Best Practices zum Einrichten einer Cloud SQL for MySQL-Instanz
Sie können MySQL zwar manuell auf Ihrer eigenen physischen Maschine oder sogar auf einer virtuellen Maschine bereitstellen und sich dann für die Selbstverwaltung entscheiden, doch immer üblicher wird die Verwendung eines verwalteten Angebots von einem Cloud-Dienstanbieter, der die vielen operativen Aspekte der Verwaltung von MySQL übernimmt.
Best Practices
Cloud SQL for MySQL ist ein vollständig verwalteter Datenbankdienst, mit dem Sie relationale MySQL-Datenbanken in Google Cloud einrichten, pflegen und verwalten können. Wenn Sie eine Cloud SQL for MySQL-Instanz erstellen möchten, stehen Ihnen einige Optionen zur Verfügung, z. B. die UI-Konsole, die gcloud CLI, Terraform und eine REST API. Ausführliche Informationen zu diesen Pfaden finden Sie in der Dokumentation. In diesem Artikel wird die Benutzeroberfläche zur Veranschaulichung verwendet. Wir stellen Ihnen eine Reihe von Best Practices zum Einrichten einer Instanz vor.
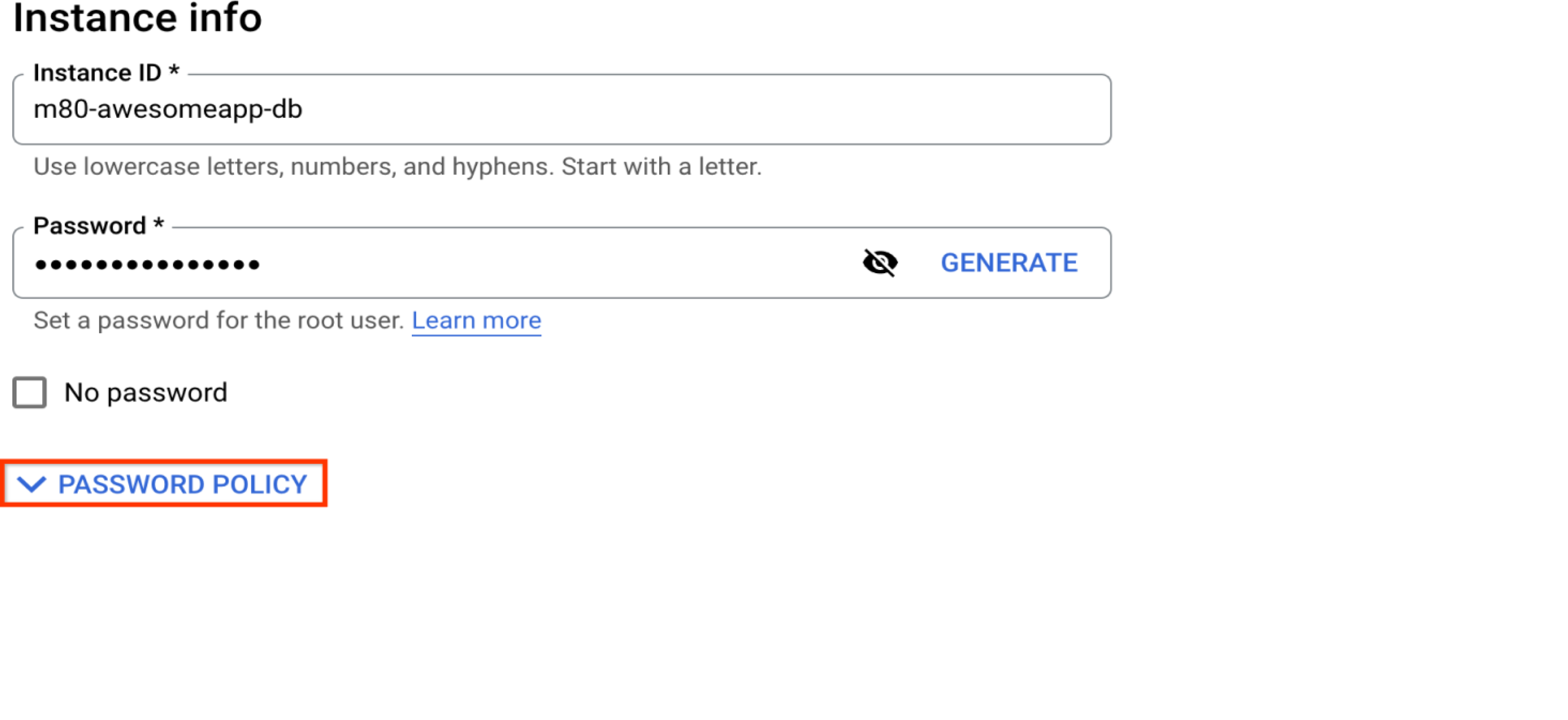
Instanzinformationen
Wählen Sie ein starkes Passwort.
Dies ist das Passwort für den Standardnutzer der Datenbank „root“@„%“, der mit der Instanz erstellt wird. Wenn Sie den Root-Nutzer als Administrator beibehalten möchten, wählen Sie hier ein starkes Passwort aus. Aus Sicherheitsgründen empfiehlt es sich, einen nicht gängigen Administrator anstelle von „root“ zu verwenden. Weitere Informationen finden Sie im Abschnitt „Datenbanknutzer verwalten“.
