借助计算字段,您可以创建从数据中派生的新指标和维度。借助计算字段,您可以扩展和转换数据源中的信息,并在报告中查看结果。
观看视频
计算字段的运作方式
计算字段是一种公式,可对数据源中的一个或多个其他字段执行某种操作。计算字段可以执行算术和数学运算;处理文本、日期和地理位置信息;以及使用分支逻辑来评估数据并返回不同的结果。您还可以使用自定义组计算字段类型创建自定义组,或使用自定义箱计算字段类型创建自定义箱。然后,在包含该计算字段的图表中,可以针对每行数据显示计算字段的输出。新数据的显示方式取决于其使用方式。
例如,假设您创建了一个名为总计的计算字段,该字段将单价字段 (Price) 乘以售出数量字段 ( Qty Sold ):
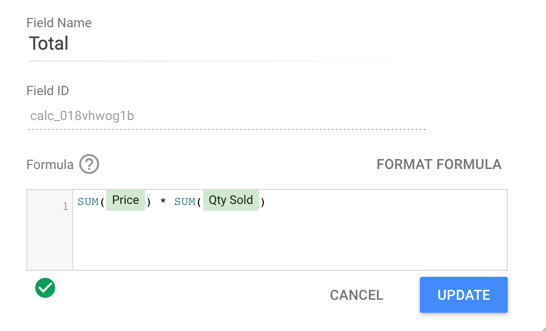
在表格中使用时,计算出的总计字段会显示每行的乘积。
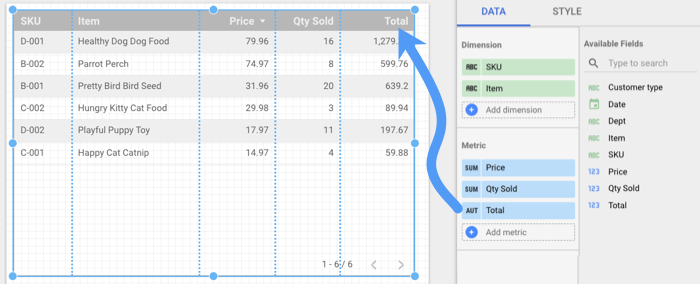
在记分卡中使用时,“总计”字段会显示所有行的商品总额(数量乘以价格)。
数据源级计算字段与图表级计算字段
计算字段分为两种,具体取决于您在何处创建它们:在数据源中或在报告中的特定图表中。每种类型的计算字段都比另一种类型具有一定的优势。
数据源中的计算字段
在数据源中创建计算字段时,您可以执行以下操作:
- 使用相应数据源的任何报告中都可以使用该计算字段。
- 您可以在图表、控件和其他计算字段中使用数据源计算字段,就像使用常规字段一样。
- 您可以像过滤常规字段一样过滤数据源计算字段。例如,您可以设置过滤条件属性,以仅包含总价值为 500 美元或更高的商品:

