Qu'est-ce que l'apprentissage non supervisé ?
Dans le domaine de l'intelligence artificielle, l'apprentissage non supervisé est un type de machine learning qui apprend à partir de données sans supervision humaine. Contrairement à l'apprentissage supervisé, les modèles de machine learning non supervisés reçoivent des données non étiquetées et identifient des modèles et des insights sans instructions ni consignes explicites.
Que vous vous en rendiez compte ou non, l'intelligence artificielle et le machine learning ont un impact sur tous les aspects de la vie quotidienne, contribuant à transformer les données en insights permettant d'améliorer l'efficacité, de réduire les coûts et de mieux éclairer la prise de décision. Aujourd'hui, les entreprises utilisent des algorithmes de machine learning (apprentissage automatique) pour proposer des recommandations personnalisées, des traductions en temps réel ou même la génération automatique de texte, d'images et d'autres types de contenus.
Nous allons aborder les principes de base du machine learning non supervisé, son fonctionnement et certaines de ses applications courantes dans la vie réelle.
Les nouveaux clients peuvent obtenir jusqu'à 300 $ de crédits pour essayer Gemini Enterprise Agent Platform et d'autres produits Google Cloud.
Comment fonctionne l'apprentissage non supervisé?
Comme son nom l'indique, l'apprentissage non supervisé utilise des algorithmes d'auto-apprentissage, c'est-à-dire qu'il apprend sans étiquettes ni entraînement préalable. Au lieu de cela, le modèle reçoit des données brutes et non étiquetées, et doit inférer ses propres règles et structurer les informations en fonction des similitudes, des différences et des modèles, sans instructions explicites sur la façon de travailler avec chaque élément de données.
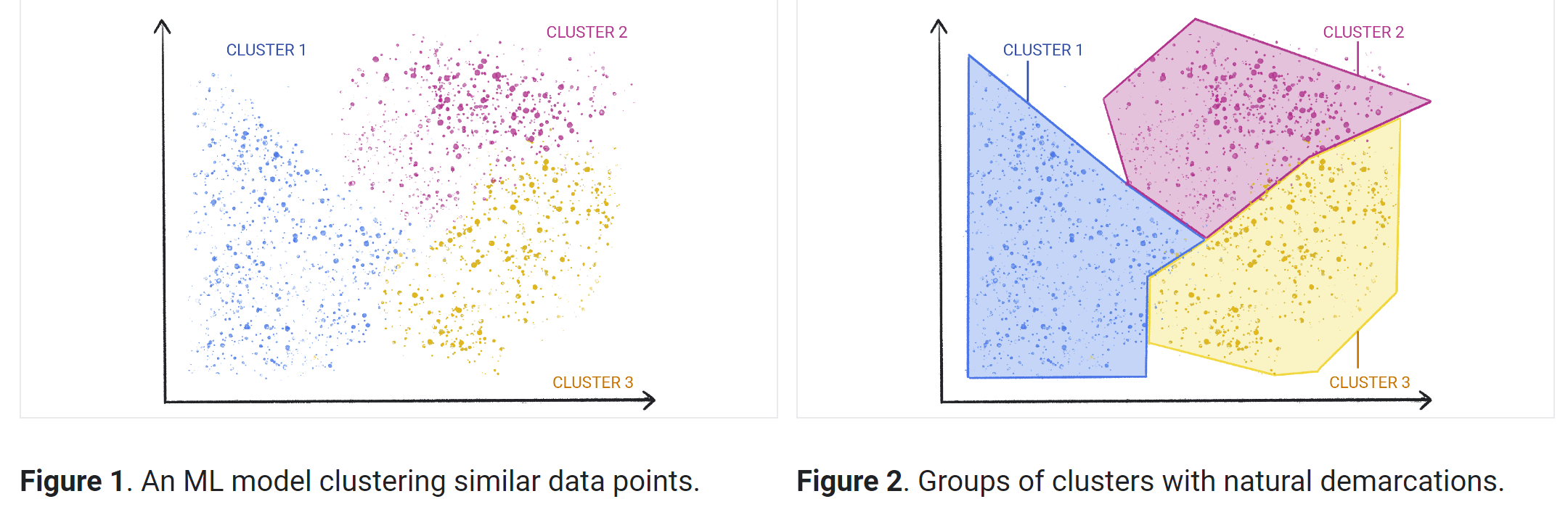
Les algorithmes d'apprentissage non supervisé sont mieux adaptés aux tâches de traitement plus complexes, telles que l'organisation de grands ensembles de données en clusters. Ils sont utiles pour identifier des modèles précédemment non détectés dans les données et peuvent aider à identifier les caractéristiques utiles pour catégoriser les données.
