このページでは、GKE Inference Gateway の設定をプレビュー版の v1alpha2 API から一般提供の v1 API に移行する方法について説明します。
このドキュメントは、GKE Inference Gateway の v1alpha2 バージョンを使用しており、最新機能を使用するために v1 バージョンにアップグレードするプラットフォーム管理者やネットワーキング スペシャリストを対象としています。
移行を開始する前に、GKE Inference Gateway のコンセプトとデプロイを理解しておいてください。GKE Inference Gateway をデプロイするを確認することをおすすめします。
始める前に
移行を開始する前に、このガイドに沿って作業する必要があるかどうかを判断します。
既存の v1alpha2 API を確認する
v1alpha2 GKE Inference Gateway API を使用しているかどうかを確認するには、次のコマンドを実行します。
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
これらのコマンドの出力によって、移行が必要かどうかが決まります。
- いずれかのコマンドが 1 つ以上の
InferencePoolリソースまたはInferenceModelリソースを返した場合は、v1alpha2API を使用しているため、このガイドに沿って操作する必要があります。 - 両方のコマンドが
No resources foundを返す場合、v1alpha2API は使用されていません。v1GKE Inference Gateway の新規インストールを続行できます。
移行パス
v1alpha2 から v1 に移行するには、次の 2 つの方法があります。
- シンプルな移行(ダウンタイムあり): このパスは高速かつシンプルですが、短時間のダウンタイムが発生します。ゼロ ダウンタイムでの移行が必要ない場合は、このパスをおすすめします。
- ゼロ ダウンタイムでの移行: このパスは、サービスの中断を許容できないユーザー向けです。これには、
v1alpha2スタックとv1スタックを並行して実行し、トラフィックを徐々に移行することが含まれます。
シンプルな移行(ダウンタイムあり)
このセクションでは、ダウンタイムを伴うシンプルな移行を行う方法について説明します。
既存の
v1alpha2リソースを削除する:v1alpha2リソースを削除するには、次のいずれかのオプションを選択します。オプション 1: Helm を使用してアンインストールする
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEオプション 2: リソースを手動で削除する
Helm を使用していない場合は、
