Auf dieser Seite wird beschrieben, wie Sie Ihre GKE Inference Gateway-Einrichtung von der Preview-API v1alpha2 zur allgemein verfügbaren API v1 migrieren.
Dieses Dokument richtet sich an Plattformadministratoren und Netzwerkspezialisten, die die v1alpha2-Version des GKE Inference Gateway verwenden und auf die Version 1 aktualisieren möchten, um die neuesten Funktionen zu nutzen.
Bevor Sie mit der Migration beginnen, sollten Sie sich mit den Konzepten und der Bereitstellung des GKE Inference Gateway vertraut machen. Wir empfehlen, dass Sie sich GKE Inference Gateway bereitstellen ansehen.
Hinweise
Bevor Sie mit der Migration beginnen, sollten Sie prüfen, ob Sie dieser Anleitung folgen müssen.
Nach vorhandenen v1alpha2-APIs suchen
Führen Sie die folgenden Befehle aus, um zu prüfen, ob Sie die v1alpha2 GKE Inference Gateway API verwenden:
kubectl get inferencepools.inference.networking.x-k8s.io --all-namespaces
kubectl get inferencemodels.inference.networking.x-k8s.io --all-namespaces
Anhand der Ausgabe dieser Befehle lässt sich feststellen, ob eine Migration erforderlich ist:
- Wenn einer der beiden Befehle eine oder mehrere
InferencePool- oderInferenceModel-Ressourcen zurückgibt, verwenden Sie diev1alpha2API und müssen dieser Anleitung folgen. - Wenn beide Befehle
No resources foundzurückgeben, verwenden Sie diev1alpha2API nicht. Sie können mit einer Neuinstallation desv1GKE Inference Gateway fortfahren.
Migrationspfade
Es gibt zwei Möglichkeiten, von v1alpha2 zu v1 zu migrieren:
- Einfache Migration (mit Ausfallzeiten): Dieser Migrationspfad ist schneller und einfacher, führt aber zu einer kurzen Ausfallzeit. Dies ist der empfohlene Weg, wenn Sie keine Migration ohne Ausfallzeiten benötigen.
- Migration ohne Ausfallzeiten:Dieser Pfad ist für Nutzer gedacht, die sich keine Dienstunterbrechung leisten können. Dabei werden sowohl
v1alpha2- als auchv1-Stacks parallel ausgeführt und der Traffic wird nach und nach umgestellt.
Einfache Migration (mit Ausfallzeit)
In diesem Abschnitt wird beschrieben, wie Sie eine einfache Migration mit Ausfallzeit durchführen.
Vorhandene
v1alpha2-Ressourcen löschen: Wählen Sie eine der folgenden Optionen aus, um diev1alpha2-Ressourcen zu löschen:Option 1: Mit Helm deinstallieren
helm uninstall HELM_PREVIEW_INFERENCEPOOL_NAMEOption 2: Ressourcen manuell löschen
Wenn Sie Helm nicht verwenden, löschen Sie alle Ressourcen, die mit Ihrer
v1alpha2-Bereitstellung verknüpft sind, manuell:- Aktualisieren oder löschen Sie
HTTPRoute, umbackendRefzu entfernen, das auf dasv1alpha2InferencePoolverweist. - Löschen Sie die
v1alpha2InferencePool, alleInferenceModel-Ressourcen, die darauf verweisen, sowie die entsprechende EPP-Bereitstellung (Endpoint Picker) und den entsprechenden Dienst.
Nachdem alle benutzerdefinierten
v1alpha2-Ressourcen gelöscht wurden, entfernen Sie die benutzerdefinierten Ressourcendefinitionen (CRDs) aus Ihrem Cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yaml- Aktualisieren oder löschen Sie
v1-Ressourcen installieren: Nachdem Sie die alten Ressourcen bereinigt haben, installieren Sie das
v1GKE Inference Gateway. Dazu sind folgende Schritte erforderlich:- Installieren Sie die neuen benutzerdefinierten Ressourcendefinitionen (Custom Resource Definitions, CRDs) für
v1. - Erstellen Sie eine neue
v1InferencePoolund die entsprechendenInferenceObjective-Ressourcen. Die RessourceInferenceObjectiveist weiterhin in derv1alpha2API definiert. - Erstellen Sie eine neue
HTTPRoute, die Traffic an Ihre neuev1InferencePoolweiterleitet.
