesión actual. Una memoria más grande para la configuración como estas conduce a un mejor rendimiento de las consultas. Sin embargo, debido a que son dinámicos y asignan uno o más por subproceso, pueden generar situaciones de falta de memoria (OOM).
Es mejor usar números moderados para valores globales y reservar números más grandes para sesiones específicas a fin de lograr un mejor rendimiento de forma controlada.
Considera performance_schema
La marca performance_schema está desactivada de forma predeterminada antes de la versión 8.0.26 de MySQL y requiere un reinicio para activarla. La marca performance_schema habilita una variedad de instrumentaciones y proporciona un amplio conjunto de datos para analizar las operaciones del servidor, pero incluye los costos de rendimiento y memoria. Las instrumentaciones predeterminadas producen alrededor de un 5% de disminución del rendimiento, y esto aumenta a medida que se agregan más instrumentos. Compara instrumentaciones con tu carga de trabajo, ya que el consumo de memoria puede crecer hasta 1 GB o más. Puedes observar este consumo de memoria en la tabla memory_summary_global_by_event_name.
Administra usuarios de bases de datos
Después de crear la instancia de Cloud SQL, hay un usuario de la base de datos disponible, “root’@’%”. Es probable que debas crear usuarios de bases de datos adicionales.
Restringe el acceso de los usuarios a las operaciones necesarias
Siempre restringe el acceso de los usuarios a las necesidades mínimas.
Cuando crees un usuario mediante la CLI de MySQL, deberás otorgarle privilegios de forma explícita.
Cuando se crea un usuario a través de la consola de Cloud, este tendrá los mismos privilegios que el usuario “root’@’%”. En las versiones 5.6 y 5.7 de MySQL, los privilegios predeterminados incluyen todos los privilegios con la opción de otorgarse, excepto los privilegios SUPER y FILE. En la versión 8.0, el usuario viene con privilegios dinámicos y, si bien los privilegios SUPER y FILE todavía están restringidos, hay más funciones de administrador disponibles para los usuarios (por ejemplo, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN y APPLICATION_PASSWORD_ADMIN). Deberás revocar cualquier privilegio innecesario mediante la CLI de MySQL. En las instancias de la versión 8.0, la variable partial_revokes está habilitada.
Considera reemplazar “root’@’%” por un usuario administrador específico
El usuario “root’@’%” es el superusuario predeterminado y más popular. Por lo tanto, suele ser objetivo de los hackers. Recomendamos crear tus propios usuarios administradores con el mismo conjunto de privilegios que el usuario “root’@’%” para luego reemplazarlo a fin de mejorar la seguridad.
Configura la supervisión
Es muy importante supervisar y hacer un seguimiento de diversos aspectos de las operaciones de la base de datos y los recursos del sistema. Te permite revisar y analizar el estado operativo de tu instancia a lo largo del tiempo, lo que también puede ayudar con la planificación de recursos.
- La página de descripción general de la consola de Cloud incluye una lista de métricas principales.
- Cloud Monitoring ofrece métricas adicionales. Puedes crear un panel con las métricas seleccionadas para tus instancias de base de datos. En la consola de Cloud, en el menú de navegación de la parte superior izquierda, elige OPERACIONES --> Monitoring para acceder a Cloud Monitoring.
- Usa Estadísticas de consultas en Cloud SQL para analizar el rendimiento de las consultas. En la sección de descripción general, se muestra la carga de CPU dividida por base de datos, usuario o dirección del cliente. El uso de CPU también se desglosa para mostrar la espera de E/S y la de bloqueo. También enumera las consultas principales según su resumen. Para cada resumen de consultas, puedes ver el tiempo de ejecución promedio, la cantidad de consultas y el promedio de filas analizadas y mostradas. Estas métricas son muy útiles para identificar las áreas críticas y las consultas que se deben optimizar.
- También puedes complementar lo anterior con herramientas de supervisión propias o de terceros. El objetivo principal es comprender las operaciones de tu base de datos que pueden influir en la optimización del servidor y de las consultas y la solución de problemas.
Configurar las alertas
Las alertas adecuadas son fundamentales para el estado del servidor. Ayudan a evitar interrupciones del servicio, como falta de memoria (OOM) o bloqueos del sistema debido a la saturación de la CPU.
Si usas Cloud Monitoring, puedes crear alertas basadas en métricas. Consulta la documentación para obtener más detalles.
Si usas otras herramientas de supervisión, asegúrate de configurar las alertas.
Configura réplicas
Para escalar las lecturas, considera agregar réplicas de lectura. Puedes usar HAProxy, ProxySQL o algún otro balanceador de cargas para distribuir las lecturas entre varias réplicas de lectura.
Cloud SQL también es compatible con la replicación en cadena. Puedes obtener más información en la sección Réplicas en cascada.
