Apa itu unsupervised learning?
Unsupervised learning dalam kecerdasan buatan adalah jenis machine learning yang belajar dari data tanpa pengawasan manusia. Tidak seperti supervised learning, model unsupervised machine learning diberi data tidak berlabel dan diizinkan untuk menemukan pola dan insight tanpa panduan atau instruksi eksplisit.
Baik Anda sadari atau tidak, kecerdasan buatan dan machine learning memengaruhi setiap aspek kehidupan sehari-hari, sehingga membantu mengubah data menjadi insight yang dapat meningkatkan efisiensi, mengurangi biaya, dan meningkatkan sebagai informasi dalam pengambilan keputusan. Saat ini, bisnis menggunakan algoritma machine learning untuk membantu mendukung rekomendasi yang dipersonalisasi, terjemahan real-time, atau bahkan secara otomatis menghasilkan teks, gambar, dan jenis konten lainnya.
Di sini, kita akan membahas dasar-dasar unsupervised machine learning, cara kerjanya, dan beberapa aplikasi umum di kehidupan nyata.
Pelanggan baru akan mendapatkan kredit gratis senilai hingga $300 untuk mencoba Gemini Enterprise Agent Platform dan produk Google Cloud lainnya.
Bagaimana cara kerja unsupervised learning?
Seperti namanya, unsupervised learning menggunakan algoritma pembelajaran mandiri, yang mereka pelajari tanpa label atau pelatihan sebelumnya. Sebaliknya, model diberi data mentah tanpa label dan harus menyimpulkan aturannya sendiri serta menyusun informasi berdasarkan kesamaan, perbedaan, dan pola tanpa instruksi eksplisit tentang cara bekerja dengan setiap bagian data.
Algoritma unsupervised learning lebih cocok untuk tugas pemrosesan yang lebih kompleks, seperti mengatur set data besar ke dalam cluster. Insight berguna untuk mengidentifikasi pola yang sebelumnya tidak terdeteksi dalam data dan dapat membantu mengidentifikasi fitur yang berguna untuk mengategorikan data.
Bayangkan Anda memiliki set data yang besar tentang cuaca. Algoritma unsupervised learning akan memeriksa data dan mengidentifikasi pola dalam titik data. Misalnya, data tersebut dapat mengelompokkan data berdasarkan suhu atau pola cuaca yang serupa.
Meskipun algoritma itu sendiri tidak memahami pola-pola ini berdasarkan informasi apa pun yang Anda berikan sebelumnya, Anda kemudian dapat melihat pengelompokan data dan mencoba mengklasifikasikannya berdasarkan pemahaman Anda tentang set data. Misalnya, Anda mungkin mengenali bahwa kelompok suhu yang berbeda mewakili keempat musim atau bahwa pola cuaca dipisahkan menjadi berbagai jenis cuaca, seperti hujan, hujan es, atau salju.
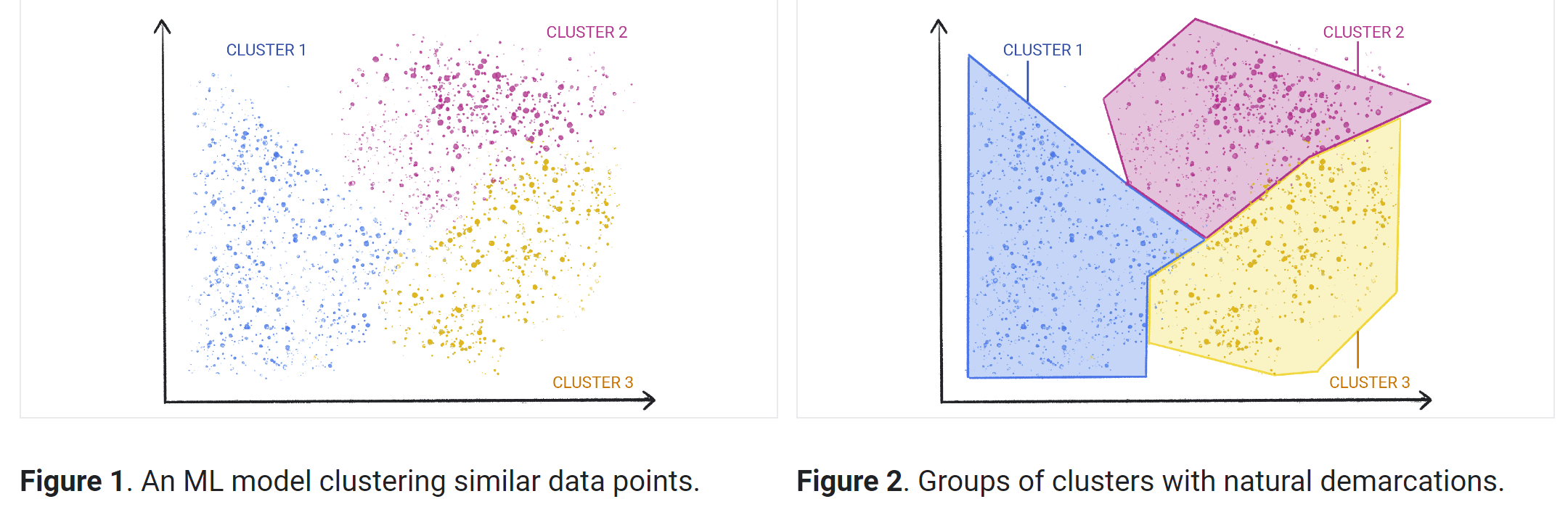
Metode unsupervised machine learning
Secara umum, ada tiga jenis tugas unsupervised learning: pengelompokan, aturan asosiasi, dan pengurangan dimensi.