数据源计算字段的限制
数据源中的计算字段具有以下限制:
- 您无法将数据源计算字段与混合数据搭配使用。
- 您必须拥有对数据源的修改权限,才能在该数据源中创建或修改计算字段。
- 在数据源中创建或修改计算字段时,您无法应用自定义值格式。
您可以在图表的属性面板的设置标签页中,为数据源计算字段应用自定义值格式。
图表专用计算字段
您可以直接向报告中的图表添加计算字段。这些特定于图表的(也称为“图表级”)计算字段可以执行数学运算、使用函数,并返回基于 CASE 语句的结果,就像数据源中的计算字段一样。
与数据源计算字段相比,图表专用计算字段具有以下优势:
- 您可以快速添加字段,而无需访问数据源。
- 您可以创建基于混合数据的特定于图表的计算字段。
- 您可以在图表专用计算字段中包含数据源计算字段。
- 您可以在创建过程中将自定义值格式应用于特定图表的计算字段。
图表专用计算字段的限制
- 特定于图表的计算字段仅存在于您创建它们的图表中。在图表中创建字段并不会同时在图表的数据源中创建该字段。
- 您无法在公式中引用其他图表专用的计算字段,即使这些字段是在同一图表中定义的也是如此。(如果您需要引用其他计算字段,请使用数据源计算字段。)
- 如需创建特定于图表的计算字段,您必须是相应报告的编辑者。
- 必须在数据源中启用报告中的字段修改功能。
下表总结了这 2 类计算字段之间的差异。
| 特征 | 数据源计算字段 | 图表专用计算字段 |
|---|---|---|
| 谁可以创建? | 数据源编辑器 | 报告编辑者 |
| 适用于混合数据吗? | 否 | 是 |