- Installieren Sie die neuen benutzerdefinierten Ressourcendefinitionen (Custom Resource Definitions, CRDs) für
Bereitstellung prüfen: Prüfen Sie nach einigen Minuten, ob Ihr neuer
v1-Stack Traffic korrekt bereitstellt.Prüfen Sie, ob der Gateway-Status
PROGRAMMEDlautet:kubectl get gateway -o wideDie Ausgabe sollte ungefähr so aussehen:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mPrüfen Sie den Endpunkt, indem Sie eine Anfrage senden:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{"model": "<var>YOUR_MODEL</var>","prompt": "<var>YOUR_PROMPT</var>","max_tokens": 100,"temperature": 0}'Achten Sie darauf, dass Sie eine erfolgreiche Antwort mit dem Antwortcode
200erhalten.
Migration ohne Ausfallzeiten
Dieser Migrationspfad ist für Nutzer gedacht, die sich keine Dienstunterbrechung leisten können. Das folgende Diagramm veranschaulicht, wie das GKE Inference Gateway die Bereitstellung mehrerer generativer KI-Modelle ermöglicht, was ein wichtiger Aspekt einer Migrationsstrategie ohne Ausfallzeiten ist.
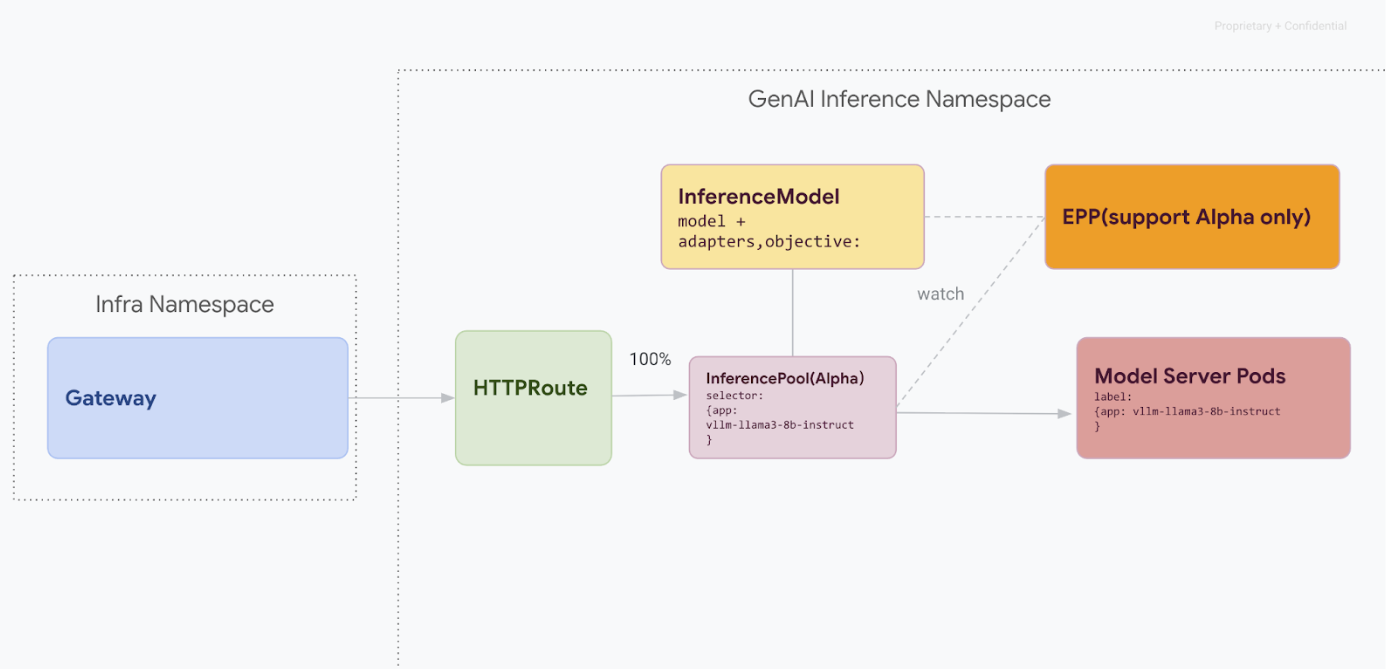
API-Versionen mit kubectl unterscheiden
Während der Migration ohne Ausfallzeiten sind sowohl v1alpha2- als auch v1-CRDs in Ihrem Cluster installiert. Dies kann zu Unklarheiten führen, wenn Sie kubectl verwenden, um InferencePool-Ressourcen abzufragen. Damit Sie mit der richtigen Version interagieren, müssen Sie den vollständigen Ressourcennamen verwenden:
Für
v1alpha2:kubectl get inferencepools.inference.networking.x-k8s.ioFür
v1:kubectl get inferencepools.inference.networking.k8s.io
Die v1 API bietet auch den praktischen Kurznamen infpool, mit dem Sie speziell v1-Ressourcen abfragen können:
kubectl get infpool
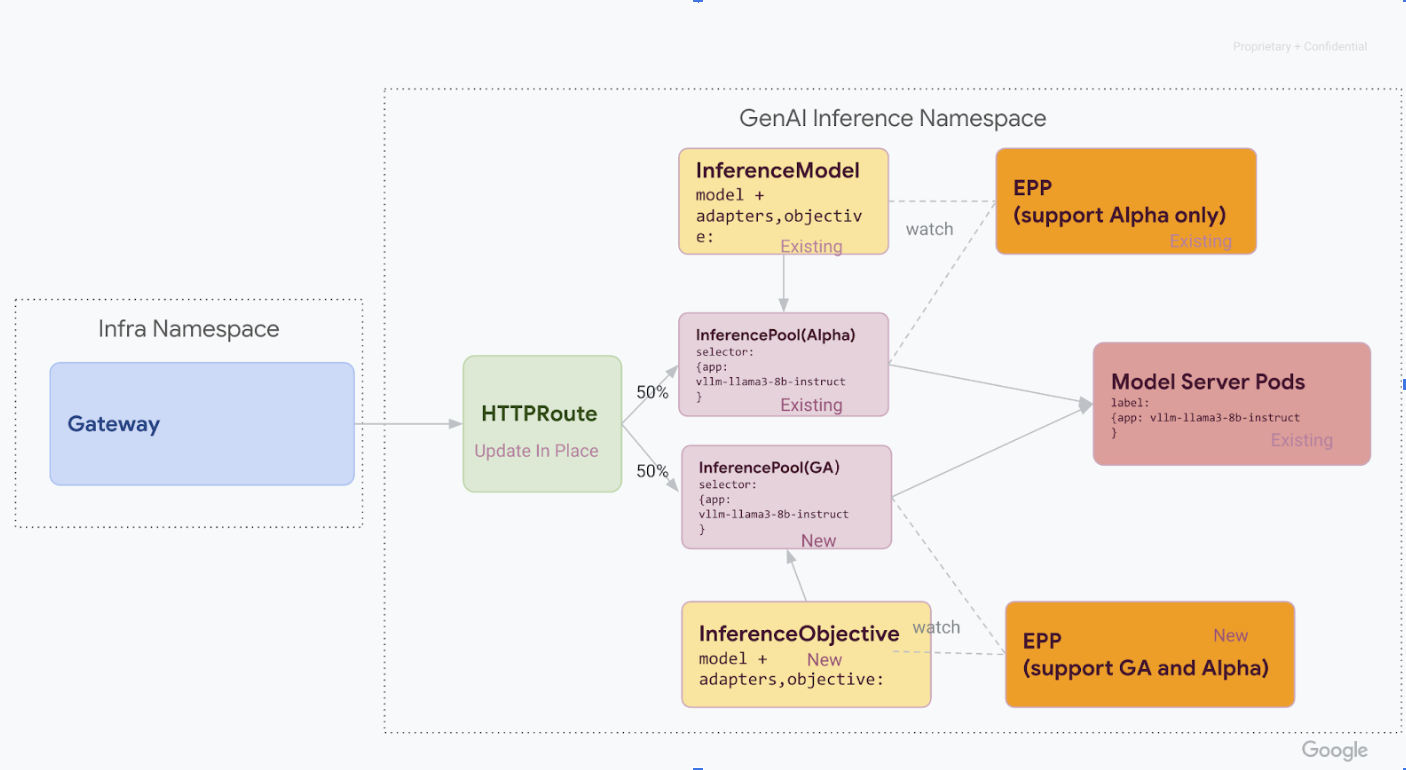
Phase 1: Paralleles V1-Deployment
In dieser Phase stellen Sie den neuen v1-InferencePool-Stack neben dem vorhandenen v1alpha2-Stack bereit, was eine sichere, schrittweise Migration ermöglicht.