Imaginez que vous avez un grand jeu de données météorologiques. Un algorithme d'apprentissage non supervisé parcourt les données et identifie des tendances dans les points de données. Par exemple, il peut regrouper les données par température ou par modèles météorologiques similaires.
Bien que l'algorithme lui-même ne comprenne pas ces modèles grâce à des informations fournies précédemment, vous pouvez ensuite parcourir les regroupements de données et essayer de les classer en fonction de votre compréhension de l'ensemble de données. Par exemple, vous pourriez reconnaître que les différents groupes de températures représentent les quatre saisons ou que les modèles météorologiques sont séparés en différents types de conditions météorologiques, comme la pluie, le grésil ou la neige.
Méthodes de machine learning non supervisé
En général, il existe trois types de tâches d'apprentissage non supervisées: le clustering, les règles d'association et la réduction de la dimensionnalité.
Nous allons maintenant examiner plus en détail chaque type de technique d'apprentissage non supervisé.
Clustering
Le clustering est une technique permettant d'explorer des données brutes et non étiquetées et de les diviser en groupes (ou clusters) en fonction de leurs similitudes ou différences. Il est utilisé dans diverses applications, y compris la segmentation de la clientèle, la détection des fraudes et l'analyse d'images. Les algorithmes de clustering divisent les données en groupes naturels en trouvant des structures ou des modèles similaires dans des données non catégorisées.
Le clustering est l'une des approches de machine learning non supervisé les plus populaires. Plusieurs types d'algorithmes d'apprentissage non supervisés sont utilisés pour le clustering: exclusifs, superposés, hiérarchiques et probabilistes.
- Clustering exclusif : les données sont regroupées de telle sorte qu'un même point de données ne puisse exister que dans un seul cluster. On parle également de clustering "dur". Un exemple courant de clustering exclusif est l'algorithme de clustering en k-moyennes, qui partitionne les points de données en un nombre K de clusters défini par l'utilisateur.
- Clustering en chevauchement : les données sont regroupées de telle sorte qu'un même point de données peut exister dans deux clusters ou plus avec des degrés d'appartenance différents. On parle également de clustering "doux".
- Clustering hiérarchique : les données sont divisées en clusters distincts en fonction de leurs similitudes, et les clusters sont ensuite fusionnés de manière répétée et organisés sur la base de leurs relations hiérarchiques. Il existe deux principaux types de clustering hiérarchique: le clustering agglomératif et le clustering divisif. Cette méthode est également appelée HAC (analyse de clustering hiérarchique).
- Clustering probabiliste : les données sont regroupées en clusters en se basant sur la probabilité que chaque point de données appartienne à chaque cluster. Cette approche diffère des autres méthodes, qui regroupent des points de données en fonction de leurs similitudes avec d'autres dans un cluster.
Association
L'extraction des règles d'association est une approche basée sur des règles qui permet de révéler des relations intéressantes entre des points de données dans de grands ensembles de données. Les algorithmes d'apprentissage non supervisé recherchent des associations "si-alors" (ou règles) fréquentes afin d'identifier les corrélations et les co-occurrences dans les données, ainsi que les différentes connexions entre les objets de données.
Elle est le plus souvent utilisée pour analyser les paniers d'achats ou les ensembles de données transactionnels afin de représenter la fréquence à laquelle certains articles sont achetés ensemble. Ces algorithmes identifient les modèles d'achat des clients et les relations auparavant cachées entre les produits, ce qui permet d'orienter les moteurs de recommandations ou d'autres opportunités de vente croisée. Vous connaissez peut-être ces règles des sections "Fréquemment achetés ensemble" et "Les personnes ayant acheté cet article ont également acheté" de votre boutique en ligne préférée.
Les règles d'association sont également souvent utilisées pour organiser les ensembles de données médicales pour les diagnostics cliniques. Le machine learning non supervisé et les règles d'association peuvent aider les médecins à identifier la probabilité d'un diagnostic spécifique en comparant les relations entre les symptômes de cas précédents.
En règle générale, les algorithmes Apriori sont les plus utilisés pour l'apprentissage de règles d'association afin d'identifier des collections d'éléments ou des ensembles d'éléments connexes. Cependant, d'autres types d'algorithme sont également utilisés, par exemple Eclat ou FP-Growth.
Réduction de la dimensionnalité
La réduction de la dimensionnalité est une technique d'apprentissage non supervisée qui réduit le nombre de caractéristiques, ou dimensions, dans un ensemble de données. Pour le machine learning, il est généralement préférable d'avoir la plus grande quantité de données possible à disposition. Cependant, cela peut aussi compliquer la visualisation des données.