| 是否包含其他计算字段? | 是 | 否 |
| 相应字段可在何处使用? | 基于相应数据源的任何报告 | 仅限创建该图表的特定图表 |
数据类型
计算字段的数据类型取决于公式中涉及的函数:
- 使用算术函数或聚合函数(例如
SUM、COUNT或MAX)的公式会创建数字类型的字段。 - 使用文本函数(例如
CONCAT、SUBSTR或LOWER)的公式会创建文本类型的字段。 - 使用日期和时间函数的公式会创建数字或日期和时间类型的字段,具体取决于所使用的函数。
您可以在数据源编辑器中使用类型下拉菜单更改计算字段的数据类型。
不妨详细了解数据类型。
聚合和计算字段
聚合是指对字段数据进行汇总的方法。您可以构建处理未汇总的逐行值或汇总值的计算字段。
例如,假设您有 2 个非汇总的数字维度,即价格和售出数量,并且有以下数据:
| 订单日期 | 商品 | 售出数量 | 价格 |
| 2019 年 10 月 2 日 | Pretty Bird 鸟食 | 7 |
7.99 |
| 2019 年 10 月 3 日 | Pretty Bird 鸟食 | 5 |
7.99 |
| 2019 年 10 月 8 日 | Pretty Bird 鸟食 | 3 |
7.99 |
| 2019 年 10 月 13 日 | Pretty Bird 鸟食 | 5 |
7.99 |
若要计算这些订单的总价值,您需要将价格与售出数量相乘:
Price * Quantity Sold
如果您在数据源中创建此字段,则结果将是一个未汇总的数字维度。在图表中使用此函数时,系统会使用默认的“求和”汇总方式,并计算每行数据的总和。