Passwortrichtlinie auf Instanzebene erstellen
Das Feature für Passwortrichtlinien ermöglicht eine verbesserte Datenbanksicherheit. Sie können damit Richtlinien für die Passwortlänge, die Komplexität, den Ablauf und die eingeschränkte Wiederverwendung konfigurieren. Weitere Informationen finden Sie unter MySQL-Instanz härten.
Datenbankversion
8.0 für eine bessere Leistung
Cloud SQL MySQL unterstützt mehrere 8.0-Nebenversionen, wobei v8.0.26 die aktuelle Standardversion ist. Benchmarktests für eine Reihe von Maschinentypen haben einen höheren Abfragedurchsatz mit der Standardversion 8.0 als mit den Versionen 5.7 und 5.6 ergeben.
Produktionsinstanz nicht auf die neueste GA-Version setzen
Trotz aller Testanstrengungen von Oracle und Cloud SQL werden Aktualisierungsversionen von MySQL nicht vollständig mit komplexen realen Szenarien geprüft. Daher empfehlen wir, für Ihre Produktionsinstanzen eine stabile Version zu verwenden und mit den Entwicklungs- und Staging-Instanzen die neuesten Nebenversionen in Cloud SQL for MySQL zu testen.
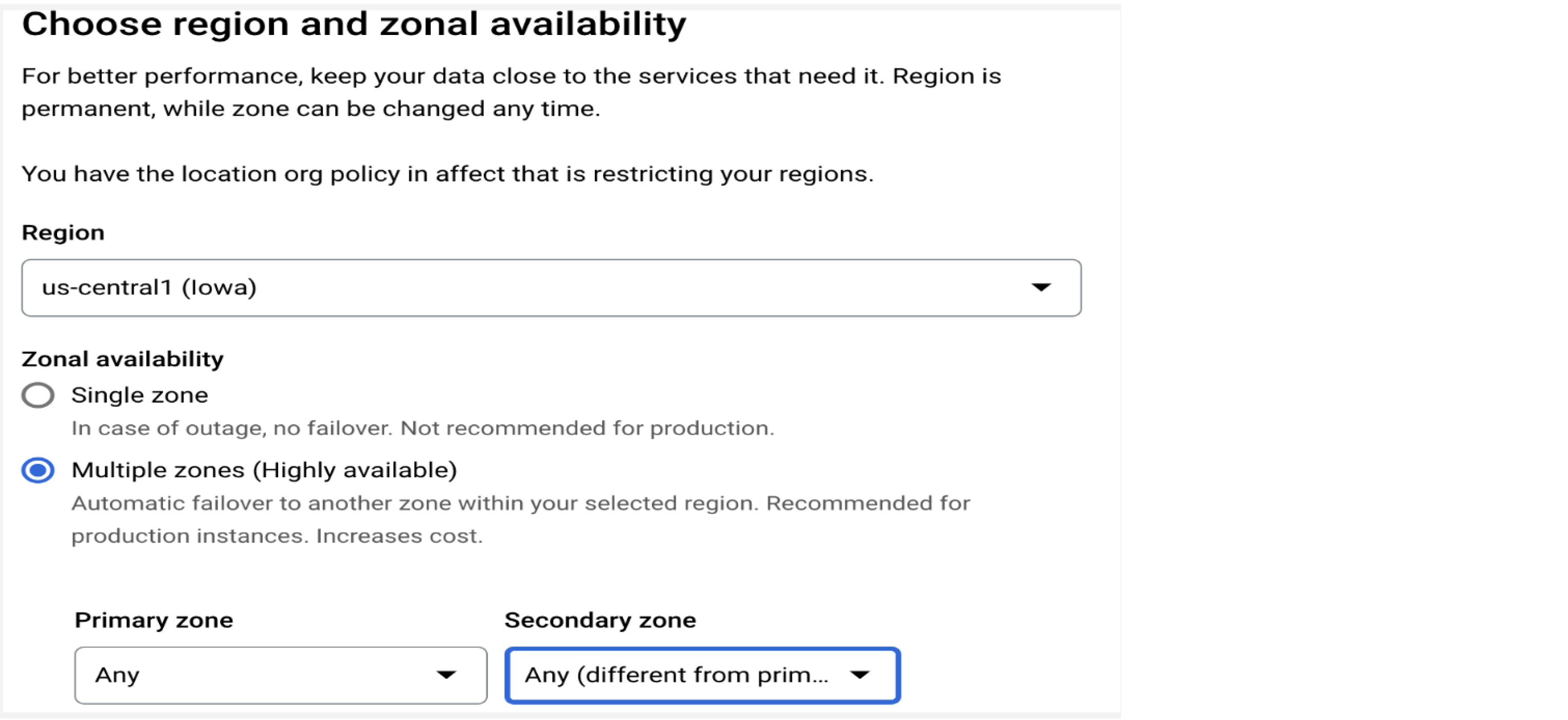
Hochverfügbarkeit
Mehrere Zonen für die Produktionsinstanz konfigurieren
Cloud SQL for MySQL bietet regionale Verfügbarkeit über ein automatisches Failover in eine zweite Zone als Hochverfügbarkeitslösung. Die beste Verfügbarkeit erzielen Sie, wenn Sie die Option für mehrere Zonen für Produktionsinstanzen so konfigurieren, dass automatisch tägliche Sicherungen und die Wiederherstellung zu einem bestimmten Zeitpunkt erfolgen. Weitere Informationen finden Sie im Abschnitt "Sicherungszeitplan".