Las réplicas de lectura se crean con la misma versión de MySQL que la instancia principal. Después de la creación, puedes elegir actualizar la réplica a la instancia principal.
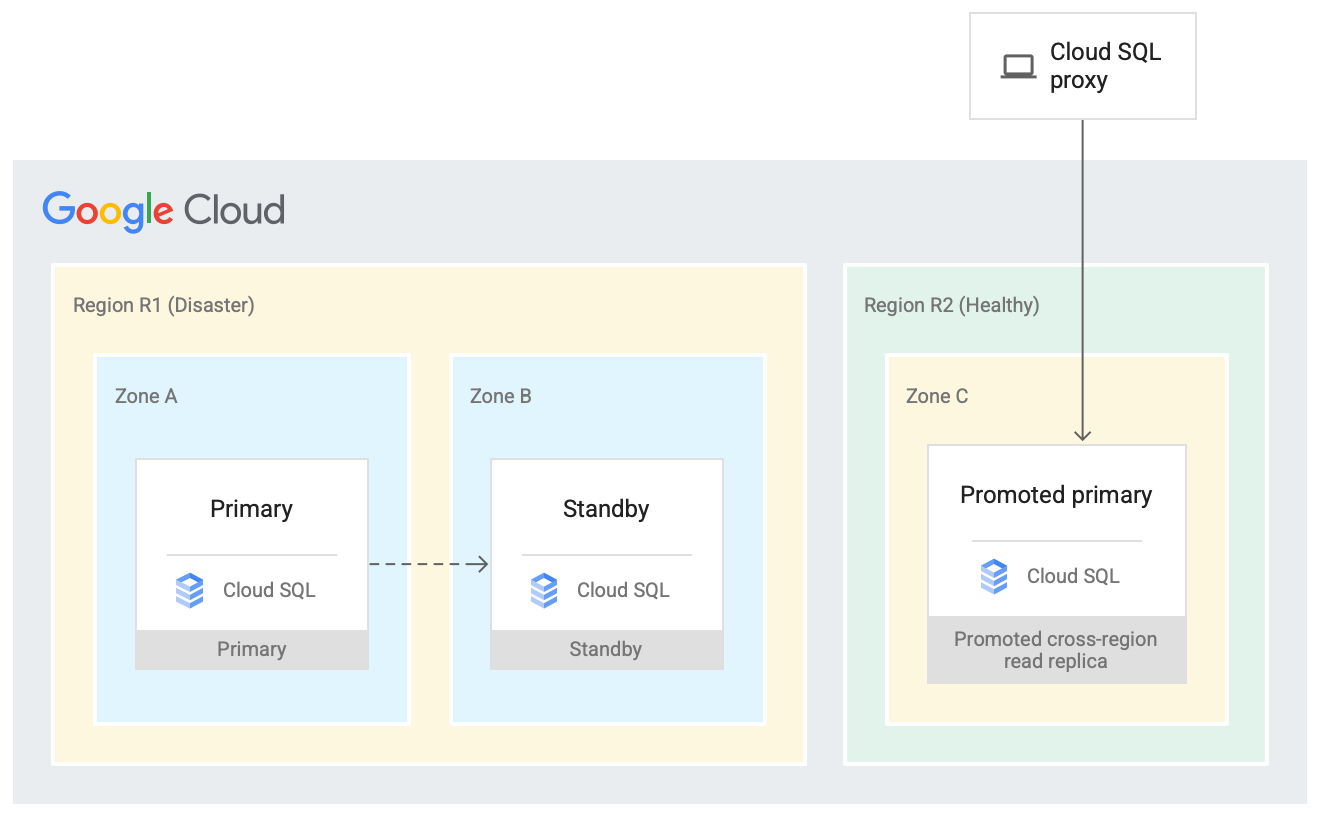
Planifica la recuperación ante desastres
La solución de alta disponibilidad proporciona redundancia de datos en una zona secundaria dentro de la misma región. En caso de desastre, una región podría dejar de estar disponible. Las réplicas de lectura entre regiones son un recurso importante de un plan de recuperación ante desastres, ya que se pueden ascender a una instancia principal cuando sea necesario. Consulta la documentación para obtener más información.
Productos y servicios relacionados
Google Cloud ofrece una base de datos administrada de MySQL que se adapta a las necesidades de tu empresa, desde la eliminación de tu centro de datos local hasta la ejecución de aplicaciones SaaS y la migración de los sistemas empresariales principales.
Da el siguiente paso
Comienza a desarrollar en Google Cloud con el crédito gratis de $300 y los más de 20 productos del nivel Siempre gratuito.
¿Necesitas ayuda para comenzar?
Comunicarse con VentasTrabaja con un socio confiable
Buscar un socioSigue explorando
Ver todos los productos


