如需创建汇总计算指标,请为构成公式的任何数字字段添加所需的汇总函数。例如,假设您想在统计信息摘要图表中显示总利润率。您可以使用如下公式来实现此目的:
SUM(Profit) / SUM(Revenue)
当您明确指定聚合方法时,字段的默认聚合设置为 Auto。这样可确保 Looker Studio 按预期聚合公式,并防止有人更改默认聚合后计算字段出现问题。
计算字段的用途
借助计算字段,您可以执行以下任务:
对数字字段执行基本数学运算
您可以使用常规运算符执行简单的算术计算:
- 加法:+
- 减法:-
- 分部:/
- 乘法:*
您可以结合使用上述任何运算符、静态数值和数据源中的未聚合数值字段来构建计算字段。使用圆括号强制指定计算顺序。
示例
Users / New Users
(SUM(Price) * SUM(Quantity)) *.085
详细了解运算符。
使用函数处理数据
借助函数,您可以采用不同的方式聚合数据、应用数学和统计运算、处理文本以及使用日期和地理位置信息。
示例
SUM(Quantity) - 将“数量”字段中的值相加。
PERCENTILE(Users per day, 50) -- 返回“每天的用户数”字段的所有值的第 50 百分位数。
ROUND(Revenue Per User, 0) - 将“每位用户的收入”字段四舍五入到 0 位小数。
SUBSTR(Campaign, 1, 5) - 返回“广告系列”字段的前 5 个字符。