Maschinentyp
Aktuelle CPU-/Arbeitsspeichernutzung bewerten, um fundierte Entscheidungen für die Migration zu treffen
Wenn Sie eine vorhandene Instanz zu Cloud SQL migrieren, kann die aktuelle Arbeitslast bei der Auswahl der richtigen VM-Größe helfen.
- CPU: Wie hoch ist Ihre CPU-Auslastung unter normalen Arbeitslastbedingungen? Welche Spitzenlast gibt es? Ist die Instanz CPU-gebunden oder E/A-gebunden? Wenn der CPU-Prozentsatz des Nutzers und/oder Systems relativ hoch ist, ist dies ein Hinweis auf eine CPU-gebundene Arbeitslast. Wenn der Prozentsatz der E/A relativ hoch ist, ist dies ein Hinweis auf eine E/A-gebundene Arbeitslast.
- Arbeitsspeicher: Was ist die normale Arbeitsspeichernutzung für die Instanz und was ist die Spitzenauslastung?
Zur Referenz: 1 vCPU in Cloud SQL for MySQL unterstützt bis zu 6,5 GB Arbeitsspeicher.
20 % bis 50 % mehr Platz für CPU und Arbeitsspeicher planen
Auch in einer allgemein stabilen Instanz sollten Sie mindestens 20 % mehr Platz für CPU und Arbeitsspeicher einplanen, um ungeplante Spitzen zu bewältigen. Für ein wachsendes Unternehmen ist dies noch wichtiger – berücksichtigen Sie zusätzliche 50 %.
Mit Cloud SQL ist ein einfaches Upgrade Ihres Maschinentyps möglich. Beachten Sie jedoch, dass bei einem Upgrade Ausfallzeiten auftreten.
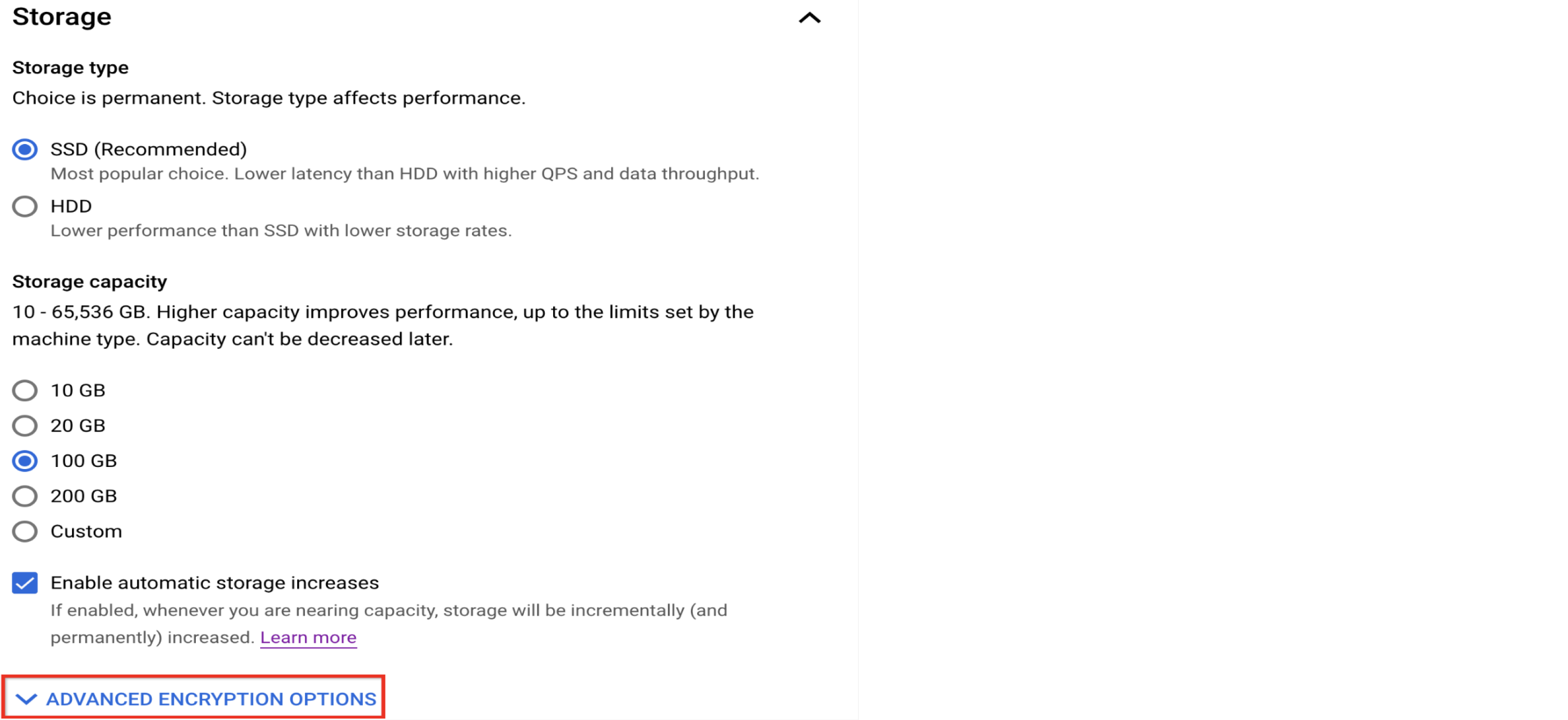
Speicher anpassen
Mit SSD die Datenbankleistung verbessern
Cloud SQL for MySQL bietet HDD als kostengünstige Speicheroption. Wenn Sie jedoch eine leistungsstarke Datenbank benötigen, wählen Sie die SSD-Option. Hier ein Vergleich der E/A-Leistung.