La réduction de la dimensionnalité extrait les caractéristiques importantes de l'ensemble de données, réduisant ainsi le nombre de caractéristiques non pertinentes ou aléatoires présentes. Cette méthode utilise des algorithmes d'analyse en composantes principales (ACP) et de décomposition en valeur singulière (SVD) pour réduire le nombre d'entrées de données sans compromettre l'intégrité des propriétés contenues dans les données d'origine.
Exemples concrets d'apprentissage non supervisé
Maintenant que vous comprenez les principes de base de l'apprentissage non supervisé, examinons les cas d'utilisation les plus courants qui aident les entreprises à explorer rapidement d'importants volumes de données.
Voici quelques exemples concrets d'apprentissage non supervisé :
- Détection d'anomalies: le clustering non supervisé peut traiter de grands ensembles de données et détecter des points de données atypiques dans un ensemble de données.
- Moteurs de recommandations: grâce à des règles d'association, le machine learning non supervisé peut vous aider à explorer des données transactionnelles afin d'identifier des modèles ou des tendances qui peuvent servir à générer des recommandations personnalisées pour les marchands en ligne.
- Segmentation de la clientèle: l'apprentissage non supervisé est aussi couramment utilisé pour générer des profils de persona d'acheteur en regroupant les caractéristiques communes ou les comportements d'achat des clients. Ces profils peuvent ensuite servir à orienter le marketing et d'autres stratégies commerciales.
- Détection des fraudes: l'apprentissage non supervisé est utile pour la détection d'anomalies, car il révèle les points de données inhabituels dans les ensembles de données. Ces insights peuvent vous aider à découvrir des événements ou des comportements qui s'écartent des schémas habituels de données, et qui peuvent révéler des transactions frauduleuses ou des comportements inhabituels tels que l'activité de bots.
- Traitement du langage naturel (NLP): l'apprentissage non supervisé est couramment utilisé pour diverses applications de NLP, comme la catégorisation des articles dans les rubriques d'actualités, la traduction et la classification de texte, ou la reconnaissance vocale dans les interfaces de conversation.
- Recherche génétique: le clustering génétique est un autre exemple courant d'apprentissage non supervisé. Les algorithmes de clustering hiérarchique sont souvent utilisés pour analyser les modèles de l'ADN et mettre en évidence des relations évolutives.
L'apprentissage non supervisé convient bien aux tâches qui nécessitent d'explorer de grandes quantités de données non étiquetées. Cette approche permet aux entreprises d'obtenir plus facilement des insights à partir des données lorsqu'aucune étiquette n'est présente. Cela les aide à comprendre la structure sous-jacente d'un ensemble de données, et à identifier des modèles et des relations entre les ensembles de données sans qu'une intervention humaine ne soit nécessaire.
Apprentissage supervisé et apprentissage non supervisé
La principale différence entre l'apprentissage supervisé et l'apprentissage non supervisé est le type de données d'entrée que vous utilisez. Contrairement aux algorithmes de machine learning non supervisé, l'apprentissage supervisé s'appuie sur des données d'entraînement étiquetées pour déterminer si la reconnaissance de formes dans un ensemble de données est exacte.
Les objectifs des modèles d'apprentissage supervisé sont également prédéterminés, ce qui signifie que le type de sortie d'un modèle est déjà connu avant l'application des algorithmes. En d'autres termes, l'entrée est mappée à la sortie sur la base des données d'entraînement.
Produits et services associés
Google propose un certain nombre de produits, de solutions et d'applications innovants basés sur l'IA et le machine learning qui permettent aux entreprises de créer et d'implémenter facilement des algorithmes et des modèles de machine learning.
 Gemini Enterprise Agent PlatformPlate-forme de machine learning unifiée et de bout en bout permettant de créer, déployer et faire évoluer des modèles d'IA.
Gemini Enterprise Agent PlatformPlate-forme de machine learning unifiée et de bout en bout permettant de créer, déployer et faire évoluer des modèles d'IA. IA Natural LanguageMachine learning de Google pour dégager des insights à partir de texte non structuré.
IA Natural LanguageMachine learning de Google pour dégager des insights à partir de texte non structuré.Solution
Data scienceUne suite complète d'outils de gestion des données, d'analyse et de machine learning
Passez à l'étape suivante
Commencez à créer sur Google Cloud avec 300 $ de crédits inclus et plus de 20 produits toujours sans frais.
Vous avez besoin d'aide pour démarrer ?
Contacter le service commercialFaites appel à un partenaire de confiance
Trouver un partenairePoursuivez vos recherches
Voir tous les produits


















