什么是非监督式学习?
人工智能中的非监督式学习是一种机器学习,无需人工监督,即可自行从数据中学习知识。与监督式学习不同,非监督式机器学习模型被赋予未加标签的数据,无需任何明确的指导或说明,即可发现模式和洞见。
无论您是否意识到,人工智能和机器学习正在影响日常生活的方方面面,帮助将数据转化为数据洞见,从而提高效率、降低成本并更好地为决策提供依据。如今,企业使用机器学习算法来帮助实现个性化推荐、实时翻译,甚至自动生成文本、图像和其他类型的内容。
在这里,我们将介绍非监督式机器学习的基础知识、工作原理及其在现实生活中的一些常见应用。
新客户最高可获享 $300 赠金,用于试用 Vertex AI 和其他 Google Cloud 产品。
非监督式学习的工作原理是什么?
顾名思义,非监督式学习使用的是自学习算法,在学习时无需任何标签,也无需事先训练。相反,模型会获得不带标签的原始数据,必须推断自己的规则,并根据相似之处、差异和模式来建立信息结构,且无需向该模型提供关于如何处理各项数据的明确说明。
非监督式学习算法更适合更复杂的处理任务,例如将大型数据集整理为集群。此类算法能够很好地识别数据中以前未检测到的模式,并且有助于识别用于数据分类的特征。
假设您有一个关于天气的大型数据集。非监督式学习算法会分析数据并识别数据点中的模式。例如,它可能会按温度或类似的天气模式对数据进行分组。
虽然算法本身无法根据您之前提供的任何信息来理解这些模式,但您可以查看数据分组情况,并尝试根据您对数据集的理解对其进行分类。例如,您可能知道不同的温度组代表所有四个季节,或者天气模式被划分为不同类型的天气,如雨、雨夹雪或雪。
非监督式机器学习方法
一般来说,有三种类型的非监督式学习任务:聚类、关联规则和降维。
下面,我们将更深入地探讨每种非监督式学习技术。
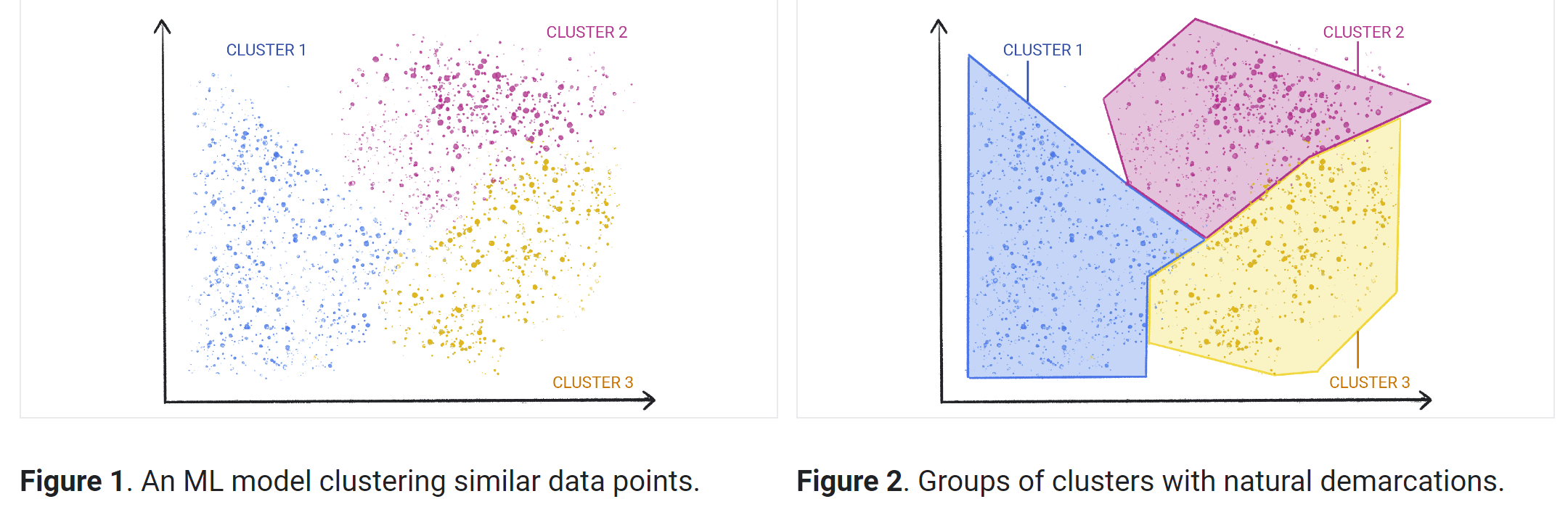
聚簇
聚类是一种探索未加标签的原始数据,并根据相似情况或差异将这些数据细分为多个组(或集群)的技术。该技术可用于各种应用,包括客户细分、欺诈检测和图像分析。聚类算法通过发现未分类数据中的相似结构或模式,将数据拆分为多个自然分组。
聚类是最常用的非监督式机器学习方法之一。用于聚类的非监督式学习算法有多种,其中包括独占算法、重叠算法、分层算法和概率学习算法。
- 独占聚类:使用此算法分组数据时,单个数据点仅能存在于一个集群中。这也称为“硬”聚类。独占聚类的一个常见示例是 K-means 聚类算法,该算法将数据点划分为用户定义的 K 个聚类。
- 重叠聚类:使用此算法分组数据时,单个数据点可存在于两个或多个关联紧密度不同的集群中。这也称为“软”聚类。
- 层次聚类:数据根据相似性分成不同的聚类,然后根据它们的层次关系反复合并和组织。层次聚类主要有两种类型:凝聚式聚类和分裂式层次聚类。这种方法也称为 HAC(层次集群分析)。
- 概率聚类:根据每个数据点属于各个集群的概率,将数据分组到各集群。这种方法与其他方法不同(根据数据点与集群中其他数据点的相似性对其进行分组)。
Association