Leistung und Kosten für Speicherkapazität im Gleichgewicht halten
Laufwerks-IOPS und -Durchsatz stehen im Verhältnis zur Größe des nichtflüchtigen Speichers. Eine höhere Kapazität führt zu mehr IOPS und einem Durchsatz innerhalb des Instanzlimits.
Bei SSD wirken sich zonale und regionale Konfigurationen auf die Leistung aus. Weitere Informationen finden Sie unter Leistungsvergleich zwischen zonalen und regionalen SSDs. Wenn Sie mehrere Zonen ausgewählt haben, lesen Sie die regionalen Leistungsdaten zur SSD. Kurz gesagt, es gibt pro GB 30 Lese- und Schreib-IOPS und der Durchsatz beträgt 0,48 MB pro GB. Bei regionalen SSDs sind die Leistungsdaten ähnlich, allerdings sind die Schreib-IOPS und der Schreibdurchsatz pro Instanz niedriger.
Die maximal unterstützte Speichergröße einer Cloud SQL-Instanz beträgt 64 TB.
Automatische Speichererweiterung aktivieren und Laufwerkswachstum überwachen
Cloud SQL hat eine automatische Speichererweiterung, die verhindert, dass der Speicherplatz für Instanzen ausgeht. Wenn das Feature aktiviert ist, wird der Speicher alle 30 Sekunden geprüft und bei Bedarf wird die inkrementelle Speicherkapazität hinzugefügt.
Dieses Feature schützt zwar vor OOD, die erhöhte Kapazität ist jedoch dauerhaft. Sie können die Instanz später nicht verkleinern. Als Erstes richten Sie Benachrichtigungen zur Laufwerkgröße ein, damit Sie die Speicherkapazität verwalten und planen können.
Informationen zu den Verschlüsselungsoptionen einholen
Cloud SQL verschlüsselt ruhende Daten standardmäßig. Es ist jedoch möglich, einen vom Kunden verwalteten Verschlüsselungsschlüssel (CMEK) anstelle des standardmäßigen Google-eigenen und von Google verwalteten Schlüssels zu verwenden, wenn dies Ihren Anforderungen besser entspricht.
Verbindungen konfigurieren
Zwischen privater und öffentlicher IP-Adresse abwägen
Private und öffentliche IP-Adressen beziehen sich auf Adresstypen, die von Geräten in einem Netzwerk verwendet werden. Private IP-Adressen bieten im Vergleich zu öffentlichen IP-Adressen eine bessere Netzwerksicherheit und eine geringere Netzwerklatenz. Für die Einrichtung einer privaten IP-Adresse sind jedoch zusätzliche API- und IAM-Konfigurationen erforderlich. In einigen Fällen kann auch eine öffentliche IP-Adresse erforderlich sein. Wenn Sie wissen, dass Sie eine öffentliche IP-Adresse verwenden müssen, aber die Sicherheit verbessern möchten, können Sie ein autorisiertes Netzwerk wählen oder den Cloud SQL Auth-Proxy verwenden.
Cloud SQL Auth-Proxy für sichere Verbindungen in Betracht ziehen
Der Cloud SQL Auth-Proxy bietet sicheren Zugriff auf die Cloud SQL-Instanz, und es müssen keine SSL oder autorisierte Netzwerke konfiguriert werden. Die Anwendung kommuniziert mit dem Auth-Proxy-Client, der in der lokalen Umgebung ausgeführt wird und einen sicheren Tunnel verwendet, um mit dem Proxyserver auf der Cloud SQL-Instanz zu kommunizieren.
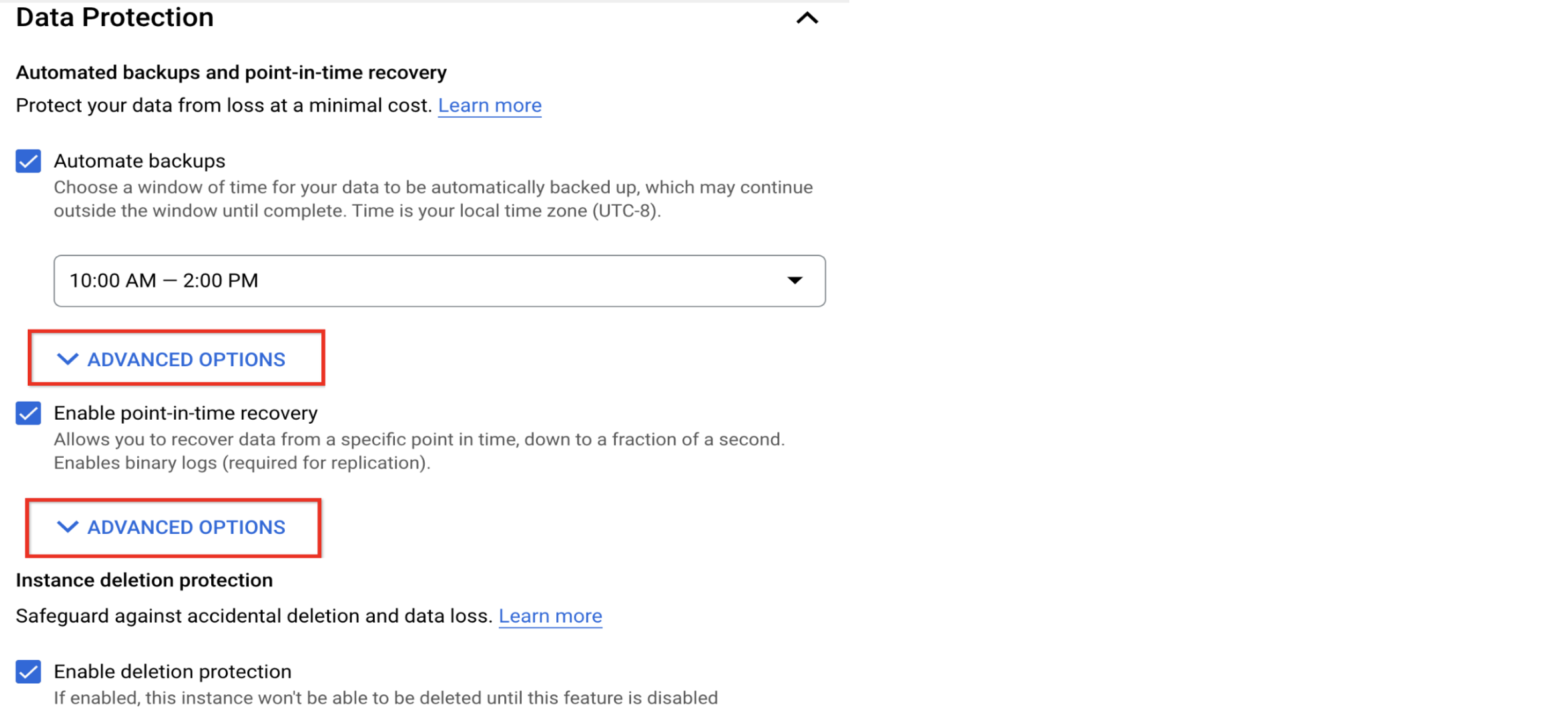
Sicherungszeitplan und Aufbewahrung festlegen
Sicherungen und Wiederherstellung zu einem bestimmten Zeitpunkt aktivieren und Aufbewahrungsrichtlinie prüfen