Nachdem Sie alle Schritte in dieser Phase abgeschlossen haben, haben Sie die folgende Infrastruktur im folgenden Diagramm:
Installieren Sie die erforderlichen benutzerdefinierten Ressourcendefinitionen (CRDs) in Ihrem GKE-Cluster:
- Führen Sie für GKE-Versionen vor
1.34.0-gke.1626000den folgenden Befehl aus, um sowohl die v1-InferencePool- als auch die Alpha-InferenceObjective-CRDs zu installieren:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.0.0/manifests.yaml- Bei GKE-Versionen
1.34.0-gke.1626000oder höher installieren Sie nur die Alpha-InferenceObjective-CRD, indem Sie den folgenden Befehl ausführen:
kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/raw/v1.0.0/config/crd/bases/inference.networking.x-k8s.io_inferenceobjectives.yaml- Führen Sie für GKE-Versionen vor
Installieren Sie das
v1 InferencePool.Installieren Sie mit Helm eine neue
v1 InferencePoolmit einem eindeutigen Releasenamen, z. B.vllm-llama3-8b-instruct-ga. DieInferencePoolmuss mitinferencePool.modelServers.matchLabels.appauf dieselben Model Server-Pods wie die Alpha-InferencePoolausgerichtet sein.Verwenden Sie zum Installieren von
InferencePoolden folgenden Befehl:helm install vllm-llama3-8b-instruct-ga \ --set inferencePool.modelServers.matchLabels.app=MODEL_SERVER_DEPLOYMENT_LABEL \ --set provider.name=gke \ --version RELEASE \ oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepoolv1alpha2 InferenceObjective-Ressourcen erstellenIm Rahmen der Migration zur Version 1.0 der Gateway API Inference Extension müssen wir auch von der Alpha-Version der
InferenceModelAPI zur neuenInferenceObjectiveAPI migrieren.Wenden Sie die folgende YAML-Datei an, um die
InferenceObjective-Ressourcen zu erstellen:kubectl apply -f - <<EOF --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: food-review spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceObjective metadata: name: base-model spec: priority: 2 poolRef: group: inference.networking.k8s.io name: vllm-llama3-8b-instruct-ga --- EOF
Phase 2: Umstellung des Traffics
Wenn beide Stacks ausgeführt werden, können Sie den Traffic von v1alpha2 zu v1 verschieben, indem Sie HTTPRoute aktualisieren, um den Traffic aufzuteilen. In diesem Beispiel wird eine Aufteilung von 50 % / 50 % gezeigt.
HTTPRoute für die Trafficaufteilung aktualisieren
Führen Sie den folgenden Befehl aus, um die
HTTPRoutefür die Traffic-Aufteilung zu aktualisieren:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-preview weight: 50 - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 50 --- EOFÜberprüfen und überwachen.
Beobachten Sie nach der Übernahme der Änderungen die Leistung und Stabilität des neuen
v1-Stacks. Prüfen Sie, ob dasinference-gateway-Gateway denPROGRAMMED-StatusTRUEhat.
Phase 3: Fertigstellung und Bereinigung
Sobald Sie sich vergewissert haben, dass die v1 InferencePool stabil ist, können Sie den gesamten Traffic dorthin leiten und die alten v1alpha2-Ressourcen außer Betrieb nehmen.
100% des Traffics auf die
v1 InferencePoolverlagern:Führen Sie den folgenden Befehl aus, um 100 % des Traffics zur
v1 InferencePoolzu verschieben:kubectl apply -f - <<EOF --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: llm-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway rules: - backendRefs: - group: inference.networking.k8s.io kind: InferencePool name: vllm-llama3-8b-instruct-ga weight: 100 --- EOFFühren Sie die endgültige Bestätigung durch.
Nachdem Sie den gesamten Traffic an den
v1-Stack weitergeleitet haben, prüfen Sie, ob er den gesamten Traffic wie erwartet verarbeitet.Prüfen Sie, ob der Gateway-Status
PROGRAMMEDlautet:kubectl get gateway -o wideDie Ausgabe sollte ungefähr so aussehen:
NAME CLASS ADDRESS PROGRAMMED AGE inference-gateway gke-l7-regional-external-managed <IP_ADDRESS> True 10mPrüfen Sie den Endpunkt, indem Sie eine Anfrage senden:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') PORT=80 curl -i ${IP}:${PORT}/v1/completions -H 'Content-Type: application/json' -d '{ "model": "YOUR_MODEL, "prompt": YOUR_PROMPT, "max_tokens": 100, "temperature": 0 }'Achten Sie darauf, dass Sie eine erfolgreiche Antwort mit dem Antwortcode
200erhalten.