REGEXP_EXTRACT(Pipe delimited values, R'^([a-zA-Z_]*)(\|)') - 提取竖线分隔字符串中的第一个值。
DATETIME_DIFF(Start Date, End Date) - 计算开始日期和结束日期之间的天数。
PARSE_DATETIME("%d/%m/%Y %H:%M:%S", DateTimeText) - 根据文本字段创建日期。
TOCITY(Criteria ID, "CRITERIA_ID") - 显示有效的 Google Ads 地理位置定位条件 ID 对应的城市名称。
使用分支逻辑
借助 CASE 语句,您可以在计算字段中执行分支“if/then/else”样式逻辑。例如,以下 CASE 公式将指定的国家/地区归类到相应区域,同时将未指定的国家/地区归类到“其他”类别:
CASE
WHEN Country IN ("USA","Canada","Mexico") THEN "North America"
WHEN Country IN ("England","France") THEN "Europe"
ELSE "Other"
END
创建自定义群组
借助自定义组,您可以为维度创建临时自定义组,而无需在计算字段或 SQL 中开发或编写 CASE 逻辑。如果您想为符合特定条件的值分配固定的标签或类别名称,此功能会非常有用。
例如,名为“按目的地划分的 FAA 航班数量”的表格图表显示了按表示航班目的地的“DestState”维度分组的“记录数”指标。
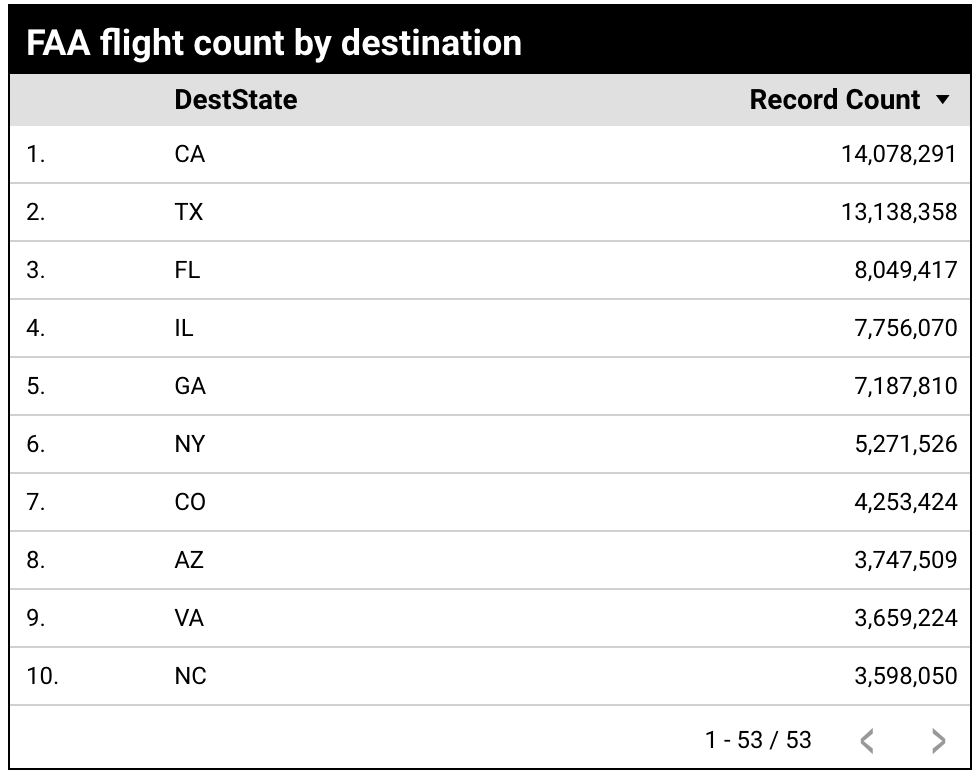