Regelmäßige Datensicherungen und überprüfbare Datenwiederherstellung sind für eine fehlerfreie Datenbankverwaltung entscheidend. Diese Verfahren sind in Situationen wie Datenbeschädigung oder ungewollten Datenvorgängen von unschätzbarem Wert – beides kann nicht durch Hochverfügbarkeit ausgeglichen werden.
Cloud SQL bietet automatische Sicherungen, Sicherungsüberprüfung und Wiederherstellung zu einem bestimmten Zeitpunkt (PITR). Diese Features sind standardmäßig aktiviert und auf Instanzen mit mehreren Zonen erforderlich. Automatische Sicherungen werden täglich erstellt. Die standardmäßige Aufbewahrungsrichtlinie umfasst sieben Kopien von Sicherungen und sieben Tage binärer Logs (erforderlich für PITR). Sie können die Aufbewahrungsrichtlinie im Abschnitt „Erweiterte Optionen“ anpassen.
Datenbank-Flags konfigurieren
Datenbankflags sind Serverkonfigurationen, die in die Datei „my.cnf“ aufgenommen werden. Es gibt eine Liste von Datenbankflags, die konfigurierbar sind, und von bestimmten verwalteten Flags, die nicht konfigurierbar sind. Es empfiehlt sich, die Datenbankflags zu prüfen und zum Zeitpunkt der Instanzerstellung auf den richtigen Wert zu konfigurieren. Da einige Datenbankflags nicht dynamisch sind, würde das Ändern der Flags einen Instanzneustart auslösen.
Zeichensatz überprüfen
In Cloud SQL for MySQL-Instanzen wird der Standardzeichensatz über character_set_server in den Versionen 5.6 und 5.7 auf UTF-8 und in der Version 8.0 auf UTF8mb4 festgelegt. Mit character_set_server werden character_set_server, character_set_server, character_set_server, character_set_server auf denselben Wert gesetzt. Für character_set_system gilt in der Version 8.0 der Standard UTF8mb3.
Wenn Sie eine Instanz migrieren und die aktuelle Konfiguration einen anderen Zeichensatz verwendet (z. B. Latin1), müssen Sie character_set_server explizit für die neue Instanz festlegen.
Zeitzone überprüfen
Die Zeitzone ist standardmäßig über das Flag system_time_zone auf UTC festgelegt. Wenn Sie eine andere Zeitzone verwenden möchten, legen Sie diese über das Flag default_time_zone fest. Dieses Flag unterstützt zwei Formate: Zeitzonenversatz (z. B. +08:00) und Zeitzonennamen (z. B. America/Los_Angeles). Wenn die Zeitzone durch Namen von Zeitzonen definiert wird, passt sie sich automatisch an die Sommerzeit an (falls relevant). Das Flag default_time_zone ist nicht dynamisch und erfordert einen Neustart der Datenbankinstanz, damit eine Änderung erfolgen kann.
Langsames Abfragelog aktivieren
Standardmäßig ist slow_query_log auf AUS gesetzt. Wir empfehlen dringend, das langsame Abfragelog zu aktivieren und slow_query_log auf einen für die Anwendung sinnvollen Schwellenwert festzulegen. Mit dem langsamen Abfragelog können Sie lang andauernde Abfragen zur Analyse und Optimierung erfassen. Diese Informationen sind nicht nur für einzelne Abfragen hilfreich, sondern auch für den gesamten Serverdurchsatz und die rückblickende Analyse unerwarteter Arbeitslasten.
innodb_buffer_pool_size prüfen
Dies ist die effektivste Konfiguration für die Leistung von InnoDB. Je mehr Daten im Arbeitsspeicher gepuffert werden können, desto besser ist die Serverleistung. Gleichzeitig muss genügend Speicherplatz für globale Zwischenspeicher und dynamische Zwischenspeicher pro Thread reserviert sein.
