Che cos'è l'apprendimento non supervisionato?
L'apprendimento non supervisionato nell'intelligenza artificiale è un tipo di machine learning che apprende dai dati senza la supervisione umana. A differenza dell'apprendimento supervisionato, i modelli di machine learning non supervisionato ricevono dati non etichettati e possono scoprire pattern e approfondimenti senza indicazioni o istruzioni esplicite.
Che tu te ne renda conto o meno, l'intelligenza artificiale e il machine learning stanno influenzando ogni aspetto della vita quotidiana, contribuendo a trasformare i dati in insight in grado di migliorare l'efficienza, ridurre i costi e orientare meglio il processo decisionale. Oggi le aziende ricorrono agli algoritmi di machine learning per offrire consigli personalizzati, traduzioni in tempo reale o persino generare automaticamente testi, immagini e altri tipi di contenuti.
Qui esamineremo le nozioni di base del machine learning non supervisionato, il suo funzionamento e alcune delle sue applicazioni più comuni nella vita reale.
I nuovi clienti ricevono fino a 300 $ di crediti senza costi per provare Gemini Enterprise Agent Platform e altri prodotti Google Cloud.
Come funziona l'apprendimento non supervisionato?
Come suggerisce il nome, l'apprendimento non supervisionato utilizza algoritmi di autoapprendimento: l'apprendimento ha luogo in assenza di etichette o senza alcun addestramento preliminare. Al contrario, il modello riceve dati non elaborati e non etichettati e deve dedurre le proprie regole e strutturare le informazioni in base a somiglianze, differenze e pattern senza istruzioni esplicite su come elaborare i singoli dati.
Gli algoritmi di apprendimento non supervisionato si prestano in maniera ottimale per attività di elaborazione più complesse, come l'organizzazione di grandi set di dati in cluster. Sono utili per identificare pattern non rilevati in precedenza nei dati e possono contribuire a identificare caratteristiche utili per classificare i dati.
Immagina di avere un set di dati di grandi dimensioni sul meteo. Un algoritmo di apprendimento non supervisionato analizzerà i dati identificando i pattern presenti nei punti dati. Ad esempio, potrebbe raggruppare i dati per temperatura o modelli meteorologici simili.
Anche se l'algoritmo non comprende i pattern identificati in base alle eventuali informazioni che hai fornito in precedenza, puoi esaminare i raggruppamenti di dati e cercare di classificarli in base alla tua comprensione del set di dati. Ad esempio, potresti riconoscere che i diversi gruppi di temperature rappresentano tutte e quattro le stagioni o che i modelli meteorologici sono stati suddivisi in base ai diversi tipi di condizioni meteorologiche, come pioggia, nevischio o neve.
Metodi di machine learning non supervisionato
In generale, esistono tre tipi di attività basate sull'apprendimento non supervisionato: clustering, regole di associazione e riduzione della dimensionalità.
Di seguito analizzeremo più nel dettaglio ciascun tipo di tecnica di apprendimento non supervisionato.
Clustering
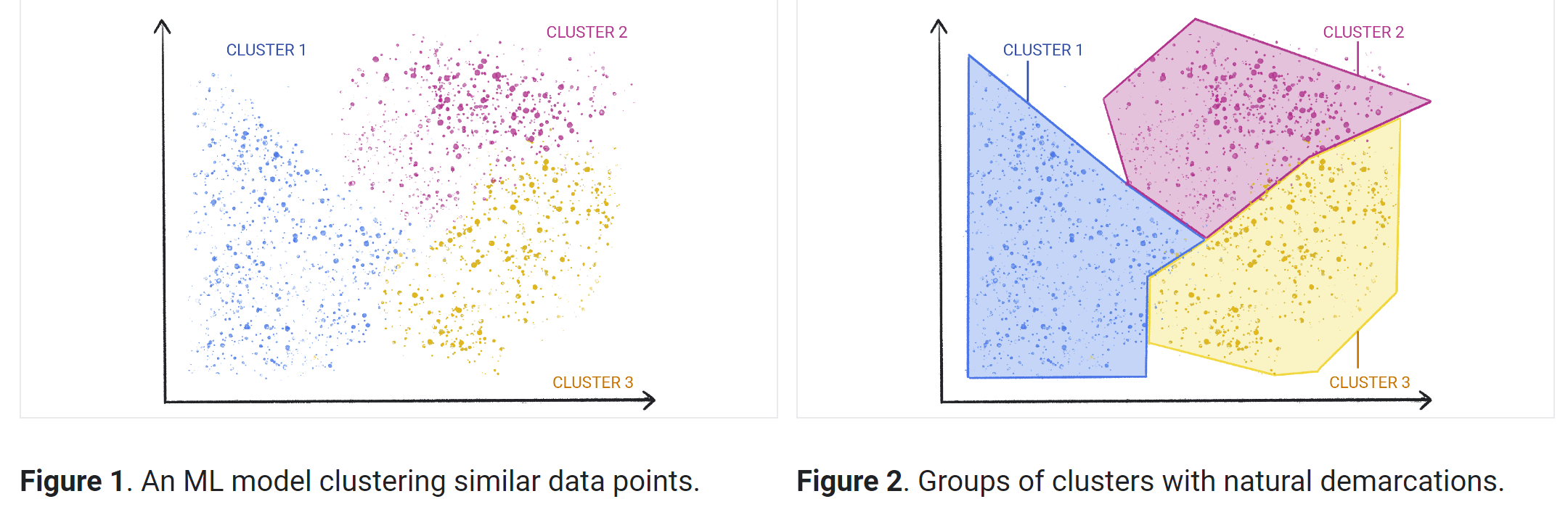
Il clustering è una tecnica utilizzata per esplorare dati non elaborati e non etichettati e suddividerli in gruppi (o cluster) in base a somiglianze o differenze. Viene utilizzato in una varietà di applicazioni, tra cui la segmentazione di clienti, il rilevamento delle frodi e l'analisi delle immagini. Gli algoritmi di clustering suddividono i dati in gruppi naturali individuando strutture o pattern simili in dati non classificati.
Il clustering è uno degli approcci di machine learning non supervisionato più diffusi. Esistono diversi tipi di algoritmi di apprendimento non supervisionato che vengono utilizzati per il clustering, che può essere di tipo esclusivo, non esclusivo, gerarchico e probabilistico.
- Clustering esclusivo: i dati sono raggruppati in modo tale che un singolo punto dati possa esistere in un unico cluster. Questo approccio è detto anche "hard clustering". Un esempio comune di clustering esclusivo è l'algoritmo di clustering delle K-means, che effettua un partizionamento dei punti dati in un numero K di cluster definito dall'utente.
- Clustering non esclusivo: i dati vengono raggruppati in modo tale che un singolo punto dati possa esistere in due o più cluster con diversi gradi di appartenenza. Questo approccio è detto anche "soft clustering".
- Cluster gerarchico: i dati vengono suddivisi in cluster distinti basati sulle somiglianze, che vengono poi ripetutamente uniti e organizzati in base alle loro relazioni gerarchiche. Esistono due tipi principali di clustering gerarchico: agglomerativo e divisivo. Questo metodo è anche noto come analisi cluster gerarchica (HAC, hierarchical cluster analysis).
- Clustering probabilistico: i dati vengono raggruppati in cluster in base alla probabilità che ciascun punto dati appartenga ai singoli cluster. Questo approccio è diverso dagli altri metodi, che raggruppano invece i punti dati in base alle loro somiglianze con gli altri presenti in un cluster.
Associazione
L'estrazione delle regole di associazione è un approccio basato su regole finalizzato a rilevare le relazioni interessanti esistenti tra i punti dati in grandi set di dati. Gli algoritmi di apprendimento non supervisionato cercano associazioni "if-then" frequenti, chiamate anche regole, per scoprire correlazioni e co-occorrenze all'interno dei dati, oltre alle diverse connessioni tra gli oggetti dati.
Questo approccio viene generalmente utilizzato per analizzare i carrelli di vendita al dettaglio o i set di dati transazionali allo scopo di rappresentare la frequenza con cui determinati articoli vengono acquistati insieme. Questi algoritmi rivelano i pattern di acquisto dei clienti e le relazioni precedentemente nascoste tra i prodotti, fornendo così informazioni utili per i motori per suggerimenti o altre opportunità di cross-sell. Queste regole potrebbero esserti più familiari dalle sezioni "Acquistati frequentemente insieme" e "Le persone che hanno acquistato questo articolo hanno acquistato anche" del tuo negozio online preferito.
Le regole di associazione vengono spesso utilizzate anche per organizzare set di dati medici per diagnosi cliniche. L'utilizzo delle regole di associazione e del machine learning non supervisionato può aiutare i medici a identificare le probabilità di una specifica diagnosi confrontando le relazioni tra i sintomi dei casi passati dei pazienti.
In genere, gli algoritmi Apriori sono quelli più utilizzati per l'apprendimento delle regole di associazione al fine di identificare raccolte di elementi correlati o insiemi di elementi. Tuttavia, vengono utilizzati anche altri tipi, come gli algoritmi Eclat e FP-growth.
Riduzione della dimensionalità
La riduzione della dimensionalità è una tecnica di apprendimento non supervisionato che riduce il numero di caratteristiche (o dimensioni) all'interno di un set di dati. In genere, più dati sono disponibili, meglio è per il machine learning, ma può anche rendere più difficile la visualizzazione dei dati.
La riduzione della dimensionalità estrae caratteristiche importanti dal set di dati, riducendo il numero di caratteristiche irrilevanti o casuali presenti. Questo metodo utilizza algoritmi di analisi delle componenti principali (ACP) e di decomposizione ai valori singolari (SVD) per ridurre il numero di input di dati senza compromettere l'integrità delle proprietà dei dati originali.
Esempi di apprendimento non supervisionato nel mondo reale
Ora che hai compreso le basi del funzionamento dell'apprendimento non supervisionato, diamo un'occhiata ai casi d'uso più comuni che aiutano le aziende a esplorare rapidamente grandi volumi di dati.
Ecco alcuni esempi di apprendimento non supervisionato nel mondo reale:
- Rilevamento di anomalie: il clustering non supervisionato può elaborare grandi set di dati e rilevare punti dati atipici in un set di dati.
- Motori per suggerimenti: utilizzando le regole di associazione, il machine learning non supervisionato può aiutarti a esaminare i dati transazionali per scoprire schemi o tendenze che possono essere utilizzati per generare suggerimenti personalizzati per i rivenditori online.
- Segmentazione dei clienti: l'apprendimento non supervisionato viene comunemente utilizzato anche per generare profili di acquirenti tipici mediante il clustering delle caratteristiche o dei comportamenti di acquisto comuni dei clienti. Questi profili possono quindi essere utilizzati per guidare il marketing e altre strategie aziendali.
- Rilevamento di frodi: l'apprendimento non supervisionato è utile per il rilevamento delle anomalie, in quanto mette in luce i punti dati insoliti all'interno dei set di dati. Queste informazioni possono contribuire a individuare eventi o comportamenti che si discostano dai normali pattern dei dati, rivelando transazioni fraudolente o comportamenti insoliti come l'attività dei bot.
- Elaborazione del linguaggio naturale (NLP): l'apprendimento non supervisionato viene comunemente utilizzato per varie applicazioni NLP, ad esempio per classificare gli articoli nelle sezioni di notizie, per la traduzione e classificazione dei testi o per il riconoscimento vocale nelle interfacce di conversazione.
- Ricerca genetica: il clustering genetico è un altro esempio comune di apprendimento non supervisionato. Gli algoritmi di clustering gerarchico vengono spesso utilizzati per analizzare sequenze di DNA e portare alla luce le relazioni evolutive.
L'apprendimento non supervisionato è adatto per attività che richiedono l'analisi di grandi quantità di dati non etichettati. Adottando questo approccio, le aziende possono ottenere più facilmente informazioni approfondite dai dati privi di etichette e comprendere così la struttura di base di un set di dati e identificare pattern e relazioni tra i set di dati senza la necessità di un intervento umano.
Apprendimento supervisionato rispetto ad apprendimento non supervisionato
La differenza principale tra apprendimento supervisionato e non supervisionato consiste nel tipo di dati di input utilizzati. A differenza degli algoritmi di machine learning non supervisionato, l'apprendimento supervisionato si basa su dati di addestramento etichettati per determinare se il riconoscimento di pattern all'interno di un set di dati è accurato.
Anche gli obiettivi dei modelli di apprendimento supervisionato sono predeterminati, il che significa che il tipo di output di un modello è già noto prima dell'applicazione degli algoritmi. In altre parole, l'input viene mappato all'output in base ai dati di addestramento.
Prodotti e servizi correlati
Google offre una serie di prodotti, soluzioni e applicazioni innovativi per l'AI e il machine learning con cui le aziende possono creare e implementare facilmente algoritmi e modelli di machine learning.
 Gemini Enterprise Agent PlatformUna piattaforma di machine learning unificata end-to-end per creare e scalare i modelli di AI ed eseguirne il deployment.
Gemini Enterprise Agent PlatformUna piattaforma di machine learning unificata end-to-end per creare e scalare i modelli di AI ed eseguirne il deployment. Natural Language AIIl machine learning di Google sarà in grado di estrarre insight da testo non strutturato.
Natural Language AIIl machine learning di Google sarà in grado di estrarre insight da testo non strutturato.Soluzione
Data scienceUna suite completa di strumenti di gestione dei dati, analisi e machine learning.
Fai un passo avanti
Inizia a creare su Google Cloud con 300 $ di crediti senza costi e oltre 20 prodotti sempre senza costi.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti


