报告创建者希望按区域(而非按各个州)查看和比较数据,但数据源中没有“地区”维度。报告创建者可以通过创建自定义群组,将特定州或国家/地区归入相应区域。
报告创建者通过输入以下规范,向图表中添加了自定义分组计算字段:
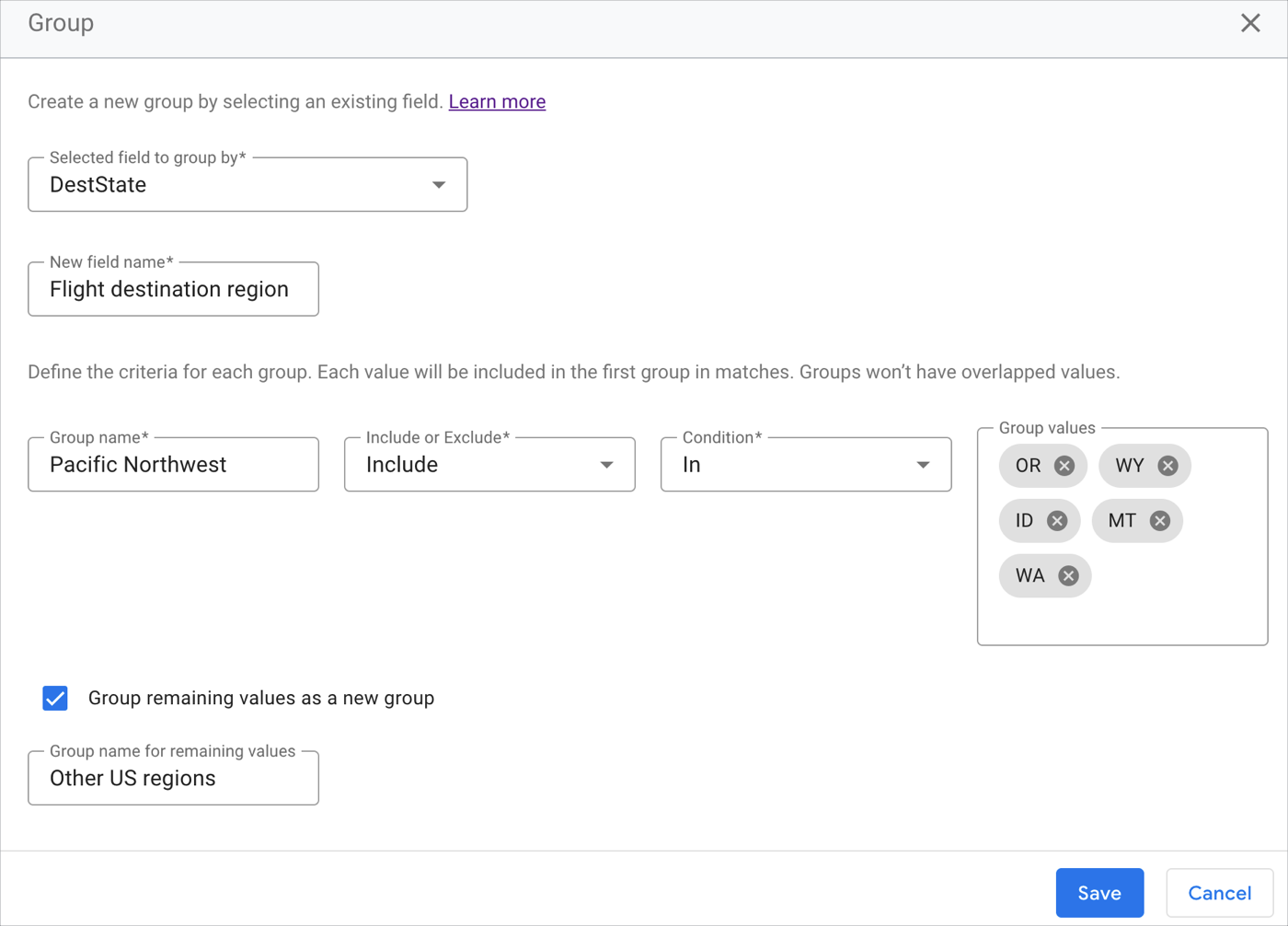
在选择要分组的字段字段中,报告创建者选择 DestState 字段。
在新字段名称字段中,报告创建者为新的分组字段提供名称。它被称为“航班目的地区域”。
在群组名称字段中,报告创建者输入了太平洋西北地区,表示太平洋西北区域中分组的州。
在包含或排除下拉菜单中,报告创建者选择包含。
在条件下拉菜单中,报告创建者选择
In函数,以便为“太平洋西北”组指定特定值。在分组值字段中,报告创建者输入了州缩写 OR、WY、ID、MT 和 WA。
报告创建者希望了解太平洋西北区域与美国其他地区的比较情况。报告创建者选中将其余值划分到一个新组中复选框。
在其余值的组名称字段中,报告创建者输入了标签美国其他地区,以便将不属于“太平洋西北地区”组的所有其余州归为一组,并使用一个标签。
报告编辑者点击保存。
生成的表格现在会显示按新的航班目的地区域维度组(美国西北太平洋沿岸地区和其他美国地区)分组的记录数指标。
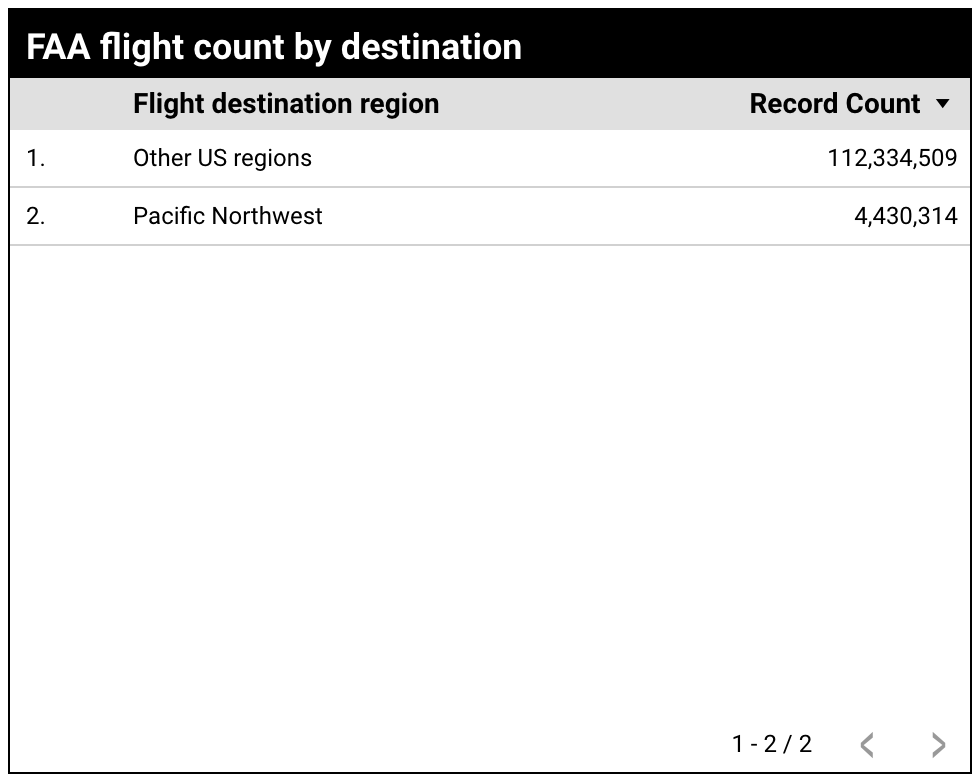
通过此表,用户可以快速了解与美国其他区域(112,334,509 次航班)相比,位于美国西北太平洋区域的航班目的地数量(4,430,314 次航班)。
创建自定义箱