In Cloud SQL hängen die zulässigen, standardmäßigen und höchsten zulässigen Werte des Flags innodb_buffer_pool_size vom Arbeitsspeicher der Instanz ab, wie in der Dokumentation beschrieben.
Eine gute Pufferpoolgröße muss nicht alle Daten enthalten, sondern nur die Daten, auf die häufig zugegriffen wird. Die Statusvariablen, die die Effizienz des Pufferpools widerspiegeln, sind Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests. Innodb_buffer_pool_read_requests ist die Anzahl der logischen Leseanfragen und Innodb_buffer_pool_read_requests die Anzahl der logischen Lesevorgänge, die vom Pufferpool nicht erfüllt werden und von der Festplatte gelesen werden müssen. Im Idealfall liegt das Verhältnis von Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests fast bei Null, wenn sich die Daten vollständig im Pufferpool befinden. Das Monitoring dieser Variablen vermittelt eine Vorstellung von der Effizienz des InnoDB-Pufferpools. Wenn innodb_buffer_pool_size den maximal zulässigen Wert hat und die Effizienz des Pufferpools nicht gut ist und die Anwendung Probleme mit der Abfrageleistung hat, sollten Sie ein Upgrade Ihrer Instanz auf einen größeren Arbeitsspeicher vornehmen.
Diese Variable ist in MySQL Version 5.7 und 8.0 bereits dynamisch. In Version 5.6 hingegen erfordert eine Änderung einen Instanzneustart.
innodb_log_file_size prüfen
Vor der Version 8.0.30 waren innodb_log_file_size und innodb_log_file_size nicht dynamisch. Beim Ändern von innodb_log_file_size musste das System ordnungsgemäß heruntergefahren werden. In Version 8.0.30 wurde innodb_redo_log_capacity eingeführt, um innodb_redo_log_capacity und innodb_redo_log_capacity zu ersetzen.
Cloud SQL for MySQL-Instanzen sind mit innodb_log_file_size=512 MB, innodb_log_file_size=2 GB (oder innodb_log_file_size=1 GB) konfiguriert. So kann InnoDB mehr Änderungen im Pufferpool speichern, ohne mit dem Laufwerk synchronisiert zu werden, was die Serverleistung verbessert. Der Nachteil von großen Redo-Logdateien ist die erhöhte Absturzwiederherstellungszeit. Abhängig von den Anforderungen der Hochverfügbarkeit und der Einrichtung der Instanz ist für diese Entscheidung ein Gleichgewicht zwischen Leistung und Verfügbarkeit erforderlich.
Im Allgemeinen empfehlen wir Redo-Logdateien, die groß genug sind, um Schreibvorgänge von einer Stunde zu erfassen. Dazu können Sie beispielsweise Innodb_os_log_written über den Tag hinweg beobachten und dann Innodb_os_log_written * Innodb_os_log_written groß genug für die beobachtete Spitzenzeit festlegen.
innodb_log_buffer_size prüfen
In MySQL Versionen 5.6 und 5.7 ist innodb_log_buffer_size nicht dynamisch und die Änderung erfordert einen Instanzneustart. Daher sollten Sie den Wert bei der Initialisierung festlegen.
Wenn innodb_log_buffer_size groß genug für die gesamte Transaktion ist, wird das Laufwerk während der Transaktionsausführung nicht zusätzlich geleert. Standardmäßig ist innodb_log_buffer_size auf 16 MB festgelegt, was im Allgemeinen ausreicht. Wenn Sie eine Vorstellung davon erhalten möchten, wieviel Puffer eine große Transaktion benötigt, überwachen Sie die Statusvariable Innodb_log_waits, während Sie eine große Transaktion ausführen. Wenn innodb_log_buffer_size zu klein ist und auf eine Leerung gewartet werden muss, erhöht sich innodb_log_buffer_size um 1.
Dynamische Variablen flexibel anpassen
Einige leistungsbezogene Datenbankflags sind dynamisch, z. B. table_open_cache, thread_cache_size. Es empfiehlt sich, mit der richtigen Größe zu beginnen. Dazu wird empfohlen, Messungen vorzunehmen und nach Bedarf zu optimieren.
Der table_open_cache bezieht sich auf die Anzahl der geöffneten Tabellen. Ein ausreichender Cache hilft, die Tabellenöffnungszeit zu reduzieren und damit die Abfrageleistung zu verbessern. Die Statusvariable Opened_tables zeigt die Anzahl der geöffneten Tabellen. Wenn Opened_tables weiter wächst, sollten Sie Opened_tables erhöhen.
thread_cache_size dient zum Zwischenspeichern von Threads nach dem Trennen der Clients. Wenn eine Instanz viele simultane neue Verbindungen erwartet, legen Sie eine größere Größe fest. Das Verhältnis der Statusvariablen Threads_created und Connections zeigt die Effizienz des Thread-Caches. Ein niedriges Verhältnis ist besser.