v1alpha2-Ressourcen bereinigen:
Nachdem Sie bestätigt haben, dass der
v1-Stack vollständig betriebsbereit ist, können Sie die altenv1alpha2-Ressourcen sicher entfernen.Nach verbleibenden
v1alpha2-Ressourcen suchen:Nachdem Sie zur
v1InferencePoolAPI migriert haben, können Sie die alten CRDs löschen. Prüfen Sie, ob noch v1alpha2-APIs vorhanden sind, um sicherzustellen, dass keinev1alpha2-Ressourcen mehr verwendet werden. Wenn Sie noch einige haben, können Sie den Migrationsprozess für diese fortsetzen.CRDs löschen
v1alpha2:Nachdem alle benutzerdefinierten
v1alpha2-Ressourcen gelöscht wurden, entfernen Sie die benutzerdefinierten Ressourcendefinitionen (CRD) aus Ihrem Cluster:kubectl delete -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v0.3.0/manifests.yamlNachdem Sie alle Schritte ausgeführt haben, sollte Ihre Infrastruktur dem folgenden Diagramm ähneln:
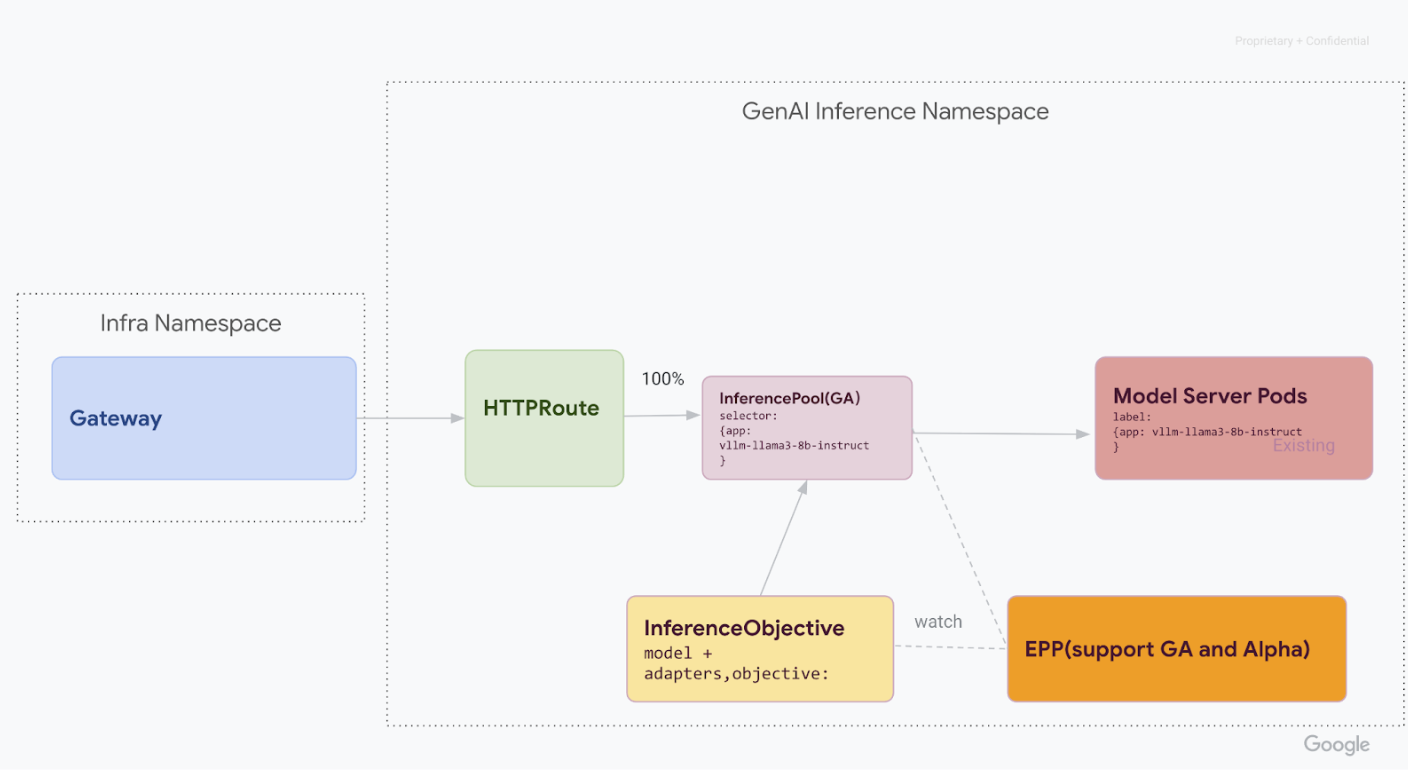
Abbildung: GKE Inference Gateway leitet Anfragen basierend auf Modellname und Priorität an verschiedene generative KI-Modelle weiter.