Di bawah ini kita akan mempelajari lebih dalam masing-masing jenis teknik unsupervised learning.
Pengelompokan
Pengelompokan adalah teknik untuk mengeksplorasi data mentah dan tidak berlabel dan memecahnya menjadi beberapa kelompok (atau cluster) berdasarkan kesamaan atau perbedaan. Informasi ini digunakan dalam berbagai aplikasi, termasuk segmentasi pelanggan, deteksi penipuan, dan analisis gambar. Algoritma pengelompokan membagi data menjadi kelompok alami dengan menemukan struktur atau pola serupa pada data yang tidak dikategorikan.
Pengelompokan adalah salah satu pendekatan unsupervised machine learning yang paling populer. Ada beberapa jenis algoritma unsupervised learning yang digunakan untuk pengelompokan, yang meliputi eksklusif, tumpang tindih, hierarkis, dan probabilistik.
- Pengelompokan eksklusif: Data dikelompokkan sedemikian rupa sehingga satu titik data hanya dapat berada dalam satu cluster. Hal ini juga disebut sebagai pengelompokan “sulit”. Contoh umum dari pengelompokan eksklusif adalah algoritma pengelompokan K-means, yang mempartisi titik data ke dalam jumlah K cluster yang ditentukan pengguna.
- Pengelompokan tumpang-tindih: Data dikelompokkan sedemikian rupa, sehingga satu titik data dapat berada dalam dua atau lebih cluster dengan tingkat keanggotaan yang berbeda. Hal ini juga disebut sebagai pengelompokan “lembut”.
- Pengelompokan hierarkis: Data dibagi menjadi beberapa cluster yang berbeda berdasarkan kesamaan, yang kemudian berulang kali digabungkan dan diatur berdasarkan hubungan hierarkisnya. Ada dua jenis utama pengelompokan hierarkis: pengelompokan aglomeratif dan pengelompokan divisif. Metode ini juga disebut sebagai HAC—analisis pengelompokan hierarkis.
- Pengelompokan probabilistik: Data dikelompokkan ke dalam kelompok berdasarkan probabilitas setiap titik data yang dimiliki oleh setiap kelompok. Pendekatan ini berbeda dari metode lain, yang mengelompokkan titik data berdasarkan kesamaannya dengan metode lain dalam sebuah cluster.
Pengaitan
Penambangan aturan asosiasi adalah pendekatan berbasis aturan untuk mengungkapkan hubungan yang menarik antara titik data dalam set data besar. Algoritma unsupervised learning mencari asosiasi jika-maka yang sering—juga disebut aturan—untuk menemukan korelasi dan kemunculan bersama dalam data serta koneksi yang berbeda di antara objek data.
Alat ini paling umum digunakan untuk menganalisis keranjang retail atau set data transaksional untuk menunjukkan seberapa sering item tertentu dibeli bersama. Algoritma ini mengungkap pola pembelian pelanggan dan hubungan yang sebelumnya tersembunyi antara produk yang membantu menginformasikan mesin pemberi saran atau peluang cross-selling lainnya. Anda mungkin sudah mengenal aturan ini dari bagian “Sering dibeli bersama” dan “Orang-orang yang membeli item ini juga membeli” di toko retail online favorit Anda.
Aturan asosiasi juga sering digunakan untuk mengatur set data medis untuk diagnosis klinis. Menggunakan unsupervised machine learning dan aturan asosiasi dapat membantu dokter mengidentifikasi kemungkinan diagnosis tertentu dengan membandingkan hubungan antara gejala dari kasus pasien sebelumnya.
Biasanya, algoritma Apriori adalah yang paling banyak digunakan untuk mempelajari aturan asosiasi guna mengidentifikasi koleksi item atau kumpulan item terkait. Namun, jenis lain digunakan, seperti algoritma pertumbuhan FP dan Eclat.