Speicher-Flags pro Thread vorsichtig einsetzen
Es gibt Puffer pro Thread, die die Abfrageleistung beeinträchtigen, z. B.tmp_table_size ,tmp_table_size, tmp_table_size, tmp_table_size und andere. Diese Variablen haben sowohl einen globalen als auch einen Sitzungsumfang. Der globale Bereich legt den Threadwert für alle neuen Verbindungen fest, während der Sitzungsumfang für nachfolgende Abfragen in der aktuellen Sitzung wirksam ist. Ein größerer Arbeitsspeicher für Einstellungen wie diese führt zu einer besseren Abfrageleistung. Da diese Einstellungen jedoch dynamisch sind und eine oder mehrere pro Thread zugewiesen werden können, besteht die Gefahr von unzureichendem Arbeitsspeicher (OOM).
Es empfiehlt sich, für globale Werte mittlere Zahlen zu verwenden und für bestimmte Sitzungen größere Zahlen zu reservieren und so auf kontrollierte Weise eine bessere Leistung zu erzielen.
performance_schema berücksichtigen
Das Leistungsschema (performance_schema) ist standardmäßig vor der Version MySQL 8.0.26 auf AUS gesetzt und erfordert einen Neustart, um es zu aktivieren. Das Leistungsschema ermöglicht eine Vielzahl von Instrumentierungen und bietet umfangreiche Daten zur Analyse der Servervorgänge, ist jedoch mit Leistungs- und Speicherkosten verbunden. Standardinstrumente führen zu etwa 5 % Leistungseinbußen. Dieser Wert nimmt zu, je mehr Instrumente hinzugefügt werden. Vergleichen Sie Instrumentierungen mit Ihrer Arbeitslast, da der Speicherverbrauch auf 1 GB oder mehr steigen kann. Sie können diesen Speicherverbrauch in der Tabelle memory_summary_global_by_event_name beobachten.
Datenbanknutzer verwalten
Nach dem Erstellen der Cloud SQL-Instanz ist ein Datenbanknutzer verfügbar: „root“@„%“. Sie müssen wahrscheinlich weitere Datenbanknutzer erstellen.
Nutzerzugriff auf die erforderlichen Vorgänge beschränken
Beschränken Sie den Nutzerzugriff immer auf das Notwendige.
Wenn Sie einen Nutzer über die MySQL-Befehlszeile erstellen, müssen Sie Berechtigungen explizit erteilen.
Wenn Sie einen Nutzer über die Cloud Console erstellen, hat er dieselben Berechtigungen wie der Nutzer „root“@„%“. In MySQL Version 5.6 und 5.7 umfassen die Standardberechtigungen alle Berechtigungen mit Berechtigungsoption, außer SUPER- und FILE-Berechtigungen. In Version 8.0 verfügt der Nutzer über dynamische Berechtigungen. Während die Berechtigungen SUPER und FILE noch eingeschränkt sind, stehen den Nutzern weitere Administratorrollen zur Verfügung (z. B. APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN, APPLICATION_PASSWORD_ADMIN und APPLICATION_PASSWORD_ADMIN). Sie müssen alle nicht erforderlichen Berechtigungen über die MySQL-Befehlszeile widerrufen. In Version 8.0-Instanzen ist die Variable partial_revokes aktiviert.
Erwägen Sie, „root“@„%“ durch einen bestimmten Administrator zu ersetzen
Der „root“@„%“-Nutzer ist der Standard- und beliebteste Superuser und daher oft Ziel von Hackern. Wir empfehlen, Ihre eigenen Administratoren mit denselben Berechtigungen wie der Nutzer „root“@„%“ zu erstellen und sie dann zu ersetzen, um die Sicherheit zu erhöhen.
Monitoring einrichten
Es ist sehr wichtig, verschiedene Aspekte der Datenbankvorgänge und -systemressourcen zu überwachen und zu verfolgen. Sie können den operativen Zustand Ihrer Instanz im Zeitverlauf beobachten und analysieren und dadurch auch die Ressourcenplanung verbessern.
- Auf der Übersichtsseite der Cloud Console finden Sie eine Liste der wichtigsten Messwerte.
- Cloud Monitoring bietet zusätzliche Messwerte. Sie können ein Dashboard mit ausgewählten Messwerten für Ihre Datenbankinstanzen erstellen. Wählen Sie in der Cloud Console oben links im Navigationsmenü „OPERATIONS“ > „Monitoring“ aus, um auf Cloud Monitoring zuzugreifen.
- Verwenden Sie Query Insights in Cloud SQL für die Analyse der Abfrageleistung. Im Übersichtsbereich wird die CPU-Auslastung nach Datenbank, Nutzer oder Clientadresse aufgeschlüsselt angezeigt. Die CPU-Nutzung wird auch nach E/A-Wartezeit und Wartezeit für die Sperre aufgeschlüsselt. Außerdem werden die häufigsten Abfragen nach dem Abfrage-Digest aufgelistet. Für jeden Abfrage-Digest sehen Sie die durchschnittliche Ausführungszeit, die Anzahl der Abfragen und die durchschnittlichen Zeilen, die gescannt und zurückgegeben wurden. Diese Messwerte sind sehr hilfreich, um Hotspots und Abfragen zu identifizieren, die optimiert werden müssen.
- Sie können die obigen Informationen auch durch eigene Monitoringtools und/oder Tools von Drittanbietern ergänzen. Das Hauptziel besteht darin, Ihre Datenbankvorgänge zu verstehen, die sowohl die Server- als auch die Abfrageoptimierung und Fehlerbehebung beeinflussen können.
Benachrichtigung einrichten
Korrekte Benachrichtigungen sind entscheidend für den Serverzustand. Sie verhindern Dienstunterbrechungen wie unzureichenden Arbeitsspeicher oder Systemstaus aufgrund der CPU-Auslastung.
