O que é aprendizado não supervisionado?
O aprendizado não supervisionado em inteligência artificial é um tipo de machine learning que aprende com os dados sem supervisão humana. Ao contrário do aprendizado supervisionado, os modelos de machine learning não supervisionados recebem dados não rotulados e permitem descobrir padrões e insights sem orientação ou instrução explícita.
Quer você perceba ou não, a inteligência artificial e o aprendizado de máquina estão afetando todos os aspectos da vida diária, ajudando a transformar dados em insights que podem aumentar a eficiência, reduzir custos e melhorar informar a tomada de decisão. Atualmente, as empresas usam algoritmos de aprendizado de máquina para melhorar as recomendações personalizadas, as traduções em tempo real e até mesmo gerar automaticamente textos, imagens e outros tipos de conteúdo.
Vamos apresentar os conceitos básicos do machine learning não supervisionado, como ele funciona e algumas das aplicações reais mais comuns.
Clientes novos ganham até US$ 300 em créditos para testar a Vertex AI e outros produtos do Google Cloud.
Como funciona o aprendizado não supervisionado?
Como o nome sugere, o aprendizado não supervisionado usa algoritmos de autoaprendizagem, ou seja, aprendem sem rótulos ou treinamento prévio. Em vez disso, o modelo recebe dados brutos e não rotulados e precisa inferir as próprias regras e estruturar as informações com base em semelhanças, diferenças e padrões, sem instruções explícitas sobre como trabalhar com cada dado.
Os algoritmos de aprendizado não supervisionados são mais adequados para tarefas de processamento mais complexas, como a organização de grandes conjuntos de dados em clusters. Eles são úteis para identificar padrões anteriormente não detectados nos dados e podem ajudar a identificar atributos úteis para categorizar dados.
Imagine que você tem um grande conjunto de dados sobre clima. Um algoritmo de aprendizado não supervisionado vai analisar os dados e identificar padrões nos pontos de dados. Por exemplo, ele pode agrupar os dados por temperatura ou padrões climáticos semelhantes.
Embora o próprio algoritmo não entenda esses padrões com base nas informações anteriores que você forneceu, é possível analisar os agrupamentos de dados e tentar classificá-los com base na sua compreensão do conjunto de dados. Por exemplo, você pode reconhecer que os diferentes grupos de temperatura representam todas as quatro estações ou que os padrões climáticos estão separados em diferentes tipos de clima, como chuva, granizo ou neve.
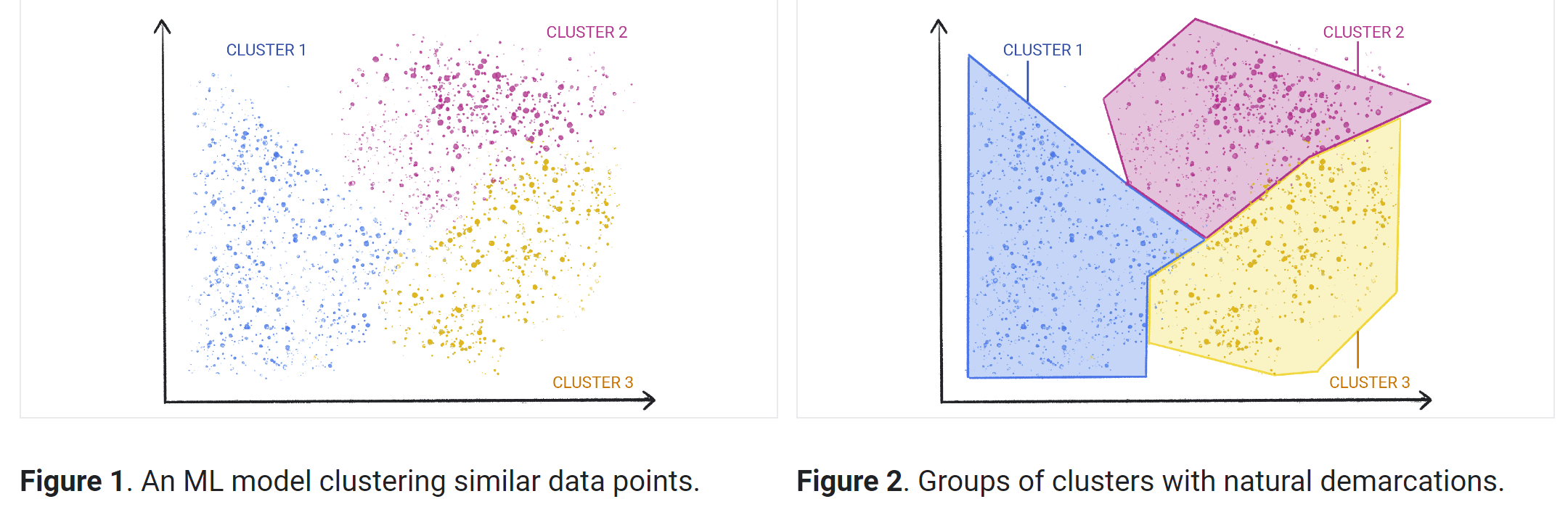
Métodos de machine learning não supervisionados
Em geral, há três tipos de tarefas de aprendizado não supervisionadas: clustering, regras de associação e redução de dimensionalidade.
Vamos conhecer melhor cada tipo de técnica de aprendizado não supervisionado.
Clustering
Clustering é uma técnica para explorar dados brutos e não rotulados e dividi-los em grupos (ou clusters) com base em semelhanças ou diferenças. Ele é usado em diversas aplicações, incluindo segmentação de clientes, detecção de fraudes e análise de imagens. Os algoritmos de clustering dividem os dados em grupos naturais ao encontrar estruturas ou padrões semelhantes em dados não categorizados.
O clustering é uma das abordagens mais conhecidas de machine learning não supervisionado. Vários tipos de algoritmos de aprendizado não supervisionados são usados para clustering, como os algoritmos exclusivos, sobrepostos, hierárquicos e probabilísticos.
- Clustering exclusivo: os dados são agrupados de maneira que um ponto de dados só possa existir em um cluster. Isso também é chamado de clustering "difícil". Um exemplo comum de clustering exclusivo é o algoritmo de clustering K-means, que particiona pontos de dados em um número K de clusters definido pelo usuário.
- Clustering sobreposto: os dados são agrupados de modo que um único ponto de dados possa existir em dois ou mais clusters com diferentes graus de associação. Isso também é chamado de clustering "soft".
- Clustering hierárquico: os dados são divididos em grupos distintos com base em semelhanças, que são repetidamente mesclados e organizados com base nas relações hierárquicas. Há dois tipos principais de agrupamento hierárquico: aglomerativo e divisivo. Esse método também é chamado de análise hierárquica de agrupamento (HAC).
- Clustering probabilístico: os dados são agrupados em clusters com base na probabilidade de cada ponto de dados pertencer a cada cluster. Essa abordagem é diferente dos outros métodos, que agrupam pontos de dados com base nas semelhanças com outros em um cluster.
Associação
A mineração de regras de associação é uma abordagem baseada em regras que revela relações interessantes entre pontos de dados em grandes conjuntos de dados. Os algoritmos de aprendizado não supervisionados procuram associações frequentes do tipo "se-então" (também chamadas de regras) para descobrir correlações e coocorrências nos dados e as diferentes conexões entre objetos de dados.
Ele é mais usado na análise de cestas de varejo ou conjuntos de dados transacionais para representar a frequência com que certos itens são comprados juntos. Esses algoritmos revelam padrões de compra dos clientes e relações anteriormente ocultas entre produtos que ajudam a informar mecanismos de recomendação ou outras oportunidades de venda cruzada. Talvez você já conheça essas regras nas seções "Comprados juntos com frequência" e "Pessoas que compraram este item também compraram" na sua loja on-line favorita.
As regras de associação também são frequentemente usadas na organização de conjuntos de dados médicos para diagnósticos clínicos. O uso de regras de associação e aprendizado de máquina não supervisionado pode ajudar os médicos a identificar a probabilidade de um diagnóstico específico ao comparar as relações entre sintomas de casos anteriores de pacientes.
Normalmente, os algoritmos Apriori são os mais amplamente utilizados para aprendizado de regras de associação para identificar coleções ou conjuntos de itens relacionados. No entanto, outros tipos são usados, como o Eclat e os algoritmos de crescimento de FP.