借助自定义箱,您可以为数值型维度创建临时箱或数值层级,而无需在计算字段或 SQL 中开发或编码 CASE 逻辑。如果您想快速将值分组到特定的整数范围内,以调整数据的精细度,箱计算字段类型会很有帮助。
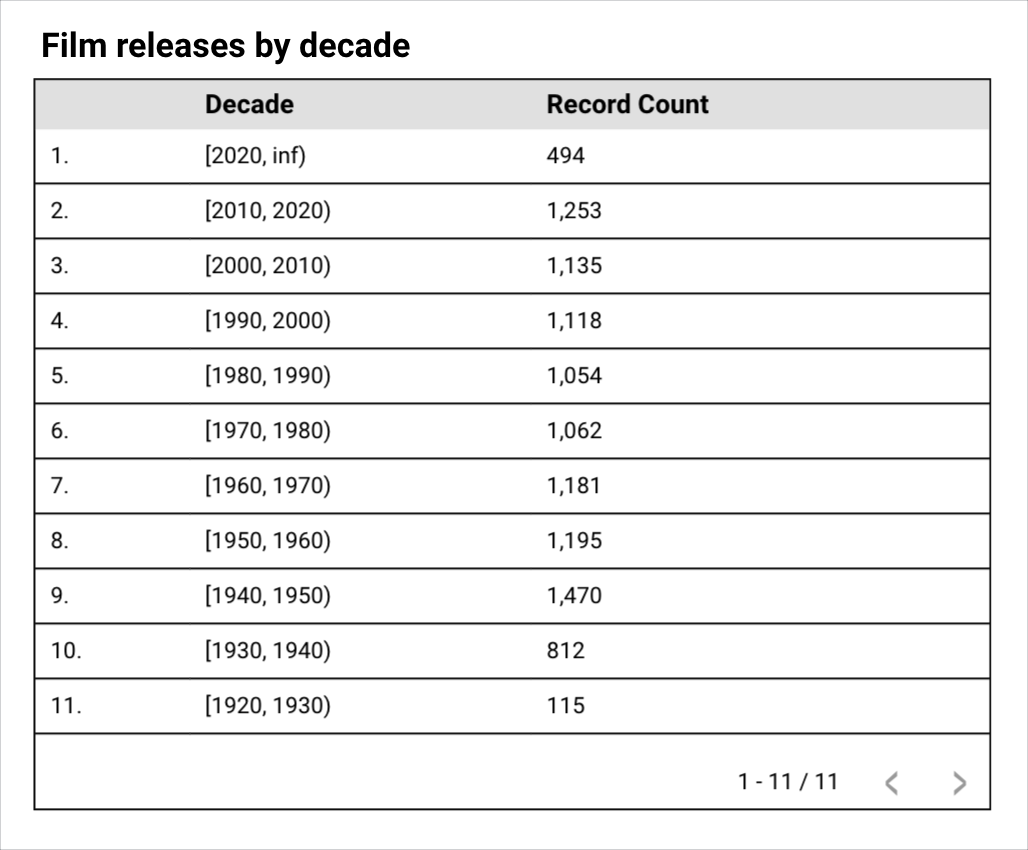
例如,名为“按年份列出的电影发行情况”的表格图表显示了按“year_film”维度(表示电影发行年份)分组的“记录数”指标。
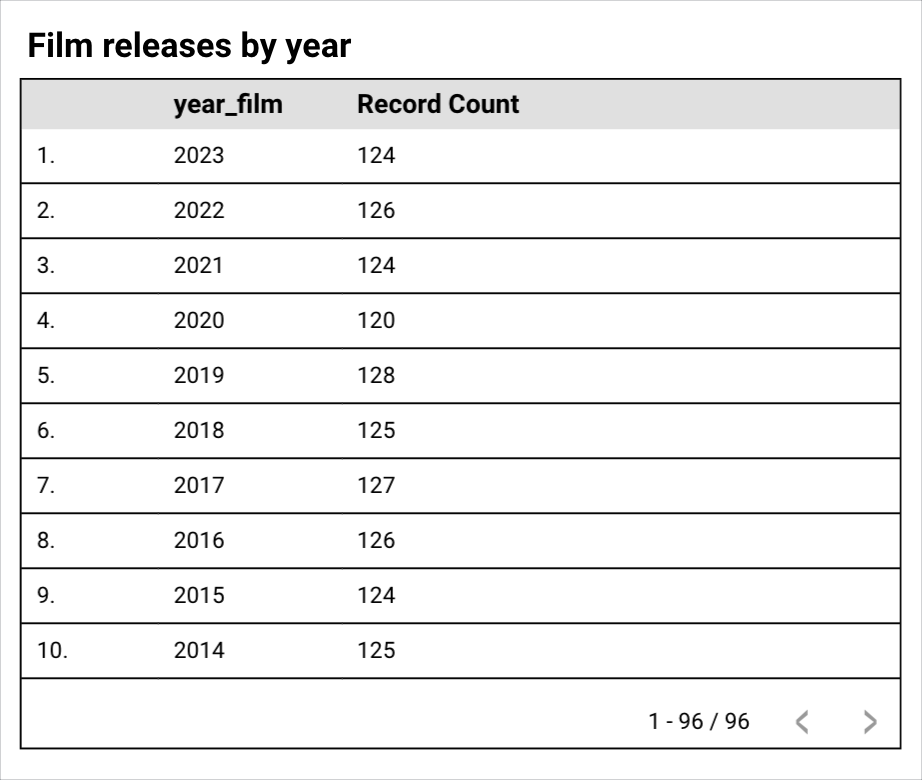
报告创建者希望按十年而不是按单个年份查看和比较数据,但数据源中没有“十年”维度。报告创建者可以通过创建自定义箱来按十年分组年份。
报告创建者通过输入以下规范,向图表中添加了一个自定义分箱计算字段:
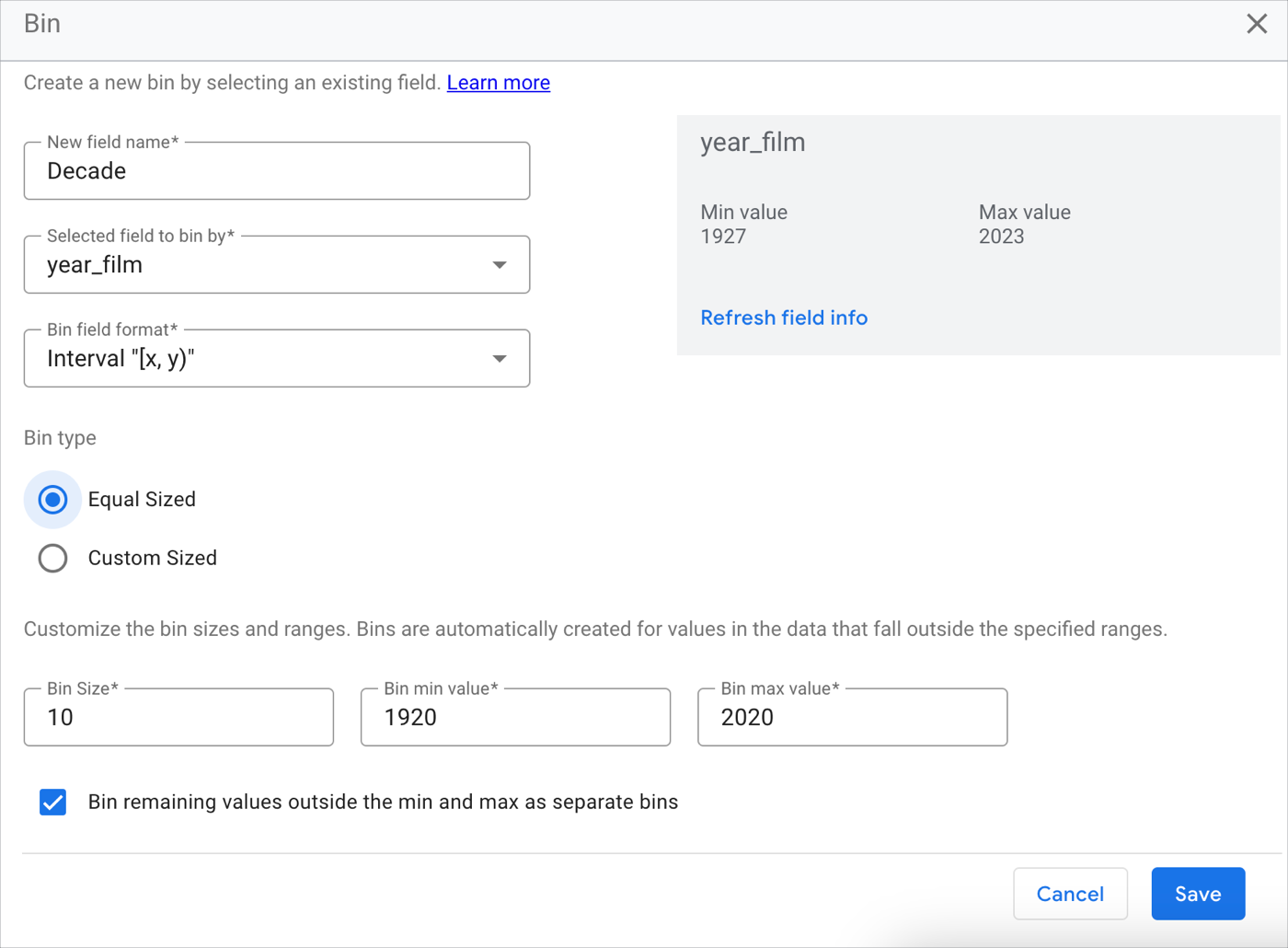
在新字段名称字段中,报告创建者为新的分组字段提供了一个名称:年代。
在要进行分箱的所选字段字段中,报告创建者选择 year_film 字段。
在箱字段格式字段中,报告创建者选择区间“[x,y)”格式。
在箱类型字段中,报告创建者选择等大小。
在箱子大小字段中,报告创建者输入 10,表示十年。
在箱最小值中,报告创建者输入 1920,以便从数据集中最早的电影发行年代开始划分箱。
在箱最大值中,报告创建者输入 2020,这会将箱的结束时间设置为数据集中的电影发布时间所在的最新十年。
为了考虑所有无关的数据点,报告创建者选中了将小于最小值和大于最大值的剩余值分箱,作为单独的分箱复选框。
报告编辑者点击保存。
生成的表格现在会显示按新的十年箱字段分组的记录数指标,以显示每个十年上映的电影数量。