Wenn Sie Cloud Monitoring verwenden, können Sie messwertbasierte Benachrichtigungen erstellen. Informationen hierzu finden Sie in der Dokumentation.
Wenn Sie andere Monitoring-Tools verwenden, müssen Sie die Benachrichtigungen konfigurieren.
Replikate konfigurieren
Wenn Sie Lesevorgänge skalieren möchten, können Sie Lesereplikate hinzufügen. Sie können HAProxy, ProxySQL oder einen anderen Load-Balancer verwenden, um Lesevorgänge auf mehrere Lesereplikate zu verteilen.
Cloud SQL unterstützt auch verkettete Replikationen. Weitere Informationen hierzu finden Sie unter Kaskadierende Replikate.
Die Lesereplikate werden mit derselben MySQL-Version wie die primäre Instanz erstellt. Nach dem Erstellen können Sie das Replikat auf das primäre Replikat upgraden.
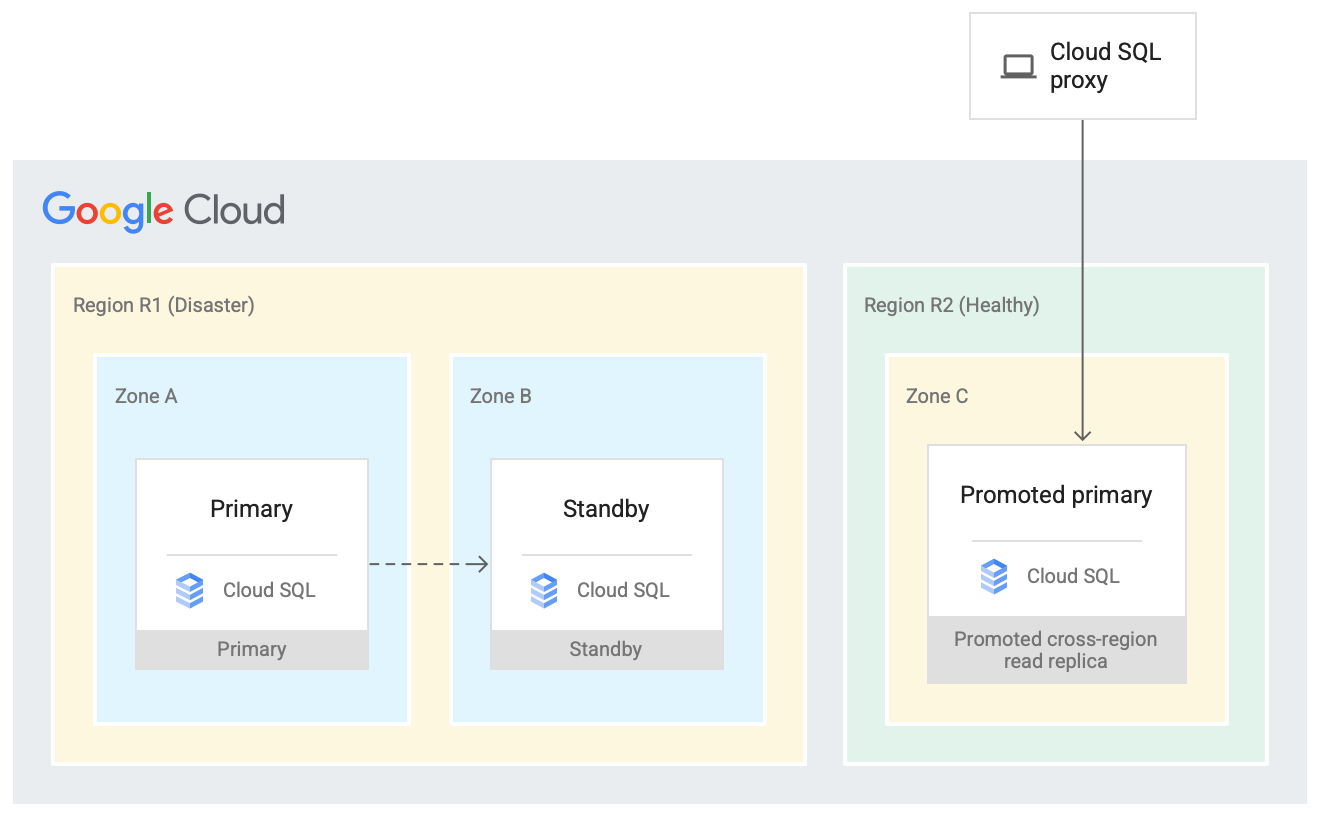
Plan für die Notfallwiederherstellung
Die Hochverfügbarkeitslösung bietet Datenredundanz in einer sekundären Zone innerhalb derselben Region. Im Notfall ist eine Region möglicherweise nicht mehr verfügbar. Regionenübergreifende Lesereplikate sind eine gute Ressource in einem Notfallwiederherstellungsplan, da sie bei Bedarf zu einer primären Instanz hochgestuft werden können. Weitere Informationen finden Sie in der Dokumentation.
Ähnliche Produkte und Dienste
Google Cloud bietet eine verwaltete MySQL-Datenbank, die auf Ihre geschäftlichen Anforderungen zugeschnitten ist – von der Stilllegung Ihres lokalen Rechenzentrums über die Ausführung von SaaS-Anwendungen bis hin zur Migration von Kerngeschäftssystemen.
Gleich loslegen
Profitieren Sie von einem Guthaben über 300 $, um Google Cloud und mehr als 20 „Immer kostenlos“ Produkte kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen











