什麼是非監督式學習?
非監督式學習是人工智慧領域的其中一種機器學習技術,可以在沒有人類監督的情況下從資料中學習。與監督式學習不同的是,研究人員會提供未標記的資料給非監督式機器學習模型,且不給予明確指引或指示,並觀察模型如何識別出資料的模式及取得深入分析。
無論您是否注意到,人工智慧和機器學習已影響日常生活的各個層面,例如協助人類將資料轉化為洞察資訊,進而提升效率、降低成本及做出明智的決策 現今各行各業紛紛採用機器學習演算法來提供個人化推薦內容、即時翻譯,甚至能自動產生文字、圖片和其他類型的內容。
本節將說明非監督式機器學習技術的基本概念、運作方式,以及常見的現實應用。
新客戶最多可獲得價值 $300 美元的免費抵免額,盡情體驗 Vertex AI 和其他 Google Cloud 產品。
非監督式學習如何運作?
顧名思義,非監督式學習採用自我學習演算法,不需要加上標籤或事先訓練。相反地,模型會取得未加上標籤的原始資料,並必須根據相似性、差異性和模式來推論出自己的規則,並建構資訊的結構,而不需對每項資料提供明確的處理指示。
非監督式學習演算法更適合用於較為複雜的處理工作,例如將大型資料集整理成叢集。這有助於識別先前未偵測到的資料模式,可幫助找出能將資料分類的特徵。
想像您有一個大型的天氣資料集。非監督式學習演算法會檢閱資料,並找出資料點的模式。例如根據溫度或類似的天氣型態,將資料分組。
雖然演算法本身無法根據任何您先前提供的資訊來解讀這些模式,但您可以檢查資料分組,並依據您對資料集的瞭解試著分類。舉例來說,您可能會注意到,不同的溫度群組代表了四季,或是天氣模式可分成不同類型的天氣,例如雨、雨夾雪或雪。
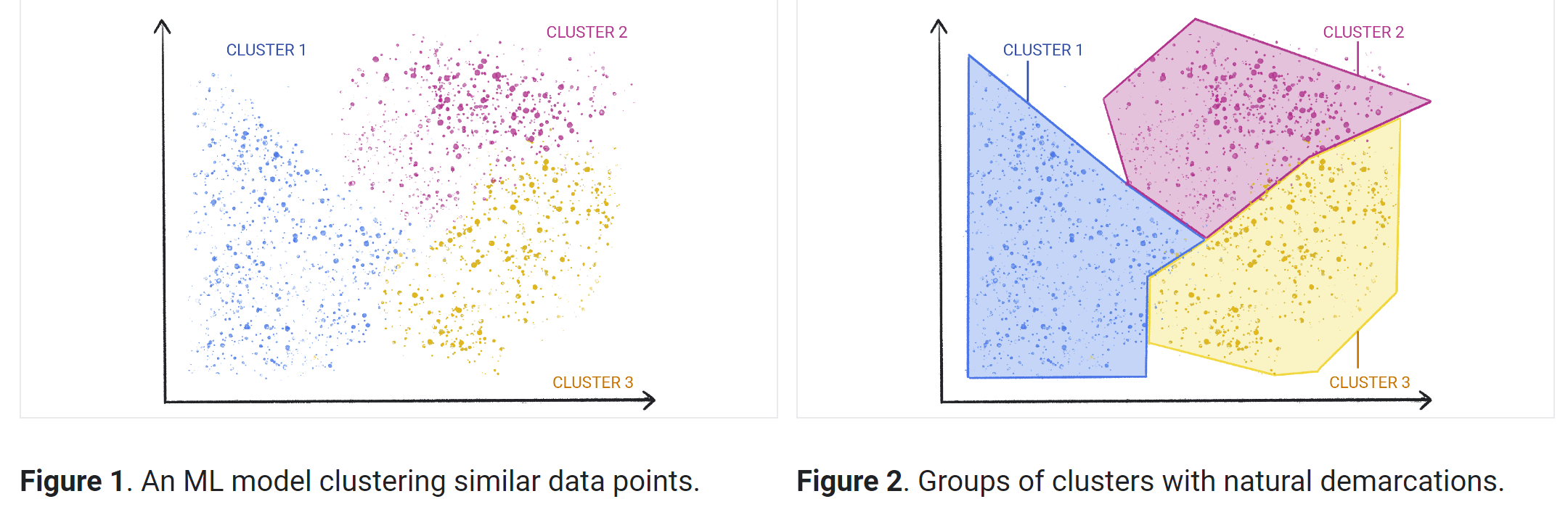
非監督式機器學習方法
一般來說,非監督式學習工作分為三種類型:分群法、關聯規則,以及降低維度。
以下將進一步說明各個非監督式學習技術。
分群
「分群法」是一種探索技術,可探索未加上標籤的原始資料,並根據相似性或差異性將這些資料分成不同的群組 (或叢集)。這項技術有多種應用方式,包括客戶區隔、詐欺偵測和圖片分析。分群演算法會在未分類的資料中找出相似的結構或規律,將資料拆分為自然群組。
分群法是最受歡迎的非監督式機器學習做法之一。用於分群的非監督式學習演算法有幾種類型,包括專屬、重疊、階層和機率性。
- 專屬分群法:資料分組的方式為單一資料點只能存在於一個叢集中。這也稱為「硬」分群法。專屬分群法的一個常見例子是 K-means 分群演算法,這個演算法會將資料點劃分為使用者定義的叢集數 K。
- 重疊分群法:資料分組的方式為單一資料點可存在於兩個以上具有不同等級會員資格的叢集中。這也稱為「軟」分群法。
- 階層分群法:系統會依據相似性,將資料分成不同的叢集,然後依據其階層關係重複合併及整理資料。階層分群法主要有兩種:聚合式分群與分散式分群。此方法也稱為階層式叢集分析 (HAC)。
- 機率性分群法:系統會根據每個資料點歸屬於每個叢集的機率,將資料分組至多個叢集。這個方法與其他方法不同,其他方法會根據資料點與叢集中其他項目的相似性來分組。
關聯
關聯規則採集是一種規則式做法,可呈現大型資料集各資料點之間的有趣關係。非監督式學習演算法會搜尋頻繁的「如果-那麼」關聯 (也稱為規則),以找出資料中的關聯性與共現性,還有資料物件之間的不同連結。
其最常見的用途是分析零售購物籃或交易資料集,以呈現特定商品被一起購買的頻率。這些演算法能找出客戶的購買模式,以及產品之間先前隱藏的關係,有助於為推薦引擎或其他交叉銷售商機提供資訊。在您最愛的線上零售店中,您可能對這些規則最為熟悉,包括「經常一起購買」和「購買這項商品的使用者也曾購買」。
關聯規則也常用於整理臨床診斷的醫療資料集。採用非監督式機器學習與關聯規則,可比較過去病患症狀之間的關係,協助醫師診斷特定病情時,可考量更多可能性。
一般而言,Apriori 演算法最常用於關聯規則學習,以識別相關的項目集合。不過也可使用其他類型的演算法,例如 Eclat 和 FP-growth 演算法。
降低維度
降低維度是一種非監督式學習技術,可減少資料集中的特徵或維度數量。資料越多,機器學習的成效通常越好,但也可能導致難以用視覺化的方式呈現資料。
降低維度技術可以擷取資料集中的重要特徵,減少不相關或隨機特徵的顯示數量。此方法使用主成分分析 (PCA) 和奇異值分解 (SVD) 演算法來減少資料輸入的數量,同時不會影響原始資料中屬性的完整性。
實際的非監督式學習範例
您已瞭解非監督式學習的基本運作原理,接著來看看有助於企業快速探索大量資料的常見使用案例。
以下列舉幾種非監督式學習的實際例子:
- 異常偵測:非監督式分群法可以處理大型資料集,並探索資料集內非典型的資料點。
- 推薦引擎:透過關聯規則,非監督式機器學習技術可協助探索交易資料,找出模式或趨勢,並用於提供線上零售商專屬的個人化推薦內容。
- 客戶區隔:非監督式學習也經常用於聚類客戶的共同特徵或購買行為,藉此產生買家人物角色資料。這些角色資料可當做制定行銷和其他業務策略的方針。
- 詐欺偵測:非監督式學習有助於偵測異常狀況,進而揭露資料集內不尋常的資料點。這類深入分析資料有助於找出偏離資料正常模式的事件或行為,藉此揭露詐欺交易或機器人活動等異常行為。
- 自然語言處理 (NLP):非監督式學習通常用於各種自然語言處理應用情境,例如將新聞專區的文章分類、翻譯和分類,或是對話式介面中的語音辨識功能。
- 基因研究:基因分群是另一種常見的非監督式學習例子。階層分群演算法通常用於分析 DNA 模式及發掘不斷變化的關係。
非監督式學習非常適合需要探索大量未加標籤資料的工作。在沒有標籤的情況下,此方法可讓企業更輕鬆地從資料中取得深入分析結果,藉此瞭解資料集的基礎結構,並識別資料集之間的模式與關係,不必由真人教導他們。
監督式學習與非監督式學習的差異
監督式學習與非監督式學習的主要差異在於你使用的輸入資料類型,與非監督式機器學習演算法不同,監督式學習是倚賴加上標籤的訓練資料,來判斷資料集內的模式識別是否準確。
監督式學習模型的目標也是預先決定的,也就是說,在系統套用演算法前,就已經知道模型的輸出內容類型。換句話說,系統會依據訓練資料將輸入內容對應至輸出內容。
相關產品和服務
Google 提供多種創新的 AI 和機器學習產品、解決方案及應用程式,讓企業輕鬆建構並實作機器學習演算法和模型。