v1alpha2デプロイに関連付けられているすべてのリソースを手動で削除します。HTTPRouteを更新または削除して、v1alpha2InferencePoolを参照するbackendRefを削除します。v1alpha2InferencePool、それを参照するInferenceModelリソース、対応する Endpoint Picker(EPP)Deployment と Service を削除します。
すべての
v1alpha2カスタム リソースが削除されたら、クラスタからカスタム リソース定義(CRD)を削除します。kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlv1 リソースをインストールする: 古いリソースをクリーンアップしたら、
v1GKE Inference Gateway をインストールします。このプロセスには次の手順が含まれます。- 新しい
v1カスタム リソース定義(CRD)をインストールします。 - 新しい
v1InferencePoolと対応するInferenceObjectiveリソースを作成します。InferenceObjectiveリソースはv1alpha2API で定義されています。 - 新しい
v1InferencePoolにトラフィックを転送する新しいHTTPRouteを作成します。
- 新しい
デプロイを確認する: 数分後、新しい
v1スタックでトラフィックが正しく処理されていることを確認します。Gateway のステータスが
PROGRAMMEDであることを確認します。kubectl get gateway -o wide出力は次のようになります。
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mリクエストを送信してエンドポイントを確認します。
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'200レスポンス コードを含む正常なレスポンスが返されることを確認します。
ゼロ ダウンタイムでの移行
この移行パスは、サービスの停止を許容できないユーザーを対象としています。次の図は、GKE Inference Gateway が複数の生成 AI モデル提供を容易にする方法を示しています。これは、ゼロ ダウンタイム移行戦略の重要な側面です。
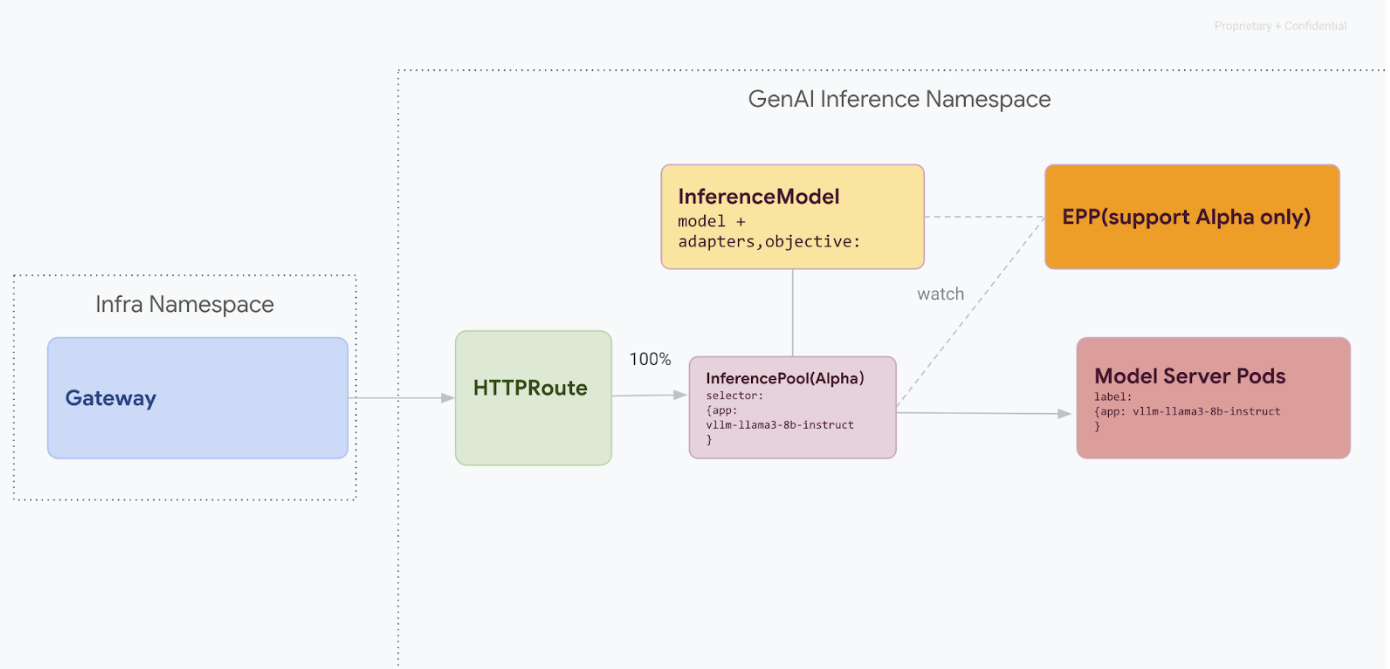
kubectl を使用した API バージョンの区別
ゼロ ダウンタイムでの移行中、v1alpha2 CRD と v1 CRD の両方がクラスタにインストールされます。これにより、kubectl を使用して InferencePool リソースをクエリするときに曖昧さが生じる可能性があります。正しいバージョンを操作するには、完全なリソース名を使用する必要があります。
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.iov1:kubectl get inferencepools.inference.networking.k8s.io
v1 API には、infpool という便利な短縮名も用意されています。これを使用すると、明確に v1 リソースをクエリできます。
kubectl get infpool
ステージ 1: サイドバイサイド v1 デプロイ
このステージでは、新しい v1 InferencePool スタックを既存の v1alpha2 スタックと一緒にデプロイします。これにより、安全かつ段階的な移行が可能になります。
このステージのすべての手順を完了すると、次の図に示すインフラストラクチャが作成されます。
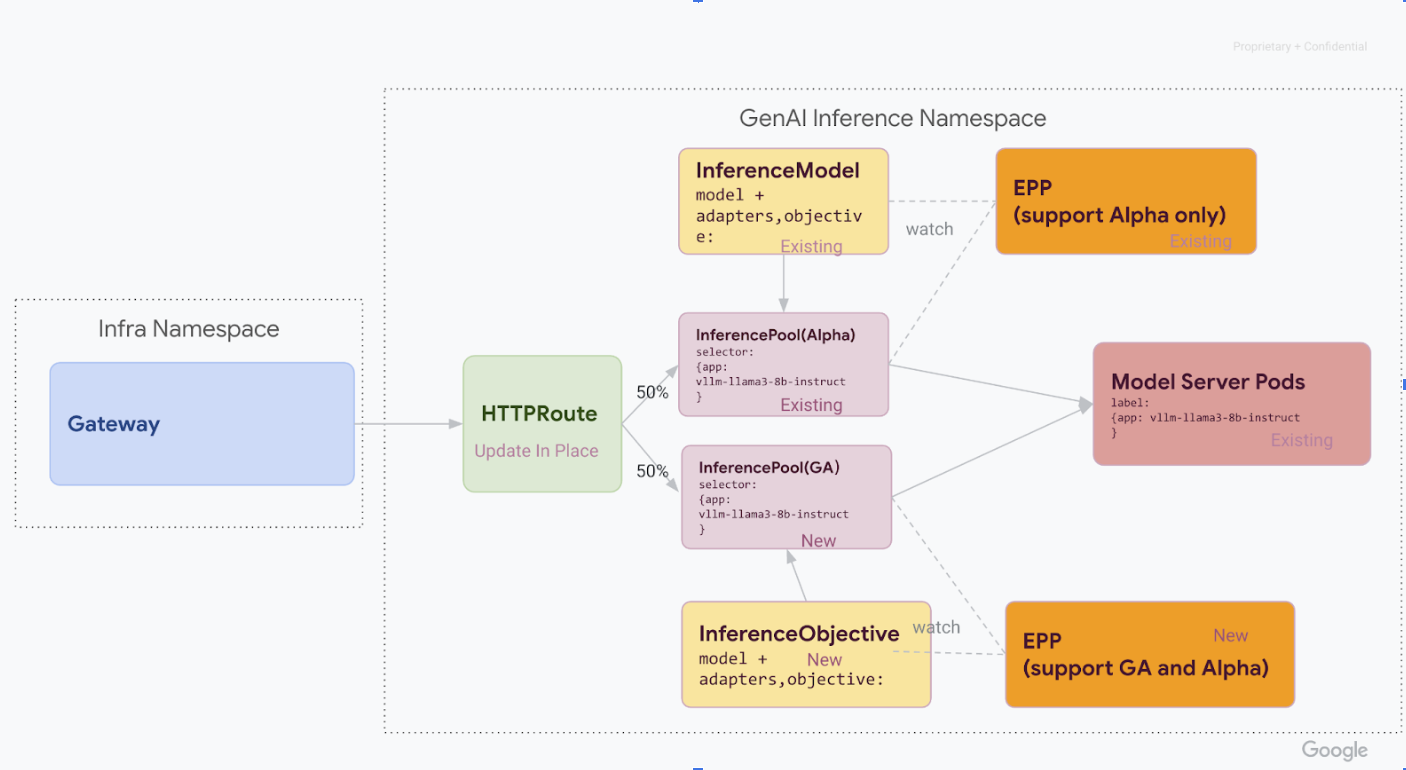
必要なカスタム リソース定義(CRD)を GKE クラスタにインストールします。
1.34.0-gke.1626000より前の GKE バージョンの場合は、次のコマンドを実行して、v1InferencePoolとアルファ版InferenceObjectiveの両方の CRD をインストールします。
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- GKE バージョン
1.34.0-gke.1626000以降の場合は、次のコマンドを実行して、アルファ版のInferenceObjectiveCRD のみをインストールします。
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yamlv1 InferencePoolをインストールします。Helm を使用して、
vllm-llama3-8b-instruct-gaのような固有のリリース名で新しいv1 InferencePoolをインストールします。InferencePoolは、inferencePool.modelServers.matchLabels.appを使用するアルファ版のInferencePoolと同じモデルサーバー Pod をターゲットにする必要があります。InferencePoolをインストールするには、次のコマンドを使用します。helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolv1alpha2 InferenceObjectiveリソースを作成します。Gateway API Inference Extension の v1.0 リリースへの移行の一環として、アルファ版の
InferenceModelAPI から新しいInferenceObjectiveAPI への移行も必要です。次の YAML を適用して、
InferenceObjectiveリソースを作成します。kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
ステージ 2: トラフィック移行
両方のスタックが実行されている状態で、HTTPRoute を更新してトラフィックを分割し、v1alpha2 から v1 へのトラフィックの移行を開始できます。この例は、50 対 50 の分割を示しています。
トラフィック分割用に HTTPRoute を更新します。
トラフィック分割の