Pengurangan dimensi
Pengurangan dimensi adalah teknik unsupervised learning yang mengurangi jumlah fitur, atau dimensi, dalam set data. Lebih banyak data umumnya lebih baik untuk machine learning, tetapi juga dapat mempersulit visualisasi data tersebut.
Pengurangan dimensi mengekstrak fitur penting dari set data, sehingga mengurangi jumlah fitur acak atau tidak relevan yang ada. Metode ini menggunakan algoritma analisis komponen prinsip dasar (PCA) dan dekomposisi nilai tunggal (SVD) untuk mengurangi jumlah input data tanpa mengorbankan integritas properti dalam data asli.
Contoh unsupervised learning di dunia nyata
Setelah Anda memahami dasar-dasar cara kerja unsupervised learning, mari kita lihat kasus penggunaan paling umum yang membantu bisnis mengeksplorasi volume data yang besar dengan cepat.
Berikut adalah beberapa contoh unsupervised learning di dunia nyata:
- Deteksi anomali: Pengelompokan yang tidak diawasi dapat memproses set data besar dan menemukan titik data yang tidak biasa dalam set data.
- Mesin pemberi saran: Dengan menggunakan aturan pengaitan, unsupervised machine learning dapat membantu mengeksplorasi data transaksional untuk menemukan pola atau tren yang dapat digunakan untuk mendorong rekomendasi yang dipersonalisasi bagi retailer online.
- Segmentasi pelanggan: Unsupervised learning juga biasa digunakan untuk menghasilkan profil persona pembeli dengan mengelompokkan karakteristik umum atau perilaku pembelian pelanggan. Profil ini kemudian dapat digunakan untuk memandu strategi pemasaran dan strategi bisnis lainnya.
- Deteksi penipuan: Unsupervised learning berguna untuk deteksi anomali, mengungkapkan titik data yang tidak biasa dalam set data. Analisis ini dapat membantu mengungkap peristiwa atau perilaku yang menyimpang dari pola normal dalam data, mengungkapkan transaksi penipuan atau perilaku tidak biasa seperti aktivitas bot.
- Natural language processing (NLP): Unsupervised learning biasanya digunakan untuk berbagai aplikasi NLP, seperti mengategorikan artikel di rubrik berita, terjemahan dan klasifikasi teks, atau pengenalan ucapan dalam antarmuka percakapan.
- Riset genetik: Pengelompokan genetik adalah contoh unsupervised learning umum lainnya. Algoritma pengelompokan hierarkis sering digunakan untuk menganalisis pola DNA dan mengungkap hubungan evolusi.
Unsupervised learning sangat cocok untuk tugas yang memerlukan eksplorasi data tidak berlabel dalam jumlah besar. Pendekatan ini memudahkan bisnis untuk mendapatkan insight dari data ketika tidak ada label, yang membantu mereka memahami struktur dasar set data serta mengidentifikasi pola dan hubungan antar-set data tanpa perlu bantuan manusia untuk mengajarinya.
Supervised learning vs. unsupervised learning
Perbedaan utama antara supervised learning dan unsupervised learning adalah jenis data input yang Anda gunakan. Tidak seperti algoritma unsupervised machine learning, supervised learning mengandalkan data pelatihan berlabel untuk menentukan apakah pengenalan pola dalam set data sudah akurat.
Tujuan model supervised learning juga sudah ditentukan sebelumnya, artinya jenis output suatu model sudah diketahui sebelum algoritma diterapkan. Dengan kata lain, input dipetakan ke output berdasarkan data pelatihan.
Produk dan layanan terkait
Google menawarkan sejumlah produk, solusi, serta aplikasi AI dan machine learning yang inovatif, yang memungkinkan bisnis membuat dan menerapkan algoritma dan model machine learning dengan mudah.
 Gemini Enterprise Agent PlatformPlatform machine learning yang terpadu dan lengkap untuk membangun, men-deploy, dan menskalakan model AI.
Gemini Enterprise Agent PlatformPlatform machine learning yang terpadu dan lengkap untuk membangun, men-deploy, dan menskalakan model AI. Natural Language AIMachine learning Google untuk mendapatkan insight dari teks yang tidak terstruktur.
Natural Language AIMachine learning Google untuk mendapatkan insight dari teks yang tidak terstruktur.Solusi
Data sciencePaket lengkap pengelolaan data, analisis, dan alat machine learning.
Langkah selanjutnya
Mulailah membangun solusi di Google Cloud dengan kredit gratis senilai $300 dan lebih dari 20 produk yang selalu gratis.
Perlu bantuan untuk memulai?
Hubungi bagian penjualanBekerja sama dengan partner tepercaya
Temukan partnerLanjutkan menjelajah
Lihat semua produk


