关联规则挖掘是一种基于规则的方法,揭示大型数据集中数据点之间的有趣关系。非监督式学习算法会搜索频繁的“if-then”关联(也称为规则),以发现数据中的相关性和同现情况,以及数据对象之间的不同联系。
它最常用于分析零售购物篮或交易数据集,以展示某些商品一起购买的频率。这些算法可以揭示客户购买模式以及之前未发现的产品关系,为商品推荐引擎或其他交叉销售机会提供信息。这些规则最让人熟悉的体现形式应该是线上零售商店中“经常一起购买”和“购买过该商品的人还买过”部分。
关联规则通常也用于整理临床诊断的医疗数据集。使用非监督式机器学习和关联规则,可以帮助医生通过比较过往病例的症状之间的关系,确定特定诊断的可能性。
一般来说,Apriori 算法最常用于关联规则学习,以标识相关的内容集合。不过也会使用其他类型,例如 Eclat 算法和 FP-Growth 算法。
降维
降维是一种非监督式学习技术,用于减少数据集中的特征或维度数量。对机器学习而言,通常是数据越多越好,但是大量的数据也会增加直观呈现数据洞见的难度。
降维可以从数据集中提取重要特征,从而减少其中不相关或随机特征的数量。这种方法使用主成分分析 (PCA) 和奇异值分解 (SVD) 算法来减少数据输入的数量,同时不破坏原始数据中属性的完整性。
现实世界的非监督式学习示例
现在,您已经了解了非监督式学习的工作原理的基础知识,下面我们来看看可帮助企业快速探索大量数据的常见应用场景。
以下是一些真实的非监督式学习示例:
- 异常值检测:非监督式聚类可以处理大型数据集,并发现数据集中非典型的数据点。
- 商品推荐引擎:非监督式机器学习可以利用关联规则来探索交易数据,从而发现模式或趋势,从而为线上零售商提供个性化推荐。
- 客户细分:非监督式学习也常用于通过对客户的共同特征或购买行为进行聚类来生成买家画像。然后,您可参考这些资料来制定营销和其他业务策略。
- 欺诈检测:非监督式学习对于异常值检测很有用,可以发现数据集中的异常数据点。这些数据分析有助于发现数据中偏离正常模式的事件或行为,从而揭露欺诈性交易或机器人活动等异常行为。
- 自然语言处理 (NLP):非监督式学习通常用于各种 NLP 应用,例如对新闻版块中的文章分类、文本翻译和分类,或对话界面中的语音识别。
- 基因研究:基因聚类是另一个常见的非监督式学习例子。层次聚类算法通常用于分析 DNA 模式和揭示进化关系。
非监督式学习非常适合需要探索大量不带标签的数据的任务。这种方法使企业在没有标签的情况下可以更轻松地从数据中获取洞见,帮助他们了解数据集的底层结构并识别数据集之间的模式和关系,而无需人工指导。
监督式学习与非监督式学习
监督式学习与非监督式学习的主要区别在于您使用的输入数据类型。与非监督式机器学习算法不同,监督式学习依靠带标记的训练数据来确定数据集内的模式识别是否准确。
监督式学习模型的目标也是预先确定的,这意味着在应用算法之前就已知道模型的输出类型。换句话说,输入会根据训练数据映射到输出。
相关产品和服务
Google 提供许多创新的 AI 和机器学习产品、解决方案和应用,使企业能够轻松构建和实现机器学习算法和模型。