HTTPRouteを更新するには、次のコマンドを実行します。kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOF検証とモニタリングを行います。
変更を適用したら、新しい
v1スタックのパフォーマンスと安定性をモニタリングします。inference-gatewayゲートウェイのPROGRAMMEDステータスがTRUEであることを確認します。
ステージ 3: 最終処理とクリーンアップ
v1 InferencePool が安定していることを確認したら、すべてのトラフィックを転送し、古い v1alpha2 リソースを廃止できます。
トラフィックの 100% を
v1 InferencePoolに移行します。トラフィックの 100% を
v1 InferencePoolに移行するには、次のコマンドを実行します。kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOF最終確認を行います。
すべてのトラフィックを
v1スタックに転送したら、すべてのトラフィックが想定どおりに処理されていることを確認します。Gateway のステータスが
PROGRAMMEDであることを確認します。kubectl get gateway -o wide出力は次のようになります。
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mリクエストを送信してエンドポイントを確認します。
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'200レスポンス コードを含む正常なレスポンスが返されることを確認します。
v1alpha2 リソースをクリーンアップします。
v1スタックが完全に動作していることを確認したら、古いv1alpha2リソースを安全に削除します。残りの
v1alpha2リソースを確認します。v1InferencePoolAPI に移行したので、古い CRD を削除しても安全です。既存の v1alpha2 API を確認して、使用中のv1alpha2リソースがなくなったことを確認します。残りのリソースがある場合は、それらの移行プロセスを続行できます。v1alpha2CRD を削除します。すべての
v1alpha2カスタム リソースが削除されたら、クラスタからカスタム リソース定義(CRD)を削除します。kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlすべての手順を完了すると、インフラストラクチャは次の図のようになります。
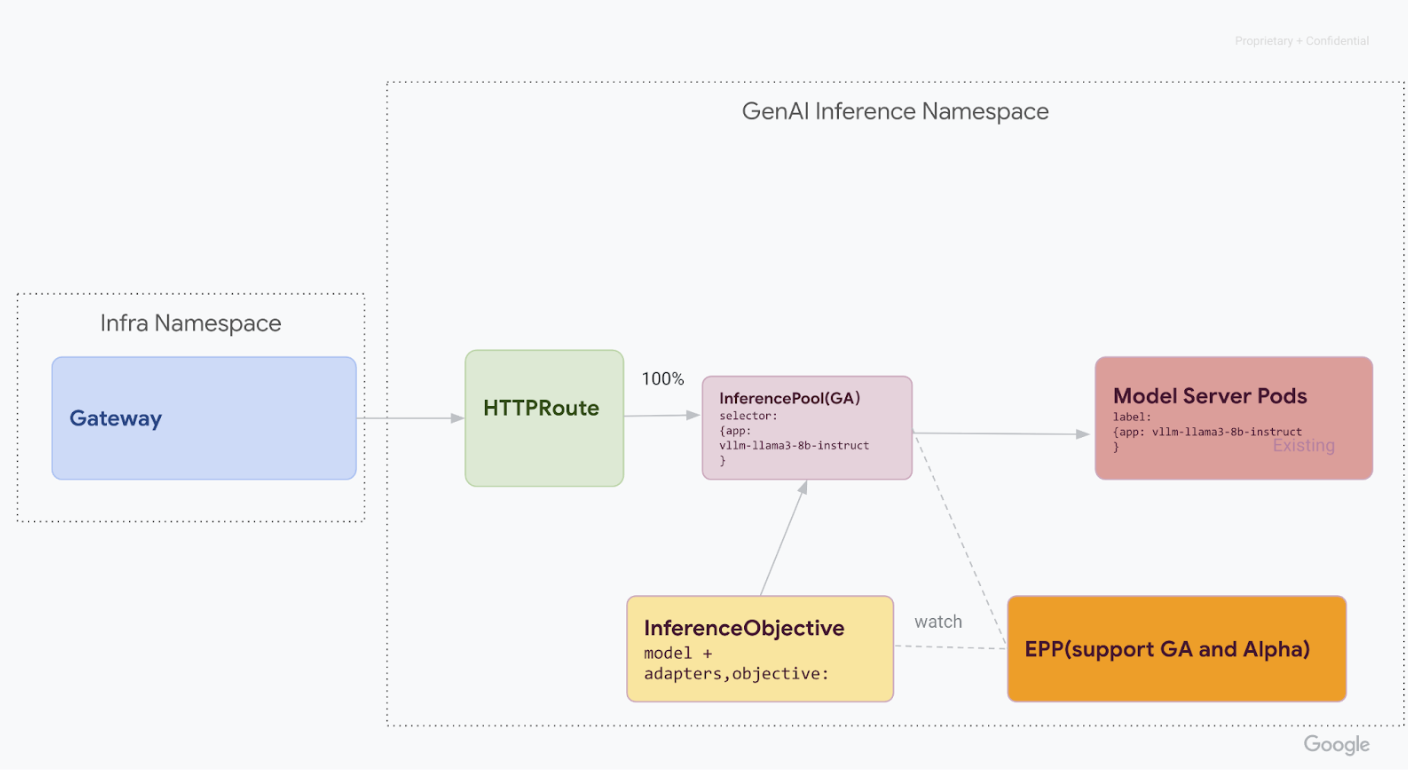
図: モデル名と優先度に基づいてさまざまな生成 AI モデルにリクエストをルーティングする GKE Inference Gateway
次のステップ
- GKE Inference Gateway をデプロイする方法を確認する。
- 他の GKE ネットワーキング機能を確認する。