Redução de dimensionalidade
A redução de dimensionalidade é uma técnica de aprendizado não supervisionada que reduz o número de atributos, ou dimensões, em um conjunto de dados. Geralmente, mais dados são melhores para o machine learning, mas também podem dificultar a visualização dos dados.
A redução de dimensionalidade extrai atributos importantes do conjunto de dados, reduzindo o número de atributos irrelevantes ou aleatórios presentes. Esse método usa algoritmos de análise de componentes principais (PCA, na sigla em inglês) e de decomposição de valor singular (SVD, na sigla em inglês) para reduzir o número de entradas de dados sem comprometer a integridade das propriedades nos dados originais.
Exemplos reais de aprendizado não supervisionado
Agora que você entende o básico de como o aprendizado não supervisionado funciona, vamos analisar os casos de uso mais comuns que ajudam as empresas a analisar grandes volumes de dados rapidamente.
Confira alguns exemplos reais de aprendizado não supervisionado:
- Detecção de anomalias: o clustering não supervisionado pode processar grandes conjuntos de dados e descobrir pontos de dados atípicos em um conjunto.
- Mecanismos de recomendação : usando regras de associação, o machine learning não supervisionado pode ajudar a explorar dados transacionais para descobrir padrões ou tendências que podem ser usadas para gerar recomendações personalizadas para varejistas on-line.
- Segmentação de clientes : o aprendizado não supervisionado também é usado com frequência para gerar perfis de compradores por meio do agrupamento de características comuns ou comportamentos de compra dos clientes. Esses perfis podem ser usados para orientar o marketing e outras estratégias de negócios.
- Detecção de fraude : o aprendizado não supervisionado é útil para a detecção de anomalias, revelando pontos de dados incomuns em conjuntos de dados. Esses insights podem ajudar a descobrir eventos ou comportamentos que desviem dos padrões normais nos dados, revelando transações fraudulentas ou comportamentos incomuns, como atividades de bots.
- Processamento de linguagem natural (PLN): o aprendizado não supervisionado é comumente usado para vários aplicativos de PLN, como a categorização de artigos em seções de notícias, tradução e classificação de textos ou reconhecimento de fala em interfaces de conversa.
- Pesquisa genética : o clustering genético é outro exemplo comum de aprendizado não supervisionado. Algoritmos de agrupamento hierárquico são frequentemente usados para analisar padrões de DNA e revelar relações evolutivas.
O aprendizado não supervisionado é adequado para tarefas que exigem a exploração de grandes quantidades de dados não rotulados. Com essa abordagem, as empresas conseguem ter insights facilmente com os dados sem rótulos, o que as ajuda a entender a estrutura subjacente de um conjunto de dados e identificar padrões e relações entre eles sem que uma pessoa precise ensiná-los.
Aprendizado supervisionado e não supervisionado
A principal diferença entre o aprendizado supervisionado e o não supervisionado é o tipo de dados de entrada que você usa. Ao contrário dos algoritmos de machine learning não supervisionados, o aprendizado supervisionado depende de dados de treinamento rotulados para determinar se o reconhecimento de padrões em um conjunto de dados é preciso.
As metas dos modelos de aprendizado supervisionado também são predeterminadas, o que significa que o tipo de saída de um modelo já é conhecido antes da aplicação dos algoritmos. Em outras palavras, a entrada é mapeada para a saída com base nos dados de treinamento.
Produtos e serviços relacionados
O Google oferece vários produtos, soluções e aplicativos inovadores de IA e machine learning. Assim, as empresas podem criar e implementar facilmente algoritmos e modelos de machine learning.
 Vertex AIUma plataforma de machine learning unificada e completa para criar, implantar e escalonar modelos de IA.
Vertex AIUma plataforma de machine learning unificada e completa para criar, implantar e escalonar modelos de IA. Natural Language AIMachine learning do Google para gerar insights de textos não estruturados.
Natural Language AIMachine learning do Google para gerar insights de textos não estruturados.Solução
Ciência de dadosUm pacote completo de ferramentas de gerenciamento de dados, análise e machine learning.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











